
Conteúdos
Introdução
Um dos problemas centrais das humanidades digitais tem sido o trabalho com e sobre textos: captura (digitalização), reconhecimento, transcrição, codificação, processamento, transformação e análise. Nesta lição nos centraremos exclusivamente na codificação de textos, ou seja, na sua categorização por meio de etiquetas (tags).
Um exemplo pode ajudar a esclarecer esta ideia. Vamos supor que temos um documento impresso já digitalizado previamente. Temos as imagens das páginas digitalizadas e, com a ajuda de um software de reconhecimento óptico de caracteres (OCR, em inglês), extraímos o texto contido nas páginas. Este texto é chamado texto simples (ou texto digitalizado), isto é, o texto sem nenhum formato (sem cursiva, negrito, etc.) nem nenhuma outra estruturação semântica.
Embora pareça estranho, o texto simples carece completamente de conteúdo. Para um computador é só uma longa cadeia de caracteres (incluindo pontuação, espaços em branco e saltos de linha, etc.) em uma codificação (por exemplo UTF-8 ou ASCII) de algum alfabeto (por exemplo, latino, grego ou cirílico). Somos nós quem, quando lemos, identificamos palavras (em uma ou várias línguas), linhas, parágrafos, etc. Somos nós também que identificamos nomes de pessoas e de lugares, títulos de livros e artigos, datas, citações, epígrafes, referências cruzadas (internas e externas), notas de rodapé e notas no final do texto. Mas, mais uma vez, o computador é completamente ‘ignorante’ a respeito de tais estruturas textuais num texto simples sem processamento ou codificação.
Sem assistência humana, por exemplo, através da codificação TEI (Text Encoding Initiative), o computador não pode “entender” ou detectar nenhum conteúdo no texto simples. Isto significa, entre outras coisas, que não podemos fazer buscas estruturadas naquele texto (por exemplo, por nomes de pessoas, lugares e datas), nem podemos extrair e processar sistematicamente aquela informação, sem antes indicar ao computador que cadeias de carateres correspondem a que estruturas semânticas: por exemplo, que esse é o nome próprio de uma pessoa, que o nome de outra pessoa se refere à mesma pessoa, que esse é um nome de um lugar, que essa é uma nota na margem feita por uma terceira pessoa, ou que este parágrafo pertence a tal seção do texto. Codificar o texto é indicar (por meio de etiquetas e outros recursos) que certas cadeias de texto simples têm um certo significado. E essa é a diferença entre texto simples e texto estruturado semanticamente.
Há muitas maneiras de codificar um texto. Por exemplo, podemos incluir os nomes próprios das pessoas entre asteriscos simples: *Fernando Pessoa*, *Carolina Maria de Jesus*, etc.; e, entre asteriscos duplos, os nomes de lugares: **Salvador**, **Lisboa**, etc. Também podemos utilizar o sublinhado (underline) para indicar os nomes de obras e livros: _A Divina Comédia_, _Memórias Pósthumas de Braz Cubas_, etc. Estes signos servem para etiquetar ou marcar o texto incluido entre eles, de modo a identificar um determinado conteúdo. Como pode facilmente imaginar, as possibilidades de codificação são quase infinitas.
Nesta lição, aprenderá como codificar textos usando uma linguagem de computador especialmente desenhada para isso: TEI.
O software que usaremos
Qualquer editor de texto simples (em formato .txt) será útil para fazer tudo o que precisamos nesta lição: o Bloco de Notas (Notepad) do Windows, por exemplo, é perfeitamente adequado para isto. Entretanto, há outros editores de texto que oferecem ferramentas ou funcionalidades destinadas a facilitar o trabalho com XML (Extensible Markup Language) e até mesmo com TEI. Um dos mais recomendados atualmente é o Oxygen XML Editor, disponível para Windows, MacOS e Linux. No entanto, não é um software gratuito (a licença académica custa cerca de US$ 100 USD), nem de código aberto.
Para esta lição usaremos o editor Visual Studio Code (VS Code, resumidamente), criado pela Microsoft e atualmente mantido por uma grande comunidade de programadores de software livre. É uma aplicação totalmente gratuita e de código aberto, disponível para Windows, MacOS e Linux.
