
Conteúdos
- Objetivos da Lição
- Para quem é útil?
- Familiarizar-se com os dados
- Construir o seu gazetteer
- Carregar os seus textos
- Escrever o programa Python
- Código Final
- Aperfeiçoar a Gazetteer
- Exibir os resultados no ficheiro CSV através do Python
- Criar um ficheiro CSV
- Sugestões para futuras leituras
Objetivos da Lição
Se tem uma cópia de um texto armazenada no seu computador, é relativamente fácil procurar por uma palavra-chave única. Muitas vezes, isto pode ser feito através de recursos integrados no seu editor de texto. Contudo, os académicos necessitam cada vez mais de encontrar um conjunto de termos variados dentro de um ou vários textos. Por exemplo, um académico pode recorrer a gazetters (em inglês) para extrair todas as menções a localidades em inglês dentro de uma série de textos, para que esses locais possam ser, posteriormente, representados num mapa. Por outro lado, pode querer extrair todos os nomes masculinos, sobrenomes, palavras vazias, ou qualquer outro conjunto de palavras. Usar esses mesmos recursos de pesquisa para alcançar um objetivo mais complexo torna o seu projeto moroso e desajeitado. Esta lição pretende ensiná-lo como utilizar o Python para extrair de uma série de textos um conjunto de palavras-chave de uma forma rápida e sistemática.
É esperado que, uma vez completada a lição, consiga generalizar as aprendizagens adquiridas, de modo a extrair conjuntos de palavras-chave personalizados de qualquer ficheiro armazenado no seu computador.
Para quem é útil?
Esta lição é útil para qualquer um que trabalhe com fontes históricas armazenadas no seu próprio computador e que estejam transcritas em formatos mutáveis de texto eletrónico. É particularmente útil para pessoas interessadas em delimitar subgrupos de documentos que contenham uma ou mais de um grande número de palavras-chave. Isto pode ser útil para identificar um subconjunto relevante para leitura atenta ou para extrair e estruturar as palavras-chave num formato que possa ser usado noutra ferramenta digital como, por exemplo, dados de entrada para um exercício de mapeamento.
O presente tutorial mostrará aos usuários como extrair todas as menções a condados ingleses e gauleses de uma série de 6,692 minibiografias de indivíduos que ingressaram na Universidade de Oxford durante o reinado de Jaime I de Inglaterra (1603-1625). Estes registos foram transcritos pela British History Online (em inglês), através da versão impressa de Alumni Oxonienses, 1500-1714. Estas biografias contêm informação sobre cada aluno, incluindo a data dos seus estudos e a faculdade ou faculdades que frequentaram. Muitas vezes incluem informações adicionais, quando conhecidas, como a data de nascimento e morte, o nome e ocupação do pai, a sua naturalidade, e o percurso profissional posterior. As biografias são fontes ricas, das quais provêm informações relativamente comparáveis sobre um grande número de indivíduos semelhantes (homens ricos que frequentaram Oxford). Os 6,692 registos foram pré-processados pelo autor e salvos num ficheiro CSV (em inglês), com uma entrada por linha.
Neste tutorial, o “dataset” envolve palavras-chave geográficas. Uma vez extraídas, os nomes de localidades podem ser georreferenciados para o seu local no globo e, depois, mapeados, recorrendo ao mapeamento digital. Isto torna possível determinar quais as faculdades que atraíam estudantes de determinadas partes do país, e se estes padrões se alteraram ao longo do tempo. Para um tutorial prático sobre como aplicar este próximo passo, veja a lição de Fred Gibbs mencionada no final desta lição. Os leitores também podem estar interessados em ler Georreferenciamento com o QGIS 3.20, também disponível no Programming Historian.
Esta abordagem não se limita a palavras-chaves de natureza geográfica. Também pode ser utilizada para extrair nomes próprios, preposições, palavras de cariz alimentar ou qualquer outro conjunto de palavras definido pelo usuário. Deste modo, este processo pode ser útil a alguém que procure isolar registos individuais que contenham alguma destas palavras-chave ou que procure calcular a frequência das suas palavras-chave dentro de um corpo de textos. Este tutorial confere caminhos para análises textuais ou geoespaciais, ao invés da procura de respostas diretas.
A capacidade de processamento de dados é cada vez mais crucial para os historiadores e académicos textuais, e qualquer pessoa que trabalhe com textos particularmente difíceis e desorganizados deve considerar ler Limpar dados com o OpenRefine, de Seth van Hooland et al. A abordagem utilizada neste tutorial não está otimizada para trabalhar com textos fracamente transcritos, como textos convertidos através do Reconhecimento Ótico de Caracteres (em inglês) se o software tiver uma grande margem de erro. Leitores que trabalhem com editores de texto antigos, com ortografia não padronizada, podem considerar esta aprendizagem desafiadora, sendo que o uso de gazetteer deve conter correspondências exatas às palavras procuradas. Contudo, com um bom gazetteer, esta abordagem demonstra ser bastante útil, e exceder a praticidade da busca tradicional por palavras-chave ao possibilitar o “fuzzy searching” (em inglês).
Para este tutorial é necessário que tenha instalado no seu computador a versão 3 do Python. A lição usará a linha de comandos, mais flexível na sua utilização em salas de aula ou laboratórios informáticos nos quais os alunos não têm a capacidade de descarregar e instalar um ambiente de desenvolvimento integrado (IDE, do inglês “Integrated Development Environment”) como o Komodo Edit. Os leitores que prefiram utilizar um IDE talvez queiram ler primeiro a lição Introdução e instalação do Python, ainda que tal seja opcional. O tutorial também pressupõe algumas habilidades básicas de Python por parte do usuário, nomeadamente, o conhecimento das seguintes estruturas de dados Python (ainda que o seu desconhecimento não comprometa a funcionalidade do código, caso siga todos os passos do tutorial):
Esta lição aborda Expressões Regulares. Por isso, alguns leitores podem achar útil ter abertas para consulta as lições relevantes do Programming Historian de Doug Knox (em inglês) ou de Laura Turner O’Hara (em inglês), conforme necessário.
