
Contenus
- Objectifs de la leçon
- Les expressions régulières : pour qui, pour quoi ?
- Récupérer le texte
- Usage ordinaire de la fonction Rechercher & remplacer
- Trouver une structure pour les lignes
- Trouver une structure pour les colonnes
- L’idée générale des expressions régulières
- Appliquer les expressions régulières
- Définir les segments
- Quelques pistes supplémentaires
- Pour en apprendre plus
Objectifs de la leçon
Dans cet exercice, nous utiliserons les fonctionnalités avancées de l’outil “rechercher-remplacer” d’un traitement de texte afin de tirer profit de la structure implicite d’un court document historique, ce dernier étant essentiellement un tableau en forme de prose. Sans pour autant utiliser un langage de programmation, nous allons toutefois mobiliser des techniques de la pensée computationnelle, notamment la recherche par motif. Elle peut être utile à des historien(ne)s, comme à d’autres, qui utilisent des traitements de texte et peut constituer une base pour approfondir la question dans des environnements de développement intégrés (Integrated Development Environment - IDE).
Nous partirons de quelque chose qui ressemble à ceci:
Arizona. — Quarter ended June 30, 1907. Estimated population,
122,931. Total number of deaths 292, including diphtheria 1, enteric
fever 4, scarlet fever 11, smallpox 2, and 49 from tuberculosis.
Et nous utiliserons la recherche par motif pour arriver à quelque chose qui ressemble à ceci:
| Arizona. | Quarter ended June 30, 1907. | Deaths | diphtheria | 1 |
| Arizona. | Quarter ended June 30, 1907. | Deaths | enteric fever | 4 |
| Arizona. | Quarter ended June 30, 1907. | Deaths | scarlet fever | 11 |
| Arizona. | Quarter ended June 30, 1907. | Deaths | smallpox | 2 |
| Arizona. | Quarter ended June 30, 1907. | Deaths | tuberculosis | 49 |
Les expressions régulières : pour qui, pour quoi ?
Peut-être n’êtes-vous pas encore sûr(e) de vouloir faire partie des historien(ne)s qui programment, et vous voulez simplement travailler plus efficacement avec vos sources. Les historien(ne)s, les bibliothécaires et d’autres spécialistes des sciences humaines et sociales travaillent souvent avec des sources textuelles dont la structure est implicite. Il n’est pas non plus rare en sciences humaines d’avoir à faire un travail fastidieux avec le texte des notes semi-structurées et des références bibliographiques. Dans ce cas, il peut être utile de connaître l’option de recherche par motif.
Un exemple simple : si vous voulez trouver dans un document une référence à une année précise, disons 1857, il est facile de chercher uniquement cette date. Par contre, si on veut trouver toutes les références à des années de la deuxième moitié du XIXe siècle, chercher plusieurs dizaines de dates à la suite n’est pas pratique du tout. En utilisant les expressions régulières, on peut faire appel à un motif concis comme “18[5-9][0-9]” pour trouver efficacement n’importe quelle année entre 1850 et 1899.
Pour cet exercice, nous utilisons LibreOffice Writer et LibreOffice Calc, des logiciels de bureautique libres, utilisés respectivement pour le traitement de texte et les feuilles de calcul. Les paquets d’installation pour Linux, Mac ou Windows peuvent être téléchargés depuis http://www.libreoffice.org/download. D’autre logiciels de traitement de texte et même des langages de programmation ont des fonctionalités similaires de recherche de motifs. Comme sa distribution est libre et comme sa syntaxe pour les expressions régulières est proche de ce qu’on trouve dans les environnements de programmation, nous utilisons Libre Office plutôt que Microsoft Office. Toutefois, si vous terminez cet exercice et trouvez les expressions régulières utiles, il sera facile d’adapter ce que vous aurez appris ici à d’autres contextes logiciels.
Nous commençons avec des motifs simples, mais nous allons rapidement arriver à des structures plus complexes voire intimidantes. Le but ici est de présenter ce qu’il est utile de mettre en place avec un exemple concret. Nous n’allons pas nous attarder sur des exemples bidons servant uniquement à illustrer les principes de base. Si vous faites cette leçon rapidement, vous devriez pouvoir reproduire les exemples par copier-coller des motifs proposés, sans nécessairement suivre tous les détails. Cela vous donnera une idée générale de ce qui est possible. Si le résultat est prometteur, vous relirez une deuxième fois pour décider quels détails sont utiles pour votre travail. Ceci étant dit tout taper soi-même est la meilleure façon de s’approprier le texte.
Récupérer le texte

Figure 1: Capture d’écran du texte non structuré
Internet Archive conserve des copies de centaines de rapports de santé publique américains du début du XXe siècle tombés dans le domaine public. Ils ont été numérisés via JSTOR et sont rangés sous le titre “Early Journal Content”. Ils sont d’une bonne longueur pour notre exercice et sont représentatifs de différents types de ressources textuelles utilisées pour toutes sortes de recherche en histoire. Pour notre exercice, nous allons utiliser un rapport de cinq pages contenant des statistiques mensuelles sur la morbidité et la mortalité dans les États et les villes des États-Unis, publié en février 1908. Il est disponible ici : http://archive.org/details/jstor-4560629/.
Prenez un moment pour parcourir brièvement les pages du document grâce au lien pour lire en ligne, afin de vous familiariser avec lui. Ce document est organisé en paragraphes plutôt qu’en tableaux. Mais on voit bien que sa structure sous-jacente peut nous aider à présenter les données sous forme de tableau. Presque tous les paragraphes du rapport commencent par des informations géographiques, précisent une période pour les statistiques, incluent éventuellement une estimation de la population, et ensuite, font le compte des morts et des cas de maladie non mortelles.
