
Conteúdos
Visão Geral
E se só quisesse ver as imagens num livro? Este é um pensamento que já ocorreu tanto a jovens crianças como a pesquisadores adultos. Se soubesse que o livro está disponível através duma biblioteca digital, seria útil fazer o download somente das páginas com imagens e ignorar o resto.
Aqui estão as miniaturas de página dum volume do HathiTrust com o identificador exclusivo osu.32435078698222. Após o processo descrito nesta lição, apenas as páginas com imagens (31 no total) foram baixadas como JPEGs para uma pasta.

Visualização dum volume para o qual só as páginas com imagens foram baixadas.
Para ver quantas páginas não ilustradas foram filtradas, compare com o conjunto total de miniaturas para todas as 148 páginas nesta edição revisada de 1845 do livro infantil bestseller de Samuel Griswold Goodrich, The Tales of Peter Parley About America (1827).
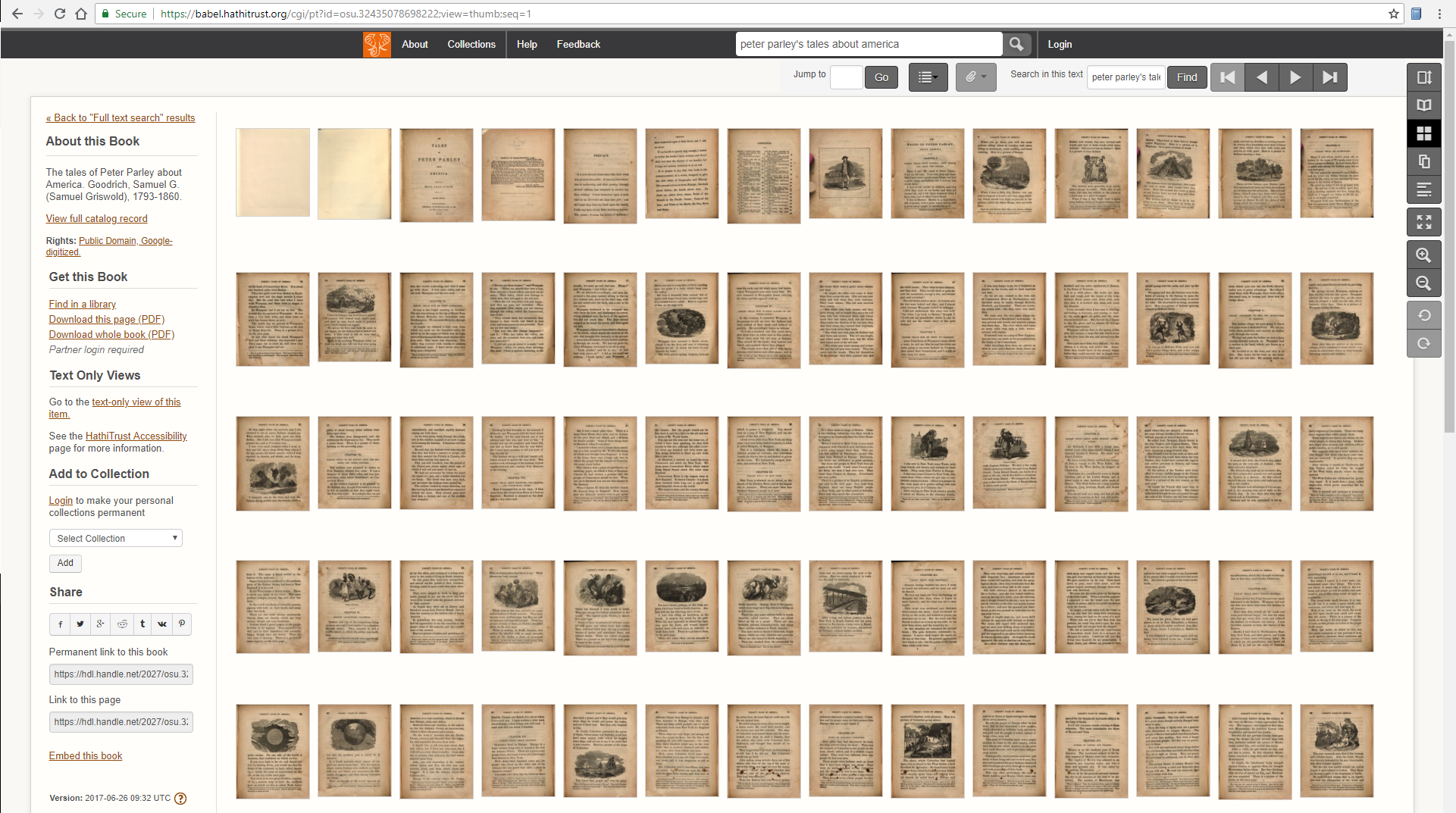
Visualização das miniaturas do HathiTrust para todas as páginas.
