
Contenus
- Cadre d’étude et objectifs de la leçon
- Introduction
- Des données oui, mais pour quoi faire ?
- Chaîne de traitement : production du jeu de données et traitement des documents
- Ouverture sur le manuscrit et conclusion
- Notes de fin
Cadre d’étude et objectifs de la leçon
Ce tutoriel présente des stratégies et bonnes pratiques pour constituer des données pertinentes et en quantité suffisantes pour reconnaître des écritures généralement peu ciblées dans les projets de reconnaissance de caractères. Le tutoriel est appliqué au traitement d’un imprimé, la Patrologie Grecque (PG), et propose une ouverture sur le traitement d’un document manuscrit de la Bibliothèque universitaire des langues et civilisations (BULAC) en écriture arabe maghrébine. Ces deux exemples sont très spécifiques mais la stratégie globale présentée, ainsi que les outils et approches introduits, sont adaptés au traitement de tout type de document numérisé, en particulier sur des langues peu dotées pour lesquelles une approche reposant sur la masse est difficilement applicable.
La PG est une collection de réimpressions de textes patristiques, théologiques et historiographiques publiée à Paris par Jacques-Paul Migne (1800-1875) entre 1857 et 1866. La PG compte 161 volumes et réunit des textes produits entre le Ier et le XVe siècle, en commençant par les écrits de Clément de Rome – « pape » de 92 à 99 – pour se clôturer par ceux du cardinal Jean Bessarion (1403-1472). La PG ne contient pas que des textes théologiques – loin de là –, mais aussi de nombreux textes exégétiques, historiques, hagiographiques, législatifs, encyclopédiques, poétiques et même romanesques. En réalité, on y trouve la plus grande part de la littérature byzantine, qui fait la synthèse entre la culture grecque et l’héritage chrétien. Malgré leur intérêt incontestable pour la recherche, une partie de ces textes n’a plus été rééditée depuis la fin du XIXe siècle ou n’est toujours pas accessible dans une version numérique1. Le projet Calfa GREgORI Patrologia Graeca (CGPG) a été créé pour combler cette lacune. L’association Calfa et le projet GREgORI, sous la responsabilité académique du professeur Jean-Marie Auwers (université catholique de Louvain) ont entrepris de rendre ces textes accessibles en ligne et d’en augmenter leurs contenus, dans un format interopérable, via des approches automatiques d’OCR et d’analyses lexicale et morphosyntaxique2.

Figure 0 : Exemple de la PG (PG 125, c. 625-626) |

Figure 0 : Exemple de la PG (PG 125, c. 1103-1104) |
À l’issue de cette leçon, le lecteur ou la lectrice sera en mesure d’établir une stratégie et un cahier des charges adapté à la reconnaissance de caractères de documents actuellement non couverts par les modèles standards d’OCR (reconnaissance optique de caractères) et de HTR (reconnaissance de l’écriture manuscrite) généralement disponibles. Cette stratégie pourra se développer au sein de projets collaboratifs. La leçon initie également au fonctionnement d’une plateforme d’annotation de documents, Calfa Vision, sans toutefois exclure les autres plateformes. Le lectorat trouvera donc ici des méthodologies transposables. Enfin, la leçon introduit par l’exemple à des notions d’apprentissage machine. Elle ne nécessite pas de pré-requis particulier : quelques exemples en python et en XML sont présentés mais ils sont ajoutés à cette leçon en guise d’illustration. De même, les principes sous-jacents d’apprentissage machine sont introduits de zéro, parfois vulgarisés, et ne nécessitent pas de connaissances préalables. Néanmoins, il est recommandé de se renseigner sur les notions de base pour l’entraînement de réseaux de neurones – notions de jeux de données, d’ensemble d’apprentissage et de test – afin de tirer profit au mieux de la leçon3.
Introduction
La reconnaissance de caractères
La transcription automatique de documents est désormais une étape courante des projets d’humanités numériques ou de valorisation des collections au sein de bibliothèques numériques. Celle-ci s’inscrit dans une large dynamique internationale de numérisation des documents, facilitée par le framework IIIF (International Image Interoperability Framework4) qui permet l’échange, la comparaison et l’étude d’images au travers d’un unique protocole mis en place entre les bibliothèques et les interfaces compatibles. Si cette dynamique donne un accès privilégié et instantané à des fonds jusqu’ici en accès restreint, la masse de données bouleverse les approches que nous pouvons avoir des documents textuels. Traiter cette masse manuellement est difficilement envisageable, et c’est la raison pour laquelle de nombreuses approches en humanités numériques ont vu le jour ces dernières années. Outre la reconnaissance de caractères, peuvent s’envisager à grande échelle la reconnaissance de motifs enluminés5, la classification automatique de page de manuscrits6 ou encore des tâches codicologiques telles que l’identification d’une main, la datation d’un manuscrit ou son origine de production7, pour ne mentionner que les exemples les plus évidents. En reconnaissance de caractères comme en philologie computationnelle, de nombreuses approches et méthodologies produisent des résultats déjà très exploitables, sous réserve de disposer de données de qualité pour entraîner les systèmes.
La leçon présente une approche reposant sur de l’apprentissage profond (ou deep learning), largement utilisé en intelligence artificielle. Dans notre cas, elle consiste simplement à fournir à un réseau de neurones un large échantillon d’exemples de textes transcrits afin d’entraîner et d’habituer le réseau à la reconnaissance d’une écriture. L’apprentissage, dit supervisé dans notre cas puisque nous fournissons au système toutes les informations nécessaires à son entraînement – c’est-à-dire une description complète des résultats attendus –, est réalisé par l’exemple et la fréquence.
Il est donc aujourd’hui possible d’entraîner des réseaux de neurones pour analyser une mise en page très spécifique ou traiter un ensemble de documents très particulier, en fournissant des exemples d’attendus à ces réseaux. Ainsi, il suffira d’apporter à un réseau de neurones l’exacte transcription d’une page de manuscrit ou la précise localisation des zones d’intérêts dans un document pour que le réseau reproduise cette tâche (voir figure 1).
Il existe dans l’état de l’art une grande variété d’architectures et d’approches utilisables. Cependant, pour être efficaces et robustes, ces réseaux de neurones doivent être entraînés avec de grands ensembles de données. Il faut donc annoter, souvent manuellement, des documents similaires à ceux que l’on souhaite reconnaître – ce que nous appelons classiquement la création de « vérité terrain » ou ground truth.
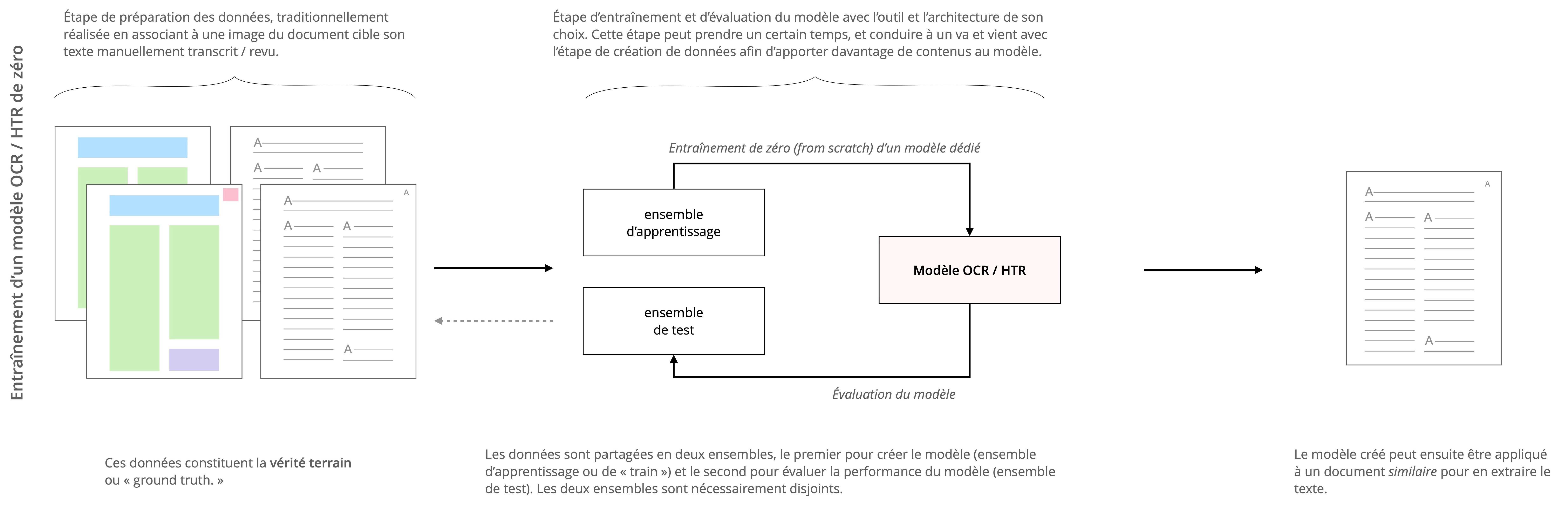
Figure 1 : Détail des étapes classiques pour l’entraînement d’un modèle OCR ou HTR
Le cas des langues et systèmes graphiques peu dotés
Annoter manuellement des documents, choisir une architecture neuronale adaptée à son besoin, suivre/évaluer l’apprentissage d’un réseau de neurones pour créer un modèle pertinent, etc., sont des activités coûteuses et chronophages, qui nécessitent souvent des investissements et une expérience en apprentissage machine (ou machine learning), conditions peu adaptées à un traitement massif et rapide de documents. L’apprentissage profond est donc une approche qui nécessite intrinsèquement la constitution d’un corpus d’entraînement conséquent, corpus qu’il n’est pas toujours aisé de constituer malgré la multiplicité des plateformes dédiées (voir infra). D’autres stratégies doivent donc être mises en place, en particulier dans le cas des langues dites peu dotées.