Familiarizar-se com os dados
O primeiro passo deste processo é analisar os dados que usaremos nesta lição. Como já foi mencionado, estes incluem detalhes biográficos de 6,692 alunos que iniciaram os seus estudos na Universidade de Oxford no início do século XVII.
The_Dataset_-_Alumni_Oxonienses-Jas1.csv (1.4MB)
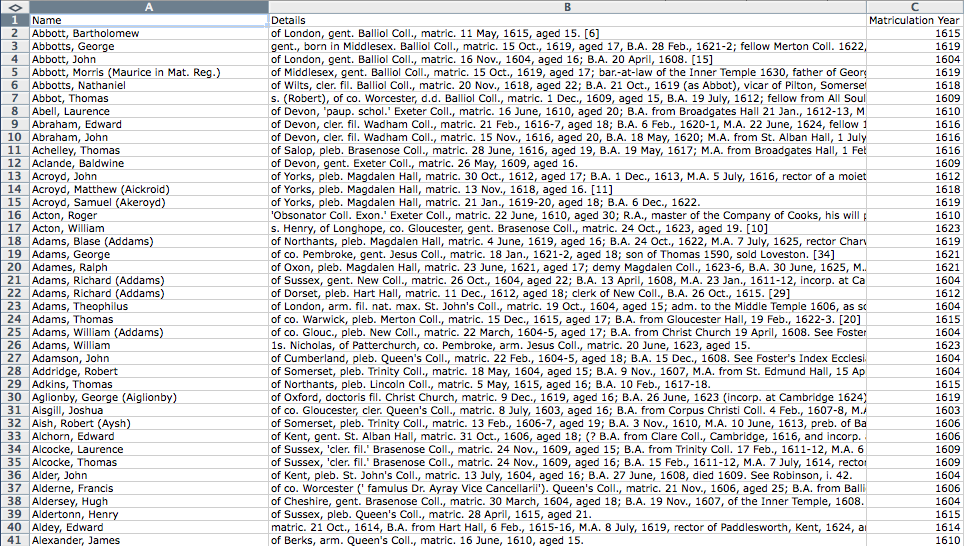
Figura 1. Captura de tela dos primeiros quarenta registos do dataset.
Faça o download do dataset e dedique alguns minutos para analisar todos os tipos de informação disponíveis. Deverá reparar em três colunas de informação. A primeira, Name (Nome), contém o nome do aluno. A segunda, Details (Detalhes), contém toda a informação biográfica conhecida sobre essa pessoa. A última coluna, Matriculation Year (Ano de matrícula), contém o ano no qual a pessoa deu início aos seus estudos. Esta última coluna foi extraída da segunda coluna no pré-processamento deste tutorial. As primeiras duas colunas encontram-se iguais à versão do documento Alumni Oxonienses do British History Online. Se notar a presença de mais de três colunas, tal significa que o seu programa definiu incorretamente o delimitador (em inglês) entre colunas. Este deve ser definido como “,” (vírgula entre aspas duplas). A maneira de selecionar o delimitador depende do programa editor de tabelas utilizado, mas deve conseguir encontrar a solução online.
A maioria destes registos biográficos (mas não todos) contém informação suficiente para indicarmos de que condado é natural o aluno. Note que um grande número de registos contém nomes de localidades correspondentes a cidades (“of London”, no primeiro registo) ou condados ingleses (“of Middlesex” no quinto registo ou “of Wilts” – diminutivo de Wiltshire, no sexto registo). Se não é britânico, é natural que não esteja familiarizado com estes nomes de localidades. Pode encontrar uma lista dos Condados Históricos de Inglaterra na Wikipedia (em inglês).
Infelizmente, a informação não está sempre disponível no mesmo formato. Por vezes, é a primeira coisa mencionada no registo. Outras vezes encontra-se no meio. O nosso desafio é extrair as localidades de origem dentro do texto desorganizado e armazená-las numa nova coluna, ao lado do registo dessa pessoa.
Construir o seu gazetteer
De modo a extrair nomes de localidades relevantes temos de, primeiramente, decidir quais são eles. Precisamos de uma lista de localidades, por norma chamada de dicionário geográfico. Muitos dos nomes de localidades mencionados nos registos são abreviaturas, como “Wilts” ao invés de “Wiltshire” ou “Salop” ao invés de “Shropshire”. Encontrar todas essas variações pode ser desafiante. Inicialmente, vamos construir um gazetteer básico de condados ingleses.
Crie um diretório (pasta) no seu computador, onde irá salvar todo o seu trabalho. Nesse diretório, crie um ficheiro de texto chamado gazetteer.txt e, utilizando os nomes listados na página da Wikipedia mencionada anteriormente, adicione cada condado a uma nova linha no documento de texto. Deve ter esta aparência:
Bedfordshire
Berkshire
Buckinghamshire
Cambridgeshire
Cheshire
Cornwall
Cumberland
Derbyshire
Devon
Dorset
Durham
Essex
Gloucestershire
Hampshire
Herefordshire
Hertfordshire
Huntingdonshire
Kent
Lancashire
Leicestershire
Lincolnshire
Middlesex
Norfolk
Northamptonshire
Northumberland
Nottinghamshire
Oxfordshire
Rutland
Shropshire
Somerset
Staffordshire
Suffolk
Surrey
Sussex
Warwickshire
Westmorland
Wiltshire
Worcestershire
Yorkshire
Confirme se não existem linhas em branco no documento do gazetteer. Se existirem, o seu programa irá pensar que todos os espaços são uma palavra-chave correspondente. Algumas ferramentas de edição de texto (particularmente no Linux) quererão adicionar uma linha em branco no fim do documento. Nesse caso, experimente outro editor de texto. É melhor optar por software que o deixe controlar o documento. Para mais informação sobre este problema, consulte a Explicação do Stack Overflow (em inglês) – agradecemos ao John Levin pelo link.