Esta lição mostra como completar estas etapas de filtragem e de download para volumes de texto em domínio público detidos pelo HathiTrust (HT) e pelo Internet Archive (IA), duas das maiores bibliotecas digitais no mundo. Será do interesse de qualquer um que deseje criar coleções de imagens com o fim de aprender sobre a História da Ilustração e o layout (mise en page) dos livros. As abordagens visuais à bibliografia digital estão a tornar-se populares, seguindo os esforços pioneiros do EBBA e do Aida. Projetos recentemente concluídos ou financiados exploram maneiras de identificar notas de rodapé e de rastrear notas de margem de página, para dar só dois exemplos.
A minha própria pesquisa tenta responder a questões empíricas sobre alterações na frequência e modo de ilustração em textos médicos e educacionais do século dezanove. Isto envolve agregar múltiplas imagens por livro e tentar estimar que processo de impressão foi usado para fazer tais imagens. Um caso de uso mais direcionado para a extração de páginas ilustradas pode ser a catalogação de ilustrações ao longo de diferentes edições do mesmo livro. Trabalhos futuros poderão investigar com sucesso as características visuais e o significado das imagens extraídas: a sua cor, o seu tamanho, o seu tema, o seu género, o número de figuras e assim por diante.
Como obter informação localizada sobre regiões visuais de interesse está para além do âmbito desta lição, visto que o processo envolve uma quantidade significativa de aprendizagem de máquina. No entanto, a classificação sim/não de páginas com (ou sem) imagens é um primeiro passo prático para reduzir o enorme volume de todas as páginas para cada livro numa coleção visada, tornando viável a localização de ilustrações. Para dar um ponto de referência, os textos médicos do século dezanove contêm (em média) ilustrações em 1-3% das suas páginas. Se estiver a tentar estudar a ilustração no interior dum corpus duma biblioteca digital sobre o qual não tem qualquer informação preexistente, é, consequentemente, razoável assumir que 90+% das páginas nesse corpus NÃO estarão ilustradas.
O HT e o IA permitem que a questão com imagens/sem imagens seja respondida indiretamente através da análise dos dados gerados pelo software optical character recognition (OCR) ou reconhecimento ótico de caracteres, em português (o OCR é aplicado após um volume físico ser digitalizado com o objetivo de gerar uma transcrição do texto muitas vezes desordenada). Aproveitar o resultado do output do OCR para encontrar páginas ilustradas foi proposto primeiramente por Kalev Leetaru numa colaboração de 2014 com o Internet Archive e o Flickr. Esta lição transfere a abordagem de Leetaru para o HathiTrust e tira proveito de bibliotecas de processamento de XML mais rápidas no Python, bem como da gama recentemente ampliada de formatos de ficheiro de imagem do IA.
Uma vez que o HT e o IA expõem a sua informação derivada do OCR de maneiras ligeiramente diferentes, eu irei adiar a apresentação dos detalhes das “características visuais” de cada biblioteca para as suas secções respetivas.
Objetivos
No final da lição, o leitor será capaz de:
- Configurar a versão “mínima” da distribuição Anaconda do Python (Miniconda) e criar um ambiente;
- Salvar e iterar sobre uma lista de IDs de volumes do HT ou do IA gerados por uma pesquisa;
- Acessar aos application programming interfaces (APIs) ou interfaces de programação de aplicações, em português, de dados do HT e do IA através das bibliotecas do Python;
- Encontrar características visuais ao nível da página;
- Fazer o download dos JPEGs de páginas programaticamente.
O grande objetivo é fortalecer as competências de coleta e exploração de dados ao criar um corpus de ilustração histórica. Combinar dados de imagem com os metadados dum volume permite a formulação de questões de pesquisa promissoras sobre a mudança visual ao longo do tempo.
Requisitos
Os requisitos de software desta lição são mínimos: o acesso a uma máquina executando um sistema operacional padrão e um navegador de internet. O Miniconda está disponível em duas versões de 32 e de 64 bits para Windows, macOS e Linux. O Python 3 é a versão estável atual da linguagem e será suportado indefinidamente1.
Este tutorial assume um conhecimento básico da linha de comando e da linguagem de programação Python. O leitor deve compreender as convenções para comentários e comandos num tutorial baseado num shell. Eu recomendo a Introduction to the Bash Command Line, de Ian Milligan e James Baker, para aprender ou para rever as suas competências com a linha de comando.
Configuração
Dependências
Os leitores mais experientes podem querer simplesmente instalar as dependências e executar os notebooks nos seus ambientes de escolha. Mais informações sobre a minha própria configuração do Miniconda (e algumas diferenças entre o Windows e o *nix) são providenciadas.
Nota de tradução: Para instalar as dependências, altere o seu diretório de trabalho para a pasta onde se encontra instalado o Python executando o comando
cde, depois, digite o comandopip installoupip3 installacompanhado pelas seguintes linhas:
hathitrust-apiouhathitrust_api(Documentos de Instalação);internetarchive(Documentos de Instalação);jupyter(Documentos de Instalação);requests(Documentos de Instalação) [o criador recomenda a instalação dopipenv; para a instalação dopip, veja PyPI].