En effet, si la masse critique de données pour du traitement de manuscrits ou documents imprimés en alphabet latin semble pouvoir être atteinte8, avec une variété de formes, polices d’écritures et mises en page représentées et représentatives des besoins classiques des institutions en matière d’HTR et d’OCR9, cela est beaucoup moins évident pour les autres alphabets. Nous nous retrouvons donc dans la situation où des institutions patrimoniales numérisent et rendent disponibles des copies numériques des documents, mais où ces derniers restent « dormants » car pas ou peu interrogeables par des systèmes automatiques. Par exemple, de nombreuses institutions, comme la Bibliothèque nationale de France (BnF) au travers de son interface Gallica, proposent des versions textes des documents écrits majoritairement avec l’alphabet latin en vue de permettre la recherche en plein texte, fonctionnalité qui malheureusement est indisponible pour les documents en arabe.
Aujourd’hui, une langue ou un système graphique peuvent être considérés comme peu dotés à plusieurs niveaux :
-
Un manque de disponibilité ou d’existence des données. Il s’agit du point le plus évident, de nombreux systèmes graphiques ne sont tout simplement pas représentés numériquement, au sens de données exploitables, même si des réseaux institutionnels se forment pour intégrer ces langues dans cette transition numérique10.
-
Une trop grande spécialisation d’un jeu de données ou dataset. A contrario, s’il peut exister des données pour une langue ciblée, celles-ci peuvent être trop spécialisées sur l’objectif poursuivi par l’équipe qui les ont produites – modernisation de l’orthographe d’une graphie ancienne ou utilisation d’une notion de ligne spécifique par exemple –, limitant sa reproductibilité et son exploitation dans un nouveau projet. Par conséquent, s’il existe des modèles gratuits et ouverts (voir infra) pour une langue ou un document, ceux-ci peuvent ne pas convenir immédiatement aux besoins du nouveau projet.
-
Un nombre potentiellement réduit de spécialistes en mesure de transcrire et d’annoter des données rapidement. Si des initiatives participatives – dites de crowdsourcing – sont souvent mises en place pour les alphabets latins11, elles sont plus difficilement applicables pour des écritures anciennes ou non latines qui nécessitent une haute expertise, souvent paléographique, limitant considérablement le nombre de personnes pouvant produire les données.
-
Une sur-spécialisation des technologies existantes pour l’alphabet latin, résultant en des approches moins adaptées pour d’autres systèmes graphiques. Par exemple, les écritures arabes tireront intuitivement profit d’une reconnaissance globale des mots plutôt que de chercher à reconnaître chaque caractère indépendamment.
-
La nécessité de disposer de connaissances en apprentissage machine pour exploiter au mieux les outils de reconnaissance automatique des écritures proposés actuellement.
Ces limites sont illustrées dans la figure 2 qui met en évidence les composantes essentielles pour le traitement efficace d’un système graphique ou d’une langue, et dont sont dépourvues, en partie, les langues peu dotées.
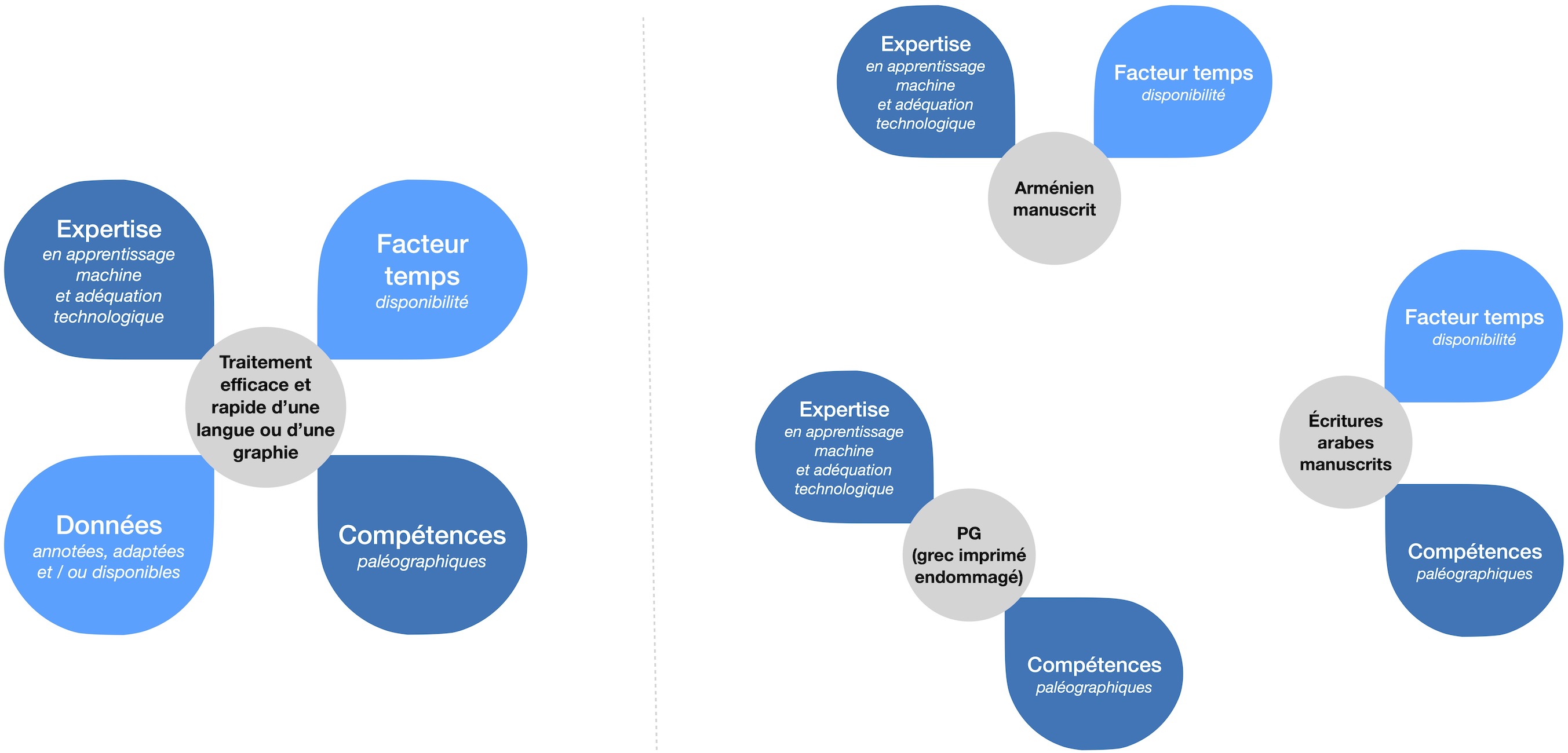
Figure 2 : Les composantes essentielles pour le traitement efficace d’une écriture (à gauche) et desquelles les langues peu dotées sont dépourvues (à droite quelques exemples classiquement traités sur Calfa Vision)
Rien d’insurmontable pour autant. Si le pipeline (ou la chaîne de traitement) classique qui consiste donc à apporter massivement des données (manuellement) annotées à une architecture neuronale s’avère manifestement peu adapté au traitement de certaines langues, plusieurs plateformes ont été implémentées pour faciliter l’accès aux OCR et HTR ces dernières années. Chacune d’elles essaie de jongler avec les composantes de la figure 2, en intégrant par exemple des modèles pré-entraînés pour avancer le travail de transcription12. L’objectif de ces plateformes consiste à compenser l’une des composantes manquantes afin de permettre le traitement de la langue/écriture cible.
La plateforme la plus connue est Transkribus (READ-COOP), utilisée sur un très large spectre de langues, écritures et types de documents. Il existe également des plateformes institutionnelles comme eScriptorium (université Paris Sciences & Lettres) dédiée aux documents historiques, et OCR4all (université de Wurtzbourg) particulièrement adaptée aux documents imprimés anciens. Enfin, des plateformes privées comme Calfa Vision (Calfa) complètent ces dernières par une multiplicité d’architectures. Cette dernière intègre une approche de spécialisation itérative pour surmonter les écueils mentionnés pour le traitement d’écritures peu dotées, à partir de petits échantillons13.