Baixe a última versão do VS Code no link https://code.visualstudio.com/ e instale-a no seu computador. Agora abra o software e verá uma tela parecida com a seguinte imagem:
Vista inicial do VS Code
Agora vamos instalar uma extensão do VS Code chamada XML Complete, para facilitar o trabalho com documentos XML. Para tal, clique no botão de extensão na barra de ferramentas lateral do lado esquerdo da janela principal:
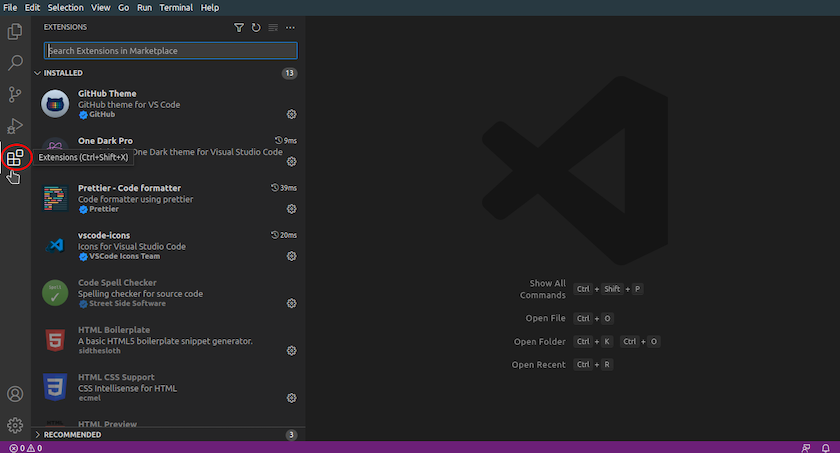
Extensões de VS Code
Digite Xml complete no campo de busca:
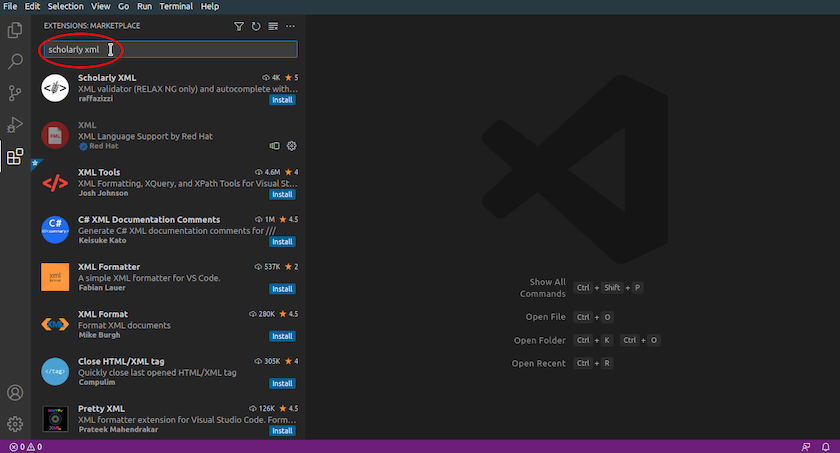
Busca de extensões de VS Code
Finalmente, clique em “Instalar”:
Instalar “XML Complete” no VS Code
A extensão XML Complete nos permite, entre outras coisas, validar formalmente documentos XML. Se houver um erro formal - por exemplo, se esquecemos de fechar uma etiqueta - o VS Code irá mostrá-lo na barra inferior:
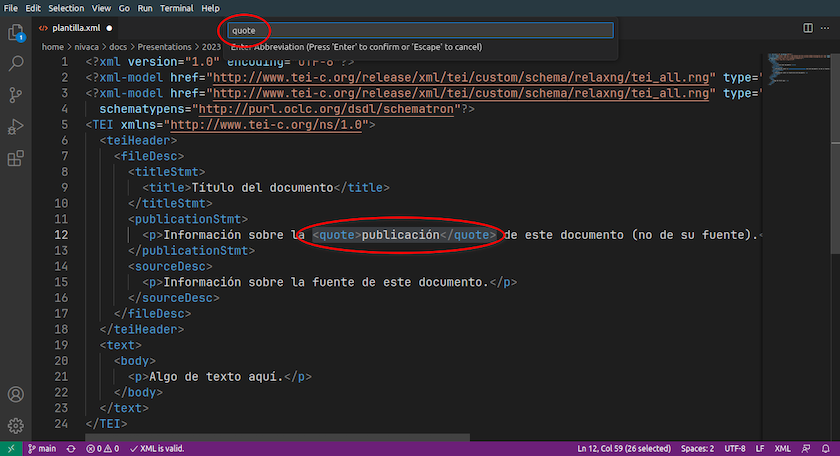
Identificar erros sintáticos no VS Code
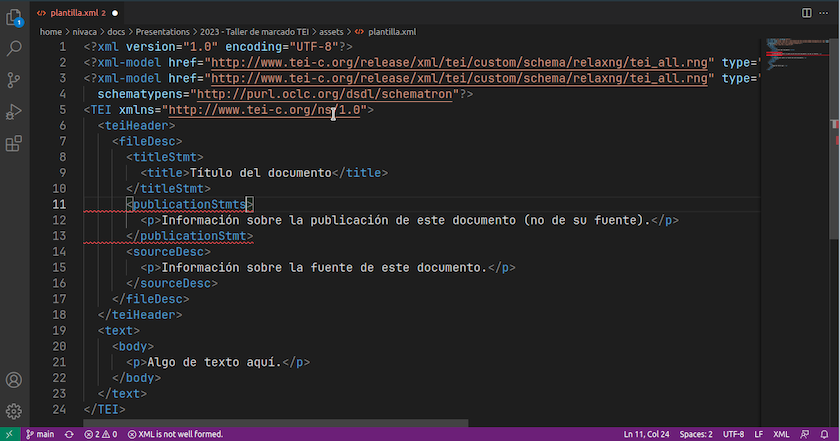
Identificar erros sintáticos no VS Code (detalhe)
Esta extensão também oferece outras ferramentas úteis para autocompletar o código XML. Para mais detalhes, consulte a documentação (unicamente disponível em inglês).
Visualização vs. categorização
