
Contenus
- Objectifs de la leçon
- À qui s’adresse cette leçon ?
- Installer R
- Utiliser la console de R
- Utiliser des jeux de données
- Les fonctions de base de R
- Travailler avec de grands jeux de données
- Data frames
- Charger votre propre jeu de données dans R
- Enregistrer des données dans R
- Conclusion et autres ressources
- Notes
Objectifs de la leçon
De plus en plus de documents historiques étant désormais numérisés, être capable d’analyser rapidement de grands volumes de données tabulaires peut rendre le travail de recherche plus rapide et efficace.
R est un langage de programmation conçu pour réaliser des analyses statistiques. Il permet de réaliser des analyses quantitatives à partir de données historiques ou d’autres types de données, comme par exemple des tests statistiques ou autres méthodes. Comme on peut réexécuter le même code autant de fois que l’on veut sur les mêmes données, R permet de faire des analyses rapidement et d’obtenir des résultats reproductibles. Une fois le code sauvegardé, on peut le réutiliser ou le modifier pour d’autres projets de recherche, ce qui fait de R un outil extrêmement flexible.
Ce tutoriel ne requiert aucune connaissance préalable de R. C’est une introduction au langage R et à certaines de ses fonctions de base. Il vous guide dans l’installation de R, passe en revue certains des outils que l’on peut utiliser dans R et explique comment travailler avec des jeux de données pour faire des travaux de recherche. Il prend la forme d’une série de mini-leçons ; celles-ci montrent quels types de sources sont adaptés à R et fournissent des exemples de calculs permettant d’identifier des informations pertinentes pour la recherche historique, et plus largement pour la recherche en sciences humaines et sociales. Dans cette leçon, nous verrons également différentes façons d’importer des données dans R, comme la création de tableaux de données et le chargement de fichiers CSV.
À qui s’adresse cette leçon ?
R est idéal pour analyser de grands jeux de données qu’il serait trop chronophage d’examiner manuellement. Une fois que vous avez compris comment écrire certaines fonctions de base et comment importer vos propres fichiers de données, vous pouvez analyser et visualiser les données rapidement et efficacement.
Bien que R soit un excellent outil pour les données tabulaires, vous trouverez peut-être plus utile d’utiliser d’autres approches pour analyser des données non tabulaires comme les archives de journaux. Si vous souhaitez étudier ce type de sources, nous vous conseillons de consulter les autres leçons de Programming Historian en français.
Installer R
R est un langage de programmation et un environnement permettant de travailler avec des données. Il peut être exécuté à l’aide de la console de R, de la ligne de commande (leçon en anglais) ou de l’interface R Studio. Dans ce tutoriel, nous allons utiliser la console de R. Pour commencer à utiliser R, téléchargez le programme sur CRAN (The Comprehensive R Archive Network). R est compatible avec Linux, Mac et Windows.
Quand vous ouvrez la console de R pour la première fois, elle apparait dans une fenêtre qui ressemble à celle-ci :
Figure 1. La console R sur un Mac
Utiliser la console de R
Quand on débute avec R, la console de R est l’endroit idéal pour commencer à travailler, parce qu’elle a été conçue spécifiquement pour ce langage et offre des fonctionnalités propres à R.
C’est dans cette console que vous saisirez les commandes. Pour effacer le contenu de la console, cliquez sur Édition dans la barre de menu et sélectionnez Effacer Console. Le contenu de la console disparaitra. Vous pouvez également modifier l’apparence de la console en cliquant sur la roue des couleurs en haut de la console sur un Mac ou en sélectionnant Préférences dans le menu Édition sur un PC. Vous pouvez également changer la couleur de l’arrière-plan de l’écran et la couleur des polices de caractères utilisée pour les fonctions.
Utiliser des jeux de données
Avant de travailler avec vos propres données, il est utile d’utiliser les jeux de données intégrés à R pour comprendre comment R fonctionne. Vous pouvez les rechercher en entrant data() dans la console. La liste de tous les jeux de données disponibles s’affichera dans une nouvelle fenêtre. Cette liste comprend les titres et une courte description des données.