L’objectif méthodologique est de tirer profit des fonctionnalités de spécialisation de la plateforme d’annotation Calfa Vision. Celle-ci intègre différentes architectures neuronales selon la langue ciblée afin de minimiser l’investissement en données, sans attendre des utilisateurs et utilisatrices une compétence particulière en apprentissage machine pour évaluer les modèles (voir infra). L’enjeu est donc de surmonter l’écueil du manque de données par des stratégies de spécialisation et de définition des besoins.
Des données oui, mais pour quoi faire ?
La reconnaissance automatique des écritures n’est possible qu’en associant l’expertise humaine à la capacité de calcul de l’ordinateur. Un important travail scientifique reste à notre charge pour définir les objectifs et les sorties d’une transcription automatique. Plusieurs questions se posent donc au moment de se lancer dans l’annotation de nos documents :
- Créer des données. Quel volume possible, pour quels besoins, quel public et quelle compatibilité ?
- Créateur et créatrice de données. Par qui et dans quelle temporalité ?
- Approche généraliste ou approche spécialisée
- Approche quantitative ou qualitative
Notre objectif est ici de réussir à transcrire automatiquement un ensemble homogène de documents, tout en minimisant l’investissement humain pour la création de modèles. Nous souhaitons créer un modèle spécialisé – et non généraliste – pour surmonter les spécificités de notre document. Ces spécificités peuvent être de plusieurs ordres et peuvent justifier la création d’un modèle spécialisé : nouvelle main, nouveau font, état variable de conservation du document, mise en page inédite, besoin d’un contenu spécifique, etc.
Pipeline classique d’un OCR/HTR
Étapes de reconnaissance
Le travail d’un OCR ou d’un HTR se décompose en plusieurs étapes : analyse et compréhension d’une mise en page, reconnaissance du texte et formatage du résultat. La figure 3 reprend l’essentiel des tâches classiquement présentes et sur lesquelles un utilisateur ou une utilisatrice a la main pour adapter un modèle à son besoin. L’intégralité de ces fonctionnalités est entraînable sur la plateforme Calfa Vision, ce qui nous assure un contrôle complet du pipeline de reconnaissance.
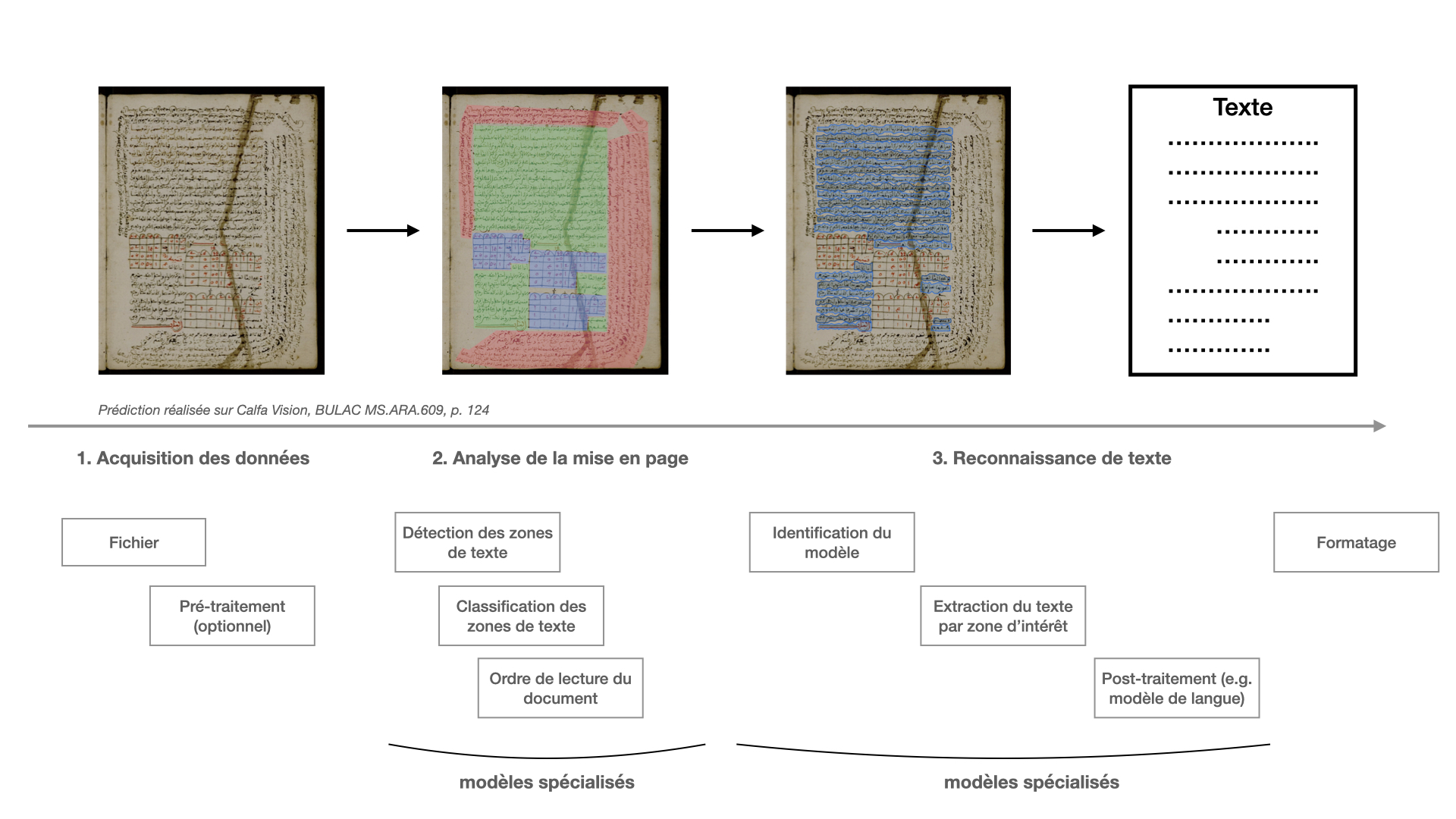
Figure 3 : Pipeline classique d’un traitement OCR/HTR. Les étapes 2 et 3 sont spécialisables aux besoins d’un projet, et l’étape 3 intègre des approches spécifiques à une langue/écriture pour maximiser les résultats en minimisant l’investissement.
La figure 3 met en évidence l’une des grandes oubliées de la reconnaissance de caractères : l’analyse de la mise en page, qui peut être spécialisée pour ne reconnaître qu’une ou plusieurs régions d’intérêt dans le document et concentrer l’extraction des lignes dans ces régions. La construction d’un modèle d’analyse de la mise en page performant est l’un des enjeux majeurs pour le traitement de nouvelles collections (voir infra).
La spécialisation des modèles (ou fine-tuning)
Le fine-tuning d’un modèle consiste à affiner et adapter les paramètres d’un modèle pré-entraîné sur une tâche similaire à notre problématique. Cette approche permet de limiter considérablement le nombre de données nécessaires, par opposition à la création d’un modèle de zéro (from scratch), l’essentiel du modèle étant déjà construit. Par exemple, nous pourrons partir d’un modèle entraîné sur le latin — langue pour laquelle nous disposons d’un grand nombre de données — pour obtenir rapidement un modèle pour le moyen-français — pour lequel les jeux de données sont plus limités. Ces deux langues partageant un grand nombre de représentations graphiques, ce travail de spécialisation permettra d’aboutir à des modèles OCR/HTR rapidement exploitables14.
La différence entre un modèle entraîné de zéro et une stratégie de fine-tuning est décrite en figures 4 et 5.
Figure 4 : Entraînement d’un modèle OCR/HTR de zéro

Figure 5 : Fine-tuning d’un modèle OCR/HTR pré-entraîné
La stratégie de fine-tuning est largement développée et utilisée dans les projets faisant appel à la reconnaissance de caractères15.
Le fine-tuning itératif des modèles sur Calfa Vision
Dans la pratique, il est difficile d’anticiper le volume de données nécessaire au fine-tuning ou à l’entraînement de zéro d’un modèle (voir infra). Entraîner, évaluer, ré-annoter des documents, et ainsi de suite jusqu’à l’obtention d’un modèle satisfaisant est non seulement chronophage mais requiert de plus une solide formation en apprentissage machine. Afin de surmonter cet écueil, la plateforme Calfa Vision intègre nativement une stratégie de fine-tuning itératif autonome (voir figure 6) au fur et à mesure des corrections de l’utilisateur ou de l’utilisatrice.
