
Contenidos
- Introducción
- Búsqueda de palabras clave en contexto
- Discusión: hacer comparaciones significativas
- Notas de traducción
Introducción
El análisis de corpus es un tipo de análisis de textos que permite hacer comparaciones a gran escala entre objetos presentes en los mismos —esto es, aquello que se conoce como lectura distante—. Lo anterior hace posible apreciar fenómenos que no necesariamente se hacen visibles cuando leemos. Si, por ejemplo, dispones de una colección de documentos, es posible que desearas encontrar patrones de uso gramatical o frases de aparición recurrente en la misma. También puede ser que quisieras hallar frases cuya probabilidad de aparición fuese más alta o más baja en la obra de un autor, o bien en un tipo determinado de textos; clases particulares de estructuras gramaticales; o muchos ejemplos de un concepto particular en una gran cantidad de documentos que se encuentran enmarcados en cierto contexto. En este sentido, el análisis de corpus resulta muy útil para demostrar hipótesis sobre textos, o para triangular resultados obtenidos a través de otras metodologías de análisis textual basadas en herramientas digitales.
Al finalizar este tutorial, tendrás la capacidad de:
- Crear o descargar un corpus de textos.
- Realizar una búsqueda de palabras clave en contexto.
- Identificar patrones respecto de una palabra determinada.
- Utilizar criterios de búsqueda más específicos.
- Revisar diferencias estadísticamente significativas entre corpus.
- Efectuar comparaciones multimodales a través de metodologías de análisis propias de la lingüística de corpus.
Es posible que te hayas acercado a la ejecución de análisis como el que se describe aquí si has realizado alguna de las siguientes tareas:
- Búsqueda de todas las apariciones de un término específico en un archivo PDF o un documento de Microsoft Word®.
- Uso de Voyant Tools para revisar patrones en un texto.
- Lectura y desarrollo de los tutoriales de introducción a Python disponibles en The Programming Historian.
En muchos sentidos, Voyant es una puerta de entrada a la realización de análisis más sofisticados y replicables, ya que la naturaleza de tipo “házlo tú mismo” de los scripts en Python o R puede no ser atractiva para todos. AntConc llena este vacío en tanto se propone como una aplicación informática independiente para el análisis lingüístico de textos, la cual se encuentra disponible de forma gratuita para los sistemas operativos Windows, Mac OS X y Linux (funciona, por tanto, en múltiples plataformas), y es objeto de actualizaciones permanentes por parte de su creador, Laurence Anthony1; si bien existen otras aplicaciones para efectuar análisis de concordancias lingüísticas, se resaltan de AntConc las dos cualidades señaladas (para acceder a recursos adicionales sobre esta temática, véase An Introductory Bibliography to Corpus Linguistics).
En este tutorial se presentan varias maneras diferentes de acercarse a un corpus de textos. Es importante tener en cuenta que las metodologías de lingüística de corpus no funcionan en todas las situaciones. Con esto, conforme sigas los pasos propuestos, es conveniente que reflexiones sobre la tarea que estés realizando y cómo puede ser de utilidad para responder una pregunta específica en relación con los datos de los que dispongas. En este sentido, si bien la presente lección está construida bajo la metodología “haz esto y luego esto para lograr X”, no siempre es necesario seguir en orden estricto los pasos que se muestran aquí: se brinda en este espacio una síntesis general de algunos de los métodos disponibles para realizar análisis de esta naturaleza, en lugar de una receta única para el éxito.
Descargas necesarias para el desarrollo de este tutorial
-
Descomprime el archivo del programa (si fuere necesario) e inícialo. Las capturas de pantalla presentadas aquí pueden diferir ligeramente de la versión de AntConc que utilices (y del sistema operativo, desde luego), pero los procedimientos son más o menos los mismos en todas las plataformas y versiones recientes de la aplicación. Este tutorial fue escrito teniendo como referente una versión específica (bastante antigua) de AntConc, en tanto consideramos que resulta más fácil de usar para fines introductorios. Puedes emplear la versión más reciente para desarrollar el tutorial si lo tienes a bien; pero, si deseas seguir los pasos con la misma información que presentamos en las capturas de pantalla de esta lección, es necesario que descargues la versión específica que empleamos aquí (3.2.4).
-
Corpus de prueba: descarga este archivo zip de reseñas cinematográficas (escritas en inglés).
Presentación sintética de las temáticas abordadas en la lección
- Trabajar con archivos de texto plano
- Interfaz de usuario y carga de corpus en AntConc
- Búsqueda de palabras clave en contexto
- Búsqueda avanzada de palabras clave en contexto
- Colocaciones y listas de palabras
- Comparación de corpus
- Discusión: hacer comparaciones significativas
- Recursos adicionales
Trabajar con archivos de texto plano
- AntConc solo funciona con archivos de texto plano de extensión .txt (por ejemplo, “Hamlet.txt”); no puede leer archivos de extensiones .doc, .docx o .pdf. Por lo tanto, si dispones de documentos de este tipo, deberás convertirlos en archivos .txt.
- La aplicación tiene la capacidad de trabajar con archivos XML (no te preocupes si los desconoces) guardados con la extensión .txt.
