
Conteúdos
- Objetivos da lição
- Porque é que os historiadores devem se preocupar com a qualidade dos dados?
- Descrição da ferramenta: OpenRefine
- Descrição do exercício: Powerhouse
- Primeiros passos: instalação do OpenRefine e importação de dados
- Conheça os seus dados
- Remoção de linhas em branco
- Remoção de duplicações
- Atomização
- Facetting e agrupamento
- Aplicação de transformações ad-hoc através do uso de expressões GREL
- Exportação dos seus dados limpos
- Construção sob os dados limpos
- Conclusões
Objetivos da lição
Não aceite os dados tal como são apresentados. Esta é a principal mensagem deste tutorial que se foca na forma como os usuários podem diagnosticar e agir perante a precisão dos dados. Nesta lição, o usuário vai aprender os princípios e a prática da limpeza de dados, ao mesmo tempo que aprende como é que o OpenRefine (em inglês) pode ser utilizado para realizar quatro tarefas essenciais que vão ajudar na limpeza de dados:
- Remover registos duplicados
- Separar múltiplos valores contidos no mesmo campo
- Analisar a distribuição de valores ao longo do Dataset
- Agrupar diferentes representações da mesma realidade
Estes passos são explicitados com a ajuda de uma série de exercicios baseados na coleção de metadados do Powerhouse (em inglês), demonstrando, assim, como métodos (semi)automáticos podem ajudar na correção de erros dos dados.
Porque é que os historiadores devem se preocupar com a qualidade dos dados?
Registros duplicados, valores vazios e formatos incossistentes são fenómenos com os quais devemos estar preparados para lidar quando utilizamos data sets históricos. Esta lição vai ensinar o usuário a descobrir inconsistências nos dados contidos em tabelas ou bases de dados. À medida que, cada vez mais, partilhamos, agregamos e reutilizamos dados na web, os historiadores terão uma maior necessidade de responder a problemas inevitáveis associados à qualidade dos dados. Utilizando um programa chamado OpenRefine, o usuário será capaz de identificar facilmente erros sistemáticos, tais como células em branco, duplicações, inconsistências ortográficas, etc. O OpenRefine não só permite um diagnóstico rápido da precisão dos dados, mas também age perante certos erros de forma automática.
Descrição da ferramenta: OpenRefine
No passado, os historiadores dependiam de especialistas em tecnologias da informação para diagnosticar a qualidade dos dados e para executar tarefas de limpeza dos mesmos. Isto exigia programas computacionais personalizados quando se trabalhava com data sets consideráveis. Felizmente, o surgimento de Ferramentas Interativas de Transformação de Dados (Interactive Data Transformation tools, ou IDTs em inglês), permite que até profissionais sem habilidades técnicas aprofundadas possam realizar operações rápidas e baratas em grandes data sets.
As Ferramentas Interativas de Transformação de Dados assemelham-se às tabelas de dados do desktop com as quais estamos familiarizados, chegando a partilhar funcionalidades com as mesmas. O usuário pode, por exemplo, usar aplicações como o Microsoft Excel para organizar os seus dados com base em vários filtros, sejam eles numéricos, alfabéticos ou até personalizados, o que permite detetar erros mais facilmente. Configurar estes filtros em tabelas de dados pode ser complicado, já que estes são uma função secundária do software. Geralmente, podemos dizer que as tabelas de dados são projetadas para funcionar em linhas ou células individuais, enquanto as Ferramentas Interativas de Transformação de Dados operam em grandes intervalos de dados ao mesmo tempo. Estas “Tabelas de dados em esteroides” fornecem uma interface integrada e amigável através da qual os usuários finais podem detetar e corrigir erros.
Nos últimos anos, têm sido desenvolvidas várias ferramentas para a transformação de dados interativos, tais como Potter’s Wheel ABC (em inglês) e Wrangler (em inglês). Aqui queremos concentrar-nos, sobretudo, no OpenRefine (anteriormente Freebase Gridworks e Google Refine), já que, na opinião dos autores, esta é a ferramenta mais amigável para processar e limpar eficazmente grandes quantidades de dados numa interface baseada no navegador de internet.
