Contents
- Lesson Goals
- What Are Regular Expressions and for Whom Is this Useful?
- Getting the Text
- Ordinary search and replace
- Finding structure for rows
- Finding structure for columns
- The general idea of regular expressions
- Applying regular expressions
- Defining segments
- Next possibilities
- To learn more
Lesson Goals
In this exercise we will use advanced find-and-replace capabilities in a word processing application in order to make use of structure in a brief historical document that is essentially a table in the form of prose. Without using a general programming language, we will gain exposure to some aspects of computational thinking, especially pattern matching, that can be immediately helpful to working historians (and others) using word processors, and can form the basis for subsequent learning with more general programming environments.
We will start with something like this:
Arizona. — Quarter ended June 30, 1907. Estimated population,
122,931. Total number of deaths 292, including diphtheria 1, enteric
fever 4, scarlet fever 11, smallpox 2, and 49 from tuberculosis.
And use pattern matching to transform it to something like this:
| Arizona. | Quarter ended June 30, 1907. | Deaths | diphtheria | 1 |
| Arizona. | Quarter ended June 30, 1907. | Deaths | enteric fever | 4 |
| Arizona. | Quarter ended June 30, 1907. | Deaths | scarlet fever | 11 |
| Arizona. | Quarter ended June 30, 1907. | Deaths | smallpox | 2 |
| Arizona. | Quarter ended June 30, 1907. | Deaths | tuberculosis | 49 |
What Are Regular Expressions and for Whom Is this Useful?
Perhaps you are not sure yet you want to be a programming historian, you just want to work more effectively with your sources. Historians, librarians, and others in the humanities and social sciences often work with textual sources that have implicit structure. It is also not unheard of in the humanities to have to do tedious textual work with semi-structured notes and bibliographic references, where it can help to have some knowledge of pattern-matching options.
As a simple example, if we want to find a reference to a particular year, say 1877, in a document, it’s easy enough to search for that single date. But if we want to find any references to years in latter half of the 19th century, it is impractical to search several dozen times for 1850, 1851, 1852, etc., in turn. By using regular expressions we can use a concise pattern like “18[5-9][0-9]” to effectively match any year from 1850 to 1899.
In this exercise we will use LibreOffice Writer and LibreOffice Calc, which are free software desktop applications for word processing and spreadsheets, respectively. Installation packages for Linux, Mac, or Windows can be downloaded from http://www.libreoffice.org/download. Other word processing software and programming languages have similar pattern-matching capabilities. This exercise uses LibreOffice because it is freely available, and its regular expression syntax is closer to what you will find in programming environments than Microsoft Office’s syntax. If you complete this exercise and find regular expressions useful, however, it should be relatively easy to adapt what you learn and apply it in other contexts.
While we will start with simple patterns, we will get to more complicated or intimidating-looking ones fairly quickly. The aim here is to share what is involved in doing useful work with a plausible example, and not to linger too long on first principles with simplified toy examples. If you are impatient, it should be possible to go through the examples fairly quickly by copying and pasting the patterns offered, without necessarily following every detail, in order to get a general sense of what is possible. If the result is promising, you could go through a second time to decide what details could be useful to pick up for your own work. But typing everything yourself is the best way to make it your own.
Getting the Text

Figure 1: Screenshot of the unstructured text
The Internet Archive has copies of hundreds of early 20th-century public domain U.S. public health reports digitized through JSTOR and organized under the title ‘Early Journal Content.’ These are of a convenient length for an exercise and can plausibly represent broad classes of textual resources that are useful in many kinds of historical research. For our exercise, we will use a five-page report of monthly morbidity and mortality statistics for states and cities in the United States, published in February 1908, available at http://archive.org/details/jstor-4560629/.
Take a moment to scan the pages through the Read Online link to become familiar with it. This document is organized as paragraphs rather than tables, but there are clearly latent structures that can help us tabulate this ourselves. Nearly every paragraph of the report starts with geographic information, specifies a time span for the statistics, optionally includes a population estimate, and then reports deaths and nonlethal cases of illness.
The page-flipping interface shows us what the original document looked like. But if we want to tabulate figures and enable ourselves to make comparisons and calculations over geography, we will need to represent the document as text and numbers, and not just images. In addition to offering several image formats for download, the Internet Archive makes available plain-text versions that have been created by means of Optical Character Recognition (OCR) software. OCR of old texts is often imperfect, but what it produces is useful in ways images can’t be; it can be searched, copied, and edited as text.