Ficheiros da Lição
Faça o download desta pasta comprimida que contém dois Jupyter notebooks, um para cada uma das bibliotecas digitais. A pasta também contém um ficheiro de metadados JSON de amostra descrevendo uma coleção do HathiTrust. Descomprima e confirme que os seguintes ficheiros estão presentes: 554050894-1535834127.json, hathitrust.ipynb e internetarchive.ipynb.
Destino do Download
Aqui está o diretório predefinido que será criado assim que todas as células em ambos os notebooks tiverem sido executadas (como providenciado). Depois de obter uma lista de quais páginas num volume contêm imagens, as funções de download do HT e do IA solicitam essas páginas como JPEGs (nomeadas pelo número de página) e arquivam-nas em subdiretórios (nomeados pelo ID do item). É claro que o leitor pode usar diferentes listas de volumes ou mudar o destino out_dir para algo que não items.
items/
├── hathitrust
│ ├── hvd.32044021161005
│ │ ├── 103.jpg
│ │ └── ...
│ └── osu.32435078698222
│ ├── 100.jpg
│ ├── ...
└── internetarchive
└── talespeterparle00goodgoog
├── 103.jpg
└── ...
5 diretórios, 113 ficheiros
As funções de download são lentas; se executar os notebooks novamente, com o diretório items similar ao que se apresenta em cima, qualquer item que já tenha a sua própria subpasta será ignorado.
Anaconda (Opcional)
A Anaconda é a principal distribuição científica do Python. O seu gerenciador de pacotes conda permite-lhe instalar bibliotecas como a numpy e a tensorflow com facilidade. A versão “Miniconda” não é acompanhada por quaisquer pacotes supérfluos pré-instalados, o que incentiva o leitor a manter o seu ambiente de base limpo e a instalar apenas o que necessita para um projeto dentro dum ambiente nomeado.
Faça o download e instale o Miniconda. Escolha a versão estável mais recente do Python 3. Se tudo correr bem, o leitor conseguirá executar which conda (no Linux/macOS) ou where conda (no Windows) no seu shell e ver a localização do programa executável no output.
A Anaconda tem uma cheat sheet ou folha de dicas, em português, útil para comandos de uso frequente.
Criar um Ambiente
Os ambientes, entre outras coisas, ajudam a controlar a complexidade associada ao uso de múltiplos gerenciadores de pacotes em conjunto. Nem todas as bibliotecas do Python podem ser instaladas através do conda. Em alguns casos, nós recorreremos ao gestor de pacote padrão do Python, o pip (ou alterações planejadas, como o pipenv). No entanto, quando o fizermos, nós usaremos uma versão do pip instalada através do conda. Isto mantém todos os pacotes que nós precisamos para o projeto no mesmo espaço virtual.
# O seu ambiente atual é precedido por um asterisco
# (será a "base" num novo shell)
conda env list
# Pacotes instalados no ambiente atual
conda list
Agora nós criamos um ambiente nomeado, configuramo-lo para usar Python 3, e ativamo-lo.
# Note a sinalização "--name", que toma um argumento de string (e.g. "extract-pages")
# e a sintaxe para especificar a versão do Python
conda create --name extract-pages python=3
# Indique o novo ambiente (no Linux/macOS)
source activate extract-pages
# O comando do Windows para ativar o ambiente é ligeiramente diferente
conda activate extract-pages
Para sair dum ambiente, execute source deactivate no Linux/macOS ou deactivate no Windows. Mas certifique-se que permanece no ambiente extract-pages durante o decorrer da lição!
Instalar os Pacotes do Conda
Nós podemos usar o conda para instalar os nossos primeiros pacotes. Todos os outros pacotes necessários (gzip, JSON, os, sys e time) fazem parte da biblioteca padrão do Python. Note como nós precisamos de especificar um canal em alguns casos. O leitor pode pesquisar por pacotes no Anaconda Cloud.
# Para garantir que nós temos uma versão local do pip (veja a discussão em baixo)
conda install pip
conda install jupyter
conda install --channel anaconda requests
O Jupyter tem muitas dependências (outros pacotes dos quais depende), por isso esta etapa pode exigir alguns minutos. Recorde-se que quando o conda lhe pergunta se deseja continuar com a instalação por via da questão Proceed ([y]/n)?, o leitor deve digitar um y ou um yes e, depois, pressionar Enter para aceitar a instalação do pacote.
conda está a trabalhar para certificar-se que todos os pacotes e dependências necessários serão instalados numa maneira compatível.
