
Conteúdos
- Introdução
- Metas de lição
- Pré-requisitos
- Computação Letrada
- Instalando o Jupyter Notebooks
- Anaconda
- Usando Jupyter Notebook para pesquisa
- Abrindo o Jupyter Notebook
- Navegando na interface do Jupyter Notebook
- Upload dos dados do exemplo
- Criando um novo notebook
- Trabalhando em Jupyter Notebooks
- Salvando, exportando e publicando Jupyter Notebooks
- Usando Jupyter Notebook para ensinar
- Convertendo códigos Python
- Cadernos Jupyter para outras linguagens de programação
- Dimensionando a computação com Jupyter Notebooks
- Conclusão
- Links
- Agradecimentos
Introdução
Quando a computação é uma parte intrínseca de sua prática de pesquisa, como você publica um argumento acadêmico de forma que torne o código tão acessível e legível como a prosa que o acompanha? Na área das humanidades, a publicação de uma pesquisa assume principalmente a forma de prosa escrita, artigo ou monografia. Embora as editoras estejam cada vez mais abertas à inclusão de códigos suplementares ou outros materiais, tal arranjo inerentemente os relega a um estatuto secundário relativo ao texto escrito.
E se você pudesse publicar sua pesquisa em um formato que desse um peso equilibrado entre a prosa e o código? A realidade das atuais diretrizes de publicação acadêmica significa que a separação forçosa do seu código e da argumentação pode ser uma necessidade, e sua reunificação pode ser impossível sem que se navegue por numerosos obstáculos. Atualmente o código é tipicamente publicado em separado no GitHub ou em outro repositório, caso no qual os leitores têm que procurar uma nota de rodapé no texto para descobrir quais scripts estão sendo referenciados, encontrar a URL do repositório, acessar a URL, procurar os scripts, baixá-los e também os ficheiro(s) de dados associados, e então executar os códigos. No entanto, se você tiver os direitos e permissões necessários para republicar o texto de sua pesquisa em outro formato, o Jupyter Notebook fornece um ambiente onde código e prosa podem ser justapostos e apresentados com igual peso e valor.
Os Jupyter Notebooks têm visto uma adoção entusiástica na comunidade de ciência de dados, a ponto de cada vez mais substituir o Microsoft Word como um ambiente padrão de escrita da pesquisa. Dentro da literatura de humanidades digitais, pode-se encontrar referência a Jupyter Notebooks (separados do iPython, ou Python interativo, notebooks em 2014) desde 2015.
Os Jupyter Notebooks também ganharam força nas humanidades digitais como uma ferramenta pedagógica. Diversos tutoriais do Programming Historian, como Mineração de texto em Python através do leitor de recursos HTRC, e Extraindo páginas ilustradas de bibliotecas digitais com python, assim como outros materiais pedagógicos para oficinas fazem referência à colocação de código em um Jupyter Notebook ou ao uso do Jupyter Notebook para orientar os estudantes, permitindo que eles remixem e editem o código livremente. O formato do notebook é ideal para o ensino, especialmente quando os estudantes têm diferentes níveis de proficiência técnica e de conforto com escrita e edição dos códigos.
O objetivo dos Jupyter Notebooks é fornecer uma interface mais acessível para o código usado em pesquisa ou práticas pedagógicas com suporte digital. Ferramentas como os Jupyter Notebook são menos significativas para aprender ou ensinar no vácuo, porque os Jupyter Notebooks em si não fazem nada para promover diretamente a pesquisa ou a pedagogia. Antes de começar esta lição, pense no que você quer obter usando Jupyter Notebooks. Deseja organizar o fluxo de trabalho do seu projeto? Você quer trabalhar analisando seus dados, acompanhando as coisas que você tenta ao longo do caminho? Você quer que os leitores da sua pesquisa possam seguir os lados teóricos e técnicos do seu argumento sem alternar entre um PDF e uma pasta de scripts? Quer ministrar oficinas de programação mais acessíveis aos participantes com uma gama de conhecimentos técnicos? Você quer usar ou adaptar notebooks que outras pessoas escreveram? Tenha seu objetivo em mente enquanto você trabalha nesta lição. Dependendo de como você imagina usar Jupyter Notebooks, você pode ser capaz de pular seções que são mais aplicáveis em outro contexto.
Metas de lição
Nesta lição você aprenderá:
-
O que são Jupyter Notebooks
-
Como instalar, configurar e usar o pacote de software do Jupyter Notebook
-
Quando os cadernos podem ser úteis em pesquisas e contextos pedagógicos
Para esta lição, vamos trabalhar em um cenário de uso de Jupyter Notebooks para analisar dados e, em seguida, adaptar esse mesmo notebook e dados para uso em sala de aula. A aula também abordará temas mais avançados relacionados aos Jupyter Notebooks, tais como:
-
Usando Jupyter Notebook para linguagens de programação que não sejam Python
-
Convertendo o código Python existente em Jupyter Notebooks
-
Usando Jupyter Notebooks para ampliar a capacidade computacional em ambientes como clusters de computação de alto desempenho
Pré-requisitos
Esta lição é adequada para iniciantes intrépidos, assumindo pouca experiência técnica anterior.
Na verdade, o Jupyter Notebook é um ótimo recurso para pessoas que estão aprendendo a escrever código.
Dependendo do notebook que você quer executar, você pode precisar instalar alguns módulos Python com pip, que assume alguma familiaridade com a linha de comando (para windows aqui, ou Mac/Linux aqui (em inglês)).
A lição é escrita usando o Jupyter Notebook 6.0, mas a interface do usuário e a funcionalidade do software tem sido bastante consistente entre as versões.
Computação Letrada
A relação entre código legível por computador e texto legível por humanos ganhou visibilidade dentro da ciência da computação na década de 1970, quando Donald Knuth propôs o paradigma da “programação letrada” (ou “programação alfabetizada”). Em vez de organizar o código de acordo com os requisitos que privilegiam a execução do código pelo computador, a programação letrada trata um programa como literatura compreensível aos seres humanos, priorizando o próprio processo de pensamento do programador. A programação letrada projetada por Knuth assume a forma de prosa escrita, com código acionável por computador incorporado em macros (um formato abreviado para escrever código). Ferramentas de programação letrada são usadas para gerar duas saídas do programa letrado: código “emaranhado” que pode ser executado pelo computador e documentação formatada “tecida”.1
Fernando Pérez, o criador do ambiente de programação iPython que acabou se tornando o Projeto Jupyter, cunhou o termo computação letrada para o modelo usado pelos Jupyter Notebooks:
Um ambiente de computação letrado é aquele que permite aos usuários não apenas executar comandos, mas também armazenar os resultados desses comandos em um formato de documento literário, juntamente com figuras e com texto em formato livre que pode incluir expressões matemáticas formatadas. Na prática, ele pode ser visto como uma mistura de um ambiente de linha de comando, como o shell Unix, com um processador de texto, uma vez que os documentos resultantes podem ser lidos como texto, mas contêm blocos de código que foram executados pelo sistema computacional subjacente.2
Jupyter não é nem o primeiro e nem o único exemplo de cadernos computacionais. Já na década de 1980, interfaces de notebook estavam disponíveis através de softwares como Wolfram Mathematica e MATLAB. Em 2013, Stéfan Sinclair e Geoffrey Rockwell propuseram “cadernos Voyant” baseados no modelo de Mathematica, que exporia algumas das suposições que sustentam as Ferramentas Voyant e as tornaram configuráveis pelo usuário.3 Eles desenvolveram ainda esse conceito em A Arte da Análise de Texto Literário Cadernos Spyral.