Visita tu portal de noticias favorito y accede a un artículo (su naturaleza no importa, siempre que se componga mayoritariamente de texto). Luego, selecciona todo el texto (encabezado, pie de página, cuerpo, etc.), haz clic derecho y selecciona “copiar”. Después, abre un editor de texto como Bloc de notas (Windows) o TextEdit (Mac OS X) y pega allí el texto que copiaste.
Existen otros editores de texto de uso gratuito, tales como Notepad++ (Windows) o TextWrangler (Mac OS X), que ostentan funciones más avanzadas y son particularmente útiles para hacer una gran cantidad de tareas de limpieza de texto. Con esto último hacemos referencia a eliminar datos paratextuales tales como el texto boilerplate (información que incluye elementos como el título de la página, los datos del editor, etc.), el cual aparece de forma reiterada en muchos artículos. Si, por el contrario, conservas esta información, los datos se verán comprometidos, por cuanto el programa de análisis de texto tomará en cuenta estos términos en recuentos de palabras, análisis estadísticos y relaciones léxicas. A este respecto podrías considerar, por ejemplo, la posibilidad de eliminar los encabezados y pies de página estándar que aparecen en cada página (véase el tutorial Limpieza de datos con OpenRefine para más información sobre cómo automatizar esta tarea). Ahora bien, en corpus de menor tamaño podría ser más conveniente que tú mismo hicieras dicha labor; de esa manera, adquirirás una mejor percepción de tu corpus.
- Guarda el artículo como un archivo .txt en el escritorio. Cabría la posibilidad de que hicieras labores adicionales de limpieza del texto, tales como la remoción de los datos del autor (elimínalos y guarda el archivo nuevamente). Recuerda en este sentido que toda la información que permanezca en el archivo puede y será tomada en cuenta por el programa de análisis de texto.
- Ve al escritorio y verifica que puedas encontrar el archivo de texto que guardaste.
Mediante la ejecución repetida de las tareas anteriores se construye un corpus de archivos de texto plano; esta labor suele implicar el abordaje de asuntos relacionados con muestreo, representatividad y organización. Recuerda: es necesario que cada archivo de tu corpus sea de texto plano para que AntConc pueda interpretarlo. A este respecto, se acostumbra nombrar los archivos con la extensión .txt para reconocer fácilmente su naturaleza.
Como lo supondrás, crear un corpus significativo puede resultar bastante tedioso si este se compone archivo por archivo, en especial si pretendes analizar un conjunto extenso de documentos. Por lo tanto, es muy común hacer web scraping (esto es, usar un programa sencillo para tomar archivos de la web de forma automatizada) para construir el corpus; si deseas obtener más información acerca de los conceptos y técnicas asociados a dicha labor, consulta las lecciones Scraping with Beautiful Soup y Automatic Downloading with wget, disponibles en The Programming Historian. Para efectos de este tutorial, en lugar de componer el corpus documento por documento, vamos a utilizar uno ya existente, compuesto por reseñas cinematográficas y tomado del Natural Language Processing Toolkit (NLTK). Este corpus se compone de 2000 reseñas, organizadas por su carácter —positivo o negativo—; abordaremos aquí un pequeño subconjunto de ellas (200 de cada categoría).
La construcción de corpus es un campo de estudio en sí mismo. Para más información sobre este tópico, sugerimos consultar “Representativeness in Corpus Design”, Literary and Linguistic Computing, 8 (4): 243-257; y Developing Linguistic Corpora: a Guide to Good Practice3.
Primeros pasos con AntConc: interfaz de usuario y carga de corpus en la aplicación
Al iniciarse, AntConc se verá como en la siguiente imagen:
Ventana principal de AntConc
En el costado izquierdo de la pantalla principal hay un cuadro que enlista todos los archivos cargados del corpus, el cual usaremos más adelante.
La parte superior de la aplicación consta de 7 pestañas:
- Concordance (concordancia): muestra lo que se conoce como keyword in context view (vista de palabras clave en contexto [KWIC, por sus iniciales en inglés]), cuyos resultados se obtienen mediante la barra de búsqueda.
- Concordance Plot (mapa de concordancia): presenta una visualización muy sencilla de los resultados de la búsqueda de palabras clave en contexto. Las apariciones del término buscado se representarán como pequeñas líneas negras dentro de un rectángulo que representa la extensión total de cada archivo analizado.
- File View (vista de archivo): brinda una vista del archivo completo en la que se resaltan las apariciones del término buscado, con lo cual se obtiene una visión más amplia del contexto en el que este aparece.
- Clusters (clústeres): muestra palabras que aparecen juntas muy frecuentemente.
- Collocates (colocaciones): mientras que la pestaña anterior muestra palabras que definitivamente aparecen juntas en el corpus, esta presenta aquellas que tienen una alta probabilidad de estarlo.
- Word List (lista de palabras): muestra todas las palabras del corpus.
- Keyword List (lista de palabras clave): presenta los resultados de comparaciones entre dos corpus.
Dado su carácter introductorio, este tutorial solo brinda una mirada superficial a lo que se puede hacer con AntConc. En consecuencia, solo nos concentraremos aquí en las funciones de las pestañas Concordance, Collocates, Keywords y Word List.
