
Contents
Introduction
Corpus analysis is a form of text analysis which allows you to make comparisons between textual objects at a large scale (so-called ‘distant reading’). It allows us to see things that we don’t necessarily see when reading as humans. If you’ve got a collection of documents, you may want to find patterns of grammatical use, or frequently recurring phrases in your corpus. You also may want to find statistically likely and/or unlikely phrases for a particular author or kind of text, particular kinds of grammatical structures or a lot of examples of a particular concept across a large number of documents in context. Corpus analysis is especially useful for testing intuitions about texts and/or triangulating results from other digital methods.
By the end of this tutorial, you will be able to:
- create/download a corpus of texts
- conduct a keyword-in-context search
- identify patterns surrounding a particular word
- use more specific search queries
- look at statistically significant differences between corpora
- make multi-modal comparisons using corpus lingiustic methods
You have done this sort of thing before, if you have ever…
- searched in a PDF or a word doc for all examples a specific term
- Used Voyant Tools for looking at patterns in one text
- Followed Programming Historian’s Introduction to Python tutorials
In many ways Voyant is a gateway into conducting more sophisticated, replicable analysis, as the DIY aesthetic of Python or R scripting may not appeal to everyone. AntConc fills this void by being a standalone software package for linguistic analysis of texts, freely available for Windows, Mac OS, and Linux and is highly maintained by its creator, Laurence Anthony. There are other concordance software packages available, but it is freely available across platforms and very well maintained. See the concordance bibliography for other resources.
This tutorial explores several different ways to approach a corpus of texts. It’s important to note that corpus linguistic approaches are rarely, if ever, a one-size-fits all affair. So, as you go through each step, it’s worth thinking about what you’re doing and how it can help you answer a specific question with your data. Although I present this tutorial in a building-block approach of ‘do this then that to achieve x’, it’s not always necessary to follow the exact order outlined here. This lessons provides an outline of some of the methods available, rather than a recipe for success.
Tutorial downloads
-
Software:AntConc. Unzip the download if necessary, and launch the application. Screen shots below may vary slightly from the version you have (and by operationg system, of course), but the procedures are more or less the same across platforms and recent versions of AntConc. This tutorial is written with a (much older) version of AntConc in mind, as I find it easier to use in an introductory context. You are welcome to use the most recent version, but if you wish to follow along with the screenshots provided, you can download the version used here, version 3.2.4.
-
Sample Corpus: Download the zip file of movie reviews.
A broad outline of this tutorial:
- Working with plain text files
- The AntConc user interface, loading corpora
- Keyword-in-context searching
- Advanced keyword-in-context searching
- Collocates and word lists
- Comparing corpora
- Discussion: Making meaningful comparisons
- Further resources
Working with Plain Text Files
- Antconc works only with plain-text files with the file appendix .txt (eg Hamlet.txt).
- Antconc will not read .doc, .docx, .pdf, files. You will need to convert these into .txt files.
- It will read XML files that are saved as .txt files (it’s OK if you don’t know what an XML file is).
Visit your favorite website for news, and navigate to a news article (doesn’t matter which one, as long as it is primarily text). Highlight all text in the article (header, byline, etc), and right-click “copy”.
Open a text editor such as Notepad (on Windows) or TextEdit (on Mac) and paste in your text.
Other free options for text editors include Notepad++ (Windows) or TextWrangler (Mac), which offer more advanced features, and are especially good for doing a lot of text clean-up. By text clean-up, I mean removing extratextual information such as “boilerplate”, which appears regularly throughout. If you keep this information, it’s going to throw your data off; text analysis software will address these words in word counts, statistical analyses, and lexical relationships. For example, you might want to remove standard headers and footers which will appear on every page. Please see “Cleaning Data with OpenRefine” for more on how to automate this task. On smaller corpora it may be more feasible to do this yourself, plus you’ll get a much better sense of your corpus this way.
Save the article as a .txt file to the desktop. You may want to do some follow-up text cleanup on other information, such as author by-line or title (remove them, then save the file again.) Remember that anything you leave in the text file can and will be addressed by text analysis software.
Go to your desktop and check to see you can find your text file.
