
Contenidos
- Introducción
- ¿Qué es XML?
- ¿Qué es XSL?
- Algunos programas necesarios o recomendados
- Cómo elegir y preparar datos en XML
- Cómo crear y probar tus hojas de estilo XSL
- Cómo poblar los resultados de tus transformaciones
- Cómo seleccionar e imprimir valores
- Cómo ordenar resultados
- Cómo filtrar resultados
- Conclusión
- Posibles soluciones a los ejercicios
- Bibliografía recomendada
- Notas
Introducción
Imagina que, con un día de antelación, un compañero de trabajo te llama por teléfono pidiéndote que lo sustituyas en un seminario centrado en Relaciones de esclavos en el Nuevo Mundo. Decides recopilar una selección de fuentes primarias para trabajar en clase, encuentras algunas páginas web y algunos libros con buenos materiales, pero escanearlo todo o copiar y pegar la información en un documento nuevo conlleva demasiado tiempo; además, el estilo de la bibliografía difiere y las citas son inconsistentes, así que empiezas a preguntarte si reunir todo este material tiene sentido. Una página web te permite descargar una versión XML de todo el material, pero son tantos los registros y hay tantos metadatos que no es fácil encontrar rápidamente la información que deseas.
O quizás… has encontrado una edición antigua de Inscriptions of Roman Tripolitania (1952) y te gustaría hacer un análisis estadístico de la aparición de ciertas frases en determinados contextos. Por suerte, King’s College London ha publicado una versión digital del texto con imágenes, traducciones e información sobre la localización de las inscripciones. Puedes explorar el material con la función “Buscar en la página” en tu navegador, pero editar la información en el formato necesario para el análisis requiere tiempo.
Imagina ahora que estás empezando un proyecto nuevo consistente en el estudio de un catálogo de subastas de libros del siglo XVII; empiezas registrando los detalles de publicación y la lista de subastas en un documento Word o Excel. Un mes más tarde el vicerrector de tu universidad te invita a dar una charla. El decano de tu facultad sugiere que hagas unas diapositivas o notas para facilitar la comprensión del proyecto. Tienes ya algunas conclusiones preliminares, pero los datos están dispersos en varios lugares y unificar el formato de la información precisa más tiempo del que dispones.
En las tres situaciones descritas, conocer cómo funciona XML y XSL te habría ahorrado tiempo y esfuerzo. En este tutorial aprenderás a convertir un conjunto de datos históricos procedentes de una base de datos XML1 (ya sea un solo documento o varios documentos interconectados) en otros formatos más adecuados para presentar (tablas, listas) o exponer información (párrafos). Tanto si quieres filtrar información contenida en una base de datos como si quieres añadir encabezados o paginación, XSL ofrece a los historiadores la posibilidad de reconfigurar datos a fin de acomodarlos a los cambios de la investigación o a las necesidades de la publicación.
Este tutorial cubre los siguientes aspectos:
- Editores: herramientas necesarias para crear hojas de estilo XSL
- Procesadores: herramientas necesarias para aplicar las instrucciones de la hoja de estilo XSL a los archivos XML
- Elección y preparación de datos XML: cómo conectar la base de datos con las instrucciones de transformación XSL
El tutorial también sirve como guía para crear las transformaciones más comunes:
- Imprimir valores: cómo imprimir o presentar los datos
- repeticiones
for-each(en bucle): cómo presentar datos concretos en cada uno de los objetos o registros existentes - Ordenar resultados: cómo presentar los datos en un determinado orden
- Filtrar resultados: cómo seleccionar qué objetos o registros se quieren presentar
¿Qué es XML?
El Lenguaje de Marco Extensible (eXtensible Markup Language, abreviado generalmente como “XML”) es un método muy flexible de codificación y estructuración de datos. Al contrario que el Lenguaje de Marcado de Hipertexto (Hypertext Markup Language, abreviado como “HTML”), que tiene un vocabulario predeterminado, XML es extensible; es decir, puede expandirse para incluir las etiquetas necesarias para, por ejemplo, identificar tantas secciones y subsecciones como quieras.
Una base de datos puede componerse de uno o más documentos XML con una estructura básica. Cada sección del archivo está contenida en un elemento, es decir, una categoría o nombre con el que se identifica el tipo de datos manejados. Así pues, como si fueran Matrioshkas, cada nivel de elementos está contenido en otro.
El elemento <raíz> es precisamente eso: la raíz del documento, es decir, el elemento que contiene al resto de elementos y entidades; y cada uno de estos otros elementos contenidos en él se considera un hijo (child) suyo.
Análogamente, el elemento que contiene un elemento hijo se llama elemento padre (parent).
Por ejemplo:
<raíz>
<padre>
<hijo></hijo>
</padre>
</raíz>
(Nota que estos nombres —raíz, padre y hijo— son completamente arbitrarios. Pudimos haberlos llamado de cualquier otro modo. Lo importante aquí son las relaciones de continencia.)
Según las reglas de nuestra base de datos, los elementos pueden tener valores (textuales o numéricos) o bien un número determinado de elementos hijos.
<raíz>
<padre>
<hijo_1>valor</hijo_1>
<hijo_2>valor</hijo_2>
<hijo_3>valor</hijo_3>
</padre>
</raíz>
También pueden tener atributos, algo así como los metadatos del elemento. Los atributos ayudan a distinguir, por ejemplo, entre distintos tipos de valores sin tener que crear un nuevo tipo de elemento. Por ejemplo:
<raíz>
<nombre>
<apellido>García</last>
<nombre tipo="formal">Cristina</first>
<nombre tipo="informal">Cris</first>
</nombre>
</raíz>
Si tienes acceso a una base de datos XML, o si quieres almacenar datos en una, puedes utilizar XSL para ordenar, filtrar y presentar la información en (casi) todas las maneras imaginables. Por ejemplo, podrías abrir un archivo XML como Word (.docx) o Excel (.xslx), inspeccionarlo y, a continuación, eliminar la información añadida por Microsoft por defecto como la localización geográfica del creador del documento. Si quieres saber más sobre XML, te recomendamos leer una explicación más detallada sobre su estructura y uso en las humanidades en la página web de la Text Encoding Initiative.