Instalar Pacotes do Pip
Se estiver a usar um ambiente conda, é melhor usar a versão local do pip. Confirme que os seguintes comandos dão como resultado do output um programa cujo caminho absoluto contém algo como /Miniconda/envs/extract-pages/Scripts/pip.
which pip
# O equivalente do Windows ao "which"
where pip
Se vir duas versões do pip no output em cima, certifique-se de digitar o caminho absoluto para a versão do ambiente local ao instalar as bibliotecas wrapper da API.
pip install hathitrust-api
pip install internetarchive
# Exemplo do Windows usando o caminho absoluto para o executável do pip local
C:\Users\stephen-krewson\Miniconda\envs\extract-pages\Scripts\pip.exe install hathitrust-api internetarchive
# Substitua "stephen-krewson" pelo seu nome de utilizador
Jupyter Notebooks
O Text Mining in Python Through the HTRC Feature Reader, de Peter Organisciak e Boris Capitanu, explica os benefícios dos notebooks para o desenvolvimento e a exploração de dados. Também contém informação útil sobre como executar eficazmente as células. Visto que nós instalámos a versão minimalista da Anaconda, nós precisamos de iniciar o Jupyter a partir da linha de comandos. No seu shell (a partir do interior da pasta contendo os ficheiros da lição) execute jupyter notebook.
Isto executará o servidor do notebook no seu shell e iniciará o seu navegador de internet predefinido com a página inicial do Jupyter2. A página inicial mostra todos os ficheiros no diretório de trabalho atual.
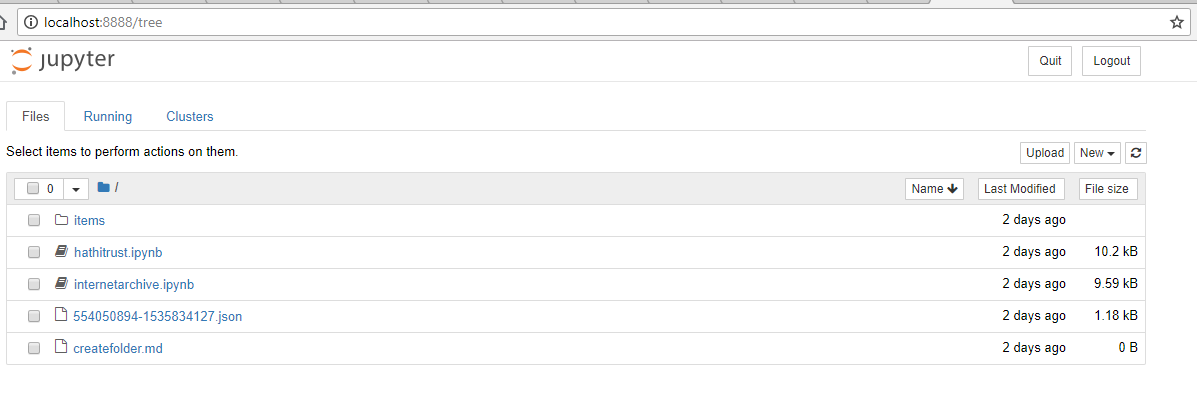
A página inicial do Jupyter mostrando os ficheiros da lição.
cd para ir até ao diretório descomprimido lesson-files.
Clique nos notebooks hathitrust.ipynb e internetarchive.ipynb para abri-los em novas abas do navegador de internet. A partir daqui, nós não precisamos de executar qualquer comando no shell. Os notebooks permitem-nos executar o código Python e ter acesso total ao sistema de pastas do computador. Quando o leitor tiver terminado, pode parar o servidor do notebook carregando em “Quit” na página inicial do Jupyter ou executando ctrl+c no shell.
HathiTrust
Acesso à API
O leitor precisa efetuar um registro no HathiTrust antes de usar o API de dados. Dirija-se ao portal de registro e preencha o seu nome, a sua organização e o seu e-mail para requerer chaves de acesso. O leitor deverá receber uma resposta no e-mail dentro de cerca dum minuto (nota de tradução: verifique também a caixa de spam). Clique no link, que o trará a uma página temporária com ambas as chaves exibidas.
No notebook hathitrust.ipynb, examine a primeira célula (mostrada em baixo). Preencha as suas chaves da API como indicado. Depois, execute a célula clicando em “Run” na barra de navegação do notebook.
# Importe o wrapper da API de dados do HT
from hathitrust_api import DataAPI
# Substitua as strings com as suas credenciais do HT (deixando as aspas)
ht_access_key = "YOUR_ACCESS_KEY_HERE"
ht_secret_key = "YOUR_SECRET_KEY_HERE"
# Instancie o objeto de conexão da API de dados
data_api = DataAPI(ht_access_key, ht_secret_key)
Criar uma Lista de Volumes
O HT permite a qualquer um fazer uma coleção de itens—o leitor nem sequer tem que estar na sua conta! No entanto, o leitor deveria registrar uma conta se quiser salvar a sua lista de volumes. Siga as instruções para fazer algumas pesquisas no texto completo e para, depois, adicionar resultados escolhidos a uma coleção. Atualmente, o HathiTrust não tem uma API de pesquisa pública para adquirir volumes programaticamente; o leitor precisa de pesquisar através da sua interface da internet.