L’interface de consultation des pages nous montre à quoi ressemblait le document original. Si nous voulons manipuler les chiffres et rendre possible les comparaisons et les calculs en utilisant l’information géographique, nous aurons besoin de travailler sur le document sous forme de texte et de chiffres, au lieu de travailler avec l’image. En plus d’offrir plusieurs formats d’images à télécharger, Internet Archive met à disposition des versions en texte brut créées au moyen de logiciels de reconnaissance optique de caractères (Optical Character Recognition - OCR). La reconnaissance optique de caractères est souvent imparfaite sur les textes anciens, mais ce qu’elle produit est déjà plus utile que des images. En effet, ce texte peut être fouillé, copié et modifié.
Passez à l’affichage en texte intégral. Nous partirons de cette base, en ignorant la dernière partie du rapport précédent. Dans un nouveau document LibreOffice, copiez le texte depuis “STATISTICAL REPORTS…” jusqu’à la fin. Lorsque vous travaillez avec des données importantes, assurez-vous d’en sauvegarder une copie dans un endroit séparé de votre copie de travail. Cela vous permettra de revenir vers l’original si quelque chose ne se passe pas comme prévu.
Usage ordinaire de la fonction Rechercher & remplacer
Nous pouvons voir quelques erreurs de reconnaissance de caractères (là où le logiciel de transcription automatique d’Internet Archive a fait des erreurs) même si globalement, cela semble être une bonne transcription. Il y a deux endroits où l’OCR a inséré par erreur des guillemets doubles dans ce fichier, dans les deux cas en les ajoutant entre la virgule qui sépare le nom d’un mois d’une séquence de quatre chiffres représentant une année, comme dans :
December," 1907.
Nous pouvons les trouver en faisant une recherche (Edition → Rechercher avec le
raccourci Ctrl-F ou Cmd-F sur un Mac) portant sur les guillemets doubles. Il
faut ensuite confirmer que ce sont les deux seules instances de guillemets dans
le fichier. Dans le cas présent, nous pouvons simplement les supprimer. Plutôt
que de le faire à la main, essayons d’utiliser la fonction de recherche et de
remplacement de LibreOffice (Ctrl-H ou Cmd-Alt-F sur Mac).
Remplacez " par rien.
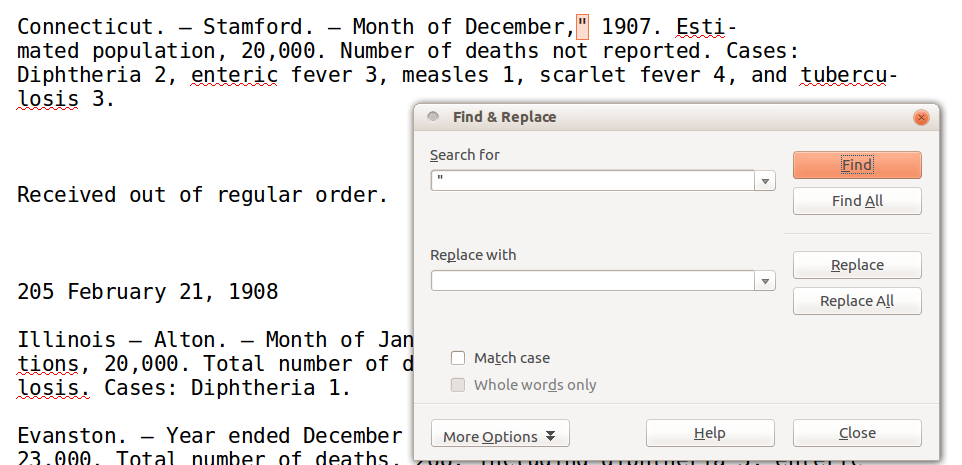
Figure 2: Capture d’écran de l’option Rechercher & remplacer
Trouver une structure pour les lignes
Nous ne faisons que commencer, mais pour estimer jusqu’où nous devons aller,
sélectionnez tout le texte dans LibreOffice Writer (Ctrl-A) et collez-le dans
LibreOffice Calc (Fichier → Nouveau → Feuille de calcul). Chaque ligne de
texte devient une rangée à une colonne dans la feuille de calcul. Ce que nous
aimerions, c’est que chaque ligne du tableau représente un enregistrement
structuré dans une forme cohérente. Il serait fastidieux de construire un tel
tableau manuellement. Dans ce qui suit, nous allons réaliser cette tâche avec
des expressions régulières dans Writer, mais gardez Calc ouvert à
l’arrière-plan : nous y retournerons pour y coller nos futures modifications et
jauger nos progrès.
De retour dans Writer, nous voulons nous débarrasser des sauts de ligne dont nous n’avons pas besoin. Il y a cependant quelques traits d’union en fin de ligne que nous devrions nettoyer en premier. Cette fois-ci, nous allons commencer à utiliser des expressions régulières. Attention, leurs implémentations diffèrent dans la manière de gérer les retours à la ligne, bien plus que dans leur mise en oeuvre.
Les expressions régulières dans Libre Office ne permettent pas de rechercher
des motifs s’étalant sur plusieurs lignes. Nous adoptons donc une stratégie
indirecte. Nous allons d’abord remplacer les sauts de ligne par un caractère de
remplacement - disons # - qui n’apparaît pas ailleurs dans notre texte.
Dans la boîte de dialogue de l’outil “Rechercher & remplacer”, activez “Plus
d’options” (“Autres options” sur Mac) et assurez-vous que l’option
expressions régulières est cochée. Ceci nous permet désormais d’utiliser des
symboles spéciaux pour définir des motifs généraux que nous cherchons.
En utilisant Rechercher & remplacer, remplacez $ par #.
