
Introducción y contexto de la lección
Esta lección ofrece una introducción breve y concisa a los datos abiertos enlazados (Linked Open Data, LOD). No es necesario ningún conocimiento previo. Los lectores lograrán comprender de forma clara los conceptos que fundamentan los datos abiertos enlazados, cómo se utilizan y cómo se crean. El tutorial se divide en cinco partes, más una de lecturas adicionales:
- Datos abiertos enlazados: ¿qué son?
- El papel del Identificador de Recursos Uniforme (URI)
- Cómo los LOD organizan el conocimiento: ontologías
- El Marco de descripción de recursos (RDF) y formatos de datos
- Cómo interrogar los datos abiertos enlazados con SPARQL
- Lecturas y recursos adicionales
El tutorial puede completarse en un par de horas, pero siempre es posible releer algunas secciones para reforzar la comprensión. Los términos técnicos se han enlazado con su página correspondiente en Wikipedia; te animamos a hacer una pausa y leer sobre los términos que encuentres más complejos. Después de haber aprendido algunos de los principios clave de LOD, la mejor manera de mejorar y consolidar ese conocimiento es practicar. Este tutorial ofrece oportunidades para hacerlo. Al final del curso deberías entender los fundamentos de LOD, incluyendo términos y conceptos clave.
Si necesitas aprender a explorar los LOD usando el lenguaje de consulta SPARQL, recomiendo la lección ‘Uso de SPARQL para acceder a datos abiertos enlazados’ de Matthew Lincoln, que sigue de una forma práctica la perspectiva conceptual ofrecida en esta lección.
Con el fin de proporcionar a los lectores una base sólida de los principios básicos de LOD, este tutorial no ofrecerá una cobertura completa de todos los conceptos LOD. Los siguientes dos conceptos de LOD no se explicarán en esta lección:
-
La web semántica y el razonamiento semántico de conjuntos de datos. Un razonador semántico deduciría que Jorge VI es el hermano o medio hermano de Eduardo VIII, dado el hecho de que a) Eduardo VIII es el hijo de Jorge V y b) Jorge VI es el hijo de Jorge V. Este tutorial no se centra en este tipo de tareas.
-
La creación y subida de conjuntos de datos abiertos enlazados a la nube de datos enlazados. Compartir tus LOD es un principio importante, al que se anima más adelante. Sin embargo, los aspectos prácticos de contribuir con tus LOD a la nube de datos enlazados está fuera del alcance de esta lección. Al final de este tutorial hay algunos recursos disponibles que pueden ayudarte a comenzar con esta tarea.
Datos abiertos enlazados: ¿qué son?
LOD es información estructurada en un formato destinado a las máquinas y, por tanto, no es necesariamente fácil de entender a primera vista. No te desanimes por esto, ya que una vez que entiendas los principios, puedes conseguir que una máquina los lea por ti.
Si todos los conjuntos de datos se publicaran en abierto y se usara el mismo formato para estructurar la información, sería posible interrogar todos los conjuntos de datos a la vez. Analizar enormes volúmenes de datos es potencialmente mucho más efectivo que la publicación individual de los conjuntos de datos propios distribuidos por la web en lo que se conoce como silos de información. Estos conjuntos de datos interoperables son el destino al que los profesionales de los LOD desean acercarse.
Para lograr este objetivo, al trabajar con LOD, recuerda siempre los tres principios siguientes:
-
Utiliza un formato estándar de LOD reconocido. Para que los LOD funcionen, los datos deben estar estructurados usando estándares reconocidos para que los ordenadores que interrogan los datos puedan procesarlos de manera consistente. Existen varios formatos para LOD, algunos de los cuales se analizan más adelante.
-
Refiérete a una entidad de la misma forma que otras personas. Si tienes datos sobre la misma persona/lugar/cosa en dos o más sitios, asegúrate de referirte a la persona/lugar/cosa de la misma manera en todos los casos.
-
Publica tus datos en abierto. Con la expresión “en abierto” queremos decir que cualquier persona pueda usarlos sin pagar una cuota y en un formato que no requiera programas de pago.
Comencemos con un ejemplo de datos sobre una persona, usando un habitual par atributo-valor típico en computación:
persona=número
En este caso, el ‘atributo’ es una persona. Y el valor —o quien es esa persona— está representado por un número. El número podría ser asignado al azar o podrías utilizar un número que ya estaba asociado con ese individuo. Este último enfoque tiene grandes ventajas: si todo el mundo que crea un conjunto de datos que menciona esa persona utiliza exactamente el mismo número y en exactamente el mismo formato, entonces podemos encontrar de forma fiable a ese individuo en cualquier conjunto de datos que se adhiera a esas reglas.
Vamos a crear un ejemplo con Jack Straw. Con este nombre propio podemos referirnos tanto a un rebelde inglés del siglo XIV como a un prominente ministro del gabinete británico de Tony Blair. Claramente es útil poder diferenciar a las dos personas que comparten un nombre común. Utilizando el modelo anterior en el que cada persona está representada por un número único, identifiquemos al ministro británico Jack Straw con el número 64183282. Su par de atributo-valor entonces se vería así:
persona=64183282
A continuación, vamos a identificar al Jack Straw descrito por el Oxford Dictionary of National Biography como ‘el enigmático líder rebelde’ con el número 33059614. En consecuencia, su par atributo-valor sería el siguiente:
persona=33059614
Procurando que todo aquél que crea LOD use estos dos números para referirse al Jack Straw respectivo, podremos entonces buscar a la persona 64183282 en un conjunto de datos abierto enlazado y estar seguros de que estamos obteniendo a la persona adecuada -en este caso, el ministro-.