Se, porventura, precisar de adicionar algum nome a este conjunto de palavras-chave, pode abrir este documento no seu editor de texto e adicionar novas palavras, cada uma com uma linha própria. Pode utilizar qualquer editor de texto , desde que não seja um processador de texto como o Microsoft Word ou o Open Office. Processadores de texto são inapropriados para escrever código pelo modo como estilizam apóstrofos e aspas, impactando a funcionalidade do código.
Carregar os seus textos
O próximo passo é colocar os textos nos quais quer pesquisar num outro documento de texto, com uma entrada por linha. A forma mais fácil de o fazer é abrir a folha de cálculo (tabela), selecionar toda a segunda coluna (Details) e colar o conteúdo num novo documento de texto. Nomeie o documento textos.txt e guarde-o no mesmo diretório que o seu documento gazetteer.txt. O seu diretório deve estar com esta aparência:

Figura 2. Conteúdos do seu diretório de trabalho.
A razão pela qual damos este passo é de modo a manter os dados originais (o documento CSV) desconectados do programa Python que iremos escrever no caso de, acidentalmente, alterarmos algo sem dar conta. Na minha opinião, esta abordagem também facilita a leitura do código, igualmente importante na aprendizagem. Não é estritamente necessário utilizar um documento .txt para este passo, pois o Python possui a capacidade de abrir e ler ficheiros CSV. No final desta lição, abordaremos como usar as ferramentas de escrita e leitura de ficheiros CSV no Python, mas este é um passo avançado opcional.
Escrever o programa Python
O último passo é escrever um programa que irá procurar, em cada um dos textos, o conjunto de palavras-chave definidos no gazetteer e, depois, providenciar um “output” que indicará quais as entradas da nossa folha de cálculo que contêm as palavras listadas. Há diversas maneiras de alcançar este resultado. Ao planear a escrita de um programa é sempre boa ideia traçar um algoritmo. Um algoritmo é um conjunto de passos legíveis por humanos para resolver um problema. É uma lista do que irá fazer, a qual irá ser convertida em instruções programáticas apropriadas. A abordagem que utilizaremos aqui baseia-se no seguinte algoritmo:
- Inserir a lista de palavras-chave que criou no
gazetteer.txte salvar cada uma numa lista de Python. - Carregar os textos de
textos.txt.e salvar cada um numa outra lista de Python. - Em cada registo bibliográfico, remova a pontuação não desejada (pontos, vírgulas, etc).
- Verificar a presença de uma ou mais palavras-chave da sua lista. Se encontrar uma correspondência, guarde-a enquanto procura por outras palavras correspondentes. Se não encontrar correspondência, segue para o próximo registo.
- Finalmente, exportar os resultados num formato que possa ser facilmente transferido para o ficheiro CSV.
Passo 1: Importar as palavras-chave
A partir do seu editor de texto, crie um ficheiro em branco e adicione as seguintes linhas:
# importar as palavras-chave
f = open('gazetteer.txt', 'r')
allKeywords = f.read().lower().split("\n")
f.close()
print(allKeywords)
print(len(allKeywords))
A primeira linha é uma indicação, para ilustrar-nos (a nós, humanos) o que o código faz, pois todas as linhas de Python iniciadas com um # são comentários. Quando o código operar, irá ignorar estes comentários, pelo que são somente para uso humano. Um código bem comentado é mais fácil para uso e trabalho futuro, pois terá os meios para decifrar o código criado anteriormente.
A segunda linha abre o ficheiro gazetteer.txt e lê-o, o que é sinalizado pelo r (de “read” (ler), ao contrário de w para “write” (escrita), ou de a para “attach” (anexar)). Isso significa que não iremos alterar os conteúdos do ficheiro. Apenas lê-los.
A terceira linha lê tudo naquele ficheiro, converte-o para minúsculas e divide o conteúdo numa lista Python, utilizando os caracteres de nova linha (em inglês) como delimitadores. Efetivamente, isto significa que, cada vez que o programa se depara com uma nova linha, armazena-a como uma nova entrada. Assim, salvamos uma lista Python que contém os 39 condados numa variável que denominámos allKeywords.
A quarta linha fecha o ficheiro aberto. Já a quinta linha exibe os resultados e a sexta linha indica-nos quantos resultados foram encontrados.
Salve este ficheiro como extraxtKeyword.py, novamente, no mesmo diretório que os outros ficheiros e, depois, clique Run Python. Para fazer isto a partir da linha de comandos, precisa de primeiro iniciar o terminal da linha de comandos.
-
No Windows, este chama-se “Prompt de Comando”. Os usuários de Windows podem achar mais fácil lançar o Python abrindo o diretório que contém o ficheiro
extractKeywords.py, pressionarshift + lado direito do ratoe, depois, selecionar abrir janela de comando aqui. Assumindo que tem o Python instalado, deverá conseguir iniciar o programa utilizando o comando começado compythonabaixo. -
No Mac OS X, isto encontra-se na pasta Aplicações e é chamado “Terminal”. Uma vez aberta a janela Terminal, necessita de apontar o seu terminal para o diretório que contém todos os ficheiros que acabou de criar. Eu denominei o meu diretório
ExtractingKeywordSetse guardei-o no ambiente de trabalho do meu computador. Para mudar o Terminal para este diretório, utilizei o seguinte comando:
cd Desktop/ExtractingKeywordSets
Precisará de mudar o nome acima consoante o nome dado ao seu diretório, e onde o armazenou no seu computador. Note que o Windows utiliza \ ao invés de / na conexão com o diretório. Se não conseguir prosseguir, altere o nome do seu diretório para ExtractingKeywordSets e coloque-o no seu ambiente de trabalho, para dar continuidade à lição.