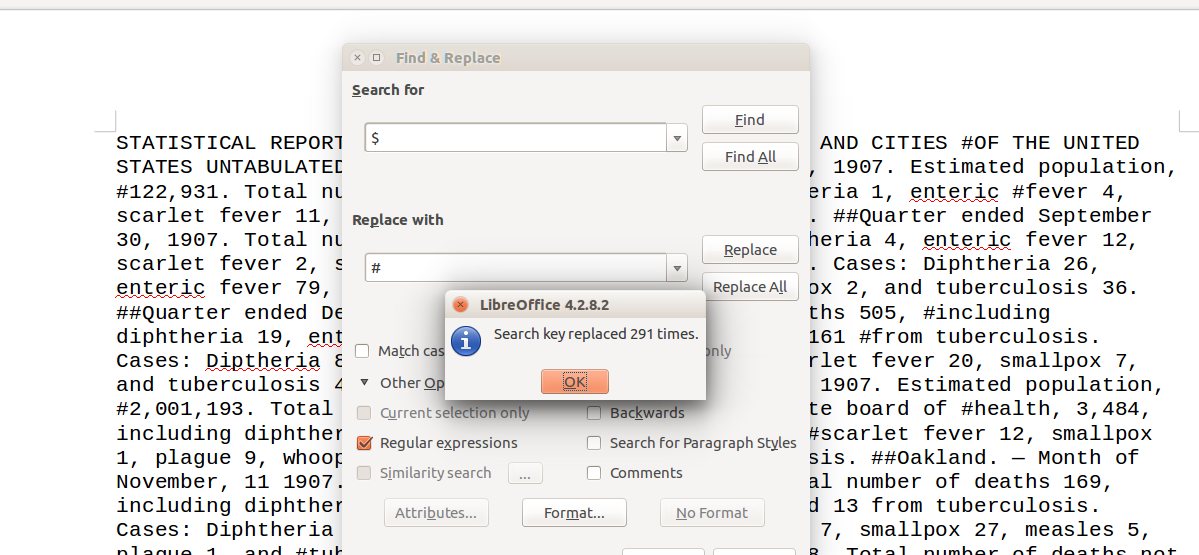
Figure 3: L’onglet « Autres options » dans la fenêtre Rechercher & remplacer d’Open Office
Le symbole du dollar est un symbole spécial qui correspond habituellement à la
fin de chaque ligne afin d’ancrer un motif plus grand. Cependant, même s’il
peut avoir cette fonction dans LibreOffice dans des modèles plus larges,
LibreOffice ne nous permettra pas de trouver une portion de texte qui s’étend
de part et d’autre d’un saut de ligne. En revanche, avec LibreOffice nous
pouvons utiliser le caractère $ seul, sans autre motif, afin de trouver les
sauts de ligne indépendamment des autres caractères et les remplacer.
Pour réaliser une opération de type “Rechercher & remplacer”, vous pouvez
commencer par cliquer sur “Rechercher” puis sur “Remplacer” lorsque vous
constatez que la portion sélectionnée correspond à vos attentes. Après l’avoir
répété plusieurs fois, vous pouvez cliquer sur “Tout remplacer” pour remplacer
tout le reste en une seule fois. Si vous faites une erreur ou en cas de doute,
vous pouvez annuler les étapes récentes avec Editer → Annuler dans la barre
de menu, ou le raccourci clavier Ctrl+Z (Cmd+Z sur Mac).
Dans ce document, le remplacement des fins de ligne entraîne 249 modifications
(ce nombre peut varier légèrement selon la quantité de texte que vous avez
copié). Cette séquence de remplacements rendra le texte moins lisible
temporairement, mais c’est nécessaire car nous ne pouvons pas transformer une
sélection qui s’étend de part et d’autre d’un saut de ligne. En revanche, nous
pouvons le faire de part et d’autre d’un caractère #.
A présent, supprimons les traits d’union. Cela peut désormais se faire à l’aide d’un remplacement littéral, sans utiliser d’expression régulière.
En utilisant encore “Rechercher & remplacer”, remplacez tous les - #
(tiret-espace-dièse) par rien.
Cela supprimera les traits d’union comme dans “tuber- #culosis” en “tuberculosis” en une seule ligne, avec un total de 27 remplacements dans notre cas.
Ensuite, remplacez tous les ## par \n (71 occurrences).
Dans cette étape, nous prenons ce qui était à l’origine des sauts de
paragraphe, marqués par 2 sauts de ligne, suivis d’un dièse doublé (##), et
nous les transformons à nouveau en sauts de ligne simples. Dans le tableau,
ils marqueront le début d’une nouvelle ligne.
Pour finir notre travail sur les sauts de lignes, remplacez tous les # par
` ` (un espace simple). Cela nous débarrasse de 122 sauts de lignes qui
n’étaient pas des sauts de paragraphes dans le texte original.
Ce n’est peut-être pas clair au premier abord, mais nous avons transformé
chaque paragraphe logique en une seule ligne. Dans LibreOffice (et dans les
éditeurs de texte similaires), vous pouvez activer l’affichage des caractères
non imprimables (en utilisant Ctrl-F10 sur Windows ou Linux) pour voir les
lignes et les sauts de paragraphes.

Figure 4: Caractères non imprimables dans LibreOffice
Une dernière manière de confirmer que nous commençons à obtenir une structure plus pratique: copions à nouveau tout le texte de Writer et collons-le dans une nouvelle feuille de calcul. Ceci devrait confirmer que chaque fiche de santé correspond maintenant à une ligne distincte dans le tableau, même si nous avons encore les en-têtes de page et les notes de bas de page mélangées au milieu de tout cela. Nous allons les nettoyer bientôt.
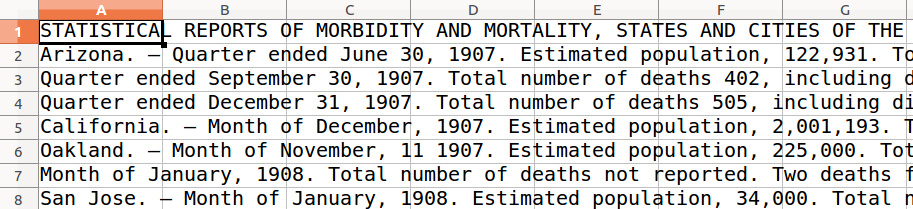
Figure 5: La structure améliorée, affichée dans LibreOffice Calc
Trouver une structure pour les colonnes
Les feuilles de calcul organisent l’information en deux dimensions, lignes et colonnes. Nous avons vu que les lignes dans Writer correspondent aux lignes dans Calc. Comment ajouter des colonnes ?