Carga de corpus
Tal como sucede con cualquier otro programa informático, comenzaremos por ir a “File” – “Open” (“Archivo” – Abrir); pero en lugar de abrir solo un archivo, haremos lo propio con la carpeta que contiene todos los documentos que constituyen el corpus. AntConc permite abrir directorios completos; en consecuencia, si ya tienes conocimiento y te sientes cómodo trabajando de esta manera, puedes abrir la carpeta “All reviews” (“Todas las reseñas”) y pasar directamente a la sección de análisis de este tutorial 4.
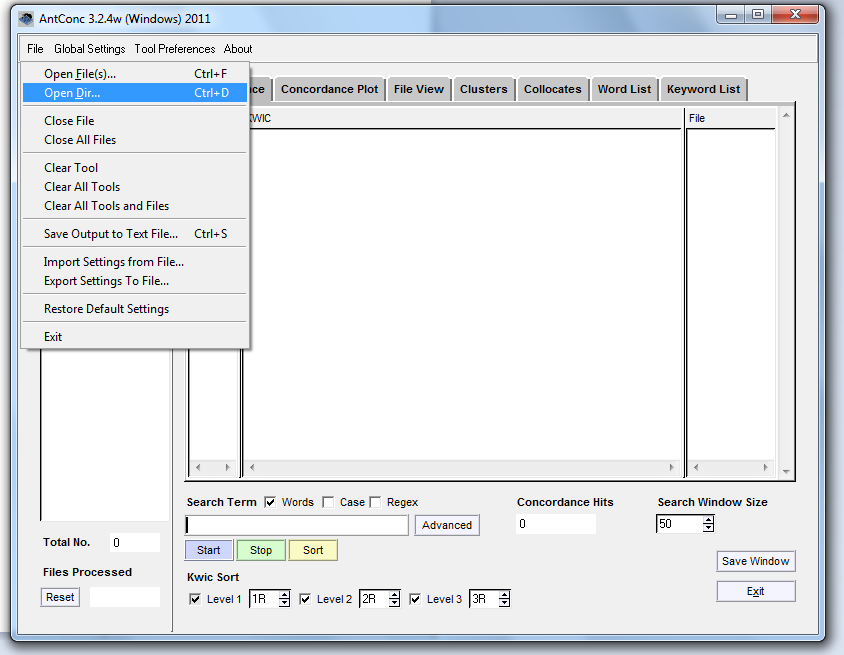
Apertura de una carpeta.
-
Recuerda que guardamos los archivos en el escritorio; dirígete entonces a esa ubicación en el menú desplegable.
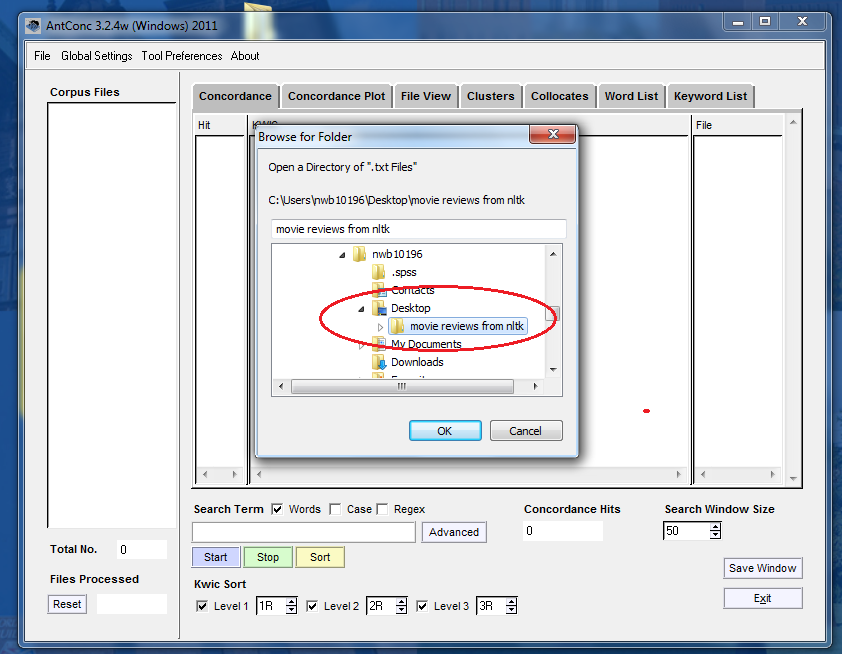
Apertura de una carpeta localizada en el escritorio.
