
Contenus
- Introduction
- Les Federalist Papers - Contexte historique
- Nos cas de test
- Préparation des données pour l’analyse
- Premier test stylométrique : les courbes caractéristiques de composition de Mendenhall
- Deuxième test stylométrique : la méthode du khi carré de Kilgariff
- Troisième test stylométrique : la méthode du Delta de John Burrows (Concepts avancés)
- Lectures et ressources additionnelles
- Remerciements
- Notes
Introduction
La stylométrie est l’étude quantitative du style littéraire à l’aide de méthodes informatiques de lecture distante. Elle se base sur l’observation faite que chaque auteur a tendance à écrire de façon relativement constante, reconnaissable et unique. Par exemple :
- Chaque individu possède son propre vocabulaire, parfois riche, parfois limité. Bien qu’un vocabulaire étendu soit généralement associé à une littérature de qualité, ce n’est pas toujours le cas. Le romancier américain Ernest Hemingway, par exemple, était célèbre pour employer un nombre étonnamment faible de mots différents,1 ce qui ne l’a pas empêché de gagner le prix Nobel de littérature en 1954.
- Certaines personnes écrivent en phrases courtes, tandis que d’autres préfèrent les phrases complexes comportant plusieurs propositions.
- Il n’y a pas deux auteurs qui utilisent les points-virgules, les tirets et autres signes de ponctuation exactement de la même façon.
Les habitudes d’usage des mots-outils, comme les articles, les prépositions et les conjonctions, se sont montrées particulièrement révélatrices en stylométrie. Dans son survol des méthodes stylométriques du passé et du présent, Efstathios Stamatatos souligne que les auteurs emploient ces mots de façon largement inconsciente et indépendante du sujet à l’étude.2 Ces caractéristiques sont très utiles pour l’analyse stylométrique puisqu’une tendance inconsciente est moins susceptible de changer au cours de la carrière d’un auteur que son vocabulaire en général. (Une tendance inconsciente est aussi beaucoup plus difficile à imiter pour un faussaire.) Les mots-outils ont également été identifiés comme d’importants marqueurs de la temporalité et du genre littéraire.
La communauté des chercheurs a fait appel à la stylométrie pour étudier une multitude de questions d’ordre culturel. Par exemple, on a beaucoup étudié les différences entre les manières dont les hommes et les femmes écrivent3 ou sont décrits dans la littérature.4 D’autres chercheurs ont tenté de déceler des signes de plagiat dans les irrégularités stylistiques au sein d’un texte5, ou même de quantifier l’évolution des paroles des chansons écrites par John Lennon et Paul McCartney, arrivant à la conclusion que celles-ci devenaient de moins en moins actives et joyeuses à la fin des années 1960, alors que la carrière des Beatles tirait à sa fin.6
L’identification de l’auteur d’un texte anonyme constitue cependant l’une des applications les plus courantes de la stylométrie. Il est parfois possible de découvrir l’identité de l’auteur d’un texte en mesurant certaines caractéristiques de ce texte, comme la longueur moyenne des phrases ou le rapport entre le nombre d’articles définis et indéfinis. Ces mesures sont ensuite comparées avec celles observées dans des textes dont les auteurs sont connus. C’est ce que nous ferons dans cette leçon, à l’aide d’une étude de cas basée sur ce qui constitue peut-être la controverse la plus célèbre de l’histoire de la science politique américaine, celle des Federalist Papers.
Objectifs d’apprentissage
À la fin de la leçon, nous aurons étudié les sujets suivants:
- Comment appliquer diverses méthodes stylométriques pour déterminer l’auteur d’un texte anonyme ou d’un ensemble de textes anonymes.
- Comment utiliser des structures de données relativement avancées, comme les dictionnaires de chaînes de caractères et les dictionnaires de dictionnaires, dans le langage de programmation Python.
- Les rudiments du Natural Language Toolkit (documentation en anglais) (nltk), un module Python populaire dédié au traitement du langage naturel.
Lectures préalables
Si vous n’avez pas d’expérience de programmation en Python ou si vous trouvez les exemples dans ce tutoriel difficiles, l’auteur vous recommande de lire les leçons intitulées Travailler avec des fichiers texte en Python et Manipuler des chaînes de caractères en Python. Notez aussi que ces leçons ont à l’origine été rédigées en Python 2 tandis que ce tutoriel utilise Python 3. Les différences de syntaxe entre les deux versions du langage peuvent être subtiles. En cas de conflit, suivez les exemples tels qu’ils sont codés dans le présent tutoriel et n’utilisez les autres ressources qu’à titre indicatif. (Plus précisément, le code intégré à ce tutoriel a été écrit en Python 3.6.4; la chaîne de type f-string qui apparaît dans la ligne with open(f'data/federalist_{nom_fichier}.txt', 'r') as f:, par exemple, requiert Python 3.6 ou une version plus récente du langage.)
Matériel requis
Ce tutoriel utilise un jeu de données et des logiciels que vous devrez télécharger et installer.
Le jeu de données
Pour compléter les exercices de ce tutoriel, vous devrez télécharger et ouvrir l’archive des Federalist Papers .zip qui contient les 85 articles dont nous aurons besoin pour effectuer notre analyse. L’archive contient également le livre électronique du Projet Gutenberg dont ces 85 documents ont été extraits. L’ouverture du fichier .zip créera un répertoire nommé data dans votre répertoire de travail courant. Assurez-vous de rester dans ce répertoire de travail courant et d’y sauvegarder tout le travail que vous réaliserez en suivant le tutoriel.
Le logiciel
Ce tutoriel requiert une version récente du langage Python et certaines bibliothèques logicielles:
- Python 3.x - la version stable la plus récente est recommandée.
- nltk - Le module Natural Language Toolkit, couramment abbrévié
nltk. - matplotlib
Certaines de ces ressources peuvent être absentes de votre ordinateur. Si vous recevez des messages d’erreurs comme “Module not found” (“module introuvable”) ou l’équivalent, vous devrez télécharger et installer les modules manquants vous-mêmes. La méthode la plus simple consiste à utiliser la commande pip. Consultez la leçon (en anglais) intitulée Installing Python modules with pip pour les détails.
Quelques notes au sujet des langues
Ce tutoriel applique des méthodes d’analyse stylométrique à un ensemble de textes rédigés en anglais à l’aide d’un module Python nommé nltk. Plusieurs des fonctions offertes par nltk sont cependant disponibles dans d’autres langues. Pour peu qu’une langue écrite divise ses mots de façon claire et précise, nltk devrait fonctionner correctement. Les langues pour lesquelles il n’y a pas de séparation nette entre les mots à l’écrit, comme par exemple le chinois, pourraient poser problème. J’ai utilisé nltk avec des textes français sans difficulté; les autres langues qui utilisent des signes diacritiques, comme l’espagnol et l’allemand, devraient être compatibles avec nltk elles aussi. Veuillez consulter la documentation de nltk (en anglais seulement) pour plus de détails.
Une seule des tâches de ce tutoriel exige du code qui varie en fonction de la langue. Pour diviser un texte en un ensemble de mots en français ou en espagnol, vous devrez spécifier la langue appropriée à l’analyseur lexical de nltk. La procédure à suivre sera expliquée au moment venu.
Enfin, veuillez noter que certaines tâches linguistiques, comme l’étiquetage grammatical des mots, peuvent ne pas être supportées par nltk dans les langues autres que l’anglais. Ce tutoriel ne couvre pas l’étiquetage grammatical. Si vos propres projets en ont besoin, veuillez consulter la documentation de nltk pour obtenir des conseils.