Ao atualizar uma coleção, o HT mantém o rastro dos metadados associados para cada item nela. Eu incluí nos ficheiros da lição os metadados para uma lição de amostra no formato JSON. Se quisesse usar o ficheiro da sua própria coleção do HT, o leitor navegaria até à página das suas coleções e colocaria o cursor do mouse sobre o link dos metadados à esquerda para revelar a opção para fazer o download como JSON, como observado na seguinte captura de tela.
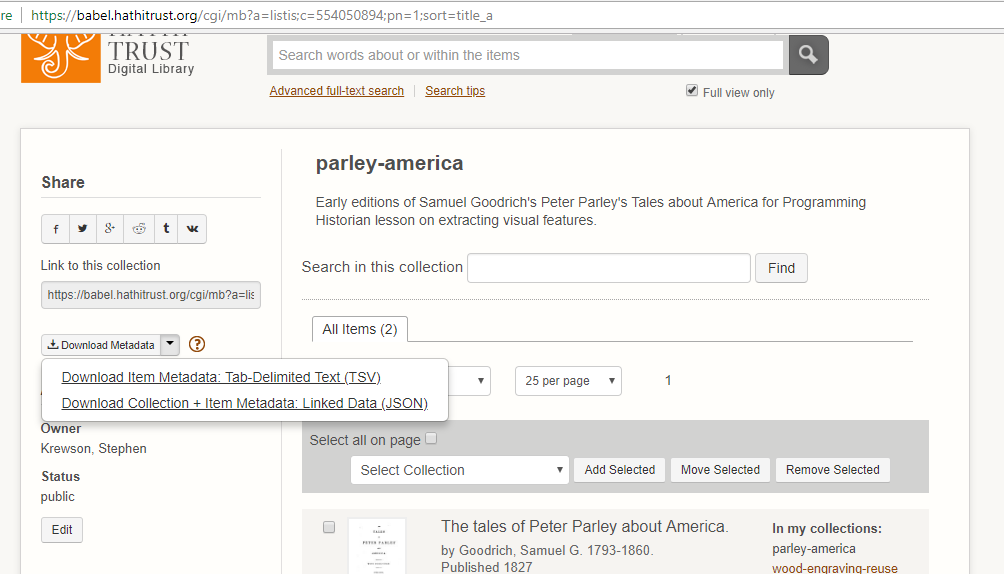
Captura de tela de como fazer o download dos metadados de coleções no formato JSON.
Assim que o leitor tiver feito o download do ficheiro JSON, basta movê-lo para o diretório onde colocou os Jupyter notebooks. Substitua o nome do ficheiro JSON no notebook do HT com o nome do ficheiro da sua coleção.
O notebook mostra como usar list comprehension para obter todas as strings htitem_id dentro do objeto gathers que contem todas as informações da coleção.
# O leitor pode especificar o ficheiro de metadados da sua coleção aqui
metadata_path = "554050894-1535834127.json"
with open(metadata_path, "r") as fp:
data = json.load(fp)
# Uma lista de todas as IDs exclusivas na coleção
vol_ids = [item['htitem_id'] for item in data['gathers']]
Característica Visual: IMAGE_ON_PAGE
Dada uma lista de volumes, nós queremos explorar que características visuais eles têm ao nível da página. A documentação mais recente (2015) para o API de dados descreve um objeto metadados chamado htd:pfeat nas páginas 9-10. htd:pfeat é a abreviação para “HathiTrust Data API: Page Features”.
htd:pfeat - the page feature key (if available):
- CHAPTER_START
- COPYRIGHT
- FIRST_CONTENT_CHAPTER_START
- FRONT_COVER
- INDEX
- REFERENCES
- TABLE_OF_CONTENTS
- TITLE
O que o wrapper hathitrust-api faz é disponibilizar os metadados completos para um volume do HT como um objeto Python. Dado o identificador dum volume, nós podemos pedir os seus metadados e, depois, fazer o drill down através da sequência de páginas até à informação ao nível da página. A lista htd:pfeat está associada com cada página num volume e, em teoria, contém todas as características que se aplicam a essa página. Na prática, existem mais algumas tags de características do que as oito listadas em cima. Aquela com a qual nós iremos trabalhar chama-se IMAGE_ON_PAGE e é mais abstratamente visual que tags estruturais como CHAPTER_START.
Tom Burton-West, um bibliotecário pesquisador na biblioteca da University of Michigan, trabalha em estreita colaboração com o HathiTrust e o HTRC, o Centro de Pesquisa do HathiTrust. O Tom disse-me por e-mail que o HathiTrust recebe a informação htd:pfeat via o Google, com o qual trabalham proximamente desde a fundação do HT, em 2008. Um contacto no Google deu permissão ao Tom para partilhar o seguinte:
Estas tags são derivadas duma combinação de Heurística, de aprendizagem de máquina e de anotação humana.