-
Una vez en el escritorio, elige la carpeta “movie reviews from ntlk” (“reseñas cienmatográficas del ntlk”):
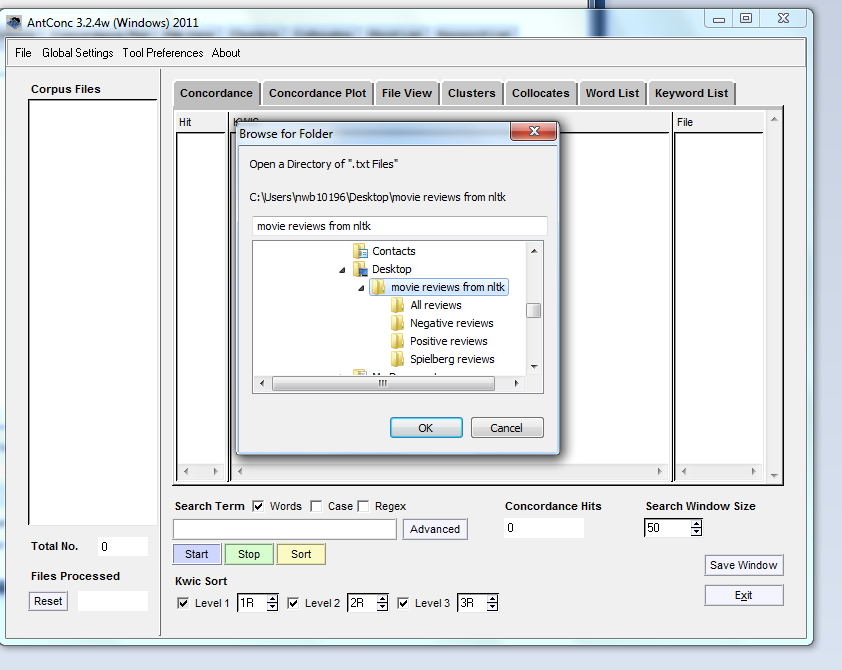
Localización de la carpeta movie reviews from nltk
-
Ahora, selecciona la carpeta “Negative reviews” (“Reseñas negativas”) y haz clic en “OK”. Hecho esto, deberían cargarse 200 archivos de texto en la columna izquierda del programa —confírmalo mediante la casilla “Total No.”—.
Carga de la carpeta Negative Reviews.
-
Repite el mismo proceso para cargar la carpeta “Positive Reviews” (“Reseñas positivas”). Con esto, deberías tener 400 textos en la columna “Corpus Files”.
Carga de la carpeta Positive Reviews.
Conjunto completo de reseñas cargadas en el programa.
Búsqueda de palabras clave en contexto
Comenzar con una búsqueda básica
Una de las labores en las cuales se destacan las herramientas de análisis de corpus como AntConc radica en encontrar patrones en el uso de la lengua que nos resulta difícil identificar como lectores. Nos es complicado rastrear palabras pequeñas y en apariencia poco importantes, tales como ‘yo’, ‘él’, ‘ella’, ‘un’ y ‘es’ porque son muy comunes, pero los computadores son muy buenos para realizar esta labor. Estos términos, que en lingüística reciben el nombre de palabras funcionales —se conocen como palabras vacías (stopwords) en el ámbito de las humanidades digitales—, suelen constituir indicadores estilísticos muy claros en materias de autoría y género en los textos. En consecuencia, tales palabras pueden ser términos de búsqueda bastante potentes por sí solos, o bien combinados con términos que se relacionen en mayor medida con el contenido (content-driven terms), lo cual ayuda al investigador a identificar patrones que tal vez no haya detectado previamente.
En la pestaña Concordance, escribe la palabra ‘the’ en el cuadro de búsqueda ubicado en la parte inferior y haz clic en “Start”. Acto seguido, el programa mostrará cada una de las apariciones de dicho término en el corpus de reseñas cinematográficas, así como el contexto en el que estas se presentan. Esto recibe el nombre de “visor de palabras clave en contexto” (keywords in context viewer).
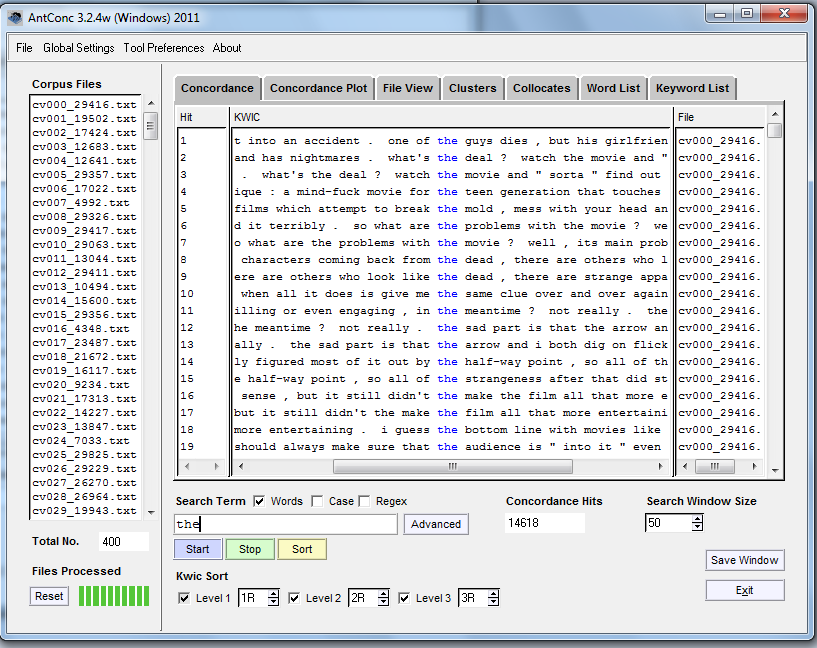
The es una palabra común en la lengua inglesa.
La palabra buscada aparece 14.618 veces en el corpus según la casilla Concordance Hits, que se encuentra en la parte inferior de la pestaña.
Como se indicó anteriormente, la lista KWIC resulta una buena forma de comenzar a buscar patrones. Aunque la cantidad de información suministrada con la búsqueda es aún muy grande, ¿qué tipo de palabras aparecen cerca de ‘the’?
