
Conteúdos
- Introdução e Âmbito da lição
- Dados abertos conectados: O que são?
- O papel do Uniform Resource Identifier (URI)
- Como o LOD organiza o conhecimento: ontologias
- RDF e formatos de dados
- Consulta de RDF com SPARQL
- Leituras e recursos adicionais
- Agradecimentos
Nota de Tradução: Alguns termos, por aparecerem constantemente e facilitarem a interpretação das imagens, apenas foram propositadamente traduzidos uma vez e serão colocados entre parênteses. Alertamos também para a existência de alguns exemplos que não foram propositadamente traduzidos para facilitar a sua introdução nos programas apresentados.
Introdução e Âmbito da lição
Esta lição oferece uma breve e concisa introdução aos dados abertos conectados (Linked Open Data ou LOD). Não é necessário conhecimento prévio para realizar este tutorial. Os leitores deverão obter uma compreensão clara dos conceitos por detrás dos dados abertos conectados, como são utilizados e como são criados. O tutorial está dividido em cinco partes, além de leituras adicionais:
- Dados abertos conectados: o que são?
- O papel do Identificador Uniforme de Recurso (Uniform Resource Identifier ou URI)
- Como o LOD organiza o conhecimento: ontologias
- A Estrutura de Descrição de Recursos (Resource Description Framework ou RDF) e formatos de dados
- Consulta de dados abertos conectados com SPARQL
- Outras leituras e recursos
A conclusão deste tutorial poderá levar algumas horas e poderá ser útil reler algumas secções para solidificar a sua compreensão. Os termos técnicos foram ligados à sua página correspondente na Wikipedia e encoraja-se a que faça uma pausa e leia sobre termos que considere desafiadores. Depois de ter aprendido alguns dos princípios-chave do LOD, a melhor maneira de melhorar e solidificar esse conhecimento é praticar. Este tutorial fornece oportunidades para fazê-lo. No final da lição, deverá compreender os princípios básicos de LOD, incluindo termos e conceitos-chave.
Se precisar aprender a como explorar LOD usando a linguagem de consulta SPARQL, recomenda-se a lição de Matthew Lincoln ‘Using SPARQL to access Linked Open Data’ (em inglês) (Nota: a lição deste link encontra-se desatualizada e já não é mantida pelo Programming Historian. Por favor veja a nota inicial dessa página sobre a razão dessa lição ter sido retirada), que segue praticamente a visão geral fornecida nesta lição.
Para proporcionar aos leitores uma base sólida dos princípios básicos de LOD, este tutorial não oferecerá uma cobertura abrangente de todos os seus conceitos. Estes não serão o foco desta lição:
- Web Semântica e raciocínio semântico (em inglês) de datasets. Um raciocinador semântico deduziria que Jorge VI é o irmão ou meio-irmão de Eduardo VIII, dado que: a) Eduardo VIII é o filho de Jorge V e b) Jorge VI é o filho de Jorge V. Este tutorial não se foca neste tipo de tarefa.
- Criação e upload de conjuntos de dados abertos conectados ligados à Nuvem de dados conectados (em inglês). Partilhar LOD é um princípio importante, que é encorajado abaixo. Contudo, os aspetos práticos de contribuir com LOD para a nuvem de dados conectados estão além do âmbito desta lição. Alguns recursos que podem ajudar a começar esta tarefa estão disponíveis no final deste tutorial.
Dados abertos conectados: O que são?
LOD é informação estruturada num formato destinado a máquinas e, por isso, não é necessariamente um conceito de fácil definição. É importante não perder a motivação com esta informação já que, ao compreender os princípios, pode colocar uma máquina a fazer uma leitura autónoma.
Se todos os datasets fossem publicados abertamente e utilizassem o mesmo formato para estruturar a informação, seria possível interrogá-los todos de uma só vez. A análise de grandes volumes de dados é potencialmente muito mais poderosa do que qualquer pessoa que utilize os seus próprios datasets individuais espalhados pela web nos chamados silos de informação (em inglês). Estes datasets interoperáveis são aquilo para que os profissionais de LOD estão a trabalhar.
Para atingir este objetivo, ao trabalhar com LOD, é importante recordar três princípios:
- Utilizar um formato padrão de LOD reconhecido. Para que o LOD funcione, os dados devem ser estruturados, utilizando normas reconhecidas para que os computadores que interrogam os dados possam processá-los de forma consistente. Há vários formatos de LOD, alguns dos quais são discutidos abaixo.
- Referir uma entidade da mesma forma que outras pessoas o fazem. Se existirem dados sobre a mesma pessoa/local/coisa em dois ou mais locais, certifique-se de que se refere à pessoa/local/coisa da mesma forma em todos os casos.
- Publicar os seus dados abertamente. Qualquer pessoa deverá poder utilizar os seus dados sem pagar uma taxa e num formato que não exija software proprietário.
Comecemos com um exemplo de dados sobre uma pessoa, utilizando uma abordagem comum par atributo-valor (em inglês) típica em computação:
pessoa=número
Neste caso, o ‘atributo’ é uma pessoa. E o valor - ou quem é essa pessoa - é representado por um número. O número pode ser atribuído aleatoriamente ou pode ser utilizado um número que já esteja associado a essa pessoa. Esta última abordagem tem grandes vantagens: se todos os que criarem um dataset que menciona essa pessoa utilizarem exatamente o mesmo número, exatamente no mesmo formato, então podemos encontrar esse indivíduo de forma fiável em qualquer dataset aderindo a essas regras. Vamos criar um exemplo usando Jack Straw: tanto o nome de um rebelde inglês do século XIV, como o de um ministro de gabinete britânico proeminente na administração de Tony Blair. É útil ser capaz de diferenciar as duas pessoas que partilham o mesmo nome.