Aqueles que estejam familiarizados com a linguagem de marcação Markdown - habitual na atualidade em fóruns técnicos na Internet, assim como no GitHub, GitLab e outros repositórios de código - certamente reconhecerão o uso de elementos como asteriscos (*), underscores (_) e hashtag (#) para fazer com que o texto apareça de certa forma no navegador. Por exemplo, o texto incluído entre asteriscos simples será mostrado em itálico e o texto incluído entre asteriscos duplos será mostrado em negrito. Inclusive, o texto desta lição está escrito em Markdown, seguindo estas convenções.
Este uso da marcação tem como objetivo principal visualizar o texto, não a sua categorização. Em outras palavras, as marcas ou etiquetas de Markdown não indicam que um texto seja de uma certa categoria (por exemplo, o nome de uma pessoa, de um lugar ou de uma obra), mas apenas que o texto deve ser exibido ou mostrado de certa forma num navegador ou outra mídia.
Compreender a diferença entre a marcação de visualização (como a de Markdown) e a marcação semântica (ou estrutural, como veremos mais adiante em TEI) é crucial para entender o propósito da codificação de textos. Quando fazemos a marcação de um fragmento de texto para o codificar, não nos preocupamos à partida como este foi representado originalmente nem tão-pouco como possa vir a ser eventualmente representado no futuro. Estamos apenas interessados na função semântica ou estrutural que um determinado texto possa ter. Sendo assim, devemos procurar identificar com precisão as funções ou categorias dos textos, deixando de parte, na medida do possível, o modo como são exibidos no papel ou no monitor.