Jupyter ganhou força em muitos campos como um ambiente de código aberto compatível com inúmeras linguagens de programação. O nome Jupyter é uma referência às três linguagens principais suportadas pelo projeto (Julia, Python e R), mas núcleos estão disponíveis que tornam o Jupyter compatível com dezenas de idiomas, incluindo Ruby, PHP, Javascript, SQL e Node.js. Pode não fazer sentido implementar projetos em todas essas línguas usando Jupyter Notebooks (por exemplo, Omeka não permitirá que você instale um plugin escrito como um Jupyter Notebook), mas o ambiente Jupyter ainda pode ser valioso para documentar códigos, ensinar linguagens de programação e fornecer aos alunos um espaço onde eles podem facilmente experimentar com exemplos fornecidos.
Instalando o Jupyter Notebooks
Desde o final de 2019, existem dois grandes ambientes que você pode usar para executar Jupyter Notebooks: O Jupyter Notebook (não confundir com os próprios ficheiro(s) do Jupyter Notebook, que possuem uma extensão .ipynb), e o mais novo Jupyter Lab. O Jupyter Notebook é amplamente usado e bem documentado, e fornece um navegador simples de ficheiro(s), juntamente com o ambiente para criar, editar e executar os notebooks. Jupyter Lab é mais complexo, com um ambiente de usuário mais parecido com um Ambiente de Desenvolvimento Integrado (discutido em tutoriais anteriores do Programming Historian para Windows, Mac e Linux). Embora o Jupyter Lab seja feito para, eventualmente, substituir o Jupyter Notebook, não há indicação de que o Jupyter Notebook deixará de ser suportado tão cedo. Devido à sua simplicidade comparativa e facilidade de uso para iniciantes, este tutorial usa o Jupyter Notebook como o software para executar ficheiro(s) de notebook. Ambos os pacotes de software estão incluídos na Anaconda, descrita abaixo. É mais fácil usar a Anaconda para instalar o Jupyter Notebook, mas se você já tem Python instalado em seu sistema e não quer lidar com o grande pacote Anaconda, você pode executar pip3 install jupyter (para Python 3).
Anaconda
Anaconda é uma distribuição gratuita de código aberto de Python e R que vem com mais de 1.400 pacotes, o gerenciador de pacotes Conda para instalação de pacotes adicionais, e o navegador Anaconda, que permite gerenciar ambientes (por exemplo, você pode instalar diferentes conjuntos de pacotes para diferentes projetos, para que eles não causem conflitos uns para os outros) usando uma interface gráfica. Após a instalação da Anaconda, você pode usar o navegador Anaconda para instalar novos pacotes (ou conda install através da linha de comando), mas muitos pacotes estão disponíveis apenas através de pip (ou seja, usando pip install através da linha de comando ou em seu Jupyter Notebook).
Para a maioria dos propósitos, você deve optar pela versão Python 3 do Anaconda, mas alguns códigos ainda podem ser escritos em Python 2. Nesta lição, você usará Python 3. O instalador Anaconda tem mais de 500 MB, e após a instalação pode levar mais de 3 GB de espaço no disco rígido, por isso certifique-se de que você tem espaço suficiente no computador e uma conexão de rede rápida antes de começar.
Para baixar e instalar a Anaconda, acesse o site da Anaconda. Certifique-se de ter clicado no ícone do seu sistema operacional (que deve alterar o texto Anaconda [número da versão] para [sistema operacional selecionado], de forma a indicar o seu sistema operacional) e, em seguida, clique no botão Baixar na caixa para a versão atual do Python 3. Se você estiver no Windows, deve baixar um ficheiro .exe; em Mac, é .pkg; no Linux, é .sh.
Abra normalmente o ficheiro para instalar o software em seu sistema operacional. Mais detalhes de instalação estão disponíveis nos documentos da Anaconda, incluindo como instalar a Anaconda através da linha de comando em cada sistema operacional. Se o computador não conseguir abrir o ficheiro que você baixou, certifique-se de selecionar o sistema operacional correto antes de baixar o instalador. No Windows, não deixe de escolher a opção de “Adicionar Anaconda à PATH Variable” durante o processo de instalação, ou você não poderá lançar Jupyter Notebook a partir da linha de comando.
Usando Jupyter Notebook para pesquisa
Esta lição descreve como você pode inicialmente escrever um Jupyter Notebook para análise de dados como parte de um projeto de pesquisa e, em seguida, adaptá-lo para uso em sala de aula. Embora este exemplo em particular seja extraído de estudos de fãs, ele se concentra na conversão de datas, que é amplamente necessária na análise de dados históricos e literários.
Abrindo o Jupyter Notebook
Supondo que você já tenha instalado a Anaconda como descrito acima, você pode abrir o Anaconda Navigator como qualquer outro aplicativo de software (você pode fechar o prompt sobre a criação de uma conta na nuvem do Anaconda; você não precisa de uma conta para trabalhar com o Anaconda). Na tela inicial, você deve ver um conjunto de ícones e breves sinopses sobre cada aplicativo incluído no Anaconda.
Clique no botão “Iniciar” sob o ícone do Jupyter Notebook.
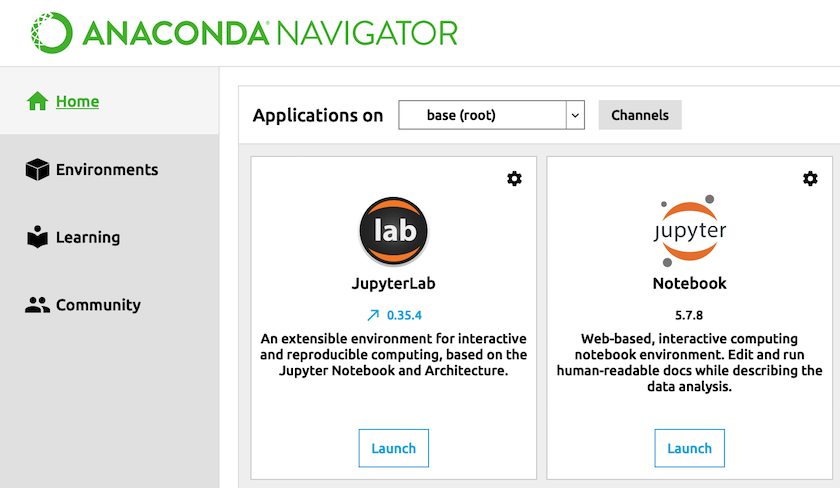
Figura 1. Interface do Anaconda Navigator
Se você preferir usar a linha de comando em vez do navegador Anaconda, uma vez que você tenha o Anaconda instalado, você deve ser capaz de abrir uma nova janela Terminal (Mac) ou Command Prompt (Win) e executar jupyter notebook para iniciar o navegador web com o aplicativo Jupyter Notebook. Se você estiver usando a linha de comando para iniciar o Jupyter Notebook, preste atenção no diretório em que você está quando o iniciar. Essa pasta se torna o diretório doméstico que aparecerá imediatamente na interface Jupyter Notebook, conforme descrito abaixo.
