
Contenidos
Introducción
Uno de los problemas centrales de las humanidades digitales ha sido el trabajo con y sobre textos: su captura (digitalización), reconocimiento, transcripción, codificación, procesamiento, transformación y análisis. En esta lección nos centraremos exclusivamente en la codificación de textos, es decir, en su categorización por medio de etiquetas (tags).
Un ejemplo puede ayudar a aclarar esta idea. Supongamos que tenemos un documento impreso que hemos digitalizado previamente. Tenemos las imágenes digitalizadas de sus páginas y, con ayuda de un software de reconocimiento óptico de caracteres (OCR, en inglés), extraemos el texto contenido en ellas. Este texto es lo que suele llamarse texto plano (o texto digitalizado), es decir, el texto sin formato alguno (sin cursivas, negritas, etc.) ni ninguna otra estructuración semántica.
Aunque parezca extraño, el texto plano carece completamente de contenido. Para un computador es solo una larga cadena de caracteres (incluyendo puntuación, espacios en blanco y saltos de línea, etc.) en alguna codificación (por ejemplo UTF-8 o ASCII) de algún alfabeto (por ejemplo latino, griego o cirílico). Somos nosotros quienes, cuando lo leemos, identificamos palabras (en una o varias lenguas), líneas, párrafos, etcétera. Somos nosotros quienes identificamos asimismo nombres de personas y de lugares, títulos de libros y artículos, fechas, citas, epígrafes, referencias cruzadas (internas y externas), notas a pie de página y notas al final del texto. Pero, de nuevo, el computador es completamente “ignorante” con respecto a dichas estructuras textuales en un texto plano sin procesar o codificar.
Sin asistencia humana, por ejemplo, por medio de codificación TEI (Text Encoding Initiative), el computador no puede “entender” o detectar contenido alguno en el texto plano. Eso quiere decir, entre otras cosas, que no podemos hacer búsquedas estructuradas sobre ese texto (por ejemplo de nombres de personas, lugares y fechas), ni podemos extraer y procesar sistemáticamente dicha información, sin antes haberle indicado al computador qué cadenas de caracteres corresponden a qué estructuras semánticas: por ejemplo, que este es un nombre propio de persona, aquel otro nombre de persona se refiere a la misma persona que este, este es un nombre de lugar, esta es una nota al margen hecha por una tercera persona, o que este párrafo pertenece a esta sección del texto. Codificar el texto es indicar (por medio de etiquetas y otros recursos) que ciertas cadenas de texto plano tienen determinada significación. Y esa es la diferencia entre texto plano y texto semánticamente estructurado.
Hay muchas formas de codificar un texto. Por ejemplo, podemos encerrar entre asteriscos simples los nombres propios de personas: *Simón Bolívar*, *Soledad Acosta*, etc. Y entre asteriscos dobles los de lugares: **Bogotá**, **Framingham**, etc. Podemos también usar guiones bajos para indicar los nombres de obras y de libros: _La divina comedia_, _Cien años de soledad_, etc. Estos signos sirven para etiquetar o marcar el texto que encierran, para así identificar en el texto un determinado contenido. Como es fácil de imaginar, las posibilidades de codificación son casi infinitas.
En esta lección aprenderás a codificar textos usando un lenguaje de computador especialmente diseñado para ello: TEI.
Software que usaremos
Cualquier editor de texto plano (en formato .txt) nos servirá para hacer todo lo que necesitemos en esta lección: el Bloc de Notas (Notepad) de Windows, por ejemplo, es perfectamente adecuado para ello. Sin embargo, hay otros editores de texto que ofrecen herramientas o funcionalidades diseñadas para facilitar el trabajo con XML (Extensible Markup Language) e incluso con TEI. Uno de los más recomendados actualmente es Oxygen XML Editor, disponible para Windows, MacOS y Linux. Sin embargo, no es un software gratuito (la licencia académica cuesta unos $100 USD) ni de código abierto, por lo que no lo usaremos en esta lección.
Para esta lección usaremos el editor Visual Studio Code (VS Code, más brevemente), creado por Microsoft y mantenido actualmente por una gran comunidad de programadores de software libre. Es una aplicación completamente gratuita y de código abierto, disponible para Windows, MacOS y Linux.