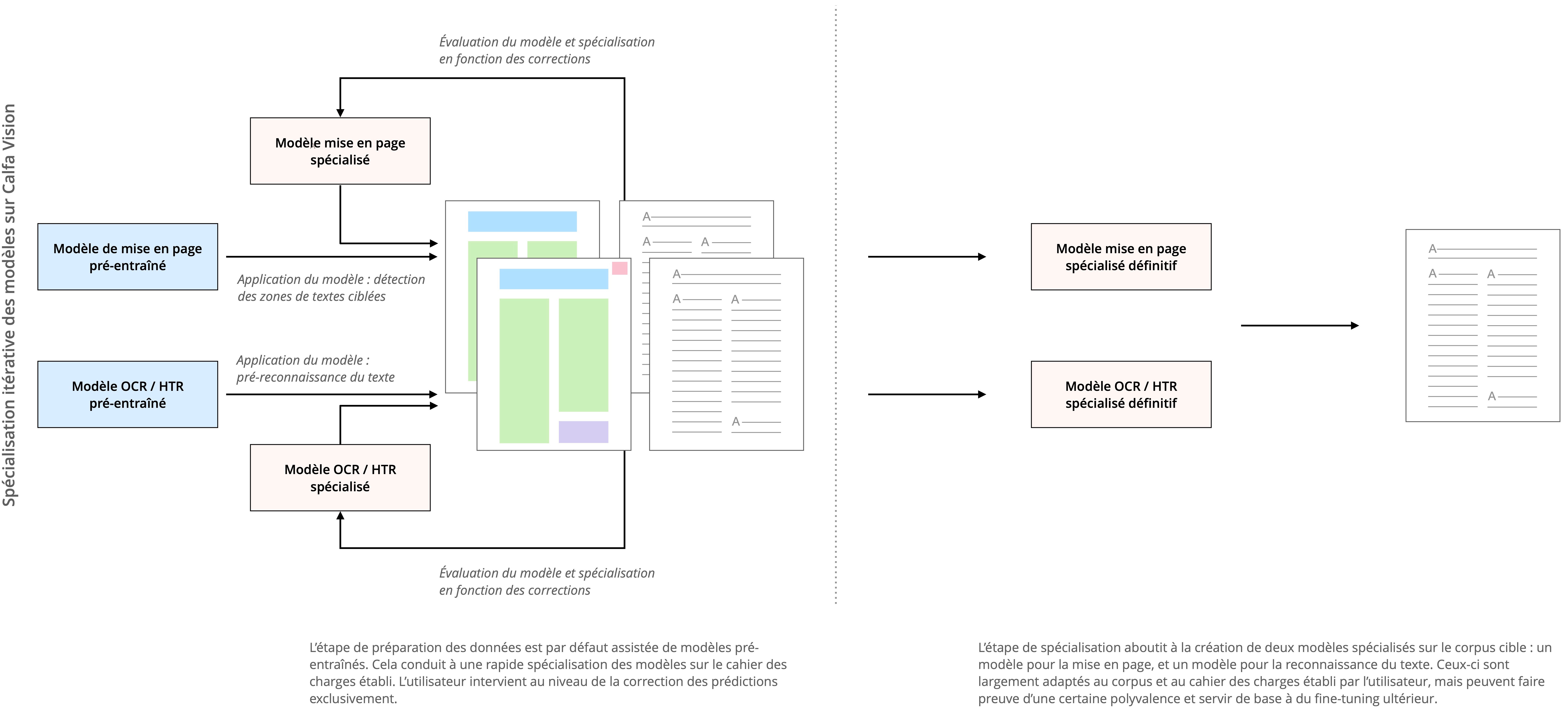
Figure 6 : Stratégie de fine-tuning itératif sur Calfa Vision
La plateforme propose en effet un grand nombre de modèles pré-entraînés sur diverses tâches – étude de documents imprimés, analyse de documents manuscrits orientaux, lecture de documents xylographiés chinois, etc. – qui sont prêts à être spécialisés sur les tâches ciblées par l’utilisateur ou l’utilisatrice, au niveau de la mise en page et de la reconnaissance de texte.
Définition des besoins
Si aujourd’hui nous pouvons tout à fait considérer la reconnaissance de caractères comme un problème largement résolu pour les écritures latines, ou les documents unilingues, et une mise en page simple, avec des taux d’erreur inférieurs à 2 %16, le résultat final peut ne pas être exploitable du tout (voir figure 7).

Figure 7 : Reconnaissance de caractères et du texte. BER ms or. quart. 304, 101v, Staatsbibliothek zu Berlin
La figure 7 met en lumière ce phénomène : en entraînant une architecture de reconnaissance spécialisée sur les caractères, nous obtenons ici un CER (Character Error Rate) de 0 %, soit une reconnaissance parfaite. En revanche :
- La mise en page par colonnes n’ayant pas été correctement détectée, nous nous retrouvons avec un seul bloc de texte
- La scriptio continua du manuscrit, bien respectée par l’HTR, aboutit à un texte dépourvu d’espace difficilement accessible pour l’être humain
- Le texte, en arménien classique, comporte un grand nombre d’abréviations qui ne sont pas développées dans le résultat final. Si le texte produit correspond bien à l’image du manuscrit, la recherche en plein texte demeure de facto limitée.
Zones d’intérêts
Dans le cadre du traitement de la PG, nous ne sommes intéressés que par le texte grec des PDF à notre disposition (en rouge dans les figures 8a et 8b). Malheureusement, nous sommes confrontés à une mise en page relativement dense et complexe, avec une alternance de colonnes en grec et en latin, des textes parfois à cheval sur les deux colonnes (ici en bleu), des titres courants, des notes de bas de page ainsi que des repères de paragraphes.

Figure 8a : Mise en page de la PG (PG 123, c. 359-360)

Figure 8b : Mise en page de la PG (PG 125, c. 625-626)
Cette mise en page ne poserait pas de problème majeur si nous ne nous intéressions pas à la question de la discrimination des zones de texte. Nous ne sommes néanmoins pas concernés par le texte latin et souhaitons obtenir un résultat aussi propre que possible, sans mélange des langues ou confusion probable dans le modèle. Nous identifions donc ici un besoin d’un modèle de mise en page spécialisé.
Choix de transcription et encodage
Nous sommes tout à fait libres de choisir une transcription qui ne corresponde pas tout à fait au contenu de l’image. Des expérimentations sur le latin manuscrit ont par exemple montré que des architectures de reconnaissance au mot (dites word-based)17, comme celles intégrées sur Calfa Vision, réussissent à développer des formes abrégées avec un taux d’erreur inférieur à 3 %18.
Ici, nous travaillons avec du grec ancien, comportant de nombreux diacritiques.
| Signes | Codes | Noms anglais | |
|---|---|---|---|
| Esprits | |||
| Esprit doux | ᾿ | U+1FBF | Greek Psili |
| Esprit rude | ῾ | U+1FFE | Greek Daseia |
| Accents | |||
| Oxyton | ´ | U+1FFD | Greek Oxeia |
| Baryton | ` | U+1FEF | Greek Vareia |
| Périspomène | ῀ | U+1FC0 | Greek Perispomeni |
| Autres | |||
| Tréma | ¨ | U+00A8 | Greek Dialytika |
| Iota souscrit | ι | U+1FBE | Greek Hypogegrammeni |
| Coronis | ᾽ | U+1FBD | Greek Koronis |
| … |
Les diacritiques se combinent au-dessus des voyelles – ou juste devant les voyelles majuscules comme Ἄ, Ἆ. Les esprits peuvent de plus apparaître au-dessus de la consonne ρ (rho) : ῤ, ῥ et Ῥ. Le iota souscrit se place sous les voyelles α (alpha), η (êta), ω (oméga) – ᾆ, ῃ, ῷ, etc. –, surmontées ou non des autres diacritiques. En tenant compte des combinaisons possibles de ces diacritiques et du changement de casse des lettres de l’alphabet grec, la lettre α (alpha) peut regrouper jusqu’à 44 glyphes : Α, α, Ἀ, ἀ, Ἁ, ἁ, Ἂ, ἂ, Ἃ, ἃ, Ἄ, ἄ, Ἅ, ἅ, Ἆ, ἆ, Ἇ, ἇ, Ὰ, ὰ, Ά, ά, ᾈ, ᾀ, ᾉ, ᾁ, ᾊ, ᾂ, ᾋ, ᾃ, ᾌ, ᾄ, ᾍ, ᾅ, ᾎ, ᾆ, ᾏ, ᾇ, ᾲ, ᾼ, ᾳ, ᾴ, ᾶ et ᾷ (table complète de l’Unicode du grec ancien).