Los pares atributo-valor también pueden almacenar información sobre otros tipos de entidades, como, por ejemplo, lugares. Jack Straw el político moderno fue miembro del parlamento británico, representando a Blackburn. Hay más de un lugar en el Reino Unido llamado Blackburn, por no hablar de otros Blackburns en todo el mundo. Usando los mismos principios descritos anteriormente, podemos desambiguar entre los diferentes Blackburns asignando un identificador único al lugar correcto: Blackburn en Lancashire, Inglaterra.
lugar=2655524
En este momento podrías estar pensando, “esto es lo que hace el catálogo de la biblioteca”. Es cierto que la idea clave aquí es la de control de autoridades, que es central en biblioteconomía (un fichero de autoridad es una lista cerrada de términos que pueden ser utilizados en un contexto particular, por ejemplo cuando se cataloga un libro). En ambos ejemplos mencionados anteriormente, hemos utilizado los ficheros de autoridad para asignar los números (los identificadores únicos) a los Jacks y a Blackburn. Los números que utilizamos para los dos Jack Straws provienen del Virtual International Authority File - Archivo de Autoridades Internacional Virtual (VIAF), que es mantenido por un consorcio de bibliotecas de todo el mundo para tratar de abordar el problema de la miríada de formas en las que una misma persona podría ser nombrada. El identificador único que utilizamos para el distrito electoral de Blackburn provino de GeoNames, una base de datos geográfica gratuita.
Pero intentemos ser más precisos por lo que entendemos por Blackburn en este caso. Jack Straw ejerció su cargo parlamentario en representación de Blackburn (que cuenta con un solo miembro en el parlamento británico). Los límites de Blackburn han cambiado con el paso del tiempo, así que en el proyecto ‘Digging Into Linked Parliamentary Data’ (Dilipad) (en el que trabajé) se crearon identificadores únicos para las afiliaciones a partidos y para los distritos electorales de cada miembro del parlamento. En este ejemplo, Jack Straw representó a la circunscripción conocida como ‘Blackburn’ en su encarnación posterior a 1955:
blackburn1955-current
Como VIAF es un archivo de autoridad reputado y bien mantenido de personas notables, fue un conjunto obvio de identificadores a usar para Jack Straw. Como el electorado representado por Straw estaba cubierto perfectamente por los archivos de autoridad creados por el proyecto Dilipad, también fue lógico usarlos. Por desgracia, no siempre es tan obvio cuál de las listas publicadas en línea es mejor utilizar. Una podría ser más usada que otra, pero quizás esta última ofrezca información más completa para un propósito particular. GeoNames funcionaría mejor que los identificadores Dilipad en algunos casos. También habrá casos en los que no puedas encontrar un conjunto de datos con esa información. Por ejemplo, imagina que quisieras escribir pares de atributo-valor sobre ti y tus relaciones familiares cercanas. En este caso, tendrías que inventar tus propios identificadores.
La falta de archivos de autoridad consistentes es uno de los principales retos a los que los LOD se enfrentan en este momento. Tim Berners-Lee, quien ideó una forma de vincular documentos a través de una red creando así la World Wide Web, ha sido durante mucho tiempo uno de sus proponentes principales de los LOD. Para alentar un mayor uso de los LOD sugirió un ‘sistema de calificación de cinco estrellas’ que anime a todos a avanzar lo más posible hacia los LOD. En esencia, cree que es bueno publicar datos en abierto, especialmente si se utilizan formatos abiertos y estándares públicos, pero mejor si también se enlaza con los datos de otras personas.
Una vez que se asignan identificadores únicos a todos los elementos, el siguiente paso es clave en la creación de LOD para tener una manera de describir la relación entre Jack Straw (64183282) y Blackburn (blackburn1955-current). En los LOD, las relaciones se expresan utilizando lo que se conoce como una ‘tripleta’. Hagamos una tripleta que representa la relación entre Jack Straw y su circunscripción electoral:
persona:64183282 rol:representanteEnElParlamentoUK circunscripción:"blackburn1955-current"
La presentación (o sintaxis) de las tripletas, incluida la puntuación utilizada anteriormente, se analizará más adelante, en la sección sobre RDF y formatos de datos. Por ahora, concéntrate en la estructura básica. La tripleta, como es lógico, tiene tres partes. Éstas se conocen convencionalmente como sujeto, predicado y objeto:
| sujeto | predicado | objeto |
|---|---|---|
| persona 64183282 | representanteEnElParlamentoUK | “blackburn1955-current” |
La forma tradicional de representar una tripleta en forma de diagrama es:

Figura 1. Manera clásica de representar una tripleta.
Así que nuestra tripleta de Jack Straw, en una forma más legible para los humanos, podría representarse así:

Figura 2. Diagrama triple que muestra que Jack Straw representó a Blackburn.
Por ahora hay tres puntos clave que recordar:
- Los LOD deben ser abiertos y estar disponibles para cualquier persona en Internet (de lo contrario, no son ‘abiertos’)
- Los impulsores de los LOD tienen como objetivo estandarizar las formas de referirse a entidades únicas
- Los LOD consisten en tripletas que describen relaciones entre entidades
El papel del Identificador Uniforme de Recursos (Uniform Resource Identifier - URI)
Una parte esencial de los LOD es el Identificador Uniforme de Recursos o URI. El URI es una manera unívoca y fiable de representar una entidad (una persona, un objeto, una relación, etc.) en una forma que es utilizable por todo el mundo.