Descarga la versión más reciente de VS Code en el enlace https://code.visualstudio.com/ e instálala en tu computador. Ábrelo y verás una pantalla como la siguiente:
Vista inicial de VS Code
Ahora instalaremos una extensión de VS Code para trabajar más fácilmente con documentos XML y TEI-XML: Scholarly XML.
Para ello haz clic en el botón de extensiones en la barra lateral de herramientas, a la izquierda en la ventana principal:
Extensiones de VS Code
Escribe Scholarly XML en el campo de búsqueda:
Búsqueda de una extensión en VS Code
Finalmente haz clic en “Install”:
Instalar Scholarly XML en VS Code
Esta extensión nos permite hacer varias cosas con el código:
Primero, seleccionar cualquier texto en un documento XML, presionar un atajo de teclado y encerrar automáticamente el texto seleccionado dentro de un elemento XML. Cuando presionamos Ctrl+E (en Windows o Linux) o Cmd+E (en MacOS), VS Code abre una ventanita con la instrucción Enter Abbreviation (Press Enter to confirm or Escape to cancel) (“Introduce la abreviatura (Presiona Intro para confirmar o Escape para cancelar)”). A continuación escribimos el nombre del elemento y presionamos la tecla Intro. El editor entonces encerrará el texto seleccionado entre una etiqueta de apertura y otra de cierre con el nombre del elemento. Cuando trabajamos con XML, automatizar la introducción las etiquetas de apertura y de cierre nos puedo ahorrar mucho tiempo, a la vez que disminuye la probabilidad de que introduzcamos errores de tipográficos involuntarios en el código.
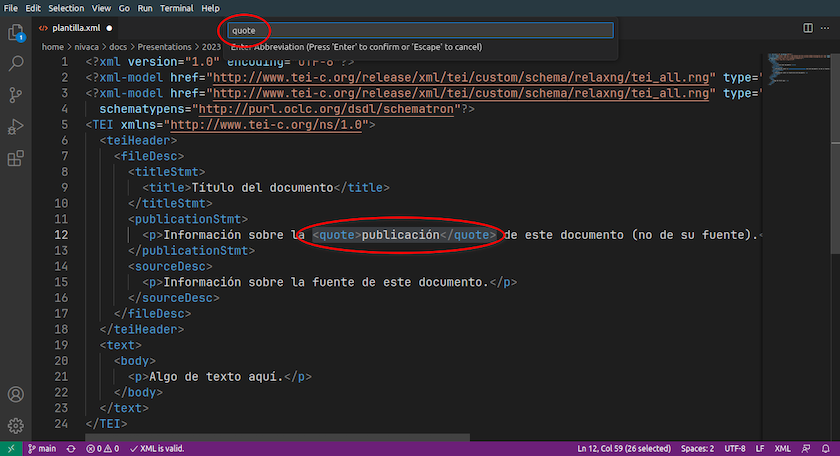
Introducir automáticamente un elemento XML en VS Code
Segundo, determinar si un documento está bien formado según la sintaxis de XML y además si es válido semánticamente con respecto a un esquema de validación de tipo RELAX NG, por ejemplo, el esquema tei-all de TEI, que contiene la totalidad de los módulos de marcado para todos los tipos de documentos previstos por el consorcio TEI. (Más abajo explicaremos los conceptos de validez sintáctica y semántica.) La extensión hace las dos cosas automáticamente.