Repeating this a lot is how you would build a corpus of plain text files; this process is called corpus construction, which very often involves addressing questions of sampling, representativeness and organization. Remember, each file you want to use in your corpus _must_ be a plain text file for Antconc to use it. It is customary to name files with the .txt suffix so that you know what kind of file it is.
As you might imagine, it can be rather tedious to build up a substantial corpus one file at a time, especially if you intend to process a large set of documents. It is very common, therefore, to use webscraping (using a small program to automatically grab files from the web for you) to construct your corpus. To learn more about the concepts and techniques for webscraping, see the Programming Historian tutorials scraping with Beautiful Soup and automatic downloading with wget. Rather than build a corpus one document at a time, we’re going to use a prepared corpus of positive and negative movie reviews, borrowed from the Natural Language Processing Toolkit. The NLTK movie review corpus has 2000 reviews, organized by positive and negative outcomes; today we will be addressing a small subset of them (200 positive, 200 negative).
Corpus construction is a subfield in its own right. Please see Representativeness in Corpus Design,” Literary and Linguistic Computing, 8 (4): 243-257 and Developing Linguistic Corpora: a Guide to Good Practice for more information.
Getting Started with AntConc: The AntConc user interface, loading corpora
When AntConc launches, it will look like this.
AntConc opening screen.
On the left-hand side, there is a window to see all corpus files loaded (which we’ll use momentarily).
There are 7 tabs across the top: Concordance: This will show you what’s known as a Keyword in Context view (abbreviated KWIC, more on this in a minute), using the search bar below it. Concordance Plot: This will show you a very simple visualization of your KWIC search, where each instance will be represented as a little black line from beginning to end of each file containing the search term. File View: This will show you a full file view for larger context of a result. Clusters: This view shows you words which very frequently appear together. Collocates: Clusters show us words which _definitely _appear together in a corpus; collocates show words which are statistically likely to appear together. Word list: All the words in your corpus. Keyword List: This will show comparisons between two corpora.
As an introduction, this tutortial barely scratches the surface of what you can do with AntConc. We will focus on the Concordance, Collocates, Keywords, and Word List functions.
Loading Corpora
Like opening a file elsewhere, we’re going to start with File > Open, but instead of opening just ONE file we want to open the directory of all our files. AntConc allows you to open entire directories, so if you’re comfortable with this concept, you can just open the folder ‘all reviews’ and jump to Basic Analysis, below
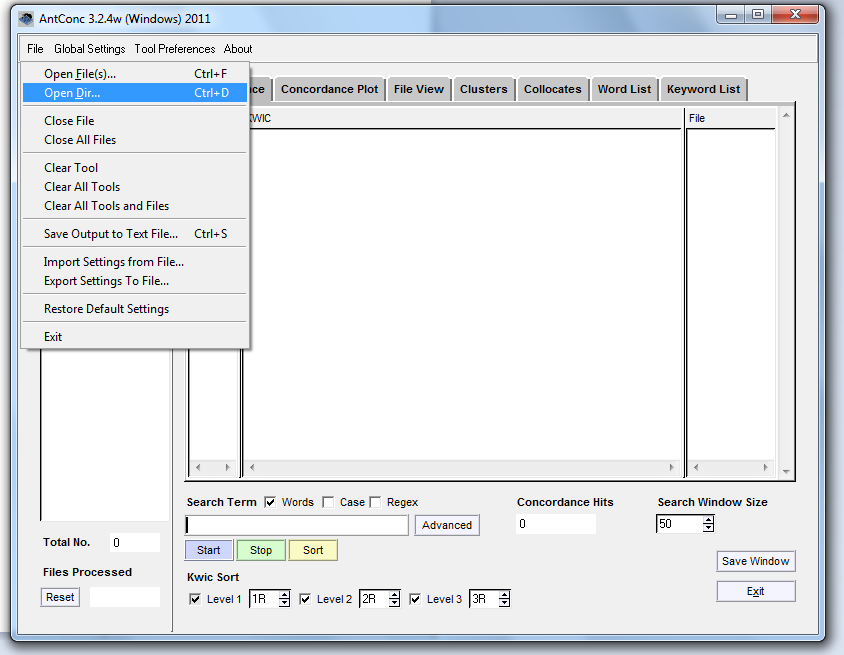
Opening a directory of files.
