
Conteúdos
- Introdução
- O corpus - Contextualização
- Nossos casos de teste
- Preparando os dados para análise
- Primeiro teste estilométrico: curvas características de composição de Mendenhall
- Segundo teste estilométrico: método qui-quadrado de Kilgariff
- Terceiro teste estilométrico: método Delta de John Burrows (avançado)
- Leituras adicionais e recursos
- Agradecimentos
- Notas finais
Introdução
Estilometria é o estudo quantitativo do estilo literário por meio de métodos de leitura distante computacional. É baseado na observação de que os autores tendem a escrever de maneiras relativamente consistentes, reconhecíveis e únicas. Por exemplo:
- Cada pessoa tem seu próprio vocabulário único, às vezes rico, às vezes limitado. Embora um vocabulário mais amplo esteja geralmente associado à qualidade literária, nem sempre é esse o caso. Ernest Hemingway é famoso por usar um número surpreendentemente pequeno de palavras diferentes em sua escrita,1 o que não o impediu de ganhar o Prêmio Nobel de Literatura em 1954;
- Algumas pessoas escrevem frases curtas, enquanto outras preferem blocos longos de texto compostos por muitas frases;
- Não há duas pessoas que usem ponto-e-vírgulas, travessões e outras formas de pontuação exatamente da mesma maneira.
As maneiras como os escritores usam pequenas function words, como artigos, preposições e conjunções, mostram-se particularmente reveladoras. Em uma pesquisa dos métodos estilométricos históricos e atuais, Efstathios Stamatatos aponta que as palavras funcionais são “usadas de maneira amplamente inconsciente pelos autores e são independentes do tópico”2. Para a análise estilométrica, isso é muito vantajoso, visto que esse padrão inconsciente tende a variar menos no corpus de um autor do que seu vocabulário geral (e também é muito difícil para um pretenso falsificador copiar). As palavras funcionais também foram identificadas como marcadores importantes do gênero literário e da cronologia.
Os pesquisadores têm usado a estilometria como uma ferramenta para estudar uma variedade de questões culturais. Por exemplo, uma quantidade considerável de pesquisas estudou as diferenças entre as maneiras como homens e mulheres escrevem3 ou sobre o que escrevem.4 Outros pesquisadores estudaram as maneiras como uma mudança repentina no estilo de escrita em um único texto pode indicar plágio5 e até mesmo a maneira como as letras dos músicos John Lennon e Paul McCartney se tornaram cada vez menos alegres e menos ativas à medida que os Beatles se aproximavam do fim de sua carreira de gravação na década de 1960.6
No entanto, uma das aplicações mais comuns da estilometria é na atribuição de autoria. Dado um texto anônimo, às vezes é possível inferir quem o escreveu medindo certas características, como o número médio de palavras por frase ou a propensão do autor de usar “todavia” em vez de “no entanto”, e comparando as medidas com outros textos escritos pelo suposto autor. Este é o objetivo deste tutorial, onde a partir de um conjunto de obras clássicas de romancistas lusos e brasileiros do século XIX iremos comparar exemplares de suas obras com o estilo literário do conjunto de autores a fim de tentar inferir suas respectivas autorias (nota de tradução: foi decidido mudar o corpus usado nesta lição para um que fosse culturalmente mais relevante para o público que fala e escreve português; foi mantida a restante estrutura da lição original, com excepção de ligeiras adaptações face à mudança do corpus).
Objetivos de aprendizado
No final desta lição, teremos percorrido os seguintes tópicos:
- Como aplicar vários métodos estilométricos para inferir a autoria de um texto anônimo ou conjunto de textos;
- Como usar estruturas de dados relativamente avançadas, incluindo dicionários de strings e dicionários de dicionários, em Python;
- O básico do Natural Language Toolkit (NLTK), um módulo Python popular dedicado a processamento de linguagem natural.
Leitura prévia
Se você não tem experiência com a linguagem de programação Python ou está tendo dificuldade nos exemplos apresentados neste tutorial, o autor recomenda que você leia as lições Trabalhando com ficheiros de texto em Python e Manipular Strings com Python. Note que essas lições foram escritas em Python versão 2, enquanto esta usa Python versão 3. As diferenças de sintaxe entre as duas versões da linguagem podem ser sutis. Se você ficar em dúvida, siga os exemplos conforme descritos nesta lição e use as outras lições como material de apoio. (Este tutorial encontra-se atualizado até à versão Python 3.8.5; as strings literais formatadas na linha with open(f'data/pg{filename}.txt', 'r', encoding='utf-8') as f:, por exemplo, requerem Python 3.6 ou uma versão mais recente da linguagem.)
Materiais requeridos
Este tutorial usa conjuntos de dados e software que você terá que baixar e instalar.
O conjunto de dados
Para trabalhar nesta lição, você precisará baixar e descompactar o ficheiro .zip contendo as 15 obras que compõem o corpus que será utilizado neste tutorial. As obras foram originalmente extraídas do Projeto Gutenberg. Ao descompactar o ficheiro, será criada uma pasta com o nome dados. Este será o seu diretório de trabalho e todo o trabalho deve ser salvo aqui durante a execução da lição.
O software
Esta lição usa as seguintes versões da linguagem Python e bibliotecas:
- Python 3.x - a última versão estável é recomendada;
- nltk - Natural Language Toolkit, geralmente abreviado
nltk; - matplotlib - visualização de dados e geração de gráficos;
- re - limpeza de dados via Regex (veremos durante o tutorial o porquê).
Alguns desses módulos podem não estar pré-instalados em seu computador. Se você encontrar mensagens de erro como: “Módulo não encontrado” ou similares, você terá que baixar e instalar o(s) módulo(s) ausente(s). A forma mais simples de realizar esta tarefa é através do comando pip. Mais detalhes estão disponíveis através do tutorial do Programming Historian Instalação de Módulos Python com pip.
Algumas notas sobre Independência Linguística
Este tutorial aplica a análise estilométrica a um conjunto de textos em português (PT-PT e PT-BR) usando uma biblioteca Python chamada nltk. Muitas das funcionalidades fornecidas pelo nltk operam com outros idiomas. Contanto que um idioma forneça uma maneira clara de distinguir os limites de uma palavra, o nltk deve ter um bom desempenho. Idiomas como o chinês, para os quais não há distinção clara entre os limites das palavras, podem ser problemáticos. O autor original desta lição utilizou nltk com textos em francês sem nenhum problema; outros idiomas que usam diacríticos, como espanhol e alemão, também devem funcionar bem com nltk. Consulte a documentação do nltk para obter detalhes.
Apenas uma das tarefas neste tutorial requer código dependente do idioma. Para dividir um texto em um conjunto de palavras em uma língua diferente do inglês, você precisará especificar o idioma apropriado como um parâmetro para o tokenizador da biblioteca nltk, que usa o inglês como padrão. Isso será explicado no tutorial.
Por fim, observe que algumas tarefas linguísticas, como part-of-speech tagging, podem não ser suportadas pelo nltk em outros idiomas além do inglês. Este tutorial não cobre a aplicação de part-of-speech tagging. Se você precisar para os seus próprios projetos, consulte a documentação do nltk para obter orientações.