Les Federalist Papers - Contexte historique
Les Federalist Papers (parfois simplement appelés le Fédéraliste) sont une collection de 85 articles fondamentaux de la théorie politique américaine, publiés entre octobre 1787 et mai 1788. Ces articles, rédigés alors que le débat sur la ratification de l’actuelle Constitution des États-Unis d’Amérique faisait rage, argumentent en faveur de cette ratification et du système de gouvernement sous lequel les Américains vivent depuis 1789. Par conséquent, le Fédéraliste est parfois décrit comme la contribution la plus importante et la plus impérissable des États-Unis dans le domaine de la philosophie politique.
Trois des hommes d’État les plus en vue de la jeune république américaine ont écrit les articles:
- Alexander Hamilton, qui fut le premier Secrétaire du Trésor (l’équivalent du ministre des Finances) des États-Unis.
- James Madison, quatrième Président des États-Unis, qui est parfois surnommé le “Père de la Constitution” en raison du rôle-clé qu’il a joué lors de la convention constitutionnelle de 1787 au cours de laquelle celle-ci a été rédigée.
- John Jay, premier juge en chef de la Cour suprême des États-Unis, second gouverneur de l’État de New York et diplomate.
Cependant, qui a écrit quel article au juste est resté un mystère pendant plus de 150 ans, et ce par la faute des auteurs eux-mêmes.
Premièrement, parce que le Fédéraliste a été publié sous le pseudonyme partagé “Publius”. La publication anonyme n’était pas chose rare au dix-huitième siècle, surtout dans les cas de textes politiques sujets à controverse. Dans le cas du Fédéraliste, le fait que trois personnes aient partagé le même pseudonyme rend cependant l’identification de l’auteur de chaque article difficile. Une tâche encore compliquée par le fait que les trois hommes écrivent sur des sujets similaires, en même temps, et en s’inspirant des mêmes courants politiques et culturels, ce qui rend leurs vocabulaires respectifs difficiles à distinguer.
Deuxièmement, parce que Madison et Hamilton ont laissé des témoignages contradictoires concernant leurs rôles respectifs au sein du projet. Dans un article célèbre publié en 1944, l’historien Douglass Adair7 a expliqué que ni Madison, ni Hamilton ne souhaitait que la paternité du Fédéraliste soit révélée, même longtemps après la ratification de la Constitution, parce qu’ils regrettaient une partie de ce qu’ils avaient écrit. Hamilton voulait cependant s’assurer que la postérité lui reconnaîtrait le premier rôle. En 1804, deux jours avant le duel où il a trouvé la mort, Hamilton a donc confié à un ami une lettre dans laquelle il affirmait avoir écrit 63 des 85 articles. Dix ans plus tard, Madison a réfuté certaines des prétentions de son rival, affirmant qu’il avait lui-même rédigé 12 des articles qui apparaissaient sur la liste de Hamilton et qu’il avait été l’auteur principal de trois autres dont Hamilton se prétendait un co-auteur d’égale importance. Hamilton étant mort depuis longtemps, il était impossible pour lui de répondre à Madison.
Troisièmement, parce que, comme le soulignent David Holmes et Richard Forsyth,8 les styles d’écriture de Hamilton et de Madison étaient anormalement similaires. Frederick Mosteller et Frederick Williams ont calculé que, dans les articles dont la paternité n’est pas en doute, les longueurs moyennes des phrases écrites par les deux hommes sont à la fois singulièrement élevées et presque identiques: respectivement 34,59 et 34,55 mots.9 Les écarts-types des longueurs de phrases sont aussi très proches. Enfin, comme ironise Mosteller, ni l’un ni l’autre n’avait l’habitude d’utiliser un mot court quand un mot long faisait l’affaire. Il n’y avait donc aucune façon simple de détecter la signature stylistique de Hamilton ou de Madison dans un article spécifique.
Ce n’est qu’en 1964 que Mosteller et David Lee Wallace10 sont parvenus à formuler une solution relativement satisfaisante au mystère à l’aide de statistiques sur l’usage des mots. En comparant les fréquences auxquelles Madison et Hamilton utilisaient des mots courants comme may (peut), also (aussi), an (un ou une), his (son, sa), etc., ils ont conclu que les articles controversés avaient tous été rédigés par Madison. Même dans le cas du Fédéraliste 55, l’article pour lequel ils considéraient les indices comme étant les moins convaincants, Mosteller et Wallace estimaient les chances que Madison en ait été l’auteur à 100 contre une.
Depuis ce temps, la répartition des articles du Fédéraliste en fonction de leur(s) auteur(s) est restée un cas d’espèce pour les algorithmes d’apprentissage automatique, du moins dans le monde anglophone.11 La stylométrie a aussi continué à utiliser le Fédéraliste pour raffiner ses méthodes, notamment pour chercher des preuves de collaborations entre de multiples auteurs dans un même texte.12 Curieusement, certains résultats de ces recherches tendent à démontrer que l’énigme du Fédéraliste n’est peut-être pas aussi résolue que Mosteller et Wallace le pensaient. En effet, Hamilton et Madison ont peut-être co-rédigé une plus grande partie de la collection qu’on ne le croyait.
Nos cas de test
Dans ce tutoriel, nous utiliserons le Fédéraliste pour expliquer et tester trois méthodes stylométriques différentes:
- Les courbes caractéristiques de composition de Mendenhall
- La méthode du khi carré de Kilgarriff
- La méthode du Delta de John Burrows
Pour ce faire, il faudra diviser les articles en six catégories:
- Les 51 articles dont l’attribution à Alexander Hamilton est certaine.
- Les 14 articles dont l’attribution à James Madison est certaine.
- Quatre des cinq articles dont l’attribution à John Jay est certaine.
- Trois articles qui ont probablement été co-écrits par Madison et Hamilton, et dont Madison réclame la paternité.
- Les 12 articles qui font l’objet de la dispute entre Hamilton et Madison.
- L’article Fédéraliste 64 tout seul.
Cette division suit essentiellement la voie tracée par Mosteller.13 La seule exception est Fédéraliste 64, qui a certainement été rédigé par John Jay mais que nous gardons séparé pour des raisons qui seront expliquées plus tard.
Nos deux premiers tests, qui utiliseront les courbes de composition caractéristiques de T.C. Mendenhall et le khi carré d’Adam Kilgariff, examineront les 12 articles disputés pour voir si, en tant que groupe, ils se rapprochent du corpus d’un auteur en particulier. Notre troisième test utilisera quant à lui la méthode du delta de John Burrows pour confirmer que Federalist 64 a bel et bien été écrit par John Jay.
Préparation des données pour l’analyse
Avant de commencer l’analyse stylométrique proprement dite, il nous faut charger les fichiers contenant les 85 articles dans des structures de données en mémoire vive.
La première étape de ce processus consiste à assigner chacun des 85 articles à l’ensemble approprié. Puisque nous avons donné à nos fichiers des noms standardisés de federalist_1.txt à federalist_85.txt, nous pouvons assigner chaque article à son auteur (ou à son ensemble de test, si nous souhaitons connaître son auteur) à l’aide d’un dictionnaire. En Python, le dictionnaire est une structure de données qui contient un nombre arbitraire de paires clé-valeur; dans le cas qui nous concerne, les noms des auteurs serviront de clés tandis que les listes des numéros d’articles constitueront les valeurs associées à ces clés.
articles = {
'Madison': [10, 14, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48],
'Hamilton': [1, 6, 7, 8, 9, 11, 12, 13, 15, 16, 17, 21, 22, 23, 24,
25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 59, 60,
61, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77,
78, 79, 80, 81, 82, 83, 84, 85],
'Jay': [2, 3, 4, 5],
'Partages': [18, 19, 20],
'Contestes': [49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 62, 63],
'CasSpecial': [64]
}
Les dictionnaires Python sont très flexibles. Par exemple, nous pouvons accéder à une valeur en indexant le dictionnaire à l’aide d’une de ses clés, nous pouvons parcourir l’ensemble du dictionnaire en itérant sur l’ensemble de ses clés, etc. Nous tirerons pleinement avantage de ces propriétés au cours du tutoriel.