Remember we’ve put our files on the desktop, so navigate there in the dropdown menu.
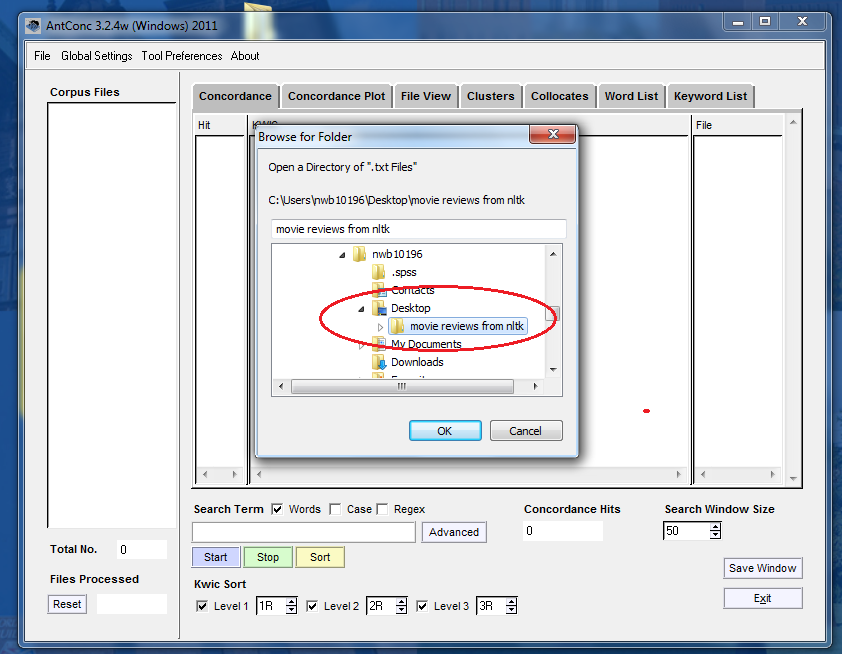
Opening a directory of files from your Desktop.
From the Desktop you want to navigate to our folder “movie reviews from nltk”:
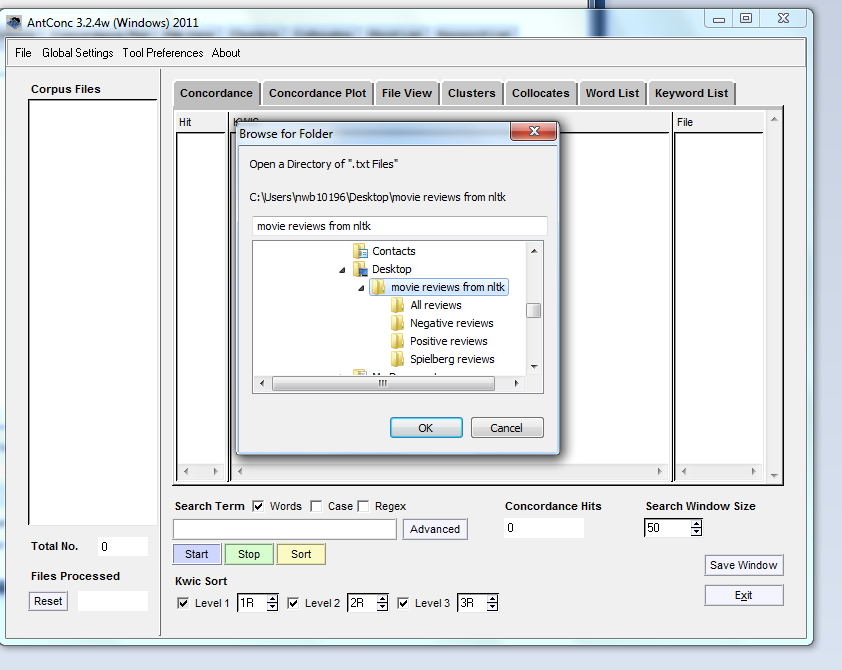
Finding movie reviews.
First you will select “Negative Reviews” and hit OK. 200 texts should load in the lefthand column Corpus Files – watch the Total No. box!
Loading negative reviews.