Além do data profiling (perfil de dados) (em inglês) e das operações de limpeza, as extensões do OpenRefine permitem aos usuários identificar conceitos num texto desestruturado através de um processo denominado Named-Entity Recognition (Reconhecimento de Entidade Nomeada) (em inglês) (NER) e reconciliar os seus próprios dados com bases de conhecimento existentes. Ao fazê-lo, o OpenRefine pode ser uma ferramenta prática de ligação dos dados com conceitos e autoridades que já foram declarados na web por entidades como a Library of Congress (Biblioteca do Congresso dos Estados Unidos da América) (em inglês) ou o OCLC (Centro de Bibliotecas de Computadores Online) (em inglês). A limpeza de dados é um pré-requisito para estas etapas; A taxa de sucesso do NER e o êxito do processo de correspondência entre os dados do usuário e as entidades externas, dependem da habilidade do mesmo de tornar estes dados o mais concretos possível.
Descrição do exercício: Powerhouse
O Powerhouse, em Sydney, permite-lhe exportar gratuitamente os metadados da sua coleção no seu sítio Web. Este museu é um dos maiores do mundo na área da ciência e tecnologia, fornecendo acesso a quase 90,000 objetos, que vão desde motores a vapor até vidros finos e de peças de alta-costura a chips de computadores.
O museu divulgou ativamente a sua coleção em linha e disponibilizou gratuitamente a maior parte dos seus dados. No seu sítio Web, era possível descarregar um ficheiro de texto separado por separadores denominado phm-collection.tsv e abri-lo como uma tabela de dados. O ficheiro descomprimido (58MB) contém metadados básicos (17 campos) para 75,823 objetos, sob a licença Creative Commons Attribution Share Alike (CCASA) (em inglês). Neste tutorial utilizaremos uma cópia dos dados que está arquivada para o usuário fazer o download (mais à frente). Isto garante que se o Powerhouse atualizar os seus dados, o usuário ainda vai conseguir acompanhar esta lição.
Ao longo do processo de limpeza e de criação do perfil dos dados, a lição vai focar o campo das 'Categorias', que é preenchido com termos do Powerhouse Object Names Thesaurus (BARTOC) (em inglês). O BARTOC reconhece o uso e a ortografia australiana e reflete, de uma maneira muito direta, os pontos fortes da coleção. Nesta coleção, o usuário vai encontrar, por exemplo, mais e melhores representações da história social e das artes decorativas e menos objetos com nomes associados às belas-artes e à história natural.
Os termos no campo das Categorias compreendem o que chamamos de Vocabulário Controlado. Um Vocabulário Controlado consiste em palavras-chave que, ao utilizarem um número limitado de termos, descrevem o conteúdo de uma coleção, sendo, normalmente, um ponto de entrada importante para historiadores em data sets de bibliotecas, arquivos e museus. É, por isso, que será dada uma importância especial ao campo das ‘Categorias’. Depois de ser feita a limpeza dos dados, deverá ser possível reutilizar os termos do Vocabulário Controlado para encontrar informação adicional sobre esses termos num outro lugar online. Isto é conhecido como a criação de Linked Data (Dados Vinculados).
Primeiros passos: instalação do OpenRefine e importação de dados
Deverá ser feito o Download do OpenRefine (em inglês) e seguidas as instruções. O OpenRefine funciona em todas as plataformas: Windows, Mac, e Linux. Este será aberto no navegador de internet do usuário, mas é importante entender que a aplicação é executada localmente e que os dados não serão guardados online. Com o OpenRefine aberto no seu navegador de internet, clique em ‘Language Settings’, presente no canto superior esquerdo, e altere a linguagem para ‘Português’. Os arquivos de dados estão disponíveis no Programming Historian como phm-collection. Por favor, faça o Download do ficheiro phm-collection.tsv que serão utilizados ao longo deste tutorial antes de continuar.