En la sección anterior usamos dos números distintos para identificar nuestros dos Jack Straws diferentes.
persona="64183282"
persona="33059614"
El problema es que en todo el mundo hay muchas bases de datos que contienen personas con estos números, y probablemente sean personas diferentes. Fuera de nuestro contexto inmediato, estas cifras no identifican individuos únicos. Tratemos de arreglar eso. Aquí están estos mismos identificadores pero como URI:
http://viaf.org/viaf/64183282/
http://viaf.org/viaf/33059614/
Así como el número único desambiguó nuestros dos Jack Straws, el URI completo anterior nos ayuda a eliminar la ambigüedad entre todos los diferentes archivos de autoridad que existen. En este caso, está claro que estamos usando VIAF como nuestro archivo de autoridad. Ya has visto esta forma de desambiguación muchas veces en la web. Hay muchos sitios web alrededor del mundo con páginas llamadas /home o /faq. Pero no hay confusión porque el dominio (la primera parte del Localizador Uniforme de Recursos (URL) - por ejemplo,bbc.co.uk) es único y, por lo tanto, todas las páginas que son parte de ese dominio son únicas, diferenciándose de otras páginas /faq de otros sitios web. En la dirección http://www.bbc.co.uk/faqs, es la parte bbc.co.uk la que hace únicas las páginas siguientes. Esto es tan obvio para las personas que usan la web todo el tiempo que no piensan en ello. Probablemente también sepas que si quieres iniciar un sitio web llamado bbc.co.uk no puedes hacerlo, porque ese nombre ya se ha registrado con la autoridad correspondiente, que es el Sistema de Nombres de Dominio (Domain Name System - DNS). El registro garantiza la unicidad. Los URIs también deben ser únicos.
Si bien los ejemplos anteriores se parecen a las URLs, es posible también construir un URI que no se parezca en nada a una URL. Tenemos muchas maneras de identificar personas y cosas de manera única y rara vez lo pensamos o nos preocupamos de ello. Los códigos de barras, los números de pasaporte e incluso tu dirección postal están diseñados para ser únicos. En el mundo desarrollado los números de teléfono móvil se colocan con frecuencia en los carteles de las tiendas precisamente porque son únicos. Todos ellos podrían usarse como URIs.
Cuando quisimos crear URIs para las entidades descritas por el proyecto ‘Tobias’, elegimos una estructura tipo URL y elegimos utilizar nuestro espacio web institucional, dejando de lado data.history.ac.uk/tobias-project/ como un lugar dedicado a alojar estos URI. Al ponerlo en data.history.ac.uk en lugar de en history.ac.uk, hubo una separación clara entre los URI y las páginas del sitio web. Por ejemplo, uno de los URIs del proyecto Tobias era http://data.history.ac.uk/tobias-project/person/15601. Si bien el formato de los URI mencionados anteriormente es el mismo que el de una URL, no se vinculan a páginas web (intenta pegarlas en un navegador web). Muchas personas nuevas con los LOD encuentran esto confuso. Todas las URL son URI, pero no todas las URI son URL. Una URI puede describir cualquier cosa, mientras que una URL describe la ubicación de algo en la web. Es decir, una URL te dice la ubicación de una página web o un archivo o algo similar. Un URI simplemente hace el trabajo de identificar algo. Así como el Número Estándar Internacional de Libro, o ISBN 978-0-1-873354-6 identifica de manera única una edición de tapa dura de Bautismo, Hermandad y Creencias en la Reforma de Alemania por Kat Hill, pero no te dice dónde conseguir una copia. Para eso, necesitarías algo como una signatura, que te da una ubicación exacta en un estante de una biblioteca específica.
Hay un poco de jerga alrededor de los URIs. La gente habla de si son, o no, desreferenciables. Eso solo significa que ¿se puede pasar desde una referencia abstracta a otra cosa? Por ejemplo, si pegas un URI en la barra de direcciones de un navegador, ¿devolverá algo? El URI de VIAF para el historiador Simon Schama es:
http://viaf.org/viaf/46784579
Si lo pones en el navegador, obtendrás una página web sobre Simon Schama que contiene datos estructurados sobre él y su historial de publicaciones. Esto es muy útil, pero, por otro lado, no es obvio desde la URI a quién o incluso a qué se refiere. Del mismo modo, si tratamos un número de teléfono móvil (con código internacional) como URI para una persona, entonces debería ser desreferenciable. Alguien podría responder el teléfono, e incluso podría ser Schama.
Pero esto no es esencial. Muchos de los URI no son desreferenciables, como en el ejemplo anterior del proyecto Tobias. No puedes encontrarlo en ningún sitio; es una convención.
El ejemplo de VIAF nos lleva a otra cosa importante sobre los URIs: no debes crearlos a menos que sea necesario. Las personas y las organizaciones han estado haciendo esfuerzos concertados para construir listas de URIs adecuadas y los LOD no funcionarán de manera efectiva si la gente duplica ese trabajo creando nuevos URIs innecesariamente. Por ejemplo, VIAF cuenta con el apoyo de muchas bibliotecas a nivel internacional. Si deseas construir URI para personas, VIAF es una muy buena opción. Si no puedes encontrar a algunas personas en VIAF, u otras listas de autoridades, sólo entonces podrías necesitar hacer las tuyas propias.
Cómo organizan los LOD el conocimiento: ontologías
Puede que no haya sido obvio por las tripletas individuales que vimos en la sección de apertura, pero los LOD pueden responder preguntas complejas. Cuando unes las tripletas forman un grafo, debido a la forma en que las tripletas se entrelazan. Supongamos que queremos encontrar una lista de todas las personas que fueron alumnos del compositor Franz Liszt. Si la información está en tripletas de datos enlazados sobre pianistas y sus profesores, podemos averigüarlo con una consulta (veremos este lenguaje de consulta, llamado SPARQL, en la sección final).
Por ejemplo, el pianista Charles Rosen fue alumno del pianista Moriz Rosenthal, quien a su vez fue alumno de Franz Liszt. Ahora expresemos eso como dos tripletas (nos limitaremos a usar cadenas para los nombres en lugar de números de ID para que los ejemplos sean más legibles):
"Franz Liszt" enseñóPianoA "Moriz Rosenthal" .