Then you’re going to repeat the process to load the folder “Positive Reviews”. You should now have 400 texts in the Corpus Files column.
Loading positive reviews.
All reviews loaded.
Searching Keywords in Context
Start with a basic search
One of the things corpus tools like Antconc are very good at are finding patterns in language which we have a hard time identifying as readers. Small boring words like the, I, he, she, a, an, is, have, will are especially difficult to keep track of as readers, because they’re so common, but computers happen to be very good at them. These words are called function words, though they commonly known as ‘stopwords’ in digital humanities; they are often very distinct measures of authorial and generic style. As a result, they can be quite powerful search terms on their own or when combined with more content-driven terms, helping the researcher identify patterns they may not have been aware of previously.
In the search box at the bottom, type the and click “start”. The Concordance view will show you every time the word the appears in our corpus of movie reviews, and some context for it. This is called a “Key Words in Context” viewer.
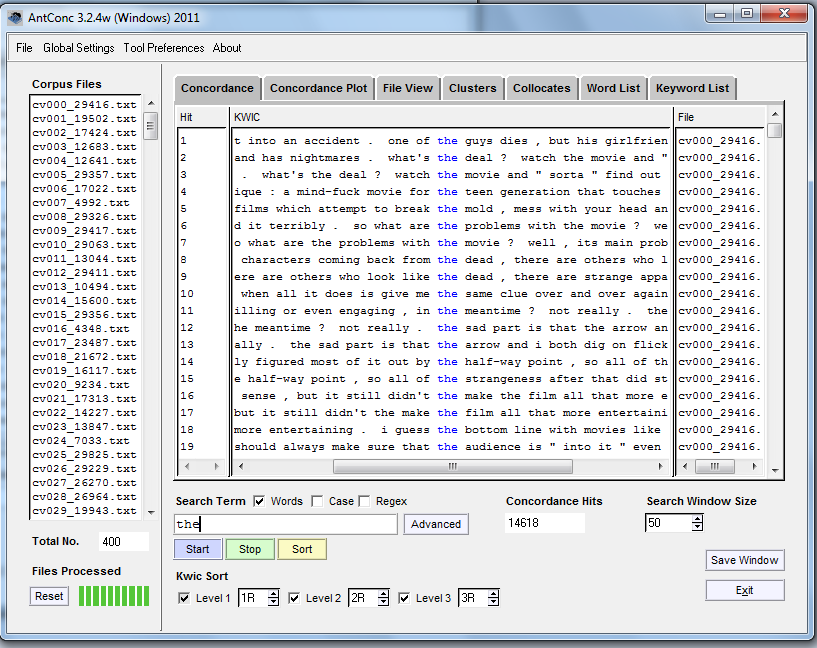
‘The’ is a common word.
(14618 times, according to the Concordance Hits box in the bottom centre.)
As above, the KWIC list is a good way to start looking for patterns. Even though it’s still a lot of information, what kinds of words appear near “the”?
Try a similar search for “a”. Both “a” and “the” are articles, but one is a definite article and one an indefinite article - and the results you get will be illustrative of that.
Now that you’re comfortable with looking at a KWIC line, try doing it again with “shot”: this will produce examples of both shot the noun (‘line up the shot’) and the verb ‘this scene was shot carefully’)
What do you see? I understand this can be a difficult to read way of identifiying patterns. Try pressing the yellow “sort” button. What happens now?