¿Qué es XSL?
El Lenguaje de Hojas de Estilo Extensibles (eXtensible Stylesheet Language, abreviado como “XSL”) es el complemento natural de XML. En términos generales, proporciona instrucciones de procesamiento; en cierto modo, podríamos decir que XSL es análogo a las Hojas de Estilos en Cascada (Cascading Stylesheets, abreviado “CSS”) necesarias para presentar archivos HTML. Ambos lenguajes permiten transformar el texto plano en un formato de texto enriquecido, así como determinar su diseño y apariencia tanto en pantalla como impreso, sin tener que alterar los archivos originales. En un nivel más avanzado, también permiten ordenar y filtrar la información según un criterio concreto y crear o visualizar otros datos derivados a partir del archivo original.
Al separar los datos (XML) de las instrucciones de procesamiento (XSL), es posible refinar y modificar la presentación sin correr el riesgo de corromper la estructura de los archivos. Asimismo, podemos crear más de una hoja de estilo, de tal modo que se utilicen en función del objetivo para transformar un solo archivo fuente. En la práctica, esto significa que solo hay que actualizar los datos en un solo lugar y luego exportar distintos documentos.2
Algunos programas necesarios o recomendados
Editores de texto
Una de las ventajas de guardar datos en formato de texto plano es la facilidad de encontrar programas para visualizarlos y manipularlos. Para los propósitos de este tutorial, recomendamos utilizar el editor Visual Studio Code (que abreviaremos aquí como “VSCode”), aunque cualquier otro editor para programación puede servir para este tutorial (Notepad++, Atom, Emacs, Vim, etc.). VSCode es un editor gratuito y de código abierto. Mantiene el formato de texto plano, pero ofrece esquemas de colores distintos (verde sobre negro o marrón sobre beige), así como la función de esconder secciones o de comentar trozos de código para desactivarlo de manera temporal.
Para los usuarios más avanzados, que precisen realizar transformaciones de naturaleza compleja, se recomienda el uso del Oxygen XML Editor, si bien no es ni gratuito ni de código abierto.
Procesadores de XSL
Tras instalar VSCode en el sistema, hace falta instalar un procesador de XSL. Hay tres maneras de utilizar una hoja de estilo para transformar documentos XML:
- mediante un navegador web, que incluye un procesador XSL básico;
- mediante un procesador XSL incluido en un editor de XML; o
- mediante un procesador XSL independiente, que se corre desde la línea de comandos (o como un binding desde otro lenguaje de programación).
Hasta hace poco, la primera opción habría sido la más cómoda para aprender a trabajar con XSL. Sin embargo, los navegadores web han introducido restricciones de seguridad que hacen más difícil la transformación y el procesamiento de documentos XML locales. A fin de evitar este problema, podrías instalar complementos (addons) en Google Chrome o en Mozilla Firefox, o modificar directamente sus políticas de seguridad, para permitir que se corran las transformaciones. Sin embargo, esto tiene el inconveniente de hacer vulnerable el navegador a ciertos tipos de ataque informático. Por esta razón, evitaremos tomar este camino.
La segunda opción requiere la instalación de un editor especializado como Oxygen XML Editor o Altova XMLSpy. Sin embargo, puesto que no son editores gratuitos ni de código abierto, tampoco tomaremos este camino aquí.
Nos queda la tercera opción. Utilizaremos un procesador XSL gratuito y de código abierto llamado Saxon-HE, desarrollada por Michael Kay, uno de los especialistas más renombrados en el campo de XML, XSL, XPath, XQuery y tecnologías relacionadas. Saxon-HE es la versión “casera” (Home Edition) del procesador XSL Saxon. Saxonica, la casa de software de Michael Kay, también tiene para la venta ediciones del procesador Saxon mucho más potentes, adecuadas para proyectos gran envergadura y requisitos técnicos. Sin embargo, para nuestros fines —y de hecho para la gran mayoría de proyectos que requieren transformación de XML por medio de XSLT—, la edición Saxon-HE es más que suficiente.
Instalación de Saxon-HE
Saxon-HE es una aplicación de Java (de hecho, su nombre técnico completo es “SaxonJ-HE”). Eso significa que tu sistema operativo debe tener instalada una máquina virtual de Java (Java Virtual Machine o Java VM) para poder ejecutar Saxon-HE. La versión 11 de Saxon-HE, a la fecha la última, requiere por lo menos la versión Java SE 8 (JDK 1.8). Debes asegurarte de que esté instalada en tu sistema. Si no lo está, deberás instalarla tú mismo.
Para verificar si ya lo está, deberás usar la línea de comandos de tu sistema operativo. Para ello, abre tu emulador de terminal (en adelante, el “terminal”). Si estás en Microsoft Windows, puedes usar para ello o bien PowerShell o bien Git Bash. Si estás en Mac OS, puedes usar la aplicación Terminal.app (incluida por defecto en el sistema). Y si estás en Linux, puedes usar cualquiera de los terminales instalados por defecto.
Si estás en Windows, escribe ahora el siguiente comando en tu terminal:
java -version
En MacOS y Linux deberás escribir lo siguiente:
java --version
(fíjate en el doble guión --).
Si Java no está instalado, verás un mensaje de error como el siguiente:
java: The term 'java' is not recognized as a name of a cmdlet, function, script file, or executable program.
Check the spelling of the name, or if a path was included, verify that the path is correct and try again.
Pero si Java sí está instalado, obtendrás algo como esto:
java version "1.8.0_321"
Java(TM) SE Runtime Environment (build 1.8.0_321-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.321-b07, mixed mode)
Ahora bien, si la versión de Java es inferior a 1.8, o si simplemente no está instalado, deberás bajar e instalar la versión más reciente.
Para ello, ve a la página oficial de descargas de Java, https://www.java.com/es/download/, y baja la versión apropiada a nuestro sistema operativo.
Luego de instalarla, deberás reiniciar tu computador a fin de que las variables globales, que le informan al sistema dónde está el ejecutable de Java, hayan sido correctamente aplicadas.