O corpus - Contextualização
No exemplo original deste tutorial em inglês, utilizaram-se os papéis federalistas como um exemplo de aplicação de estilometria, utilizando as técnicas que serão apresentadas para inferir a autoria dos textos contestados dentro do conjunto de documentos que configura o corpus.7 Como na língua portuguesa não temos um conjunto de textos que possua estas mesmas características, no exemplo que apresentaremos traremos um total de 15 obras completas de 5 autores diferentes, três deles portugueses e dois brasileiros, todos romancistas do século XIX, disponibilizadas pelo Projeto Gutenberg. Utilizaremos duas obras de cada autor para definir seus respectivos estilos e uma terceira para constituir o conjunto de testes, para avaliarmos se as técnicas utilizadas realizarão a inferência correta de autoria através do grau de similaridade de cada obra deste conjunto com o estilo obtido de cada autor.
Os autores e obras utilizadas são os seguintes:
| Autor | Obra 1 | Obra 2 | Obra 3 |
|---|---|---|---|
| Machado de Assis (Brasil) | Quincas Borba (55682) | Memorias Posthumas de Braz Cubas (54829) | Dom Casmurro (55752) |
| José de Alencar (Brasil) | Ubirajara (38496) | Cinco minutos (44540) | Como e porque sou romancista (29040) |
| Camilo Castelo Branco (Portugal) | Carlota Angela (26025) | Amor de Salvação (26988) | Amor de Perdição: Memorias d’uma familia (16425) |
| António Feliciano de Castilho (Portugal) | A Chave do Enigma (32002) | A Primavera (65021) | O presbyterio da montanha (28127) |
| Manuel Pinheiro Chagas (Portugal) | Historia alegre de Portugal (29394) | A Lenda da Meia-Noite (23400) | Astucias de Namorada, e Um melodrama em Santo Thyrso (29342) |
As partes destacadas do nome de cada autor indicam como os mesmos serão referenciados neste tutorial a partir deste ponto. Para os códigos utilizaremos o EBook-No. (número de referência da obra no Projeto Gutenberg), presente no nome dos ficheiros disponibilizados.
Nossos casos de teste
Nesta lição, usaremos obras de romancistas brasileiros e portugueses do século XIX como um estudo de caso para demonstrar três abordagens estilométricas diferentes:
- Curvas características de composição de Mendenhall
- Método Qui-Quadrado de Kilgariff
- Método Delta de John Burrows
Em todas as abordagens acima mencionadas, utilizaremos os documentos das colunas Obra 1 e Obra 2 para definir o estilo de cada autor. Os documentos da coluna Obra 3 serão testados individualmente com cada um dos 5 autores para tentarmos inferir a autoria pela proximidade de estilo.
Preparando os dados para análise
Antes de prosseguirmos com a análise estilométrica, precisamos carregar os ficheiros contendo todas as 15 obras em estruturas de dados na memória do computador.
O primeiro passo neste processo é designar cada obra para o seu respectivo conjunto. Como cada obra está relacionada com o seu respectivo EBook-No., podemos atribuir cada obra (valor) à chave do seu autor (ou a uma chave separada, se ela fizer parte da amostra de teste) usando um dicionário Python. O dicionário é um tipo de conjunto de dados composto de um número arbitrário de pares de chave-valor; neste caso, os nomes dos autores servirão como chaves (separados entre treino e teste), enquanto os EBook-No. das obras serão os valores associados a essas chaves.
ids_obras = {
'Assis' : [55752, 54829],
'Alencar' : [38496, 44540],
'Castelo Branco' : [26025, 26988],
'Castilho' : [32002, 65021],
'Chagas' : [29394, 23400],
'Assis (teste)' : [55682],
'Alencar (teste)' : [29040],
'Castelo Branco (teste)' : [16425],
'Castilho (teste)' : [28127],
'Chagas (teste)' : [29342]
}
Os dicionários Python são muito flexíveis. Por exemplo, podemos acessar um valor específico indexando o dicionário com uma de suas chaves, podemos varrer o dicionário inteiro fazendo um loop em sua lista de chaves, etc. Faremos amplo uso desta funcionalidade à medida que avançarmos.
A seguir, como estamos interessados no vocabulário de cada autor, definiremos uma breve função em Python que irá criar uma longa lista de palavras em cada uma das obras atribuídas a um único autor. Isso será armazenado como uma string. Abra o seu ambiente de desenvolvimento Python escolhido. Se você não sabe como fazer isso, leia “Configurar um ambiente de desenvolvimento integrado para Python” (Windows, Linux, Mac) antes de prosseguir.
# Função que compila todos os ficheiros de texto de cada grupo em uma única string
import re
def ler_ficheiros_para_string(ids_ficheiros):
global texto
strings = []
for id_ficheiro in ids_ficheiros:
with open(f'dados/pg{id_ficheiro}.txt', 'r',
encoding='utf-8') as f:
texto = f.read()
texto = re.search(r"(START.*?\*\*\*)(.*)(\*\*\* END)",
texto,
re.DOTALL).group(2)
strings.append(texto)
return '\n'.join(strings)
Perceba que, dentro da função, temos também uma etapa de limpeza dos textos usando expressões regulares. Isso foi necessário para este corpus específico pois as obras publicadas no Projeto Gutenberg possuem uma estrutura de cabeçalho e rodapé de metadados que não pode ser considerada na análise estilométrica, uma vez que não foram redigidas pelos autores analisados. A utilização de expressões regulares não faz parte do escopo deste tutorial, então limitaremo-nos a compreender que estamos utilizando a biblioteca re para capturar apenas o conjunto de caracteres entre os marcadores *** START OF THIS PROJECT GUTENBERG [NOME DA OBRA] *** e *** END OF THIS PROJECT GUTENBERG [NOME DA OBRA] *** presentes em cada documento do projeto. Para maiores dúvidas sobre a utilização de expressões regulares e da biblioteca re, consulte a documentação.
Na sequência, construímos uma nova estrutura de dados chamando repetidamente a função ler_ficheiros_para_string (), passando a ela uma lista diferente de documentos a cada vez. Armazenaremos os resultados em outro dicionário, este com nomes do autor/caso de teste como chaves e todo o texto dos respectivos documentos como valores. Para simplificar, iremos nos referir à string contendo uma lista de documentos como “corpus do autor”.
# Criar um dicionário com os corpora dos autores
obras = {}
for autor, ids_ficheiros in ids_obras.items():
obras[autor] = ler_ficheiros_para_string(ids_ficheiros)
Para nos certificarmos de que os ficheiros foram carregados corretamente, imprima os primeiros cem caracteres de cada entrada do dicionário na tela:
for autor in obras:
print(obras[autor][:100])
Se esta operação de impressão exibir quaisquer trechos de texto no console, então a operação de leitura dos ficheiros funcionou conforme o esperado e você pode prosseguir para a análise estilométrica.
Primeiro teste estilométrico: curvas características de composição de Mendenhall
O pesquisador literário T. C. Mendenhall escreveu certa vez que a assinatura estilística de um autor pode ser encontrada contando a frequência com que usa palavras de tamanhos diferentes.8 Por exemplo, se contarmos os tamanhos de palavras em vários segmentos de 1.000 ou 5.000 palavras de qualquer romance e, em seguida, traçarmos um gráfico das distribuições de comprimento das palavras, as curvas pareceriam praticamente as mesmas, não importando que partes do romance tivéssemos escolhido. Na verdade, Mendenhall acreditava que se alguém contasse palavras suficientes selecionadas de várias partes da obra de toda a vida de um escritor (digamos, 100.000 ou mais), a “curva característica” de uso de comprimento de palavras do autor se tornaria tão precisa que seria constante ao longo de sua vida.