Na página inicial do OpenRefine crie um novo projeto utilizando o ficheiro de dados que fez o download e clique ‘Próximo’ . A primeira linha será processada como o nome da coluna por defeito, mas será preciso desmarcar a caixa de seleção ‘Usar caracter “ encerrar células contendo separadores de colunas’, já que as aspas dentro do ficheiro não têm qualquer significado para o OpenRefine. Além disto, deverá selecionar a caixa de seleção ‘Tentar analisar texto de células como números’ para que o OpenRefine detete automaticamente números. Agora deverá clicar em ‘Criar projeto’. Se tudo correr como planejado, deverá ver no canto superior esquerdo 75,814 linhas.
O data set do Powerhouse consiste em metadados detalhados sobre todos os objetos da coleção incluindo o título, a descrição, as várias categorias às quais o item pertence, informação sobre a proveniência do mesmo e um link persistente para a página que hospeda o objeto dentro do site do museu. Para ter uma ideia do objeto a que corresponde os metadados, clique no link persistente e o site será aberto.
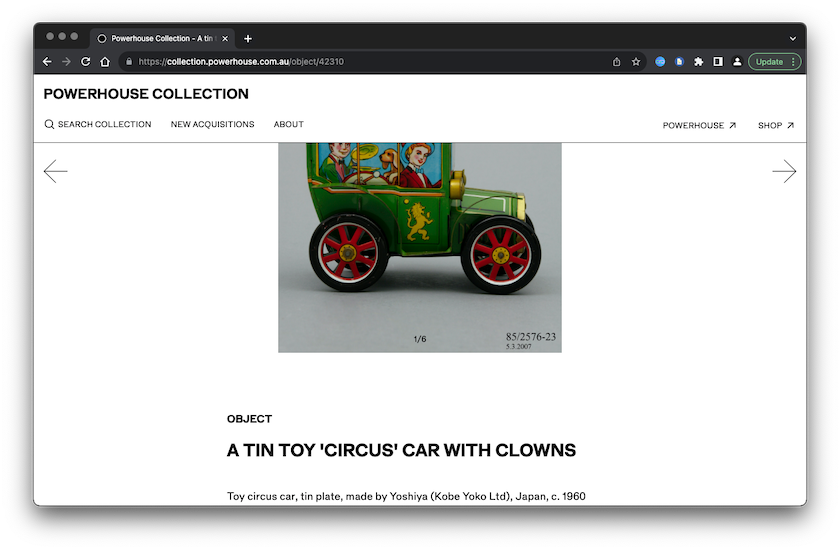
Figura 1: Captura de tela de um objeto de amostra no site Powerhouse
Conheça os seus dados
A primeira coisa a fazer é observar e conhecer os seus dados. Poderá inspecionar os diferentes valores de dados exibindo-os em facetas e filtros. Poderá considerar a faceta (em inglês) uma lente através da qual é possível ver um subconjunto específico de dados baseados no critério da sua escolha. Clique no triângulo em frente ao nome da coluna, selecione Faceta e crie uma Faceta. Por exemplo, experimente o Faceta de texto ou o Faceta numérica, dependendo da natureza dos valores contidos nesses campos (os valores numéricos estão expostos a verde). No entanto, tenha em atenção que estas Facetas de texto têm uma maior eficácia em campos com valores redundantes (Categories (categorias), por exemplo); Se ocorrer o erro ‘Muitas para mostrar’ você pode escolher aumentar o limite da contagem de opções a cima do padrão dos 2,000. Todavia, um limite muito alto pode tornar o aplicativo mais lento (por norma, 5,000 é uma escolha segura). Facetas numéricas não têm esta restrição. Para mais opções, selecione Facetas personalizadas : Faceta por valores em branco, por exemplo, torna-se útil na procura de quantos valores foram preenchidos em cada campo. Vamos explorar mais detalhadamente estas funcionalidades nos exercícios a seguir.