Hecho esto, verifica de nuevo en la línea de comandos la versión de Java.
(Si ya has instalado la versión más reciente y con todo te aparece un mensaje de error indicando que no está instalada, deberás ajustar manualmente la variable PATH en tu sistema.
Para ello, revisa esta explicación.)
A continuación deberás descargar e instalar Saxon-HE.
Puede bajarlo del repositorio de SourceForge de Saxonica en esta dirección:
https://sourceforge.net/projects/saxon/files/Saxon-HE/11/Java/
Busca en la lista la versión más reciente.
(A la fecha de hoy esta es la versión 11.2.)
Descarga entonces el archivo SaxonHE11-2J.zip (o el más reciente) y descomprímelo en alguna carpeta de tu equipo. (No olvides dónde quedó.)
Ahora abre el terminal ahí mismo y ejecuta el siguiente comando (ten en cuenta que el nombre del ejecutable —saxon-he-11.2.jar— puede ser diferente para ti):
java -jar saxon-he-11.2.jar -t
(el parámetro -t le dice a Saxon que muestre su versión, así como otra información útil).
Por ejemplo, en Windows obtendrás:
PS C:\Users\usuario\Downloads\SaxonHE11-2J> java -jar saxon-he-11.2.jar -t
SaxonJ-HE 11.2 from Saxonica
Java version 1.8.0_321
No source file name
Usage: see http://www.saxonica.com/documentation/index.html#!using-xsl/commandline
Format: net.sf.saxon.Transform options params
Options available: -? -a -catalog -config -cr -diag -dtd -ea -expand -explain -export -ext -im -init -it -jit -json -l -lib -license -nogo -now -ns -o -opt -or -outval -p -quit -r -relocate -repeat -s -sa -scmin -strip -t -T -target -TB -threads -TJ -Tlevel -Tout -TP -traceout -tree -u -val -versionmsg -warnings -x -xi -xmlversion -xsd -xsdversion -xsiloc -xsl -y --?
Use -XYZ:? for details of option XYZ
Params:
param=value Set stylesheet string parameter
+param=filename Set stylesheet document parameter
?param=expression Set stylesheet parameter using XPath
!param=value Set serialization parameter
Ahora bien, dado que hemos descomprimido Saxon en una carpeta cualquiera (en C:\Users\usuario\Downloads, en nuestro ejemplo), solo podremos correr Saxon desde ahí.
Esto quiere decir que si estamos en otra carpeta en nuestro sistema, no podremos correr simplemente la instrucción java -jar saxon-he-11.2.jar para empezar a trabajar, puesto que el ejecutable saxon-he-11.2.jar no estará disponible ahí.
Esto no es necesariamente un problema.
Tan solo debes asegurarte de que los documentos XML y XSL que vayas a utilizar en tus transformaciones se encuentren siempre en la misma carpeta del ejecutable de Saxon.
Los ejemplos de código de línea de comandos que mostraremos aquí presupondrán que tal es el caso.3
Cómo elegir y preparar datos en XML
Para empezar a transformar un documento XML, primero es necesario obtener un archivo bien formado.4 Muchas bases de datos históricas disponibles en línea están modeladas en XML y, a veces, ofrecen sus datos en abierto. Para realizar este tutorial utilizaremos la base de datos Scissors and Paste.
La base de datos Scissors and Paste es una colección colaborativa, en continuo crecimiento, que contiene noticias procedentes de periódicos británicos e imperiales de los siglos XVIII y XIX. Los dos objetivos originales del proyecto eran facilitar la comparación de reediciones aparecidas en distintos periódicos y detectar temas similares en distintas publicaciones inglesas. Como muchas bases de datos XML, Scissors and Paste contiene datos (el texto), información sobre el formato (como las cursivas o las justificación de los párrafos) y metadatos.5 Los metadatos recogen la paginación de la noticia, la fecha de impresión, algunos detalles adicionales sobre el periódico, los temas principales y una lista con las personas y lugares mencionados.
En 2015, la base de datos alcanzó las 350 noticias con metadatos. Aunque quizás algunos investigadores quieran acceder a toda la información, la mayoría están interesados en una porción de los datos como el año de publicación o el tema principal de la noticia. Gracias al uso de XSL, es posible filtrar la información innecesaria u ordenar el material de un modo que sea más útil para investigar. Por ejemplo, como imaginábamos en la introducción, quizás nos sería de utilidad preparar una lista de publicaciones o bien una tabla con las fechas, los títulos y la paginación de las noticias humorísticas contenidas en la base de datos. En ambos casos, podemos obtener los resultados sin muchos problemas utilizando hojas de estilo XSL.
Para empezar a trabajar con la base de datos Scissors and Paste, descarga el archivo master.zip.
Descomprime el archivo ZIP para obtener la carpeta llamada scissorsandpaste-master.
Puedes descomprimirlo haciendo doble clic desde el explorador de archivos (en Windows, MacOS o Linux) o usando un programa especial para ello.
La carpeta contiene tres ítems principales:
- el archivo
TEISAP.XML: la base de datos XML - la carpeta
Transformers: una colección de hojas de estilo XSL - la carpeta
Outputs: archivos derivados de la base de datos mediante las hojas de estilo XSL
También encontrarás ahí los siguientes documentos:
- el archivo
Template_TEISAP.xml, una plantilla para los investigadores que quieran contribuir con más noticias - el archivo
README.mdcon información sobre la base de datos - el archivo
cite.mdque explica cómo citar la base de datos - el archivo
license.mdcon los términos de uso
Al finalizar este tutorial, te recomendamos explorar las otras hojas de estilo XSL contenidas en la carpeta Transformers y los archivos generados con ellas; de esta manera podrás descubrir otras posibilidades y crear archivos adaptados a tus necesidades.
La información contenida en el archivo TEISAP.XML ha sido codificada según las recomendaciones de la Text-Encoding Initiative (TEI), gran parte de la cual corresponde a los metadatos.
Sin embargo, en este tutorial utilizaremos una versión simplificada que cubre los datos históricos más importantes.6
Deberás descargar el archivo
SAPsimple_es.xml.