As duas abordagens abrirão uma nova janela ou guia no seu navegador padrão com a interface Jupyter Notebook. O Jupyter Notebook é baseado no navegador: você só interage com ele através do seu navegador, mesmo quando o Jupyter Notebook está sendo executado no seu próprio computador.
Navegando na interface do Jupyter Notebook
A interface do gerenciador de ficheiro do Jupyter Notebook é a principal maneira de abrir um ficheiro Jupyter Notebook (.ipynb). Se você tentar abrir em um editor de texto simples, o notebook será exibido como um ficheiro JSON, não com blocos interativos de código. Para visualizar um notebook através da interface Jupyter, você tem que abrir o Jupyter Notebook primeiro (que será exibido em uma janela do navegador), e abrir o ficheiro de dentro do Jupyter Notebook. Infelizmente, não há como definir o Jupyter Notebook como o aplicativo de software padrão para abrir ficheiro.ipynb quando você clica duas vezes neles.
Quando você lança o Jupyter Notebook do navegador Anaconda, ele exibe automaticamente o diretório doméstico. Este é geralmente o diretório com seu nome de usuário em um Mac (/Users/seu nome de usuário). Em um PC geralmente é C: \ . Se você abrir o Jupyter Notebook a partir da linha de comando, ele exibirá o conteúdo da pasta em que você estava quando o lançou (usando a linha de comando, você também pode lançar diretamente um notebook específico, por exemplo, jupyter-notebook-example.ipynb.)
Para evitar desordenar esta pasta, você pode fazer uma nova pasta dentro deste diretório para seus notebooks. Você pode fazer isso na sua interface usual de gerenciamento de ficheiro(s)(Finder no Mac, ou File Explorer no Windows), ou dentro do próprio Jupyter Notebook, já que o Jupyter Notebook, assim como o Google Drive, fornece uma interface de gerenciamento de ficheiro(s) dentro de um navegador, bem como uma interface de menu e de barra de ferramentas para a criação de ficheiro(s). Para adicionar uma nova pasta no Jupyter Notebook, clique em Novo no canto superior direito e escolha Pasta. Isso criará uma nova pasta chamada “Pasta Sem Título”. Para alterar o nome, clique na caixa de seleção à esquerda da “Pasta Sem Título”, em seguida, clique no botão “Renomear” que aparece na guia “ficheiro(s)”. Nomeie os notebooks da pasta. Clique nele para abrir essa pasta.
Upload dos dados do exemplo
O ficheiro CSV de exemplo para esta lição é um extrato de metadados de fan fiction de Harry Potter coletados do site de fanfic italiano https://efpfanfic.net, depois limpos usando uma combinação de expressões regulares e OpenRefine. O CSV tem três colunas: a classificação da história (similar a uma classificação de filme), a data que foi originalmente publicada, e a data mais recente de atualização. As opções de classificação são verde (verde), giallo (amarelo), arancione (laranja), e rosso (vermelho). A publicação e as datas atualizadas são criadas automaticamente; quando consistente a história é postada no site ou atualizado, assim você pode tomá-las como consistentes.
Baixe o ficheiro CSV.
Dentro do navegador de ficheiro(s) Jupyter Notebook, você deve estar dentro do diretório de notebooks que acabou de criar. No canto superior direito, clique no botão “Carregar” e carregue o ficheiro CSV de amostra. Será mais fácil de acessar se estiver no mesmo diretório do Jupyter Notebook que você criará na próxima etapa a fim de converter as datas.

Figura 2. Upload de ficheiro(s) na interface Jupyter Notebook
Observe que esta não é a única maneira de fazer os ficheiro(s) aparecerem no gerenciador de ficheiro(s) do Jupyter Notebook. A pasta de notebooks que você criou é um diretório regular em seu computador, e assim você também pode usar sua interface usual de gerenciamento de ficheiro(s) (por exemplo, Finder no Mac, ou File Explorer no Windows) para colocar ficheiro(s) .ipynb e/ou de dados neste diretório. Os Jupyter Notebooks usam a localização do próprio ficheiro do notebook (o ficheiro.ipynb) como o caminho de partida padrão. Para oficinas e cursos, pode fazer sentido criar uma pasta onde você pode armazenar o notebook, qualquer imagem anexada e os dados com os quais você vai trabalhar, todos juntos. Se tudo não estiver na mesma pasta, você terá que incluir o caminho ao referenciá-lo ou usar o código Python dentro do notebook para alterar o diretório de trabalho.
Criando um novo notebook
Dentro da pasta de notebooks, crie um novo Jupyter Notebook para converter as datas para o seu projeto de pesquisa. Clique no botão “new” no canto superior direito da interface do gerenciador de ficheiro(s) do Jupyter Notebook. Se você acabou de instalar o Anaconda como descrito acima, sua única opção será criar um Jupyter Notebook usando o kernel Python 3 (o componente de backend que realmente executa o código escrito no notebook), mas vamos discutir abaixo como adicionar kernels para outras linguagens de programação. Clique em “Python 3”, e o Jupyter Notebook abrirá uma nova guia com a interface para os próprios Jupyter Notebooks. Por padrão, o notebook será chamado de “Sem título”; você pode clicar nesse texto na parte superior da tela para renomeá-lo.

Figura 3. Criando um novo Jupyter Notebook
Trabalhando em Jupyter Notebooks
Um notebook é composto de células: caixas que contêm código ou texto legível por humanos. Cada célula tem um tipo, que pode ser selecionado a partir das opções drop-down do menu (“menu deslizante”). A opção padrão é “Code”; as caixas de textos legíveis por humanos devem usar o tipo “Markdown” e precisarão ser escritas usando as convenções de formatação do Markdown. Para saber mais sobre Markdown, veja a lição do Programming Historian “Introdução ao Markdown”.
Quando você cria um novo Jupyter Notebook, a primeira célula será uma célula de código. No topo da interface do Jupyter Notebook está uma barra de ferramentas com funções que se aplicam à célula selecionada atualmente. A primeira função do menu deslizante é, por padrão, “Code”. Clique nesse menu e selecione “Markdown” (você também pode usar um atalho de teclado, esc + m, para alterar a célula atual para Markdown, e esc + y muda de volta para uma célula de código). Vamos começar este caderno com um título e uma breve explicação do que o caderno está fazendo. No momento, isso é apenas para sua própria memória e referência; você não quer investir muito em prosa e formatação nesta fase do projeto, quando você não sabe se você vai acabar usando este código como parte de seu projeto final, ou se você vai usar uma ferramenta ou método diferente. Mas ainda pode ser útil incluir algumas células de marcação com notas para ajudá-lo a reconstruir seu processo.