Switch to the Full Text view. We will start from this base, ignoring the last part of the previous report. Copy the text from “STATISTICAL REPORTS…” to the end into a new LibreOffice document. When working with material you care about, be sure to save a copy somewhere separately from your working copy, so that you can get back to your original if something goes wrong.
Ordinary search and replace
We can see some Optical Character Recognition (OCR) errors, where the Internet Archive’s automated transcription software has made mistakes, although for the most part this looks like a good transcription. There are two places where the OCR has inserted double quotation marks into this file mistakenly, in both cases by putting them between a comma following a month and a four-digit year, as in
December," 1907.
We can find these by doing a search (Edit → Find with shortcut Ctrl-F
or Cmd-F on a Mac) for double quotation marks, and confirm that these
are the only two instances of quotation marks in the file. In this case
we can simply delete them. Rather than do so by hand, just for practice
try using LibreOffice’s find-and-replace function (Ctrl-H or
Cmd-Alt-F on Mac).
Replace " with nothing.
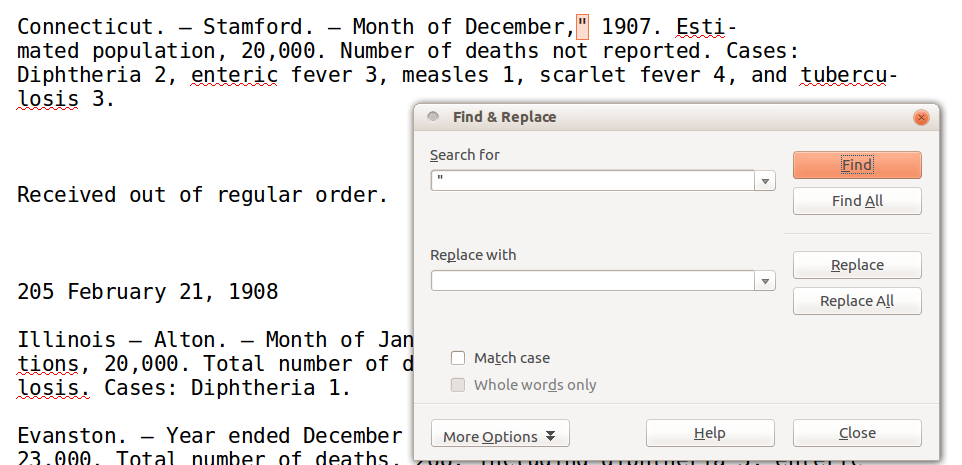
Figure 2: Screenshot of Find and Replace feature
Finding structure for rows
We are just getting started, but to estimate how far we have to go,
select the full text from LibreOffice Writer (Ctrl-A) and paste it
into LibreOffice Calc (File->New->Spreadsheet). Each line of text
becomes a single-celled row of the spreadsheet. What we would like is
for each row of the spreadsheet to represent one kind of record in a
consistent form. It would take a lot of tedious work to tabulate this by
hand with this as our starting point. In what follows we will be doing
all our work with regular expressions in Writer, but keep Calc open in
the background. We can return to it to paste future iterations and gauge
our progress.
Returning to Writer, we will want to get rid of the line breaks that we don’t need — but there are some end-of-line hyphenations we should clean up first. This time we will start using regular expressions, but with a disclaimer that regular expression implementations differ in their handling of line breaks more than in their features for matching patterns within lines.
Regular expressions in LibreOffice do not readily match patterns of
text that extend across line breaks, so we will adopt an indirect
strategy . We will first replace line breaks with a placeholder
character — let’s use # — that does not otherwise appear in our
text.
In the Find & Replace box show More Options (Other Options on Mac)
and make sure the Regular expressions checkbox is selected. This
will enable us to use special symbols to define general patterns to
match.
Using find-and-replace,
replace $ with #.