Utilizando o modelo acima, no qual cada pessoa é representada por um número único, vamos atribuir ao ministro britânico Jack Straw o número 64183282. O seu par atributo-valor ficaria então com este aspeto:
pessoa=64183282
E vamos atribuir a Jack Straw, descrito no Oxford Dictionary of National Biography (em inglês) como ‘o enigmático líder rebelde’, o número 33059614, fazendo com que o seu par atributo-valor se pareça com isto:
pessoa=33059614
Desde que todos os que fazem LOD utilizem estes dois números para se referirem aos respetivos Jack Straws, podemos agora procurar a pessoa 64183282 num conjunto de dados abertos conectados e podemos estar confiantes de que estamos a obter a pessoa certa - neste caso, o ministro.
Os pares atributo-valor também podem armazenar informações sobre outros tipos de entidades: lugares, por exemplo. Jack Straw, o político moderno, era membro do Parlamento britânico, representando o assento de Blackburn. Há mais do que um lugar no Reino Unido chamado Blackburn, para não mencionar outros Blackburn em todo o mundo. Usando os mesmos princípios acima delineados, podemos desambiguar entre os vários Blackburns, atribuindo um identificador único ao lugar correto: Blackburn em Lancashire, Inglaterra.
Lugar=2655524
Neste momento pode estar pensando, “isso é o que um catálogo de biblioteca faz”. É verdade que a ideia-chave aqui é a do ficheiro de autoridade, central na biblioteconomia (um ficheiro de autoridade é uma lista definitiva de termos que podem ser utilizados num contexto particular, por exemplo, quando se cataloga um livro). Nos dois exemplos acima descritos, utilizamos ficheiros de autoridade para atribuir números (os identificadores únicos) aos Jacks e ao Blackburn. Os números que utilizamos para os dois Jack Straws provêm do Virtual International Authority File (em inglês) (VIAF) (Arquivo Internacional de Autoridade Virtual), que é mantido por um consórcio de bibliotecas de todo o mundo, de modo a tentar resolver o problema da miríade de maneiras pelas quais a mesma pessoa pode ser referida. O identificador único que utilizamos para o distrito eleitoral de Blackburn provém da GeoNames (em inglês), uma base de dados geográfica gratuita.
Vamos tentar ser mais precisos com o que, neste caso, queremos dizer com ‘Blackburn’. Jack Straw representou o círculo eleitoral (uma área representada por um único membro do parlamento) de Blackburn, que mudou os seus limites ao longo do tempo. O projeto “Digging Into Linked Parliamentary Data” (Dilipad) (em inglês), no qual trabalhei, produziu identificadores únicos para as filiações partidárias e circunscrições eleitorais para cada membro do parlamento. Neste exemplo, Jack Straw representou o distrito eleitoral conhecido como ‘Blackburn’ na sua encarnação pós-1955:
blackburn1955-presente
Como o VIAF é um ficheiro de autoridade respeitado e bem mantido, fornece um conjunto óbvio de identificadores a utilizar para Jack Straw. Como o distrito eleitoral representado por Straw estava perfeitamente coberto pelos ficheiros de autoridade criados pelo projeto Dilipad, também era um ficheiro de autoridade lógico a utilizar. Infelizmente, nem sempre é tão óbvio qual das listas publicadas online é a melhor para se usar. Uma pode ser mais utilizada do que outra, mas esta última pode ser mais abrangente para um determinado fim. O GeoNames funcionaria melhor do que os identificadores da Dilipad em alguns casos. Haverá também casos em que não se consegue encontrar um dataset com essa informação. Por exemplo, se quiser escrever pares atributo-valor sobre si próprio e as suas relações familiares imediatas terá de inventar os seus próprios identificadores.
Esta falta de ficheiros de autoridade coerentes é um dos maiores desafios que o LOD enfrenta neste momento. Tim Berners-Lee, que inventou uma forma de ligar documentos em rede e criou assim a World Wide Web, um dos principais proponentes de LOD, para encorajar uma maior utilização de dados conectados, sugeriu um “sistema de classificação de cinco estrelas” (em inglês) para que todos avançassem o mais longe possível em direção ao LOD. Essencialmente, Tim Berners-Lee apoia a publicação aberta de dados, especialmente ao utilizar formatos abertos e normas públicas, mas o melhor é que os dados se liguem também aos dados de outras pessoas.
Com os identificadores únicos atribuídos a todos os elementos, o próximo passo fundamental na criação de LOD é ter uma forma de descrição da relação entre Jack Straw (64183282) e Blackburn (blackburn1955-presente). Em LOD, as relações são expressas utilizando o que é conhecido como ‘tripla semântica’ (em inglês). Vamos fazer uma tripla semântica que represente a relação entre Jack Straw e o seu distrito eleitoral:
pessoa:64183282 papel:representaNoParlamentoBritânicodistritoeleitoral:"blackburn1955-presente" .
A apresentação (ou sintaxe) das triplas semânticas, incluindo a pontuação utilizada acima, será discutida mais tarde, na secção sobre RDF e formatos de dados. Por agora, vamos focar-nos na estrutura básica. A tripla semântica, não surpreendentemente, tem três partes. Estas são convencionalmente referidas como sujeito (subject), predicado (predicate) e objeto (object):
| o sujeito | o predicado | o objeto |
|---|---|---|
| pessoa 64183282 | representadaNoParlamentoBritânico | “blackburn1955-presente” |
A forma tradicional de representar uma tripla semântica em forma esquemática é a seguinte (em inglês):

Figura 1. Forma tradicional de representar uma tripla semântica.
Assim, a nossa tripla semântica do Jack Straw, apresentado de forma mais legível para o ser humano, poderia assumir a seguinte forma:

Figura 2. Diagrama da tripla semântica que demonstra que Jack Straw representava Blackburn.
Por enquanto, é importante fixar três pontos-chave:
- O LOD deve estar aberto e disponível para qualquer pessoa na Internet (caso contrário, não está “aberto”)
- Os defensores do LOD têm como objetivo normalizar as formas de referência a entidades únicas
- O LOD consiste em triplas semânticas que descrevem as relações entre entidades
O papel do Uniform Resource Identifier (URI)
Uma parte essencial de LOD é o Identificador Uniforme de Recurso(Uniform Resource Identifier ou URI). O URI é uma forma única e fiável de representar uma entidade (uma pessoa, um objeto, uma relação, etc.), de uma forma que é utilizável por todos no mundo.