Pelos padrões de hoje, contar o comprimento das palavras parece uma forma muito direta (e talvez simplista) de medir o estilo literário. O método de Mendenhall não leva em consideração as palavras do vocabulário de um autor, o que é obviamente problemático. Portanto, não devemos tratar as curvas características como uma fonte particularmente confiável de evidência estilométrica. No entanto, Mendenhall publicou a sua teoria há mais de cento e trinta anos e fez todos os cálculos à mão. É compreensível que ele tivesse optado por trabalhar com uma estatística que, embora grosseira, fosse ao menos fácil de compilar. Em honra ao valor histórico de sua tentativa inicial de estilometria, e porque a curva característica produz resultados visuais interessantes que podem ser implementados rapidamente, usaremos o método de Mendenhall como um primeiro passo em nossa exploração das técnicas de atribuição de autoria.
O trecho de código necessário para calcular e exibir as curvas características para os autores e os documentos de teste é o seguinte:
# Carregar nltk e matpotlib
import nltk
nltk.download('punkt')
import matplotlib.pylab as plt
obras_tokens = {}
obras_distribuicao_comprimento = {}
id_subplot = 1
fig = plt.figure(figsize=(20,20))
autores = list(obras.keys())
for autor in autores:
# Transformar os corpora dos autores em listas de tokens de palavras
tokens = nltk.word_tokenize(obras[autor], language="portuguese")
# Filtrar pontuação
obras_tokens[autor] = ([token for token in tokens
if any(c.isalpha() for c in token)])
# Obter a distribuição de comprimentos de tokens
token_comprimentos = [len(token) for token in obras_tokens[autor]]
obras_distribuicao_comprimento[autor] = nltk.FreqDist(token_comprimentos)
# Plotar a curva característica de composição
lista_chaves = []
lista_valores = []
for i in range(1,16):
lista_chaves.append(i)
lista_valores.append(obras_distribuicao_comprimento[autor][i])
lista_valores_normalizado = [value/max(lista_valores) for value in lista_valores]
plt.subplot(5, 5, id_subplot)
plt.plot(lista_chaves, lista_valores_normalizado)
plt.xticks(lista_chaves)
plt.title(autor)
id_subplot += 1
plt.savefig("stilometry_comparacao.jpeg", dpi=300, bbox_inches='tight')
plt.show()
Se você estiver trabalhando em um Jupyter Notebook, adicione a expressão %matplotlib inline após a importação das bibliotecas; caso contrário, você pode não ver os gráficos em sua tela. Se você estiver trabalhando em um Jupyter Lab, substitua esta expressão por %matplotlib ipympl.
A primeira linha no trecho de código acima carrega o módulo Natural Language Toolkit (nltk), que contém um número enorme de funções e recursos úteis para processamento de texto. Mal tocaremos em seus fundamentos nesta lição; se você decidir explorar mais a análise de texto em Python, recomendo fortemente que comece com a documentação do nltk.
As próximas linhas configuram estruturas de dados que serão preenchidas pelo bloco de código dentro do loop for. Este loop faz os mesmos cálculos para todos os nossos “autores”:
- Invoca o método
word_tokenize()donltk, explicitando a linguagem do corpus para português através do argumentolanguage="portuguese", e divide o corpus em tokens, ou seja, palavras, números, pontuação, etc.; - Olha para esta lista de tokens e filtra as não-palavras;
- Cria uma lista contendo os comprimentos de cada token de palavra restante;
- Cria um objeto de distribuição de frequência a partir dessa lista de comprimentos de palavra, basicamente contando quantas palavras de uma letra, palavras de duas letras, etc., existem no corpus do autor, e em seguida realiza a normalização dessa distribuição, ou seja, ajusta todos os valores em um intervalo entre 0 e 1. Esta etapa é realizada para comparar gráficos de distribuição em corpus de tamanhos diferentes de forma mais clara;
- Plota um gráfico da distribuição de comprimentos de palavras no corpus, para todas as palavras de até 15 caracteres.
Os resultados que obtemos são os seguintes:
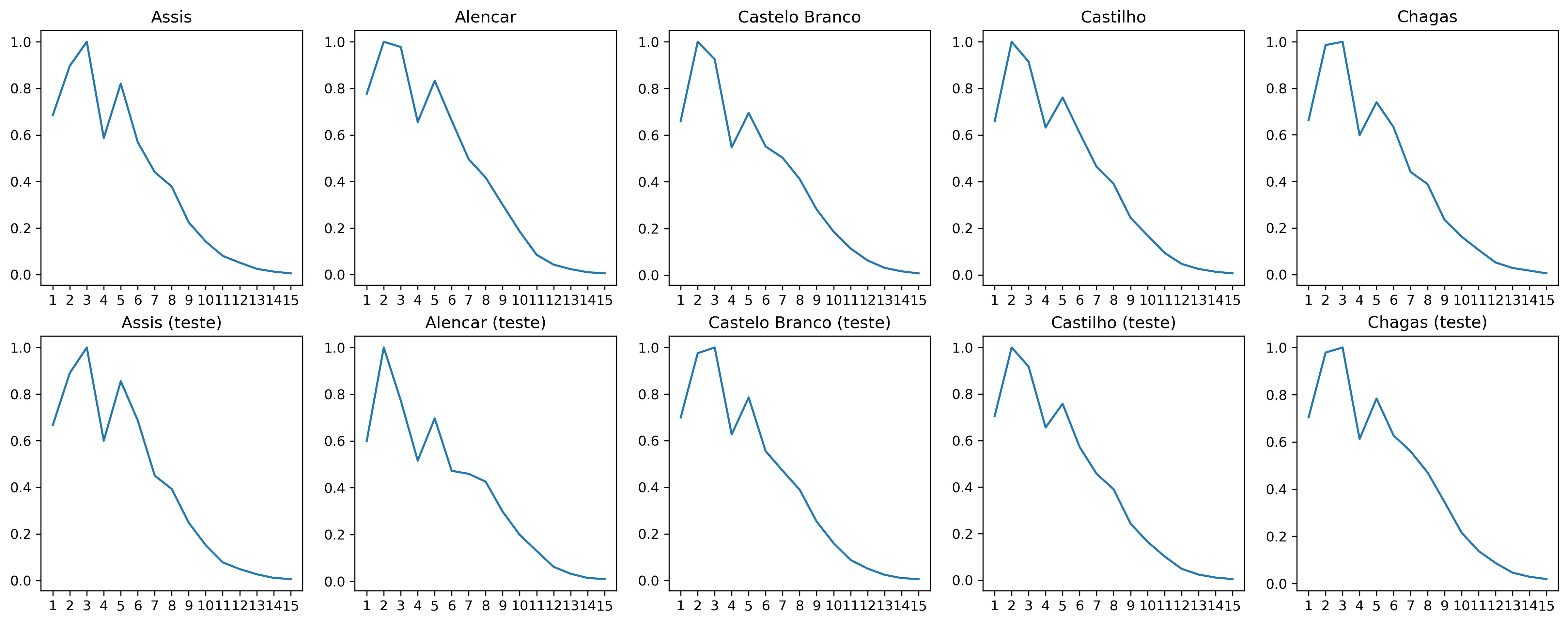
Imagem 1: Comparação da curva de Mendenhall para cada corpus.