Ahora, prueba a hacer una búsqueda del término ‘a’; tanto este último como ‘the’ son artículos en la lengua inglesa, pero el primero es definido y el segundo indefinido; y los resultados arrojados por la búsqueda ilustrarán esa diferencia.
Llegados a este punto, ya debes estar familiarizado con las líneas de texto que componen la vista KWIC. Ahora, realiza una nueva búsqueda, esta vez de la palabra ‘shot’: los resultados mostrarán las apariciones del término tanto en la función sintáctica de sustantivo (por ejemplo, “line up the shot”) como en la de verbo conjugado (por ejemplo, “this scene was shot carefully”).
¿Qué ves? Entendemos que esta puede ser una forma de identificar patrones difícil de intepretar. Intenta presionar el botón amarillo “Sort” (clasificar): ¿qué sucede al hacerlo?
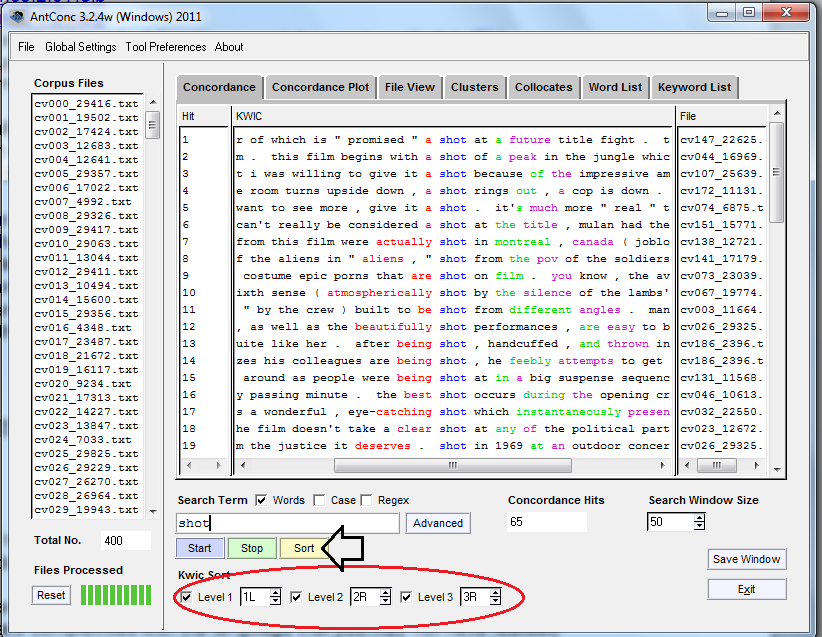
Palabras que aparecen junto a shot.
Puedes ajustar la forma en que AntConc ordena la información encontrada si cambias los parámetros que en la imagen anterior aparecen encerrados en el círculo de color rojo: L corresponde a izquierda (left) y R a derecha (right); lo anterior puede extenderse hasta 5 posiciones en cualquier dirección. Los valores por defecto de la aplicación son 1 izquierda (1L), 2 derecha (2R), 3 derecha (3R); pero puedes alterarlos, por ejemplo, a 3 izquierda (3L), 2 izquierda (2L), 1 derecha (1R) (en aras de obtener frases o trigramas que finalicen con el término buscado) si haces clic en las flechas hacia arriba y abajo que se encuentran junto a los parámetros. Si no deseas realizar este tipo de clasificación, puedes omitirla (dejar los valores predeterminados 1L, 2R y 3R) o dejar todos los parámetros con el valor 0. Cabe la posibilidad de generar clasificaciones menos lineales, como 4L, 3R, 5R, que arrojarían como resultado mucha más información del contexto. El programa puede tardar un poco en mostrar este tipo de clasificaciones, por lo que sugerimos tener paciencia al efectuarlas. Si no estás seguro de cuáles serán los resultados arrojados por la búsqueda, haz clic en “Sort” para ver qué ocurre y efectúa los ajustes a los que haya lugar según tus necesidades.
Operadores de búsqueda
Operador * (comodín)
El operador * (que sirve para buscar 0 o más caracteres) puede ayudar a encontrar las formas de sustantivos en singular y plural, por ejemplo.
Tarea: busca qualit* y ordena los resultados. ¿Qué tiende a preceder y seguir a las palabras ‘quality’ y ‘qualities’? Una pista: son vocablos diferentes con contextos de uso distintos; identifica patrones de uso mediante la búsqueda KWIC.
Para obtener una lista completa de los operadores comodín disponibles y su función, revisa “Global Settings” – “Wildcard Settings”.
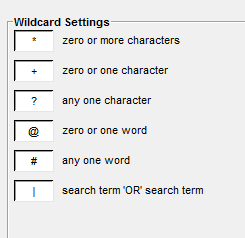
Configuración de operadores de búsqueda.
Para conocer la diferencia entre los operadores * y ?, busca th*n y luego th?n. Estas dos búsquedas, que a simple vista parecieran muy similares, arrojan resultados distintos.
El operador ? es más específico que *, así:
wom?n – ‘women’ y ‘woman’.
m?n – ‘man’, ‘men’ y ‘min’.
Una búsqueda de m*n, en cambio, no es útil porque se obtendrán resultados que incluirán ‘mean’, ‘melon’, etc.
Tarea: compara los resultados de las búsquedas de wom?n y m?n.