Na secção anterior, utilizamos dois números diferentes para identificar os diferentes Jack Straws.
pessoa="64183282"
pessoa="33059614"
O problema é que em todo o mundo existem muitas bases de dados que contêm pessoas com estes números e são, provavelmente, todas pessoas diferentes. Fora do nosso contexto imediato, estes números não identificam indivíduos únicos. Vamos tentar resolver isso. Aqui estão estes mesmos identificadores, mas como URIs:
http://viaf.org/viaf/64183282/
http://viaf.org/viaf/33059614/
Tal como o número único desambiguou os nossos dois Jack Straws, o URI completo acima ajuda-nos a desambiguar entre todos os diferentes ficheiros de autoridade lá fora. Neste caso, é evidente que estamos a utilizar o VIAF como o nosso ficheiro de autoridade. Com certeza, já viu esta forma de desambiguação muitas vezes na web. Existem muitos websites em todo o mundo com páginas chamadas /home ou /faq. Mas não há confusão porque o domínio (a primeira parte do Localizador Uniforme de Recursos (Uniform Resource Locator ou URL) - ex. bbc.co.uk) é único, portanto, todas as páginas que fazem parte desse domínio são únicas em outras páginas /faq de outros websites. No endereço http://www.bbc.co.uk/faqs é a parte bbc.co.uk que torna as páginas subsequentes únicas. Isto é tão óbvio para as pessoas que utilizam a web a toda a hora que não pensam sobre isso. Provavelmente, também sabe que se quiser criar um website chamado bbc.co.uk não conseguirá, porque esse nome já foi registado com a autoridade apropriada, que é o Sistema de Nomes de Domínio (Domain Name System). O registo garante a singularidade. Os URIs também têm de ser únicos.
Embora os exemplos acima se pareçam com URLs, também é possível construir um URI que não se pareça nada com um URL. Temos muitas formas de identificar pessoas e coisas de forma única e raramente pensamos ou nos preocupamos com isso. Os códigos de barras, números de passaporte, até mesmo os códigos postais são concebidos para serem únicos. Os números de telefone são frequentemente colocados como placas de loja precisamente porque são únicos. Todos eles podem ser utilizados como URIs.
Quando criamos URIs para as entidades descritas pelo projeto ‘Tobias’ (em inglês), escolhemos uma estrutura do tipo URL e escolhemos utilizar o nosso espaço web institucional, pondo de lado data.history.ac.uk/tobias-project/ como um lugar dedicado à hospedagem destes URIs. Ao colocá-lo em data.history.ac.uk em vez de history.ac.uk, houve uma separação clara entre URIs e as páginas do website. Por exemplo, um dos URIs do projeto Tobias era ‘http://data.history.ac.uk/tobias-project/person/15601’. Embora o formato dos URIs acima mencionados seja o mesmo que um URL, eles não se ligam a websites (tente colá-lo num navegador web). Muitas pessoas novas no LOD acham isto confuso. Todos os URLs são URIs, mas nem todos os URIs são URLs. (nota de tradução: tendo em conta que o site original do projeto Tobias já não se encontra disponível, o leitor da lição deve entender os exemplos aqui indicados como meramente ilustrativos daquilo que o autor pretende demonstrar) Um URI pode descrever qualquer coisa, enquanto o URL descreve a localização de algo na web. Assim, um URL diz-lhe a localização de uma página web, de um ficheiro ou algo semelhante. Um URI faz apenas o trabalho de identificar algo. Tal como o Número internacional Normalizado do Livro (International Standard Book Number ou ISBN (em inglês) 978-0-1-873354-6 identifica exclusivamente uma edição de capa dura de Baptism, Brotherhood and Belief in Reformation Germany, de Kat Hill, mas não diz onde obter uma cópia. Para isso precisaria de algo como um número de acesso, que lhe dá uma localização exata de um livro numa prateleira de uma biblioteca específica.
Há um pouco de jargão em torno de URIs. As pessoas falam sobre se são ou não desreferenciáveis. Isso apenas significa que podemos transformar uma referência abstrata em algo diferente? Por exemplo, se colarmos um URI na barra de endereços de um browser, será que ele encontra algo? O VIAF URI para o historiador Simon Schama é:
http://viaf.org/viaf/46784579
Se o colocarmos no browser, receberemos de volta uma página web sobre Simon Schama que contém dados estruturados sobre ele e a sua história editorial. Isto é muito útil por um motivo. A partir do URI não é óbvio quem ou mesmo o que é que está a ser referido. Da mesma forma, se tratarmos um número de telefone (com código internacional) como o URI de uma pessoa, então deve ser desreferenciável. Alguém pode atender o telefone e pode até ser Schama.
Mas isto não é essencial. Muitos URIs não são desreferenciáveis, como no exemplo acima do projeto Tobias. Não se pode encontrá-lo em lado nenhum; é uma convenção.
O exemplo do VIAF leva-nos a outra coisa importante sobre os URIs: não os invente a não ser que tenha de o fazer. As pessoas e organizações têm feito esforços para construir boas listas de URI e o LOD não vai funcionar eficazmente se as pessoas duplicarem esse trabalho criando novos URIs desnecessariamente. Por exemplo, o VIAF tem o apoio de muitas bibliotecas internacionais. Se quiser construir URIs para pessoas, o VIAF é uma escolha muito boa. Se não conseguir encontrar algumas pessoas no VIAF, ou noutras listas de autoridade, só então poderá precisar fazer a sua própria.