Vous allez dans un premier temps charger le jeu de données AirPassengers1, qui est une série temporelle, dans votre session R. Tapez data(AirPassengers) et appuyez sur Entrée. Pour visualiser les données, tapez AirPassengers sur la ligne suivante, puis appuyez à nouveau sur Entrée. Vous verrez alors un tableau indiquant le nombre de passagers qui ont voyagé sur des compagnies aériennes internationales entre janvier 1949 et décembre 1960, exprimé en milliers de personnes. Voici ce qui devrait s’afficher :
data(AirPassengers)
AirPassengers
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
1949 112 118 132 129 121 135 148 148 136 119 104 118
1950 115 126 141 135 125 149 170 170 158 133 114 140
1951 145 150 178 163 172 178 199 199 184 162 146 166
1952 171 180 193 181 183 218 230 242 209 191 172 194
1953 196 196 236 235 229 243 264 272 237 211 180 201
1954 204 188 235 227 234 264 302 293 259 229 203 229
1955 242 233 267 269 270 315 364 347 312 274 237 278
1956 284 277 317 313 318 374 413 405 355 306 271 306
1957 315 301 356 348 355 422 465 467 404 347 305 336
1958 340 318 362 348 363 435 491 505 404 359 310 337
1959 360 342 406 396 420 472 548 559 463 407 362 405
1960 417 391 419 461 472 535 622 606 508 461 390 432
Vous pouvez maintenant utiliser R pour répondre à un certain nombre de questions basées sur ces données. Par exemple, pendant quels mois de l’année les voyageurs étaient-ils les plus nombreux ? Y a-t-il eu une augmentation des vols internationaux au fil du temps ? Vous pourriez probablement trouver les réponses à ces questions en parcourant simplement la série, mais vous ne seriez pas aussi rapide que votre ordinateur. De plus, examiner une série de valeurs manuellement devient très compliqué quand il y a beaucoup plus de données.
Les fonctions de base de R
R peut être utilisé pour réaliser des calculs qui peuvent vous être utiles pour effectuer des recherches sur vos jeux de données. Par exemple, vous pouvez obtenir la moyenne, la médiane, la valeur minimale et la valeur maximale. Pour calculer la moyenne et la médiane de la série AirPassengers, il faut écrire respectivement mean(AirPassengers) et median(AirPassengers) dans la console. Il est également possible de calculer plusieurs mesures à la fois. Pour obtenir un résumé des données, entrez summary(AirPassengers) dans la console. Vous obtiendrez ainsi la valeur minimale et la valeur maximale ainsi que la moyenne, la médiane, le premier et le troisième quartiles.
summary(AirPassengers)
Min. 1st Qu. Median Mean 3rd Qu. Max.
104.0 180.0 265.5 280.3 360.5 622.0
La fonction summary() (résumé) montre que de janvier 1949 à décembre 1960, le nombre minimum de passagers par mois est de 104 000 et que le nombre maximum est de 622 000. La moyenne (« mean ») indique qu’environ 280 300 personnes ont voyagé chaque mois sur la durée pendant laquelle ont été recueillies les données. Ces valeurs peuvent être utiles pour déterminer la façon dont le nombre de passagers varie dans le temps.
Sélectionner des valeurs dans un vecteur
Cette fonction est bien pratique pour avoir une vue d’ensemble d’une série de valeurs numériques, mais comment faire pour analyser un sous-ensemble du jeu de données, comme une année particulière ou certains mois ? On peut sélectionner certaines observations (correspondant par exemple à un mois) ou ensembles d’observations (comme les valeurs d’une année) pour faire différents calculs. Par exemple, on peut sélectionner la première valeur de la série AirPassengers en indiquant sa position entre crochets :
AirPassengers[1]
[1] 112
On peut également additionner le nombre de passagers sur deux mois afin de déterminer le nombre total de personnes qui ont voyagé pendant cette période. Ici, nous allons additionner les deux premières valeurs d’AirPassengers dans la console en indiquant la position du premier et du second mois de la série. Après avoir appuyé sur Entrée, vous devriez obtenir ceci :
AirPassengers[1] + AirPassengers[2]
[1] 230
Le résultat indique le nombre total de passagers, exprimé en milliers de personnes, qui ont voyagé en janvier et en février 1949 (c’est-à-dire la première et la deuxième valeur de la série AirPassengers).