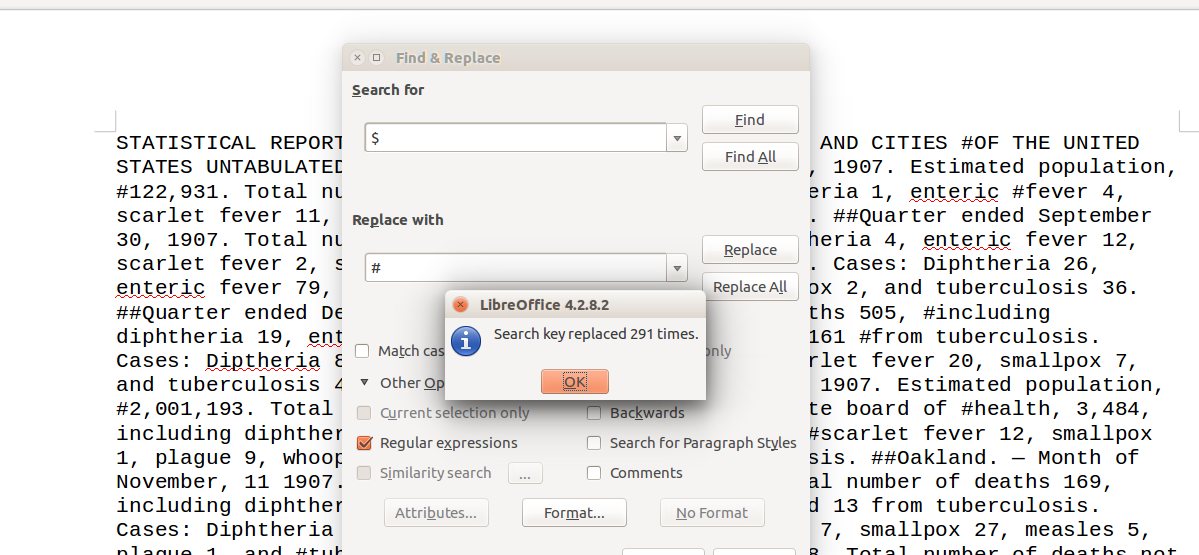
Figure 3: The ‘More Options’ tab in Open Office Find & Replace
The dollar sign symbol
is a special symbol that traditionally matches the end of each line in
order to anchor a larger pattern. However, while it can have this
function in LibreOffice in larger patterns, LibreOffice will not let
us let us match text across line breaks. But LibreOffice will let us
use the $ character on its own, without other patterns, to match and
replace line breaks independent of other characters.
To carry out a search and replace operation, you might start by
clicking Find and then Replace when you see that the highlighted
selection matches your expectations. After repeating this a few times
you can click Replace All to replace all the rest at once. If you
make a mistake or are uncertain, you can undo recent steps with Edit
→ Undo from the menu bar, or keyboard shortcut Ctrl+Z (Cmd+Z on
Mac).
In this document replacing line ends results in 291
replacements. (Your number may differ slightly depending on the number
of lines you copied.) This sequence of replacements will make the
text less readable, temporarily, but it’s necessary because we cannot
match patterns across line breaks, but we can match across a #
character.
Next let’s close up our hyphenated words. This in fact can now be accomplished by literal replacement without relying on generalized pattern matching.
Again using find-and-replace,
replace all - # (hyphen-space-hash) with nothing.
This will close up patterns like “tuber- #culosis” to “tuberculosis” on one line, and will make a total of 27 replacements in this case.
Next:
replace all ## with \n.
This results in 71 replacements. In this step we take what were originally paragraph breaks, which appeared as double line breaks, and then were represented as doubled # characters, and we turn them back again into actual single line breaks. These will function in a spreadsheet context to mark new rows.
To conclude our line break work:
replace all # with ` ` *(a single space). This will get rid of 122 line breaks that were not paragraph breaks in the original text.
At first it may not be clear what happened here, but this has in fact
made each paragraph a single paragraph or logical line. In LibreOffice
(and similar word processing programs) you can turn on nonprinting
characters (View→Nonprinting Characters with shortcut Ctrl-F10 on
Windows or Linux) to see line and paragraph breaks.

Figure 4: Non-Printing Characters in LibreOffice
As a last way of confirming that we are starting to get a more useful structure from this, let’s copy the full text from Writer again and paste it into a blank spreadsheet. This should confirm that each health record is now a separate row in the spreadsheet (although we also have page headings and footnotes mixed in — we will clean those up shortly).