Para que este ponto fique bem esclarecido, voltemos ao nosso exemplo inicial. Vamos supor que no texto digitalizado a partir do qual começamos aparecem nomes próprios impressos, como no fragmento a seguir (nota de tradução: na lição original em espanhol foi usado o texto D. Quixote de Cervantes; nesta lição traduzida iremos usar Memórias Pósthumas de Braz Cubas de Machado de Assis, bem como outros excertos de textos em português em substituição dos exemplos originais em espanhol):
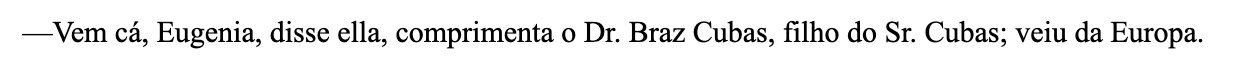
Fragmento curto de texto digitalizado de Memórias Pósthumas de Braz Cubas
Como veremos mais adiante, a TEI nos permite codificar, por meio de uma série de etiquetas, o texto que queremos categorizar. Por exemplo, podemos utilizar uma etiqueta como <name> para demarcar os nomes próprios contidos no texto, desta forma:
Vem cá, <name>Eugenia</name>, disse ella, comprimenta o <name>Dr. Braz Cubas</name>, filho do <name>Sr. Cubas</name>; veiu da Europa.
Mais adiante veremos em detalhe o que é uma etiqueta (ou mais precisamente um elemento) e como ela funciona em XML e TEI. Por enquanto, note-se que a etiqueta não significa que o texto tenha sido originalmente representado em versaletes (ou de qualquer outra forma). Apenas significa que o texto contido tem o estatuto de um nome próprio, independentemente de como este seja representado. De fato, podemos codificar exaustivamente um documento com centenas ou milhares de etiquetas, sem que nenhuma delas apareça no final numa eventual representação.
XML e TEI: rumo a um padrão de codificação de textos
Desde o início das humanidades digitais nos anos 60, houve muitas abordagens à codificação de textos. Quase todos os projetos de codificação tinham o seu próprio padrão, o que levou à existência de projetos incompatíveis e intraduzíveis entre si, dificultando e, até mesmo, impossibilitando o trabalho colaborativo.
Para resolver este problema, quase vinte anos depois, foi estabelecido um novo padrão de codificação de textos, concertado por um grande número de pesquisadores de todo o mundo, especialmente de universidades anglo-saxônicas: a Text Encoding Initiative (TEI).
A própria TEI é construída sobre a linguagem de marcação XML e é, portanto, às vezes referida como “TEI-XML” (ou também “XML/TEI”). XML (que significa “eXtensible Markup Language”) é uma linguagem computacional cujo objetivo é descrever, por meio de uma série de marcações ou etiquetas (tags em inglês), um determinado objeto de texto. XML e TEI são linguagens de marcação e nesse sentido se diferenciam das linguagens de programação como C, Python ou Java, que descrevem objetos, funções ou procedimentos a serem executados por um computador.
XML
Nesta lição, não entraremos em pormenores sobre a sintaxe e o funcionamento do XML. Recomendamos, portanto, que o leitor consulte esta outra lição (em inglês) para mais informações sobre XML, assim como a bibliografia e as referências sugeridas no final desta lição.
Por enquanto, só precisamos de saber que cada documento XML deve obedecer a duas regras básicas para ser válido:
- Deve existir apenas um elemento raiz (que contenha todos os outros elementos, se houver).
- Cada etiqueta de abertura deve ter uma etiqueta de fecho.
Validação sintática de documentos XML
Podemos descobrir se um documento XML é sintaticamente válido com a ajuda do nosso editor de texto (VS Code com a extensão XML Complete). Também é possível encontrar aplicações de validação gratuitas na Internet como, por exemplo, https://codebeautify.org/xmlvalidator ou https://www.xmlvalidation.com.