Notez que vous pouvez exécuter la même opération en sélectionnant une plage de valeurs avec l’opérateur :, puis en leur appliquant la fonction sum(). Affichez, puis sommez les deux premières valeurs de la série AirPassengers :
AirPassengers[1:2]
[1] 112 118
sum(AirPassengers[1:2])
[1] 230
Assigner des valeurs à un objet
R peut faire bien plus que ce type de calcul simple. En assignant les valeurs à des objets enregistrés dans votre session de travail, vous pourrez les manipuler plus facilement. Par exemple, on peut créer un objet Jan1949, qui contient le nombre de passagers en janvier 1949. Écrivez Jan1949 <- 112 dans la console, puis Jan1949 sur la ligne suivante. Le signe <- assigne la valeur 112 à l’objet Jan1949. Vous devriez obtenir ceci :
Jan1949 <- 112
Jan1949
[1] 112
R étant sensible à la casse, il est essentiel d’utiliser exactement la même orthographe quand on crée un objet et quand on s’en sert pour faire des calculs ou d’autres actions. Notez que dans R, les noms d’objets commencent nécessairement par une lettre (majuscule ou minuscule). Consultez l’article de Rasmus Bååth, The State of Naming Conventions in R (en anglais), pour plus d’informations sur les meilleures façons de nommer les objets dans R.
Pour nommer vos objets, vous pouvez utiliser des lettres (x, y, etc.) mais, quand vous travaillez avec vos propres données, il est plus pratique d’utiliser des noms représentatifs du contenu de la variable. Par exemple, avec les données AirPassengers, choisir des noms d’objets correspondant à certains mois ou années permet de savoir précisément ce qu’ils contiennent.
Pour supprimer un objet de la console, tapez rm() en indiquant le nom de l’objet dont vous voulez vous débarrasser entre les parenthèses, puis appuyez sur Entrée. Pour voir tous les objets que vous avez créés, tapez ls() dans la console et appuyez sur Entrée. Cela vous aidera à éviter d’utiliser le même nom pour plusieurs objets. C’est également important car R stocke tous les objets que vous créez dans sa mémoire ; donc, même si vous ne voyez pas un objet nommé x dans la console, il peut avoir été créé auparavant et vous pourriez accidentellement l’écraser en créant un nouvel objet appelé x.
Voici la liste des objets que nous avons créés jusqu’à présent :
ls()
[1] "AirPassengers" "Jan1949"
On a donc l’objet AirPassengers et l’objet Jan1949. Nous allons maintenant supprimer l’objet Jan1949 et taper à nouveau ls(). On voit ceci :
rm(Jan1949)
ls()
[1] "AirPassengers"
Si une fonction ne fonctionne pas ou si vous ne parvenez pas à résoudre une erreur, tapez help() dans la console pour ouvrir la page d’aide. Vous pouvez aussi faire une recherche en cliquant Aide dans la barre de menu de la console de R. Si vous voulez changer quelque chose dans le code que vous avez déjà écrit, vous pouvez réécrire le code sur une nouvelle ligne. Pour gagner du temps, utilisez les touches directionnelles de votre clavier (flèche vers le haut et flèche vers le bas) pour trouver par autocomplétion la ligne de code que vous souhaitez modifier.
Mise en pratique
-
Créez deux objets correspondant aux valeurs de janvier 1950 et de janvier 1960 du jeu de données
AirPassengers. Sur la ligne suivante, additionnez les deux objets. -
Utilisez les objets que vous venez de créer pour trouver la différence entre le nombre de passagers en 1960 et en 1950.
Solutions
1.
Créez deux objets correspondant aux valeurs de janvier 1950 et de janvier 1960 du jeu de données AirPassengers. Sur la ligne suivante, additionnez les deux objets.
Jan1950 <- 115
Jan1960 <- 417
Jan1950 + Jan1960
[1] 532
Le résultat indique que 532 000 personnes ont voyagé sur des vols internationaux en janvier 1950 et en janvier 1960.
2. Utilisez les objets que vous venez de créer pour trouver la différence entre le nombre de passagers en 1960 et en 1950.
Jan1960 - Jan1950
[1] 302
Cela signifie qu’il y a eu 302 000 passagers de plus sur les vols internationaux en janvier 1960 qu’en janvier 1950.