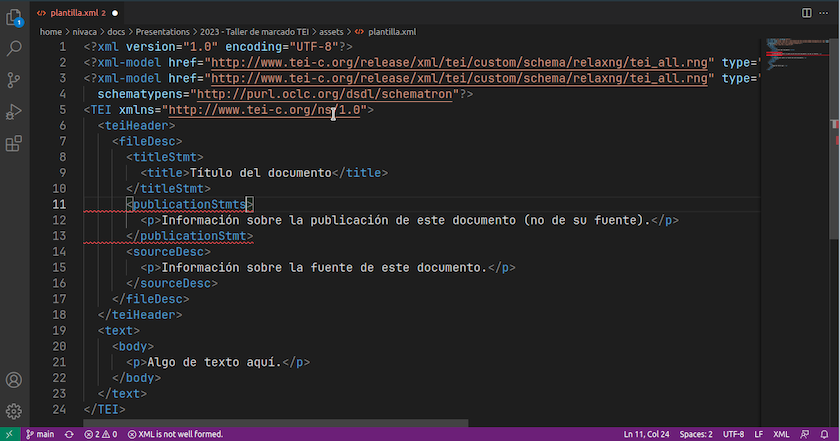
Detectar errores de XML en VS Code
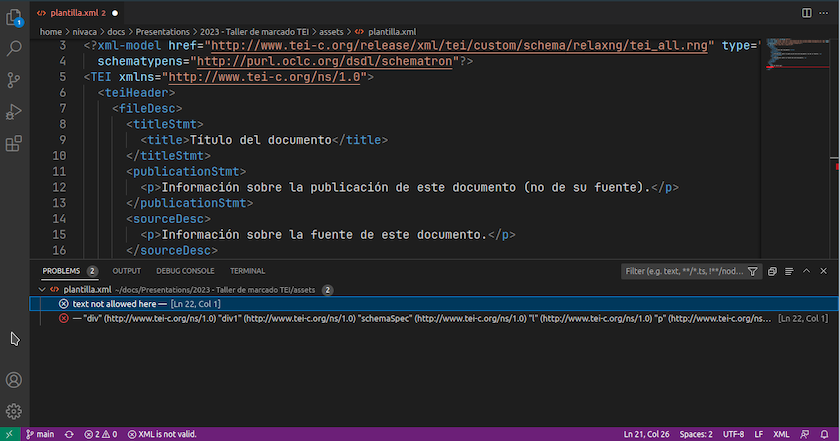
Detectar errores de XML en VS Code
Ahora bien, para realizar el segundo tipo de validación, es preciso que en el documento se especifique el URI del esquema en una declaración <?xml-model> al principio del documento, por ejemplo así:
<?xml-model href="http://www.tei-c.org/release/xml/tei/custom/schema/relaxng/tei_all.rng" type="application/xml" schematypens="http://relaxng.org/ns/structure/1.0"?>
<?xml-model href="http://www.tei-c.org/release/xml/tei/custom/schema/relaxng/tei_all.rng" type="application/xml"
schematypens="http://purl.oclc.org/dsdl/schematron"?>
Puedes bajar una plantilla básica de un documento TEI-XML aquí, con estas líneas ya incluidas.
Tercero, la extensión ofrece también una herramientas para autocompletar el código de XML a partir del esquema de validación RELAX NG. Por ejemplo, si hemos introducido en el documento un elemento <q> (para marcar un texto entrecomillado, por ejemplo una cita), podemos presionar la barra espaciador luego del q de la etiqueta de apertura y VS Code nos mostrará una lista de atributos posibles para seleccionar en el menú:
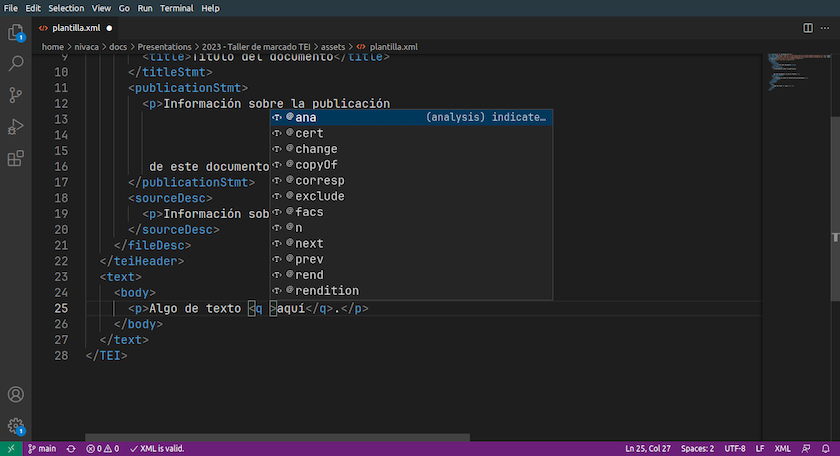
Menú de autocompleción de código de XML en VS Code
Ahora bien, para poder usar esta u otras extensiones de VS Code es necesario que el editor no esté en modo restringido (Restricted Mode), como nos aparece en esta ventana:
Aviso de modo restringido en VS Code
Este modo evita que las extensiones o el código del documento ejecuten instrucciones que puedan dañar nuestro sistema. Puesto que estamos trabajando con nuestros documento y la extensión recomendada es altamente confiable, podemos desactivar el modo restringido haciendo clic en el hipervínculo de arriba que dice Manage (“Administrar”) y luego clic en el botón Trust (“Confiar”), así:
Salir del modo restringido en VS Code
Ahora que hemos configurado nuestro editor, podemos empezar a trabajar en TEI-XML.