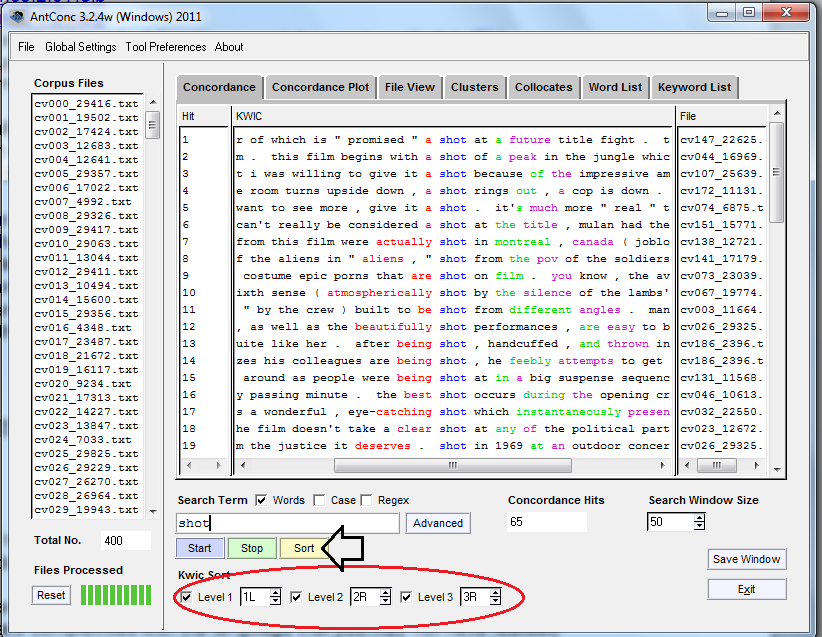
Words that appear next to ‘shot’.
(This might be easier to read!) You can adjust the way AntConc sorts information by changing the parameters in the red circle: L corresponds with ‘left’ and R corresponds with ‘right’; you can extend these up to ±5 in either direction. The default is 1 left, 2 right, 3 right, but you can change that to search 3 left, 2 left, 1 right (to get phrases and/or trigrams that end in the search term in question, for example) by clicking the arrow buttons up or down. If you don’t want to include a sorting option you can skip it (as in the default: 1L, 2R, 3R) or include it as a 0. Less linear sorting practices are available, such as 4 left, 3 right, 5 right, which includes a lot of other contextual information. These parameters can be slow to respond, but be patient. If you’re not sure what the resulting search is, just press ‘sort’ to see what’s happened and adjust accordingly.
Search Operators
The * operator (wildcard)
The * operator (which finds zero or more characters) can help, for instance, find both the singular and the plural forms of nouns.
Task: Search for qualit*, then sort this search. What tends to precede and follow quality & qualities? (Hint: they’re different words, and have different contexts. Again- look for patterns in usage using the KWIC!)
For a full list of available wildcard operators and what they mean, go to Global Settings > Wildcard Settings.
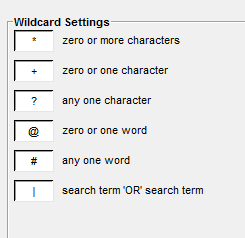
Adjusting the wildcard settings.
To find out the difference between * and ?, search for th*n and th?n. These two search queries look very similiar, but show very different results.
The ? operator is more specific than the * operator: wom?n – both women and woman m?n – man and men, but also min contrast to m*n: not helpful, because you’ll get mean, melon, etc.
Task: Compare these two searches: wom?n and m?n
- sort each search in a meaningful way (eg. by search term then 1L then 2L)
- File > Save output to text file (& append with .txt.
HINT: During the course of exploring in your research, you may generate many such files for reference; it’s helpful to use descriptive filenames that describe what’s in them (such as “wom?n-results.text”, not “antconc_results.txt”).
Save output as text file
Save As dialog window.
And now you can open the plain text file in your text editor; you might have to widen the application window to make it readable:
The plain text file displayed in a text editor.
Do this for each of the two searches and then look at the two text files side by side. What do you notice?
The | operator (“or”)
Task: Search on she|he.
Now search for these separately: how many instances of she vs he?
There are many fewer instances of she – why? That’s a research question! A good follow-up questions might be to sort the she|he search for patterns, and look to see if particular verbs follow each.
Task: Practice searching a word of your choice, sorting in different ways, using wildcard(s), and finally exporting. Guiding focus question here: what kinds of patterns do you see? Can you explain them?
Collocates and word lists
Having looked at the KWIC lines for patterns, don’t you wish there was a way for the computer to give you a list of words which appear most frequently in company with your keyword?
Good news - there is a way to get this information, and it’s available from the Collocates tab. Click that, and AntConc will tell you it needs to create a word list. Hit OK; it will do it automatically.
NOTE: You will only get this notice when you haven’t created a word list yet.
Word list warning
Try generating collocates for she.