Poderá executar o programa que escreveu com o seguinte comando:
python extractKeywords.py
Uma vez executado o programa, deverá ver o seu gazetteer exibido como uma lista Python no resultado do comando, juntamente com o número de entradas na sua lista (39). Se sim, ótimo! Prossiga para o passo 2.
gazetteer.txt, ele encontra 40 resultados, não 39.
Se a última linha do seu resultado indica que só existe 1 resultado, isso significa que o código não operou corretamente, uma vez que sabemos que devem existir 39 palavras-chave na sua gazetteer. Reveja o seu código e procure se existe algum erro. Se continuar sem conseguir resolver o problema, tente alterar \n para \r na linha três. Alguns editores de texto usam o retorno de carro (“carriage return”) ao invés de caracteres de nova linha ao criar uma linha. O \r significa “retorno de carro” e deve resolver o problema.
Passo 2: Carregar os textos
O segundo passo é bastante semelhante ao primeiro exceto que, desta vez, importaremos o ficheiro textos.txt em conjunto com o ficheiro gazetteer.txt.
Adicione as seguintes linhas ao final do seu código:
# importar os textos que quer pesquisar
f = open('textos.txt', 'r')
allTexts = f.read().lower().split("\n")
f.close()
print(allTexts)
Se conseguiu colocar o passo 1 a funcionar, conseguirá entender este próximo passo. Antes de executar o código, confirme que salvou o seu programa ou poderá, acidentalmente, executar a versão antiga e ficar confuso com o resultado. Uma vez feito este processo, volte a executar o código. Como atalho, ao invés de reescrever o comando no Terminal, pode pressionar a seta para cima, que mostrará o último comando que inseriu. Se continuar a pressionar as setas, poderá aceder aos comandos anteriores, sem necessitar de reescrevê-los. Quando encontrar o comando para executar o programa, clique Enter para executar o código.
Se o código funcionou, deverá ver um grande bloco de texto. Estes são os textos que importamos para o programa. Desde que os veja, está tudo bem. Antes de prosseguir para o próximo passo, apague as 3 linhas do código iniciadas por print. Agora que sabemos que o código está a apresentar os conteúdos destes ficheiros, não necessitamos de continuar a verificar. Prossiga para o passo 3.
Passo 3: Remover a pontuação desnecessária
Ao procurar correspondências entre termos, tem de ter a certeza de que a pontuação não o impede. Tecnicamente, London. é um termo diferente de London ou ;London, devido à pontuação adicional. Estes três termos, que para nós, leitores humanos, significam o mesmo, são vistos pelo computador como entidades distintas. Para resolver este problema, a solução mais fácil é remover toda a pontuação. Pode fazê-lo utilizando expressões regulares. As lições de Doug Knox e Laura Turner O’Hara do Programming Historian são boas introduções para o fazer.
Para simplificar as coisas, este programa irá apenas substituir os tipos de pontuação mais comuns por uma entrada em branco ao invés de, efetivamente, apagar pontuação.
Adicione as seguintes linhas de comando ao seu programa:
for entry in allTexts:
# para cada registo
allWords = entry.split(' ')
for words in allWords:
# remover pontuação que interfere com a correspondência
words = words.replace(',', '')
words = words.replace('.', '')
words = words.replace(';', '')
A variável allTexts contém todos os nossos textos. Através de um laço de repetição for, vamos analisar um registo de cada vez.
Uma vez que estamos interessados em palavras singulares, iremos dividir o texto em palavras singulares utilizando o método .split(), procurando explicitamente por espaços: entry.split(‘ ‘). Note que existe um único espaço entre as aspas. Uma vez que as palavras são geralmente separadas por espaços, deverá funcionar bem. Isto significa que agora temos uma lista Python chamada allWords que contém cada palavra numa única entrada bibliográfica.
Utilizamos outro laço de repetição for para verificar cada palavra nessa lista. Onde quer que se encontre uma vírgula, ponto ou ponto e vírgula, essa pontuação será substituída por nada, efetivamente removendo-a. Note que não há um espaço entre as aspas das últimas três linhas.
Temos agora um conjunto de palavras limpo, que podemos comparar com as entradas da gazetteer, de modo a encontrar correspondências.
Passo 4: Procurar por palavras-chave correspondentes
Uma vez que as palavras do texto já estão numa lista chamada allWords e que todas as nossas palavras-chave estão numa lista chamada allKeywords, tudo o que temos de fazer agora é procurar por essas palavras-chave nos nossos textos.
Primeiro, precisamos de um lugar para armazenar os detalhes de qualquer correspondência que tenhamos. Imediatamente depois da linha de comando for entry in allTexts, com um nível de parágrafo, adicione as seguintes duas linhas de comando:
matches = 0
storedMatches = []
A indentação é importante no Python. As duas linhas acima devem encontrar-se num nível a mais de indentação do que o laço acima delas. Isso significa que este código deverá ser executado todas as vezes que o laço for executado – é parte integrante do laço. Se o seu editor de texto não o permitir, poderá usar espaços ao invés de parágrafos.
A variante storedMatches é uma lista em branco, onde podemos armazenar as nossas correspondências. A variável matches é conhecida como um “sinalizador”, que usaremos no próximo passo quando começarmos a exibir o resultado.
Para efetuar a correspondência em si, adicione as seguintes linhas de comando no final do seu programa, tomando novamente atenção à indentação (2 níveis desde a margem esquerda) e confirmando que volta a salvar o programa:
# se encontrar correspondência, guardar resultado
if words in allKeywords:
if words in storedMatches:
continue
else:
storedMatches.append(words)
matches += 1
print(matches)
Se quiser confirmar que a indentação foi feita corretamente, verifique o código final no fim da lição.