Visualización vs. categorización
Quienes estén familiarizados con el lenguaje de marcado Markdown —hoy en día habitual en foros técnicos en Internet, así como en GitHub, GitLab y otros repositorios de código— reconocerán seguramente el uso de elementos tales como asteriscos (*), guiones bajos (_) y numerales (#) para hacer que el texto aparezca de cierto modo en el navegador. Por ejemplo, un texto encerrado entre asteriscos simples será mostrado en cursivas y uno encerrado entre asteriscos dobles lo será en negritas. De hecho, el texto de esta lección está escrito en Markdown siguiendo esas convenciones.
Ese uso del marcado tiene como finalidad principal la visualización del texto, no su categorización. En otras palabras, las marcas o etiquetas de Markdown no indican que un texto sea de cierta categoría (por ejemplo, el nombre de una persona, de un lugar o de una obra), sino únicamente que el texto ha de ser visualizado o mostrado de cierto modo en un navegador o en otro medio.
Comprender la diferencia entre entre marcado de visualización (como el de Markdown) y marcado semántico (o estructural, como el que veremos a continuación en TEI) es crucial para entender el objetivo de la codificación de textos. Cuando marcamos un fragmento de texto para codificarlo, lo hacemos sin importarnos en principio cómo fue representado originalmente ni cómo pueda ser eventualmente representado en el futuro. Nos interesa únicamente la función semántica o estructural que un texto particular tenga. Por eso debemos procurar identificar con precisión las funciones o categorías de los textos, dejando de lado, en la medida de lo posible, el modo como son mostrados en el papel o la pantalla.
Aclaremos mejor esto volviendo a nuestro ejemplo inicial. Supongamos que en el texto digitalizado del que partimos los nombres propios aparecen siempre impresos en letra versalita, como en el siguiente fragmento:

Fragmento corto de texto digitalizado de Don Quijote
Como veremos a continuación, TEI nos permite codificar, por medio de una serie de etiquetas, el texto que queremos categorizar. Por ejemplo, podemos utilizar una etiqueta como <name> para demarcar los nombres propios contenidos en el texto, así:
Despidióse del cabrero <name>don Quijote</name> y, subiendo otra vez sobre <name>Rocinante</name>, mandó a <name>Sancho</name> que le siguiese, el cual lo hizo, con su jumento, de muy mala gana.
Luego veremos en detalle qué es y cómo funciona una etiqueta (o más precisamente un elemento) en XML y TEI. Por ahora notemos que la etiqueta no significa que el texto haya sido representado originalmente en versalitas (o en ningún otro modo). Tan solo significa que el texto contenido en ella tiene la categoría de nombre propio, independientemente de cómo sea representado. De hecho, podemos codificar exhaustivamente un documento con cientos o miles de etiquetas, sin que ninguna de ellas aparezca al final en una eventual representación.
XML y TEI: hacia un estándar de codificación de textos
Desde los inicios de las humanidades digitales en los años sesenta, hubo muchas aproximaciones a la codificación de textos. Casi que cada proyecto de codificación tenía su propio estándar, lo que conducía a que los proyectos fueran incompatibles e intraducibles entre sí, entorpeciendo e incluso imposibilitando el trabajo colaborativo.
Para resolver ese problema, unos veinte años después se estableció un nuevo estándar de codificación de textos, convenido un gran número de investigadores e investigadoras de todo el mundo, especialmente de universidades anglosajonas: el Text Encoding Initiative (TEI).