Les tableurs peuvent lire et écrire des fichiers de données en format texte brut, en suivant l’une ou l’autre de diverses conventions pour représenter le passage d’une colonne à la suivante. Un format très commun utilise la virgule pour séparer les colonnes, et de tels fichiers sont souvent stockés avec l’extension “.csv” pour “comma-separated values” (valeurs séparées par des virgules). Un autre format courant utilise la tabulation, un type d’espace spécial, pour séparer les colonnes. Comme notre texte contient des virgules et pour éviter toute confusion, nous utiliserons un caractère de tabulation pour séparer les colonnes. Même si l’on peut sauvegarder un fichier de texte brut en guise d’intermédiaire, dans cet exercice nous supposerons que nous copions et collons directement de Writer à Calc.
De retour dans Writer, commençons à diviser nos données en colonnes en séparant
les informations temporelles et géographiques des chiffres rapportés. Presque
tous les rapports contiennent les mots Total number of deaths. Cherchez cette
expression et remplacez-la par exactement la même phrase, mais avec “\t” au
début de la chaîne de caractères (\t représentant un caractère de
tabulation) :
\tNombre total de décès
Après avoir fait ce remplacement (53 occurrences), sélectionnez tout le texte et copiez-collez-le à nouveau dans une feuille de calcul vide.
On dirait que rien n’a changé, LibreOffice Calc met le texte complet de chaque
paragraphe dans une seule cellule, tabulations comprises. Nous devons forcer le
logiciel à interpréter le texte pour que Calc nous demande comment traiter les
tabulations. Essayons encore une fois. Vous pouvez vider la feuille de calcul
rapidement en sélectionnant tout (Ctrl-A) et en supprimant la sélection.
Dans une feuille de calcul vide, sélectionnez Edition → Collage spécial (ou
faites un clic droit pour y accéder), puis sélectionnez “Texte non formaté”
dans les options de la fenêtre qui apparaît. Cela devrait ouvrir une fenêtre
“Import de texte”. Assurez-vous que la case “Tabulation” est cochée sous
“Options de séparateur”, puis cliquez sur “OK”. (Avant de cliquer sur OK, vous
pouvez cocher et décocher les options “Virgule” ou “Espace” comme séparateurs
pour prévisualiser ce qu’il se passerait ici, même si nous ne voulons pas les
traiter comme séparateurs dans ce contexte).
Nous voyons maintenant le début prometteur d’une structure de tableau, avec les informations géographiques et l’intervalle de temps toujours dans la colonne A, mais avec le “nombre total de décès” et le texte suivant clairement alignés dans une colonne séparée.

Figure 6 : La nouvelle version des données délimitée par les tabulations, affichée dans LibreOffice Calc
Si dans certains cas le texte s’étend dans une troisième colonne ou au-delà, il
se peut que vous ayez, par inadvertance, mis trop de tabulations. Dans la
structure que nous avons actuellement, nous ne nous attendons pas à voir deux
tabulations à la suite. Retournez dans LibreOffice Writer, où vous pouvez
vérifier cela et résoudre le problème en recherchant \t\tet en les remplaçant
par \t, en répétant au besoin jusqu’à ce qu’il n’y ait plus de
double-tabulation.
Parfois, appliquer plusieurs fois le remplacement d’un motif introduit des changements supplémentaires qui peuvent être ou non intentionnels. D’autres fois, répéter le remplacement n’aura aucun effet après la première application. Cela vaut la peine de garder cette distinction à l’esprit quand on travaille avec des expressions régulières.
L’idée générale des expressions régulières
Avant de reprendre les manipulations sur le fichier, c’est le moment de faire une courte introduction aux expressions régulières. Les expressions régulières (ou “regex” pour faire court) sont une façon de définir un motif qui peut s’appliquer à une séquence d’éléments. Elles ont ce nom rigolo en raison de leurs origines dans le monde de l’informatique et des langages formels théoriques et elles sont incorporées à la plupart des langages de programmation généraux.
Les regex sont souvent accessibles sous une forme ou une autre dans les logiciels de traitement de texte avancés, nous procurant ainsi une option “rechercher et remplacer” plus puissante que le simple remplacement d’une séquence exacte, lettre par lettre. Il existe différentes syntaxes et différentes implémentations des expressions régulières. Ce dont on peut disposer dans un logiciel de traitement de texte est souvent moins poussé, moins robuste et moins conforme à la pratique la plus courante que ce que l’on peut trouver dans le contexte d’un langage de programmation. Il y a cependant des principes essentiels communs.
A b 1 |
Littéral - les lettres, les chiffres et les espaces sont représentés par eux-mêmes |
[Ab1] |
Une classe de caractères, on sélectionne alors A ou b ou 1 dans ce cas-là |
[a-z] |
Toutes les minuscules, dans un intervalle donné |
[0-9] |
Tous les chiffres |
. |
N’importe quel caractère |
* |
Zéro ou plus |
() |
Si le contenu entre parenthèses correspond, cela définit un groupe auquel il sera possible de faire référence par la suite |
$1 |
Fait référence à un groupe sélectioné auparavant (Ceci est la notation utilisée par LibreOffice ; d’autres notations, telles que \1 peuvent aussi être utilisées |
\t |
Tabulation |
^ |
Début de ligne |
$ |
Fin de ligne |
Pour une liste plus complète d’expressions régulières dans LibreOffice, voir la Liste des expressions régulières.
Appliquer les expressions régulières
Commençons à en utiliser quelques-unes pour supprimer les en-têtes de pages contenant la date et le numéro de page. Revenez à votre fenêtre LibreOffice Writer.
Remplacer : ^.*February 21.*1908.*$ par rien (4 occurrences).
Remplacer : ^.*Received out of regular order..*$ par rien (2
occurrences).