Ensuite, puisque nous nous intéressons au vocabulaire employé par chaque auteur, nous allons définir une courte fonction en Python pour créer la longue liste des mots contenus dans chacun des articles de chaque auteur. Cette liste sera enregistrée dans une chaîne de caractères. Ouvrez votre environnement de développement Python. Si vous ne savez pas comment faire, consultez la leçon appropriée pour votre système Mac, Linux ou Windows avant de continuer.
# Une fonction qui concatène un ensemble de fichiers texte en
# une seule chaîne de caractères
def lire_fichiers_en_chaine(noms_fichiers):
chaines = []
for nom_fichier in noms_fichiers:
with open(f'data/federalist_{nom_fichier}.txt', 'r') as f:
chaines.append(f.read())
return '\n'.join(chaines)
Troisièmement, nous allons construire les structures de données en appelant plusieurs fois cette fonction lire_fichiers_en_chaine() et en lui passant à chaque fois une liste d’articles différente. Nous allons enregistrer les résultats dans un autre dictionnaire, dont les six clés sont celles du dictionnaire article ci-dessus et dont les valeurs sont les six corpus correspondants. Dorénavant, par souci de simplicité, nous utiliserons l’expression “le corpus d’un auteur” pour référer à un ensemble d’articles, même lorsque cet ensemble contient des articles contestés ou partagés plutôt que des textes dont nous connaissons l’auteur.
# Construire un dictionnaire contenant les corpus de chaque "auteur"
federalist_par_auteur = {}
for auteur, fichiers in articles.items():
federalist_par_auteur[auteur] = lire_fichiers_en_chaine(fichiers)
Afin de vérifier que le chargement des données s’est effectué comme prévu, affichez les cent premiers caractères de chacune des entrées du dictionnaire à l’écran:
for articles_par_auteur in articles:
print(federalist_par_auteur[articles_par_auteur][:100])
Si cette opération produit des résultats lisibles, la lecture des textes en mémoire a fonctionné comme prévu et nous pouvons passer à l’analyse stylométrique.
Premier test stylométrique : les courbes caractéristiques de composition de Mendenhall
Le chercheur en littérature T. C. Mendenhall a émis l’hypothèse que la signature stylistique d’un individu pourrait être décelée en comptant les nombres de mots de différentes longueurs dans ses oeuvres.14 Par exemple, si l’on comptait les longueurs de mots dans plusieurs segments de 1000 ou de 5000 mots d’un roman et que l’on traçait les graphes des résultats, les courbes seraient similaires quelles que soient les parties du roman choisies. En fait, Mendenhall pensait que si l’on comptait les longueurs d’un assez grand nombre de mots tirés de l’ensemble de l’oeuvre d’un auteur (disons 100 000 mots) sa “courbe caractéristique” pourrait être calculée de façon si précise que celle-ci demeurerait constante pendant toute la vie de l’auteur.
Selon les standards d’aujourd’hui, compter les longueurs de mots peut sembler une façon bien rudimentaire de mesurer le style d’écriture. Mendenhall ne tient pas compte des mots eux-mêmes, ce qui est évidemment problématique. Nous ne pouvons donc pas traiter les courbes de composition comme des sources d’information stylométrique particulièrement fiables. Cependant, Mendenhall a publié sa théorie il y a plus de 130 ans et il effectuait ses calculs à la main. Il est donc compréhensible qu’il ait choisi de travailler avec une statistique qui, bien que rudimentaire, était au moins facile à calculer. En l’honneur de la valeur historique de son approche, et parce que les courbes de composition produisent des résultats visuels attrayants et faciles à implanter, nous utiliserons la méthode de Mendenhall comme première étape de notre étude des méthodes d’identification des auteurs.
Le code requis pour calculer les courbes caractéristiques des auteurs du Fédéraliste est le suivant:
# Charger nltk
import nltk
nltk.download('punkt')
%matplotlib inline
# Comparons les articles contestés à ceux écrits par chaque
# auteur et aux articles partagés
auteurs = ("Hamilton", "Madison", "Contestes", "Jay", "Partages")
# Découper le corpus de chaque "auteur" en occurrences
federalist_par_auteur_occs = {}
federalist_par_auteur_dist_longueurs = {}
for auteur in auteurs:
occs = nltk.word_tokenize(federalist_par_auteur[auteur])
# Filtrer la ponctuation, qui ne sert pas dans ce test
federalist_par_auteur_occs[auteur] = ([occ for occ in occs
if any(c.isalpha() for c in occ)])
# Obtenir et dessiner la distribution des fréquences de longueurs
occs_longueurs = [len(occ) for occ in federalist_par_auteur_occs[auteur]]
federalist_par_auteur_dist_longueurs[auteur] = nltk.FreqDist(occs_longueurs)
federalist_par_auteur_dist_longueurs[auteur].plot(15,title=auteur)
La clause %matplotlib inline sous la ligne import nltk est nécessaire si vous travaillez dans un environnement de développement Jupyter Notebook, comme c’était le cas pour moi lorsque j’ai rédigé ce tutoriel; en son absence, les graphes pourraient ne pas apparaître à l’écran. Si vous travaillez plutôt dans Jupyter Lab, veuillez remplacer cette clause par %matplotlib ipympl.
La première ligne du segment de code ci-dessus charge le module Natural Language Toolkit (nltk), qui regorge de fonctions et de ressources utiles pour la manipulation informatique des textes. Nous ne ferons qu’effleurer ses bases dans ce tutoriel; si vous décidez d’explorer l’analyse de texte en Python plus en profondeur, je vous recommande fortement de commencer en lisant la documentation de nltk.
Les lignes suivantes préparent des structures de données qui seront remplies par le bloc de code à l’intérieur de la boucle for. Cette boucle applique les mêmes calculs aux corpus de chacun de nos “auteurs”:
- Elle invoque la méthode
word_tokenize()denltkpour diviser le corpus d’un auteur en ses différents éléments constitutifs : les mots, les nombres, les signes de ponctuation, etc. En anglais, ces éléments constitutifs sont appelés “tokens”; en français, ce sont des occurrences. - Elle filtre la liste d’occurrences pour en retirer tout ce qui n’est pas un mot;
- Elle crée une liste des longueurs (nombre de caractères) de toutes les occurrences de mots qui ont survécu à l’étape précédente;
- Elle calcule une distribution des fréquences de cette liste de longueurs, ce qui consiste à compter le nombre de 1, le nombre de 2, etc., que l’on retrouve dans le corpus d’un auteur;
- Elle trace une courbe de la distribution des fréquences dans le corpus, pour toutes les longueurs de mots entre 1 et 15.
Par défaut, nltk.word_tokenize() divise un texte en suivant les règles de la grammaire anglaise. Pour appliquer les règles d’une autre langue, il suffit de changer une ligne dans le code ci-dessus pour fournir la langue désirée à l’analyseur lexical. Par exemple:
occs = nltk.word_tokenize(federalist_par_auteur[auteur], language='french'). Lisez la documentation de nltk pour plus de détails.
Les résultats devraient ressembler à ceci :
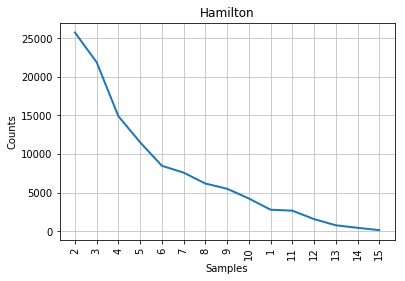
Figure 1: Courbe de Mendenhall pour Hamilton.
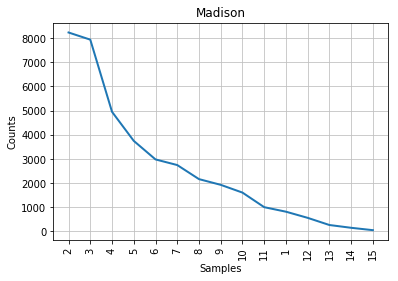
Figure 2: Courbe de Mendenhall pour Madison.