-
Ordena los resultados de cada búsqueda de manera que arrojen datos significativos (por ejemplo, configurar los parámetros de la búsqueda en 0, 1L y 2L)
-
Haz clic en “File” – “Save Output to Text File” y guarda el archivo (no olvides agregar la extensión .txt al nombre del mismo).
Sugerencia: durante la exploración en tu investigación, generarás muchos documentos como este para efectos de consulta. Es conveniente, por tanto, nombrar los archivos de tal manera que se describa lo que estos contienen (por ejemplo, “wom?n-results.txt” en lugar de “antconc-results.txt”).
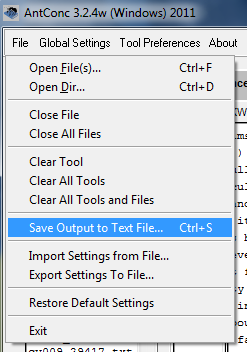
Opción Save output as text file.
Cuadro de diálogo Save As.
Con lo anterior, puedes abrir el archivo de texto plano generado por el programa en un editor de texto; es posible que debas ampliar la ventana de la aplicación para que este sea legible.
Archivo de resultados de búsqueda KWIC exportado por Antconc, tal como se muestra en un editor de texto.
Realiza el proceso anterior con los resultados de las dos búsquedas y compara los archivos de texto generados. ¿Qué fenómenos puedes ver?
Operador | (“o”)
Tarea: busca she|he.
Ahora, busca las dos palabras anteriores por separado: ¿cuántas veces aparece ‘she’ en comparación con ‘he’?
La palabra ‘she’ (ella) aparece en mucha menor cantidad que ‘he’ (él). ¿Por qué? ¡Esa es una pregunta de investigación! Una buena manera de ampliar este cuestionamiento podría radicar en ordenar la búsqueda anterior para identificar patrones de uso de las palabras en cuestión, y revisar si las mismas están seguidas de algún verbo en particular.
Tarea: a modo de práctica, busca una palabra que te interese, ordena los resultados de formas diferentes, usa los operadores comodín y exporta los datos obtenidos como archivos de texto plano. He aquí un interrogante orientador: ¿qué tipo de patrones puedes observar? ¿Puedes explicarlos?
Colocaciones y listas de palabras
Después de haber analizado las líneas de resultados de la vista KWIC en busca de patrones, ¿no te gustaría que hubiera una forma de que el computador te brindara una lista de palabras que aparecen más frecuentemente con la palabra clave buscada?
Buenas noticias: existe una manera de obtener esta información en AntConc; está disponible en la pestaña Collocates (colocaciones). Al hacer clic en la misma, aparecerá un mensaje por medio del cual la aplicación dirá que necesita crear una lista de palabras. Haz clic en “OK” y el programa lo hará automáticamente.
Nota: solo recibirás este aviso cuando no hayas creado una lista de palabras.
Mensaje de advertencia para indicar la necesidad de generar una lista de palabras.
Ahora, intenta generar la lista de colocaciones para el término ‘she’.
Los resultados sin clasificar parecerán comenzar con palabras funcionales (palabras con las que se construyen frases) y luego pasarán a palabras de contenido (términos que dan sentido al texto): las primeras son las más frecuentes en inglés, en tanto funcionan mayormente como elementos para construir frases. Versiones más recientes de AntConc suelen incluir el término buscado como primer resultado, posiblemente porque está presente en el texto y se quiere hallar palabras que puedan aparecer junto a él.
Algunas personas podrían tener la intención de prescindir de esta clase de palabras mediante el uso de una lista de palabras funcionales (esta es una labor común cuando se hace modelado de tópicos). Desde nuestra óptica, no promovemos esta práctica porque los computadores se destacan, justamente, en la identificación de palabras con alta frecuencia de aparición; tal como se expresó anteriormente, tendemos a pasarlas por alto. Los computadores —y en especial las aplicaciones como AntConc—, pueden mostrar dónde aparecen o no estas palabras, y esa información puede ser de interés, especialmente en colecciones de texto de gran envergadura (como se vio con las búsquedas de ‘a’, ‘she’ y ‘he’).
No obstante, en el caso de la lengua inglesa, la frecuencia de aparición de la letra ‘s’ en el corpus también puede ser bastante alta, en tanto representa el posesivo ʼs (la aplicación no toma en cuenta el apóstrofo), pero AntConc la toma como otra palabra. Asimismo, la forma ʼt puede aparecer junto al verbo ‘do’ por cuanto conforman la contracción donʼt; la alta frecuencia de su aparición conjunta los convierte en colocaciones altamente probables.
Tarea: genera la lista de colocaciones para las búsquedas de m?n y wom?n. Ahora, ordénalas de acuerdo con su frecuencia de aparición respecto del parámetro 1L. Los resultados muestran lo que, en teoría, hace que un hombre (man) o una mujer (woman) sea “digno de mostrarse en el cine”:
- las mujeres deben ser “bellas” (beautiful), “sofisticadas” (sophisticated) o estar “embarazadas” (pregnant).
- Los hombres tienen que estar, en cierto modo, fuera de lo común: deben ser “santos” (holy), “negros” (black) o “viejos” (old).