Haz una copia de él en la misma carpeta donde antes habías descomprimido el ejecutable de Saxon.
Ahora ábrelo en el editor VSCode y examina su contenido.
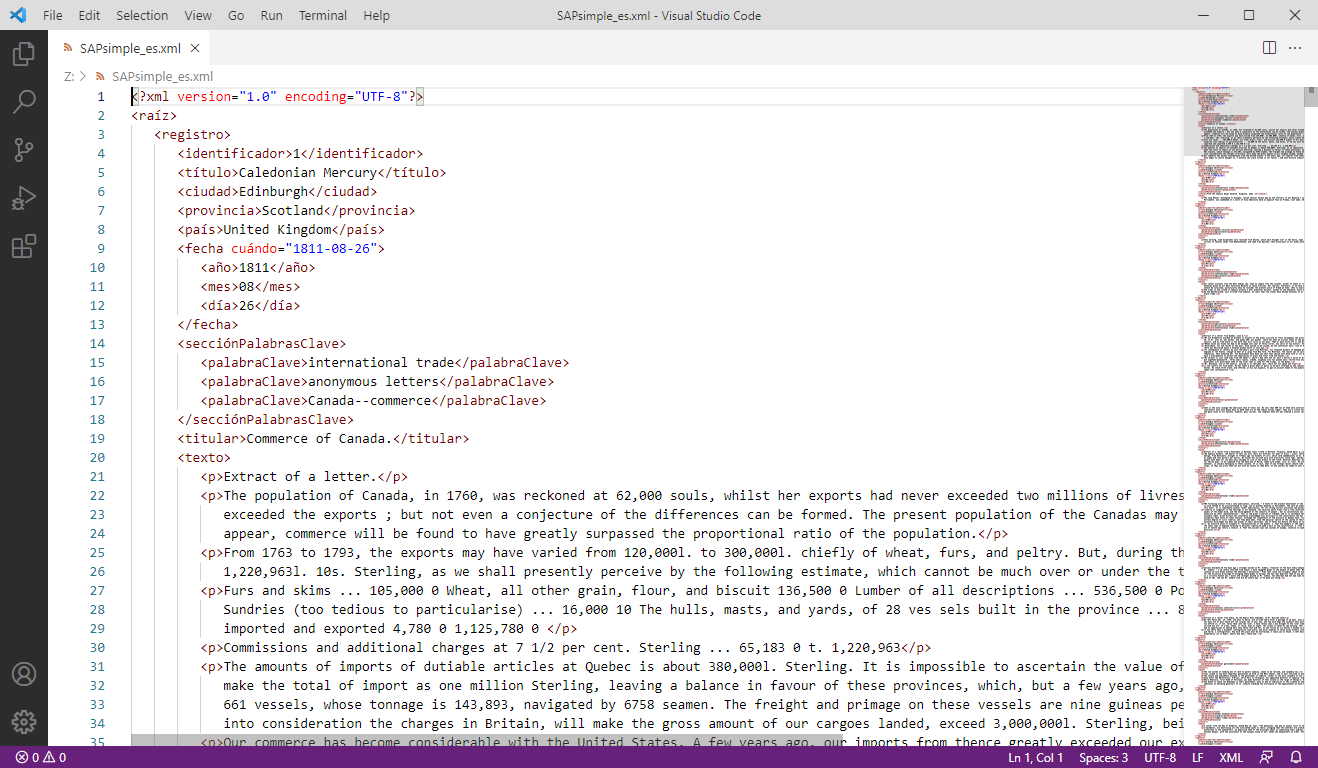
Figura 1: Una primera mirada a un documento XML
La primera línea del archivo XML es la siguiente:
<?xml version="1.0" encoding="UTF-8"?>
Esta línea indica la versión de XML utilizada (1.0) y el método de codificación del texto (UTF-8). En la segunda línea se encuentra la etiqueta de apertura <raíz> y, al final, la etiqueta de cierre </raíz>.
Esto quiere decir que <raíz>, como su nombre lo indica, es el elemento raíz que contiene todos los artículos de periódicos, cada uno etiquetado con un elemento <registro>. Antes de continuar, ubica la etiqueta de cierre </registro>.
Dentro de cada registro hay varios elementos hijos. La Text Encoding Initiative permite anidar centenares de elementos para modelar datos de muy distinta naturaleza. Además, la gracia de XML es que puedes dar nombre a tus elementos nuevos con bastante libertad. En la base de datos Scissors and Paste cada registro contiene los siguientes elementos:
<identificador>: número de identificación del registro<título>: título del periódico<ciudad>: ciudad del periódico<provincia>: provincia o región del periódico<país>: país del periódico<fecha>: fecha del artículo en formato ISO7<año>: año de la publicación<mes>: mes de la publicación<día>: día de la publicación<secciónPalabrasClave>: sección que contiene las palabras claves<palabraClave>: palabra clave que describe el artículo<titular>: titular del artículo (opcional)<texto>: sección que contiene el artículo<p>: párrafo de texto
Tal es, pues, la tipología de datos que utilizaremos para crear otros archivos derivados.
Cómo crear y probar tus hojas de estilo XSL
Ha llegado la hora de crear una archivo XSL para transformar el documento XML.
Para ello, abre el editor VSCode, crea un archivo nuevo en blanco y guárdalo con el nombre miestilo.xsl.
De nuevo, asegúrate de que el archivo se haya guardado en el mismo directorio que contiene tanto el archivo SAPsimple_es.xml como el ejecutable de Saxon.
La primeras tres líneas de tu archivo XSL serán las siguientes:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
La primera línea declara que este es un documento XML versión 1.0, codificado como UTF-8.
(¡Nota que un documento XSL es en últimas un tipo especial de documento XML!)
La segunda línea declara que se trata de la versión 1.0 de XSL y que el uso del espacio de nombres (namespace, en inglés) es el estándar establecido por el Consorcio World Wide Web, cuya URI (Uniform Resource Identifier) figura en la instrucción.
Finalmente, la tercera línea le indica al procesador XSL que queremos generar un archivo de texto plano.
(También podrías haber puesto xml o html, en lugar de text, para generar un documento XML o uno HTML, respectivamente.)