Como o LOD organiza o conhecimento: ontologias
Pode não ter sido óbvio a partir das triplas semânticas individuais que analisamos na secção anterior, mas o LOD pode responder a perguntas complexas. Quando se juntam as triplas semânticas, estas formam um Mapa conceitual, devido à forma como as triplas semânticas se interligam. Suponhamos que queremos encontrar uma lista de todas as pessoas que foram alunos do compositor Franz Liszt. Se a informação estiver em triplas semânticas de dados conectados sobre pianistas e os seus professores, podemos descobrir o que procuramos com uma consulta (veremos esta linguagem de consulta, chamada SPARQL, na secção final).
Por exemplo, o pianista Charles Rosen foi aluno do pianista Moriz Rosenthal, que foi aluno de Franz Liszt. Vamos agora expressar isto em duas triplas semânticas (vamos cingir-nos às sequências de caracteres para os nomes em vez dos números de identificação, para tornar os exemplos mais legíveis):
"Franz Liszt" ensinouPianoAo "Moriz Rosenthal" .
"Moriz Rosenthal" ensinouPianoAo "Charles Rosen" .
Poderíamos igualmente ter criado as nossas triplas semânticas desta forma:
"Charles Rosen" aprendeuPianoCom "Moriz Rosenthal" .
"Moriz Rosenthal" aprendeuPianoCom "Franz Liszt" .
Estamos a inventar exemplos simplesmente para fins de ilustração, mas se quiser ligar os seus dados a outros datasets na “nuvem de dados conectados” deve olhar para as convenções que são utilizadas nesses datasets e fazer o mesmo. Na verdade, esta é uma das características mais úteis de LOD porque muito do trabalho já foi feito. As pessoas têm passado muito tempo a desenvolver formas de modelar a informação dentro de uma determinada área de estudo e a pensar sobre como as relações dentro dessa área podem ser representadas. Estes modelos são geralmente conhecidos como ontologias. Uma ontologia é uma abstração que permite a representação de um conhecimento particular sobre o mundo. Neste sentido, estas são bastante recentes e foram concebidas para fazer o que uma taxonomia hierárquica faz (pense na classificação das espécies na Taxonomia de Lineu, mas de uma forma mais flexível.
Uma ontologia é mais flexível porque não é hierárquica. Visa representar a fluidez do mundo real, onde as coisas podem ser relacionadas umas com as outras de formas mais complexas do que quando são representadas por uma estrutura hierárquica em forma de árvore. Em vez disso, uma ontologia é mais parecida com uma teia de aranha.
O que quer que pretenda representar com LOD, sugerimos que encontre um vocabulário existente e que o utilize, em vez de tentar escrever o seu próprio vocabulário. Esta página tem uma lista de alguns dos vocabulários mais populares (em inglês).
Uma vez que o nosso exemplo acima se concentra nos pianistas, seria uma boa ideia encontrar uma ontologia apropriada em vez de criar o nosso próprio sistema. De facto, existe uma ontologia para música (em inglês). Para além de uma especificação bem desenvolvida, esta tem também alguns exemplos úteis da sua utilização. Pode dar uma olhada nas páginas de iniciação (em inglês) para ter uma ideia de como se pode utilizar esta ontologia em particular.
Infelizmente, não conseguimos encontrar nada que descreva a relação entre um professor e um aluno na Ontologia da Música. Mas a ontologia é publicada abertamente, logo podemos utilizá-la para descrever outras características da música e depois criar a nossa própria extensão. Se então publicássemos a nossa extensão abertamente, outros poderiam utilizá-la se assim o desejassem e este ato pode tornar-se num padrão. Embora o projeto Music Ontology (Ontologia Musical) não tenha a relação que precisamos, o projeto Linked Jazz (em inglês) permite o uso de ‘mentorOf’, o que parece funcionar bem no nosso caso. Embora esta não seja uma solução ideal, é uma solução que faz um esforço para utilizar o que já existe por aí.
Agora, se estivéssemos a estudar a história do pianismo, poderíamos querer identificar muitos pianistas que foram ensinados por alunos de Liszt, para estabelecer uma espécie de árvore genealógica e ver se estes ‘netos’ de Liszt têm algo em comum. Poderíamos pesquisar os alunos de Liszt, fazer uma grande lista deles, depois pesquisar cada um dos alunos e tentar fazer listas de quaisquer alunos que eles tivessem. Com LOD poderíamos (novamente, se as triplas semânticas existissem) escrever uma query semelhante a:
Dá-me os nomes de todos os pianistas ensinados por x
onde x aprendeu piano com Liszt
Isto encontraria todas as pessoas do dataset que eram alunos de alunos de Liszt. Não nos entusiasmemos demasiado: esta pergunta não nos dará todos os alunos de todos os alunos de Liszt que já existiram, porque essa informação provavelmente não existe e não existe dentro de nenhum conjunto de triplas semânticas existentes. Lidar com dados do mundo real mostra todo o tipo de omissões e inconsistências, que veremos quando olharmos para o maior conjunto de LOD, a DBpedia, na secção final.
Se tiver utilizado bases de dados relacionais poderá estar a pensar que estas podem desempenhar a mesma função. No nosso caso de Liszt, a informação sobre pianistas acima descrita pode estar organizada numa tabela de base de dados denominada por algo como ‘Alunos’.
| IDaluno | IDprofessor |
|---|---|
| 31 | 17 |
| 35 | 17 |
| 49 | 28 |
| 56 | 28 |
| 72 | 40 |
Se não estiver familiarizado com bases de dados não se preocupe. Mas, provavelmente, ainda pode ver que alguns pianistas nesta tabela tinham o mesmo professor (números 17 e 28). Sem entrar em pormenores, se Liszt estiver nesta tabela de bases de dados, seria bastante fácil extrair os alunos de Liszt, ao utilizar um Join (join).
De facto, as bases de dados relacionais podem oferecer resultados semelhantes ao LOD. A grande diferença é que o LOD pode ir mais longe: pode ligar datasets que foram criados sem intenção explícita de serem ligados entre si. A utilização do Quadro de Descrição de Recursos (Resource Description Framework ou RDF) e URIs permite que isto aconteça.