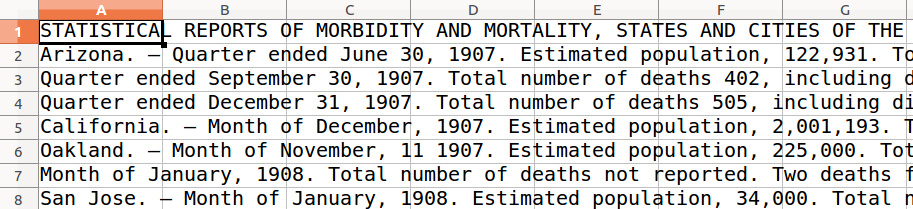
Figure 5: The improved structure, shown in LibreOffice Calc
Finding structure for columns
Spreadsheets organize information in two dimensions, rows and columns. We have seen that lines in Writer correspond to rows in Calc. How do we make columns?
Spreadsheet software can read and write plain-text files using any of several conventions for representing breaks between columns. One common format uses commas to separate columns, and such files are often stored with the extension “.csv” for “comma-separated values.” Another common variant is to use a tab character, a special kind of space, to separate columns. Because our text contains commas, to avoid confusion we will use a tab character to separate columns. Though one could save a intermediate plain-text file, in this exercise we will assume we are copying and pasting directly from Writer to Calc.
Back in Writer, let’s start making columns by splitting the place-and-time information from the reported numbers. Almost all reports include the words
Total number of deaths
Search for this and replace it with exactly the same phrase, but with “\t” at the front of the string representing a tab character:
\tTotal number of deaths
After making this replacement (which makes 53 changes), select all the text and copy and paste it into an empty spreadsheet again.
Does it look like nothing changed? LibreOffice Calc is putting the full
text of each paragraph in a single cell, tabs and all. We need to insist
on a plain-text interpretation to get Calc to ask us what to do with
tabs. Let’s try again. You can empty the spreadsheet conveniently by
selecting all (Ctrl-A) and deleting the selection.
In an empty spreadsheet, select Edit → Paste Special, (or right-click
to reach the same) and then select “unformatted text” from the options
in the window appears. That should result in a popup “Text Import”
window. Make sure the Tab checkbox is selected under Separator options
and then click “OK”. (Before clicking OK you may want to try checking
and unchecking Comma and Space as separators to preview what they would
do here, but we do not want to treat them as separators in this
context.)
Now we see the promising start of a table structure, with geography and time span still in column A, but with “Total number of deaths” and subsequent text clearly aligned in a separate column.

Figure 6: The newly tab-delimited version of the data shown in LibreOffice Calc
Do you have any instances that moved over into a third column or beyond? In that case you may inadvertently have put in too many tabs. In the structure we have right now we don’t expect to ever see two tab characters in a row. Back in LibreOffice Writer we can check for this and fix the problem by searching for
\t\t and replacing with \t
repeating as needed until no more double-tabs are found.
Sometimes multiple applications of a replacement pattern introduce additional changes after the first, which may or may not be what we intend, and sometimes multiple applications will have no effect beyond the first application. It is worth keeping this distinction in mind while working with regular expressions.
The general idea of regular expressions
Before doing any more practical work with the file, this is a good time for a brief introduction to regular expressions. Regular expressions (or “regexes” for short) are a way of defining patterns that can apply to sequences of things. They have the funny name that they do because of their origins in computer science and formal language theory, and they are incorporated into most general programming languages.
Regexes are also often available in some form in advanced word processors, providing a more powerful means of find-and-replace than matching exact sequences letter by letter. There are different syntaxes and implementations of regular expressions, and what we have available in word processing programs often isn’t as extensive, robust, or in conformance with wider practice as what one finds in programming language contexts, but there are essential common principles. LibreOffice for the most part follows notational conventions that you will see in other contexts. If you use a proprietary word processor you will likely find similar functionality even if the notation differs.
A b 1 |
literals — letters, digits, and spaces match themselves |
[Ab1] |
a character class, matching one instance of any of A, b, or 1 in this case |
[a-z] |
all lowercase letters within a range |
[0-9] |
all digits |
. |
any character |
* |
zero or more |
+ |
one or more |
( ) |
if contents within parentheses match, define a group for future reference |
$1 |
refer to a matched group (this is the notation in LibreOffice; other notations such as \1 are sometimes used elsewhere) |
\t |
tab |
^ |
beginning of line |
$ |
end of line |
For a more complete list of regular expressions in LibreOffice, see their List of Regular Expressions.
Applying regular expressions
Let’s start to use some of these to remove the page headings with date and page number. Switch back to your LibreOffice Writer window.
Replace: ^.*February 21.*1908.*$ with nothing (4 matches).