Cole o seguinte na primeira célula. Se a primeira linha não aparecer com uma fonte grande (como um cabeçalho), certifique-se de ter selecionado “Markdown” no menu suspenso na parte superior.
# Fanfic date conversion
Converting published & updated dates for Italian fanfic into days of the week.
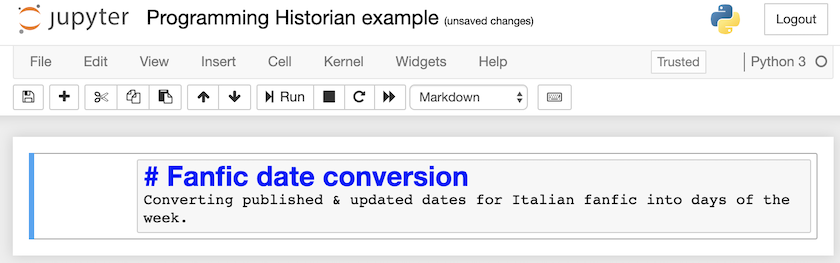
Figura 4. Editando a célula Markdown em um Jupyter Notebook
Quando você está editando uma célula, você pode usar Ctrl + Z (Win) ou Command + Z (Mac) para desfazer as alterações que você fez. Cada célula mantém seu próprio histórico de edição; mesmo que você passe para uma célula diferente e faça edições lá, você pode posteriormente clicar de volta na primeira célula e desfazer suas alterações anteriores lá, sem perder as alterações realizadas para a segunda célula.
Para deixar o modo de edição e “executar” esta célula (para uma célula Markdown, isso não faz nada, apenas move o cursor mais para baixo no notebook), você pode clicar na barra de ferramentas ou pressione Ctrl+Enter (Ctrl+Return no Mac). Se você quiser retomar a edição mais tarde, você pode clicar duas vezes nela ou selecionar a célula (que mostrará uma linha azul vertical à esquerda uma vez selecionada) clicando-a uma vez e, em seguida, pressionando a tecla Enter (Win) ou Return (Mac). Para deixar o modo de edição, você pode clicar na barra de ferramentas ou pressionar Ctrl+Enter (Ctrl+Return no Mac). Se você quiser executar sua célula atual e adicionar uma nova célula (por padrão, uma célula de código) imediatamente abaixo dela, você pode pressionar Alt+Enter (Option+Enter no Mac).
Em seguida, você precisa descobrir como fazer a conversão. A busca por termos relevantes pode levá-lo a essa discussão do StackOverflow, e a primeira resposta envolve o uso do módulo Python datetime. Como primeiro passo, você precisa importar datetime, usando uma célula de código. Você também sabe que o seu ficheiro de entrada é um CSV, então você deve importar o módulo csv também.
Para adicionar uma nova célula, clique no botão + (mais) na barra de ferramentas (ou use o atalho do teclado esc + b). Isso criará uma nova célula de código abaixo da célula que está atualmente selecionada. Crie uma nova célula de código e cole o código a seguir para importar um módulo Python:
import datetime
import csv
Pensando desde já na possibilidade de compartilhar este notebook ou parte dele, pode ser útil dividir as importações de módulos em células individuais, e colocar o código em si em outra célula, para que você possa incluir uma célula Markdown que explique o que cada uma delas está fazendo.
Ambos os pacotes que você está importando para este notebook já estão instalados como parte do Anaconda, mas existem muitos pacotes de nicho relevantes para a pesquisa (por exemplo, o Classic Languages Toolkit, CLTK, para fazer análise de texto em línguas históricas) que não estão incluídos com a Anaconda, e não estão disponíveis através do instalador conda. Se você precisa de um pacote como esse, você tem que instalá-lo usando pip. Instalar pacotes de dentro do Jupyter notebook pode ser um pouco complicado, porque pode haver diferenças entre o kernel Jupyter que o notebook está usando, e outras versões do Python que você pode ter instalado no seu computador. Você pode encontrar uma longa discussão técnica sobre esses problemas neste post de blog.
Se você está trabalhando em um notebook que deseja compartilhar, e ele inclui pacotes menos comuns, você pode incluir uma célula Markdown instruindo os usuários a instalar os pacotes com antecedência usando conda ou pip, ou você pode usar:
import sys
!conda install --yes --prefix {sys.prefix} YourModuleNameHere
para instalar algo do notebook usando conda; a sintaxe ! indica que o código está executando algo da linha de comando, em vez do kernel Jupyter. Ou, se o pacote não estiver disponível na conda (muitos pacotes de nicho relevantes para a pesquisa não estão), você pode usar pip:
import sys
!{sys.executable} -m pip install YourModuleNameHere
Se você não tinha instalado o Python no computador antes de instalar o Anaconda para esta lição, talvez seja necessário adicionar o pacote pip para poder usá-lo para instalar outros pacotes. Você pode adicioná-lo através da GUI (interface gráfica do usuário) do navegador Anaconda, ou executar conda install pip a partir da linha de comando.
Voltando ao nosso exemplo, em seguida adicione uma nova célula de código e cole o seguinte código (certifique-se de que incluiu os espaçamentos):
with open('ph-jupyter-notebook-example.csv') as f:
csv_reader = csv.reader(f, delimiter=',')
for row in csv_reader:
datetime.datetime.strptime(row[1], '%d/%m/%Y').strftime('%A')
print(row)
Clicar no botão ‘play’ na barra de ferramentas quando você tem uma célula de código selecionada executa o código dentro da célula (se você tentar executar este código depois de executar as declarações de importação, verá um erro: “ValueError: time data ‘1/7/18’ does not match format ‘%d/%m/%Y’”. Não se preocupe, vamos depurar isso a seguir).
Depois de executar uma célula de código, um número aparecerá entre colchetes à esquerda da célula. Este número indica a ordem em que a célula foi executada. Se você voltar e executar o celular novamente, o número é atualizado.
Se um número não aparecer imediatamente ao lado da célula, você verá um asterisco entre os colchetes. Isso significa que a célula de código não terminou de funcionar. Isso é comum para códigos computação intensiva (por exemplo, processamento de linguagem natural) ou tarefas de longa duração, como extração de conteúdo na web. Sempre que uma célula de código está sendo executada, o favicon na guia do navegador do notebook muda para uma ampulheta. Se você quiser alterar as guias e fazer outra coisa enquanto o código estiver em execução, você pode saber que a ação anterior foi concluída quando a ampulheta muda de volta para o ícone do notebook.

Figura 5. Executando uma célula de código em um Jupyter Notebook
O Jupyter notebook funciona melhor se você executar as células sequencialmente. Às vezes, você pode obter erros ou saídas incorretas se executar as células fora de ordem ou tentar editar e executar iterativamente diferentes partes do notebook. Se você fez muitas alterações e executou blocos de código de forma não linear e descobrir que você está recebendo uma saída estranha, você pode redefinir o Jupyter Notebook clicando no _Kernel_ no menu e escolhendo _Restart & Clear Output_. Mesmo que você não tenha notado nada de estranho, é uma boa ideia utilizar o Restart & Clear Output em seu código, uma vez que você tenha terminado de escrevê-lo, para ter certeza de que o resultado está correto.