RDF e formatos de dados
LOD utiliza uma norma, definida pelo Consórcio World Wide Web (em inglês) (World Wide Web Consortium ou W3C), chamada Resource Description Framework ou apenas RDF. As normas são úteis desde que sejam amplamente adotadas - pense no metro ou nos tamanhos de parafuso padrão - mesmo que sejam essencialmente arbitrárias. O RDF tem sido amplamente adotado como a norma LOD.
Ouvirá frequentemente o LOD referido simplesmente como RDF. Atrasamos a conversa sobre o RDF até agora porque é bastante abstrato. RDF é um modelo de dados que descreve como é que os dados são estruturados num nível teórico. Assim, a insistência na utilização de triplas semânticas (em vez de quatro partes, ou duas ou nove, por exemplo) é uma regra no RDF. Mas quando se trata de questões mais práticas, há algumas escolhas quanto à implementação. Assim, o RDF diz-lhe o que tem de fazer, mas não exatamente como o tem de fazer. Estas escolhas dividem-se em duas áreas: como se escrevem as coisas (serialização) e as relações que as suas triplas semânticas descrevem.
Serialização
A Serialização é o termo técnico para “como se escrevem as coisas”. O chinês padrão (mandarim) pode ser escrito em caracteres tradicionais, caracteres simplificados ou romanização Pinyin e a língua em si não muda. Tal como o mandarim, o RDF pode ser escrito de várias formas. Aqui vamos olhar para duas (há outras, mas por uma questão de simplicidade, vamos concentrar-nos nestas):
1) Turtle (em inglês) 2) RDF/XML
Reconhecer a serialização que está a ser utilizada significa que podemos então escolher ferramentas apropriadas concebidas para esse formato. Por exemplo, o RDF pode vir serializado no formato XML. Podemos então utilizar uma ferramenta ou biblioteca de códigos concebida para analisar esse formato em particular, o que é útil se já souber como trabalhar com ele. O reconhecimento do formato também lhe dá as palavras-chave certas para procurar ajuda online. Muitos recursos permitem descarregar as suas bases de dados LOD, podendo escolher qual a serialização que deseja fazer o Download.
Turtle
‘Turtle’ é um jogo de palavras. ‘Tur’ é a abreviatura de ‘terse’ e ‘tle’ - é a abreviatura de ‘triple language’ (linguagem de triplos). Turtle é uma forma agradavelmente simples de escrever triplas semânticas.
O Turtle usa apelidos ou atalhos, conhecidos como prefixos (em inglês), o que nos poupa ter de escrever URIs completos todas as vezes. Voltemos ao URI que criamos na secção anterior:
http://data.history.ac.uk/tobias-project/person/15601
Não queremos escrever isto cada vez que nos referimos a esta pessoa (lembrar-se-á de Jack Straw). Por isso, só temos de enunciar o nosso atalho:
@prefix toby: <http://data.history.ac.uk/tobias-project/person/> .
Então Jack é toby:15601, que substitui o longo URI e é mais fácil à vista. Eu escolhi ‘toby’, mas poderia igualmente escolher qualquer sequência de letras.
Vamos agora passar de Jack Straw para William Shakespeare e utilizar Turtle para descrever algumas coisas sobre as suas obras. Vamos ter de decidir sobre os ficheiros de autoridade a utilizar, um processo que, como mencionado acima, é melhor ser selecionado ao olhar para outros conjuntos de LOD. Aqui usaremos como um dos nossos prefixos Dublin Core, uma norma de metadados de bibliotecas (Número de controle da Biblioteca do Congresso (Library of Congress Control Number) como outro e, o último (VIAF) deverá ser-lhe familiar. Juntos, estes três ficheiros de autoridade fornecem identificadores únicos para todas as entidades que tenciono utilizar neste exemplo:
@prefix lccn: <http://id.loc.gov/authorities/names/> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix viaf: <http://viaf.org/viaf/> .
lccn:n82011242 dc:creator viaf:96994048 .
Note o espaçamento do ponto final após a última linha. Esta é a forma de Turtle indicar o fim. Tecnicamente não é necessário ter o espaço, mas facilita a leitura após uma longa sequência de caracteres.
No exemplo acima, lccn:n82011242 representa Macbeth; dc:creator liga Macbeth ao seu autor; viaf:96994048 representa William Shakespeare.
O Turtle também permite listar triplas semânticas sem se preocupar em repetir cada URI quando acabou de o usar. Acrescentemos a data em que os estudiosos pensam que Macbeth foi escrito, utilizando o par atributo-valor Dublin Core: dc:create 'YYYY':
@prefix lccn: <http://id.loc.gov/authorities/names/> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix viaf: <http://viaf.org/viaf/> .
lccn:n82011242 dc:creator viaf:96994048 ;
dc:created "1606" .
Lembra-se da estrutura da tripla semântica discutida na secção 1? Aí demos este exemplo:
1 pessoa 15601 (o sujeito) 2 representadaNoParlamentoBritânico (o predicado) 3 "Blackburn" (o objeto)
O essencial é que o predicado liga o sujeito e o objeto. Ele descreve a relação entre eles. O sujeito vem primeiro na tripla semântica, mas isso é uma questão de escolha, como discutimos com o exemplo de pessoas que foram ensinadas a tocar piano por Liszt.
Pode-se usar um ponto e vírgula se o sujeito for o mesmo mas o predicado e o objeto forem diferentes, ou uma vírgula se o sujeito e o predicado forem o mesmo e apenas o objeto for diferente.
lccn:no2010025398 dc:creator viaf:96994048 ,
viaf:12323361 .
Aqui estamos a dizer que Shakespeare (96994048) e John Fletcher (12323361) foram ambos os criadores da obra The Two Noble Kinsmen.
Quando analisamos as ontologias anteriormente sugeri que visse a Music Ontology (em inglês). Dê agora uma olhada novamente. Isto ainda é complicado, mas será que agora fazem mais sentido?