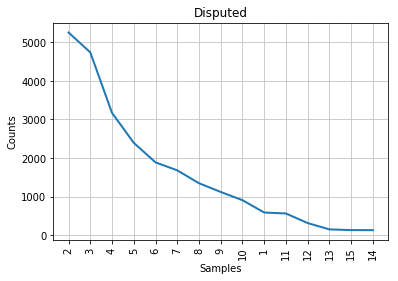
Figure 3: Courbe de Mendenhall pour les articles contestés.
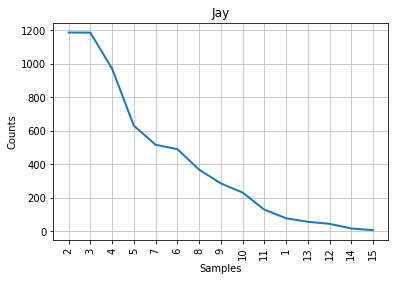
Figure 4: Courbe de Mendenhall pour Jay.
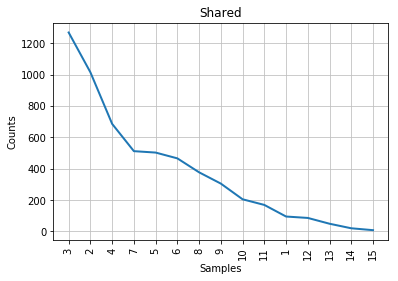
Figure 5: Courbe de Mendenhall pour les articles co-rédigés par Madison et par Hamilton.
Comme vous pouvez le constater à la lecture des graphiques, la courbe caractéristique associée aux articles contestés s’apparente à un compromis entre celles de Madison et de Hamilton. Sur la gauche des graphiques, là où l’on retrouve les longueurs de mots les plus fréquentes, la courbe des articles contestés ressemble un peu plus à celle de Madison; à droite, à celle de Hamilton. Cela concorde avec l’observation historique selon laquelle les styles des deux auteurs sont assez similaires, mais cela ne nous aide pas beaucoup dans notre tâche d’identification de l’auteur des textes contestés. Tout au mieux pouvons-nous affirmer que John Jay n’a presque certainement pas écrit ceux-ci puisque sa courbe ne ressemble en rien aux autres. Les points correspondant aux longueurs de mots 6 et 7 sont mêmes inversés dans le cas de son corpus.
Si nous ne disposions d’aucune information supplémentaire, il faudrait se résoudre à conclure (sans beaucoup de confiance) que les articles contestés sont probablement l’oeuvre de Madison. Mais heureusement, la stylométrie a beaucoup progressé depuis l’époque de Mendenhall.
Deuxième test stylométrique : la méthode du khi carré de Kilgariff
En 2001, Adam Kilgariff15 a proposé d’utiliser la statistique du khi carré (également nommée “khi deux”) pour déterminer l’auteur d’un texte anonyme. Les lecteurs familiers avec les méthodes quantitatives savent peut-être que le khi carré est parfois utilisé pour déterminer si un ensemble d’observations, par exemple les intentions de vote énoncées par les électeurs lors d’un sondage, suivent une loi de probabilité particulière. Ce n’est pas ce que nous cherchons ici. Nous utiliserons plutôt la statistique pour mesurer la “distance” entre les vocabulaires employés dans deux ensembles de texte. Plus ces vocabulaires sont similaires, plus il est probable que les ensembles de textes sous-jacents soient l’oeuvre de la même personne. (Cela suppose que le vocabulaire d’une personne et ses habitudes d’usage des mots soient relativement constants.)
Voici comment appliquer la statistique du khi carré à notre problème d’identification :
- Prenons les corpus associés à deux auteurs.
- Fusionnons-les en un seul corpus combiné de plus grande taille.
- Comptons les occurrences de tous les mots qui apparaissent dans ce corpus combiné.
- Conservons les n mots les plus fréquents.
- Calculons le nombre d’occurrences de ces
nmots les plus fréquents que l’on se serait attendu à observer dans chacun des deux corpus originaux si ceux-ci avaient été rédigés par la même personne. Pour ce faire, il faut diviser le nombre d’occurrences observé dans le corpus combiné, proportionnellement aux tailles des deux corpus originaux. -
Calculons un khi carré en additionnant, pour chacun des
nmots les plus fréquents, les carrés des différences entre les nombres d’occurrences observés dans les corpus des auteurs et les nombres d’occurrences attendus, divisés par les nombres d’occurrences attendus. La figure 6 montre la formule de calcul du khi carré, où C(i) représente le nombre d’occurrences observé pour le mot ‘i’ tandis que E(i) représente le nombre d’occurrences attendu pour ce mot.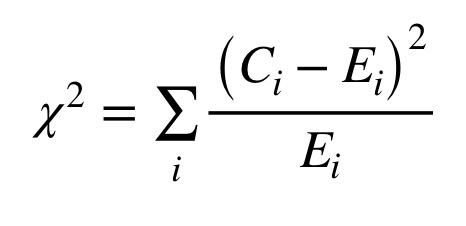
Figure 6: Formule de calcul du khi carré.
Plus la valeur du khi carré est basse, plus les deux corpus sont similaires. Nous allons donc calculer un khi carré pour mesurer la différence entre les articles contestés et le corpus de Madison, puis un autre pour la différence entre les articles contestés et le corpus de Hamilton. La plus petite des deux valeurs nous indiquera lequel des deux individus est l’auteur le plus probable des articles contestés.
Notons en passant que, quelle que soit la méthode stylométrique employée, le choix de n, le nombre de mots à considérer, relève de l’art autant que de la science. Dans la littérature scientifique résumée par Stamatatos2, des chercheurs ont suggéré pour n des valeurs allant de 100 à 1000; un projet a même conservé tous les mots qui sont apparus dans le corpus à au moins deux reprises. En règle générale, plus le corpus est vaste, plus il est possible d’utiliser un grand nombre de mots comme traits caractéristiques sans risquer d’accorder une importance injustifiée à un mot qui n’apparaît qu’à quelques reprises. Dans le cadre de ce tutoriel, nous utiliserons une valeur de n relativement élevée pour la méthode du khi carré et une valeur plus faible pour la méthode suivante. Changer la valeur de n influencera certainement les résultats des calculs; cependant, si ces changements sont si considérables qu’ils en viennent à renverser l’identification de l’auteur, c’est que le test est incapable de fournir des preuves significatives au sujet du texte à l’étude.
Le segment de code suivant implante la méthode du khi carré de Kilgariff, en utilisant les 500 mots les plus fréquents dans le corpus pour réaliser les calculs:
# Qui sont les auteurs auxquels comparer les articles contestés?
auteurs = ["Hamilton","Madison"]
# Convertir les occurrences en minuscules pour que toutes les occurrences
# d'un même mot, avec ou sans majuscule, soient comptabilisées ensemble
for auteur in auteurs:
federalist_par_auteur_occs[auteur] = (
[occ.lower() for occ in federalist_par_auteur_occs[auteur]])
# Faire la même chose avec les occurrences des articles contestés
federalist_par_auteur_occs["Contestes"] = (
[occ.lower() for occ in federalist_par_auteur_occs["Contestes"]])
# Calculer un khi carré pour les deux candidats: Madison et Hamilton
for auteur in auteurs:
# Construire un corpus combiné et trouver les 500 mots les plus
# fréquents dans celui-ci
corpus_combine = (federalist_par_auteur_occs[auteur] +
federalist_par_auteur_occs["Contestes"])
corpus_combine_freq_dist = nltk.FreqDist(corpus_combine)
mots_communs = list(corpus_combine_freq_dist.most_common(500))