Como podemos ver pelos gráficos, é possível notar diferenças (embora sutis) entre todas as 5 curvas características de cada autor (linha superior de gráficos). Ao compararmos os documentos de teste (linha inferior de gráficos) com os autores, podemos notar que a curva característica dos documentos de teste dos autores Assis, Castilho e Chagas se assemelham mais à curva dos seus respectivos autores que de qualquer outro, o que seriam inferências corretas. O documento de Alencar é o que mais diverge da curva característica do autor. Isso pode ocorrer pelo fato do documento de teste ser uma autobiografia do autor, enquanto os documentos de treino são duas obras de ficção, o que poderia influenciar no seu estilo de escrita. Veremos nas próximas abordagens se conseguimos contornar esta situação. O documento de Castelo Branco também parece não ter se assemelhado à curva característica do autor.
Para além desta análise meramente visual (que pode muitas vezes induzir ao erro), podemos ter um resultado quantitativo calculando a soma das distâncias entre os valores (normalizados) de frequência de cada documento de teste com os valores de frequência do corpus de cada possível autor. Por consequência, o autor que possuir a menor distância de frequência com o documento de teste seria o mais provável autor deste documento. Podemos implementar isso da seguinte forma:
# Dividir a lista de corpus entre autores e obras destacadas
autores = list(obras.keys())[:5]
obras_destacadas = list(obras.keys())[5:]
obras_distribuicao_comprimento_normalizado = {}
# Normalizar a distribuição de comprimentos de tokens em um novo dicionário
for index, obra in obras_distribuicao_comprimento.items():
obras_distribuicao_comprimento_normalizado[index] = {k:
v/max(obra.values())
for k, v in dict(obra).items()}
# Calcular a soma da diferença da distribuição entre o documento de teste e cada autor (de 1 até 15 caracteres)
for obra in obras_destacadas:
for autor in autores:
soma_diferenca = 0
for i in range(1,16):
diferenca = abs(obras_distribuicao_comprimento_normalizado[obra][i] -
obras_distribuicao_comprimento_normalizado[autor][i])
soma_diferenca = soma_diferenca + diferenca
print('A soma da diferença do documento ' +
obra +
' para o autor ' +
autor +
' é ' +
str(soma_diferenca))
print('\n')
O resultado deste trecho serão 5 blocos, cada um comparando um documento com os 5 possíveis autores. Abaixo o exemplo de como o primeiro bloco deve parecer:
A soma da diferença do documento Assis (teste) para o autor Assis é 0.25782806530977137
A soma da diferença do documento Assis (teste) para o autor Alencar é 0.5192643726222002
A soma da diferença do documento Assis (teste) para o autor Castelo Branco é 0.7410205025846326
A soma da diferença do documento Assis (teste) para o autor Castilho é 0.46876355973646266
A soma da diferença do documento Assis (teste) para o autor Chagas é 0.3466043230715998
Vamos colocar os resultados dos 5 testes em uma matriz de confusão (limitando a 4 casas decimais) para avaliarmos:
| Assis | Alencar | Castelo Branco | Castilho | Chagas | |
|---|---|---|---|---|---|
| Assis (teste) | 0.2578 | 0.5192 | 0.7410 | 0.4687 | 0.3466 |
| Alencar (teste) | 0.9744 | 0.9844 | 0.4313 | 0.6979 | 0.7897 |
| Castelo Branco (teste) | 0.2812 | 0.4436 | 0.4761 | 0.2772 | 0.2803 |
| Castilho (teste) | 0.4396 | 0.4624 | 0.4114 | 0.1394 | 0.3184 |
| Chagas (teste) | 0.7746 | 0.5883 | 0.6636 | 0.6732 | 0.5888 |
Os documentos de teste de Assis e Castilho possuem menor valor com seus respectivos autores, o que indica a maior proximidade. Isso é condizente com a similaridade dos gráficos que vimos anteriormente. O documento de teste de Chagas teve um “empate técnico” entre o estilo do próprio autor (0.5888) e Alencar (0.5883). Tanto os documentos de teste de Alencar quanto Castelo Branco ficaram com o maior valor em relação aos seus respectivos autores, logo a técnica não foi eficaz para estes dois autores.
Se não tivéssemos informações adicionais para trabalharmos, poderíamos inferir corretamente 50% da atribuição de autoria (2 acertos, 2 erros e um “empate”), o que é um resultado considerável para uma técnica relativamente simples. Felizmente, a ciência estilométrica avançou muito desde a época de Mendenhall.
Segundo teste estilométrico: método qui-quadrado de Kilgariff
Em um artigo de 2001, Adam Kilgarriff9 recomenda o uso da estatística qui-quadrado para determinar a autoria. Leitores familiarizados com métodos estatísticos podem se lembrar que o qui-quadrado às vezes é usado para testar se um conjunto de observações (digamos, as intenções dos eleitores conforme declarado em uma pesquisa) segue uma certa distribuição de probabilidade ou padrão. Não é isso que buscamos aqui. Em vez disso, simplesmente usaremos a estatística para medir a “distância” entre os vocabulários empregados em dois conjuntos de textos. Quanto mais semelhantes os vocabulários, mais provável é que o mesmo autor tenha escrito os textos em ambos os conjuntos. Isso pressupõe que o vocabulário de uma pessoa e os padrões de uso das palavras são relativamente constantes.
Veja como aplicar a estatística para atribuição de autoria:
- Pegue os corpora associados a dois autores;
- Junte-os em um único corpus, maior;
- Conte os tokens para cada uma das palavras que podem ser encontradas neste corpus maior;
- Selecione as
npalavras mais comuns no corpus maior; - Calcule quantos tokens dessas
npalavras mais comuns esperaríamos encontrar em cada um dos dois corpora originais se fossem do mesmo autor. Isso significa simplesmente dividir o número de tokens que observamos no corpus combinado em dois valores, com base nos tamanhos relativos das contribuições dos dois autores para o corpus comum; -
Calcule uma distância qui-quadrada somando, sobre as
npalavras mais comuns, os quadrados das diferenças entre os números reais de tokens encontrados no corpus de cada autor e os números esperados, divididos pelos números esperados; A Figura 2 mostra a equação para a estatística qui-quadrado, onde C(i) representa o número observado de tokens para o recurso ‘i’ e E(i), o número esperado para esse recurso.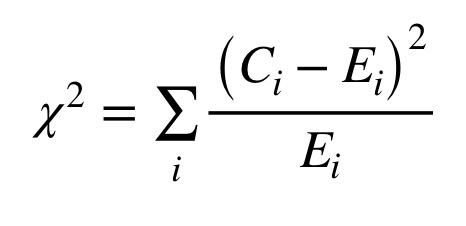
Imagem 2: Equação para a estatística qui-quadrado.
Quanto menor o valor do qui-quadrado, mais semelhantes são os dois corpora. Portanto, calcularemos o qui-quadrado de cada documento de teste com os 5 possíveis autores: os menores valores representarão a possível autoria de cada documento (assim como vimos no primeiro exemplo).