"Moriz Rosenthal" enseñóPianoA "Charles Rosen" .
Podríamos haber creado nuestras tripletas igualmente de esta manera:
"Charles Rosen" aprendióPianoCon "Moriz Rosenthal" .
"Moriz Rosenthal" aprendióPianoCon "Franz Liszt" .
Estamos poniendo ejemplos simplemente con el fin de ilustrar, pero si deseas enlazar tus datos a otros conjuntos de datos en la ‘nube de datos vinculados’ debes ver qué convenciones se utilizan en esos conjuntos de datos y hacer lo mismo. En realidad, esta es una de las características más útiles de los LOD porque gran parte del trabajo se ha realizado para ti. La gente ha dedicado mucho tiempo a desarrollar formas de modelar información dentro de un área particular de estudio y a pensar en cómo se pueden representar las relaciones dentro de esa área. Estos modelos generalmente se conocen como ontologías. Una ontología es una abstracción que permite que representar un conocimiento particular sobre el mundo. Las ontologías, en este sentido, son bastante nuevas y fueron diseñadas para hacer lo que hace una taxonomía jerárquica (como la clasificación de las especies del sistema de Linneo), pero de manera más flexible.
Una ontología es más flexible porque no es jerárquica. Su objetivo es representar la fluidez del mundo real, donde las cosas se pueden relacionar entre sí de formas más complejas que las representadas por una estructura jerárquica de tipo arbóreo. En cambio, una ontología es más como una tela de araña.
Sea lo que sea que desees representar con los LOD, te sugerimos que busques un vocabulario existente y lo uses, en lugar de intentar escribir el tuyo propio. Esta página principal incluye una lista de algunos de los vocabularios más populares
N.T.: desplázate hacia la zona derecha/abajo de la página: “Popular Vocabularies”
Dado que nuestro anterior ejemplo se centra en los pianistas, sería una buena idea encontrar una ontología adecuada en lugar de crear nuestro propio sistema. De hecho, hay una ontología para la música. Además de una especificación bien desarrollada, tiene también algunos ejemplos útiles de su uso. Puedes echar un vistazo a las páginas de Introducción para tener una idea de cómo puedes usar esa ontología particular.
Lamentablemente, no encuentro nada que describa la relación entre un profesor y un alumno en Music Ontology. Pero la ontología se publica en abierto, así que puedo usarla para describir otras características de la música y luego crear mi propia extensión. Si luego publico mi extensión en abierto, otros pueden usarla si lo desean y puede convertirse en un estándar. Si bien el proyecto Music Ontology no tiene la relación que necesito, el proyecto Linked Jazz permite el uso de ‘mentorDe’, que parece que podría funcionar bien en nuestro caso. Aunque esta no es la solución ideal, conviene esforzarse por usar lo que ya existe.
Ahora bien, si estuvieras estudiando la historia de los pianistas, querrías identificar a muchos pianistas a quienes los alumnos de Liszt enseñaron, establecer una especie de árbol genealógico y ver si estos “nietos” de Liszt tienen algo en común. Podrías investigar a los alumnos de Liszt, hacer una gran lista de ellos, y luego investigar a cada uno de los alumnos e intentar hacer una lista de los alumnos que tuvieron. Con los LOD podrías (de nuevo, si es que las tripletas existen) hacer una consulta como:
Dame los nombres de todos los pianistas enseñados por x
donde x fue enseñado a tocar el piano por Liszt
La consulta devolvería todas las personas en el conjunto de datos que fueron alumnos de un alumno de Liszt. No nos entusiasmemos demasiado: esta consulta no nos dará a cada alumno de cada alumno de Liszt que haya existido alguna vez porque esa información probablemente no exista y no exista dentro de ningún grupo de tripletas existente. Lidiar con datos del mundo real muestra todo tipo de omisiones e inconsistencias que veremos cuando analicemos el mayor conjunto de LOD, DBpedia, en la sección final.
Si has utilizado bases de datos relacionales, podrías pensar que pueden realizar la misma función. En el caso de Liszt, la información sobre pianistas descrita anteriormente podría organizarse en una tabla de base de datos llamada algo así como ‘Alumnos’.
| alumnoID | profesorID |
|---|---|
| 31 | 17 |
| 35 | 17 |
| 49 | 28 |
| 56 | 28 |
| 72 | 40 |
Si no estás familiarizado con las bases de datos, no te preocupes. Pero probablemente aún puedas ver que algunos pianistas en esta tabla tenían el mismo profesor (números 17 y 28). Sin entrar en detalles, si Liszt está en esta tabla de la base de datos, sería bastante fácil extraer los alumnos de los alumnos de Liszt, utilizando la sentencia SQL join.
De hecho, las bases de datos relacionales pueden ofrecer resultados similares a los LOD. La gran diferencia es que los LOD pueden ir más allá: puede enlazar conjuntos de datos creados sin intención explícita de ser enlazados. El uso de Resource Description Framework (RDF) y las URIs permite que esto suceda.
RDF y formatos de datos
Los LOD usan un estándar, definido por el World Wide Web Consortium, o W3C, llamado Resource Description Framework, o simplemente RDF. Los estándares son útiles siempre que sean adoptados de forma generalizada -piensa en el metro o en los tamaños estándar de tornillo- incluso si son esencialmente arbitrarios. RDF ha sido adoptado como el estándar para los LOD.