Se copiarmos e colarmos o último exemplo neste último link (ou se carregarmos o ficheiro correspondente), teremos o seguinte erro:
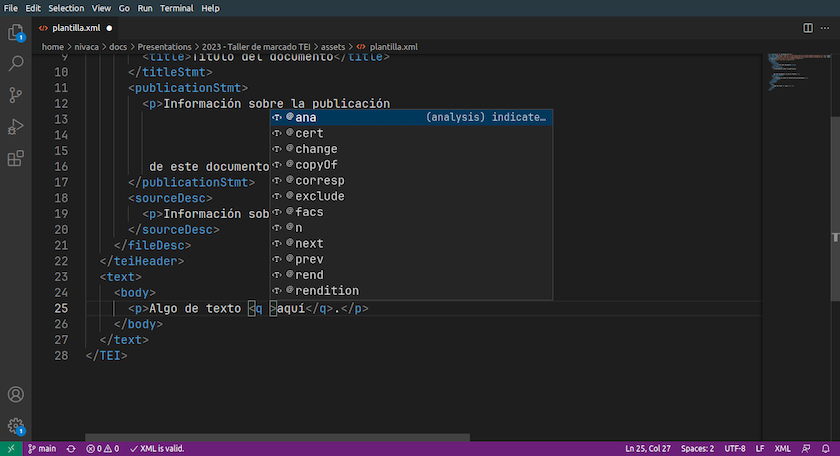
Validação online do último exemplo
O que é a TEI?
A XML é uma linguagem tão geral e abstrata que é totalmente indiferente ao seu conteúdo. Pode ser usada, por exemplo, para descrever coisas tão díspares quanto um texto grego clássico do século VIII a. C. ou a mensagem que um termóstato inteligente envia para uma aplicação de um smartphone usado para o controlar.
A TEI é uma implementação particular da XML. Ou seja, é uma série de regras que determinam quais os elementos e quais os atributos são permitidos num documento de um determinado tipo. Mais precisamente, a TEI é uma linguagem de marcação para codificar textos de todo o tipo, tendo como objetivo que estes possam ser processados por um computador para que possam ser analisados, transformados, reproduzidos e armazenados, dependendo das necessidades e interesses dos usuários (tanto os de carne e osso como os computacionais). É por isso que podemos dizer que a TEI está no coração das humanidades digitais (ou pelo menos num de seus corações!). É um padrão de trabalho computacional com uma classe de objetos tradicionalmente central para as humanidades: os textos. Assim, enquanto a XML não se importa se os elementos nm documento descrevem textos (ou as propriedades do texto), a TEI foi desenhada exclusivamente para trabalhar com eles.
Os tipos de elementos e atributos permitidos na TEI, e as relações existentes entre eles, são especificados pelas regras do TEI. Por exemplo, se quisermos codificar um poema, podemos utilizar o elemento <lg> (de line group, “grupo de linhas”) da TEI. As regras da TEI determinam que tipos de atributos esse elemento pode ter e que elementos podem, por sua vez, conter ou ser contidos por ele. A TEI determina que cada elemento <lg> deve ter, pelo menos, um elemento <l> (de line, “linha”).
Como ilustração, examinemos as primeiras três linhas do soneto Hiato de Manuel Bandeira (abaixo em texto simples):
És na minha vida como um luminoso
Poema que se lê comovidamente
Entre sorrisos e lágrimas de gozo...
Podemos propor a seguinte codificação na TEI:
<lg met="11,11,11" rhyme="abba">
<l n="1">És na minha vida como um luminoso</l>
<l n="2">Poema que se lê comovidamente</l>
<l n="3">Entre sorrisos e lágrimas de gozo...</l>
</lg>
Neste caso, utilizamos o atributo @rhyme do elemento <lg> para codificar o tipo de rima do trecho; o atributo @met para indicar o tipo de métrica do primeiro verso (hendecassílabo) (isto teria de ser feito em cada um dos versos, ainda que para clareza do código o tenhamos feito apenas no primeiro); e finalmente o atributo @n para indicar o número do verso dentro do grupo.
Comparar o texto simples do fragmento do soneto com a sua codificação permite começar a ver as vantagens da TEI como uma linguagem de marcação de textos. Não só fica explicitamente declarado que da segunda a quarta linha (no código acima) são versos de um poema, mas que elas têm um tipo de rima e métrica. Uma vez codificado todo o poema, ou todos os poemas de uma coleção, podemos, por exemplo, usar um software para realizar buscas estruturadas, de modo que este devolva todos os poemas com um certo tipo de rima ou todas as linhas que têm um certo tipo de métrica. Ou podemos usar (ou criar) um aplicativo para determinar quantos versos dos sonetos de Bandeira - se houver - têm métrica imperfeita. Também podemos comparar as diferentes versões (os “testemunhadores” e as “testemunhas” manuscritas e impressas) dos sonetos, visando fazer uma edição crítica dos mesmos.