Depois de executar a segunda célula de código, você verá um erro. Para descobrir o que está acontecendo, você pode consultar a documentação para datação que explica cada uma das diferentes opções de formatação. Lá, você verá que a única opção de valores para “dia” assume o uso de dois dígitos (ou seja, dias de um dígito são prefixados com um 0). Olhando para os dados do exemplo, os meses (listados em segundo lugar nesta ordem de data) já são acrescidos de zero, quando tem apenas um dígito, mas não os dias. Você tem duas opções: você pode tentar alterar os dados, ou você pode tentar alterar seu código.
Digamos que você queira tentar uma abordagem diferente, mas quer deixar o que você fez até agora, no caso de você querer revisitar esse código, e talvez usá-lo depois de alterar os dados. Para lembrar do que aconteceu, adicione uma célula Markdown acima da sua segunda célula do código. Clique na primeira célula do código e clique no botão mais na barra de ferramentas. Se você clicar no botão de adição na barra de ferramentas depois de executar a última célula de código, a nova célula aparecerá na parte inferior do notebook. Você pode movê-la para onde quiser clicando no botão de seta para cima. Certifique-se de que está no modo Markdown e cole o seguinte texto:
### Não funciona, precisa de datas precedidas por zero
[documentação do datetime](https://docs.python.org/2/library/datetime.html?highlight=strftime#strftime-and-strptime-behavior).
Modificar o ficheiro de origem?
Lendo ainda mais na discussão do StackOverflow, há outra abordagem que usa uma biblioteca diferente, dateutil, que parece ser mais flexível com os tipos de datas que ela aceita. Volte para a célula usada para importar módulos e edite-a para adicionar a nova biblioteca (em qualquer lugar dessa célula, desde que cada declaração de importação esteja em sua própria linha):
import dateutil
Re-execute essa célula de código; note que o número ao lado da célula muda na segunda vez que você executá-lo.
Agora crie uma nova célula Markdown na parte inferior do notebook e cole:
#### tentando dateutil para analisar datas, conforme https://stackoverflow.com/a/16115575
Abaixo dele, adicione uma nova célula de código com o seguinte código (prestando atenção ao espaçamento, de modo que o código seja indentado assim como você vê abaixo):
with open('ph-jupyter-notebook-example.csv') as f:
csv_reader = csv.reader(f, delimiter=',')
for row in csv_reader:
parseddate = dateutil.parser.parse(row[1])
print(parseddate)
Execute a célula com o código que você acabou de adicionar. Pode levar mais tempo; continue esperando até que o asterisco ao lado da célula de código se transforme em um número. O resultado deve mostrar a lista de datas de publicação, formatadas de forma diferente, com hífen em vez de barras, e com a adição das horas, minutos e segundos (como zeros, porque as datas registradas não incluem esses dados). À primeira vista, parece que funcionou, mas se você compará-lo mais de perto com o ficheiro de origem, você verá que o módulo dateutil não está sendo consistente em como analisa as datas. Datas em que o valor do dia é maior que 12 estão sendo analisadas corretamente (ele sabe que um valor maior que 12 não pode ser um mês), mas quando o valor da data é 12 ou menos, a data está sendo identificada com o mês primeiro. A primeira linha do ficheiro de origem tem a data 1/7/18, que é entendida como “2018-01-07 00:00:00”. Na documentação para dateutil, você descobrirá que você pode especificar dayfirst=true para corrigir isso. Edite a última célula de código e altere a penúltima linha para ler:
parseddate = dateutil.parser.parse(row[1], dayfirst=True)
Quando você executar a linha novamente, você verá que todas as datas foram analisadas corretamente.
Analisar a data é apenas o primeiro passo – você ainda precisa usar o módulo datetime para converter as datas em dias da semana.
Exclua a última linha do bloco de código e substitua-a pelo seguinte (certificando-se de que você tenha o mesmo nível de recuo da última linha anterior, para ambas as linhas):
dayofweek = datetime.date.strftime(parseddate, '%A')
print(dayofweek)
Execute o bloco de códigos novamente. Isso deve lhe dar uma lista de dias da semana.
Agora que você tem código para analisar e re-formatar uma data, você precisa fazê-lo para ambas as datas em cada linha do seu ficheiro de origem. Porque você sabe que tem código funcionante na célula de código atual, se você não se sentir muito confortável com Python, você pode querer copiar a célula de código atual antes de fazer modificações. Selecione a célula que deseja copiar e clique no botão copiar na barra de ferramentas; o botão de colar irá colar a célula abaixo de qualquer célula atualmente selecionada. Fazer uma cópia permite que você faça livremente alterações no código, sabendo que você sempre pode voltar facilmente para uma versão que funciona.
Se você não quiser resolver isso por conta própria, você pode copiar e colar esse código em uma nova célula de código ou substituir a célula de código atual:
#identifica o ficheiro fonte a ser aberto, chama-o f
with open('ph-jupyter-notebook-example.csv') as f:
#cria um ficheiro de saída (referido como "out" no notebook) para ser gravado
with open('ph-jupyter-notebook-example-dayofweek.csv', 'w') as out:
#define "csv_reader" como executando a função csv.reader no ficheiro
csv_reader = csv.reader(f, delimiter=',')
#define "csv_writer" como executando a função csv.writer para "out" (o ficheiro de saída)
csv_writer = csv.writer(out)
#para cada linha que está sendo lida pelo csv_reader...
for row in csv_reader:
#define "csv_reader" como executando a função csv.reader no ficheiro
csv_reader = csv.reader(f, delimiter=',')
#para cada linha que está sendo lida pelo csv_reader...
for row in csv_reader:
#cria uma lista chamada "values" com o conteúdo da linha
values = list(row)
#define "rating" como a primeira coisa na lista
#contagem em Python começa com 0, não 1
rating = values[0]
#define "parseddatepub" como a segunda coisa (1, porque começamos com 0) na lista,
#convertido em um formato de data padrão usando dateutil.parser
#e quando essas datas são analisadas, o analisador deve saber
#que o primeiro valor na sequência é o dia
parseddatepub = dateutil.parser.parse(values[1], dayfirst=True)
#mesmo que acima para a data atualizada, a terceira coisa (2) na lista
parseddateupdate = dateutil.parser.parse(values[2], dayfirst=True)
#define "dayofweekpub" como parseddatepub (definido acima), convertido para o dia da semana
#%A é usado para mudar para o dia da semana
#Pode ver outros formatos aqui: https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior
dayofweekpub = datetime.date.strftime(parseddatepub, '%A')
#mesma coisa para data de atualização
dayofweekupdate = datetime.date.strftime(parseddateupdate, '%A')
#cria uma lista da classificação e as novas datas formatadas
updatedvalues = [rating, dayofweekpub, dayofweekupdate]
#escreve todos os valores nesta célula de código
csv_writer.writerow(updatedvalues)
print(updatedvalues)
Depois de executar este código, você terá um novo ficheiro ph-jupyter-notebook-exemplo-dayofweek.csv, com seus dados no formato que você precisa para a análise.