Créer une variable : combiner une série de valeurs dans un vecteur
Créer un objet pour chaque valeur peut être fastidieux, surtout quand on choisit des noms assez longs. À la place, on peut créer une variable qui contient plusieurs valeurs, comme toutes les valeurs correspondant à une année. Pour ce faire, il faut créer une série de valeurs que l’on appelle « vecteur » en utilisant la fonction c(). c() veut dire « combiner » et permet de mettre plusieurs valeurs dans une même variable. Par exemple, on peut créer un vecteur contenant les données de l’année 1949 d’AirPassengers, que l’on va appeler Air49 :
Air49 <- c(112,118,132,129,121,135,148,148,136,119,104,118)
On peut accéder à chaque élément du vecteur en indiquant le nom de la variable et la position de l’élément, ce que l’on appelle l’indexation par position. Celle-ci commence à 1. Ci-dessous, Air49[2] renvoie la valeur correspondant à février 1949, soit 118.
Air49[2]
[1] 118
On peut créer une série de valeurs consécutives en utilisant un signe deux-points. Voici un exemple :
y <- 1:10
y
[1] 1 2 3 4 5 6 7 8 9 10
En utilisant ces connaissances, vous pouvez utiliser l’expression suivante pour créer une variable contenant les valeurs de l’année 1949 d’AirPassengers :
Air49 <- AirPassengers[1:12]
Air49
[1] 112 118 132 129 121 135 148 148 136 119 104 118
Air49 renvoie les douze premières observations de la série temporelle AirPassengers. Vous obtenez donc la même variable que celle que nous avons créée plus haut, mais cette méthode est plus rapide et réduit le risque de faire une faute de frappe.
Pour obtenir le nombre total de passagers en 1949, vous pouvez additionner tous les éléments du vecteur en utilisant la fonction sum() :
sum(Air49)
[1] 1520
En 1949, environ 1 520 000 personnes ont voyagé sur des vols internationaux.
Enfin, la fonction length() permet de connaitre le nombre d’éléments d’un vecteur :
length(Air49)
[1] 12
Mise en pratique
- Créez une variable correspondant à l’année 1950 du jeu de données
AirPassengers. - Affichez le deuxième élément de ce vecteur.
- Combien d’éléments y a-t-il dans la variable que vous avez créée dans la question 1 ?
- Combien y a-t-il eu de passagers en 1950 ?
Solutions
1.
Air50 <- AirPassengers[13:24]
Air50
[1] 115 126 141 135 125 149 170 170 158 133 114 140
2.
Air50[2]
[1] 126
3.
length(Air50)
[1] 12
4.
sum(Air50)
[1] 1676
Pour connaitre l’évolution du nombre de passagers au fil du temps, on peut créer une variable pour chacune des années du jeu de données et utiliser certains des outils que nous avons vus. Voici une liste des variables pour les années 1949 à 1960, suivie du nombre total de passagers pour chaque année :
Air49 <- AirPassengers[1:12]
Air50 <- AirPassengers[13:24]
Air51 <- AirPassengers[25:36]
Air52 <- AirPassengers[37:48]
Air53 <- AirPassengers[49:60]
Air54 <- AirPassengers[61:72]
Air55 <- AirPassengers[73:84]
Air56 <- AirPassengers[85:96]
Air57 <- AirPassengers[97:108]
Air58 <- AirPassengers[109:120]
Air59 <- AirPassengers[121:132]
Air60 <- AirPassengers[133:144]
sum(Air49)
[1] 1520
sum(Air50)
[1] 1676
sum(Air51)
[1] 2042
sum(Air52)
[1] 2364
sum(Air53)
[1] 2700
sum(Air54)
[1] 2867
sum(Air55)
[1] 3408
sum(Air56)
[1] 3939
sum(Air57)
[1] 4421
sum(Air58)
[1] 4572
sum(Air59)
[1] 5140
sum(Air60)
[1] 5714
Ces informations nous permettent de constater que le nombre de passagers a augmenté avec le temps. On peut aller plus loin et essayer de savoir à quelles périodes de l’année les gens allaient le plus souvent en vacances, ou calculer l’augmentation du nombre de passagers au fil du temps sous forme de pourcentage.
Travailler avec de grands jeux de données
Les méthodes que nous avons utilisées plus haut ne sont pas adaptées aux jeux de données qui comptent plusieurs milliers d’observations, voire plus, décrites par des dizaines ou des centaines de variables. Compter les observations pour trouver les valeurs qui nous intéressent serait extrêmement fastidieux. Imaginez par exemple à quel point il serait difficile de trouver les informations correspondant à l’année numéro 96 dans un jeu de données couvrant 150 années.