Cada vez que se abre un <elemento>, es necesario cerrarlo con la etiqueta </elemento> (comoquiera que se llame).
De lo contrario, se producirá un error de sintaxis y el archivo no será bien formado.
Por lo tanto, añade ahora la siguiente línea al final de tu hoja de estilos XSL:
</xsl:stylesheet>
La siguiente parte de tu hoja de estilo XSL será la plantilla principal —las instrucciones de formato— para tu output.
En una línea nueva, inmediatamente después de <xsl:output method="text"/>, escribe
<xsl:template match="/">
</xsl:template>
Dentro de estas dos etiquetas pondrás todas las instrucciones relativas al formato deseado.
El valor del atributo match (que puede traducirse como “hacer coincidir” o “emparejar”) contiene una barra /, porque queremos que la instrucción se aplique a todo el contenido del documento XML.
Podríamos haber escrito en su lugar raíz para indicar que solo queremos utilizar los datos contenidos en el elemento <raíz>.
Sin embargo, esto podría crear algunos problemas, así que es mejor que usemos la barra / en la instrucción principal.
Tras esto, tu archivo miestilo.xsl debería tener este aspecto:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
</xsl:template>
</xsl:stylesheet>
Guarda tu archivo. En lo que sigue, asegúrate de guardarlo antes de correr cualquier transformación nueva.
Dentro de la instrucción que acabamos de crear, escribe <xsl:value-of select="raíz"/>. No es necesario introducir una línea nueva, ni tampoco sangrarla a la derecha; pero si lo haces, será más fácil de leer.
Te habrás dado cuenta de que no hemos incluido una etiqueta de cierre </xsl:value-of>; esto se debe a que la instrucción <xsl:value-of select="raíz"/> no tiene contenido y ya está “auto-cerrada” gracias a la barra / situada al final.
Tu archivo miestilo.xsl deberá verse así:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:value-of select="raíz"/>
</xsl:template>
</xsl:stylesheet>
Ahora vamos a transformar nuestro documento XML SAPsimple_es.xml en texto plano, utilizando el la hoja de estilos XSL que acabamos de crear.
Para ello, ubícate en la línea de comandos y ejecuta esto:
java -jar saxon-he-11.2.jar -xsl:miestilo.xsl -s:SAPsimple_es.xml
Al ejecutar este comando, verás una gran cantidad de texto desplegarse en el terminal, tanto que no es fácil leerlo ahí mismo.
El parámetro -xsl: proporciona el nombre de la hoja de estilos XSL que será utilizada para transformar el documento XML, cuyo nombre es proporcionado por el parámetro -s: (de source, “fuente”).
Si quieres guardar el texto que Saxon ha arrojado, debes usar el parámetro -o: (de output, “salida”), seguido de un nombre de archivo, por ejemplo así:
java -jar saxon-he-11.2.jar -xsl:miestilo.xsl -s:SAPsimple_es.xml -o:salida.txt
(Ese será siempre el comando que debes correr en el terminal para transformar un XML por medio de una hoja de estilos XSLT. Deberás ejecutarlo cada vez que quieras realizar una transformación. En otras palabras, no bastará con que hagas cambios en tu hoja de estilos para que se produzca la transformación; siempre deberás ejecutar Saxon para llevarla a cabo.)
Ahora puedes abrir el archivo salida.txt en VSCode para inspeccionarlo. El resultado debería ser el texto con los saltos de línea existentes, pero sin los elementos XML, tal como se percibe en la siguiente imagen:
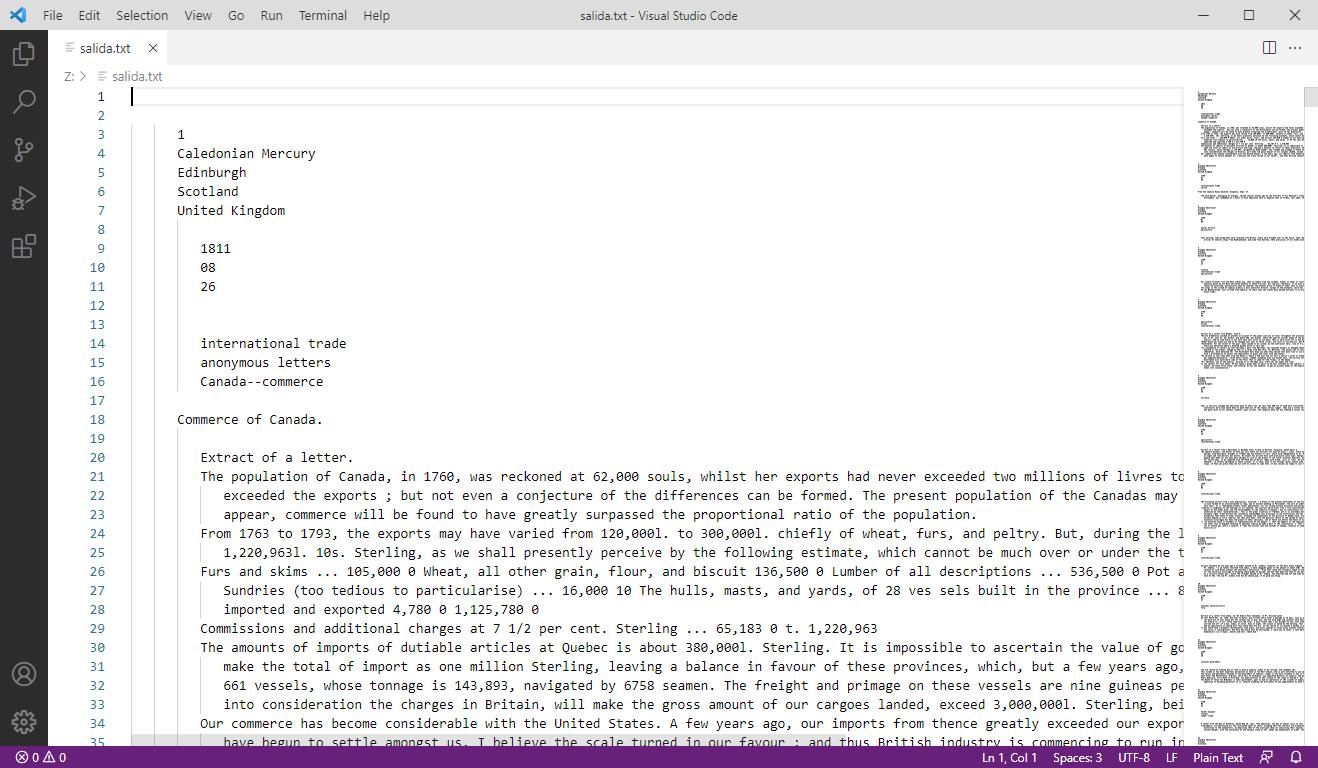
Figura 2: Salida del texto inicial
Cómo poblar los resultados de tus transformaciones
La línea de código <xsl:value-of select="raíz"/> selecciona e imprime la base de datos entera en formato de texto plano y la arroja como salida de la transformación. Si examinas los componentes de la línea, sabrás por qué:
-
xsl:value-of: sirve para seleccionar e imprimir el valor de un elemento, es decir, el texto contenido entre la etiqueta de inicio y de cierre. -
select="raíz": indica el nombre del elemento que debería seleccionarse e imprimirse; en este caso, este elemento la raíz del documento XML, que incidentalmente se llama aquí<raíz>(aunque pudo haberse llamado de cualquier otro modo). A menos que declares lo contrario, si apuntas hacia un elemento padre, el procesador también seleccionará el contenido de los todos elementos que estén en él. Por lo tanto, al apuntar al elemento<raíz>, obtenemos el texto contenido en los elementos<identificador>,<título>, etc. (Técnicamente hablandoselectes un atributo del elemento<xsl:value-of>, y el valor de ese atributo esraízaquí.)