# Quelle proportion du corpus combiné est formé d'occurrences
# tirées du corpus de l'auteur candidat?
portion_candidat = (len(federalist_par_auteur_occs[auteur])
/ len(corpus_combine))
# Comparons maintenant le nombre d'occurrences observées pour chacun
# des 500 mots les plus communs dans le corpus de l'auteur candidat
# avec le nombre d'occurrences auquel on se serait attendu si les
# articles du candidat et les articles contestés étaient deux
# échantillons aléatoires tirés de la même distribution.
khicarre = 0
for mot,occs_corpus_combine in mots_communs:
# Nombre d'occurrences observées
auteur_occs = federalist_par_auteur_occs[auteur].count(mot)
contestes_occs = federalist_par_auteur_occs["Contestes"].count(mot)
# Nombre d'occurrences attendues
auteur_occs_attendues = occs_corpus_combine * portion_candidat
contestes_occs_attendues = occs_corpus_combine * (1-portion_candidat)
# Ajouter la contribution de ce mot au khi carré
khicarre += ((auteur_occs-auteur_occs_attendues) *
(auteur_occs-auteur_occs_attendues) /
auteur_occs_attendues)
khicarre += ((contestes_occs-contestes_occs_attendues) *
(contestes_occs-contestes_occs_attendues)
/ contestes_occs_attendues)
print("Le khi carré mesuré pour le candidat", auteur, "est", khicarre)
Les résultats devraient ressembler à ceci:
Le khi carré mesuré pour le candidat Hamilton est 3434.6850314768426
Le khi carré mesuré pour le candidat Madison est 1907.5992915766838
Comme nous pouvons le constater à la lecture des résultats ci-dessus, la valeur du khi carré séparant le corpus de Hamilton des articles contestés est considérablement supérieure à celle entre les articles contestés et le corpus de Madison. Il s’agit d’une preuve relativement convaincante du fait que, si un seul auteur est responsable de tous les articles contestés, cet auteur est Madison plutôt que Hamilton.
Cependant, le khi carré constitue toujours une méthode approximative. Par exemple, les mots qui apparaissent fréquemment dans un corpus ont tendance à occuper une place démesurée dans le calcul. Parfois, ce comportement est approprié; dans d’autres cas, les différences subtiles qui n’apparaissent que lorsque l’on observe les fréquences d’utilisation de certains mots rares passent inaperçues.
Une note au sujet de l’étiquetage grammatical
Dans certaines langues, il peut être utile d’étiqueter grammaticalement les occurrences de mots avant de les compter, pour que les occurrences de certains mots polysémiques puissent être divisées entre deux traits distincts. Par exemple, en français, les mots “le” et “la” servent à la fois d’articles et de pronoms. Ce tutoriel n’applique pas l’étiquetage grammatical puisqu’il est rarement utile pour l’analyse stylométrique de textes en anglais contemporain et parce que l’analyseur syntaxique de nltk ne gère pas très bien les autres langues.
Si vous avez besoin d’étiqueter les occurrences pour vos propres projets, il est possible de télécharger des analyseurs extérieurs, d’obtenir des outils séparés comme Tree Tagger, ou même d’entraîner vos propres modèles d’étiquetage, mais ces techniques sont hors du cadre de ce tutoriel.
Troisième test stylométrique : la méthode du Delta de John Burrows (Concepts avancés)
Les deux méthodes stylométriques que nous avons employées jusqu’ici sont faciles à implanter. La prochaine, basée sur la statistique Delta de John Burrows16, est plus complexe tant au point de vue conceptuel (les calculs mathématiques sont plus nombreux) qu’au point de vue computationnel (nous aurons besoin de beaucoup plus de code). Il s’agit cependant de l’une des méthodes stylométriques les plus populaires en recherche.
Comme la méthode du khi carré de Kilgariff, le Delta de Burrows mesure la “distance” entre un texte dont nous souhaitons déterminer l’auteur et un corpus quelconque. Mais contrairement au khi carré, Delta est conçu pour comparer un texte (ou un ensemble de textes) anonyme aux signatures stylistiques de plusieurs auteurs en même temps. Plus précisément, Delta mesure comment le texte anonyme et des ensembles de textes rédigés par un nombre arbitraire d’auteurs connus divergent tous d’une norme établie en rassemblant tous ces textes dans un seul et même corpus. De plus, Delta accorde le même poids à chacun des traits caractéristiques mesurés, ce qui évite que les mots très fréquents dominent complètement les calculs comme dans le cas du khi carré. Pour toutes ces raisons, Delta constitue habituellement une solution plus efficace au problème de l’identification de l’auteur d’un texte anonyme.
L’algorithme original de Burrows peut être résumé ainsi:
- Assembler un grand corpus formé de textes rédigés par un nombre arbitraire d’auteurs. Disons que ce nombre d’auteurs est
x. - Trouver les
nmots les plus fréquents dans ce grand corpus; ce seront nos traits à étudier. - Pour chacun des
ntraits, calculer la proportion du sous-corpus de chacun desxauteurs représentée par ce trait, en pourcentage du total de mots. Par exemple, le mot “the” pourrait représenter 4,72% de toutes les occurrences dans les textes de l’auteur A. - Calculer la moyenne et l’écart-type de ces
xmesures de présence. Celles-ci serviront de moyenne et d’écart-type officiels pour le corpus entier. En d’autres mots, nous utiliserons une moyenne de moyennes plutôt que de calculer une seule valeur représentant la proportion du corpus entier représentée par chaque mot. Il s’agit d’un choix stratégique qui empêche qu’un sous-corpus d’auteur beaucoup plus étendu que les autres, comme celui de Hamilton dans le Fédéraliste, n’exerce une influence exagérée de telle sorte que l’algorithme s’attende à ce que tout ce qu’il observe lui ressemble. -
Pour chacun des
ntraits et desxsous-corpus d’auteurs, calculer une cote Z qui décrit l’écart entre la présence de ce trait dans ce sous-corpus et la norme du corpus. Pour ce faire, il faut soustraire la “moyenne de moyennes” du corpus pour le trait de la présence de ce trait observée dans le sous-corpus, puis diviser le résultat par l’écart-type du trait. La figure 7 présente la formule de calcul de la cote Z pour le trait ‘i’, où C(i) représente la fréquence observée, la lettre grecque mu représente la moyenne des moyennes, et la lettre grecque sigma représente l’écart-type.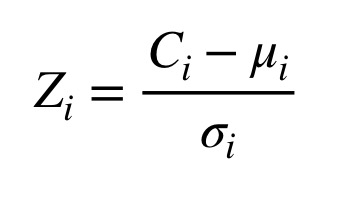
Figure 7: Formule de calcul de la cote Z.
- Puis, calculer de la même façon des cotes Z pour chacun des traits dans le texte dont il faut déterminer l’auteur.
-
Enfin, calculer une cote Delta qui compare le texte anonyme avec les sous-corpus de chacun des auteurs connus. Pour ce faire, il faut calculer la moyenne des valeurs absolues des différences entre les cotes Z de chacun des traits pour le texte anonyme et pour le sous-corpus de l’auteur. (Lisez cette phrase deux fois!) Ce calcul accorde le même poids à chaque trait, peu importe les nombres d’occurrences des différents mots; autrement, les trois ou quatre mots les plus fréquents domineraient le calcul. La figure 8 montre la formule de calcul de Delta, où Z(c,i) est la cote Z pour le trait ‘i’ dans le sous-corpus de l’auteur ‘c’ et Z(t,i) est la cote Z pour le trait ‘i’ dans le texte soumis au test.
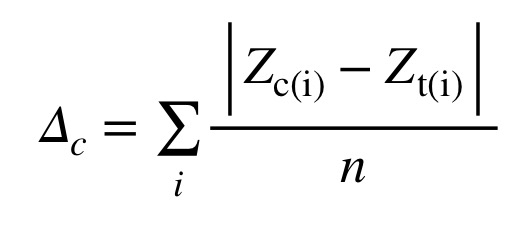
Figure 8: Formule de calcul du Delta de John Burrows.