The unsorted results will seem to start with function words (words that build phrases) then go down to content words (words that build meaning)– these small boring words are the most frequent words in English, which are largely phrase builders. Later versions of AntConc often include the search term as the first hit, presumably because the search term you are looking for shows up in the text and we are looking for words which are likely to appear with this word.
Some people might want to remove these small words by using a stopword list; this is a common step in topic modelling. Personally I don’t encourage this practice because addressing highly-frequent words is where computers shine! As readers we tend not to notice them very much. Computers, especially software like Antconc, can show us where these words do and do not appear and that can be quite interesting, especially in very large collections of text - as explored earlier in the tutorial, with the, a, she and he.
Additionally you may have a single letter ‘s’ appear, quite high as well - that represents the possessive ’s (the apostrophe won’t be counted), but AntConc considers that s indicative of another word. Another example of this is ‘t appearing with do, as they contract as don’t. Because these so commonly appear together, this makes them highly likely collocates.
Task: Generate collocates for m?n and wom?n. Now sort them by frequency to 1L. This tells us about what makes a man or woman ‘movie-worthy’: – women have to be ‘beautiful’ or ‘pregnant’ or ‘sophisticated’ – men have to be somehow outside the norm – ‘holy’ or ‘black’ or ‘old’
This is not necessarily telling us about the movies but about the way those movies are written about in reviews, and can lead us to ask more nuanced questions, like “How are women in romantic comedies described in reviews written by men compared to those written by women?”
Comparing corpora
One of the most powerful types of analysis is comparing your corpus to a larger reference corpus.
I’ve pulled out reviews of movies with which Steven Spielberg is associated (as director or producer). We can compare them to a reference corpus of movies by a range of directors.
Be sure to think carefully about what a reference corpus for your own research might look like (eg. a study of Agatha Christie’s language in her later years would work nicely as an analysis corpus for comparison to a reference corpus of all her novels). Remember, again, that corpus construction is a subfield in its own right.
Settings > Tool preferences > Keyword List Under ‘Reference Corpus’ make sure “Use raw files” is checked Add Directory > open the folder containing the files that make up the reference corpus Ensure you have a whole list of files!
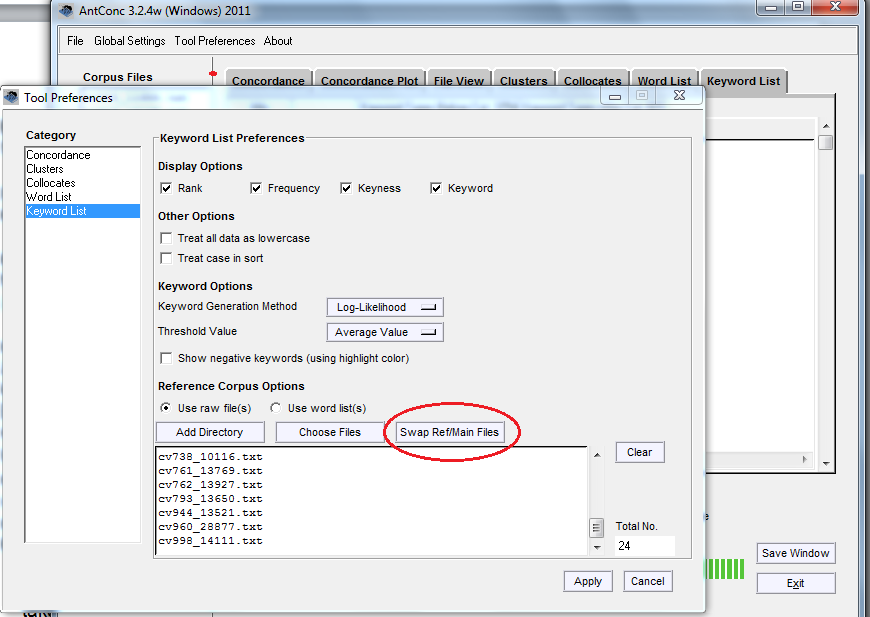
Adding a reference corpus.
Hit Load (& wait …) then once the ‘Loaded’ box is checked, hit Apply. You can also opt to swap reference corpus & main files (SWAP REF/MAIN FILES). It is worth looking at what both results show.