Conséquence : selon la normalisation Unicode considérée, un caractère grec peut avoir plusieurs valeurs différentes, ce dont on peut se convaincre très facilement en python.
char1 = "ᾧ"
char1
>>> ᾧ
len(char1)
>>> 1
char2 = "\u03C9\u0314\u0342\u0345" # Le même caractère mais avec les diacritiques explicitement décrits en Unicode.
char2
>>> ᾧ
len(char2)
>>> 4
char1 == char2
>>> False
Dès lors, le problème de reconnaissance de caractères n’est plus le même selon la normalisation appliquée. Dans un cas, nous n’aurons qu’une seule classe à reconnaître, le caractère Unicode ᾧ, tandis que dans l’autre nous devrons en reconnaître quatre – ω + ̔ + ͂ + ͅ – comme nous pouvons le voir ci-après.
print(u'\u03C9', u'\u0314', u'\u0342', u'\u0345')
>>> ω ̔ ͂ ͅ
Il existe plusieurs types de normalisation Unicode : NFC (Normalization Form Canonical Composition), NFD (Normalization Form Canonical Decomposition), NFKC (Normalization Form Compatibility Composition) et NFKD (Normalization Form Compatibility Decomposition), dont on peut voir les effets avec le code ci-dessous :
from unicodedata import normalize, decomposition
len(normalize("NFC", char1))
>>> 1
len(normalize("NFD", char1))
>>> 4
len(normalize("NFC", char2))
>>> 1
normalize("NFC", char1) == normalize("NFC", char2)
>>> True
## Ce qui nous donne dans le détail :
decomposition(char1)
>>> '1F67 0345'
print(u'\u1F67')
>>> ὧ
decomposition(u'\u1F67')
>>> '1F61 0342'
print(u'\u1F61')
>>> ὡ
decomposition(u'\u1F61')
>>> '03C9 0314'
print(u'\u03C9')
>>> ω
Dans notre exemple, il apparaît que la normalisation NFC – et NFKC – permet de recombiner un caractère en un seul caractère Unicode, tandis que la normalisation NFD – et NFKD – réalise la décomposition inverse19. L’avantage de ces dernières normalisations est de regrouper toutes les matérialisations d’une lettre sous un seul sigle afin de traiter la variété seulement au niveau des diacritiques.
Et donc, quelle normalisation choisir ici ?
Au-delà de l’aspect technique sur un caractère isolé, l’approche du problème est sensiblement différente selon le choix.
phrase = "ἀδιαίρετος καὶ ἀσχημάτιστος. Συνάπτεται δὲ ἀσυγ-"
len(normalize("NFC", phrase))
>>> 48
len(normalize("NFD", phrase))
>>> 56
Les impressions de la PG présentent une qualité très variable, allant de caractères lisibles à des caractères pratiquement entièrement effacés ou a contrario très empâtés (voir figure 9 et tableau 2). Il y a également présence de bruit résiduel, parfois ambigu avec les diacritiques ou ponctuations du grec.

Figure 9 : Exemples d’impression de la PG
Envisager une normalisation NFD ou NFKD permettrait de regrouper chaque caractère sous une méta-classe – par exemple α pour ά ᾶ ὰ – et ainsi lisser la grande variété dans la qualité des images. Il nous semble toutefois ambitieux de vouloir envisager de reconnaître chaque diacritique séparément, au regard de la grande difficulté à les distinguer ne serait-ce que par nous-même. Notre choix est donc largement conditionné par (i) la qualité de la typographie, parfois médiocre, de la PG et (ii) la qualité de la numérisation, comme le montre le tableau 2.
| Image | Transcription | Variation du α |
|---|---|---|
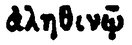
|
ἀληθινῷ | ἀ |
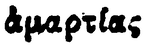
|
ἁμαρτίας | ἁ |

|
μεταφράσαντος | ά |
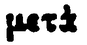
|
μετὰ | ὰ |
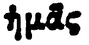
|
ἡμᾶς | ᾶ |
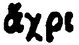
|
ἄχρι | ἄ |
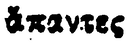
|
ἅπαντες | ἅ |
Le tableau 2 met en évidence la forte ambiguïté présente dans la PG. Les lignes 1 et 2 semblent par exemple, à tort, comporter la lettre α surmontée du même esprit. Il en est de même pour les lignes 3 et 4, et les lignes 6 et 7. Il apparaît difficile, avec peu de données, d’arriver à reconnaître ces esprits sans erreur indépendamment de la lettre. A contrario, la reconnaissance directe de la lettre accentuée pourra être facilitée par son contexte d’apparition.
Nous choisissons donc une normalisation de type NFC, qui aura pour conséquence de démultiplier le nombre de classes. Ce choix entraînera peut-être la nécessité de transcrire davantage de lignes20.
Par ailleurs, nous ne sommes pas intéressés par les appels de note présents dans le texte (voir figure 9), et ceux-ci ne sont donc pas présents dans la transcription. Cela créera une ambiguïté supplémentaire dans le modèle OCR, puisqu’à une forme graphique dans l’image ne correspondra aucune transcription. Nous identifions ici un besoin d’un modèle d’OCR spécialisé21.
Approches architecturales et compatibilité des données
À ce stade, nous avons identifié deux besoins qui conditionnent la qualité escomptée des modèles, le travail d’annotation et les résultats attendus. En termes d’OCR du grec ancien, nous ne partons pas non plus tout à fait de zéro puisqu’il existe déjà des images qui ont été transcrites et rendues disponibles22, pour un total de 5100 lignes. Un dataset plus récent, GT4HistComment23, est également disponible, avec des imprimés de 1835-1894 et des mises en page plus proches de la PG. Le format de données est le même que pour les datasets précédents (voir infra). Nous ne retenons pas ce dataset en raison du mélange d’alphabets présent dans la vérité terrain (voir tableau 3, ligne GT4HistComment).
| Source | Data |
|---|---|
greek_cursive |

|
| Vérité terrain | Αλῶς ἡμῖν καὶ σοφῶς ἡ προηγησαμένη γλῶσσα τοῦ σταυροῦ τὰς ἀκτῖ- |
gaza-iliad |
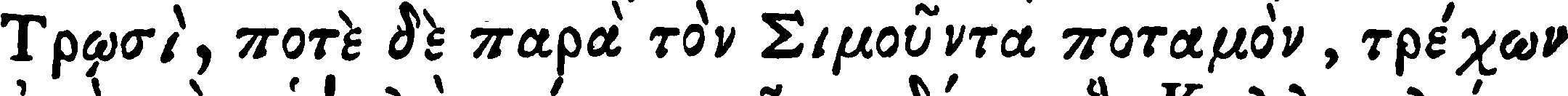
|
| Vérité terrain | Τρῳσὶ, ποτὲ δὲ παρὰ τὸν Σιμοῦντα ποταμὸν, τρέχων |
voulgaris-aeneid |
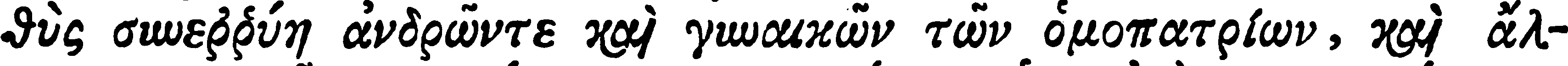
|
| Vérité terrain | θὺς συνεῤῥύη ἀνδρῶντε καὶ γυναικῶν τῶν ὁμοπατρίων, καὶ ἄλ- |
GT4HistComment |
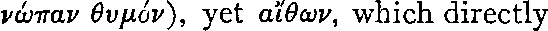
|
| Vérité terrain | νώπαν θυμόν), yet αἴθων, which directly |
Les données du tableau 3 montrent une nette différence de qualité et de police entre ces données et la PG (voir tableau 2). Les données greek_cursive présentent des formes graphiques très éloignées des formes de la PG, tandis que les autres documents sont beaucoup plus « propres ». Néanmoins, cela apporte un complément lexical qui pourra peut-être s’avérer utile par la suite. L’intégration et l’évaluation de ces données sur Calfa Vision donnent un modèle avec un taux d’erreur de 2,24 %24 dans un test in-domain, modèle sur lequel se basera le fine-tuning pour le modèle de PG. Néanmoins, il s’avère indispensable d’envisager un modèle spécialisé sur la PG afin de gérer les difficultés mises en évidence en figure 9.
Les données sont disponibles dans le format originellement proposé par OCRopus25, c’est-à-dire une paire composée d’une image de ligne et de sa transcription (voir tableau 3).
├── dataset
│ ├── 000001.gt.txt
│ ├── 000001.png
│ ├── 000002.gt.txt
│ ├── 000002.png
│ ├── 000003.gt.txt
│ └── 000003.png
Il s’agit d’un format ancien, la ligne de texte étant contenue dans un rectangle englobant (ou bounding box) parfaitement adapté aux documents sans courbure, ce qui n’est pas tout à fait le cas de la PG, dont les scans sont parfois courbés sur les tranches (voir figure 10). Ces données ne permettront pas non plus d’entraîner un modèle d’analyse de la mise en page, puisque ne sont proposées que les images des lignes sans précision sur la localisation dans le document.