Ici, ^ (accent circonflexe) correspond au début de la ligne. Le . (point)
correspond à n’importe quel caractère. Le * (astérisque) correspond à toute
séquence de zéro caractère ou plus. Enfin, $ (le symbole dollar) correspond à la
fin de la ligne. En épelant la date, nous apparierons seulement les lignes où
cette séquence apparaît, lettre par lettre, et en utilisant .* aux deux
extrémités nous apparierons toutes les lignes contenant cette séquence
indépendamment de ce qui apparaît avant ou après elle sur la ligne. Après avoir
effectué ce remplacement, il nous restera quelques lignes vierges.
Pour supprimer les lignes vides dans LibreOffice, Remplacez ^$ par
rien (5 occurrences).
Dans d’autres environnements d’expressions régulières, d’autres techniques seront nécessaires pour travailler avec les fins de lignes. Certaines peuvent être plus pratiques que ce que LibreOffice offre, mais cela suffira pour nos besoins actuels.
Certains documents mentionnent un État, d’autres une ville dont l’État est implicite, d’autres encore une ville et son État ensemble. Le texte n’est pas assez structuré pour nous donner une façon fiable de distinguer les rapports de la Californie et d’Oakland, d’une manière qui nous permette de classer automatiquement “Californie” dans une colonne “État”, et “Oakland” dans une colonne “ville”. Nous devrons à terme faire quelques éditions à la main, en nous appuyant sur nos propres connaissances. Mais les références aux périodes de temps sont très uniformes. Nous pouvons utiliser ces références pour créer des structures qui nous aideront à aligner les segments pour créer des colonnes cohérentes.
Par commodité, insérons dans le texte des marqueurs qui ne seront pas confondus avec ce qui s’y trouve déjà. Nous pouvons facilement distinguer ces marqueurs du texte existant, et les supprimer plus tard quand nous n’en avons plus besoin. Cherchons les références temporelles et mettons “<t>” au début et “</t>” à la fin, avec la mnémonique “t” pour “temps”. Nous aurions pu utiliser un marqueur plus explicite, comme “<time>” ou au contraire un marqueur non-signifiant comme “asdfJKL ;” (tant que cette suite de caractère n’existe pas déjà dans notre texte). Dans cet exercice, nous utilisons des marqueurs formés sur le modèle de “<t>”. Si vous connaissez HTML ou XML, nos marqueurs ressemblent beaucoup aux balises qui marquent les éléments de ces langages. Nous ne sommes pas en train de produire du HTML ou du XML conformes en faisant cela, et nous supprimerons ces marqueurs rapidement, mais il y a une ressemblance.
Avertissement: Les expressions régulières sont puissantes, mais elles ont leurs limites et, lorsqu’elles sont utilisées pour modifier du texte auquel vous tenez, elles peuvent être dangereuses: une erreur et vous pouvez rapidement supprimer ou altérer de nombreuses informations par inadvertance. De plus, comme quelques fans du XML pourront vous le dire avec insistance, les expressions régulières ne sont pas adaptées pour l’analyse syntaxique de fichiers XML. Après avoir vu à quel point les expressions régulières sont utiles pour traiter certains types de motifs, on est tenté de penser, chaque fois qu’on voit un motif, qu’un ordinateur devrait être capable d’aider, que les expressions régulières sont tout ce dont on a besoin. Dans de nombreux cas, cela s’avérera faux. Les expressions régulières ne sont pas adéquates pour traiter les modèles hiérarchiquement imbriqués qu’on décrit facilement en revanche avec XML.
Mais ce n’est pas grave. Dans le cadre de ce tutoriel, nous ne prétendons pas savoir quoi que ce soit sur XML, ni ne nous soucions-nous de la grammaire des langages formels. Nous voulons simplement mettre des marqueurs pratiques dans un texte pour nous aider à rendre une structure implicite relativement simple un peu plus explicite. Quand nous en aurons fini, nous retirerons ces marqueurs. Il y a une raison pour laquelle de tels marqueurs sont utiles. Si ce qui peut être fait avec les motifs dans cet exercice vous intrigue, vous voudrez sans doute en savoir davantage sur HTML et sur XML, et apprendre ce que leurs structures plus explicites permettent de faire.
Définir les segments
Les quelques modèles suivants deviendront rapidement plus compliqués. Si toutefois vous prenez le temps de regarder la documentation pour voir comment les symboles définissent les motifs, ils deviendront plus clairs.
Les références géographiques dans notre texte sont suivies de tirets longs (d’une longueur équivalente à celle de la lettre “m” mais plus long que le tiret moyen; sachant que le trait d’union n’est pas un signe de ponctuation et a une longueur différente). On peut les remplacer par des tabulations, ce qui va nous aider à mettre les États et les villes dans des colonnes séparées dans la feuille de calcul.
Remplacez [ ]?—[ ]? par \t (42 occurrences).
Une manière facile d’insérer le tiret long dans le motif de recherche est de copier-coller un des tirets longs qu’on trouve dans le texte lui-même. Les crochets ne sont pas vraiment nécessaires ici, mais ils aident à rendre visible le fait qu’on cherche un espace vide. Cela signifie que notre motif acceptera un tiret long avec ou sans espace de part et d’autre.
Maintenant nous allons chercher des références explicites au temps et nous allons les encadrer de “<t>” et “</t>”. Une fois que nous aurons ces marqueurs ils fourniront une base à partir de laquelle construire de nouveaux motifs. Notez que dans le prochain motif, nous devons nous assurer d’appliquer le remplacement une fois seulement, sinon, certaines références de temps risquent d’être encadrées plusieurs fois. Il sera donc plus efficace d’utiliser “Tout remplacer” une seule fois pour chaque modèle encadré.
Remplacez (Month of [A-Z][a-z, 0-9]+ 19[0-9][0-9].) par <t>$1</t>.