Agora, tudo isso e muito mais só é possível em virtude do fato de termos explicitado, graças à TEI, o conteúdo desses sonetos. Se tivéssemos apenas o texto simples deles, seria tecnicamente impossível tirar proveito das ferramentas computacionais projetadas para editá-los, transformá-los, visualizá-los, analisá-los ou publicá-los.
Um documento mínimo de TEI
Examinemos agora o seguinte documento mínimo de TEI:
<?xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Título</title>
</titleStmt>
<publicationStmt>
<p>Informação da publicação</p>
</publicationStmt>
<sourceDesc>
<p>Informação sobre a fonte</p>
</sourceDesc>
</fileDesc>
</teiHeader>
<text>
<body>
<p>Algum texto...</p>
</body>
</text>
</TEI>
A primeira linha é a já tradicional declaração do documento XML.
A segunda linha contém o elemento principal ou “raiz” deste documento: o elemento <TEI>. O atributo @xmlns com o valor http://www.tei-c.org/ns/1.0 simplesmente declara que todos os elementos e atributos filhos do elemento <TEI> pertencem ao “namespace” do TEI (representado aqui pela URL). Não teremos de nos preocupar mais com isso a partir de agora.
O interessante vem a seguir nas linhas três e dezesseis que contêm, respectivamente, os dois filhos imediatos do elemento raiz:
Vejamos agora em que consistem estes dois elementos.
O elemento <teiHeader>
Todos os metadados do documento estão codificados no elemento <teiHeader>: o título, autoras ou autores, onde, quando e como foi publicado, a sua fonte, de onde a fonte foi retirada, e assim por diante. É comum que as pessoas que começam a codificar texto em TEI passem por cima destas informações, preenchendo estes campos com dados genéricos e incompletos. No entanto, as informações no <teiHeader> são essenciais para a tarefa do codificador, pois servem para identificar com precisão o texto codificado.
O <teiHeader> deve conter pelo menos um elemento chamado <fileDesc> (de file description ou descrição do arquivo) que, por sua vez, contém três elementos filhos:
<titleStmt>(de title statement ou enunciado de título): a informação sobre o título do documento (dentro do elemento<title>); opcionalmente também pode incluir dados sobre o autor ou autores (dentro do elemento<author>)<publicationStmt>(de publication statement ou enunciado de publicação): a informação sobre como o documento é publicado ou disponibilizado (ou seja, o próprio documento TEI, não a sua fonte). Nesse sentido, é análogo às informações da editora/impressora na folha de rostro de um livro. Pode ser um parágrafo descritivo (dentro do elemento de parágrafo genérico<p>) ou pode estar estruturada em um ou vários campos dentro dos seguintes elementos:<address>: o endereço postal de quem edita/codifica<date>: a data de publicação do documento<pubPlace>: o local de publicação do documento<publisher>: a pessoa que edita/codifica o documento<ref>(ou também<ptr>): uma referência externa (URL) onde fica disponível o documento
<sourceDesc>(de source description ou descrição da fonte): a informação sobre a fonte da qual é tirado o texto a ser codificado. Pode ser um parágrafo descritivo (dentro do elemento de parágrafo genérico,<p>). Também pode estar estruturada de várias maneiras. Por exemplo, pode ter um elemento<bibl>, que inclui uma referência bibliográfica não-estruturada (p. ex.<bibl>Machado de Assis, "Memórias Pósthumas de Braz Cubas", Rio de Janeiro: Typographia Nacional , 1881</bibl>); ou pode conter uma referência estruturada do elemento<biblStruct>que, por sua vez, contém outros elementos relevantes
Suponha que queremos codificar as Memórias Pósthumas de Braz Cubas de Machado de Assis, a partir dessa edição disponível gratuitamente no Gutenberg Project. O <teiHeader> do nosso documento TEI poderia muito bem ser o seguinte:
<teiHeader>
<fileDesc>
<titleStmt>
<title>Memórias Pósthumas de Braz Cubas</title>
<author>Machado de Assis</author>
</titleStmt>
<publicationStmt>
<p>
Codificado em TEI por NOME em DATA.