Remoção de linhas em branco
Uma coisa que irá reparar quando criar Facetas numéricas para a coluna do Record ID (Identificador do registo), é que existem três linhas sem dados. Poderá encontrá-las ao desmarcar a caixa de seleção numérica, deixando apenas valores não-numéricos. Na verdade, estes valores não estão realmente a branco, mas contêm apenas um caractere de espaço em branco, que pode ser visível se mover o seu cursor para onde deveria estar esse valor e clicar no botão ‘edit’ (Editar) que aparece. Para remover estas linhas, clique no triângulo em frente à primeira coluna denominada por ‘Todos’ , selecione ‘Editar linhas’ e depois ‘Remover as linhas que corresponderam’. Feche a faceta numerica para verificar que permanecem agora 75,811 linhas.
Remoção de duplicações
O segundo passo é detetar e remover duplicações. Estas podem ser identificadas ao classificar colunas, como o Record ID, por um valor único (neste caso vamos assumir que o Record ID é, de facto, único para cada entrada). Esta operação pode ser realizada ao clicar no triângulo à esquerda do Record ID, depois devemos selecionar a opção ‘Ordenar…’ e escolher o marcador ‘números’. No OpenRefine, ordenar é apenas uma ajuda visual, a não ser que torne a reordenação permanente. Para o fazer, clique na opção Ordenar por cima do Marks (Marcas) e, em seguida, deverá escolher a opção ‘Reordenar linhas permanentemente’. Se se esquecer de fazer isto, posteriormente, irá ter resultados imprevisíveis neste tutorial.
Linhas idênticas estão agora adjacentes umas às outras. Em seguida, deixe em branco as linhas do Record ID que têm o mesmo Record ID que as a cima delas, marcando-as como duplicações. Para o fazer, deve clicar no triângulo do Record ID, escolher Editar células > Transformar em vazias abaixo. A mensagem de status dirá que 84 colunas foram afetadas (se se esqueceu de reordenar as linhas permanentemente, apenas vão ser afetadas 19 colunas; em caso afirmativo, desfaça a operação Transformar em vazias abaixo no separador ‘Desfazer/Refazer’ e volte ao parágrafo anterior refazendo-o de modo a ter a certeza que as linhas estão reordenadas e não apenas classificadas). Elimine essas linhas ao criar uma faceta em ‘Transformar em vazias abaixo’ na coluna do Record ID (‘Faceta’ > ‘Facetas personalizadas’ > ‘Faceta por valores em branco’) em seguida deverá selecionar as 84 linhas a branco clicando em ‘true’ (Verdade) e removê-las usando o triângulo da coluna ‘Todos’ (‘Editar linhas’ > Remover as linhas que corresponderam’). Quando fechar a faceta deverá observar que existem agora 75,727 linhas únicas.
O usuário deverá ter uma atenção especial ao eliminar duplicações. Na etapa mencionada acima, assumimos que o data set possui um campo com valores únicos, indicando que uma linha inteira representa uma duplicação. Este não é necessariamente o caso e, por isso, devemos ter cuidado e verificar manualmente se a linha inteira representa uma duplicação ou não.
Atomização
Depois de remover os registos duplicados, podemos focar-nos na coluna Categories. Em média, foram atribuídas 2.25 categorias a cada objeto. Estas categorias estão contidas no mesmo campo, separadas por uma barra vertical ‘|’. O registo 9, por exemplo, contém três: ‘Mineral samples|Specimens|Mineral Samples-Geological’ (Amostras minerais|Espécimes|Amostras minerais-Geológicas). Para analisar em detalhe o uso destas palavras-chave, os valores do campo das categorias devem ser separados em células individuais com base na barra vertical, expandindo os 75,727 registos em 170,167 linhas. Escolha ‘Editar células’, ‘Dividir células com múltiplos valores’, digitando ‘|’ como separador de valores. O OpenRefine irá informá-lo que tem agora 170,167 linhas.
É importante compreender totalmente o paradigma das linhas/entradas. Torne a coluna Record ID visível para ver o que se passa. Pode mudar entre a opção de visualização ‘linhas’ e ‘entradas’ ao clicar nos links que dão pelos mesmos nomes, logo em cima do cabeçalho das colunas. Na opção ‘linhas’, cada linha representa um par de Record IDs e uma única categoria, permitindo a manipulação de cada uma individualmente. A opção ‘entradas’ tem uma entrada para cada Record ID, que pode ter categorias diferentes em linhas diferentes (agrupadas a cinzento ou branco), mas cada registo é manipulado como um todo. Concretamente, existem agora 170,167 atribuições de categorias (Linhas), separadas em 75,736 itens de coleção (Entradas). Pode também ter reparado que estamos com mais 9 registos do que os originais 75,727, mas não se preocupe com isso agora, iremos voltar a esta pequena diferença mais tarde.