A menudo oirás que los LOD son denominados simplemente como RDF. Hemos retrasado hablar de RDF hasta ahora porque es bastante abstracto. RDF es un modelo de datos que describe cómo se estructuran los datos en un nivel teórico. Así, la insistencia en usar tripletas (en lugar de cuatro partes, o dos o nueve, por ejemplo) es una regla de RDF. Pero cuando se trata de asuntos más prácticos, tienes algunas opciones de implementación. Por tanto, RDF te dice lo que tienes que hacer, pero no exactamente cómo tienes que hacerlo. Estas opciones se dividen en dos áreas: cómo escribes las cosas (serialización) y las relaciones que describen tus tripletas.
Serialización
La serialización es el término técnico para ‘cómo escribes las cosas’. El chino estándar (mandarín) se puede escribir en caracteres tradicionales, caracteres simplificados o romanización Pinyin y el idioma en sí no cambia. Del mismo modo, RDF se puede escribir en diversas formas. Aquí veremos dos (hay otros, pero por simplicidad, nos centraremos en estos):
1) Turtle
2) RDF/XML
Reconocer qué serialización estás viendo significa que puedes elegir las herramientas adecuadas diseñadas para ese formato. Por ejemplo, RDF puede venir serializado en formato XML. Luego puedes usar una herramienta o biblioteca de código diseñada para analizar ese formato en particular, lo que es útil si ya sabes cómo trabajar con él. El reconocimiento del formato también te brinda las palabras clave correctas para buscar ayuda en línea. Muchos recursos ofrecen sus bases de datos de LOD para su descarga y puedes elegir qué serialización deseas descargar.
Turtle
‘Turtle’ (Tortuga en español) es un juego de palabras. ‘Tur’ es la abreviatura de ‘terse’ (conciso), y ‘tle’ -es la abreviatura de ‘triple language’ (lenguaje de tripletas)-. Turtle es una forma gratamente simple de escribir tripletas.
Turtle usa alias o atajos conocidos como prefijos, lo que nos ahorra tener que escribir URIs completos todo el tiempo. Regresemos al URI que inventamos en la sección anterior:
http://data.history.ac.uk/tobias-project/person/15601
No queremos escribir esto cada vez que nos referimos a esta persona (Jack Straw, como recordarás). Entonces sólo tenemos que anunciar nuestro atajo:
@prefix toby: <http://data.history.ac.uk/tobias-project/person/> .
Así, Jack es toby:15601, que reemplaza el URI largo y es más fácil de leer. He elegido ‘toby’, pero podría haber elegido cualquier cadena de letras con la misma facilidad.
Pasemos ahora de Jack Straw a William Shakespeare y usemos Turtle para describir algunos elementos sobre sus obras. Tendremos que decidir qué archivos de autoridad usar, un proceso que, como se mencionó anteriormente, se optimiza si consultamos otros conjuntos de LOD. Aquí usaremos Dublin Core, un estándar de metadatos usado por las bibliotecas, como uno de nuestros prefijos, el archivo de autoridad del Número de control de la Biblioteca del Congreso para otro, y el último (VIAF) debería serte familiar. En conjunto, estos tres archivos de autoridad proporcionan identificadores únicos para todas las entidades que planeo usar en este ejemplo:
@prefix lccn: <http://id.loc.gov/authorities/names/> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix viaf: <http://viaf.org/viaf/> .
lccn:n82011242 dc:creator viaf:96994048 .
Ten en cuenta el espaciado del punto final después de la última línea. Esta es la forma de Turtle de indicar el final. Técnicamente no tiene que tener el espacio, pero lo hace más fácil de leer después de una larga cadena de caracteres.
En el ejemplo anterior, lccn: n82011242 representa a Macbeth; dc: creator vincula Macbeth a su autor; viaf: 96994048 representa a William Shakespeare.
Turtle también te permite listar tripletas sin molestarte en repetir cada URI cuando acabas de usarlo. Agreguemos la fecha en la que los expertos creen que Macbeth fue escrita utilizando el par atributo-valor de Dublin Core:dc: created 'YYYY' :
@prefix lccn: <http://id.loc.gov/authorities/names/> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix viaf: <http://viaf.org/viaf/> .
lccn: n82011242 dc: creator viaf: 96994048 ;
dc: created "1606" .
¿Recuerdas la estructura de la tripleta, discutida en la sección 1? Allí pusimos este ejemplo:
1 persona 15601 (el sujeto) 2 representanteEnElParlamentoUK (el predicado) 3 "Blackburn" (el objeto)
La clave es que el predicado conecta el sujeto y el objeto. Describe la relación entre ellos. El sujeto ocupa el primer lugar en la tripleta, pero eso es una cuestión de elección propia, como comentamos en el ejemplo de las personas a quienes Liszt enseñó piano.
Puedes usar un punto y coma si el sujeto es el mismo pero el predicado y el objeto son diferentes, o una coma si el sujeto y el predicado son iguales y solo el objeto es diferente.
no2010025398 dc:creator viaf:96994048 ;
viaf:12323361 .
Aquí estamos diciendo que Shakespeare (96994048) y John Fletcher (12323361) fueron los creadores de la obra Los dos nobles caballeros.
Cuando anteriormente vimos las ontologías, sugerí que le echaras un vistazo a los ejemplos de la Music Ontology. Espero que no te decepcionaran. Echa un vistazo de nuevo ahora. Todavía es algo complicado, pero ¿tiene más sentido ahora?
Una de las ontologías más accesibles es Friend of a Friend, o FOAF. Está diseñada para describir personas y es, quizás por esa razón, bastante intuitiva. Si, por ejemplo, deseas escribirme para decirme que este tutorial es lo mejor que has leído, aquí está mi dirección de correo electrónico expresada como tripletas en FOAF:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
:"Jonathan Blaney" foaf:mbox <mailto:jonathan.blaney@sas.ac.uk> .