Disponível em LINK_PARA_TEXTO_CODIFICADO
</p>
</publicationStmt>
<sourceDesc>
<p>
Texto retirado de:
Machado de Assis, "Memórias Pósthumas de Braz Cubas". Rio de Janeiro: Typographia Nacional, 1881.
Disponível em https://www.gutenberg.org/ebooks/54829
</p>
</sourceDesc>
</fileDesc>
</teiHeader>
Esta é a informação mínima para identificar o documento codificado. Informa sobre o título e o autor do texto, a pessoa responsável pela codificação e a fonte da qual o texto foi tirado.
Entretanto, é possível - e às vezes desejável - especificar os metadados do documento com mais detalhes. Por exemplo, considere esta outra versão do <teiHeader> para o mesmo texto:
<teiHeader>
<fileDesc>
<titleStmt>
<title>Memórias Pósthumas de Braz Cubas</title>
<author>Machado de Assis</author>
</titleStmt>
<publicationStmt>
<publisher>NOME</publisher>
<pubPlace>LOCAL_E_PAÍS</pubPlace>
<date>2021</date>
<availability>
<p>Esta é una obra de acesso aberto licenciada sob uma licença Creative Commons Attribution 4.0 International.</p>
</availability>
<ref target="LINK_PARA_TEXTO_CODIFICADO"/>
</publicationStmt>
<sourceDesc>
<biblStruct>
<monogr>
<author>Machado de Assis</author>
<editor></editor>
<title>Memórias Pósthumas de Braz Cubas</title>
<edition>1</edition>
<imprint>
<publisher>Typographia Nacional</publisher>
<pubPlace>Rio de Janeiro</pubPlace>
<date>1881</date>
</imprint>
</monogr>
<ref target="https://www.gutenberg.org/ebooks/54829"/>
</biblStruct>
</sourceDesc>
</fileDesc>
</teiHeader>
A decisão sobre a abrangência das informações no <teiHeader> depende da sua disponibilidade, e atende os propósitos de codificação e os interesses do codificador/editor. Agora bem, mesmo que os metadados contidos no <teiHeader> de um documento TEI não apareçam literal e necessariamente no texto codificado, não significa que sejam irrelevantes para o processo de codificação, edição e eventual transformação. Na realidade, na medida em que um <teiHeader> seja seja codificado de forma correta e exaustiva, as informações contidas no documento poderão ser extraídas e transformadas.
Por exemplo, se fosse importante para nós distinguirmos entre as diferentes edições e impressões de Memórias Pósthumas de Braz Cubas, as informações dos diferentes documentos transcritos contidas no <teiHeader> seriam suficientes para discriminá-los automaticamente. Na realidade, poderíamos aproveitar os elementos <edição> e <impressão> para esse fim, e com a ajuda de tecnologias como XSLT, XPath e XQuery poderíamos localizar, extrair e processar toda a informação.
Em conclusão, quanto mais completa e minuciosamente os metadados dos textos forem codificados no <teiHeader> de nossos documentos TEI, mais controle teremos sobre sua identidade e natureza.
O elemento <text>
Como vimos acima no documento mínimo, <text> é o segundo filho de <TEI>. Este contém todo o texto do documento propriamente dito. Conforme a documentação TEI, o <text> pode conter vários elementos nos quais o texto objeto vai ser estruturado:
Elementos possíveis de <text>
O mais importante destes elementos é <body>, que contém o corpo principal do texto. Entretanto, outros elementos importantes filhos de <text> são <front>, que contém o frontmatter (páginas preliminares) de um texto (introdução, prefácio, etc.), e <back>, que contém o backmatter (páginas finais, anexos, índices, etc.).
O elemento <body> pode, por sua vez, conter muitos outros elementos:
Elementos possíveis de <body>
Embora todas estas possibilidades possam nos sobrecarregar à primeira vista, devemos lembrar que normalmente um texto é dividido naturalmente em secções ou partes constitutivas. É recomendável, dessa maneira, usar o elemento <div> para cada uma das partes e usar atributos como @type ou @n para qualificar as suas diferentes classes e posições no texto (p. ex. <div n="3" type="subsecção">...</div>).