Agora que você tem um código que funciona para converter as datas do formulário que você tem para o formulário que você precisa, você pode limpar as falsas partidas e notas para si mesmo. Você vai querer manter o primeiro código com as declarações de importação, e a primeira célula Markdown com o título e a descrição, mas você deve excluir outras células de código e Markdown que não são o seu código final. Para excluir uma célula, clique nela e clique no botão tesoura na barra de ferramentas. Se você excluir uma célula por engano, você pode clicar em Editar no menu e escolher “Desfazer excluir células”.
Salvando, exportando e publicando Jupyter Notebooks
O Jupyter salva automaticamente seu trabalho de forma periódica, criando “pontos de verificação”. Se algo der errado com seu notebook, você pode reverter para um ponto de verificação anterior indo em “File”, em seguida, “Revert to Checkpoint”, e escolhendo um horário. Dito isto, ainda é importante salvar seu notebook (usando o botão de salvar), porque se você fechar e desligar o kernel do notebook (incluindo reiniciar o kernel), os pontos de verificação serão perdidos.
Você também pode baixar o notebook (File> Download as) em vários formatos de ficheiro diferentes. Baixar o formato Notebook (.ipynb) é útil se você quiser compartilhar seu código em seu formato completo de notebook. Você também pode baixá-lo como código em qualquer linguagem em que seu notebook estiver (por exemplo, .r se em R ou .py se Python ou .js se JavaScript), como um ficheiro de .html, como um ficheiro de marcação (.md) ou como um PDF via LaTeX. Se você baixá-lo como código, as células Markdown se tornam comentários (se você quiser converter um ficheiro, ficheiro.ipynb para outro formato depois de baixá-lo, você pode usar a ferramenta nbconvert).
Se você está trabalhando em um projeto de pesquisa, você pode usar um Jupyter notebook, ou uma série de notebooks, ao longo do caminho para acompanhar seu fluxo de trabalho. Alguns estudiosos postam esses cadernos no GitHub, juntamente com slides ou PDFs de pôsteres e dados de origem (ou metadados, se os direitos autorais permitirem), para acompanhar apresentações e palestras. O GitHub renderiza versões não interativas de ficheiro(s) de notebook, para que possam ser visualizados dentro de um repositório. Alternativamente, você pode colar a URL de um repositório do GitHub que tem notebooks Jupyter em nbviewer, o que às vezes pode ser uma visualização mais rápida e confiável. Você pode querer incluir uma célula Markdown com uma citação recomendada para o seu Jupyter notebook, e uma referência para o repositório do GitHub onde ela está armazenada, especialmente se o seu notebook inclui código que outros possam reutilizar para análises semelhantes.
O código que você acabou de desenvolver como parte desta lição pertence a algum lugar no meio de um projeto real. Se você estiver usando notebooks para documentar seu fluxo de trabalho, você pode optar por adicionar a nova célula de código a um notebook existente, em vez de baixá-lo como um notebook separado e autônomo. Os Jupyter notebooks podem ser particularmente úteis para documentar fluxos de trabalho de projetos quando você está trabalhando com colaboradores que só podem estar envolvidos por um curto período de tempo (como estagiários de graduação no período de férias escolares). Com colaboradores de curto prazo, é importante ajudá-los a entender e começar a usar os fluxos de trabalho do projeto sem muito tempo de iniciação, e os Jupyter notebooks podem definir esses fluxos de trabalho passo a passo, explicar onde e como os ficheiro(s) são armazenados e fornecer dicas para tutoriais externos e materiais de treinamento para ajudar os colaboradores que estão menos familiarizados com os fundamentos técnicos do projeto a serem iniciados. Por exemplo, dois projetos que usaram Jupyter notebooks para publicar fluxos de trabalho são o Projeto Realismo Socialista de Sarah McEleney e a “mineração de texto da literatura infantil inglesa 1789-1914 para a representação de insetos e outros rastejantes assustadores”.
À medida que seu projeto progride, se você estiver publicando através de canais de acesso aberto e se seus conjuntos de dados podem ser compartilhados livremente, os Jupyter notebooks podem fornecer um formato ideal para tornar o código que sustenta seu argumento acadêmico visível, testável e reutilizável. Embora os periódicos e publicações possam não aceitar os Jupyter notebooks como um formato de submissão, você pode desenvolver uma “versão” do seu artigo que inclui o texto completo (como células Markdown),com células de código integradas ao fluxo da narrativa acadêmica como uma ilustração imediatamente acessada da análise que você está descrevendo. Você também pode incluir as células de código que compõem os fluxos de trabalho de preparação de dados como um apêndice, seja no mesmo notebook, ou em um separado. Integrar o código com o texto de um artigo acadêmico torna muito mais provável que os leitores realmente se envolvam com o código, já que eles podem simplesmente executá-lo dentro do mesmo caderno onde estão lendo o argumento. Alguns estudiosos, particularmente na Europa, também postam seus cadernos no Zenodo, um ficheiro para dados de pesquisa, independentemente do país de origem, financiador ou disciplina. O Zenodo suporta configurações de dados de até 50 GB (vs. o limite de tamanho de ficheiro de 100 MB no Github), e fornece DOIs para o material carregado, incluindo notebooks. Alguns estudiosos combinam arquivamento no Zenodo para sustentabilidade com a publicação no GitHub para a possibilidade de encontrar, incluindo o Zenodo DOI como parte do ficheiro readme.md no repositório do GitHub que inclui os notebooks. Como exemplo, o caderno de workshop “Análise de Dados Aplicados” por Giovanni Colavizza e Matteo Romanello para o DHOxSS 2019 é publicado no GitHub, mas inclui um Zenodo DOI.
Embora a argumentação e o código totalmente integrados ainda sejam difíceis de encontrar devido à falta de um local para publicar esse tipo de trabalho, os estudiosos começaram a usar os Jupyter notebooks como um passo incremental mais interativo para publicações computacionais dinâmicas. José Calvo tem um exemplo de um caderno acompanhando um artigo sobre estilizometria (em espanhol), e Jed Dobson publicou um conjunto de cadernos para acompanhar seu livro Critical Digital Humanities: The Search for a Methodology, que aborda diretamente os Jupyter Notebooks como objetos acadêmicos (p.39-41).
Usando Jupyter Notebook para ensinar
O Jupyter Notebook é uma ótima ferramenta para ensinar programação, ou para ensinar conceitos como modelagem de tópicos ou vetores de palavras que envolvem programação. A capacidade de fornecer instruções e explicações como Markdown permite que os educadores forneçam notas detalhadas sobre o código através de marcação alternada e células de código, de modo que o texto de Markdown explique o código na célula logo abaixo. Isso é útil para oficinas práticas, pois as instruções e o código podem ser escritos com antecedência. Isso permite que os participantes abram o notebook, baixem um conjunto de dados e executem o código conforme está. Se você espera ministrar uma oficina onde os alunos terão diferentes níveis de familiaridade com a programação, você pode configurar o notebook para ter tarefas suplementares para os alunos que se sentem confortáveis em modificar o código. Ao mesmo tempo, mesmo os alunos que hesitam em tocar no código ainda poderão alcançar o resultado principal da oficina apenas executando células de código pré-escritas.