Figure 10 : Gestion de la courbure des lignes sur Calfa Vision
Une approche par baselines (en rouge sur la figure 10, il s’agit de la ligne de base de l’écriture) est ici justifiée puisqu’elle permet de prendre en compte cette courbure, afin d’extraire la ligne de texte avec un polygone encadrant (en bleu sur les figures 8a et 8b) et non plus une simple bounding box26. Cette fois-ci les données ne sont plus exportées explicitement en tant que fichiers de lignes, mais l’information est contenue dans un XML contenant les coordonnées de chaque ligne. Cette approche est aujourd’hui universellement utilisée par tous les outils d’annotation de documents textuels : elle est donc applicable ailleurs.
<?xml version="1.0" ?>
<PcGts xmlns="http://schema.primaresearch.org/PAGE/gts/pagecontent/2013-07-15" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://schema.primaresearch.org/PAGE/gts/pagecontent/2013-07-15 http://schema.primaresearch.org/PAGE/gts/pagecontent/2013-07-15/pagecontent.xsd">
<Metadata>
<Creator>Calfa</Creator>
<Created>2022-08-23T14:48:18+00:00</Created>
</Metadata>
<Page imageFilename="grc_grna_or_409.jpg" imageHeight="3506" imageWidth="1686">
<TextRegion id="52467" custom="structure {type:col_greek;}">
<Coords points="193,225 147,667 171,3259 1525,3269 1505,246"/>
<TextLine id="629162">
<Coords points="241,264 241,317 239,331 1465,344 1469,329 1467,278 241,264"/>
<Baseline points="243,319 1471,331"/>
<TextEquiv>
<Unicode>Βʹ. Καὶ ἵνα γε καθ´ ὁδὸν ὁ λόγος ἡμῖν προΐῃ, περὶ</Unicode>
</TextEquiv>
</TextLine>
<TextLine id="629163">
<Coords points="1479,407 1479,368 1036,348 1034,348 185,354 185,395 183,401 1475,412 1479,407"/>
<Baseline points="187,396 1480,409"/>
<TextEquiv>
<Unicode>τῆς δειλίας προτέρας οὔσης καὶ διαλέξομαι· οὐδὲ γὰρ</Unicode>
</TextEquiv>
</TextLine>
<TextLine id="629164">
<Coords points="194,420 194,469 192,484 1477,490 1481,484 1481,446 194,420"/>
<Baseline points="196,470 1482,485"/>
<TextEquiv>
<Unicode>ἀνέχομαι πλήττεσθαί τινας ἐν ἐμοὶ τῶν πάντα τη-</Unicode>
</TextEquiv>
</TextLine>
Exemple de structure du format PAGE (XML), décrivant l’ensemble de l’arborescence des annotations – la région de texte et son type, les coordonnées de la ligne, la baseline et la transcription. D’autres formats du même type existent, comme le format ALTO (XML).
Le mélange des formats aboutit en général, dans les OCR disponibles, à une perte de qualité, en raison d’une gestion de l’information différente selon le format. Nous observons ainsi sur la figure 11 que non seulement une bounding box ne peut pas appréhender convenablement la courbure du texte et chevauche la ligne supérieure, mais aussi que les données polygonales ne sont par défaut pas compatibles avec les données de type bounding-box en raison de la présence du masque. Il est néanmoins possible de les combiner sur Calfa Vision afin d’extraire non pas un polygone mais une bounding box à partir de la baseline. Cette fonctionnalité a été précisément mise en place afin de convertir des datasets habituellement incompatibles pour exploiter des données plus anciennes et assurer une continuité dans la création de données27.

Figure 11 : Différence de visualisation d’une ligne entre une bounding-box, un masque polygonal, et un polygone extrait de Calfa Vision
Et maintenant ?
En résumé, à l’issue de cette étape de description des besoins, il en résulte que :
- Zones de texte. Nous souhaitons concentrer la détection et la reconnaissance du texte sur les colonnes principales en grec, en excluant le texte latin, les titres courants, les notes inter-colonnes, l’apparat critique et toute note marginale.
- Lignes de texte. Nous avons à prendre en compte des lignes courbes et choisissons donc une approche par baseline.
- Modèle de base. Un modèle de base est disponible mais entraîné avec des données plus anciennes. Nous utiliserons une approche combinant baseline et bounding box pour tirer profit au maximum des données existantes.
- Choix de transcription. Nous partons sur une transcription avec normalisation de type NFC, sans intégrer les signes d’édition éventuels et les appels de note. La complexité offerte par la PG laisse supposer qu’un jeu de données important devra être produit. Nous verrons dans la partie suivante comment limiter les données nécessaires en considérant une architecture dédiée et non générique.
Petit aparté sur les métriques
Pour appréhender les résultats proposés par l’OCR/HTR, tant au niveau de la mise en page que de la reconnaissance de caractères, nous devons définir quelques métriques couramment utilisées pour quantifier l’erreur de ces modèles.
CER
Nous avons déjà abordé discrètement le CER (Character Error Rate), qui donne le taux d’erreur au niveau du caractère dans la prédiction d’un texte. Le CER se calcule simplement en comptant le nombre d’opérations nécessaires pour passer de la prédiction au texte attendu. Le CER utilise la distance de Levenshtein. Il est donné par la formule suivante :
\[CER = \frac{S+D+I}{N}\]où S = le nombre de substitutions, D = le nombre de délétions, I = le nombre d’additions, et N = le nombre total de caractères à prédire.
Par exemple, si mon OCR prédit le mot Programm*m*ingHisto*y*an à la place de ProgrammingHistorian, autrement dit :
- Un m superfétatoire a été ajouté
- Le i a été substitué par un y
- Le r n’a pas été reconnu
Nous avons donc les valeurs suivantes : S = 1, I = 1 D = 1 et N = 20.
\[CER = \frac{1+1+1}{20} = 0,15\]Autrement dit, nous obtenons un taux d’erreur au niveau du caractère de 15 %.
Il existe une variante applicable au mot, le WER (ou Word Error Rate), dont le fonctionnement est totalement similaire.
Le CER et le WER sont très pratiques et intuitifs pour quantifier le pourcentage d’erreur dans une prédiction. Toutefois, selon le cahier des charges adopté, ces métriques pourront se révéler moins pertinentes voire ambiguës. L’exemple le plus évident est celui d’une lecture automatique des abréviations où il ne serait pas pertinent de comptabiliser les additions et les substitutions – par exemple à la place de p. ex.28.
Précision et rappel
La précision (precision) et le rappel (recall) sont des métriques incontournables pour évaluer l’adéquation et la finesse des prédictions. Elles seront notamment utilisées lors de l’analyse de la mise en page. La précision correspond au nombre total de résultats pertinents trouvés parmi tous les résultats obtenus. Le rappel correspond au nombre total de résultats pertinents trouvés parmi tous les résultats pertinents attendus.
Étudions ces deux métriques sur la tâche de détection des lignes (voir figure 12, où les lignes correctement détectées sont en rouge et les lignes incorrectement détectées, c’est-à-dire avec des erreurs de détection et des lignes omises, sont en vert).

Figure 12 : Comparaison de la précision et du rappel sur le manuscrit BULAC.MS.ARA.1947, image 178658 (RASAM)
GT (ground truth) : nous souhaitons détecter 23 baselines – nous décidons d’ignorer les gloses interlinéaires.
Dans le cas 1, nous détectons 37 baselines. Parmi les 37 baselines, les 23 baselines attendues sont bien présentes. Le modèle propose donc des résultats pertinents mais est globalement peu précis. Cela se traduit par un rappel élevé, mais une précision basse. Dans le détail :
\[Précision = \frac{23}{37} = 0,62\] \[Rappel = \frac{23}{23} = 1\]Dans le cas 2, nous détectons 21 baselines, dont 10 sont correctes. Le modèle est à la fois peu précis et assez peu pertinent, puisqu’il manque plus de 50 % des lignes souhaitées. Cela se traduit par un rappel bas et une précision basse. Dans le détail :
\[Précision = \frac{10}{21} = 0,47\] \[Rappel = \frac{10}{23} = 0,43\]Dans le cas 3, nous détectons douze baselines, qui sont toutes bonnes. Le modèle est assez peu pertinent, puisque la moitié seulement des lignes a été détectée, mais très précis car les lignes trouvées sont effectivement bonnes. Cela se traduit par une précision haute et un rappel bas. Dans le détail :
\[Précision = \frac{12}{12} = 1\] \[Rappel = \frac{12}{23} = 0,52\]La précision et le rappel sont souvent résumés avec le F1-score, qui correspond à leur moyenne harmonique – l’objectif étant d’être le plus près possible de 1.
Intersection sur l’Union (Intersection over Union ou IoU)
Cette métrique s’applique à la détection d’objets dans un document, autrement dit elle est utilisée pour mesurer la qualité de l’analyse et de la compréhension de la mise en page : identification des titres, des numéros de page, des colonnes de texte, etc. Dans la pratique, nous mesurons le nombre de pixels communs à la vérité terrain et à la prédiction, divisés par le nombre total de pixels.
\[IoU = \frac{GT \cap Prediction}{GT \cup Prediction}\]Cette métrique est calculée séparément pour chaque classe à détecter, et une moyenne générale (en anglais mean) de toutes les classes est calculée pour fournir un score global, le mean IoU.