RDF/XML
En contraste con Turtle, RDF/XML puede parecer un poco pesado. Para empezar, convirtamos una tripleta del Turtle anterior, la que dice que Shakespeare fue el creador de Los dos parientes nobles:
no2010025398 dc:creator viaf:96994048 .
En RDF/XML, con los prefijos declarados dentro del fragmento XML, es así:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-
xmlns:dc="http://purl.org/dc/terms/">
<rdf:Description rdf:about="http://info:lccn/2010025398">
<dc:creator rdf:resource="http://viaf.org/96994048"/>
</rdf:Description>
</rdf:RDF>
El formato RDF/XML tiene la misma información básica que Turtle, pero se escribe de forma muy diferente, basándose en los principios de las etiquetas XML anidadas.
Pasemos a un ejemplo diferente para mostrar cómo RDF/XML combina tripletas y, al mismo tiempo, presentamos SKOS (Simple Knowledge Organization System - Sistema Simple de Organización del Conocimiento), que está diseñado para codificar tesauros o taxonomías.
<skosConcept rdf:about="http://www.ihr-tobias.org/concepts/21250/Abdication">
<skos:prefLabel>Abdication</skos:prefLabel>
</skosConcept>
Aquí estamos diciendo que el concepto SKOS 21250, abdicación, tiene una etiqueta preferida de “abdicación”. La forma en que funciona es que el elemento sujeto (incluida la parte de abdicación, que es un valor de atributo en términos XML) tiene el predicado y el objeto anidados dentro de él. El elemento anidado es el predicado y el nodo hoja (the leaf node), es el objeto. Este ejemplo está tomado de un proyecto para publicar un tesauro de historia británica e irlandesa.
Al igual que con Turtle, podemos agregar más tripletas. Entonces, declaremos que el término más restringido en nuestra jerarquía de temas, uno más abajo de Abdicación será Crisis de la abdicación (1936).
<skosConcept rdf:about="http://www.ihr-tobias.org/concepts/21250/abdication">
<skos:prefLabel>Abdication</skos:prefLabel>
</skosConcept>
<skosConcept rdf:about="http://www.ihr-tobias.org/concepts/21250/abdication">
<skos:narrower rdf:resource="http://www.ihr-tobias.org/concepts/19838/abdication_crisis_1936"/>
</skosConcept>
¿Recuerdas cómo los predicados y los objetos están anidados dentro del sujeto? Aquí lo hemos hecho dos veces con el mismo sujeto, por lo que podemos hacer esto menos detallado al anidar ambos conjuntos de predicados y objetos dentro de un sujeto:
<skosConcept rdf:about="http://www.ihr-tobias.org/concepts/21250/abdication">
<skos:prefLabel>Abdication</skos:prefLabel>
<skos:narrower rdf:resource="http://www.ihr-tobias.org/concepts/19838/abdication_crisis_1936"/>
</skosConcept>
Si estás familiarizado con XML, esto será muy fácil para ti. Si no lo estás, podrías preferir un formato como Turtle. Pero la ventaja aquí es que creando tu RDF/XML puedes usar las herramientas habituales disponibles para XML, como editores y analizadores XML, para verificar que tu RDF/XML esté formateado correctamente. Si no tienes experiencia con XML, recomiendo Turtle, para lo que puedes usar una herramienta en línea para verificar que tu sintaxis sea correcta.
Consultas RDF con SPARQL
Para esta sección final, interrogaremos algunos LOD y veremos qué podemos hacer con ellos.
El lenguaje de consulta que utilizamos para los LOD se llama SPARQL. Es uno de esos acrónimos recursivos amados por los tecnólogos: Protocolo SPARQL y lenguaje de consulta RDF.
Como mencioné al principio, The Programming Historian en español tiene una lección completa, por Matthew Lincoln, sobre el uso de SPARQL. Esta última sección sólo proporciona una descripción general de los conceptos básicos y, si SPARQL despierta tu interés, puedes obtener una base sólida con el tutorial de Lincoln.
Vamos a ejecutar nuestras consultas SPARQL en DBpedia, que es un gran conjunto de LOD derivado de Wikipedia. Además de estar lleno de información que es muy difícil de encontrar a través de la interfaz habitual de Wikipedia, tiene varios “puntos finales” SPARQL: interfaces donde puedes escribir consultas SPARQL y obtener resultados de las tripletas de DBpedia.
El punto de entrada (endpoint) de consulta SPARQL que yo uso se llama snorql: http://dbpedia.org/snorql/. Estos puntos de entrada a veces parecen desconectarse, por lo que, si ese fuera el caso, busca dbpedia sparql en internet para encontrar un reemplazo similar.
Si vas a la URL snorql indicada antes, verás que al principio ya están declarados varios prefijos, lo cual te será útil. También reconocerás ya algunos de los prefijos.
Figura 3. Cuadro de consulta predeterminado de snorql, con algunos prefijos declarados para ti.
En el cuadro de consulta, debajo de las declaraciones de prefijo, deberías ver:
SELECT * WHERE {
...
}
Si alguna vez ha escrito una consulta de base de datos en Structured Query Language, más conocido como SQL, esto te resultará bastante familiar y te ayudará a aprender SPARQL. Si no, no te preocupes. Las palabras clave utilizadas aquí, SELECT y WHERE no distinguen entre mayúsculas y minúsculas, pero algunas partes de una consulta SPARQL lo pueden hacer (ver a continuación), por lo que te recomiendo que sigas fielmente los ejemplos mostrados a lo largo de las consultas en este curso.
Aquí SELECT significa devolver algo y * significa darme todo. WHEREintroduce una condición, que es donde pondremos los detalles de qué clase de cosas queremos que nos devuelva la consulta.