Como outra abordagem, você também pode usar Jupyter notebooks para escrever código na medida em que o desenvolve. Em tal oficina, os alunos podem começar com um caderno em branco, e escrever o código junto com você. As células ajudam a segmentar o código como você o escreve, em vez de usar um editor de texto ou IDE (Ambiente de Desenvolvimento Integrado) que não quebra o código de forma tão clara e pode causar confusão, especialmente quando ensina iniciantes.
Você pode usar Jupyter notebooks para tarefas em sala de aula dando instruções em Markdown e fazendo com que os alunos escrevam código em uma célula em branco com base nas instruções. Dessa forma, você pode criar uma tarefa de programação interativa que ensina aos alunos não apenas a sintaxe e o vocabulário de uma linguagem de programação, mas também pode explicar as melhores práticas de programação em geral.
Se você já está usando Jupyter notebooks para documentar o fluxo de trabalho do seu projeto, você pode ser capaz de reformular esses cadernos de pesquisa para uso em sala de aula, como uma maneira de trazer sua pesquisa para a sala de aula. Este exemplo de caderno pedagógico é um híbrido de algumas das abordagens pedagógicas descritas acima. A primeira seção do caderno destina-se a estudantes que têm pouca ou nenhuma experiência anterior executando o código; o principal resultado do aprendizado é comparar o tempo necessário para converter manualmente formatos de dados, em comparação com fazê-lo com código. Você poderia usar este caderno para uma sessão de laboratório prática em uma introdução à humanidades digitais ou história digital, onde todos os alunos instalam Anaconda e aprendem o básico do Jupyter Notebook. Se a turma tem uma mistura de alunos sem formação técnica e alunos com exposição prévia ao Python, você pode orientar os alunos com experiência de programação a trabalhar em conjunto em grupos de dois ou três para propor soluções para os prompts na segunda parte do notebook. Tenha em mente que se você usar uma tarefa de classe como esta como uma forma de fazer com que os alunos de ciência da computação escrevem código que ajude seu projeto de pesquisa, eles devem ser creditados como colaboradores e reconhecidos em publicações subsequentes vindas do projeto.4
Existem muitos cursos e workshops de ‘Introdução ao Python’ nas Humanidades Digitais que utilizam Jupyter Notebook (incluindo Introdução ao Python e Desenvolvimento web com Python para as Humanidades by Thibault Clérice, traduzido do material por Matthew Munson). O Jupyter Notebook também é comumente usado em oficinas de análise de texto, como a oficina de vetores de palavras na DH 2018, ministrada por Eun Seo Jo, Javier de la Rosa e Scott Bailey.
Ensinar com Jupyter Notebook nem sempre tem que envolver o processo demorado de baixar e instalar a Anaconda, especialmente se você está imaginando ter apenas uma ou duas lições que envolvem notebooks. Se suas atividades em sala de aula com Jupyter notebooks envolvem o uso de dados de exemplo que você já preparou, e se você já escreveu pelo menos parte do código, você pode querer explorar a execução de Jupyter Notebooks usando recursos gratuitos de computação em nuvem, desde que seus alunos tenham a garantia de ter conectividade confiável com a internet em sala de aula. Rodar notebooks na nuvem também fornece um ambiente consistente para todos os alunos, poupando você de ter que negociar diferenças entre Windows e Mac, ou fornecer uma alternativa para estudantes cujos laptops não têm espaço ou memória para executar Anaconda efetivamente.
Como as opções estão evoluindo rapidamente, é melhor usar seu mecanismo de busca favorito para encontrar uma lista mais atualizada com opções de computação em nuvem para Jupyter Notebook. Um projeto que tem visto uma absorção particular entre usuários acadêmicos de notebooks é o MyBinder. Nele você levará um repositório do GitHub que contém dados relacionados a ficheiro(s) jupyter.ipynb (imagens incorporadas, conjuntos de dados que você deseja usar os notebooks, etc.), as informações sobre pacotes e dependências necessários (em um requisito.txt ou ficheiro-environment.yml) e torná-lo incializável usando um servidor de nuvem. Uma vez que você tenha o pacote MyBinder até o seu repo GitHub, você pode adicionar um “crachá” binder ao ficheiro readme para o repo. Quem estiver vendo o relatório pode lançar o notebook diretamente do seu navegador, sem ter que baixar ou instalar nada.
Como os dados que o notebook precisa acessar devem ser incluídos no repo, isso não funcionará para todas as situações (por exemplo, se os dados não podem ser redistribuídos legalmente no GitHub, excede o tamanho máximo de ficheiro(s) do GitHub e não podem ser baixados de outros lugares como parte da configuração do ambiente Binder, ou se você quiser que as pessoas usem o notebook com seus próprios dados), mas é uma ótima opção para oficinas ou aulas onde todos estão trabalhando com os mesmos dados compartilháveis.
Se você quiser começar a explorar opções de nuvem, Shawn Graham criou alguns modelos para configurar notebooks Python e R Jupyter para uso no Binder.
Finalmente, se você precisa manter seus notebooks fora da nuvem (por exemplo, devido a dados sensíveis ou de outra forma restritos), mas quiser fornecer um ambiente consistente para todos os seus alunos, você pode explorar o JupyterHub, que tem sido adotado como infraestrutura técnica central para um número crescente de programas de ciência de dados.
Convertendo códigos Python
Mesmo que você goste da ideia de usar Jupyter Notebooks, qualquer conversão de formato requer trabalho adicional. Se você já tem seu código escrito como scripts Python, a conversão para Os Jupyter Notebooks é bastante simples. Você pode copiar e colar o código do seu ficheiro.py em uma única célula de código de um novo notebook e, em seguida, dividir a célula de código em segmentos e adicionar células de Markdown adicionais conforme necessário.
Alternativamente, pode ser mais fácil segmentar à medida que você transfere o código, copiando um segmento de cada vez em uma nova célula de código. Qualquer método funciona e é uma questão de preferência pessoal.
Há também ferramentas como o pacote ‘p2j’ que convertem automaticamente o código Python existente em notebooks Jupyter, seguindo um conjunto documentado de convenções (por exemplo, transformando comentários em células Markdown).
Cadernos Jupyter para outras linguagens de programação
Os Jupyter Notebooks permitem que você use muitas linguagens de programação diferentes, incluindo R, Julia, JavaScript, PHP ou Ruby. Uma lista atual de linguagens disponíveis pode ser encontrada na página do Jupyter Kernels GitHub.