Une IoU de 0,5 est généralement considérée comme un bon score, car cela signifie qu’au moins la moitié des pixels ont été attribués à la bonne classe, ce qui est généralement suffisant pour identifier correctement un objet. Une IoU de 1 signifie que la prédiction et la vérité terrain se chevauchent complètement, une IoU de 0 signifie qu’aucun pixel n’est commun à la prédiction et à la vérité terrain.
Chaîne de traitement : production du jeu de données et traitement des documents
Méthodologie technique
Calfa Vision est une plateforme qui intègre un grand nombre de modèles pré-entraînés pour différentes tâches manuscrites et imprimées, dans plusieurs systèmes graphiques non latins29 : détection et classification de zones de textes, détection et extraction des lignes, reconnaissance de texte – arménien, géorgien, syriaque, écritures arabes, grec ancien, etc30. Les travaux d’annotation et de transcription peuvent être menés en collaboration avec plusieurs membres d’une équipe et la plateforme prend en charge différents types de format. Une liste non exhaustive des modèles pré-entraînés disponibles est proposée dans le tableau 4. La langue associée à chaque nom correspond à la langue dominante et au cas classique d’utilisation, sans pour autant exclure toute autre langue. Les projets spécialisés peuvent être développés et mis à disposition par les utilisateurs et utilisatrices de la plateforme, au bénéfice de toute la communauté, comme c’est le cas pour le projet Arabic manuscripts (Zijlawi).
| Type de projet | Description |
|---|---|
| Projets génériques | |
| Arabic manuscripts (default) | Modèles de mise en page génériques pour une grande variété de manuscrits historiques arabes, simples et complexes, avec nombreux contenus marginaux courbes et endommagés. |
| Armenian archives | Modèles de mise en page génériques pour des documents d’archives, principalement en langue arménienne – mises en page simples à très complexes, notamment des lettres –, avec classification sémantique des contenus – destinataire, signataire, date, contenu, marges, etc. |
| Chinese printed | Modèles de mise en page génériques pour le traitement de textes verticaux imprimés anciens, avec mises en page simples à très denses. |
| Default | Modèles de mise en page génériques entraînés sur une très large variété de documents anciens et modernes, imprimés et manuscrits, avec classification sémantique des contenus. Capables d’une très grande polyvalence et d’une spécialisation rapide dans un grand nombre de cas. |
| Ethiopian archives | Modèles de mise en page génériques pour des documents d’archives extrêmement denses, avec grande variété de mises en page, avec classification sémantique des contenus. |
| Newspaper | Modèles de mise en page génériques pour l’analyse, la compréhension et la segmentation de journaux anciens et nouveaux. Classification sémantique des contenus pour l’arménien et l’arabe. |
| Printed documents | Modèles de mise en page génériques pour le traitement de documents imprimés anciens, modernes et contemporains, avec une grande variété de mises en page et de langues. |
| Projets spécialisés (liste non exhaustive) | |
| Arabic manuscripts (Zijlawi) | Modèles de mise en page spécialisés pour les manuscrits Zijlawi – arabe, mise en page complexe avec un texte très dense et des marginalia verticaux. Mis à disposition par un utilisateur de la plateforme. |
| Greek printed (Patrologia Graeca) | Modèles de mise en page spécialisés pour la PG – détection d’informations grecques dans des documents multilingues. Type de modèle utilisé dans la leçon pour Programming Historian. |
Ces modèles, en mesure de traiter un large spectre non exhaustif de documents, peuvent ne pas être parfaitement adaptés à notre chantier d’annotation de la PG. En revanche, la plateforme, qui repose donc sur le fine-tuning itératif de ses modèles en fonction des annotations des utilisateurs et utilisatrices, doit pouvoir rapidement se spécialiser sur un nouveau cas. Ainsi, partant par exemple d’un modèle de base pour la mise en page, nos relectures et précisions vont progressivement être intégrées dans le modèle afin de correspondre aux besoins de notre projet. Les différentes plateformes mentionnées précédemment intègrent des approches plus ou moins similaires pour le fine-tuning de leurs modèles, le lecteur ou la lectrice pourra donc réaliser un travail similaire sur ces plateformes. Calfa Vision a ici l’avantage de limiter l’engagement de chacun(e) à l’analyse de ses besoins, le fine-tuning étant réalisé de façon autonome au fil des annotations.

Figure 13 : Calfa Vision - Analyse automatique de la mise en page sur deux exemples de la PG. En haut, le modèle détecte bien les multiples zones de texte, sans distinction, et l’ordre de lecture est le bon. En bas, la compréhension du document n’est pas satisfaisante et a entraîné une fusion des différentes colonnes et lignes.
Nous observons sur la figure 13 que le modèle pré-entraîné à partir du modèle issu des projets Printed documents de la plateforme donne des résultats allant de très satisfaisants (en haut) à plus mitigés (en bas). Outre la mise sur le même plan de tous les types de régions, catégorisées en paragraph, le modèle ne réussit pas toujours à comprendre la disposition en colonne. En revanche, malgré une fusion de toutes les lignes dans le second cas, l’ensemble des zones et des lignes est correctement détecté, il n’y a pas d’informations perdues. Nous pouvons donc supposer que la création d’un nouveau modèle spécialisé pour la PG sera rapide.
Quelles annotations de mise en page réaliser ?
Pour les pages où la segmentation des zones est satisfaisante, nous devons préciser à quel type chaque zone de texte correspond, en spécifiant ce qui relève d’un texte en grec (en rouge sur les figures 8a et 8b) et ce qui relève d’un texte en latin (en bleu), et supprimer tout autre contenu jugé inutile dans notre traitement. Pour les pages non satisfaisantes, nous devrons corriger les annotations erronées.
Concernant la transcription du texte, le modèle construit précédemment donne un taux d’erreur au niveau du caractère de 68,13 % sur la PG – test hors domaine31 –, autrement dit il est inexploitable en l’état au regard de la grande différence qui existe entre les données d’entraînement et les documents ciblés. Nous nous retrouvons bien dans un scénario d’écriture peu dotée en raison de l’extrême particularité des impressions de la PG.
Au regard des difficultés identifiées en figure 9 et de la grande dégradation du document, une architecture au niveau du caractère pourrait ne pas être la plus adaptée. Nous pouvons supposer l’existence d’un vocabulaire récurrent, au moins à l’échelle d’un volume de la PG. Le problème de reconnaissance pourrait ainsi être simplifié avec un apprentissage au mot plutôt qu’au caractère. Il existe une grande variété d’architectures neuronales qui sont implémentées dans les diverses plateformes de l’état de l’art32. Elles présentent toutes leurs avantages et inconvénients en termes de polyvalence et de volume de données nécessaires. Néanmoins, une architecture unique pour tout type de problème peut conduire à un investissement beaucoup plus important que nécessaire. Dans ce contexte, la plateforme que nous utilisons opère un choix entre des architectures au caractère ou au mot, afin de simplifier la reconnaissance en donnant un poids plus important au contexte d’apparition du caractère et du mot. Il s’agit d’une approche qui a montré de bons résultats pour la lecture des abréviations du latin – à une forme graphique abrégée dans un manuscrit on transcrit un mot entier33 – ou la reconnaissance des écritures arabes maghrébines – gestion d’un vocabulaire avec diacritiques ambigus et ligatures importantes34.
Quel volume de données ?
Il est très difficile d’anticiper le nombre de données nécessaire pour le fine-tuning des modèles. Une évaluation de la plateforme montre une adaptation pertinente de l’analyse de la mise en page et de la classification des zones de texte dès 50 pages pour des mises en page complexes sur des manuscrits arabes35. Le problème est ici plus simple – moins de variabilité du contenu. Pour la détection des lignes, 25 pages suffisent36. Il n’est toutefois pas nécessaire d’atteindre ces seuils pour mesurer le gain dans l’analyse et la détection.
Au niveau de la transcription, l’état de l’art met en évidence un besoin minimal de 2000 lignes pour entraîner un modèle OCR/HTR37, ce qui peut correspondre à une moyenne entre 75 et 100 pages pour des documents manuscrits sur les scripta non latines. Pour la PG, au regard de la densité particulière du texte, cela correspond à une moyenne de 50 pages.
Ströbel et al.38 montrent par ailleurs qu’au-delà de 100 pages il n’existe pas de grande différence entre les modèles pour un problème spécifique donné. L’important n’est donc pas de miser sur un gros volume de données, mais au contraire de concentrer l’attention sur la qualité des données produites et leur adéquation avec l’objectif recherché.