Comencemos con algo simple para ver cómo funciona esto. Pega esto (o, mejor, escríbelo) en el cuadro de consulta:
SELECT * WHERE {
:Lyndal_Roper ?b ?c
}
Haz clic en “Go!”(ir) y, si dejaste el cuadro desplegable como “Browse” (navegar), deberías obtener dos columnas con la etiqueta “b” y “c”. (Ten en cuenta que aquí, las mayúsculas y minúsculas sí importan: lyndal_roper no te dará ningún resultado).
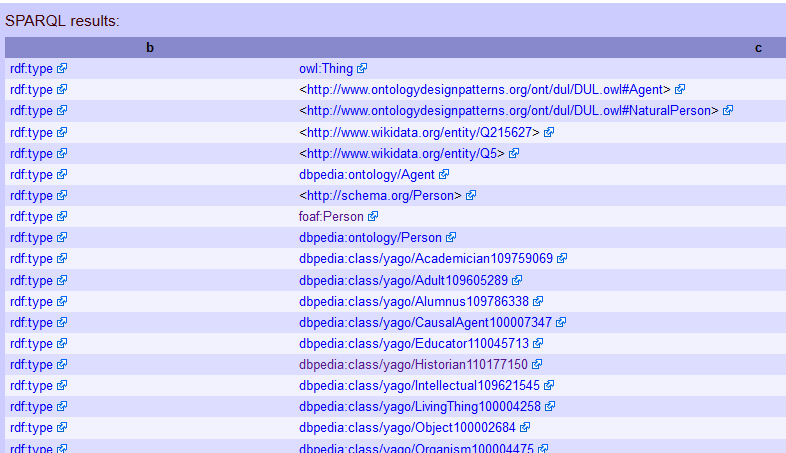
Figura 4. Parte inicial de la lista de resultados de una consulta para todas las tripletas con ‘Lyndal_Roper’ como sujeto.
Recapitulando, ¿qué acaba de pasar? ¿Y cómo sé qué escribir?
En realidad no lo sabía y ese es uno de los problemas con los puntos de entrada SPARQL. Al conocer un conjunto de datos, debes probar y descubrir qué términos se usan. Como este proviene de Wikipedia y me interesaba saber qué información sobre historiadores podía encontrar, fui a la página de Wikipedia del historiador Lyndal Roper.
La parte al final de la URL es Lyndal_Roper y llegué a la conclusión de que esta cadena es probablemente la forma en que se hace referencia a Roper en DBpedia. Como no sé qué más podría haber en las tripletas que mencionen a Roper, usé ?b y ?c. Estos son comodines: podría haber escrito igualmente ?en_cualquier_sitio y ?como_gustes y las columnas tendrían esos títulos. Cuando desees ser más preciso sobre lo que estás obteniendo, será más importante etiquetar las columnas de forma significativa.
Prueba ahora tu propia consulta SPARQL ahora: elije una página de Wikipedia y copia la parte final de la URL, lo que aparece después de la barra diagonal final, y colócalo en lugar de Lyndal_Roper. Luego presiona ‘Go!’.
A partir de la información que obtienes de estos resultados, es posible generar consultas más precisas. Esto puede ser un tanto impredecible, al menos para mí, así que no te preocupes si algunos no funcionan.
Volvamos a los resultados de la consulta que ejecuté hace un momento:
SELECT * WHERE {
:Lyndal_Roper ?b ?c
}
Puedo ver una larga lista en la columna etiquetada como c . Estos son todos los atributos que Roper tiene en la DBpedia y nos ayudarán a encontrar otras personas con estos atributos. Por ejemplo, puedo ver http://dbpedia.org/class/yago/Historian110177150. ¿Puedo usar esto para obtener una lista de historiadores? Voy a poner esto en mi consulta pero en tercer lugar (porque ahí es donde estaba cuando lo encontré en los resultados de Lyndal Roper). Mi consulta se ve así:
SELECT * WHERE {
?historian_name ?predicate <http://dbpedia.org/class/yago/Historian110177150>
}
He hecho un pequeño cambio aquí. Si esta consulta funciona entonces espero que mis historiadores estén en la primera columna, porque “historiador” no parece ser un predicado: no funciona como un verbo en una oración; así que voy a llamar a mi primera columna de resultados ‘nombre_historiador’ y a mi segunda (de la que no sé nada) ‘predicado’.
Ejecuta la consulta. ¿Te funciona? Yo obtuve una gran lista de historiadores.
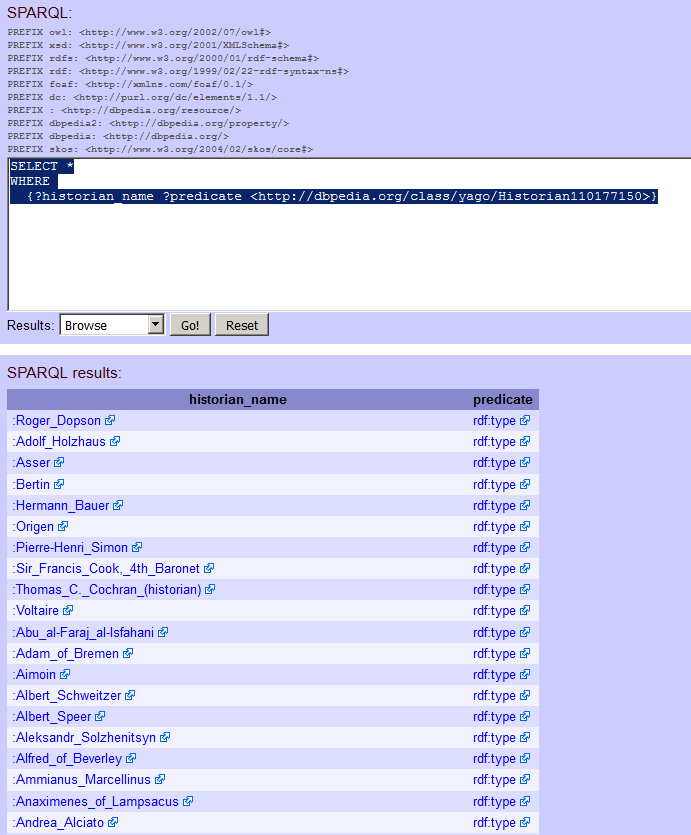
Figura 5. Historiadores, según DBpedia.