Cómo seleccionar e imprimir valores
Si quieres seleccionar e imprimir el valor de un cierto elemento, sustituye el nombre raíz por el del elemento que quieras. Intentémoslo.
En la hoja de estilos XSL, reemplaza raíz por título en la línea apropiada, así:
<xsl:value-of select="título"/>
Guarda el archivo, ejecuta de nuevo el comando de transformación en el terminal y examina el resultado en VSCode. (VSCode automáticamente refrescará la ventana cada vez que detecta que un archivo ha sido actualizado.)
¿No funcionó? Eso es porque el procesador XSL no sabe dónde ubicar los elementos <título>. Veamos por qué.
Padres e hijos
El elemento <título> no está situado en el nivel más alto de la jerarquía, así que debemos explicarle al procesador cómo llegar hasta el elemento que queremos.
El lenguaje con que se hace esto se conoce como XPATH y funciona de una manera similar al modo como se estructuran las rutas de las carpetas en un computador.
Sustituye título por raíz/registro/título. La hoja de estilos XSL quería entonces así:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:value-of select="raíz/registro/título"/>
</xsl:template>
</xsl:stylesheet>
Guárdala, corre la transformación y examina el resultado en VSCode de nuevo.
Ahora deberías obtener “Caledonian Mercury”, es decir, el título del primer registro en el documento XML. Sin embargo, tenemos más de 300 elementos título. ¿Qué ha ocurrido? Es muy sencillo: como no hemos especificado cuál título queríamos imprimir, el procesador ha asumido que solo nos interesaba el primero. Una vez lo selecciona y lo imprime, se detiene.8
Bucles con for-each
Para un ser humano quizás parezca normal querer el contenido de todos los elementos <título> en la base de datos XML, pero el procesador no sabe esto por defecto.
Para remediar la situación, debemos repetir la operación una y otra vez por medio de un bucle for.
Además de seleccionar todos y cada uno de los elementos, los bucles for nos permiten controlar con mucha precisión cómo hacer esto.
El bucle le indica al procesador XSL que debe procesar todo el documento XML y llevar a cabo la transformación indicada cada vez que una cierta condición sea se cumpla.
Así pues, crea una nueva línea después de <xsl:template match="/"> e inserta <xsl:for-each select="raíz/registro">. Esta instrucción le indica al procesador que para cada elemento <registro> situado dentro del elemento <raíz> debe realizar una determinada acción.
A continuación, elimina raíz/registro del valor del atributo @select en el elemento <xsl:value-of> y deja solo título.
La razón de esto es que ya estamos adentro del contexto raíz/registro (cuando lo seleccionamos con el elemento <xsl:for-each select="raíz/registro">)
Tras <xsl:value-of>, hay que terminar la operación con la etiqueta de cierre </xsl:for-each>.
El archivo resultante será el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:value-of select="título"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Ahora el elemento <xsl:template> contiene tres líneas de código:
- una etiqueta de inicio para el bucle
- una instrucción para seleccionar un
<título>e imprimir su contenido - una etiqueta de cierre para el bucle
Guarda la hoja de estilos XLS, corre la transformación en el terminar y examina el resultado en VSCode.
Deberías obtener una única línea larguísima de texto con el valor de cada uno de los elementos <título>.
Puedes mejorar la forma como se imprime indicándole al procesador que añada un salto de línea tras cada entrada.
Para ello, justo después de la línea <xsl:value-of select="título"/> en tu archivo XSL, añade <xsl:text>
</xsl:text> para crear un salto de línea.

 es el código hexadecimal ISO 10646 con el que se representa un salto de línea. 9
Con el elemento <xsl:text> especificamos que queremos imprimir el contenido como texto plano.
Dependiendo del tipo de output que se haya escogido (con el elemento <xsl:output>), algunos caracteres especiales, específicamente los espacios múltiples o los saltos de línea, pueden no visualizarse correctamente si se introducen por sí solos.
El uso de elementos <xsl:text> garantiza que tu texto se visualizará exactamente como lo deseas.
El código completo de nuestra hoja de estilos XSL será entonces este:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:value-of select="título"/>
<xsl:text>
</xsl:text>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Guarda el archivo, ejecuta de nuevo el comando de transformación en el terminal y examina el resultado en VSCode. Ahora deberías ver impreso el valor de los títulos de todos los registros contenidos en el documento.