Uma das ontologias mais acessíveis é a ‘Friend of a Friend’ (amigo de um amigo) ou FOAF (em inglês). Esta é concebida para descrever pessoas e, talvez por essa razão, é bastante intuitiva. Se, por exemplo, quiser escrever-me para me dizer que este curso é a melhor coisa que já leu, aqui está o meu email expresso como triplas semânticas em FOAF:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
:"Jonathan Blaney" foaf:mbox <mailto:jonathan.blaney@sas.ac.uk> .
RDF/XML
Em contraste com o Turtle, o RDF/XML pode parecer um pouco pesado. Para começar, vamos apenas converter uma tripla semântica da Turtle acima, aquela que refere que Shakespeare foi o criador de The Two Noble Kinsmen:
lccn:no2010025398 dc:creator viaf:96994048 .
Em RDF/XML, com os prefixos declarados dentro do trecho de código de XML, fica:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/terms/">
<rdf:Description rdf:about="http://id.loc.gov/authorities/names/no2010025398">
<dc:creator rdf:resource="http://viaf.org/viaf/96994048"/>
</rdf:Description>
</rdf:RDF>
O formato RDF/XML tem a mesma informação básica que o formato Turtle, mas é escrito de forma muito diferente, baseando-se nos princípios das etiquetas XML encaixadas.
Passemos a um exemplo diferente para mostrar como o RDF/XML combina triplas semânticas e, ao mesmo tempo, introduz o Simple Knowledge Organization System (SKOS) (Sistema Simples de Organização do Conhecimento), que foi concebido para codificar tesauros ou taxonomias.
<skosConcept rdf:about="http://www.ihr-tobias.org/concepts/21250/Abdication">
<skos:prefLabel>Abdication</skos:prefLabel>
</skosConcept>
Aqui estamos a dizer que o conceito SKOS 21250, markdown abdication, tem um rótulo preferido de “abdication”. A forma como funciona é que o elemento sujeito (incluindo a parte da ‘abdication’, que é um valor de atributo em termos de XML) tem o predicado e o objeto encaixados no seu interior. O elemento encaixado é o predicado e o nó folha (em inglês), é o objeto. Este exemplo é retirado de um projeto para publicar um Tesauro de História Britânica e Irlandesa (em inglês).
Tal como com o Turtle, podemos acrescentar mais triplas semânticas. Portanto, vamos declarar que o termo mais restrito na nossa hierarquia de sujeitos, um abaixo de Abdication, vai ser Abdication crisis (1936).
<skosConcept rdf:about="http://www.ihr-tobias.org/concepts/21250/abdication">
<skos:prefLabel>Abdication</skos:prefLabel>
</skosConcept>
<skosConcept rdf:about="http://www.ihr-tobias.org/concepts/21250/abdication">
<skos:narrower rdf:resource="http://www.ihr-tobias.org/concepts/19838/abdication_crisis_1936"/>
</skosConcept>
Lembra-se de como os predicados e os objetos são encaixados dentro do sujeito? Aqui já o fizemos duas vezes com o mesmo sujeito, para que possamos tornar isto menos prolixo, aninhando ambos os conjuntos de predicados como objetos dentro do mesmo sujeito:
<skosConcept rdf:about="http://www.ihr-tobias.org/concepts/21250/abdication">
<skos:prefLabel>Abdication</skos:prefLabel>
<skos:narrower rdf:resource="http://www.ihr-tobias.org/concepts/19838/abdication_crisis_1936"/>
</skosConcept>
Se estiver familiarizado com XML isto será fácil. Se não estiver, talvez prefira um formato como o Turtle. Mas a vantagem aqui é que ao criar o seu RDF/XML pode usar as ferramentas habituais disponíveis com XML, como editores e analisadores dedicados ao XML, para verificar se o seu RDF/XML está corretamente formatado. Se não for uma pessoa que use o XML recomendo o Turtle, podendo usar uma ferramenta online (em inglês) para verificar se a sua sintaxe está correta.
Consulta de RDF com SPARQL
Para esta secção final iremos interrogar algum LOD e ver o que poderá ser feito com ele.
A linguagem de consulta que usamos para LOD é chamada SPARQL. É um daqueles acrónimos recursivos amados pelos técnicos: SPARQL Protocol and RDF Query Language (Protocolo SPARQL e Linguagem de Consulta RDF).
Como mencionado no início, o Programming Historian tem uma lição completa (em inglês), de Matthew Lincoln, sobre a utilização do SPARQL (embora não seja já mantida (ver nota no início desta tradução). A secção final aqui presente é apenas uma visão geral dos conceitos básicos. Se o SPARQL despertar o seu interesse, pode obter uma fundamentação completa no tutorial de Lincoln.
Vamos realizar as nossas consultas SPARQL na DBpedia, que é um enorme conjunto de LOD derivado da Wikipedia. Além de estar cheio de informação que é muito difícil de encontrar através da habitual interface da Wikipédia, tem vários “pontos de extremidade” (end points) SPARQL - interfaces onde se podem digitar as consultas SPARQL e obter resultados a partir das triplas semânticas da DBpedia.
O end point de consulta SPARQL que é utilizado chama-se snorql: http://dbpedia.org/snorql/ (em inglês). Estes end points ocasionalmente ficam offline. Se for o seu caso, tente procurar por dbpedia sparql e deverá encontrar um substituto semelhante.
Se for ao URL snorql acima verá, no início, um número de prefixos que já nos foram declarados, o que é útil. Agora também irá reconhecer alguns dos prefixos.
Figura 3. Caixa de consulta padrão do snorql, com alguns prefixos declarados para si.
Na caixa de consulta abaixo das declarações de prefixo, deverá ver o seguinte:
SELECT * WHERE {
...