Vous pouvez tout simplement sélectionner des lignes ou des colonnes spécifiques si le jeu de données est dans un format adéquat, de préférence de type data.frame. Chargez le jeu de données mtcars dans la console et affichez son type avec la fonction class() :
data(mtcars)
class(mtcars)
[1] "data.frame"
Affichez le contenu de ce jeu de données :
mtcars
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
Ce jeu de données fournit un aperçu des tests réalisés sur des voitures (Motor Trend Car Road Tests) par le magazine Motor Trend en 1974 2. Il contient plusieurs informations, dont le nombre de miles qu’une voiture peut parcourir avec un gallon US de carburant (un gallon correspond à 3,78 litres et un mile à 1,61 kilomètre), le nombre de cylindres de chaque modèle, son nombre de chevaux, sa puissance, son poids, le rapport de l’essieu arrière, et d’autres caractéristiques. Ces données peuvent être utilisées pour savoir quelles caractéristiques ont rendu chaque modèle plus ou moins fiable au fil du temps.
Vous pouvez sélectionner des colonnes en saisissant le nom du jeu de données suivi de crochets et du numéro de la ligne ou de la colonne qui vous intéresse. Ainsi, dans l’expression dataset[x,y], dataset correspond au jeu de données avec lequel vous travaillez, x est la ligne et y est la colonne.
Si vous voulez visualiser la première ligne du jeu de données mtcars, il faut écrire ceci dans la console :
mtcars[1,]
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21 6 160 110 3.9 2.62 16.46 0 1 4 4
Pour afficher le contenu d’une colonne, ici la deuxième, écrivez :
mtcars[,2]
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
Vous obtenez ainsi toutes les valeurs de la catégorie cyl, ou « cylindre ». On constate que la plupart des modèles de voitures ont des moteurs à quatre, six ou huit cylindres. Vous pouvez également sélectionner une seule observation en précisant une valeur pour x (la ligne) et une valeur pour y (la colonne) :
mtcars[1,2]
[1] 6
R renvoie l’observation située dans la première ligne et la deuxième colonne. Grâce à cette technique de sélection des données, vous pouvez obtenir le résumé statistique d’une ligne ou d’une colonne sans avoir à compter le nombre d’observations dans le jeu de données. Par exemple, summary(mtcars[,1]) renvoie le résumé statistique de la colonne mpg (nombre de miles par gallon) pour toutes les voitures du jeu de données mtcars :
summary(mtcars[,1])
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.40 15.42 19.20 20.09 22.80 33.90
Le résumé statistique indique que la voiture qui consomme le moins est la Toyota Corolla, avec 33,9 miles par gallon, et que la voiture la plus gourmande en carburant est la Lincoln Continental, qui permet seulement de parcourir 10,4 miles par gallon. Pour identifier les voitures correspondant aux valeurs, il suffit de regarder le tableau de données. Cette méthode est bien plus pratique pour trouver une valeur rapidement que d’essayer de faire le calcul dans sa tête ou de fouiller la feuille de calcul d’un tableur.