Lo anterior no alude directamente a las películas, sino a la forma como se escribe sobre ellas en las reseñas, y puede llevar a cuestionamientos más sutiles, tales como “¿de qué manera se describen los roles de las mujeres en las comedias románticas en las reseñas escritas por hombres frente a las escritas por mujeres?”
Comparación de corpus
Uno de los tipos de análisis más potentes radica en comparar el corpus propio con uno de referencia más extenso.
Para este ejercicio, hemos tomado reseñas de filmes en los que Steven Spielberg ha estado involucrado (como director o productor). Podemos compararlos con un corpus de referencia de películas de toda una gama de directores.
Asegúrate de pensar cuidadosamente sobre las características que podría tener un corpus de referencia para tu propia investigación (por ejemplo, un estudio del lenguaje de Agatha Christie en sus últimos años funcionaría muy bien como un corpus de análisis para compararlo con un corpus de referencia de todas sus novelas). Recuerda que, como lo expresamos anteriormente, la construcción del corpus es un subcampo en sí mismo.
- Dirígete a “Settings” – “Tool preferences” – “Keyword List”.
- Asegúrate de que la casilla de verificación “Use raw files” esté seleccionada en el menú “Reference Corpus”.
- Haz clic en el botón “Add Directory” y selecciona la carpeta que contiene los archivos del corpus de referencia.
-
Verifica que dispongas de la lista completa de archivos en el listado que se mostrará.
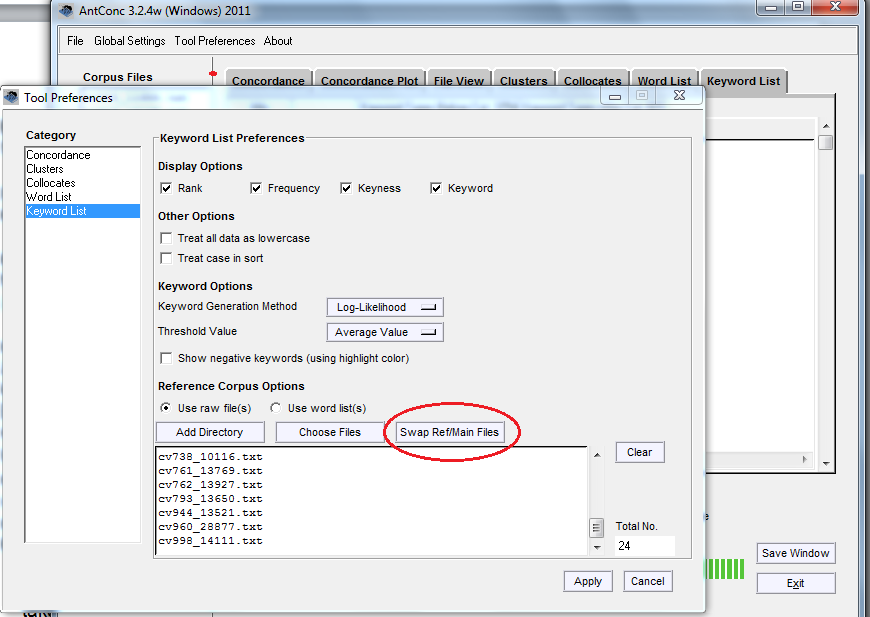
Carga de un corpus de referencia.
- Haz clic en el botón “Load” y espera que el programa cargue los archivos; una vez la casilla de verificación “Loaded” esté marcada, haz clic en “Apply”.
Existe la posibilidad de intercambiar los roles del corpus de referencia y los archivos principales (es decir, dar al primero la función de los segundos y viceversa) por medio del botón “Swap Ref/Main Files”; en este punto vale la pena experimentar con esta opción y comparar los resultados obtenidos.
Si estás utilizando una versión más reciente del programa, el botón anterior puede llamarse “Swap with Target Files”. Adicionalmente, cualesquiera sean los datos que vayas a utilizar como corpus de referencia, asegúrate de que estos se carguen correctamente en AntConc (esto es, haz clic en el botón “Load” cada vez que cargues o intercambies un corpus).
- Dirígete a la pestaña “Keyword list” y una vez allí, presiona el botón “Start” (sin escribir nada en la casilla de búsqueda). Si intercambiaste el corpus de referencia con los archivos objeto del análisis, el programa anunciará la necesidad de crear una nueva lista de palabras antes de generar la lista de palabras clave. Esta se compondrá de aquellos términos que resulten mucho más “inusuales” —de aparición menos probable en terminos estadísticos— en el corpus que se está viendo vs. el de referencia.
Keyness (calidad de la palabra clave): corresponde a la frecuencia de aparición de una palabra en el texto cuando se la compara con su frecuencia en un corpus de referencia, “de tal suerte que la probabilidad estadística, calculada mediante un procedimiento determinado, es menor o igual que el valor p especificado por el usuario” (información tomada de este sitio). Para profundizar sobre los detalles estadísticos de este tópico, sugerimos revisar la sección sobre el mismo en la página 7 del archivo Readme de AntConc.
¿Cuáles son nuestras palabras clave?