Nota: Independentemente do método estilométrico que usamos, a escolha de n, o número de palavras a levar em consideração, é uma espécie de arte sombria. Na literatura pesquisada por Stamatatos2, pesquisadores sugeriram entre 100 e 1.000 das palavras mais comuns; um projeto chegou a usar cada palavra que aparecia no corpus pelo menos duas vezes. Como diretriz, quanto maior o corpus, maior o número de palavras que podem ser usadas como elementos sem correr o risco de dar importância indevida a uma palavra que ocorra apenas algumas vezes. Nesta lição, usaremos um n relativamente grande para o método qui-quadrado e um menor para o próximo método. Mudar o valor de n certamente mudará um pouco os resultados numéricos; no entanto, se uma pequena modificação de n causar uma mudança na atribuição de autoria, isso é um sinal de que o teste que você está realizando não é capaz de fornecer evidências significativas sobre o seu caso de teste.
O seguinte trecho de código implementa o método de Kilgariff, com as frequências das 500 palavras mais comuns no corpus conjunto sendo usadas no cálculo:
# Converter os tokens para caracteres minúsculos para que a mesma palavra,
# maiúscula ou não, conte como uma palavra
for autor in autores:
obras_tokens[autor] = (
[token.lower() for token in obras_tokens[autor]])
# Calcular o qui-quadrado de cada documento de teste com cada um dos 5 autores
for obra in obras_destacadas:
for autor in autores:
# Primeiro, construir um corpus conjunto e identificar
# as 500 palavras mais frequentes nele
corpus_conjunto= (obras_tokens[obra] +
obras_tokens[autor])
freq_dist_conjunto = nltk.FreqDist(corpus_conjunto)
termos_comuns = list(freq_dist_conjunto.most_common(500))
# Que proporção do corpus conjunto é constituído pelos
# tokens do autor candidato?
autor_compartihado = (len(obras_tokens[autor])
/ len(corpus_conjunto))
# Agora, vamos observar as 500 palavras mais frequentes no corpus do candidato
# e comparar o número de vezes que elas podem ser observadas
# ao que seria esperado se os artigos do autor e o documento de teste
# fossem ambas amostras aleatórias do mesmo conjunto.
quiquadrado = 0
for word,count_conjunto in termos_comuns:
# Com que frequência vemos essa palavra comum?
autor_count = obras_tokens[autor].count(word)
obra_count = obras_tokens[obra].count(word)
# Com que frequência deveríamos vê-la?
autor_count_esperado = count_conjunto * autor_compartihado
teste_count_esperado = count_conjunto * (1-autor_compartihado)
# Adicionar a contribuição da palavra para a estatística qui-quadrado
quiquadrado += ((autor_count-autor_count_esperado) *
(autor_count-autor_count_esperado) /
autor_count_esperado)
quiquadrado += ((obra_count-teste_count_esperado) *
(obra_count-teste_count_esperado)
/ teste_count_esperado)
print("A estatística de qui-quadrado do documento",
obra,
"para o candidato",
autor,
"é =",
quiquadrado)
print("\n")
Assim como no primeiro exemplo, o resultado será 5 blocos de resultados, cada um para um documento de teste. O primeiro bloco se parecerá com isso:
A estatística de qui-quadrado do documento Assis (teste) para o candidato Assis é = 12266.387624251674
A estatística de qui-quadrado do documento Assis (teste) para o candidato Alencar é = 13832.008019914058
A estatística de qui-quadrado do documento Assis (teste) para o candidato Castelo Branco é = 15659.980573183348
A estatística de qui-quadrado do documento Assis (teste) para o candidato Castilho é = 19458.24314684532
A estatística de qui-quadrado do documento Assis (teste) para o candidato Chagas é = 13681.732446564287
Agora, vamos dar uma olhada na matriz de confusão dos resultados para esta técnica:
| Assis | Alencar | Castelo Branco | Castilho | Chagas | |
|---|---|---|---|---|---|
| Assis (teste) | 12266 | 13832 | 15659 | 19458 | 13681 |
| Alencar (teste) | 2550 | 3153 | 2581 | 2663 | 2765 |
| Castelo Branco (teste) | 17294 | 12063 | 11187 | 18133 | 13954 |
| Castilho (teste) | 11349 | 9203 | 8925 | 4531 | 7548 |
| Chagas (teste) | 6683 | 5700 | 5836 | 6970 | 5332 |
Como podemos observar, o teste de qui-quadrado obteve um resultado superior à curva característica de composição de Mendenhall. Assis e Castilho permanecem com a inferência correta de autoria. Chagas, que passou pelo “empate técnico” na curva de composição, com o qui-quadrado também faz a inferência correta com uma distância considerável entre os demais possíveis autores. Dos autores que não haviam sido avaliados corretamente na curva de composição, Castelo Branco possui o menor valor de qui-quadrado, outra inferência correta. Alencar, no entanto, segue como o maior valor entre os 5 possíveis autores. De qualquer forma, já passamos de 50% de acerto com a curva característica de composição para 80% com o método qui-quadrado!
No entanto, o qui-quadrado ainda é um método pouco refinado. Por um lado, palavras que aparecem com muita frequência tendem a ter um peso desproporcional no cálculo final. Às vezes, isso é bom; outras vezes, diferenças sutis de estilo representadas pelas maneiras como os autores usam palavras mais incomuns passarão despercebidas.
Uma nota sobre classes gramaticais
Em alguns casos e idiomas, pode ser útil aplicar a marcação de Part-of-speech (classes gramaticais) aos tokens de palavras antes de contá-los, de modo que a mesma palavra usada como duas classes gramaticais diferentes possa contar como dois elementos diferentes (por exemplo, o termo “mais” sendo usado como substantivo ou como advérbio de intensidade). Esta lição não usa marcação de classes gramaticais, mas poderia refinar os resultados em estudos de caso mais complexos.
Se você precisar aplicar a marcação de classe gramatical aos seus próprios dados, poderá fazer o download de marcadores para outros idiomas, para trabalhar com uma ferramenta de terceiros como Tree Tagger, ou mesmo para treinar o seu próprio marcador, mas essas técnicas estão muito além do escopo da lição atual.
Terceiro teste estilométrico: método Delta de John Burrows (avançado)
Os primeiros dois métodos estilométricos foram mais fáceis de implementar. Este próximo, baseado na estatística Delta de John Burrows10, é consideravelmente mais complexo, tanto conceitualmente (a matemática é mais complicada) quanto computacionalmente (mais código necessário). É, no entanto, um dos métodos estilométricos mais proeminentes em uso hoje.
Assim como o qui-quadrado de Kilgariff, o método Delta de Burrows é uma medida da “distância” entre um texto cuja autoria queremos averiguar e algum outro corpus. Ao contrário do qui-quadrado, no entanto, o método Delta é projetado para comparar um texto anônimo (ou conjunto de textos) com as assinaturas de vários autores diferentes ao mesmo tempo. Mais precisamente, o método Delta mede como o texto anônimo e conjuntos de textos escritos por um número arbitrário de autores conhecidos divergem da média de todos eles juntos. Além disso, o método Delta atribui peso igual a todas as características que mede, evitando assim o problema de palavras comuns sobrecarregarem os resultados, o que era um problema com os testes de qui-quadrado. Por todas essas razões, o método Delta de John Burrows é geralmente uma solução mais eficaz para a questão da autoria.