- Le “vainqueur” est l’auteur pour lequel la cote Delta est le plus bas.
Stefan Evert et al17 présentent une discussion détaillée des variantes, complexités et raffinements de la méthode, mais nous nous en tiendrons à l’algorithme de base pour les besoins de ce tutoriel. Si vous lisez l’espagnol, une autre explication de la méthode Delta et une application de celle-ci à un corpus de romans se retrouvent dans un récent article de José Calvo Tello.18
Notre cas de test
Nous allons tester la méthode à l’aide de l’article Fédéraliste 64. Dans la lettre mentionnée au début de ce tutoriel, Alexander Hamilton affirmait en être l’auteur. Un brouillon du Fédéraliste 64 a cependant été retrouvé plus tard dans les papiers personnels de John Jay et le consensus scientifique lui reconnaît la paternité du texte. On ne soupçonne pas Hamilton d’avoir eu de mauvaises intentions. En effet, dans la même lettre, Hamilton attribuait à Jay un autre article, dont le numéro est similaire, qu’il avait pourtant clairement rédigé lui-même. Hamilton, distrait par la perspective de se battre en duel, a peut-être été victime d’un trou de mémoire.
Puisque la méthode Delta fonctionne peu importe le nombre de candidats au titre d’auteur du texte anonyme (l’article original de Burrows en utilise environ 25), nous comparerons la signature stylistique de Fédéraliste 64 à celles de cinq corpus : les textes de Hamilton, ceux de Madison, ceux de Jay, ceux qui ont été co-rédigés par Hamilton et Madison et ceux qui sont revendiqués par ces deux derniers. Nous nous attendons à ce que la méthode Delta affirme que Jay est l’auteur le plus probable. Tout autre résultat remettrait en question soit la méthode, soit l’historiographie, soit les deux.
Sélection des traits à étudier
Combinons les cinq sous-corpus en un seul corpus pour que Delta puisse calculer un “standard” auquel tout comparer par la suite. Choisissons ensuite un nombre de mots à utiliser comme traits distinctifs. Rappelons que nous avons utilisé 500 mots dans le calcul du khi carré de Kilgariff. Cette fois-ci, nous allons nous limiter à 30 traits, tous ou presque des mots-outils et des verbes auxiliaires.
# Nous allons comparer le cas spécial de test aux cinq autres corpus "d'auteurs"
auteurs = ["Hamilton", "Madison", "Jay", "Contestes", "Partages"]
# Convertir les occurrences en minuscules pour que toutes les occurrences
# d'un même mot, avec ou sans majuscule, soient comptabilisées ensemble
for auteur in auteurs:
federalist_par_auteur_occs[auteur] = (
[occ.lower() for occ in federalist_par_auteur_occs[auteur]])
# Former un seul corpus avec les articles des cinq "auteurs"
corpus_entier = []
for auteur in auteurs:
corpus_entier += federalist_par_auteur_occs[auteur]
# Obtenir une distribution de fréquences
corpus_entier_freq_dist = list(nltk.FreqDist(corpus_entier).most_common(30))
corpus_entier_freq_dist[ :10 ]
Un échantillon des mots les plus fréquents et de leurs nombres d’occurrences ressemble à ceci:
[('the', 17846),
('of', 11796),
('to', 7012),
('and', 5016),
('in', 4408),
('a', 3967),
('be', 3770),
('that', 2747),
('it', 2520),
('is', 2178)]
Calcul des traits de chaque sous-corpus
Calculons les présences de chacun des traits dans chacun des sous-corpus, en terme de pourcentages du nombre total d’occurrences dans ce sous-corpus. Nous enregistrerons les résultats de ces calculs dans un dictionnaire de dictionnaires, une structure de données commode pour représenter un tableau de données à deux dimensions en Python.
# La structure de données principale
traits = [mot for mot,freq in corpus_entier_freq_dist]
traits_freqs = {}
for auteur in auteurs:
# Un dictionnaire pour les traits de chaque auteur
traits_freqs[auteur] = {}
# Combien d'occurrences dans le corpus de cet auteur?
en_tout = len(federalist_par_auteur_occs[auteur])
# Calculer la présence de chaque trait dans le corpus de l'auteur
for trait in traits:
presence = federalist_par_auteur_occs[auteur].count(trait)
traits_freqs[auteur][trait] = presence / en_tout
Calcul des moyennes et des écarts-types pour chacun des traits
Étant données les présences des traits dans tous les sous-corpus que nous venons de calculer, nous pouvons déterminer une “moyenne de moyennes” et un écart-type pour chaque trait. Nous enregistrerons ces valeurs dans un autre dictionnaire de dictionnaires.
import math
# La structure de données dans laquelle nous allons enregistrer les statistiques
# du corpus
corpus_traits = {}
# Pour chaque trait...
for trait in traits:
# Créer un sous-dictionnaire comprenant la moyenne et l'écart-type pour ce trait
corpus_traits[trait] = {}
# Calculer la moyenne des fréquences observées chez chaque auteur
trait_moyenne = 0
for auteur in auteurs:
trait_moyenne += traits_freqs[auteur][trait]
trait_moyenne /= len(auteurs)
corpus_traits[trait]["Moyenne"] = trait_moyenne
# Calculer l'écart-type
trait_ecart_type = 0
for auteur in auteurs:
diff = traits_freqs[auteur][trait] - corpus_traits[trait]["Moyenne"]
trait_ecart_type += diff*diff
trait_ecart_type /= (len(auteurs) - 1)
trait_ecart_type = math.sqrt(trait_ecart_type)
corpus_traits[trait]["EcartType"] = trait_ecart_type
Calcul des cotes Z
Nous allons maintenant transformer les présences observées de chaque trait dans chaque sous-corpus en cotes Z qui décrivent la distance entre ces observations et la “norme” du corpus. Il suffit d’appliquer la définition de la cote Z à chaque trait et d’enregistrer les résultats dans un autre tableau à deux dimensions.
traits_cotes_z = {}
for auteur in auteurs:
traits_cotes_z[auteur] = {}
for trait in traits:
# Calcul d'une cote Z: (valeur - moyenne) / écart-type
# Nous utiliserons des variables intermédiaires pour simplifier
# la lecture du code
trait_valeur = traits_freqs[auteur][trait]
trait_moyenne = corpus_traits[trait]["Moyenne"]
trait_ecart_type = corpus_traits[trait]["EcartType"]
traits_cotes_z[auteur][trait] = ((trait_valeur-trait_moyenne) /
trait_ecart_type)
Calcul des traits et des cotes Z du cas de test
Il faut maintenant comparer Fédéraliste 64 à la norme du corpus. Le segment de code ci-dessous, qui récapitule en quelque sorte tout ce que nous avons fait jusqu’ici, calcule les présences de chacun des 30 traits dans Fédéraliste 64 et transforme celles-ci en cotes Z:
# Diviser le cas spécial de test (Federalist 64) en ses occurrences
cas_special_occs = nltk.word_tokenize(federalist_par_auteur["CasSpecial"])
# Filtrer la ponctuation et convertir en lettres minuscules
cas_special_occs = [occ.lower() for occ in cas_special_occs
if any (c.isalpha() for c in occ)]
# Calculer les traits du cas spécial
en_tout = len(cas_special_occs)
cas_special_freqs = {}
for trait in traits:
presence = cas_special_occs.count(trait)
cas_special_freqs[trait] = presence / en_tout
# Calculer les cotes Z du cas spécial
cas_special_cotes_z = {}
for trait in traits:
trait_valeur = cas_special_freqs[trait]
trait_moyenne = corpus_traits[trait]["Moyenne"]
trait_ecart_type = corpus_traits[trait]["EcartType"]
cas_special_cotes_z[trait] = (trait_valeur - trait_moyenne) / trait_ecart_type
print( "Cote Z du Federalist 64 pour le trait", trait, "=",
cas_special_cotes_z[trait])
Les résultats du calcul des cotes Z pour quelques traits du Federalist 64 ressemblent à ceci:
Cote Z du Fédéraliste 64 pour le trait the = -0.7692828380408238
Cote Z du Fédéraliste 64 pour le trait of = -1.8167784558461264
Cote Z du Fédéraliste 64 pour le trait to = 1.032705844508835
Cote Z du Fédéraliste 64 pour le trait and = 1.0268752924746058
Cote Z du Fédéraliste 64 pour le trait in = 0.6085448502160903
Cote Z du Fédéraliste 64 pour le trait a = -0.9341289591084886
Calculs de Delta
Enfin, nous appliquerons la formule du Delta définie par Burrows pour obtenir des cotes comparant Fédéraliste 64 avec chacun des cinq sous-corpus. Rappelons que plus une cote Delta est basse, plus la signature stylistique de Fédéraliste 64 ressemble à celle du corpus auquel il est comparé dans le calcul de cett cote.