TEI está a su vez construido sobre el lenguaje de marcado XML y es por ello que suele ser denominado a veces como “TEI-XML” (o también “XML/TEI”). Por su parte, XML (que es la sigla para “eXtensible Markup Language”) es un lenguaje de computador cuyo propósito es describir, por medio de una serie de marcas o etiquetas (tags en inglés), un determinado texto objeto. XML y TEI son lenguajes de marcado y en eso se diferencian de los lenguajes de programación como C, Python o Java, que describen objetos, funciones o procedimientos que han de ser ejecutados por un computador.
XML
En esta lección no entraremos en detalle en la sintaxis y el funcionamiento de XML. Recomendamos, por lo tanto, que el lector le dé una mirada a esta otra lección para más información sobre XML, así como a la bibliografía y referencias sugeridas al final de esta lección.
Por ahora solo debemos saber que todo documento XML debe cumplir dos reglas básicas para ser válido:
- Debe haber un solo elemento raíz (que contiene a todos los demás elementos, si los hay).
- Toda etiqueta de apertura debe tener una etiqueta de cierre.
Por suerte, los editores de código XML como VS Code (con la extensión Scholarly XML) u OxygenXML nos permiten detectar fácilmente errores de este tipo.
¿Qué es TEI?
XML es un lenguaje tan general y abstracto que es totalmente indiferente respecto de su contenido. Puede ser usado, por ejemplo, para describir cosas tan disímiles como un texto en griego clásico del siglo VIII a.C. y un mensaje que un termostato inteligente le envía a una aplicación de un smartphone usada para controlarlo.
TEI es una implementación particular de XML. Es decir, es una serie de reglas que determinan qué elementos y qué atributos son permitidos en un documento de cierto tipo. Más precisamente, TEI es un lenguaje de marcado para codificar textos de toda clase. Esto con el fin de que sean procesados por un computador, de modo que puedan ser analizados, transformados, reproducidos y almacenados, dependiendo de las necesidades e intereses de los usuarios (tanto los de carne y hueso como los computacionales). Es por eso que podemos decir que TEI está en el corazón de las humanidades digitales (¡o al menos en uno de sus corazones!). Es un estándar para trabajar computacionalmente con una clase de objetos tradicionalmente central a las humanidades: los textos. Así las cosas, mientras que a XML le es indiferente si los elementos de un documento describen textos (o propiedades de textos), TEI está diseñado exclusivamente para trabajar con ellos.
El tipo de elementos y atributos permisibles en TEI, y las relaciones existentes entre ellos, están especificados por las reglas de TEI. Por ejemplo, si queremos codificar un poema, podemos usar el elemento <lg> (de line group, “grupo de líneas”) de TEI. Las reglas de TEI determinan qué tipos de atributos puede tener ese elemento y qué elementos pueden, a su vez, contener o ser contenidos por él. TEI determina que todo elemento elemento <lg> debe tener al menos un elemento elemento <l> (de line, “línea”).
A modo de ilustración, examinemos los primeros cuatro versos del soneto Amor constante más allá de la muerte de Francisco de Quevedo (a continuación en texto plano):
Cerrar podrá mis ojos la postrera
sombra que me llevare el blanco día;
y podrá desatar esta alma mía
hora a su afán ansioso lisonjera;
Podemos proponer la siguiente codificación en TEI:
<lg met="11,11,11,11" rhyme="abba">
<l n="1">Cerrar podrá mis ojos la postrera</l>
<l n="2">sombra que me llevare el blanco día;</l>
<l n="3">y podrá desatar esta alma mía</l>
<l n="4">hora a su afán ansioso lisonjera;</l>
</lg>
En este caso, nos hemos valido del atributo @rhyme del elemento <lg>, para hacer codificar el tipo de rima del pasaje; del atributo @met para indicar el tipo de métrica del primer verso (endecasílabo) (esto tendríamos que hacerlo en cada uno de los versos, aunque por claridad del código lo hemos hecho solo en el primero); y finalmente el atributo @n para indicar el número del verso dentro el grupo.
La comparación entre el texto plano del fragmento del soneto con su codificación nos permite empezar a ver las ventajas de TEI como un lenguaje de marcado para textos. No solo queda explícitamente dicho que las líneas (en el código anterior) dos a la cinco son versos de un poema, sino que ellas tienen un tipo de rima y de métrica. Una vez codificado todo el poema, o todos los poemas de una colección, podemos ,por ejemplo, usar un software para realizar búsquedas estructuradas, de modo que nos arroje todos los poemas que tienen cierto tipo de rima o todas las líneas que tienen cierto tipo de métrica. O podemos usar (o crear) una aplicación para determinar cuántos versos de los sonetos de Quevedo —si los hay— tienen métrica imperfecta. O podemos comparar las distintas versiones (los “testigos” o “testimonios” manuscritos e impresos) de los sonetos, para realizar una edición crítica de ellos.