O algoritmo original de Burrows pode ser resumido da seguinte forma:
- Reúna um grande corpus composto por textos escritos por um número arbitrário de autores; digamos que o número de autores seja
x; - Encontre as
npalavras mais frequentes no corpus para usar como elementos; - Para cada uma dessas
ncaracterísticas, calcule a participação de cada subcorpora dosxautores, como uma porcentagem do número total de palavras. Por exemplo, a palavra “ele” pode representar 4,72% das palavras no subcorpus do Autor A; - Em seguida, calcule a média e o desvio padrão desses
xvalores e use-os como a média oficial e o desvio padrão para esse elemento em todo o corpus. Em outras palavras, estaremos usando uma média de médias em vez de calcular um único valor que represente a parcela de todo o corpus dado por cada palavra. Fazemos isso porque queremos evitar que um subcorpus maior tenha maior influência nos resultados a seu favor e defina a norma do corpus de tal forma que se espere que tudo se pareça com ele; -
Para cada um dos
nelementos exsubcorpora, calcule umz-scoredescrevendo o quão distante da norma do corpus está o uso desse elemento particular neste subcorpus específico. Para fazer isso, subtraia a “média das médias” de um dado elemento da frequência com que ela é encontrada no subcorpus e divida o resultado pelo seu desvio padrão. A Figura 3 mostra a equação de z-score para o elemento ‘i’, onde C(i) representa a frequência observada, a letra grega mu representa a média das médias e a letra grega sigma, o desvio padrão;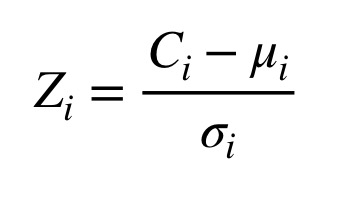
Imagem 3: Equação para a estatística de z-score.
- Em seguida, calcule os mesmos
z-scorespara cada elemento no texto para o qual queremos determinar a autoria; -
Finalmente, calcule um score delta comparando o documento de teste com o subcorpus de cada candidato. Para fazer isso, tome a média dos valores absolutos das diferenças entre os
z-scorespara cada elemento entre o documento de teste e o subcorpus do candidato. (leia duas vezes!) Isso dá peso igual a cada elemento, não importa a frequência com que as palavras ocorram nos textos; caso contrário, os 3 ou 4 principais elementos sobrecarregariam todo o resto. A Figura 4 mostra a equação para Delta, onde Z(c,i) é oz-scorepara o elemento ‘i’ no candidato ‘c’, e Z(t,i) é oz-scorepara o elemento ‘i’ no caso de teste;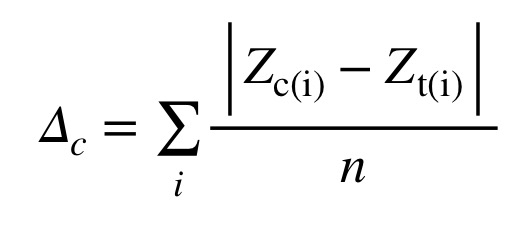
Imagem 4: Equação para a estatística Delta de John Burrows.
- O candidato “vencedor”, assim como nas duas outras técnicas que aplicamos, é o autor para o qual a pontuação delta entre o subcorpus do autor e o documento de teste é a mais baixa.
Stefan Evert et al.11 fornece uma discussão aprofundada das variantes, refinamentos e complexidades do método, mas nos ateremos ao essencial para os propósitos desta lição. Uma explicação diferente de Delta, escrita em espanhol, e uma aplicação a um corpus de romances espanhóis também podem ser encontradas em um artigo recente de José Calvo Tello.12
Seleção de elementos
Vamos combinar todos os subcorpora em um único corpus para Delta calcular um “padrão” para trabalhar. Então, vamos selecionar um número de palavras para usar como característica. Lembre-se de que usamos 500 palavras para calcular o qui-quadrado de Kilgariff; desta vez, usaremos um conjunto menor de 30 palavras (a maioria, senão todas, palavras funcionais e verbos comuns) como nossos elementos.
# Combinar todos os corpora, exceto os documentos de teste, em um único corpus
corpus_completo = []
for autor in autores:
corpus_completo += obras_tokens[autor]
# Obter uma distribuição de frequência
freq_dist_corpus_completo = list(nltk.FreqDist(corpus_completo).most_common(30))
freq_dist_corpus_completo[ :10 ]
Uma amostra das palavras mais frequentes e suas respectivas ocorrências parece com o seguinte:
[('a', 17619),
('que', 17345),
('de', 17033),
('e', 15449),
('o', 14283),
('não', 7086),
('do', 6019),
('da', 5647),
('os', 5299),
('um', 4873)]
Calculando elementos para cada subcorpus
Vejamos as frequências de cada característica no subcorpus de cada candidato, como uma proporção do número total de tokens no subcorpus. Vamos calcular esses valores e armazená-los em um dicionário de dicionários, uma maneira conveniente de construir um array bidimensional em Python.
# Criar uma lista com os elementos e a estrutura principal de dados
features = [word for word,freq in freq_dist_corpus_completo]
feature_freqs = {}
for autor in autores:
# Criar um dicionário para os elementos de cada candidato
feature_freqs[autor] = {}
# Obter um valor auxiliar contendo o número de tokens no subcorpus do autor
geral = len(obras_tokens[autor])
# Calcular a presença de cada elemento no subcorpus
for feature in features:
presenca = obras_tokens[autor].count(feature)
feature_freqs[autor][feature] = presenca / geral
Calculando médias de elementos e desvios-padrão
Dadas as frequências de elementos para todos os subcorpora que acabamos de calcular, podemos encontrar uma “média das médias” e um desvio padrão para cada elemento. Armazenaremos esses valores em outro “dicionário de dicionários”.
import math
# A estrutura de dados na qual iremos armazenar
# as "estatísticas padrão do corpus"
corpus_features = {}
# Para cada elemento...
for feature in features:
# Criar um subdicionário que conterá a média e o desvio padrão do elemento
corpus_features[feature] = {}
# Calcular a média das frequências expressas no subcorpora
feature_average = 0
for autor in autores:
feature_average += feature_freqs[autor][feature]
feature_average /= len(autores)
corpus_features[feature]["Mean"] = feature_average
# Calcular o desvio padrão usando a fórmula básica para uma amostra
feature_stdev = 0
for autor in autores:
diff = feature_freqs[autor][feature] - corpus_features[feature]["Mean"]
feature_stdev += diff * diff
feature_stdev /= (len(autores) - 1)
feature_stdev = math.sqrt(feature_stdev)
corpus_features[feature]["StdDev"] = feature_stdev
Calculando z-scores
Em seguida, transformamos as frequências de características observadas no subcorpora dos cinco candidatos em z-scores, descrevendo o quão distante da “estatística padrão do corpus” essas observações estão. Nada extravagante aqui: nós meramente aplicamos a definição do z-score para cada elemento e armazenamos os resultados em outro array bidimensional.
feature_zscores = {}
for autor in autores:
feature_zscores[autor] = {}
for feature in features:
# Definição do z-score = (value - mean) / stddev
# Usamos variáveis intermediárias para tornar o
# código mais fácil de ler
feature_val = feature_freqs[autor][feature]
feature_mean = corpus_features[feature]["Mean"]
feature_stdev = corpus_features[feature]["StdDev"]
feature_zscores[autor][feature] = ((feature_val-feature_mean) /
feature_stdev)
Calculando elementos, z-scores e Delta para nosso caso de teste
Em seguida, precisamos comparar os documentos de teste com o corpus. O seguinte trecho de código, que essencialmente recapitula tudo o que fizemos até agora, conta as frequências de cada um de nossos 30 elementos nos documentos de teste e calcula os z-scores de acordo.