}
Se alguma vez escreveu uma consulta de bases de dados em Structured Query Language, mais conhecida como SQL, isto vai parecer-lhe bastante familiar e vai ajudá-lo a aprender SPARQL. Se não, não se preocupe. As palavras-chave aqui utilizadas, SELECT (SELECIONAR) e WHERE (ONDE) não são sensíveis a maiúsculas e minúsculas, mas algumas partes de uma consulta SPARQL podem ser (ver abaixo), por isso recomendo que se cinja ao caso dado ao longo das consultas neste curso.
Aqui SELECT significa “encontrar alguma coisa” e * significa “dá-me tudo”. WHERE introduz uma condição, que é onde vamos colocar os detalhes de que tipo de coisas queremos que a consulta encontre.
Vamos começar com algo simples para ver como é que isto funciona. Cole (ou, melhor, escreva) isto na caixa de consulta:
SELECT * WHERE {
:Lyndal_Roper ?b ?c
}
Clique em ‘go’ (ir). Se deixar o menu drop-down como ‘browse’ (navegar) deverá obter duas colunas com os rótulos “b” e “c”. (Note que aqui, as maiúsculas/minúsculas importam: lyndal_roper não lhe dará resultados).
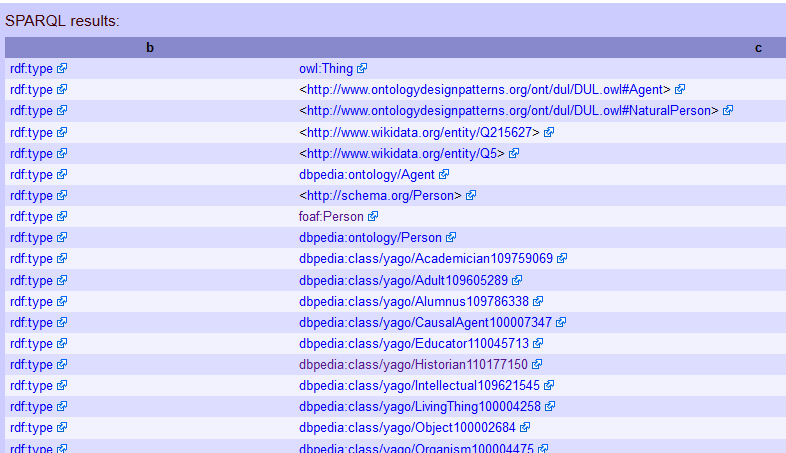
Figura 4. Topo das listas de resultados de uma consulta com todas as triplas semânticas com ‘Lyndal_Roper’ como sujeito.
Então o que é que acabou de acontecer? E como é que soubemos o que escrever?
Na verdade, não sabíamos. Esse é um dos problemas com end points do SPARQL. Quando se conhece um dataset, é preciso experimentar coisas e descobrir que termos são utilizados. Porque isto vem da Wikipedia e nós estávamos interessados sobre que informação sobre historiadores podíamos encontrar. Então vamos à página da Wikipedia da historiadora Lyndal Roper (em inglês).
A parte final do URL é Lyndal_Roper e concluímos então que é provável que esta cadeia de caracteres seja a forma como Roper é referida na DBpedia. Porque não sabemos o que mais poderia estar em triplas semânticas que mencionam Roper, nós utilizamos ?b e ?c: estes são apenas marcadores de posição. Poderia igualmente ter digitado ?whatever e ?you_like e as colunas teriam esses rótulos. Quando quiser ser mais preciso sobre o que se está a pesquisar, será importante etiquetar as colunas de forma significativa.
Experimente agora a sua própria consulta SPARQL: escolha uma página Wikipedia e copie a parte final do URL, após a barra final, e coloque-a no lugar de Lyndal_Roper. Depois clique em ‘go’.
A partir da informação que se obtém destes resultados é possível gerar queries mais precisas. Isto pode ser pouco fiável, por isso não se preocupe se algumas não funcionarem.
Vamos voltar aos resultados para a consulta que fizemos há momentos:
SELECT * WHERE {
:Lyndal_Roper ?b ?c
}
Podemos ver uma longa lista na coluna etiquetada c. Estes são todos os atributos que Roper tem na DBpedia e que nos ajudarão a encontrar outras pessoas com estes atributos. Por exemplo, podemos ver http://dbpedia.org/class/yago/Historian110177150. Poderemos utilizar isto para obter uma lista de historiadores? Vamos colocá-lo na nossa pergunta, mas em terceiro lugar, porque era onde estava quando a encontrei nos resultados da Lyndal Roper. A minha consulta tem este aspecto:
SELECT * WHERE {
?historian_name ?predicate <http://dbpedia.org/class/yago/Historian110177150>
}
Fizemos uma pequena mudança aqui. Se esta consulta funcionar de todo, então esperemos que os nossos historiadores estejam na primeira coluna, porque ‘historiador’ não parece poder ser um predicado: não funciona como um verbo numa frase; por isso vamos chamar à nossa primeira coluna de resultados ‘historian_name’ e à minha segunda (sobre a qual não sabemos nada) ‘predicate’ (predicado).
Execute a querie. Deverá encontrar uma grande lista de historiadores.