Facetting e agrupamento
Um dos conteúdos do campo foi devidamente atomizado, filtros, facetas e agrupamentos podem ser aplicados para fornecer uma visão rápida e geral dos problemas clássicos dos metadados. Ao aplicar a faceta customizada ‘Faceta por valores em branco’ à coluna Categories, é possível identificar imediatamente os 461 registos que não têm uma categoria, representando 0.6% da coleção. Ao aplicar uma faceta de texto ao campo das categorias podemos ter uma visão geral das 4,935 diferentes categorias utilizadas na coleção (o limite padrão é 2,000, mas poderá clicar na opção ‘Definir o limite da contagem da escolha’ para aumentá-la para 5,000). Os títulos podem ser ordenados alfabeticamente (nome’) ou por frequência (‘quantidade’), fornecendo ao utilizador uma lista dos termos mais usados para indexar a coleção. Os três títulos principais são ‘Numismática’ (Numismatics) (8,041), ‘Cerâmica’ (Ceramics) (7,390) e ‘Roupas e vestuário’ (Clothing and dress) (7,279).
Após aplicar a faceta, o OpenRefine propõe aglomerar as escolhas da faceta com base em vários métodos de similaridade. Tal como a Figura 2 demonstra, o agrupamento permite ao usuário resolver problemas relacionados com inconsistências, o uso incoerente tanto da forma singular como plural e erros de ortografia simples. O OpenRefine apresenta os valores relacionados e propõe uma fusão resultante no valor mais recorrente. Deverá selecionar a opção ‘Agrupar’ para abrir o comando de uniformização dos termos, em seguida, escolha os valores que deseja agrupar ao selecionar as caixas individualmente ou ao clicar ‘Marcar todos’ na parte inferior e, por fim, ‘Unir selecionados e Re-agrupar’.
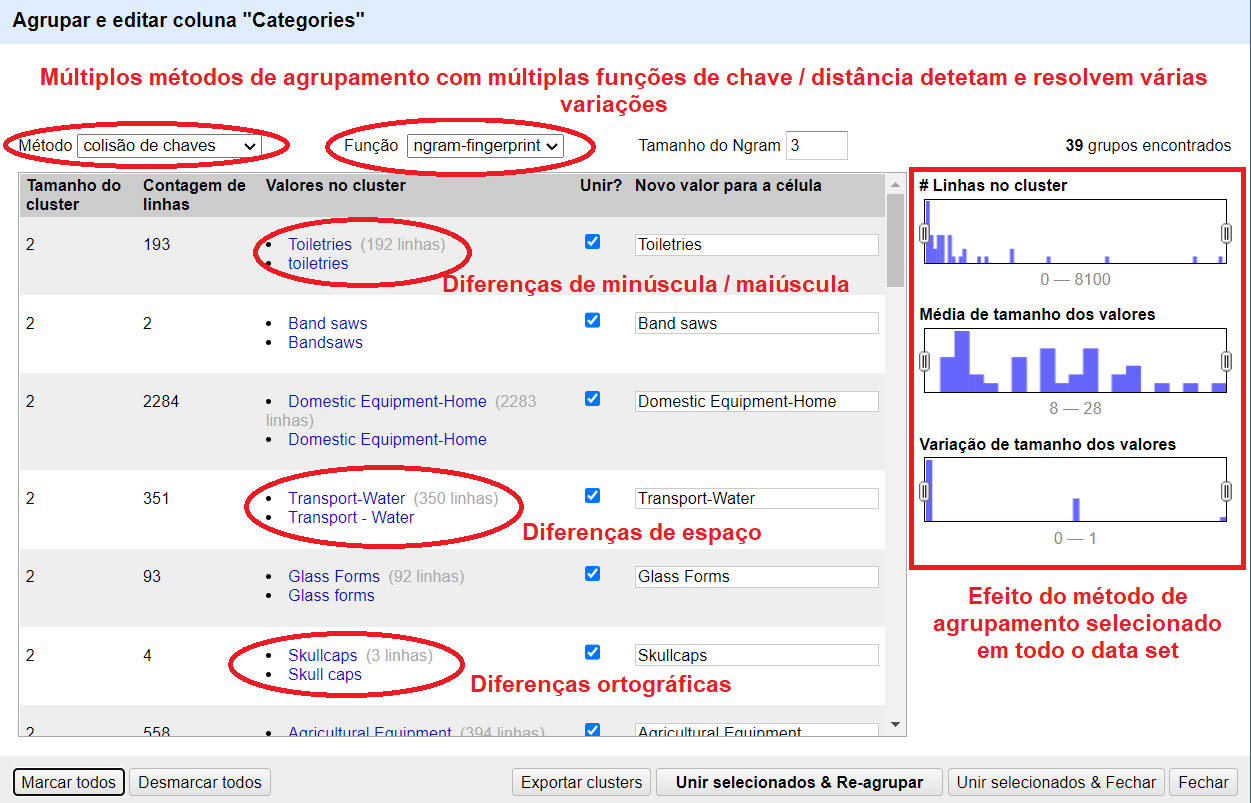
Figura 2: Visão geral de alguns agrupamentos
O método padrão de aglomeramento não é muito complexo, portanto ainda não encontra todos os aglomerados. Experimente com diferentes métodos para ver quais são os resultados que estes produzem. Deverá ter cuidado: alguns métodos podem ser muito agressivos e alguns valores, que não deverão estar juntos, podem acabar agrupados. Agora que os valores foram agrupados individualmente, podemos colocá-los de volta numa única célula. Clique no triângulo das categories e escolha Editar células, Unir células com múltiplos valores, escolha a barra vertical (‘|’) como separador, OK. As linhas têm agora a mesma aparência que tinham antes, com um campo de categorias com vários valores.