Replace ^.*Received out of regular order.*$ with nothing (2
matches).
Here ^ (caret) matches the beginning of the line, . (period) matches
any character, .* (period-asterisk) matches any sequence of zero or
more characters, and $ (dollar-sign) matches the end of the line. By
spelling out the date, we will match only the lines where that sequence
appears, letter by letter, and by using .* at both ends we match all
lines with that sequence regardless of what else is before or after it
on the line. After making this replacement, we will be left with some
blank lines.
To remove the blank lines in LibreOffice,
Replace ^$ with nothing (5 matches).
(In other regular expression environments, other techniques for working with line endings will be necessary; some may be more convenient than what LibreOffice offers, but this will work now for our purposes.)
Some records list a state, some a city with the state implicit, some a state and city together. The text does not have enough structure to give us a reliable way of distinguishing the California and Oakland records so that we will be able automatically to put California in a state column and Oakland in a city column. We will eventually need to do some editing by hand, drawing on our own knowledge. But there is a lot of consistency in the references to spans of time. We can use those references to develop structures that will help keep similar segments aligned across rows.
For convenience, let’s put some markers in the text that won’t be confused with anything already present. We can easily distinguish these markers from existing text, and easily remove them later when we don’t need them. Let’s match time span references and put “<t>” at the beginning of them and “</t>” at the end, with the mnemonic “t” for time. We could put a more verbose marker in, like “<time>” or a more meaningless and untidy-looking one, like “asdfJKL;” as long as that sequence wasn’t for some reason already in our text. But in this exercise we will use markers like “<t>” If you have seen HTML or XML, these look a lot like the tags that mark elements. We are not creating acceptable HTML or well-formed XML by doing this, and we will remove these markers quickly, but there is a resemblance.
Obligatory warning: Regular expressions are powerful, but they do have their limits and (when used to modify material that someone cares about) they can be dangerous, in that a mistake can inadvertently remove or scramble a lot of information quickly. Also, as XML aficionados may passionately tell you, regular expressions are not up to the job of general-purpose parsing of XML. After one sees how useful regular expressions are at dealing with certain kinds of patterns, there is a temptation to think, whenever we see a pattern that a computer ought to be able to help with, that regular expressions are all we need. In many cases that will turn out not to be true. Regular expressions are not adequate to deal with hierarchically nested patterns that XML is good at describing.
But that’s OK. In the context of this tutorial, we don’t claim to know anything in particular about XML, or to care about formal language grammars. We just want to put some convenient markers into a text in order to get some leverage in making a relatively simple implicit structure a bit more explicit, and we will take those markers out before we are done. There is a reason why such markers are useful. If you find yourself intrigued by what can be done with patterns in this exercise, you may want to learn more about HTML and XML, and learn what can be done with appropriate methods that their more explicit structure makes possible.
Defining segments
The next few patterns will rapidly get more complicated. If you slow down to consult the reference to how the symbols define patterns, however, the patterns should start to make sense.
Geographic references in our text are followed by emdashes (dashes that are roughly the width of the letter ‘m’; wider than endashes.) We can replace these with tab characters, which will effectively help us put states and cities in separate columns of the spreadsheet.
Replace [ ]?—[ ]?
with \t
You should have 42 matches. (One easy way to get the emdash into your pattern is to copy and paste from an existing emdash in the text itself. The square brackets aren’t entirely necessary here, but help make visible the fact that we are matching a blank space — optionally matching it, thanks to the question mark. That means our pattern will accept an emdash with or without a space on either or both sides of it.)
Now we will look for explicit references to time and wrap them in
“<t>” and “</t>” markers before and after. Once we have those
markers they will provide some scaffolding on which we can build further
patterns. Note that in the next pattern we want to be sure to apply the
replacement just once, otherwise some time references may be repeatedly
wrapped. It will be most efficient to use Replace All just once for
each wrapping pattern.