for auteur in auteurs:
delta = 0
for trait in traits:
delta += math.fabs((cas_special_cotes_z[trait] -
traits_cotes_z[auteur][trait]))
delta /= len(traits)
print( "Cote Delta du candidat", auteur, "est", delta )
Le résultat? Delta estime que Federalist 64 a bel et bien été rédigé par John Jay:
Cote Delta du candidat Hamilton est 1.768470453004334
Cote Delta du candidat Madison est 1.6089724119682816
Cote Delta du candidat Jay est 1.5345768956569326
Cote Delta du candidat Contestés est 1.5371768107570636
Cote Delta du candidat Partagés est 1.846113566619675
Comme prévu, le Delta parmet d’identifier John Jay comme l’auteur le plus probable de Fédéraliste 64. Il est intéressant de noter que, selon le Delta, Fédéraliste 64 est cependant plus proche des articles contestés par Hamilton et Madison que de ceux qui ont clairement été écrits par l’un ou par l’autre. L’explication de ce phénomène devra cependant attendre une autre occasion.
Lectures et ressources additionnelles
Études de cas intéressantes
La stylométrie et/ou l’identification des auteurs de textes anonymes, à l’aide de plusieurs techniques différentes, ont été utilisées dans de multiples contextes. Voici quelques études de cas intéressantes:
- Javier de la Rosa et Juan Luis Suárez tentent de déterminer l’auteur d’un célèbre roman espagnol du XVIe siècle, à partir d’une liste de candidats d’une taille considérable.19
- Maria Slautina et Mikhail Marusenko appliquent la reconnaissance des motifs à un ensemble de traits lexicométriques, grammaticaux et syntactiques, allant des simples décomptes de mots étiquetés grammaticalement jusqu’à différentes phrases complexes, pour établir la similarité stylistique entre des textes médiévaux.20
- Ellen Jordan, Hugh Craig et Alexis Antonia examinent des périodiques britanniques du XIXe siècle, dans lesquels les articles étaient habituellement anonymes, pour déterminer l’auteur de quatre critiques d’oeuvres écrites par les soeurs Brontë ou qui parlent de ces dernières.21 Cette étude applique une version préliminaire d’une autre technique développée par John Burrows, celle du Zeta, qui se concentre sur les mots favoris d’un auteur plutôt que sur les mots-outils.22
- Valérie Beaudoin et François Yvon étudient 58 pièces en vers de Corneille, de Racine et de Molière, pour conclure que la structure des oeuvres des deux premiers était beaucoup plus prévisible.23
- Marcelo Luiz Brocardo, Issa Traore, Sherif Saad et Isaac Woungang appliquent des techniques d’apprentissage automatique supervisé et développent des modèles de n-grammes pour déterminer les auteurs de courts messages pour lesquels de grands nombres de candidats existent, comme le courrier électronique et les tweets.24
- Moshe Koppel et Winter Yaron ont proposé la “méthode de l’imposteur”, qui tente de déterminer si deux textes ont été écrits par la même personne en les insérant dans un ensemble de textes rédigés par de faux candidats.25 Justin Anthony Stover et al. ont appliqué la même technique pour déterminer l’auteur d’un manuscrit du IIe siècle récemment découvert.26
- Enfin, une équipe dirigée par David I. Holmes étudie le curieux exemple de documents qui ont été écrits soit par un soldat de la guerre de Sécession américaine, soit par sa veuve qui aurait peut-être copié intentionnellement le style d’écriture de son défunt mari.27
Autres références sur la stylométrie
La référence la plus complète en matière d’identification d’auteurs, incluant l’histoire de la discipline, ses fondements mathématiques et linguistiques et ses méthodes, a été écrite par Patrick Juola en 2007.28 Le chapitre 7 démontre notamment comment appliquer les méthodes d’attribution pour relever des marqueurs d’identités de genre, de nationalité, de dialecte, etc., pour suivre l’évolution du langage dans le temps, et même pour étudier la personnalité et la santé mentale des auteurs.
Un résumé plus concis se retrouve dans Moshe Koppel et al., qui discute des cas où il n’y a qu’un seul candidat dont il faut confirmer le rôle d’auteur, de grands nombres de candidats pour lesquels il n’existe que de petits échantillons d’écriture, ou même pas de candidat du tout.29
L’article de Stamatatos déjà cité2 contient lui aussi un résumé de qualité.
Varia
Les historiens programmeurs qui désirent explorer la stylométrie plus en profondeur pourraient être intéressés par le téléchargement du module Stylo30, qui s’est établi comme un standard de facto. Stylo contient notamment une implantation de la méthode Delta, des outils d’extraction de traits caractéristiques et des interfaces graphiques pour la manipulation de données et pour la production de résultats visuellement attrayants. Notez que Stylo est programmé en langage R, ce qui signifie qu’il vous faudra avoir installé R sur votre ordinateur pour vous en servir. Cependant, l’interface graphique et les tutoriels fournis avec Stylo sont suffisamment intuitifs pour que peu ou pas d’expérience préalable avec R ne soit nécessaire.
Clémence Jacquot explore les implications épistémiques de l’interaction entre les méthodes qualitatives et quantitatives dans le cadre d’une analyse du style d’écriture.31
Étonnamment, il a été démontré qu’il est possible d’identifier l’auteur d’un texte même lorsque l’on ne dispose pour celui-ci que de données d’océrisation qui souffrent d’un taux d’erreurs élevé.32
Les lecteurs qui souhaitent en savoir plus sur l’histoire du Fédéraliste et sur les diverses théories qui ont été proposées à son sujet sont invités à consulter en premier lieu les travaux d’Irving Brant33 et de Paul Ford et Edward Bourne34. Le sujet est cependant presque inépuisable.
Enfin, il existe un groupe Zotero dédié à la stylométrie, où l’on peut trouver des références à de nombreuses études et méthodes supplémentaires.
Remerciements
La première itération de ce projet a été développée dans le cadre des séminaires de recherche de Stéfan Sinclair et d’Andrew Piper à l’Université McGill (Canada). Merci à ma directrice de recherche doctorale, Susan Dalton, pour ses conseils toujours précieux.