Ejercicio A
Nota: algunas soluciones posibles para estos ejercicios se encuentran al final del tutorial.
Imprime un inventario de los registros que contenga el identificador, el título y la fecha de cada registro.
Ejercicio B
Imprime el texto de todos los artículos, precedido por el identificador entre corchetes cuadrados ([]).
Atributos
En un elemento, no siempre se almacena la información dentro su contenido (esto es, aquello que va entre sus etiquetas de apertura y de cierre).
Algunos datos pueden almacenar como valores de atributos de ese elemento.
Por ejemplo, el elemento <fecha> tiene un atributo llamado cuándo que contiene el valor de la fecha del artículo, así:
<fecha cuándo="1789-01-05">
Ahora bien, para obtener el valor contenido en el atributo cuándo hay que hacer referencia a este atributo utilizando el valor @cuándo (nota la arroba @ que precede su nombre), así
<xsl:value-of select="fecha/@cuándo"/>
lo que significa: selecciona e imprime el valor del atributo cuándo del elemento <fecha>.
Ejercicio C
Crea un inventario de registros en el que se liste el título del periódico seguido de la fecha de publicación.
Cómo ordenar resultados
Esta base de datos XML fue escrita según se iba recolectando la información, sin organizar los registros por fecha o título.
A fin de organizarlos, podemos añadir un elemento <xsl:sort> (literalmente, ordena o clasifica) al principio de la repetición en bucle, es decir, inmediatamente después del elemento <xsl:for-each>.
Este elemento tiene varios atributos opcionales que modifican cómo los datos se ordenan en el documento resultante:
select: contiene el nombre del elemento que sirve como criterio para ordenar los datosorder: define si los datos se ordenan de manera ascendiente (con el valorascending) o descendiente (con el valordescending)data-type: informa al procesador XSL si los datos son de texto (con el valortextual) o numéricos (connumber)
Por ejemplo, podemos escribir la siguiente instrucción para ordenar los datos a partir del elemento <identificador> en orden descendiente, es decir de mayor a menor:
<xsl:sort select="identificador" order="descending" data-type="number"/>
Vale aclarar que es posible ordenar los resultados utilizando un cierto elemento, incluso si no se lo desea imprimir.
Ejercicio D
Imprime el texto de todos los artículos, ordenados de más a menos recientes.
Para ello, utiliza el elemento <xsl:sort> y trata las fechas como si fueran texto (text).
Cómo filtrar resultados
Hasta el momento hemos impreso todos los registros contenidos en el documento XML.
Ahora bien, si solo queremos seleccionar unos cuantos, necesitaremos filtrar los resultados mediante condiciones.
Esto se consigue utilizando el elemento <xsl:if> (literalmente, si) y añadiendo la condición deseada en el atributo test.
Si se cumple la condición, el procesador llevará a cabo la instrucción contenida en <xsl:if>.
Si no la cumple, lo ignorará y seguirá adelante.
Así, para imprimir los identificadores de los registros del año 1789, podemos usar el siguiente código:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:if test="fecha/año='1789'">
<xsl:value-of select="identificador"/>
<xsl:text>
</xsl:text>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Si queremos excluir el año 1789, en cambio, utilizaremos la expresión fecha/año!=1789' (donde != significa: no igual a).
Ejercicio E
A modo de recapitulación, crea una lista de registros fechados a partir de 1789 ordenada del más reciente al más antiguo y que contenga el identificador, el título y la fecha separados por comas; cada registro deberá mostrarse tras un salto de línea.
Si lo deseas, puedes especificar que el archivo de salida sea un archivo de Valores separados por comas (CSV), que puede abrirse y manipularse como una hoja de cálculo con Microsoft Excel o LibreOffice Calc. Para hacer eso, tan solo especifícalo en la línea de comandos cuando realices la transformación:
java -jar saxon-he-11.2.jar -xsl:miestilo.xsl -s:SAPsimple_es.xml -o:salida.csv
Conclusión
Esta lección ha cubierto el funcionamiento principal de XSL.
Con la información proporcionada, resulta fácil generar varios outputs en distintos formatos: texto plano, valores separados por coma o por tabulaciones, o Markdown.
También sería posible crear páginas web cambiando valor el atributo method en el elemento <xsl:output> de text a html, y envolviendo las instrucciones <xsl:value-of> con los elementos HTML pertinentes.
Existen muchas más instrucciones con las que transformar documentos XML a otros formatos y estructuras.
Aunque algunas transformaciones más avanzadas requieren un procesador XSL 2.0 o 3.0, las explicaciones de este tutorial satisfacen las necesidades más comunes de los historiadores.
Para los usuarios más experimentados, recomendamos explorar el directorio Transformers de la base de datos Scissors and Paste a fin de ver más ejemplos de cómo transformar datos estructurados con lenguaje XML.
Posibles soluciones a los ejercicios
Introducción (fuentes primarias)
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<html>
<body>
<xsl:for-each select="raíz/registro">
<xsl:if test="secciónPalabrasClave/palabraClave = 'slave insurrections'">
<h2>
<i><xsl:value-of select="título"/></i>, <xsl:value-of select="substring(fecha/@cuándo, 9, 2)"/>
<xsl:text> </xsl:text>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '01'">January</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '02'">February</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '03'">March</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '04'">April</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '05'">May</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '06'">June</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '07'">July</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '08'">August</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '09'">September</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '10'">October</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '11'">November</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '12'">December</xsl:if>
<xsl:text> </xsl:text>
<xsl:value-of select="substring(fecha/@cuándo, 1, 4)"/>
<xsl:text>

</xsl:text>
</h2>
<xsl:for-each select="texto/p">
<p>
<xsl:value-of select="."/>
</p>
</xsl:for-each>
</xsl:if>
</xsl:for-each>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
El punto (.) en el elemento XSL <xsl:value-of select="."/> es la forma de referirnos al elemento actual en el contexto.
En este caso nos referimos al elemento seleccionado con la instrucción <xsl:for-each select="texto/p">, es decir, el elemento <p> hijo de <texto>.