Observe todo o seu programa. Estas linhas de comando surgem imediatamente depois da secção onde removeu a pontuação. Por isso, cada vez que foi removida a pontuação de uma palavra (se a palavra tivesse pontuação para ser removida), foi imediatamente verificada a sua presença na lista de palavras-chave do seu ficheiro gazetteer. Se for correspondente, verificamos se ainda não temos essa palavra registada na nossa variável storedMatches. Caso já esteja registada, passamos para a próxima palavra. Se não, adicionamo-la à lista storedMatches. Este processo mantém o registo de palavras correspondentes para cada texto. Quando encontramos uma correspondência, também aumentamos o nosso sinalizador matches, de modo a sabermos quantas correspondências encontrámos para cada texto.
Este código irá, automaticamente, verificar cada palavra num texto, registando as correspondências na lista storedMatches. Quando chega ao fim de um texto, ele esvazia a variável storedMatches e recomeça. Imprimir a variável matches serve somente para ficarmos a saber quantas correspondências foram encontradas para cada texto. Ao executar este código, deve verificar entre 0 e 2 correspondências por cada registo. Se indicar 0 correspondências em todos, reveja o seu código. Se tiver apenas uma entrada a mostrar resultados, volte atrás até ao primeiro passo e confirme que o seu programa identificou o número correto de palavras-chave (39).
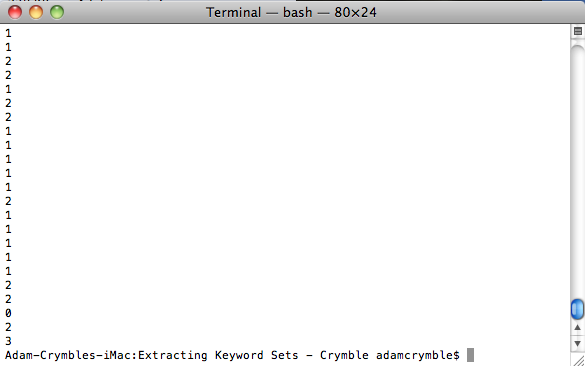
Figura 3. Resultado correto do seu código neste momento.
Se parece ter funcionado, apague a linha print matches e prossiga para o próximo passo.
Passo 5: Exportar resultados
Se conseguiu chegar a este passo, o seu programa Python está a encontrar palavras-chave correspondentes nos textos através da sua gazetteer. Agora, é necessário exibi-las no painel de resultados num formato em que as possamos trabalhar facilmente.
Adicione as seguintes linhas de comando ao seu programa tendo em conta, como sempre, a indentação:
# se tiver um resultado armazenado, exibe-o
if matches == 0:
print(' ')
else:
matchString = ''
for matches in storedMatches:
matchString = matchString + matches + "\t"
print(matchString)
Este código verifica se o número de correspondências é igual a 0. Se for, não encontrámos nenhuma palavra-chave e, portanto, não precisamos de exibi-las. Contudo, iremos apresentar um espaço em branco, porque queremos que o nosso resultado tenha o mesmo número de linhas que o ficheiro importado (queremos 1 linha de resultado por linha de texto pesquisado). Isto tornará mais fácil colar o nosso resultado diretamente no ficheiro CSV e alinhá-lo com o texto correspondente.
Se, de facto, houver correspondência, então o programa cria uma variável chamada matchString (pode ser nomeada de qualquer maneira). Assim, cada uma das palavras-chave correspondentes mantidas em storedMatches é transferida para matchString, juntamente com um caracter de tabela (\t). Este último é útil para ficheiros CSV, pois quando é colado numa tabela, o conteúdo separado pelo caracter irá automaticamente para uma célula adjacente. Isto significa que, se um texto tem mais do que uma palavra-chave correspondente, será colada uma correspondência por célula. Este processo facilita a separação das palavras-chave quando transferidas para o ficheiro CSV.
Quando todas as palavras-chave tiverem sido transferidas para o matchString, o programa irá imprimir o resultado do comando antes de seguir para o próximo texto.
Se guardar o seu trabalho e executar o seu programa, deverá ter um código que alcança todos os passos do algoritmo escrito anteriormente e imprime os resultados das suas linhas de comando.
O código final deverá parecer-se com isto:
Código Final
# importar as palavras-chave
f = open('gazetteer.txt', 'r')
allKeywords = f.read().lower().split("\n")
f.close()
# importar os textos que quer pesquisar
f = open('textos.txt', 'r')
allTexts = f.read().lower().split("\n")
f.close()
# o nosso programa
for entry in allTexts:
matches = 0
storedMatches = []
# para cada registo
allWords = entry.split(' ')
for words in allWords:
# remover pontuação que interfere com a correspondência
words = words.replace(',', '')
words = words.replace('.', '')
words = words.replace(';', '')
# se encontrar correspondência, guardar resultado
if words in allKeywords:
if words in storedMatches:
continue
else:
storedMatches.append(words)
matches += 1
# se tiver um resultado armazenado, exibe-o
if matches == 0:
print(' ')
else:
matchString = ''
for matches in storedMatches:
matchString = matchString + matches + "\t"
print(matchString)
Se não gostar do formato final do resultado, pode alterá-lo ao ajustar a penúltima linha do código. Por exemplo, pode salvar os seus resultados num ficheiro .txt ao invés de no painel. Para o fazer, basta substituir print matchString com o código abaixo (tenha em atenção o nível de parágrafo em que se encontra, pois este deve manter-se igual):
f = open('output.txt', 'a')
f.write(matchString)
f.close()
Repare no a ao invés do r utilizado anteriormente. Isto “anexa” o texto ao ficheiro chamado output.txt, que será salvo no seu diretório de trabalho. Há que ter cuidado, pois ao executar o programa várias vezes, irá anexar todos os resultados a este ficheiro, criando um ficheiro muito longo. Há maneiras de evitá-lo, que iremos abordar posteriormente. Pode considerar verificar como funciona a ferramenta de escrita w e experimentar vários formatos de exportação. Há mais informação sobre estas ferramentas na lição ‘Trabalhando com ficheiros de texto em Python’.