Replace (Month of [A-Z][a-z, 0-9]+ 19[0-9][0-9].)
with <t>$1</t>
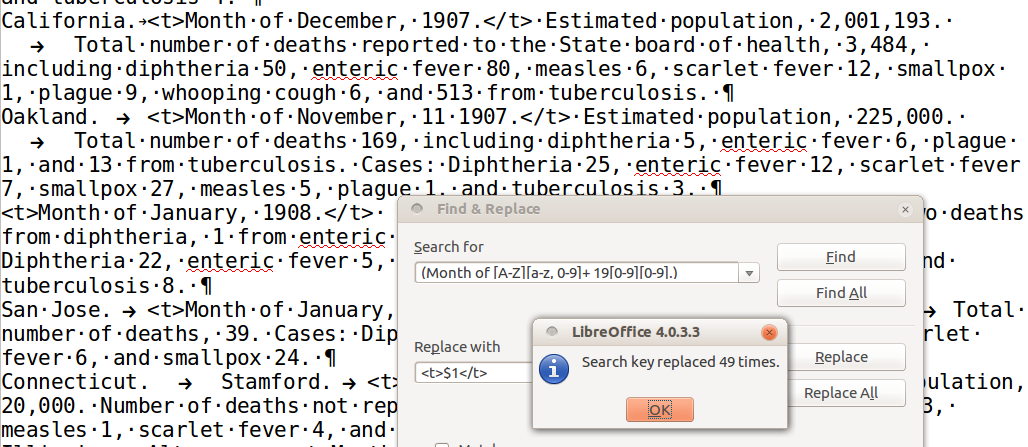
Figure 7: Finding time using Regular Expressions
Here we are using parentheses to define everything that we match in the search pattern as a single group, and in the replacement pattern we use $1 to simply repeat that match, with a few additional characters before and after it.
In addition to months, we need to match quarterly reports with a similar approach:
Replace ([-A-Za-z ]+ ended [A-Z][a-z, 0-9]+ 19[0-9][0-9].)
with <t>$1</t>
You should have 7 more matches. It looks like we have references to time accounted for. Extending this strategy to other kinds of information here, let’s use “<p>” for population estimates, “<N>” for total number of deaths, and “<c>” for the word “Cases,” which separates mortality from morbidity. (If you are familiar with HTML or XML, you may recognize “<p>” as a paragraph marker. We’re not using it in the same way here.)
Here are some patterns to wrap each of those kinds of information, all using the same strategy we just used:
Replace (Estimated population, [0-9,]+.)
with <p>$1</p> (34 matches).
Replace (Total number of deaths[A-Za-z ,]* [0-9,]+)
with <N>$1</N> (48 matches).
Replace (Cases ?:)
with <c>$1</c> (49 matches).
This next part is a little trickier. It would be great if we could get hold of the disease (let’s use “<d>”) and count (“<n>”) segments. Because the prose in this document is so formulaic, especially following the indication of total number of deaths, in this case we will be able to get pretty far without having to match each disease name explicitly, one by one. First match the disease-count pair after the word “including”:
Replace </N> including ([A-Za-z ]+) ([0-9]+),
with </N> including <d>$1</d> <n>$2</n> (29 matches).
And then iteratively match disease-count pairs that appear after existing markers:
Replace > ([A-Za-z ]+) ([0-9]+)([.,])
with > <d>$1</d> <n>$2</n>
Note that we are getting rid of commas after the disease counts by ignoring the third match in our replacement.
Repeat this replacement as many times as necessary until there are no further matches. It should take you seven iterations.
Our patterns have not done anything with phrases like ‘and 3 from tuberculosis.’ We can match those phrases and reverse the order so that the disease name appears before the count:
Replace and ([0-9])+ from ([a-z ]+)
with <d>$2</d> <n>$1</n> (32 matches).
It looks like our markers are now capturing a lot of the semantic structure that we are interested in. Now let’s copy and paste (“paste special … unformatted”) into LibreOffice Calc to see how close we are to getting a table. We are successfully separating location data into cells, but the cells are not aligned vertically yet. We want to get all of the time references into the third column.
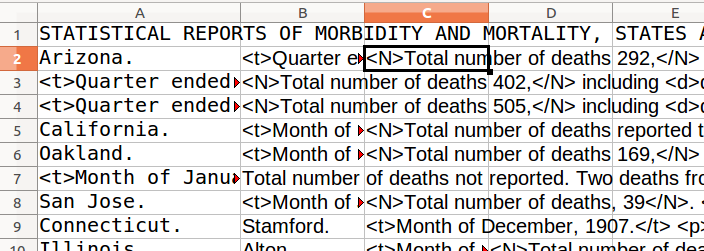
Figure 8: Measuring progress using LibreOffice Calc
The instances with two columns of location information should already be OK. The rows with one location need an extra column. Most are cities, so we will put the locations into the second column, and in a few instances we will need to move state names back to the first column by hand. Go back to your LibreOffice Writer window and:
Replace ^([A-Za-z .]+\t<t>)
with \t$1 (30 matches).