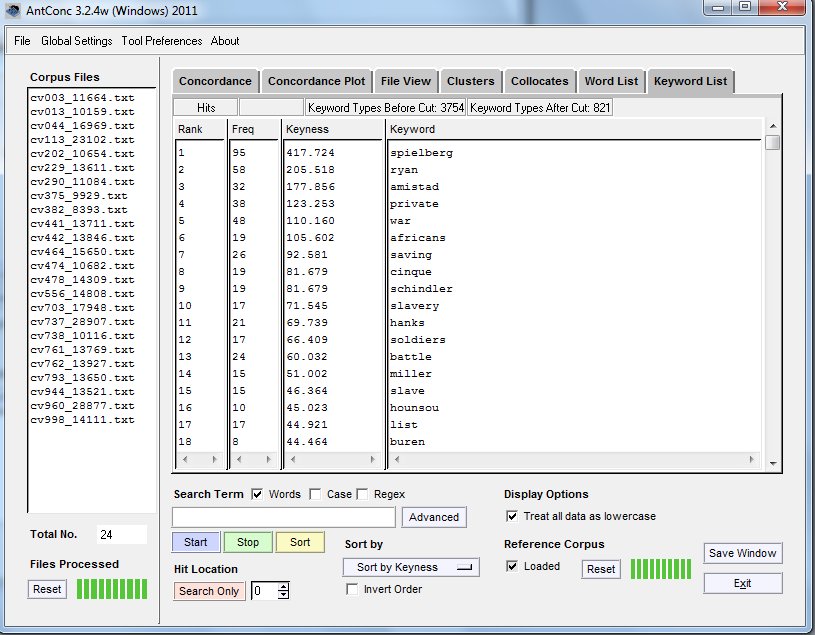
Spielberg vs. reseñas cinematográficas.
Discusión: hacer comparaciones significativas
Es importante tener en cuenta que la forma en que se organicen los archivos de texto para la investigación tendrá efectos en el tipo de interrogantes que puedan surgir de los mismos, así como en los resultados que se obtengan del análisis. A este respecto, recuerda que la comparación realizada aquí entre reseñas negativas y positivas es extremadamente simple; si se quisiere, podrían efectuarse comparaciones adicionales con otros subconjuntos de reseñas, lo cual daría pie a la formulación de interrogantes muy distintos.
Así entonces, los archivos que se dispongan en el corpus determinarán los resultados obtenidos. Reiteramos que los temas de representatividad y muestreo son muy relevantes en este sentido: no siempre es necesario o ideal utilizar todo un conjunto de datos, incluso si se dispone de él. En este punto, realmente cabe preguntarse por la manera como estos métodos de análisis textual ayudan a generar preguntas de investigación.
Si se piensa, por ejemplo, en el funcionamiento de las reseñas cinematográficas en tanto género discursivo, puede dirigirse la atención hacia oposiciones como las siguientes:
- Reseñas cinematográficas vs. reseñas musicales
- Reseñas cinematográficas vs. reseñas de libros
- Reseñas cinematográficas vs. noticias deportivas
- Reseñas cinematográficas vs. noticias en general
Cada una de estas comparaciones aportará información distinta y puede derivar en preguntas de investigación diferentes, tales como:
-
¿En qué difieren las reseñas cinematográficas de otros tipos de reseñas de productos mediáticos?
- ¿En qué se diferencian las reseñas cinematográficas de otros tipos de escritos susceptibles de publicarse?
- ¿Cómo se comparan las reseñas de películas con otros géneros de escritura, tales como la crónica deportiva?
- ¿Qué tienen en común las reseñas cinematográficas y las musicales?
Desde luego, puede darse la vuelta a estos cuestionamientos para generar nuevas preguntas:
-
¿En qué se diferencian las reseñas bibliográficas de las cinematográficas?
- ¿En qué difieren las reseñas musicales de las cinematográficas?
- ¿Qué tienen en común los artículos que se publican en la prensa escrita?
- ¿En qué se asemejan las reseñas cinematográficas a otros tipos de escritos susceptibles de publicarse?
En síntesis, vale la pena pensar en:
- Por qué se quiere comparar dos corpus.
- Qué tipo de consultas da lugar a preguntas de investigación significativas.
- Principios de construcción de corpus: muestreo y capacidad de asegurar que se obtengan datos representativos.
Recursos adicionales
A Short Bibliography on Corpus Linguistics
Una versión más sencilla de este tutorial, concebida para usuarios con pocos conocimientos de computación (en inglés).
Guía rápida de análisis de corpus con AntConc, publicada por la Universidad de Alicante (2015).
Notas de traducción
-
Investigador y docente de la Universidad de Waseda (Japón). ↩
-
La interfaz del programa solo está disponible en inglés. ↩
-
Dos materiales en español pueden ser de utilidad si se desea profundizar en esta témática: de un lado, la conferencia Aproximación al concepto de representatividad de corpus; y de otro, la obra Explotación de los córpora textuales informatizados para la creación de bases de datos terminológicas basadas en el conocimiento. ↩
-
Si se requiere trabajar con corpus en cuyos textos se emplean caracteres especiales (como es el caso de los documentos escritos en lengua española), es imperativo prestar atención a la codificación con la cual se guardaron los archivos que los componen. Por defecto, AntConc está configurado para operar con documentos de texto plano con codificación Unicode (UTF-8). Así entonces, es preciso verificar en el editor de texto que estos se hayan guardado atendiendo a lo anterior, o bien cambiar los parámetros de importación de archivos en el programa según las necesidades (por ejemplo, trabajar con archivos codificados en ANSI). ↩