Aplicação de transformações ad-hoc através do uso de expressões GREL
Relembre-se que existiu um aumento no número de registos depois do processo de divisão: nove registos apareceram do nada. Para encontrar a causa desta disparidade, precisamos de voltar atrás, antes da divisão das categorias em linhas separadas. Para fazer isso, altere o separador ‘Desfazer / Refazer’ à direita do separador ‘Faceta / Filtro’ e vai obter um histórico de todas as ações que executou desde que o projeto foi criado. Selecione o passo antes de ‘Split multi-valued cells in column Categories’ (Dividir células com vários valores na coluna Categorias) (se seguiu o nosso exemplo deverá ser ‘Remove 84 rows’ (Remover 84 linhas)). Depois volte para o separador ‘Faceta / Filtro’.
O problema surgiu durante a operação de divisão no caractere de barra vertical, portanto há uma grande probabilidade do que correu mal estar relacionado com esse caractere. Vamos aplicar um filtro na coluna Categorias ao selecionar ‘Filtro de texto’ no menu. Primeiro, digite um único | no campo da esquerda: o OpenRefine deverá informá-lo que existem 71,064 registos correspondentes (i.e. registos que contenham uma barra vertical) num total de 75,727. Células que não contenham a barra vertical podem ser células em branco ou células apenas com uma categoria, não tendo assim um separador. Tal como o registo 29 que apenas tem ‘Scientific instruments’ (Instrumentos científicos).
Agora insira um segundo ‘|’ depois do primeiro para obter ‘||’ (dupla barra vertical): poderá observar que existem 9 registos que correspondem a este padrão. Estes são, provavelmente, os 9 registos culpados pela nossa discrepância: quando o OpenRefine divide os registos, a dupla barra vertical é interpretada como uma quebra entre dois registos em vez de um separador duplo sem sentido. Agora, como é que corrigimos estes valores? Vá ao menu do campo das categorias e escolha ‘Editar células’ > ‘Transformar…. Bem-vindo à interface de transformação de texto personalizada, uma funcionalidade poderosa do OpenRefine que usa a Google Refine Expression Language (GREL).