Por fim, usamos a fórmula para Delta definida por Burrows para extrair uma única pontuação comparando cada documento de teste com cada um dos cinco “autores candidatos”. Lembre-se: quanto menor a pontuação Delta, mais semelhante a assinatura estilométrica do documento à do candidato.
for obra in obras_destacadas:
# Tokenizar o documento de teste
testcase_tokens = nltk.word_tokenize(obras[obra])
# Filtrar a pontuação e colocar os tokens em minúsculas
testcase_tokens = [token.lower() for token in testcase_tokens
if any(c.isalpha() for c in token)]
# Calcular as frequências dos elementos do documento de teste
geral = len(testcase_tokens)
testcase_freqs = {}
for feature in features:
presenca = testcase_tokens.count(feature)
testcase_freqs[feature] = presenca / geral
# Calcular os z-scores dos elementos do documento de teste
testcase_zscores = {}
for feature in features:
feature_val = testcase_freqs[feature]
feature_mean = corpus_features[feature]["Mean"]
feature_stdev = corpus_features[feature]["StdDev"]
testcase_zscores[feature] = (feature_val - feature_mean) / feature_stdev
# Calcular Delta para cada autor
for autor in autores:
delta = 0
for feature in features:
delta += math.fabs((testcase_zscores[feature] -
feature_zscores[autor][feature]))
delta /= len(features)
print( "Delta score do documento",
obra,
"para o candidato",
autor,
"é =",
delta )
print("\n")
Como nas outras duas técnicas, o resultado serão 5 blocos de código dando o valor de Delta de cada documento para cada suposto autor. O primeiro bloco se parecerá com isso:
Delta score do documento Assis (teste) para o candidato Assis é = 0.8715781237572774
Delta score do documento Assis (teste) para o candidato Alencar é = 1.2624531605759595
Delta score do documento Assis (teste) para o candidato Castelo Branco é = 1.2303968803032856
Delta score do documento Assis (teste) para o candidato Castilho é = 1.6276770882853728
Delta score do documento Assis (teste) para o candidato Chagas é = 1.0527125070730734
Vamos avaliar todos os valores Delta na nossa matriz de confusão (reduzidos para 4 casas decimais):
| Assis | Alencar | Castelo Branco | Castilho | Chagas | |
|---|---|---|---|---|---|
| Assis (teste) | 0.8715 | 1.2624 | 1.2303 | 1.6276 | 1.0527 |
| Alencar (teste) | 1.9762 | 1.3355 | 1.3878 | 1.6425 | 1.5042 |
| Castelo Branco (teste) | 1.004 | 1.3208 | 0.8182 | 1.5202 | 1.2829 |
| Castilho (teste) | 1.5705 | 1.2553 | 1.0970 | 0.4518 | 0.8176 |
| Chagas (teste) | 1.1444 | 1.0169 | 0.9462 | 0.9864 | 0.7756 |
Com o método Delta, pudemos inferir corretamente 100% da autoria dos documentos de teste! Alencar, que teve o pior valor nas duas outras técnicas, aqui aparece com o menor valor entre os 5 candidatos. Ao utilizarmos autores brasileiros e portugueses, tínhamos em mente também a possibilidade de que a comparação entre ficheiros de autores de uma mesma nacionalidade pudessem ter valores mais próximos que entre autores de nacionalidades distintas, em função de particularidades linguísticas, o que parece que não foi o caso aqui. Por se tratarem de obras do século XIX, poderíamos buscar explicações para isso na maior similaridade das línguas na época, na influência da Academia Portuguesa no Brasil, ou mesmo do letramento e influências dos autores. Uma segunda análise com obras mais contemporâneas seria um excelente segundo passo para esta análise, e fica como sugestão para o leitor.
Leituras adicionais e recursos
Estudos de caso interessantes
Estilometria e/ou atribuição de autoria têm sido utilizadas em diversos contextos, empregando diversas técnicas. Aqui estão alguns estudos de caso interessantes:
- Javier de la Rosa e Juan Luis Suárez procuram o autor de um famoso romance espanhol do século XVI entre uma lista considerável de candidatos. 13
- Maria Slautina e Mikhail Marusenko usam o reconhecimento de padrões em um conjunto de recursos sintáticos, gramaticais e lexicais, desde a contagem de palavras simples (com marcação de classe gramatical) a vários tipos de frases, a fim de estabelecer semelhanças estilísticas entre os textos medievais.14
- Ellen Jordan, Hugh Craig e Alexis Antonia examinam o caso de periódicos britânicos do século XIX, nos quais os artigos geralmente não eram assinados, para determinar o autor de quatro resenhas de trabalhos de ou sobre as irmãs Brontë.15 Este estudo de caso aplica uma versão inicial de outro método desenvolvido por John Burrows, o método Zeta, que se concentra nas palavras favoritas de um autor em vez de palavras de função comum.16
- Valérie Beaudoin e François Yvon analisaram 58 peças em verso dos dramaturgos franceses Corneille, Racine e Molière, descobrindo que as duas primeiras foram muito mais consistentes na maneira como estruturaram sua escrita do que as últimas.17
- Marcelo Luiz Brocardo, Issa Traore, Sherif Saad e Isaac Woungang aplicam aprendizagem supervisionada e modelos n-gram para determinar a autoria de mensagens curtas com um grande número de autores em potencial, como e-mails e tweets.18
- Moshe Koppel e Winter Yaron propõem o “método do impostor”, que tenta determinar se dois textos foram escritos pelo mesmo autor, inserindo-os em um conjunto de textos escritos por falsos candidatos.19 Justin Anthony Stover et al. recentemente aplicou a técnica para determinar a autoria de um manuscrito do século II recém-descoberto.20
- Finalmente, uma equipe liderada por David I. Holmes estudou o caso peculiar de documentos escritos por um soldado da Guerra Civil ou por sua viúva que pode ter copiado intencionalmente seu estilo de escrita.21
Referências adicionais sobre autoria e estilometria
A referência mais exaustiva em todos os assuntos relacionados à atribuição de autoria, incluindo a história do campo, seus fundamentos matemáticos e linguísticos e seus vários métodos, foi escrita por Patrick Juola em 2007.22 O Capítulo 7, em particular, mostra como a atribuição de autoria pode servir como um marcador para várias identidades de grupo (gênero, nacionalidade, dialeto, etc.), para mudanças na linguagem ao longo do tempo, e até mesmo para personalidade e saúde mental.
Uma pesquisa mais curta pode ser encontrada em Moshe Koppel et al., que discute casos em que há um único autor candidato cuja autoria deve ser confirmada, um grande número de candidatos para os quais apenas pequenas amostras de escrita estão disponíveis para treinar um algoritmo de aprendizado de máquina, ou nenhum candidato conhecido.23
O artigo de Stamatatos citado anteriormente2 também contém uma pesquisa qualitativa do campo.
Varia
Programming historians que desejam explorar mais a estilometria podem fazer o download do pacote Stylo,24 que se tornou um padrão de facto. Entre outras coisas, o pacote Stylo fornece uma implementação do método Delta, funcionalidade de extração de recursos e interfaces gráficas de usuário convenientes tanto para manipulação de dados quanto para produção de resultados visualmente atraentes. Observe que o Stylo é escrito em R, o que significa que você precisará do R instalado no seu computador para executá-lo, mas entre a interface gráfica do usuário e os tutoriais, pouco ou nenhum conhecimento prévio de programação R deve ser necessário.