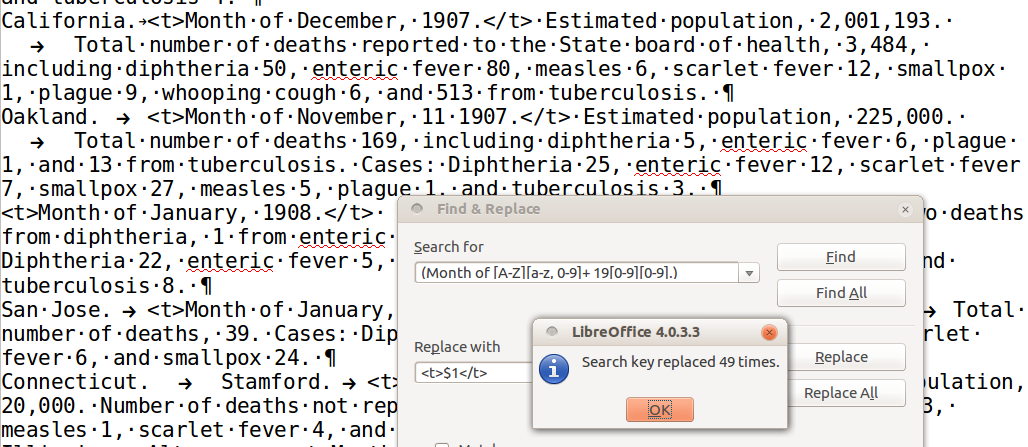
Figure 7 : Trouver les informations temporelles en utilisant les expressions régulières
Ici les parenthèses permettent de définir un groupe au sein du motif de
recherche. Ce groupe est ensuite appelé dans le motif de remplacement avec
$1. Cela permet de répéter la cible, en ajoutant au passage des caractères
supplémentaires avant et/ou après.
Nous avons besoin d’appliquer une approche similaire, cette fois-ci pour les rapports trimestriels :
Remplacer ([-A-Za-z ]+ ended [A-Z][a-z, 0-9]+ 19[0-9][0-9].) par
<t>$1</t>
Cette fois, nous en avons terminé le traitement des références temporelles.
Continuons cette stratégie pour traiter les autres types d’informations que
nous avons ici. Nous pouvons utiliser <p> pour les estimations de population,
<N> pour les nombres totaux de décès et <c>, pour “Cases” (cas) qui
est utilisé dans le texte pour séparer les informations sur la mortalité et
celles sur la morbidité. Si vous connaissez un peu HTML ou XML, il vous
semblera peut-être reconnaître “<p>”, le marqueur de paragraphe. Ici, nous ne
l’utilisons pas dans ce sens.
Voici quelques motifs pour étiqueter chaque type d’information, toujours en suivant la même stratégie :
Remplacez (Estimated population, [0-9,]+.) par <p>$1</p> (34
occurrences).
Remplacez (Total number of deaths[A-Za-z ,]* [0-9,]+) par <N>$1</N>
(48 occurrences).
Remplacez (Cases ?:) par <c>$1</c> (49 occurrences).
La partie suivante est un peu plus compliquée. Il faudrait que nous puissions
identifier les maladies (utilisons <d>, pour disease) et compter (<n>)
les segments. Comme la langue utilisée dans ce document est très standardisée,
surtout pour les passages qui concernent le décompte des morts, nous allons
pouvoir aller assez loin sans avoir à chercher chaque nom de maladie, un par
un. Tout d’abord, ciblons les paires maladie-décompte qui sont données après le
mot “including” (y compris):
Remplacez </N> including ([A-Za-z ]+) ([0-9]+), par
</N> including <d>$1</d> <n>$2</n> (29 occurences).
Ensuite, on cible de manière itérative les paires maladie-décompte qui apparaissent après nos marqueurs existants :
Remplacez > ([A-Za-z ]+) ([0-9]+)([.,]) par > <d>$1</d> <n>$2</n>
Remarquez que nous nous débarrassons des virgules après le décompte du nombre de victimes de la maladie en ne faisant pas référence au troisième groupe dans le motif de remplacement.
Répétez ce remplacement autant de fois que nécessaire, jusqu’à ce qu’il n’y ait plus aucun résultat correspondant à la recherche. Cela devrait vous prendre plusieurs itérations.
Notre motif n’a eu aucun effet sur les phrases comme “and 3 from tuberculosis” (“et 3 de la tuberculose”). Nous pouvons cibler ces phrases et changer l’ordre des élements pour que la maladie apparaisse avant le décompte :
Remplacez and ([0-9])+ from ([a-z ]+) par <d>$2</d> <n>$1</n> (32
occurrences).
Nos marqueurs contiennent désormais beaucoup de structures sémantiques qui nous
intéressent. Copions et collons (Collage spécial -> Texte non formaté) le texte
dans LibreOffice Calc afin de voir à quel point nous nous rapprochons de la
structure d’un tableau. Nous parvenons désormais à séparer les données de
localisation dans des cellules, mais ces cellules ne sont pas encore alignées
verticalement. Nous voulons placer toutes les références de temps dans la
troisième colonne.
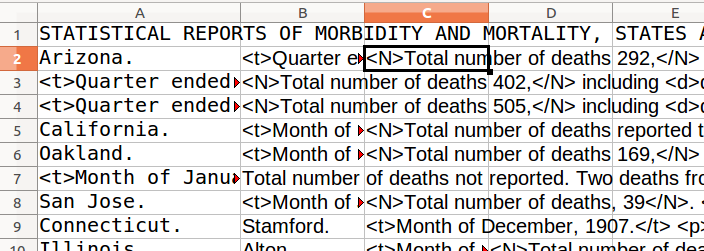
Figure 8: Mesurons nos progrès en utilisant LibreOffice Calc
Lorsque deux colonnes contiennent des informations de localisation, il n’y a pas de problème. Par contre, les lignes avec une seule colonne pour la localisation ont besoin d’être complétées. Pour la plupart, il s’agit de villes, donc nous avons besoin de déplacer manuellement le nom de l’État dans la première colonne. Retournez dans la fenêtre de LibreOffice Writer et :
Remplacez ^([A-Za-z .]+\t<t>) par \t$1 (30 occurrences).