Um exemplo heurístico pode ser o facto do primeiro elemento na sequência de páginas do volume ser quase sempre a FRONT_COVER. A aprendizagem de máquina pode ser usada para treinar modelos a discriminar, digamos, entre dados de imagem que são mais típicos das linhas de prosa numa escrita ocidental ou das linhas numa gravura. A anotação humana é a atribuição manual de etiquetas a imagens. A habilidade de ver as ilustrações dum volume nos bancos de dados do EEBO e do ECCO é um exemplo de anotação humana.
O uso da “aprendizagem de máquina” pelo Google parece um pouco misterioso. Até o Google publicitar os seus métodos, é impossível saber todos os detalhes. No entanto, é provável que as tags IMAGE_ON_PAGE tenham sido propostas pela primeira vez após a deteção de blocos de “Imagens” nos ficheiros de output do OCR (um processo discutido em baixo, na secção do Internet Archive). Mais filtragem pode, então, ser aplicada.
Passo a Passo Para o Código
Encontrar as imagens
Nós vimos como criar uma lista de volumes e observámos que a API de dados pode ser usada para obter objetos metadados contendo características experimentais ao nível da página. A função essencial no notebook do HT tem a assinatura digital ht_picture_download(item_id, out_dir=None). Dado um identificador exclusivo e um diretório de destino opcional, esta função irá, em primeiro lugar, obter os metadados do volume a partir da API e convertê-los num formato JSON. Depois, percorre a sequência de páginas e verifica se a tag IMAGE_ON_PAGE está na lista htd:pfeat (se a mesma existir).
# Metadados da API no formato JSON (diferente dos metadados da coleção do HT)
meta = json.loads(data_api.getmeta(item_id, json=True))
# A sequência dá-nos cada página do item digitalizado em ordem, com qualquer
# informação adicional que lhe pode estar disponível
sequence = meta['htd:seqmap'][0]['htd:seq']
# A lista de páginas com imagens (vazio para a iniciação)
img_pages = []
# O bloco try/except lida com situações onde nenhuma "pfeats" existe OU
# os números da sequência não são numéricos
for page in sequence:
try:
if 'IMAGE_ON_PAGE' in page['htd:pfeat']:
img_pages.append(int(page['pseq']))
except (KeyError, TypeError) as e:
continue
Note que nós precisamos de fazer o drill down por vários níveis até ao objeto do nível de topo para obter o objeto htd:seq, sobre o qual nós podemos iterar.
As duas exceções que eu quero evitar são o KeyError, que ocorre quando a página não tem qualquer característica ao nível da página a si associada, e o TypeError, que ocorre quando o campo pseq para a página é, por alguma razão, não numérico e, portanto, não pode ser destinado a um int. Se algo correr mal com uma página, nós simplesmente executamos continue para passar à próxima. O plano é obter todos os dados bons que conseguirmos. Não é limpar inconsistências ou falhas nos metadados do item.
Fazer o Download das Imagens
Assim que img_pages contém a lista completa de páginas com a tag IMAGE_ON_PAGE, nós podemos fazer o download dessas páginas. Note que, se nenhum out_dir for fornecido a ht_picture_download(), então a função simplesmente retorna a lista img_pages e NÃO faz o download do quer que seja.
A chamada da API getpageimage() retorna um JPEG por predefinição. Nós simplesmente colocamos os bytes do JPEG num ficheiro na forma normal. Dentro da subpasta do volume (ela própria dentro do out_dir), as páginas serão nomeadas 1.jpg para a página 1 e assim sucessivamente.
Uma coisa a considerar é a nossa taxa de uso da API. Nós não queremos abusar do nosso acesso ao fazer centenas de pedidos por minuto. Para estar a salvo, especialmente se pretendermos executar grandes trabalhos, nós esperamos dois segundos antes de fazer cada pedido de página. Isto pode ser frustrante a curto prazo, mas ajuda a evitar o sufocamento ou a suspenção da API.
for i, page in enumerate(img_pages):
try:
# Uma simples mensagem de estado
print("[{}] Downloading page {} ({}/{})".format(item_id, page, i+1, total_pages))
img = data_api.getpageimage(item_id, page)
# N.B.: O loop só é executado se "out_dir" não for "None"
img_out = os.path.join(out_dir, str(page) + ".jpg")
# Escreva a imagem
with open(img_out, 'wb') as fp:
fp.write(img)
# Para evitar exceder o uso da API permitido
time.sleep(2)
except Exception as e:
print("[{}] Error downloading page {}: {}".format(item_id, page,e))
Internet Archive
Acesso à API
Nós conectamos à biblioteca API do Python usando uma conta no Archive.org com e-mail e palavra-chave ao invés das chaves de acesso do API. Isto é discutido no Guia Quickstart. Se não tiver uma conta, registre-se para obter o seu “Virtual Library Card”.
Na primeira célula do notebook internetarchive.ipynb, introduza as suas credenciais como indicado. Execute a célula para autenticar-se perante a API.