Aperfeiçoar a Gazetteer
Pode copiar e colar o resultado diretamente na sua tabela, ao lado da primeira entrada. Verifique se as correspondências se alinham corretamente. A última entrada da sua tabela deve corresponder às palavras-chave corretas extraídas. Neste caso, a última linha deve estar em branco, mas a penúltima deve ter escrito “dorset”.

Figura 4. O resultado colado no ficheiro CSV.
Neste momento, talvez queira aproveitar para aperfeiçoar a gazetteer, uma vez que muitos nomes de locais foram esquecidos. Alguns deles são diminutivos ou estão escritos de forma arcaica (Wilts, Salop, Sarum, Northants, etc). Pode verificar cada uma das células em branco e ver se encontra palavras-chave que tenham escapado ao programa. Talvez seja útil saber que pode encontrar a próxima célula em branco de uma coluna no Excel ao pressionar CTRL + seta para baixo (CMD + seta para baixo no Mac).
Uma das formas mais fáceis para encontrar todas as células em branco é ordenar a sua tabela de dados através das novas colunas que acabou de adicionar. Se ordenar as correspondências por ordem alfabética, então as células no final da página estarão em branco. Para o fazer, basta selecionar toda a tabela e clicar no item Dados > Ordenar. Também pode ordenar cada uma das novas colunas de A-Z.
Antes de ordenar a sua tabela de dados, é uma boa ideia adicionar uma coluna com a “ordem original”, caso queira retomar a sua ordem original. Para fazê-lo, adicione uma nova coluna, e nas primeiras 3 linhas escreva 1, 2 e 3, respetivamente. Depois, destaque as três células e coloque o seu cursor por cima do canto inferior direito. Se estiver a usar o Microsoft Excel, o cursor irá mudar para uma seta preta. Quando esta aparecer, clique e segure o botão do rato, arrastando o cursor até ao final da tabela antes de o largar. Este processo deverá numerar automaticamente as linhas consecutivas, de modo a conseguir reordenar as células na sua ordem original.
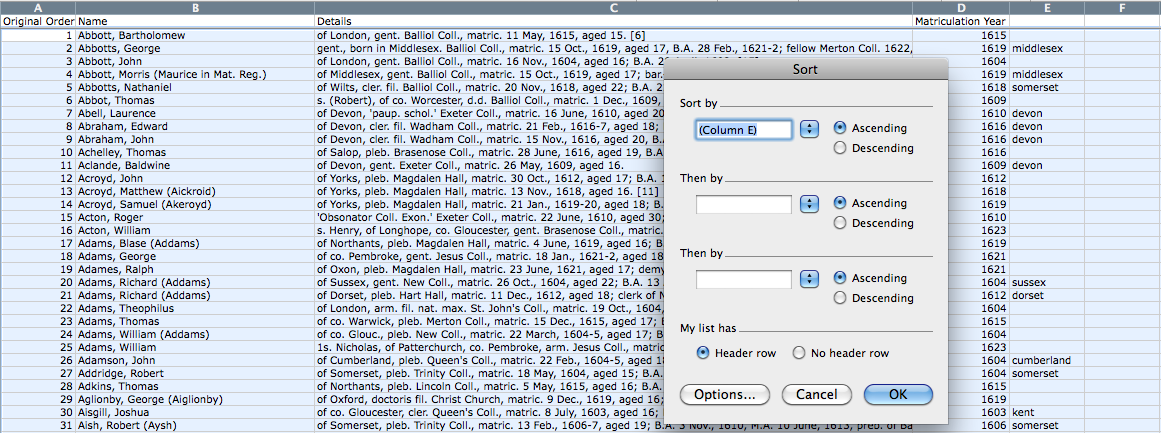
Figura 5. Adicionando uma coluna com a ordem original e ordenando os registos.
Agora consegue ordenar os dados e ler algumas das entradas para as quais não foram encontradas correspondências. Se encontrar um nome de um local lá, adicione-o ao seu ficheiro gazetteer.txt, mantendo uma entrada por linha. Nesta fase, não tem de ser um processo exaustivo. Pode adicionar algumas entradas e depois experimentar o código novamente para ver o impacto que estas causaram no resultado.
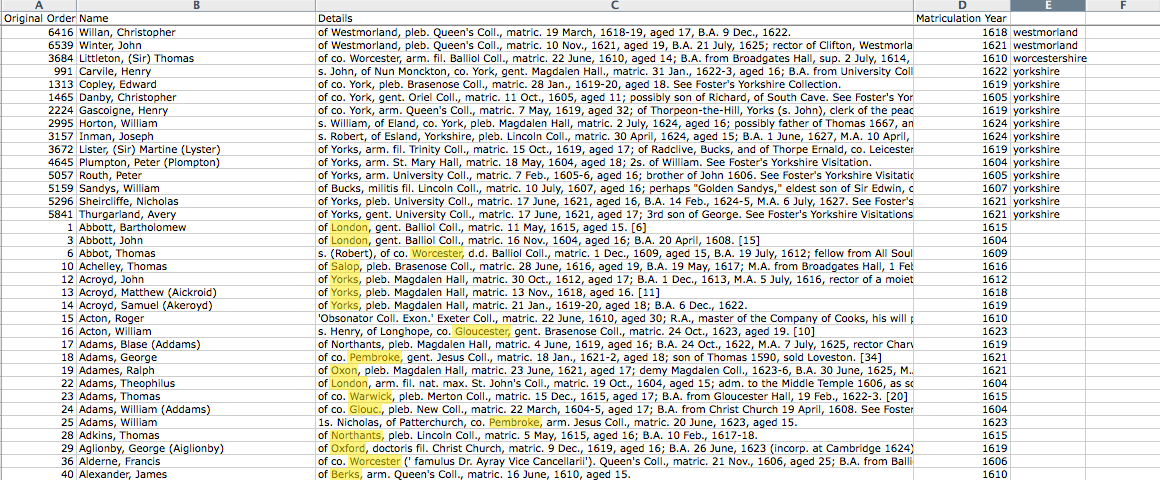
Figura 6. Nomes de locais esquecidos destacados a amarelo.