Data frames
Maintenant que vous comprenez mieux les fonctions de base de R, vous pouvez vous en servir pour analyser vos propres données. Pour les jeux de données de petite taille, vous pouvez créer vos propres tableaux de données, ou « data frames ». Savoir construire des tableaux est très utile car si vous avez peu de données vous pouvez simplement en créer un au lieu d’importer un fichier CSV. Le plus simple, pour construire un data frame, est de créer au moins deux variables, ou vecteurs, et de les associer. Nous allons en créer un avec des données qui se trouvent sur le site d’Old Bailey, la Cour centrale de la Couronne britannique :
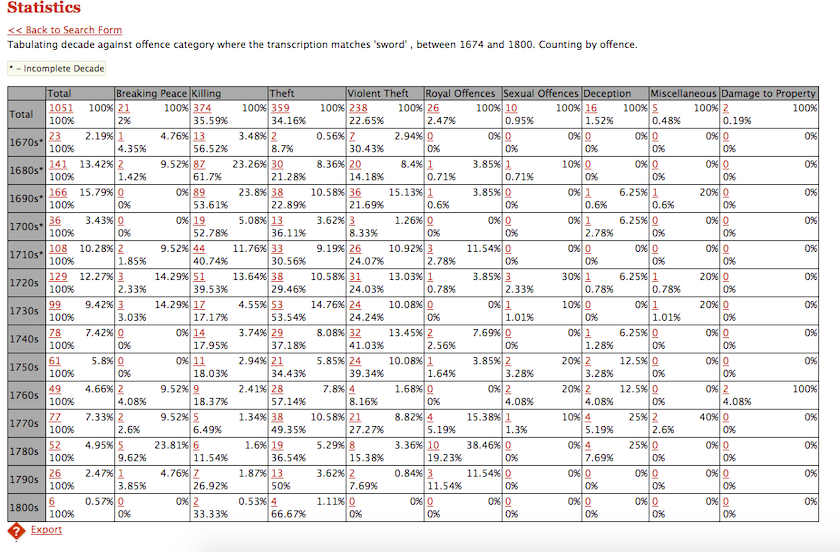
Figure 2. Le jeu de données des affaires pénales d’Old Bailey par décennie, de 1670 à 1800.
Le site d’Old Bailey fournit des statistiques et des informations sur les affaires pénales traitées par la Cour centrale de la Couronne britannique entre 1674 et 1913. On pourrait par exemple analyser le nombre d’infractions de vol et de vol avec violence pour les décennies comprises entre 1670 à 1710 en plaçant les valeurs dans un data frame.
Commençons par créer les variables Vols et VolsAvecViolence, en indiquant les valeurs correspondant à chaque décennie :
Vols <- c(2,30,38,13)
VolsAvecViolence <- c(7,20,36,3)
Pour créer un data frame, on utilise la fonction data.frame(), qui permet de juxtaposer les valeurs de plusieurs vecteurs de même taille. Nous allons associer les variables Volset VolsAvecViolence dans l’objet Crimes ci-dessous :
Vols <- c(2,30,38,13)
VolsAvecViolence <- c(7,20,36,3)
Crimes <- data.frame(Vols, VolsAvecViolence)
Crimes
Vols VolsAvecViolence
1 2 7
2 30 20
3 38 36
4 13 3
La fonction t() permet de « transposer » le data frame, c’est-à-dire de transformer les lignes en colonnes et vice versa :
Crimes2 <- t(Crimes)
Crimes2
[,1] [,2] [,3] [,4]
Vols 2 30 38 13
VolsAvecViolence 7 20 36 3
Maintenant que nous avons notre data frame, nous pouvons afficher le contenu des variables en indiquant le nom du data frame suivi de l’opérateur $et du du nom de la colonne désirée :
Crimes$Vols
[1] 2 30 38 13
Nous pouvons effectuer des calculs, en calculant par exemple le nombre total de vols :
sum(Crimes$Vols)
[1] 83
Le nombre total d’infractions de vol et de vol avec violence :
sum(Crimes)
[1] 149
Ou bien le nombre moyen de vols avec violence par décennie :
mean(Crimes$VolsAvecViolence)
[1] 16.5
La fonction apply() permet d’exécuter la même fonction sur chaque ligne ou colonne d’un data frame. Elle prend trois arguments : le nom du data frame , 1 pour appliquer la fonction sur les lignes ou 2 sur les colonnes, et enfin le nom de la fonction que l’on veut exécuter sur le data frame :
Crimes
Vols VolsAvecViolence
1 2 7
2 30 20
3 38 36
4 13 3
apply(Crimes, 1, mean)
[1] 4.5 25.0 37.0 8.0
L’exemple ci-dessus montre comment utiliser la fonction apply() sur le data frame Crimes pour calculer la moyenne de chaque ligne, afin de connaitre le nombre moyen de l’ensemble des vols (avec ou sans violence) commis pendant chaque décennie. Pour obtenir la moyenne de chaque colonne, il faut indiquer 2 à la place de 1 dans la fonction :
apply(Crimes, 2, mean)
Vols VolsAvecViolence
20.75 16.50
Le résultat indique le nombre moyen de vols et le nombre moyen de vols avec violence entre 1670 à 1710.