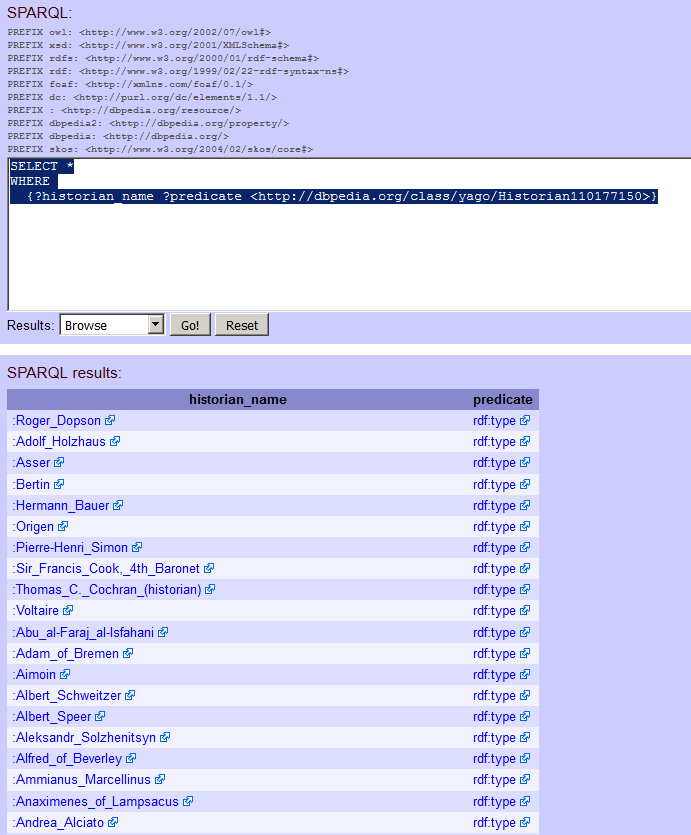
Figura 5. Historiadores de acordo com a DBpedia.
Assim, esta ferramenta funciona para criar listas, o que é útil, mas seria muito mais poderoso combinar listas para obter intersecções de conjuntos. Encontrei mais algumas coisas que podem ser interessantes consultar nos atributos DBpedia de Lyndal Roper: http://dbpedia.org/class/yago/WikicatBritishHistorians e http://dbpedia.org/class/yago/WikicatWomenHistorians. É muito fácil combiná-los pedindo uma variável a ser devolvida (no nosso caso isto é ?name (nome)) e depois utilizando-a em múltiplas linhas de uma querie. Note também o espaço e o ponto completo no final da primeira linha que começa com ?name:
SELECT ?name
WHERE {
?name ?b <http://dbpedia.org/class/yago/WikicatBritishHistorians> .
?name ?b <http://dbpedia.org/class/yago/WikicatWomenHistorians>
}
Funciona! Devemos obter cinco resultados. Na altura em que escrevo, há cinco historiadoras britânicas na DBpedia…
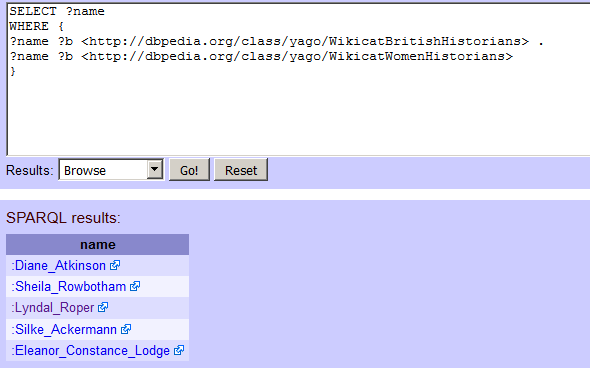
Figura 6. Historiadoras britânicas segundo a DBpedia.
Apenas cinco historiadoras britânicas? Claro que há, na realidade, muitas mais do que isso, como poderíamos facilmente mostrá-lo substituindo o nome de, digamos, Alison Weir na nossa primeira consulta sobre Lyndal Roper. Isto leva-nos ao problema com a Dbpedia que mencionamos anteriormente: não é muito consistentemente marcado com informação estrutural do tipo que a DBpedia que utiliza. A nossa consulta pode listar algumas historiadoras britânicas mas acontece que não podemos utilizá-la para gerar uma lista significativa de pessoas nesta categoria. Tudo o que encontrámos foram as pessoas nas entradas da Wikipedia que alguém decidiu classificar como “historiadora britânica” e “historiadora”.
Com SPARQL na DBpedia, é preciso ter cuidado com as inconsistências do material de origem coletiva. Poderá usar o SPARQL exatamente da mesma forma num dataset mais confiável, por exemplo, os dados do governo britânico: https://data-gov.tw.rpi.edu//sparql (em inglês) e esperar obter resultados mais robustos (há aqui um breve tutorial para este dataset: https://data-gov.tw.rpi.edu/wiki/A_crash_course_in_SPARQL (em inglês).
No entanto, apesar das suas inconsistências, a DBpedia é um ótimo local para aprender SPARQL. Esta foi apenas uma breve introdução, mas há muito mais em Usando SPARQL para aceder ao Linked Open Data (em inglês).
Leituras e recursos adicionais
- Dean Allemang e James Hendler, Semantic Web for the Working Ontologist, 2nd edn, Elsevier, 2011
- Tim Berners-Lee Linked Data (em inglês)
- Bob DuCharme, Learning SPARQL, O’Reilly, 2011
- Blog de Bob DuCharme (em inglês) também vale a pena ler
- Richard Gartner, Metadata: Shaping Knowledge from Antiquity to the Semantic Web, Springer, 2016
- Seth van Hooland and Ruben Verborgh, Linked Data for Libraries, Archives and Museums, 2015
- Matthew Lincoln ‘Using SPARQL to access Linked Open Data’ (em inglês)
- Linked Data guides and tutorials (em inglês)
- Dominic Oldman, Martin Doerr e Stefan Gradmann, ‘Zen and the Art of Linked Data: New Strategies for a Semantic Web of Humanist Knowledge’, em A New Companion to Digital Humanities, editado por Susan Schreibman et al.
- Max Schmachtenberg, Christian Bizer e Heiko Paulheim, State of the LOD Cloud 2017 (em inglês)
- David Wood, Marsha Zaidman e Luke Ruth, Linked Data: Structured data on the Web, Manning, 2014
Agradecimentos
Gostaria de agradecer aos meus dois colegas revisores, Matthew Lincoln e Terhi Nurmikko-Fuller e ao meu editor, Adam Crymble, por me ajudarem generosamente a melhorar esta lição com numerosas sugestões, esclarecimentos e correções. Este tutorial baseia-se num outro escrito como parte do ‘Thesaurus of British and Irish History as SKOS’ (Tobias) project (em inglês), financiado pelo AHRC (em inglês). A lição foi revista para o projeto Programming Historian.