Así que esto funciona para crear listas, lo cual es útil, pero sería mucho más potente combinar listas, para obtener intersecciones de conjuntos. Encontré un par de cosas más que podrían ser interesantes para consultar en los atributos de DBpedia de Lyndal Roper: http://dbpedia.org/class/yago/WikicatBritishHistorians y http://dbpedia.org/class/yago/WikicatWomenHistorians. Es muy fácil combinarlos pidiendo una variable que retornará (en nuestro caso, esta es ?name) y luego usar eso en múltiples líneas de una consulta. Ten en cuenta también el espacio y el punto al final de la primera línea que comienza con ?name:
SELECT ?name
WHERE {
?name ?b <http://dbpedia.org/class/yago/WikicatBritishHistorians> .
?name ?b <http://dbpedia.org/class/yago/WikicatWomenHistorians>
}
¡Funciona! Obtengo cinco resultados. En el momento de escribir, hay cinco historiadoras británicas en DBpedia…
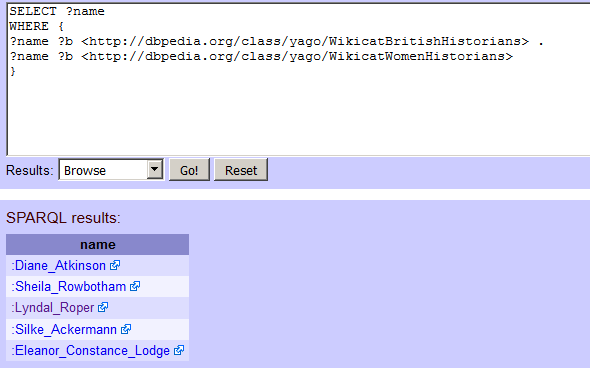
Figura 6. Historiadoras británicas, según DBpedia.
¿Solo cinco mujeres británicas historiadoras? Por supuesto que hay, en realidad, muchas más que eso, como podríamos demostrar fácilmente sustituyendo el nombre de, digamos, Alison Weir en nuestra primera consulta de Lyndal Roper. Esto nos lleva al problema con Dbpedia que mencioné anteriormente: no está marcado de manera consistente con información estructural del tipo que usa DBpedia. Nuestra consulta puede enumerar algunas historiadoras británicas, pero resulta que no podemos usarla para generar una lista significativa de personas en esta categoría. Todo lo que hemos encontrado es la gente en las entradas en Wikipedia que alguien ha decidido categorizar como “Historiador británico” y “mujer historiadora”.
Con SPARQL en DBpedia, debes tener cuidado con las inconsistencias del material de múltiples fuentes. Podrías usar SPARQL exactamente de la misma manera en un conjunto de datos más mantenido, por ejemplo, los datos del gobierno del Reino Unido: https://data-gov.tw.rpi.edu//sparql y esperar obtener resultados más sólidos (hay un breve resumen tutorial para este conjunto de datos aquí: https://data-gov.tw.rpi.edu/wiki/A_crash_course_in_SPARQL).
Sin embargo, a pesar de sus inconsistencias, DBpedia es un gran lugar para aprender SPARQL. Esto solo ha sido una breve introducción pero hay mucho más en ‘Uso de SPARQL para acceder a datos abiertos enlazados’.
Lecturas adicionales y recursos
-
Dean Allemang y James Hendler, Semantic Web for the Working Ontologist, 2nd edn, Elsevier, 2011
-
Tim Berners-Lee Linked Data
-
Bob DuCharme, Learning SPARQL, O’Reilly, 2011
-
El blog de Bob DuCharme merece la pena leerlo también.
-
Richard Gartner, Metadata: Shaping Knowledge from Antiquity to the Semantic Web, Springer, 2016
-
Seth van Hooland y Ruben Verborgh, Linked Data for Libraries, Archives and Museums, 2015
-
Matthew Lincoln ‘Using SPARQL to access Linked Open Data’
-
Dominic Oldman, Martin Doerr y Stefan Gradmann, “Zen and the Art of Linked Data: New Strategies for a Semantic Web of Humanist Knowledge”, in A New Companion to Digital Humanities, editado por Susan Schreibman et al.
-
Max Schmachtenberg, Christian Bizer y Heiko Paulheim, State of the LOD Cloud 2017
-
David Wood, Marsha Zaidman y Luke Ruth, Linked Data: Structured data on the Web, Manning, 2014
-
Biblioteca del Congreso Nacional de Chile, Linked Open Data: ¿Qué es?
-
Ana-Isabel Torre-Bastida, Marta González-Rodríguez y Esther Villar-Rodríguez, Datos abiertos enlazados (LOD) y su implantación en bibliotecas: iniciativas y tecnologías
Agradecimientos
El autor del tutorial agradece a los revisores del tutorial original, Matthew Lincoln y a Terhi Nurmikko-Fuller, y al editor, Admam Cyrmble, por dedicar tiempo generosamente a ayudarle a mejorar este tutorial con numerosas sugerencias, aclaraciones y correcciones. Esta lección se basa en un trabajo perteneciente al “Tesauro de historia Británica e Irlandsesa como SKOS” (proyecto Tobias), financiado por el AHRC. Ha sido revisado para The Programming Historian.