Antes de voltar a executar o seu código Python, tem de atualizar o seu ficheiro textos.txt para que o programa execute sobre os textos na ordem correta. Uma vez que o código irá exibir os resultados na mesma ordem que os recebe do ficheiro textos.txt, é importante garantir que não os mistura com as reordenações feitas na tabela onde pretende armazená-los. Pode reordenar a tabela pela sua ordem original antes de correr o programa ou copiar todas as células na coluna Details e colá-las, salvando-as no ficheiro textos.txt.
Desafio-o a fazer algumas mudanças à sua gazetteer antes de continuar, para ganhar prática neste processo.
Uma vez satisfeito com as alterações, pode descarregar a minha Lista completa de condados ingleses e gauleses, diminutivos e várias outras cidades (London, Bristol, etc) e localidades (Jersey, Ireland, etc). Esta lista contém 157 entradas e deve conferir-lhe todas as entradas que possam ser extraídas dos textos nesta coleção.
Neste momento pode parar, uma vez que já alcançou os seus objetivos. Esta lição ensinou-o como usar um pequeno programa Python para procurar num grande grupo de textos um conjunto de palavras-chave definidos por si.
Com os resultados adquiridos nesta lição, poderá rapidamente mapear estas entradas através da geolocalização dos nomes de localidades. Isto poderá revelar novas perspetivas sobre os padrões espaciais dos alunos de Oxford à época.
Ter a capacidade de procurar por um grande número de palavras-chave simultaneamente abre portas a uma maior flexibilidade do seu processo de pesquisa e torna fazível um trabalho que, de outra forma, tomaria grande parte do seu tempo. Pode experimentar um conjunto de palavras completamente diferente ou utilizar esta técnica noutro conjunto de textos. As possibilidades de pesquisa são, claramente, ilimitadas.
Se, por outro lado, quiser aperfeiçoar ainda mais o seu programa, pode utilizar o Python para ler diretamente o ficheiro CSV e exibir os resultados num novo ficheiro CSV para que tudo aconteça automaticamente desde a janela do Terminal, sem necessitar de cortar e colar.
Exibir os resultados no ficheiro CSV através do Python
O Python tem uma biblioteca de código embutida que consegue trabalhar com ficheiros CSV, chamada “csv”.
Para utilizar esta biblioteca e as respetivas ferramentas tem de, primeiramente, importá-la. No topo do seu:
import csv
Agora, faremos algumas mudanças no nosso programa original. Ao invés de cortar todos os textos para um ficheiro textos.txt, vamos usar o Python para ler os dados diretamente para a nossa variável allTexts. Substitua:
# importar os textos que quer pesquisar
f = open('textos.txt', 'r')
allTexts = f.read().lower().split("\n")
f.close()
Por isto:
# importar a coluna ‘Details’ do ficheiro CSV
allTexts = []
fullRow = []
with open('The_Dataset_-_Alumni_Oxonienses-Jas1.csv') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
# toda a linha de cada entrada, que usaremos para recrear o ficheiro CSV melhorado
fullRow.append((row['Name'], row['Details'], row['Matriculation Year']))
# a coluna que queremos analisar com as nossas palavras-chave
row = row['Details'].lower()
allTexts.append(row)
Uma vez que esta é uma opção avançada, não explicarei a função de cada linha em detalhe, mas pode olhar para os comentários no código para ter uma ideia de como este funciona. Efetivamente, usa o Python para ler os ficheiros CSV e armazenar toda a informação na coluna Details na mesma variável allTexts onde estavam anteriormente e no mesmo formato. Este código também guarda cada linha do ficheiro CSV numa outra lista chamada fullRow, que será utilizada para escrever um novo ficheiro CSV, contendo os resultados do nosso programa.
Há algumas linhas de código extra aqui, mas não precisou de cortar e colar nada no ficheiro textos.txt e não há o risco da ordem da sua tabela causar problemas relacionados com a ordem dos produtos e resultados. Deste modo, esta é uma opção mais robusta. Pode imprimir qualquer uma destas variáveis utilizando a ferramenta print, para ter a certeza que contêm aquilo que espera delas.
TROUBLESHOOTING: Se lhe aparecer o seguinte erro quando tentar ler o seu ficheiro CSV através do Python, o ficheiro CSV pode ter sido salvo num Mac e a biblioteca CSV do Python só consegue ler ficheiros CSV compatíveis com o Windows.
(Error: new-line character seen in unquoted field - do you need to open the file in universal-newline mode?).
Para resolver este problema, abra o seu ficheiro CSV num programa de folhas de cálculo (ex. Excel), selecione Guardar Como e, no formato, escolha “Windows Comma Separated (csv)”. Isto deverá resolver o problema. Para ler mais sobre este problema, veja o Stack Overflow (em inglês).
Criar um ficheiro CSV
De seguida, precisamos de criar um ficheiro CSV onde os resultados da análise possam ser armazenados. É sempre uma boa ideia fazer um novo ficheiro, ao invés de anexar os resultados à nossa única cópia dos dados originais. É também uma boa ideia anexar a data e tempo atuais ao nome do novo ficheiro. Deste modo, pode correr o código várias vezes enquanto o aperfeiçoa e será sempre claro qual é o ficheiro que contém os seus resultados mais recentes.