If you’re using a later version of AntConc, the Swap Ref/Main files option may be marked as ‘swap with target files’, and you will need to ensure the target and reference corpora have been loaded (press the load button each time you upload, or swap, a corpus).
In Keyword List, just hit Start (with nothing typed in the search box). If you’ve just swapped the reference corpus and the target files, you may be prompted to create a new word list before AntConc will calculate the keywords. We see a list of Keywords that have words that are much more “unusual” – more statistically unexpected – in the corpus we are looking at when compared to the reference corpus.
> Keyness: this is the frequency of a word in the text when compared with its frequency in a reference corpus, “such that the statistical probability as computed by an appropriate procedure is smaller than or equal to a p value specified by the user.” – taken from here.) For those interested in the statistical details, see the section on keyness on p7 of Laurence Anthony’s readme file.
What are our keywords?
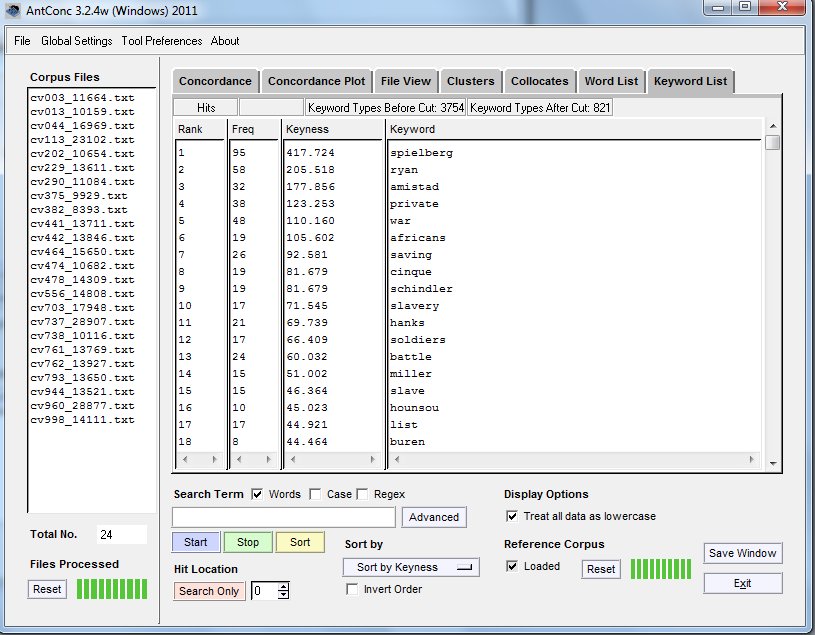
Spielberg vs movie reviews.
Discussion: Making meaningful comparisons
Keep in mind that the way your organize your text files makes a difference to the kinds of questions you can ask and the kinds of results you will get. Remember that we are comparing ‘negative’ and ‘positive’ reviews quite flatly here. You could, for instance, make other comparisons with different subsets of reviews, which yield very different kinds of questions.
Of course, the files you put in your corpus will shape your results. Again, the question of representativeness and sampling are highly relevant here – it’s not always necessary or even ideal to use all of a dataset at once, even if you do have it. At this juncture, it’s really worth interrogating how these methods help produce research questions.
When thinking about how movie reviews work as a genre, you could consider, for example…
- Movie reviews vs music reviews
- Movie reviews vs book reviews
- Movie reviews vs news articles about sport
- Movie reviews vs news articles in general
Each of these comparisons will tell you something different, and can produce different research questions, such as:
- How are movie reviews different than other kinds of media reviews?
- How are movie reviews different than other kinds of published writing?
- How do movie reviews compare to other specific kinds of writing, such as sport writing?
- How do movie reviews have in common with music reviews?
And of course you could flip those questions to make further research questions:
- How are book reviews different to movie reviews?
- How are music reviews different than movie reviews?
- What do published newspaper articles have in common?
- How are movie reviews similar to other kinds of published writing?
In summary: it’s worth thinking about:
- Why you might want to compare two corpora
- What kinds of queries make meaningful research questions
- Principles of corpora construction: sampling & ensuring you can get something representative
Further resources for this tutorial
A short bibliography on corpus linguistics. A more step-by-step version of this tutorial, assuming no computer knowledge