A présent, réglez les cas qui ne contiennent aucune information sur la localisation car elle est implicitement la même que celle de la ligne précédente, mais où la période de temps est différente.
Remplacez ^<t> par \t\t<t> (19 occurrences)

Figure 9: Affinage approfondi des résultats
Les premières colonnes devraient avoir meilleure allure si vous les collez
dans Calc. Le texte dans Writer est toujours notre copie de travail, donc si
vous voulez corriger le nom des États, il vous faut le faire dans Writer en
supprimant des tabulations (\t) avant le nom de l’État et en introduisant un
nouveau caractère de tabulation après. Ou bien vous pouvez attendre que nous en
ayons fini avec notre travail dans Writer, pour corriger ces erreurs dans Calc,
une fois que nous serons prêts à en faire notre copie de travail. Mais nous
n’en sommes pas encore là !
Il nous faut décider comment gérer les listes de maladies. Les lignes contiennent des listes de longueurs variables. Même s’il serait facile à ce stade d’introduire un caractère de tabulation pour placer chaque maladie et le nombre de victimes ou de malades dans des colonnes différentes, ces colonnes ne seraient pas très pratiques. Les maladies et les décomptes ne seraient pas alignés. À la place, nous pouvons plutôt créer de nouvelles lignes pour chaque maladie. Les rapports distinguent décomptes des victimes et décomptes des malades, qui sont déjà séparés par “cases:”. (Il y a un cas, pour l’Indiana, où le texte indique cette section avec le terme “Morbidity”. Notre motif de recherche l’a manqué. Vous pouvez réparer le balisage à la main à présent, si vous le souhaitez, ou bien l’ignorer puisqu’il s’agit ici d’un exercice. C’est un bon exemple qui montre à quel point les outils d’automatisation ne constituent pas le seul et unique moyen d’éditer vos sources et ne vous empêchent pas de les regarder. Ce ne sera pas le seul exemple de ce type).
Nous pouvons commencer en créant une nouvelle ligne pour la liste des cas (“cases”), afin que nous puissions les gérer séparément. De retour dans LibreOffice Writer :

Figure 10: Création de nouvelles lignes pour les ‘cas’
Remplacez ^(.*\t)(.*\t)(<t>.*</t>)(.*)(<c>.*) par
$1$2$3$4\n$1$2$3\t$5 (47 occurrences).
Remarquez ici que nous utilisons certains des modèles de remplacement deux
fois. Nous ciblons trois groupes jusqu’à la référence temporelle, puis tout ce
qui précède <c> dans un quatrième groupe, et enfin tout ce qui se trouve
après <c> dans un cinquième. Dans le modèle de remplacement, nous remettons
les groupes 1 à 4 dans l’ordre, puis nous introduisons une nouvelle ligne et
imprimons à nouveau les groupes 1 à 3, suivis d’une tabulation et du groupe 5.
Nous avons ainsi déplacé les listes des cas sur leurs propres lignes, et avons
reproduit mot pour mot les champs lieu et temps.
Allons plus loin et séparons chaque cas listé pour le mettre dans sa propre ligne :
Remplacez ^(.*\t)(.*\t)(<t>.*</t>)(.*<c>.*)(<d>.*</d>) (<n>.*</n>)
par $1$2$3$4\n$1$2$3\tCases\t$5$6
et répétez autant de fois que nécessaire jusqu’à ce qu’il n’y ait plus de remplacement possible (7 itérations).
Maintenant, faisons de même pour séparer les listes de victimes :
Remplacez ^(.*\t)(.*\t)(<t>.*</t>)(.*<N>.*)(<d>.*</d>) (<n>.*</n>)
par $1$2$3$4\n$1$2$3\tDeaths\t$5$6
et répétez autant de fois que nécessaire jusqu’à ce qu’il n’y ait plus de remplacement possible (8 itérations).
Cela se rapproche de plus en plus d’une structure tabulaire, comme vous pouvez vous en rendre compte si vous collez à nouveau le texte dans Calc à nouveau. Encore un peu de patience toutefois: il nous faut nettoyer notre travail avec de très simples motifs de remplacement rapides à utiliser. De cette manière, le gros du travail aura été fait.
Remplacez .*</c> $ par rien
Remplacez ^$ par rien
Remplacez <n> par \t
Remplacez </n> par rien
Remplacez <d>and par <d>
Remplacez </?[tdp]> par rien
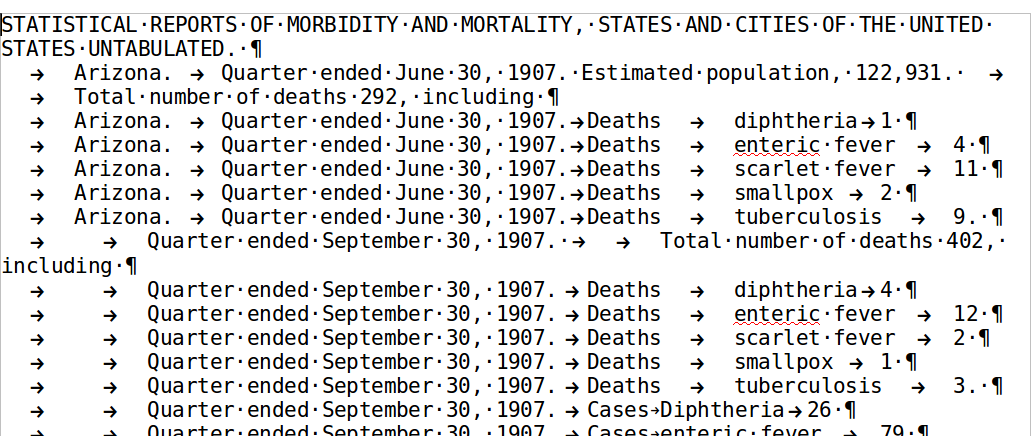
Figure 11: Vue finale dans LibreOffice Writer
Maintenant, copiez et collez tout cela dans Calc, et vous devriez obtenir un tableau relativement bien structuré.