Ahora bien, todo eso y mucho más es posible solo en virtud de que hemos hecho explícito, gracias a TEI, el contenido de esos sonetos. Si solo tuviéramos el texto plano de ellos, sería técnicamente imposible aprovechar herramientas computacionales diseñadas para editar, transformar, visualizar, analizar o publicarlos.
Un documento mínimo de TEI
Examinemos ahora el siguiente documento mínimo de TEI:
<?xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Título</title>
</titleStmt>
<publicationStmt>
<p>Información de publicación</p>
</publicationStmt>
<sourceDesc>
<p>Información sobre la fuente</p>
</sourceDesc>
</fileDesc>
</teiHeader>
<text>
<body>
<p>Algún texto...</p>
</body>
</text>
</TEI>
La primera línea ya es la tradicional declaración del documento XML.
La segunda línea contiene el elemento principal o “raíz” de este documento: el elemento <TEI>. El atributo @xmlns con el valor http://www.tei-c.org/ns/1.0 simplemente declara que todos los elementos y atributos hijos del elemento <TEI> pertenencen al “namespace” de TEI (representado aquí por ese URL). Eso no tendrá que preocuparnos más en lo sucesivo.
Lo interesante viene luego en las líneas tres y dieciseis, que contienen respectivamente a los dos hijos inmediatos del elemento raíz:
Veamos ahora en qué consisten esos dos elementos.
El elemento <teiHeader>
Todos los metadatos del documento están codificados en el elemento <teiHeader>: el título, autores o autoras, dónde, cuándo y cómo fue publicado, su fuente, de dónde se tomó la fuente, etcétera. Es habitual que las personas que empiezan a codificar texto de TEI pasen de largo esa información, llenando estos campos con datos genéricos e incompletos. Sin embargo, la información del <teiHeader> es esencial a la tarea del codificador, pues sirve para identificar con toda precisión el texto codificado.
El <teiHeader> debe contener al menos un elemento llamado <fileDesc> (de file description o descripción del archivo), que a su vez contiene tres elementos hijos:
<titleStmt>(de title statement o enunciado de título): la información sobre el título del documento (dentro del elemento<title>); opcionalmente también puede incluir datos sobre el autor o autores (dentro del elemento<author>)<publicationStmt>(de publication statement o enunciado de publicación): la información de cómo está publicado o disponible el documento (esto es, el documento mismo TEI, no su fuente). En ese sentido es análogo a la información del editor/imprenta en el “imprint” o página legal de un libro. Puede ser un párrafo descriptivo (dentro del elemento genérico de párrafo<p>) o puede estar estructurada en uno o varios campos dentro los siguientes elementos:<address>: la dirección postal de quien edita/codifica<date>: la fecha de publicación del documento<pubPlace>: el lugar de publicación del documento<publisher>: la persona que edita/codifica el documento<ref>(o también<ptr>): una referencia externa (URL) donde está disponible el documento
<sourceDesc>(de source description o descripción de la fuente): la información sobre la fuente de la que se toma el texto que está siendo codificado. Puede ser un párrafo descriptivo (dentro del elemento genérico de párrafo,<p>). También puede estar estructurada de varias formas. Por ejemplo, puede tener un elemento<bibl>, que incluye una referencia bibliográfica sin estructurar (p. ej.<bibl>Miguel de Cervantes Saavedra, "Don Quijote de La Mancha", Madrid: Espasa-Calpe, 2010</bibl>); o puede contener una referencia estructurada en el elemento<biblStruct>que contiene a su vez otros elementos relevantes
Supongamos que queremos codificar el Quijote de Cervantes, partiendo de esta edición disponible gratuitamente en el Internet Archive. El <teiHeader> de nuestro documento TEI bien podría ser el siguiente:
<teiHeader>
<fileDesc>
<titleStmt>
<title>El ingenioso hidalgo Don Quijote de La Mancha</title>
<author>Miguel de Cervantes Saavedra</author>
</titleStmt>
<publicationStmt>
<p>
Codificado en TEI por Nicolás Vaughan en junio de 2021.