Mise en pratique
- Créez deux variables intitulées
ViolationsPaix, contenant les valeurs2,3,3, etMeurtres, contenant les valeurs44,51,1. Elles indiquent le nombre de Breaking Peace (Violations de la Paix) — une catégorie qui comprend diverses infractions comme les agressions, menaces et voies de fait) — et le nombre de meurtres entre 1710 et 1730, selon le tableau d’Old Bailey présenté plus haut. - Utilisez la fonction
data.frame()pour combinerViolationsPaixetMeurtresdans un data frame que vous appellerezCrimes3. Affichez le data frame. - Calculez la moyenne de chaque colonne du data frame créé dans la question 2 en utilisant la fonction
apply().
Solutions
1.
ViolationsPaix <- c(2,3,3)
Meurtres <- c(44,51,17)
2.
Crimes3 <- data.frame(ViolationsPaix, Meurtres)
Crimes3
ViolationsPaix Meurtres
1 2 44
2 3 51
3 3 17
3.
apply(Crimes3, 2, mean)
ViolationsPaix Meurtres
2.666667 37.333333
Créer un data frame soi-même peut être utile quand on a peu de données. Toutefois, ce n’est pas toujours la meilleure solution car cela peut être fastidieux. Il est parfois plus pratique de créer un fichier avec un tableur comme Excel ou Open Office. Vous pourrez ainsi vous assurer que toutes les informations que vous voulez analyser sont organisées correctement, puis importer le fichier dans R.
Charger votre propre jeu de données dans R
Maintenant que vous vous êtes entrainé·e avec des données simples, vous pouvez commencer à travailler avec vos propres données. Celles-ci se trouvent sans doute sur une feuille de calcul créée avec un tableur. Comment les charger dans R ? Il y a plusieurs solutions. Tout d’abord, vous pouvez charger une feuille de calcul Excel directement dans R. Il est également possible d’importer un fichier CSV ou TXT dans R.
Pour charger directement un fichier Excel dans la console de R, il faut d’abord avoir installé le package readxl en tapant install.packages("readxl") dans la console puis en appuyant sur Entrée. Vous devrez ensuite charger le package, ce que vous pouvez faire de deux façons : en entrant library(readxl) dans la console, ou en cliquant sur Gestionnaire de packages dans l’onglet Packages & Données du menu de R et cochant la case située à gauche du package readxl. Ensuite, vous pourrez sélectionner un fichier et le charger dans R. Voici un exemple qui montre comment faire :
x <- read_excel("MonFichier.xlsx")
x
a b
1 1 5
2 2 6
3 3 7
4 4 8
Après la commande read_excel, indiquez le nom de votre fichier dans les parenthèses, en le mettant entre guillemets. Les nombres ci-dessus correspondent aux données entrées dans mon fichier. On peut voir que les lignes sont numérotées et que les colonnes ont le nom que je leur ai donné dans ma feuille de calcul Excel.
Quand vous chargez des données dans R, assurez-vous que votre fichier se trouve bien dans le répertoire de travail de votre ordinateur. Pour le vérifier vous pouvez utiliser la fonction dir(), qui affiche la liste des fichiers et des sous-répertoires du répertoire de travail, ou la fonction getwd(), qui renvoie le chemin du répertoire de travail. Vous pouvez changer le répertoire de travail en allant sur l’onglet Divers du menu de R, puis en cliquant sur Changer de Répertoire de Travail et en sélectionnant le répertoire de votre choix. Si le fichier que vous voulez charger n’est pas dans le répertoire de travail, R ne pourra pas le trouver.
On peut également charger des fichiers CSV dans R, ce qui est la méthode la plus communément utilisée. Un fichier CSV, ou « comma-separated values » (valeurs séparées par des virgules), est un fichier contenant des données tabulaires et dans lequel les virgules correspondent aux séparations entre les colonnes. Vous pouvez enregistrer tous les documents Excel au format .csv et ensuite les charger dans R. Pour ce faire, il faut donner un nom à votre fichier en utilisant la commande <- et l’expression read.csv(file="nom-du-fichier.csv", header=TRUE, sep=",") dans la console. nom-du-fichier indique à R quel fichier ouvrir et l’argument header=TRUE précise que la première ligne est composée des noms des colonnes et non d’observations. sep signifie que les valeurs sont séparées par des virgules.