Nota de tradução: O comando
ia.configure(ia_email, ia_password)é atualmente desnecessário e pode gerar um erro extenso, em cuja mensagem final consta:InvalidURL: Invalid URL 'https:///services/xauthn/': No host supplied. Sugerimos que o mesmo não seja executado no ficheiro IPYNB.
Criar uma Lista de Volumes
A biblioteca IA do Python permite-lhe submeter query strings e receber uma lista de pares chave-valor correspondentes na qual a palavra “identifier”, ou identificador, em português, é a chave e o verdadeiro identificador é o valor. A sintaxe para uma query é explicada na página de Advanced Search para o IA. O leitor pode especificar parâmetros ao usar uma palavra-chave como “date” ou “mediatype” seguida de dois pontos e o valor que quer atribuir a esse parâmetro. Por exemplo, eu só quero resultados que são textos (em oposição a vídeos, etc.). Certifique-se que os parâmetros e as opções que está a tentar usar são suportadas pela funcionalidade de pesquisa do IA. Caso contrário, pode perder ou obter resultados estranhos e não saber porquê.
No notebook, eu gero uma lista de IDs do IA com o seguinte código:
# Uma pesquisa de amostra (deve gerar dois resultados)
query = "peter parley date:[1825 TO 1830] mediatype:texts"
vol_ids = [result['identifier'] for result in ia.search_items(query)]
Característica Visual: Blocos de Imagens
O Internet Archive não apresenta quaisquer características ao nível da página. Ao invés, disponibiliza um certo número de ficheiros brutos do processo de digitalização aos utilizadores. O mais importante destes para os nossos propósitos é o ficheiro XML Abbyy. Abbyy é uma empresa russa cujo software FineReader domina o mercado do OCR.
Todas as versões recentes do FineReader produzem um documento XML que associa diferentes “blocos” com cada página no documento digitalizado. O tipo de bloco mais comum é Text mas também existem blocos Picture ou “Imagem”, em português. Aqui está um bloco de exemplo tirado dum ficheiro de XML Abbyy do IA. Os cantos superior esquerdo (“t” e “l”) e inferior direito (“b” e “r”) são suficientes para identificar a região de bloco retangular.
<block blockType="Picture" l="586" t="1428" r="768" b="1612">
<region><rect l="586" t="1428" r="768" b="1612"></rect></region>
</block>
O equivalente no IA a ver as tags IMAGE_ON_PAGE no HT é a análise do ficheiro XML Abbyy e a iteração sobre cada página. Se existir pelo menos um bloco Picture nessa página, a página é sinalizada como possivelmente contendo uma imagem.
Enquanto a característica IMAGE_ON_PAGE do HT não contém informação sobre a localização dessa imagem, os blocos Picture no ficheiro XML estão associados a uma região retangular na página. No entanto, porque o FineReader se especializa no reconhecimento de letras de conjuntos de caracteres ocidentais, é muito menos preciso a identificar regiões de imagem. O projeto de Leetaru (veja Visão Geral) usou as coordenadas da região para cortar imagens, mas nesta lição nós iremos simplesmente fazer o download da página inteira.
Parte da diversão intelectual desta lição é usar um dataset (tags de bloco do OCR) por vezes confuso para um propósito largamente não intencional: identificar imagens e não palavras. A certa altura, tornar-se-á computacionalmente viável executar modelos de aprendizagem aprofundada em todas as páginas ilustradas nuas num volume e escolher o(s) tipo(s) de imagem(/ns) desejada(s). Mas, como a maior parte das páginas na maioria dos volumes não são ilustradas, esta é uma tarefa dispendiosa. Por agora, faz mais sentido aproveitar os dados existentes que nós detemos do processo de ingestão do OCR.
Para mais informações sobre como o próprio OCR funciona e interage com o processo de digitalização, por favor, veja a lição do PH de Mila Oiva, OCR With Tesseract and ScanTailor (atenção que esta lição já não é actualizada). Erros podem surgir por causa de distorções, artefactos e muitos outros problemas. Estes erros acabam por afetar a fiabilidade e a precisão dos blocos “Picture”. Em muitos casos, o Abbyy estimará que páginas em branco ou descoloridas são, na realidade, imagens. Estas tags de bloco incorretas, ainda que indesejadas, podem ser combatidas com o uso de redes neurais convolucionais retreinadas. Pense nas páginas com imagens cujo download foi feito nesta lição como um primeiro passo num processo mais longo para obter um dataset limpo e útil de ilustrações históricas.
Passo a Passo do Código
Encontrar as Imagens
Tal como com o HT, a função principal para o IA é ia_picture_download(item_id, out_dir=None).
Visto que envolve o I/O dum ficheiro, o processo para obter a lista img_pages é mais complicado do que o do HT. Usando a utilidade ia (que é instalada com a biblioteca) da linha de comando, o leitor pode obter uma ideia dos ficheiros de metadados disponíveis para um volume. Com muitas poucas exceções, um ficheiro com o formato “Abbyy GZ” deveria estar disponível para volumes com o tipo de media text no Internet Archive.