Disponible en https://github.com/nivaca/quijoteuno
</p>
</publicationStmt>
<sourceDesc>
<p>
Texto tomado de:
Miguel de Cervantes Saavedra, "El ingenioso hidalgo Don Quijote de La Mancha". Edición y notas de Francisco Rodríguez Marín. Madrid: Ediciones de La Lectura, 1911.
Disponible aquí: https://archive.org/details/donquijotedelama01cerv
</p>
</sourceDesc>
</fileDesc>
</teiHeader>
Esta es la información mínima para identificar el documento codificado. Nos dice el título y autor del texto, el responsable de la codificación y la fuente de donde se tomó dicho texto.
Sin embargo, es posible —y a veces es deseable— especificar más detalladamente los metadatos del documento. Por ejemplo, consideremos esta otra versión del <teiHeader> para el mismo texto:
<teiHeader>
<fileDesc>
<titleStmt>
<title>El ingenioso hidalgo Don Quijote de La Mancha</title>
<author>Miguel de Cervantes Saavedra</author>
</titleStmt>
<publicationStmt>
<publisher>Nicolás Vaughan</publisher>
<pubPlace>Bogotá, Colombia</pubPlace>
<date>2021</date>
<availability>
<p>Esta es una obra de acceso abierto licenciada bajo una licencia Creative Commons Attribution 4.0 International.</p>
</availability>
<ref target="https://github.com/nivaca/quijoteuno"/>
</publicationStmt>
<sourceDesc>
<biblStruct>
<monogr>
<author>Miguel de Cervantes Saavedra</author>
<editor>Francisco Rodríguez Marín</editor>
<title>El ingenioso hidalgo Don Quijote de La Manchat</title>
<edition>1</edition>
<imprint>
<publisher>Ediciones de La Lectura</publisher>
<pubPlace>Madrid</pubPlace>
<date>1911</date>
</imprint>
</monogr>
<ref target="https://archive.org/details/donquijotedelama01cerv"/>
</biblStruct>
</sourceDesc>
</fileDesc>
</teiHeader>
La decisión sobre la exhaustividad de la información en el <teiHeader> depende de su disponibilidad, y obedece a los fines de la codificación y a los intereses de quien codifica/edita. Ahora bien, aunque los metadatos contenidos en el <teiHeader> de un documento TEI no necesariamente aparezcan literalmente en el texto codificado, no por eso son irrelevantes para el proceso de codificación, edición y eventual transformación. De hecho, en la medida en que un <teiHeader> haya sido correcta y exhaustivamente codificado, en esa misma medida podrá extraerse y transformarse la información contenida en el documento.
Por ejemplo, si fuera importante para nosotros distinguir entre las diferentes ediciones e impresiones del Quijote, la información contenida en los <teiHeader> de los distintos documentos transcritos sería suficiente para poder discriminarlos automáticamente. En efecto, podríamos aprovechar los elementos <edition> e <imprint> para tal fin, y con ayuda de tecnologías como XSLT, XPath y XQuery podríamos ubicar, extraer y procesar toda esa información.
En conclusión, entre más completa y minuciosamente se codifiquen los metadatos de los textos en el <teiHeader> de nuestros documentos TEI, más control tendremos sobre su identidad y naturaleza.
El elemento <text>
Como vimos arriba en el documento mínimo, <text> es el segundo hijo de <TEI>. Contiene todo el texto del documento, propiamente hablando. De acuerdo con la documentación de TEI, <text> puede contener una serie de elementos en los que el texto objeto se ha de estructurar:

Elementos posibles de <text>
El más importante de estos elementos es <body>, que contiene el cuerpo principal del texto. Sin embargo, otros elementos importantes como hijos de <text> son <front>, que contiene el frontmatter (páginas preliminares) de un texto (introducción, prólogo, etc.), y <back>, que contiene el backmatter (páginas finales, apéndices, índices, etcétera).