Para fazer isto, importe a biblioteca “time”, abaixo do local onde importou a biblioteca csv.
import time
Depois, adicione as seguintes duas linhas de código logo abaixo de onde estava a trabalhar com o novo código CSV.
# usar a data e hora atuais para criar o nome do ficheiro
timestr = time.strftime("%Y-%m-%d-(%H-%M-%S)")
filename = 'output-' + str(timestr) + '.csv'
Isto irá criar uma variável chamada filename, a qual iremos utilizar quando fizermos o novo ficheiro de resultados.
O resto do processo envolve construir esse ficheiro de resultados, colocá-lo nos cabeçalhos corretos colando os dados originais e, depois, colando os novos resultados de correspondências gazetteer. Isto envolve algumas alterações no código original, por isso, de modo a tornar mais claro todo este processo, incluí o código final abaixo. Adicionei NOVO!, ANTIGO! e ALTERADO! nos comentários de cada seção, para que possa ver rapidamente quais as partes que mudaram:
encoding='latin1', como no exemplo abaixo:
with open('The_Dataset_-_Alumni_Oxonienses-Jas1.csv', encoding='latin1') as csvfile:
# NOVO!
import csv
import time
# ANTIGO! Importar as palavras-chave
f = open('gazetteer.txt', 'r')
allKeywords = f.read().lower().split("\n")
f.close()
# ALTERADO! Importar a coluna ‘Details’ do ficheiro CSV
allTexts = []
fullRow = []
with open('The_Dataset_-_Alumni_Oxonienses-Jas1.csv') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
# toda a linha de cada entrada, que usaremos para recriar o ficheiro CSV melhorado
fullRow.append((row['Name'], row['Details'], row['Matriculation Year']))
#a coluna que queremos analisar com as nossas palavras-chave
row = row['Details'].lower()
allTexts.append(row)
# NOVO! Um sinalizador usado para registar qual a linha que está a ser exibida no ficheiro CSV
counter = 0
# NOVO! Usar a data e hora atuais para criar o nome do ficheiro
timestr = time.strftime("%Y-%m-%d-(%H-%M-%S)")
filename = 'output-' + str(timestr) + '.csv'
# NOVO! Abrir o novo ficheiro de resultados CSV para anexar (’a’) linhas uma de cada vez
with open(filename, 'a') as csvfile:
# NOVO! Definir os cabeçalhos das colunas e escrevê-los no novo ficheiro
fieldnames = ['Name', 'Details', 'Matriculation Year', 'Placename']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# NOVO! Definir o resultado de cada linha e exibi-lo no ficheiro de resultados csv
writer = csv.writer(csvfile)
# ANTIGO! Isto mantêm-se como antes, for currentRow in fullRow
for entry in allTexts:
matches = 0
storedMatches = []
# para cada registo
allWords = entry.split(' ')
for words in allWords:
# remover a pontuação que interfere na correspondência
words = words.replace(',', '')
words = words.replace('.', '')
words = words.replace(';', '')
# se encontrar correspondência, guardar o resultado
if words in allKeywords:
if words in storedMatches:
continue
else:
storedMatches.append(words)
matches += 1
# ALTERADO! Enviar qualquer correspondência para uma nova linha do ficheiro csv
if matches == 0:
newRow = fullRow[counter]
else:
matchTuple = tuple(storedMatches)
newRow = fullRow[counter] + matchTuple
#NOVO! Escrever os resultados de cada linha no ficheiro csv
writer.writerows([newRow])
counter += 1
O código está detalhadamente comentado, por isso, se passar algum tempo a lê-lo, irá entender como funciona. Guarde este código e volte a executá-lo através do Python. Deverá aparecer um ficheiro chamado output.csv no seu diretório de trabalho que, ao abrir, deverá conter toda a informação que tinha anteriormente, mas sem a necessidade de cortar ou colar.
Para sumarizar todas as alterações feitas à versão original:
- Os textos foram extraídos automaticamente desde o ficheiro de dados original, ao invés de ter de os colar num ficheiro
textos.txt. - Através da biblioteca time, utilizámos a data e tempo correntes de modo a criar um único e facilmente decifrável nome para o nosso ficheiro de resultados.
- Através da biblioteca csv criámos um ficheiro CSV, utilizando esse nome de ficheiro e colocámos os cabeçalhos das colunas que queríamos usar.
- Corremos o mesmo código para correspondências, comparando
allTexts?comallWordse armazenámos os resultados. - Ao invés de imprimirmos os resultados no ecrã, guardámos os dados originais de cada linha (Name, Details, Matriculation Year) + as correspondências para um énuplo chamado
newRow. - Através da biblioteca csv, escrevemos os dados da
newRowpara um novo ficheiro CSV, linha por linha.
Esta abordagem criou um código mais longo e complexo, mas o resultado é um programa poderoso que lê a partir de um ficheiro CSV, compara o conteúdo dos textos com uma gazetteer e, depois, automaticamente, escreve o resultado num novo ficheiro CSV em branco, sem passos intermédios para o seu usuário. Não precisava de ir tão longe, mas esperemos que consiga perceber as vantagens de o ter feito.
Sugestões para futuras leituras
Os leitores que tenham completado esta lição podem estar interessados em, depois, georreferenciar o resultado através do Google API e mapear os resultados. Pode aprender mais sobre este processo através do tutorial de Fred Gibbs, Extract and Geocode Placenames from a Text File (em inglês). Isto permitirá que visualize as possibilidades práticas deste tutorial. Por outro lado, os leitores podem estar interessados no tutorial de Jim Clifford, Georreferenciamento com o QGIS 3.20, um programa SIG que funciona em código aberto.