Enquanto o Python é suportado por padrão quando você instala o Jupyter Notebook através da Anaconda, as outras linguagens de programação precisam ter seus núcleos de linguagens instalados antes que eles possam ser executados no Jupyter Notebook. As instruções de instalação são diferentes para cada núcleo de linguagem, por isso é melhor apenas encontrar e seguir as instruções para a sua linguagem preferida. Pelo menos para R, isso é relativamente simples. A página Jupyter Kernels GitHub tem links para instruções para todos os kernels de linguagens disponíveis.
Uma vez que você tenha o kernel para a linguagem desejada instalado, você pode executar cadernos escritos nessa linguagem de programação, ou você pode criar seus próprios cadernos que executam essa linguagem. Cada linguagem com um kernel instalado em seu computador estará disponível como uma opção quando você criar um novo notebook como descrito acima.
Como exemplo de um notebook R, veja esta adaptação jupyter do código R de Andrew Piper de “Enumerações”.
Dimensionando a computação com Jupyter Notebooks
Especialmente se você é novo em programar em Python, apenas conseguir qualquer coisa para trabalhar pode parecer uma vitória. No entanto, se você começar a trabalhar com conjuntos de dados maiores, poderá descobrir que algumas das “soluções” iniciais encontradas (como usar readlines() para ler um ficheiro de texto linha por linha) se tornam computacionalmente ineficientes, a ponto de causar problemas. Uma maneira de começar a entender as ineficiências em seu código é adicionar %%timeit ao topo de uma célula. O notebook escolherá um número de iterações para executar o código, dependendo da complexidade da tarefa, imprimirá o número de iterações e o tempo médio. Fazer várias iterações, em vez de apenas uma, pode ser útil para contabilizar pequenos atrasos no âmbito do sistema (por exemplo, se seu laptop estiver momentaneamente atolado com outros processos). Você pode colocar %timeit na frente da linha. Tenha cuidado com a ordenação significativa: ordenar uma aplicação pequena de muito mais tempo para a primeira iteração do que para a segunda, depois que a lista já estiver em ordem. Em casos como a classificação de listas em que não faz sentido medir várias iterações ou para tarefas de longa duração onde pequenos atrasos no sistema não terão um impacto significativo, você pode usar %%time no topo de uma célula ou %time na frente de uma linha, que mede o tempo que uma única execução leva. Esses comandos fazem parte de uma família de “comandos mágicos” integrados disponíveis em Jupyter Notebooks. Veja a documentação do Jupyter para saber de mais detalhes.
Ter alguma ideia de aumento do tempo previsto para ser implementado é um requisito necessário para aumentar o tempo dos clusters em uso, como no caso dos clusters de programação de alto desempenho (HPC) financiados de forma centralizadamente, disponíveis em muitas instituições. A maioria esmagadora dos pesquisadores que usam esses recursos está nas ciências duras, mas geralmente qualquer membro do corpo docente pode solicitar acesso. É possível que você também possa ter acesso a recursos de HPC regionais ou nacionais. Esses recursos de computação podem acelerar significativamente grandes trabalhos de computação, especialmente tarefas como modelagem 3D que podem tirar proveito de nós computacionais com poderosas unidades de processamento gráfico (GPUs). Aprender a usar clusters HPC é um tópico suficientemente grande para sua própria lição, mas os notebooks Jupyter podem permitir que você pegue um atalho. Alguns grupos de computação de pesquisa oferecem maneiras mais fáceis para os pesquisadores executarem Jupyter Notebooks usando recursos de cluster HPC, e você pode encontrar vários guias e exemplos de uso geral para fazê-lo. Se você conseguir acesso aos recursos do HPC, vale a pena contatar a equipe de TI que com computação para uma área de e pesquisar sobre como você pode executar o Jupyter Notebook caso você não lidou com sua redação a respeito no site da sua instituição. O TI que trabalha majoritariamente com pesquisa pode se comunicar de forma brusca do que você é de forma mais pessoal, mas não permite que a maioria dos humanos querem, porque usam a diversidade da sua base de usuários é importante para suas medidas de atuação na universidade.
Conclusão
Desde a experimentação do código até a documentação de fluxos de trabalho, da pedagogia à publicação acadêmica, o Jupyter Notebook é uma ferramenta flexível e multiuso que pode apoiar a pesquisa digital em diversos contextos. Mesmo que você não tenha certeza de como exatamente você vai usá-los, é bastante fácil instalar o software Jupyter Notebook e baixar e explorar notebooks existentes, ou experimentar alguns dos seus próprios. Os Jupyter Notebooks têm uma grande promessa de fazer a ponte das facetas críticas e computacionais da pesquisa de humanidades digitais. Para concluir com uma citação de Jed Dobson’s Critical Digital Humanities: The Search for a Methodology.
Notebooks são teoria - não apenas código como teoria, mas teoria como reflexo reflexivo com o trabalho teórico e implicações do próprio código. As normas disciplinares, incluindo enquadramento contextual, teoria e autocrítica, precisam acompanhar, complementar e informar qualquer crítica computacional. Revelar o máximo possível do código, dos dados e dos métodos é essencial para permitir a conversa disciplinar em curso. Compilando-os juntos em um único objeto, que pode ser exportado, compartilhado, examinado e executado por outros, produz um tipo dinâmico de teorização que é modular, mas firmemente ligado ao seu objeto.5
Links
- Uma lista crescente de notebooks Jupyter para DH, em múltiplas linguagens humanas e de programação. Obrigado a todos que enviaram sugestões no Twitter; referências adicionais são bem-vindas.
- Uma descrição técnica detalhada da instalação de pacotes Python do Jupyter.
Agradecimentos
-
Obrigado a Stéfan Sinclair pelas referências a discussões anteriores sobre o uso de notebooks em humanidades digitais.
-
Obrigado a Rachel Midura por sugerir o uso de Jupyter Notebooks para colaboração.
-
Knuth, Donald. 1992. Literate Programming Stanford, Califórnia: Centro para o Estudo da Linguagem e da Informação. ↩
-
Millman, KJ e Fernando Perez. 2014. “Developing open source scientific practice”. In Implementing Reproducible Research, Ed. Victoria Stodden, Friedrich Leisch, and Roger D. Peng. https://osf.io/h9gsd/ ↩
-
Sinclair, Stéfan & Geoffrey Rockwell. 2013. “Voyant Notebooks: Literate Programming and Programming Literacy”. Journal of Digital Humanities, Vol. 2, No. 3 Summer 2013. http://journalofdigitalhumanities.org/2-3/voyant-notebooks-literate-programming-and-programming-literacy/ ↩
-
Haley Di Pressi, Stephanie Gorman, Miriam Posner, Raphael Sasayama, and Tori Schmitt, with contributions from Roderic Crooks, Megan Driscoll, Amy Earhart, Spencer Keralis, Tiffany Naiman, and Todd Presner. “A Student Collaborator’s Bill of Rights”. https://humtech.ucla.edu/news/a-student-collaborators-bill-of-rights/ ↩
-
Dobson, James. 2019. Critical Digital Humanities: The Search for a Methodology. Urbana-Champaign: University of Illinois Press. p. 40. ↩