Si en su lugar tuviéramos p, no seleccionaríamos nada, pues no existe ningún texto/p/p.
Ejercicio A
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:value-of select="identificador"/>, <xsl:value-of select="título"/>, <xsl:value-of select="fecha/año"/><xsl:text>
</xsl:text>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Ejercicio B
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
[<xsl:value-of select="identificador"/>]
<xsl:value-of select="texto"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Para eliminar la sangría del texto que precede al identificador entre corchetes, necesitarás hacerte cargo directo del espaciado introduciendo saltos de línea tras el identificador y cada párrafo, así:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro"><xsl:text>
</xsl:text>[<xsl:value-of select="identificador"/>]<xsl:text>
</xsl:text><xsl:for-each select="texto/p"><xsl:value-of select="."/><xsl:text>
</xsl:text></xsl:for-each></xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Ejercicio C
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:text>
</xsl:text>
<xsl:value-of select="título"/>
<xsl:text> </xsl:text>
<xsl:value-of select="fecha/@cuándo"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
  es el código HEX equivalente a un espacio.
Aunque es posible añadir un espacio en la instrucción, es mejor utilizar el código hexadecimal para asegurarnos que se mantendrá en el documento generado.
También es posible utilizar una coma o cualquier otro separador.
Ejercicio D
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" />
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:sort select="fecha/@cuándo" order="ascending" data-type="text"/>
<xsl:for-each select="texto/p">
<xsl:text>
</xsl:text><xsl:value-of select="."/>
</xsl:for-each>
<xsl:text>
</xsl:text>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Ejercicio E
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:sort select="fecha/@cuándo" order="descending" data-type="text"/>
<xsl:if test="fecha/año = '1789'">
<xsl:value-of select="identificador"/>, <xsl:value-of select="título"/>, <xsl:value-of select="fecha/@cuándo"/><xsl:text>
</xsl:text>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Bibliografía recomendada
- Hunter, David et al. Beginning XML, 4a ed. Indianapolis, IN: Wiley, 2007. Impreso.
- Kay, Michael, XSLT 2.0 and XPATH 2.0: Programmer’s Reference. Indianapolis, IN: Wiley, 2011. Impreso.
- Kelly, David J. XSLT Jumpstarter: Level the Learning Curve and Put Your XML to Work. Raleigh, NC: Peloria Press, May 2015. Impreso.
- Mangano, Sal. XSLT Cookbook, 2a ed. Sebstopol, CA: O’Reilly, 2006. Impreso.
- Riley, Jenn. Understanding Metadata: What is Metadata, and What is For? NISO, 2017. Web
- Tennison, Jeni. Beginning XSLT 2.0. From Novice to Professional. Nueva York: Apress, 2005. Impreso.
- Tidwell, Doug. XSLT, 2a ed. Sebstopol, CA: O’Reilly, 2008. Impreso
Notas
-
Nota del traductor: Según Wikipedia, una base de datos XML es un programa “que da persistencia a datos almacenados en formato XML. Estos datos pueden ser interrogados, exportados y serializados”. Pueden distinguirse dos tipos: bases de datos habilitadas (por ejemplo, una basee de datos relacional clásica que acepta XML como formato de entrada y salida) y bases de datos nativas (es decir, que utilizan documentos XML como unidad de almacenamiento) como eXist o BaseX. En este tutorial, sin embargo, la autora, a menudo, no distingue entre el continente (el programario) y el contenido de la base de datos XML (los documentos). ↩
-
El lenguaje XSL tiene dos ramas: (1) XSL Formatting Objects (XSL:FO), que contiene instrucciones de formato para producir un documento PDF a partir de un documento XML; y (2) Extensible Stylesheet Language Transformations (XSLT), es contiene instrucciones para transformar un documento XML en otros documentos (XML, HTML, XHTML y texto plano). En este tutorial solo se discute la segunda. ↩
-
Otra posibilidad es que ubiquemos el ejecutable de Saxon en una carpeta que ya esté incluida en la variable global de sistema
PATH(o que cambiemos dicha variable para que incluya la carpeta que hemos escogido para Saxon). Quienes tengan interés pueden consultar estas páginas que explican cómo hacerlo en Windows, MacOS y Linux. ↩ -
Nota del traductor: La Text Encoding Initiative considera que un documento XML está bien formado cuando cumple tres reglas: (1) un solo elemento (o elemento raíz) contiene todo el documento; (2) todos los elementos están contenidos en el elemento raíz; y (3) las etiquetas de apertura y cierre marcan, respectivamente, el inicio y el fin de todos los elementos. Para más detalles sobre el funcionamiento de XML, aconsejamos consultar Hunter et al. (2007). ↩
-
Nota del traductor: La National Information Standards Organization (NISO), nacida en Estados Unidos en 1983 en el ámbito de las bibliotecas, define los metadatos como “la información creada, almacenada y compartida para describir objetos y que nos permite interactuar con éstos a fin de obtener conocimiento” (Riley, 2017). ↩
-
Nota del traductor: En la versión española de este tutorial, hemos traducido al español los nombres de los elementos (pero no su contenido) y hemos adaptado las instrucciones XSL para que coincidan con los utilizados en el archivo fuente (input). En adelante, daremos por sentado que estás utilizando el archivo XML
SAPsimple_es.xml. ↩ -
Nota del traductor: Más información en Wikipedia y en la página web de International Organization for Standardization. ISO es una organización internacional fundada en 1947 y establecida en Ginebra que tiene por misión la creación y mantenimiento de estándares. ↩
-
Desde la versión 2.0 de XSLT, la instrucción
<xsl:value-of>selecciona todas las ocurrencias de la expresión en el documento XML. (Al respecto, véase aquí.) Si quieres intentarlo, debes cambiar el valor del atributo@versionde1.0a2.0(o a3.0) en la línea<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">de la hoja de estilos XSL. ↩ -
En lugar de usar la entidad

, puedes reemplazar la línea con este código:<xsl:text> </xsl:text>(Fíjate en la línea en blanco como contenido del elemento
<xsl:text>.) Ambas expresiones son equivalentes, aunque esta segunda ocupa más espacio (y es más evidente) que la primera. ↩