Notes
-
Voir, par exemple, Justin Rice, “What Makes Hemingway Hemingway? A statistical analysis of the data behind Hemingway’s style” ↩
-
Efstathios Stamatatos, “A Survey of Modern Authorship Attribution Method,” Journal of the American Society for Information Science and Technology, vol. 60, no. 3 (Décembre 2008), p. 538–56, citation à la page 540, https://doi.org/10.1002/asi.21001. ↩ ↩2 ↩3
-
Jan Rybicki, “Vive La Différence: Tracing the (Authorial) Gender Signal by Multivariate Analysis of Word Frequencies,” Digital Scholarship in the Humanities, vol. 31, no. 4 (Décembre 2016), p. 746–61, https://doi.org/10.1093/llc/fqv023. Sean G. Weidman et James O’Sullivan, “The Limits of Distinctive Words: Re-Evaluating Literature’s Gender Marker Debate,” Digital Scholarship in the Humanities, 2017, https://doi.org/10.1093/llc/fqx017. ↩
-
Ted Underwood, David Bamman, et Sabrina Lee, “The Transformation of Gender in English-Language Fiction”, Cultural Analytics, 13 février 2018, DOI: 10.7910/DVN/TEGMGI. ↩
-
Sven Meyer zu Eissen et Benno Stein, “Intrinsic Plagiarism Detection,” dans ECIR 2006, édité par Mounia Lalmas, Andy MacFarlane, Stefan Rüger, Anastasios Tombros, Theodora Tsikrika et Alexei Yavlinsky, Berlin, Heidelberg: Springer, 2006, p. 565–69, https://doi.org/10.1007/11735106_66. ↩
-
Cynthia Whissell, “Traditional and Emotional Stylometric Analysis of the Songs of Beatles Paul McCartney and John Lennon,” Computers and the Humanities, vol. 30, no. 3 (1996), p. 257–65. ↩
-
Douglass Adair, “The Authorship of the Disputed Federalist Papers”, The William and Mary Quarterly, vol. 1, no. 2 (Avril 1944), p. 97-122. ↩
-
David I. Holmes et Richard S. Forsyth, “The Federalist Revisited: New Directions in Authorship Attribution”, Literary and Linguisting Computing, vol. 10, no. 2 (1995), p. 111-127. ↩
-
Frederick Mosteller, “A Statistical Study of the Writing Styles of the Authors of the Federalist Papers”, Proceedings of the American Philosophical Society, vol. 131, no. 2 (1987), p. 132‑40. ↩
-
Frederick Mosteller et David Lee Wallace, Inference and Disputed Authorship: The Federalist, Addison-Wesley Series in Behavioral Science : Quantitative Methods (Reading, Mass.: Addison-Wesley, 1964). ↩
-
Voir par exemple Glenn Fung, “The disputed Federalist papers: SVM feature selection via concave minimization”, TAPIA ‘03: Proceedings of the 2003 conference on Diversity in Computing, p. 42-46; et Robert A. Bosch et Jason A. Smith, “Separating Hyperplanes and the Authorship of the Disputed Federalist Papers,” The American Mathematical Monthly, vol. 105, no. 7 (1998), p. 601–8, https://doi.org/10.2307/2589242. ↩
-
Jeff Collins, David Kaufer, Pantelis Vlachos, Brian Butler et Suguru Ishizaki, “Detecting Collaborations in Text: Comparing the Authors’ Rhetorical Language Choices in The Federalist Papers”, Computers and the Humanities, vol. 38 (2004), p. 15-36. ↩
-
Mosteller, “A Statistical Study…”, p. 132-133. ↩
-
T. C. Mendenhall, “The Characteristic Curves of Composition”, Science, vol. 9, no. 214 (11 mars 1887), p. 237-249. ↩
-
Adam Kilgarriff, “Comparing Corpora”, International Journal of Corpus Linguistics, vol. 6, no. 1 (2001), p. 97-133. ↩
-
John Burrows, “‘Delta’: a Measure of Stylistic Difference and a Guide to Likely Authorship”, Literary and Linguistic Computing, vol. 17, no. 3 (2002), p. 267-287. ↩
-
Stefan Evert et al., “Understanding and explaining Delta measures for authorship attribution”, Digital Scholarship in the Humanities, vol. 32, no. suppl_2 (2017), p. ii4-ii16. ↩
-
José Calvo Tello, “Entendiendo Delta desde las Humanidades,” Caracteres, 27 mai 2016, http://revistacaracteres.net/revista/vol5n1mayo2016/entendiendo-delta/. ↩
-
Javier de la Rosa et Juan Luis Suárez, “The Life of Lazarillo de Tormes and of His Machine Learning Adversities,” Lemir, vol. 20 (2016), p. 373-438. ↩
-
Maria Slautina et Mikhaïl Marusenko, “L’émergence du style, The emergence of style,” Les Cahiers du numérique, vol. 10, no. 4 (Novembre 2014), p. 179–215, https://doi.org/10.3166/LCN.10.4.179-215. ↩
-
Ellen Jordan, Hugh Craig, et Alexis Antonia, “The Brontë Sisters and the ‘Christian Remembrancer’: A Pilot Study in the Use of the ‘Burrows Method’ to Identify the Authorship of Unsigned Articles in the Nineteenth-Century Periodical Press,” Victorian Periodicals Review, vol. 39, no. 1 (2006), p. 21–45. ↩
-
John Burrows, “All the Way Through: Testing for Authorship in Different Frequency Strata,” Literary and Linguistic Computing, vol. 22, no. 1 (Avril 2007), p. 27–47, https://doi.org/10.1093/llc/fqi067. ↩
-
Valérie Beaudoin et François Yvon, “Contribution de La Métrique à La Stylométrie,” JADT 2004: 7e Journées internationales d’Analyse statistique des Données Textuelles, vol. 1, Louvain La Neuve, Presses Universitaires de Louvain, 2004, p. 107–18. ↩
-
Marcelo Luiz Brocardo, Issa Traore, Sherif Saad et Isaac Woungang, “Authorship Verification for Short Messages Using Stylometry,” 2013 International Conference on Computer, Information and Telecommunication Systems (CITS), 2013, https://doi.org/10.1109/CITS.2013.6705711. ↩
-
Moshe Koppel et Winter Yaron, “Determining If Two Documents Are Written by the Same Author,” Journal of the Association for Information Science and Technology, vol. 65, no. 1 (Octobre 2013), p. 178–87, https://doi.org/10.1002/asi.22954. ↩
-
Justin Anthony Stover et al., “Computational authorship verification method attributes a new work to a major 2nd century African author”, Journal of the Association for Information Science and Technology, vol. 67, no. 1 (2016), p. 239–242. ↩
-
David I. Holmes, Lesley J. Gordon et Christine Wilson, “A widow and her soldier: Stylometry and the American Civil War”, Literary and Linguistic Computing, vol. 16, no 4 (2001), p. 403–420. ↩
-
Patrick Juola, “Authorship Attribution,” Foundations and Trends in Information Retrieval, vol. 1, no. 3 (2007), p. 233–334, https://doi.org/10.1561/1500000005. ↩
-
Moshe Koppel, Jonathan Schler et Shlomo Argamon, “Computational Methods in Authorship Attribution,” Journal of the Association for Information Science and Technology. vol. 60, no. 1 (Janvier 2009), p. 9–26, https://doi.org/10.1002/asi.v60:1. ↩
-
Maciej Eder, Jan Rybicki et Mike Kestemont, “Stylometry with R: A Package for Computational Text Analysis,” The R Journal, vol. 8, no. 1 (2016), p. 107–21. ↩
-
Clémence Jacquot, “Rêve d’une épiphanie du style: visibilité et saillance en stylistique et en stylométrie,” Revue d’Histoire Littéraire de la France , vol. 116, no. 3 (2016), p. 619–39. ↩
-
Patrick Juola, John Noecker Jr et Michael Ryan, “Authorship Attribution and Optical Character Recognition Errors”, TAL, vol. 53, no. 3 (2012), p. 101–127. ↩
-
Irving Brant, “Settling the Authorship of the Federalist”, The American Historical Review, vol. 67, no. 1 (Octobre 1961), p. 71-75. ↩
-
Paul Leicester Ford et Edward Gaylord Bourne, “The Authorship of the Federalist”, The American Historical Review, vol. 2, no. 4 (Juillet 1897), p. 675-687. ↩