Now fix the cases with no location information, where the location is implicitly the same as the row above, and the time span is different.
Replace ^<t>
with \t\t<t> (19 matches)

Figure 9: Further refining the results
The first few columns should look better after pasting this again into Calc. The Writer text is still our working copy, so if you want to fix up the state names, you could do so now in Writer by deleting the tab character before a state name and introducing a new tab character after it. Or you could wait until we are done with our work in Writer, and fix them in Calc after we are ready for that to be our live working copy. But we are not there yet.
We need to decide how to handle the lists of diseases. The rows have different lists of varying lengths. While it would be easy enough now to insert tab characters to put each disease and mortality or morbidity count into a separate column, the columns would not be that helpful. Diseases and tallies would not be vertically aligned. What we can do instead is make a new row for each disease. The reports distinguish between mortality counts and morbidity counts, which are already conveniently separated by “Cases:”. (There is one case, Indiana, where the text marks this section with the word “Morbidity”. Our searching patterns missed this. You can fix the markup there by hand now, if you like, or ignore it since this is an exercise. It’s a good example of how automated tools aren’t a full substitute for editing or looking at your sources, and it won’t be the last such example.)
We can start by making a new row for “cases” lists, so that we can handle them separately. Head back to LibreOffice Writer.

Figure 10: Making a new row for ‘cases’
Replace ^(.*\t)(.*\t)(<t>.*</t>)(.*)(<c>.*)
with $1$2$3$4\n$1$2$3\t$5 (47 matches).
One thing to notice here is that we are using some of the replacement patterns twice. We are matching the three fields up to the time reference, then matching everything before “<c>” in a fourth group, and everything from “<c>” on in a fifth. In the replacement pattern, we put groups 1-4 back in order, then introduce a newline and print groups 1-3 again, followed by a tab and group 5. We’ve effectively moved the case listings to their own lines, and copied the place and time fields verbatim.
Let’s go further, and split all the case lists into separate rows:
Replace ^(.*\t)(.*\t)(<t>.*</t>)(.*<c>.*)(<d>.*</d>) (<n>.*</n>)
with $1$2$3$4\n$1$2$3\tCases\t$5$6
and repeat as many times as necessary until there are no more replacements (seven iterations).
Now similarly split all the mortality lists into separate rows:
Replace ^(.*\t)(.*\t)(<t>.*</t>)(.*<N>.*)(<d>.*</d>) (<n>.*</n>)
with $1$2$3$4\n$1$2$3\tDeaths\t$5$6
and repeat as many times as necessary until there are no more replacements (eight iterations).
This is getting very close now to a tabular structure, as you can see if you paste again into Calc, though if you want to wait just a bit, some cleanup work with short and simple patterns will get us most of the rest of the way:
Replace .*</c> $ with nothing
Replace ^$ with nothing
Replace <n>
with \t
Replace </n> with nothing
Replace <d>and
with <d>
Replace </?[tdp]> with nothing
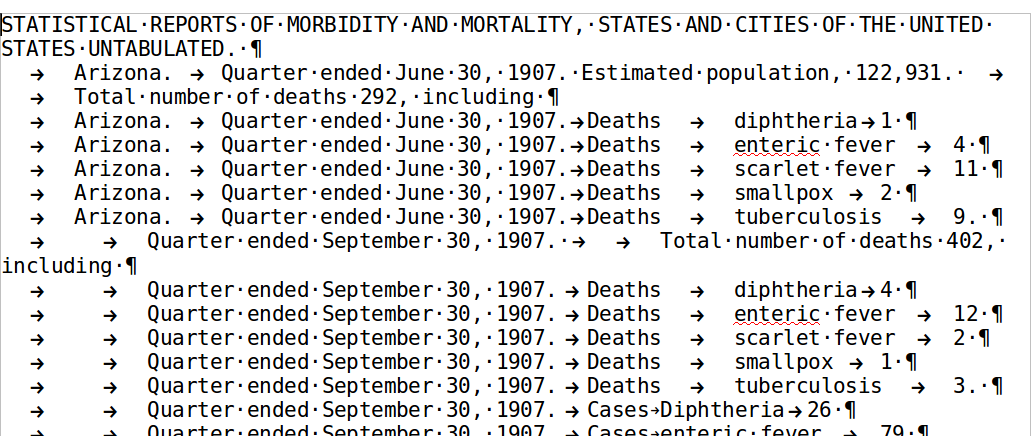
Figure 11: The final view in LibreOffice Writer
Now copy and paste this into Calc, and you should see a (mostly) well-structured table.