A palavra ‘value’ (valor) no campo de texto representa o valor atual de cada célula, valor esse visível em baixo. Podemos modificar este valor ao aplicar-lhe funções (ver a GREL documentation (documentação da GREL, em inglês) para uma lista completa). Neste caso, queremos substituir a dupla barra vertical por uma única barra. Isto pode ser realizado ao inserir a seguinte expressão GREL (certifique-se que não se esquece das aspas):
value.replace('||', '|')
Em baixo do campo de texto ‘Expressão’, terá uma pré-visualização dos valores modificados com as duplas barras verticais removidas. Clique em OK e tente dividir as categorias de novo com a opção ‘Editar células’ > ‘Dividir células com múltiplos valores…’. O número de registos ficará agora nos 75,727 (clique no link ‘entradas’ para verificar).
* * *
Outro problema que pode ser resolvido com a ajuda da GREL é o dos registos para os quais a mesma categoria é listada duas vezes. Observe o registo 41 por exemplo, cujas categorias são ‘Models|Botanical specimens|Botanical Specimens|Didactic Displays|Models’ (Modelos|Espécimes botânicos|Espécimes Botânicos|Expositores Didáticos|Modelos). A categoria ‘Models’ aparece duas vezes sem nenhuma razão aparente, pelo que vamos querer remover esta duplicação. Clique no triângulo da coluna das ‘Categories’ e escolha ‘Editar células’, ‘Unir células com múltiplos valores’, OK. Escolha a barra vertical como separador. Agora as categorias estão listadas como antes. Em seguida selecione ‘Editar células’ > ‘Transformar’, também na coluna das categorias. Ao usar a GREL podemos dividir sucessivamente as categorias na barra vertical, procurar categorias únicas e juntá-las de novo. Para isso, basta digitar a seguinte expressão:
value.split('|').uniques().join('|')
Ao fazê-lo irá reparar que 33.006 células foram afetadas, mais de metade da coleção.
Exportação dos seus dados limpos
Desde que carregou os seus dados no OpenRefine, todas as operações de limpeza foram executadas na memória do software, deixando os dados originais intocados. Se desejar salvar os dados que limpou, terá de os exportar ao clicar no menu ‘Exportar’ no canto superior direito do ecrã. O OpenRefine suporta uma larga variedade de formatos, tais como CSV (em inglês), HTML ou Excel: selecione o que melhor se adapta a si e acrescente o seu próprio modelo de exportação ao clicar ‘Criando modelo’. Poderá também exportar o seu projeto num formato interno do OpenRefine de modo a partilhá-lo com os outros.
Construção sob os dados limpos
Depois de limpar os seus dados, poderá dar o próximo passo e explorar outros recursos interessantes do OpenRefine. A comunidade de utilizadores do OpenRefine desenvolveu duas interessantes extensões que permitem ligar os seus dados a dados que já foram publicados na web. A RDF Transform extension (em inglês) transforma palavras-chave de texto simples em URLs. A NER extension (em inglês) permite ao usuário aplicar a named-entity recognition (NER) que identifica palavras chave em texto corrido e atribui-lhes um URL.
Conclusões
Se apenas se lembrar de uma coisa desta lição, deverá ser o seguinte: Todos os dados são sujos, mas poderá fazer algo quanto a isso. Tal como mostrámos aqui, já existe muito que pode ser feito para aumentar significativamente a qualidade dos dados. Em primeiro lugar, aprendemos como é que podemos ter uma visão geral e rápida de quantos valores vazios existem no nosso data set e com que frequência é que um valor particular (e.g. uma palavra-chave) é usada ao longo da coleção. Esta lição também demonstra como resolver problemas recorrentes, tais como duplicações e inconsistências ortográficas de maneira automática com a ajuda do OpenRefine. Não hesite em experimentar as ferramentas de limpeza enquanto executa estas etapas numa cópia dos seus data sets, já que o OpenRefine permite-lhe rastrear e refazer todos os passos caso tenha cometido um erro.