Por su parte, el elemento <body> puede a su vez contener muchos otros elementos:

Elementos posibles de <body>
Aunque todas esas posibilidades puedan abrumarnos a primera vista, debemos recordar que un texto suele dividirse naturalmente en secciones o partes constitutivas. Es recomendable, entonces, usar el elemento <div> para cada una de ellas y usar atributos como @type o @n para cualificar sus diferentes clases y posición en el texto (p. ej. <div n="3" type="subsección">...</div>).
Si nuestro texto es corto o simple, podríamos usar un solo <div>. Por ejemplo:
<text>
<body>
<div>
<!-- aquí iría todo nuestro texto -->
</div>
</body>
</text>
Pero si nuestro texto es más complejo, usaríamos varios elementos <div>:
<text>
<body>
<div>
<!-- aquí iría la primera sección o división -->
</div>
<div>
<!-- aquí iría la segunda sección o división -->
</div>
<!-- etc. -->
</body>
</text>
La estructura de nuestro documento TEI debe en principio ser similar a la estructura del texto objeto, es decir, el texto que queremos codificar. Así pues, si nuestro texto objeto se divide en capítulos, y estos se dividen en secciones o apartados, y estos, a su vez, en párrafos, entonces lo recomendable es que repliquemos esa misma estructura en el documento TEI.
Para los capítulos y las secciones podemos usar el elemento <div> y para los párrafos el elemento <p>.
Veamos, por ejemplo, el siguiente esquema:
<text>
<body>
<div type="capítulo" n="1">
<!-- este es el primer capítulo -->
<div type="sección" n="1">
<!-- esta es la primera sección -->
<p>
<!-- este es el primer párrafo -->
</p>
<p>
<!-- este es el segundo párrafo -->
</p>
<!-- ... -->
</div>
</div>
<!-- ... -->
</body>
</text>
Aunque TEI nos permita codificar exhaustivamente muchos de los aspectos y propiedades de un texto, en ocasiones no nos interesan todos ellos. Es más, el proceso de codificación puede extenderse innecesariamente en el tiempo si codificamos elementos que nunca vamos a aprovechar en una eventual transformación. Por ejemplo, si estamos codificando el texto de una edición impresa, puede ocurrir que las divisiones de línea en los párrafos no sean relevantes para nuestra codificación.
En ese caso podemos ignorarlas y quedarnos solo con las divisiones de párrafo, sin descender más allá de ellas. O quizás sintamos la tentación de codificar sistemáticamente todas las fechas y los nombres de lugares (con los elementos <date> y <placeName>, respectivamente) que aparezcan en nuestro texto objeto, aun cuando nunca los aprovechemos posteriormente. Hacerlo no es un error, desde luego, pero quizás perdamos tiempo valioso en ello.
En suma, podríamos formular la “regla de oro” de la codificación así: codifiquemos todos y solo los elementos que tengan una determinada significación para nosotros, teniendo en cuenta que eventualmente los podremos aprovechar para fines concretos.
Conclusiones
En esta primera parte de la lección has aprendido:
- Qué significa códificar un texto
- Qué son los documentos XML y XML-TEI
En la segunda parte verás en detalle dos ejemplos de codificación de textos.
Referencias recomendadas
-
La documentación completa de TEI (los TEI Guidelines) está disponible en la página del consorcio. Si bien está dispónible en varios idiomas, solo está completa en inglés.
-
Una buena introducción a TEI es el libro ¿Qué es la iniciativa de codificación de textos? Cómo añadir marcado inteligente a los recursos digitales de Lou Burnard (Marsella: OpenEdition Press, 2012/2022) disponible gratuitamente en línea.
-
Un buen tutorial para XML está disponible en: https://www.w3schools.com/xml/.
-
El consorcio TEI también ofrece una buena introducción a XML.
-
La documentación oficial de XML está disponible en la página del consorcio W3C También está disponible la documentación para toda la familia XSL (incluido XSLT).
-
La Mozilla Foundation también ofrece una buena página sobre XSLT y tecnologías asociadas (en español) y (en inglés).
-
La página TTHUB contiene una excelente “Introducción a la Text Encoding Initiative” por Susanna Allés Torrent (2019).
-
Una lección introductoria de Programming Historian a XML y las transformaciones XSL es Transformación de datos con XML y XSL para su reutilización, de M. H. Beals.