Il est important de noter ici que les tableurs configurés en langue française utilisent généralement des points-virgules pour séparer les colonnes et non des virgules. Pourquoi ? Parce qu’en français les virgules servent à séparer les décimales. Si vous utilisez la fonction ci-dessus, vous risquez de ne pas pouvoir charger votre fichier correctement. Il y a deux solutions simples : utiliser la fonction read.csv() en indiquant le point-virgule comme séparateur (read.csv(file="nom-du-fichier.csv",header=TRUE,sep=";")) ou utiliser la fonction read.csv2() de la façon suivante : read.csv(file="nom-du-fichier.csv"). Enfin, si votre fichier comporte des nombres avec décimales séparées par des virgules, il faudra remplacer les virgules par des points avant d’ouvrir votre fichier (par exemple en utilisant la fonctionnalité Rechercher et Remplacer. Sinon, R considèrera les nombres comme du texte.
Un fichier CSV peut contenir de très nombreuses données, mais nous allons faire simple pour commencer. Nous allons créer un fichier CSV, avec Excel ou tout autre tableur, en utilisant les données d’Old Bailey utilisées dans la section sur les data frames. On a besoin de trois colonnes : une colonne Date qui indique les décennies 1710, 1720 et 1730, une colonne ViolationsPaix qui indique le nombre de violations de la paix (Breaking Peace dans le tableau de données d’Old Bailey) et une colonne Meurtres qui indique le nombre de meurtres (Killing*) correspondant à chaque décennie.
Enregistrez le fichier au format CSV (et non CSV2) en lui donnant le nom OldBailey.csv. Puis, chargez les données dans R en suivant les explications ci-dessus. Normalement, vous devriez voir ceci :
read.csv(file="OldBailey.csv",header=TRUE,sep=",")
Date ViolationsPaix Meurtres
1 1710 2 44
2 1720 3 51
3 1730 4 17
Vous pouvez maintenant accéder aux données dans R et effectuer les calculs de votre choix. Les fichiers CSV peuvent être bien plus complexes que l’exemple fourni ci-dessus, bien entendu, et ils peuvent tous être ouverts dans R.
Les fichiers TXT (ou fichiers texte brut) peuvent être importés dans R d’une façon similaire aux fichiers CSV : utilisez la fonction read.table(), avec la même syntaxe que pour la fonction read.csv.
Enregistrer des données dans R
Vous savez désormais comment charger des données dans R et vous avez des bases vous permettant de les analyser. Vous pouvez sauvegarder vos données sous un autre format, en utilisant par exemple la fonction write.csv() pour créer un fichier CSV.
write.csv(OldBailey, file ="OldBailey.csv")
Il est également possible de créer un fichier Excel avec la fonction write.xlsx(). Installez le package xlsx, chargez-le dans R et créez un fichier Excel avec les données d’Old Bailey :
library(xlsx)
write.xlsx(x = OldBailey, file = "OldBailey.xlsx", sheetName = "OldBailey", row.names = TRUE)
Conclusion et autres ressources
Ce tutoriel vous a présenté les bases de R pour travailler avec des données tabulaires. R est un outil très utile pour la recherche en sciences humaines et sociales, notamment parce qu’il permet de créer des analyses reproductibles et d’analyser des données rapidement, sans mettre en place un système complexe. Maintenant que vous avez quelques bases, vous pouvez explorer les autres fonctions de R pour faire des analyses statistiques, réaliser des graphiques et créer vos propres fonctions.
Pour en savoir plus sur R, consultez le manuel de R (en anglais).
Vous trouverez en ligne de nombreux tutoriels sur R. Nous vous conseillons :
- R: A self-learn tutorial (en anglais). Ce tutoriel passe en revue plusieurs fonctions et propose des exercices pour s’entrainer.
- Introduction à R. Cours proposé par le site Datacamp qui vous permet de vous entrainer en ligne (gratuit, mais il faut s’inscrire pour y accéder). Les exercices interactifs permettent d’identifier vos erreurs et d’apprendre à écrire du code plus efficacement.
- R pour les débutants. Écrit par Emmanuel Paradis, il s’agit d’un des premiers manuels francophones d’introduction à R.
- L’ouvrage Computational Historical Thinking. Écrit par Lincoln A. Mullen, c’est une ressource précieuse pour les historiennes et historiens qui souhaitent utiliser R pour faire leurs travaux de recherche.