Se o nosso texto for curto ou simples, podemos usar um <div> unicamente. Por exemplo:
<text>
<body>
<div>
<!-- aqui ficaria todo nosso texto -->
</div>
</body>
</text>
Mas se o nosso texto for mais complexo, utilizaremos vários elementos <div>:
<text>
<body>
<div>
<!-- aqui ficaria a primeira secção ou divisão -->
</div>
<div>
<!-- aqui ficaria a segunda secção ou divisão -->
</div>
<!-- etc. -->
</body>
</text>
A estrutura do nosso documento TEI deve, em princípio, ter semelhança com a estrutura do texto objeto, isto é, o texto que queremos codificar. Dessa forma, se o nosso objeto está dividido em capítulos, e estes se dividem em seções ou apartados e, por sua vez, estes em parágrafos, o recomendável é que repliquemos essa mesma estrutura no documento TEI.
Para os capítulos e secções podemos usar o elemento <div> e para os parágrafos o elemento <p>.
Vejamos, por exemplo, o seguinte esquema:
<text>
<body>
<div type="capítulo" n="1">
<!-- este é o primeiro capítulo -->
<div type="secção" n="1">
<!-- esta é a primeira secção -->
<p>
<!-- este é o primeiro parágrafo -->
</p>
<p>
<!-- este é o segundo parágrafo -->
</p>
<!-- ... -->
</div>
</div>
<!-- ... -->
</body>
</text>
Embora a TEI nos permita codificar exaustivamente muitos dos aspectos e propriedades de um texto, às vezes não estamos interessados em todos eles. Além disso, o processo de codificação pode ser desnecessariamente demorado se codificarmos elementos dos quais nunca tiraremos vantagem numa eventual transformação. Por exemplo, se estamos codificando o texto de uma edição impressa, pode acontecer que as divisões de linha nos parágrafos não sejam relevantes para nossa codificação.
Nesse caso, podemos ignorá-las e simplesmente ficar com as divisões de parágrafos, sem ir além delas. Ou podemos ser tentados a codificar sistematicamente todas as datas e nomes de lugares (com os elementos <date> e <placeName>, respectivamente) que aparecem no nosso texto objeto, mesmo que nunca os utilizemos mais tarde. Fazer isso não é um erro, é claro, mas podemos perder tempo valioso ao fazê-lo.
Em resumo, poderíamos formular a “regra de ouro” da codificação da seguinte forma: codificar todos e somente aqueles elementos que possuem um certo significado para nós, considerando que eventualmente poderemos usá-los para fins específicos.
Conclusões
Nesta primeira parte da lição, aprendeu:
- O que significa codificar um texto
- O que são documentos XML e XML-TEI
Na segunda parte, a ser publicada em breve, verá em detalhe dois exemplos de codificação de texto.
Nota de tradução: para a versão em português foi usado o texto Memórias Póstumas de Brás Cubas de Machado de Assis e o poema Hiato de Manuel Bandeira, mantendo o tipo de exercícios e o código da lição original.
Referências recomendadas
-
A documentação completa do TEI (as TEI Guidelines) está disponível em o site do consórcio. Embora esteja disponível em vários idiomas, só está completa em inglês.
-
Uma boa introdução ao TEI é o livro What Is the Text Encoding Initiative de Lou Burnard, disponível gratuitamente online.
-
Um bom tutorial para XML está disponível em: https://www.w3schools.com/xml/.
-
O consórcio TEI também oferece uma boa introdução ao XML.
-
A documentação XML oficial está disponível no site do consórcio W3C. Documentação para toda a família XSL (incluindo XSLT) também está disponível.
-
A Fundação Mozilla também fornece uma boa página sobre XSLT e tecnologias relacionadas (em espanhol) e (em inglês).
-
A página TTHUB contém uma excelente “Introducción a la Text Encoding Initiative” de Susanna Allés Torrent (2019).
-
Uma lição introdutória de Programming Historian sobre XML e as transformações XSL é Transformação de dados com XML e XSL para reutilização, de M. H. Beals.