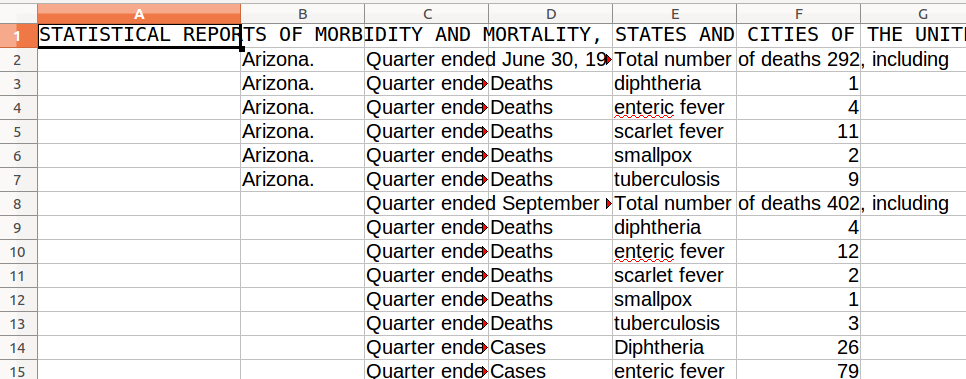
Figure 12: The final view in LibreOffice Calc
If this were not an exercise but a source we were editing for research or publication, there are still things that we would need to fix. We didn’t do anything with estimated population figures. Our pattern-matching wasn’t sophisticated enough to manage everything. In lines that didn’t have patterns like “Total number of deaths 292, including,” we missed all subsequent patterns that assumed we had already put in an “</N>” marker.
Next possibilities
Some of these problems could be fixed by additional pattern-matching steps, some by hand-editing of the source document at particular points along the way, and some by later editing of the data in spreadsheet or similar tabular form.
We might want to consider other structures for the table, too — perhaps mortality and morbidity would be more convenient to tally if they were in different columns. Word processors are not the best tools for making use of these kinds of structures. Spreadsheets, XML, and programmatic tools for working with data are much more likely to be helpful. But word processors do have advanced find-and-replace functions that are good to get to know. Regular expressions and advanced pattern matching can be helpful in editing, and can provide a bridge between sequences with implicit structure and more explicit structures that we may want to match or create.
There are more than 400 public health reports like this one available from the Internet Archive. If we wanted to tabulate all of them, LibreOffice would not be the best primary tool. It would be better to learn a little Python, Ruby, or shell scripting. Programmer-oriented plain text editors, including classic ones such as Emacs and Vi or Vim, have great regular expression support as well as other features useful for dealing with plain text in a programmatic way. If you are comfortable opening up a Unix-like shell command line (in Mac or Linux, or on Windows through a virtual machine or the Cygwin environment), you can learn and use regular expressions very well with tools like “grep” for searching and “sed” for line-oriented replacing.
Regular expressions can be immensely useful in dealing with patterns across hundreds of files at once. The patterns we have used in this example would need to be refined and extended to deal with assumptions that are certain to be mistaken when applied to longer texts or larger sets of texts, but with a programming language we could record what we are doing in a short script, and refine and rerun it repeatedly to get closer to what we want.
To learn more
The Wikipedia page on regular expressions is a useful place to find a brief history of regular expressions and their relation to formal language theory, as well as an overview of syntactic variants and formal standardization efforts.
The documentation for whatever tools you use will be invaluable for practical use, especially for work in word processing environments where regular expression implementations may be especially idiosyncratic. There are many resources available to learn how to use regular expressions in programming contexts; which is best for you may depend on what programming language is most familiar or convenient to start with.
There are a number of freely available web-based regular expression editors. Rubular, built on the Ruby programming language, has a helpful interface that lets you test regular expressions against a sample text and dynamically shows matches and matched groups. David Birnbaum, Chair of the Department of Slavic Languages and Literatures at the University of Pittsburg, has some good materials on how to work with regular expressions and XML tools to help mark up plain-text files in TEI XML.