Leitores fluentes em francês interessados em explorar as implicações epistemológicas das interações entre métodos quantitativos e qualitativos na análise do estilo de escrita devem ler Clémence Jacquot.25
Surpreendentemente, os dados obtidos por meio de reconhecimento ótico de caracteres (OCR) se mostraram adequados para fins de atribuição de autoria, mesmo quando os dados sofrem de altas taxas de erro de OCR.26
Por fim, existe um grupo Zotero dedicado à estilometria, onde você pode encontrar muitas outras referências a métodos e estudos.
Agradecimentos
Agradecimentos a Stéfan Sinclair e Andrew Piper, em cujos seminários na Universidade McGill este projeto começou. Também agradeço à minha orientadora de tese, Susan Dalton, cuja orientação é sempre inestimável.
Notas finais
-
Veja, por exemplo, Justin Rice, “What Makes Hemingway Hemingway? A statistical analysis of the data behind Hemingway’s style” ↩
-
Efstathios Stamatatos, “A Survey of Modern Authorship Attribution Method,” Journal of the American Society for Information Science and Technology, vol. 60, no. 3 (December 2008), p. 538–56, citation on p. 540, https://doi.org/10.1002/asi.21001. ↩ ↩2 ↩3
-
Jan Rybicki, “Vive La Différence: Tracing the (Authorial) Gender Signal by Multivariate Analysis of Word Frequencies,” Digital Scholarship in the Humanities, vol. 31, no. 4 (December 2016), pp. 746–61, https://doi.org/10.1093/llc/fqv023. Sean G. Weidman e James O’Sullivan, “The Limits of Distinctive Words: Re-Evaluating Literature’s Gender Marker Debate,” Digital Scholarship in the Humanities, 2017, https://doi.org/10.1093/llc/fqx017. ↩
-
Ted Underwood, David Bamman, e Sabrina Lee, “The Transformation of Gender in English-Language Fiction”, Cultural Analytics, Feb. 13, 2018, https://doi.org/10.22148/16.019. ↩
-
Sven Meyer zu Eissen e Benno Stein, “Intrinsic Plagiarism Detection,” in ECIR 2006, edited by Mounia Lalmas, Andy MacFarlane, Stefan Rüger, Anastasios Tombros, Theodora Tsikrika, e Alexei Yavlinsky, Berlin, Heidelberg: Springer, 2006, pp. 565–69, https://doi.org/10.1007/11735106_66. ↩
-
Cynthia Whissell, “Traditional and Emotional Stylometric Analysis of the Songs of Beatles Paul McCartney and John Lennon,” Computers and the Humanities, vol. 30, no. 3 (1996), pp. 257–65. ↩
-
Douglass Adair, “The Authorship of the Disputed Federalist Papers”, The William and Mary Quarterly, vol. 1, no. 2 (April 1944), pp. 97-122. ↩
-
T. C. Mendenhall, “The Characteristic Curves of Composition”, Science, vol. 9, no. 214 (Mar. 11, 1887), pp. 237-249. ↩
-
Adam Kilgarriff, “Comparing Corpora”, International Journal of Corpus Linguistics, vol. 6, no. 1 (2001), pp. 97-133. ↩
-
John Burrows, “‘Delta’: a Measure of Stylistic Difference and a Guide to Likely Authorship”, Literary and Linguistic Computing, vol. 17, no. 3 (2002), pp. 267-287. ↩
-
Stefan Evert et al., “Understanding and explaining Delta measures for authorship attribution”, Digital Scholarship in the Humanities, vol. 32, no. suppl_2 (2017), pp. ii4-ii16. ↩
-
José Calvo Tello, “Entendiendo Delta desde las Humanidades,” Caracteres, vol.5, no.1 (May 27 2016), pp.140-176. ↩
-
Javier de la Rosa and Juan Luis Suárez, “The Life of Lazarillo de Tormes and of His Machine Learning Adversities,” Lemir, vol. 20 (2016), pp. 373-438. ↩
-
Maria Slautina e Mikhaïl Marusenko, “L’émergence du style, The emergence of style,” Les Cahiers du numérique, vol. 10, no. 4 (November 2014), pp. 179–215, https://doi.org/10.3166/LCN.10.4.179-215. ↩
-
Ellen Jordan, Hugh Craig, e Alexis Antonia, “The Brontë Sisters and the ‘Christian Remembrancer’: A Pilot Study in the Use of the ‘Burrows Method’ to Identify the Authorship of Unsigned Articles in the Nineteenth-Century Periodical Press,” Victorian Periodicals Review, vol. 39, no. 1 (2006), pp. 21–45. ↩
-
John Burrows, “All the Way Through: Testing for Authorship in Different Frequency Strata,” Literary and Linguistic Computing, vol. 22, no. 1 (April 2007), pp. 27–47, https://doi.org/10.1093/llc/fqi067. ↩
-
Valérie Beaudoin e François Yvon, “Contribution de La Métrique à La Stylométrie,” JADT 2004: 7e Journées internationales d’Analyse statistique des Données Textuelles, vol. 1, Louvain La Neuve, Presses Universitaires de Louvain, 2004, pp. 107–18. ↩
-
Marcelo Luiz Brocardo, Issa Traore, Sherif Saad e Isaac Woungang, “Authorship Verification for Short Messages Using Stylometry,” 2013 International Conference on Computer, Information and Telecommunication Systems (CITS), 2013, https://doi.org/10.1109/CITS.2013.6705711. ↩
-
Moshe Koppel e Winter Yaron, “Determining If Two Documents Are Written by the Same Author,” Journal of the Association for Information Science and Technology, vol. 65, no. 1 (October 2013), pp. 178–87, https://doi.org/10.1002/asi.22954. ↩
-
Justin Anthony Stover et al., “Computational authorship verification method attributes a new work to a major 2nd century African author”, Journal of the Association for Information Science and Technology, vol. 67, no. 1 (2016), pp. 239–242. ↩
-
David I. Holmes, Lesley J. Gordon, e Christine Wilson, “A widow and her soldier: Stylometry and the American Civil War”, Literary and Linguistic Computing, vol. 16, no 4 (2001), pp. 403–420. ↩
-
Patrick Juola, “Authorship Attribution,” Foundations and Trends in Information Retrieval, vol. 1, no. 3 (2007), pp. 233–334, https://doi.org/10.1561/1500000005. ↩
-
Moshe Koppel, Jonathan Schler, e Shlomo Argamon, “Computational Methods in Authorship Attribution,” Journal of the Association for Information Science and Technology. vol. 60, no. 1 (January 2009), pp. 9–26, https://doi.org/10.1002/asi.v60:1. ↩
-
Maciej Eder, Jan Rybicki, e Mike Kestemont, “Stylometry with R: A Package for Computational Text Analysis,” The R Journal, vol. 8, no. 1 (2016), pp. 107–21. ↩
-
Clémence Jacquot, “Rêve d’une épiphanie du style: visibilité et saillance en stylistique et en stylométrie,” Revue d’Histoire Littéraire de la France , vol. 116, no. 3 (2016), pp. 619–39. ↩
-
Patrick Juola, John Noecker Jr, e Michael Ryan, “Authorship Attribution and Optical Character Recognition Errors”, TAL, vol. 53, no. 3 (2012), pp. 101–127. ↩