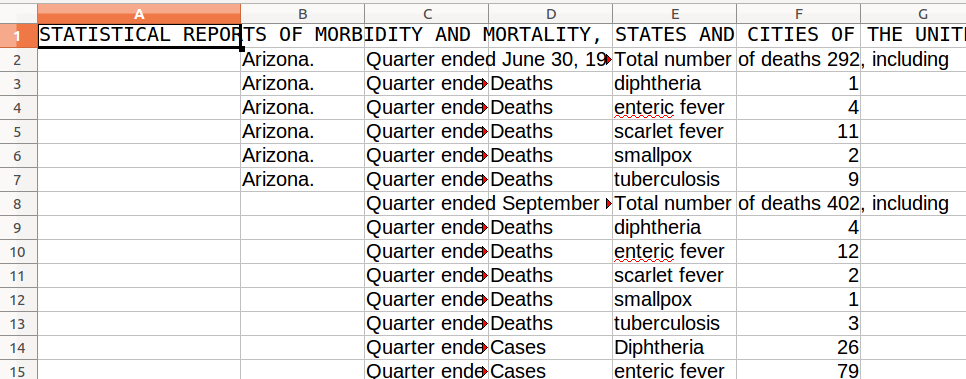
Figure 12: Vue finale dans LibreOffice Calc
Si ce n’était pas un exercice, mais une source que nous éditions pour une
publication ou pour la recherche, il resterait des choses à régler. Nous
n’avons pas traité les chiffres donnés pour les estimations de population.
Notre système de motif n’était pas assez sophistiqué pour tout gérer. Dans les
lignes qui n’avaient pas de motifs comme “Total number of deaths 292,
including”, nos motifs de recherche qui auraient nécessité l’insertion préalable d’un marqueur </N> n’ont pas pu fonctionner.
Quelques pistes supplémentaires
Certains de ces problèmes pourraient être résolus par des étapes supplémentaires de comparaison de motifs, d’autres par une édition manuelle du document entre certaines étapes de notre travail. D’autres, encore, supposeraient qu’on modifie les données en fin de parcours, une fois qu’elles sont sous une forme tabulaire.
Nous pourrions aussi envisager d’autres structures pour ce tableau. Par exemple, peut-être que la mortalité ou la morbidité seraient plus faciles à compter si elles se trouvaient dans des colonnes différentes. Les logiciels de traitement de texte ne sont pas les meilleurs outils pour utiliser ce genre de structure. Les feuilles de calcul, XML et les outils programmatiques qui servent à traiter les données sont bien plus susceptibles de correspondre à nos besoins. Mais ces mêmes logiciels ont des fonctionnalités avancées pour “rechercher & remplacer” qui sont utiles à connaître. Les expressions régulières et la recherche avancée de motifs sont très utiles pour l’édition. Elles permettent de construire des passerelles entre des séquences dont la structure est implicite et une structure plus explicite qu’on peut vouloir créer ou cibler.
Il y a plus de 400 rapports de santé publique comme celui-ci, disponibles en
ligne depuis l’Internet Archive. Si vous voulez vous amuser à toutes les
tabuler, LibreOffice n’est pas le meilleur outil de départ. Ce serait mieux
d’apprendre un peu de Python, de Ruby ou de développement de scripts pour la
ligne de commande de votre système d’exploitation. Les éditeurs de texte brut
orientés pour la programmation, y compris des classiques comme Emacs et Vi ou
Vim, supportent très bien les expressions régulières ainsi que d’autres
techniques de paramétrage utiles pour traiter le texte brut de façon
programmatique. Si vous êtes à l’aise pour ouvrir une ligne de commande de type
Unix (sous Mac ou Linux, ou sous Windows avec une machine virtuelle ou
l’environnement Cygwin), vous pouvez apprendre et très bien utiliser les
expressions régulières avec des outils comme grep pour la recherche et sed
pour le remplacement orienté-ligne (line-oriented replacing).
Les expressions régulières peuvent être extrêmement utiles quand on doit rechercher des motifs dans plusieurs centaines de documents. Les motifs employés ici reposent sur différents postulats qui pourraient s’avérer erronés s’ils étaient appliqués à des textes plus longs ou à des ensembles de textes plus longs. Cependant, avec un langage de programmation, nous pourrions enregistrer ce que nous faisons sous la forme d’un petit script, l’améliorer et le réexécuter autant de fois que nécessaire pour atteindre nos objectifs.
Pour en apprendre plus
La page Wikipedia sur les expressions régulières est un endroit utile pour trouver un bref historique des expressions régulières et de leur lien avec la théorie des langages formels. Vous y trouverez aussi un résumé des variations syntaxiques et des efforts de standardisation formelle.
Quel que soit l’outil que vous utilisez, sa documentation est importante pour les cas pratiques, en particulier pour le travail dans des environnements de traitement de texte où les implémentations d’expressions régulières peuvent être particulièrement idiosyncrasiques. Il existe de nombreuses ressources disponibles pour apprendre comment utiliser les expressions régulières dans un contexte de programmation. La meilleure solution pour vous peut dépendre du langage de programmation qui vous est le plus familier ou avec lequel il est le plus pratique de commencer.
Il existe de nombreux éditeurs d’expressions régulières en ligne gratuitement. Rubular, construit à partir de Ruby, dispose d’une interface très utile qui vous permet de tester les expressions régulières sur des échantillons de texte. Il vous montre dynamiquement les motifs ciblés ou les groupes. David Birnbaum, directeur du département des langues et littératures slaves de Pittsburgh, a quant à lui de bons cas de figures sur la manière de travailler avec des expressions régulières et des outils pour XML, dans le but de baliser des fichiers de texte brut pour en faire des fichiers XML.