Estes ficheiros, mesmo quando comprimidos, podem facilmente ter centenas de megabytes de tamanho! Se existir um ficheiro Abbyy para o volume, nós obtemos o seu nome e depois fazemos o download. A chamada ia.download() usa alguns parâmetros úteis para ignorar a solicitação se o ficheiro já existe e, se não, para fazer o seu download sem criar um diretório aninhado. Para salvar espaço, nós eliminamos o ficheiro Abbyy depois de o analisar.
# Use o cliente da linha de comandos para ver os formatos de metadados disponíveis:
# `ia metadata formats VOLUME_ID`
# Para esta lição, só o ficheiro Abbyy é necessário
returned_files = list(ia.get_files(item_id, formats=["Abbyy GZ"]))
# Certifique-se de que algo é devolvido
if len(returned_files) > 0:
abbyy_file = returned_files[0].name
else:
print("[{}] Could not get Abbyy file".format(item_id))
return None
# Faça o download do ficheiro Abbyy para o CWD
ia.download(item_id, formats=["Abbyy GZ"], ignore_existing=True, \
destdir=os.getcwd(), no_directory=True)
Assim que nós tivermos o ficheiro, nós precisamos de analisar o XML usando a biblioteca padrão do Python. Nós tomamos vantagem do facto de que nós podemos abrir o ficheiro comprimido diretamente com a biblioteca gzip. Os ficheiros Abbyy são indexadas a partir do zero, por isso a primeira página na sequência digitalizada tem o índice de 0. No entanto, nós temos que filtrar 0 porque não pode ser exigido do IA. A exclusão do índice 0 por parte do IA não está documentada em qualquer lugar; em vez disso, eu descobri através de tentativa e erro. Se o leitor ver uma mensagem de erro de explicação difícil, tente rastrear a origem e não tenha medo em pedir ajuda, seja a alguém com experiência relevante, seja a alguém da própria organização.
# Colecione as páginas com pelo menos um bloco de imagem
img_pages = []
with gzip.open(abbyy_file) as fp:
tree = ET.parse(fp)
document = tree.getroot()
for i, page in enumerate(document):
for block in page:
try:
if block.attrib['blockType'] == 'Picture':
img_pages.append(i)
break
except KeyError:
continue
# 0 não é uma página válida para a realização de solicitações GET ao IA, mas às vezes
# está no ficheiro Abbyy comprimido
img_pages = [page for page in img_pages if page > 0]
# Acompanhe o progresso do download
total_pages = len(img_pages)
# Os ficheiros do OCR são pesados, por isso elimine assim que tivermos a lista de páginas
os.remove(abbyy_file)
Fazer o Download das Imagens
O wrapper do IA incorporado no Python não providencia uma função de download de páginas únicas—apenas em massa. Isto significa que nós usaremos a RESTful API do IA para obter páginas específicas. Primeiro, nós construímos um URL para cada página de que nós precisamos. Depois, nós usamos a biblioteca requests para enviar uma solicitação GET de HTTP e, se tudo correr bem (i.e. o código 200 é enviado na resposta), nós escrevemos o conteúdo da resposta num ficheiro JPEG.
O IA tem estado a trabalhar numa versão alpha duma API para o corte e redimensionamento de imagens que obedeça às exigências do International Image Interoperability Framework (IIIF). O IIIF representa uma profunda melhoria face ao antigo método para downloads de páginas únicas que requeriam a realização do download de ficheiros JP2, um formato de ficheiro largamente não suportado. Agora, é extremamente simples obter um só JPEG duma página:
# Veja: https://iiif.archivelab.org/iiif/documentation
urls = ["https://iiif.archivelab.org/iiif/{}${}/full/full/0/default.jpg".format(item_id, page)
for page in img_pages]
# Sem download de página direto a partir da biblioteca do Python, construa uma solicitação GET
for i, page, url in zip(range(1,total_pages), img_pages, urls):
rsp = requests.get(url, allow_redirects=True)
if rsp.status_code == 200:
print("[{}] Downloading page {} ({}/{})".format(item_id, \
page, i+1, total_pages))
with open(os.path.join(out_dir, str(page) + ".jpg"), "wb") as fp:
fp.write(rsp.content)
Próximos Passos
Assim que o leitor tiver entendido as principais funções e o código de unpacking dos dados nos notebooks, sinta-se livre para executar as células em sequência ou carregar em “Run All” e ver as páginas ilustradas a entrar nas pastas. O leitor é encorajado a adaptar estes scripts e funções para as suas próprias questões de pesquisa.
-
Nota de tradução: Aconselhamos o leitor a adicionar o Python ao PATH, processo que pode ser feito na ocasião da sua instalação. Isto irá suavizar a incorporação das dependências (veja Dependências). ↩
-
Nota de tradução: Inicialmente, aparece uma página de transição, a qual deverá remeter rapidamente para o Jupyter. Caso tal não aconteça, basta seguir as instruções nesta página. ↩