Toutefois, ces volumes correspondent aux besoins de modèles entraînés de zéro. Dans un cas de fine-tuning, les volumes sont bien inférieurs. Via la plateforme Calfa Vision, nous avons montré une réduction de 2,2 % du CER pour de l’arménien manuscrit39 avec seulement trois pages transcrites, passant de 5,42 % à 3,22 % pour un nouveau cahier des charges de transcription, ou encore un CER de 9,17 % atteint après 20 pages transcrites en arabe maghrébin pour un nouveau modèle – réduction de 90,83 % du volume de données nécessaire par rapport à un modèle entraîné depuis zéro40.
Les dernières expériences montrent une spécialisation pertinente des modèles après seulement dix pages transcrites.
Introduction à la plateforme d’annotation
Le détail des principales étapes sur la plateforme Calfa Vision est donné en figures 14 et 15. L’accent est tout d’abord mis sur la gestion de projets, qui permet à un utilisateur ou une utilisatrice de créer, de gérer et de superviser des projets d’annotation, seul(e) ou en équipe. La figure 14 illustre la procédure de création d’un nouveau projet, en particulier la sélection d’un type de projet, et d’ajout de nouvelles images.
Figure 14 : Calfa Vision - Résumé de l’interface et des étapes de création de projets
La figure 15 résume les étapes essentielles pour l’annotation automatique d’une image. Le détail est donné dans la suite de cette leçon à travers l’application sur la PG. Chacun(e) est libre d’utiliser les modèles d’analyse de la mise en page et de génération des lignes, sans limite en volume, tandis que la reconnaissance du texte est quant à elle conditionnée au type de profil.
Figure 15 : Calfa Vision - Résumé de l’interface et des étapes d’annotation de documents
Un tutoriel complet de chaque étape est proposé sur la plateforme; il est disponible après connexion. Le lectorat y trouvera des détails sur les formats d’import et d’export, les scripts automatiques, la gestion de projet, l’ajout de collaborateurs et collaboratrices ainsi que de nombreuses autres fonctionnalités propres à la plateforme qu’il n’est pas possible d’aborder dans cette leçon plus générale. La démarche classique consiste à :
- Créer un compte sur la plateforme
- Créer un projet pour chaque document cible
- Importer ses images, et ses annotations si l’on en dispose déjà, et lancer les scripts d’analyse automatique
- Vérifier les prédictions obtenues
Étapes d’annotation
Nous avons construit un premier dataset composé de 30 pages représentatives de différents volumes de la PG. Ces 30 pages nous servent d’ensemble de test pour évaluer précisément les modèles tout au long de l’annotation. Les annotations produites dans la suite de cette partie constituent l’ensemble d’apprentissage (voir figures 5 et 6).
Figure 16 : Calfa Vision - Liste des images d’un projet de transcription
Gestion du projet d’annotation
Après avoir créé un projet Patrologia Graeca de type Printed documents (v1.9 06/2022), nous ajoutons les documents que nous souhaitons annoter au niveau de la mise en page et du texte. L’import peut être réalisé avec une image, un fichier ZIP d’images, avec un manifeste IIIF – fichier JSON mis à disposition par les bibliothèques compatibles IIIF, contenant les métadonnées du document et les liens vers chaque image – ou, dans notre cas, en important un fichier PDF. La figure 16 montre l’interface utilisateur avec les images en attente d’annotation.
Une fois devant l’interface de transcription d’une image (voir figure 15), nous disposons de plusieurs actions pour réaliser des analyses automatiques de nos documents :
Layout Analysisqui va détecter et classifier des zones et lignes de texteGenerate Polygonsqui va extraire des lignes détectées la ligne entière à transcrire – détection de la bounding box ou du polygone encadrant, sous réserve de lignes détectéesText Recognitionqui va procéder à la reconnaissance des lignes détectées et extraites
Les trois étapes sont dissociées afin de laisser à chacun(e) le contrôle complet du pipeline de reconnaissance, avec notamment la possibilité de corriger toute prédiction incomplète ou erronée. Nous procédons à ce stade à l’analyse de la mise en page, massivement sur l’ensemble des images du projet.
Annotation de la mise en page
En accédant à l’interface d’annotation, les prédictions sont prêtes à être relues. Nous avons trois niveaux d’annotation dans le cadre de ce projet :
├── La région de texte (en vert), avec un type associé
│ └── La ligne de texte, composée
| ├── D'une baseline (en rouge)
| └── D'un polygone ou d'une bounding box (en bleu)
| └── La transcription
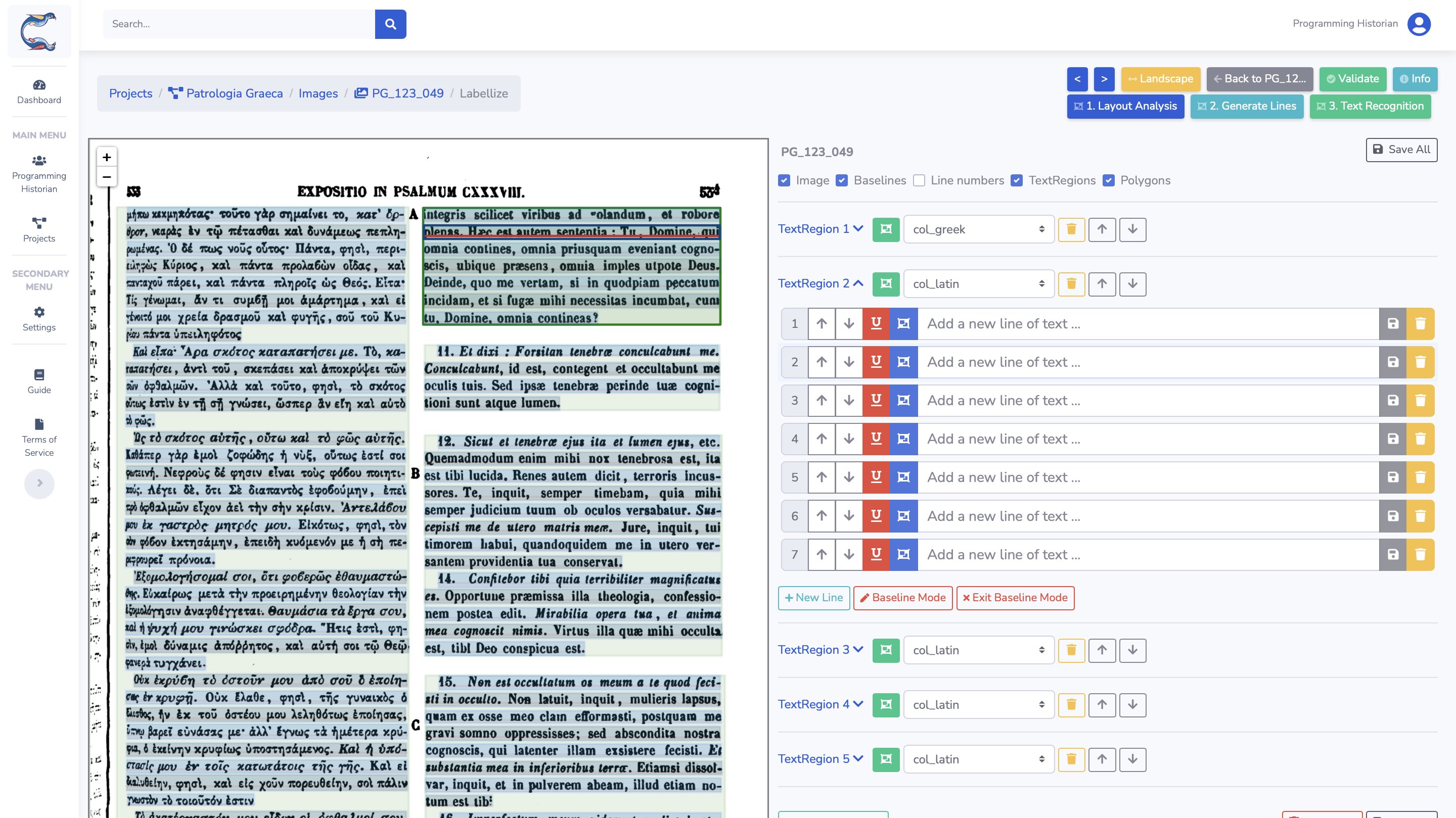
Figure 17 : Calfa Vision - Interface d’annotation et mise en page
Il n’est pas nécessaire de pré-traiter les images et d’en réaliser une quelconque amélioration - redressement, nettoyage, etc.
Chaque objet – région, ligne et texte – peut être manuellement modifié, déplacé, supprimé, etc. en fonction de l’objectif poursuivi. Ici, nous nous assurons de ne conserver que les zones que nous souhaitons reconnaître, à savoir col_greek et col_latin, auxquelles nous ajoutons cette information sémantique. C’est l’occasion également de contrôler que les lignes ont bien été détectées, notamment pour les pages qui posent problème.
Nous réalisons ce contrôle sur 10, 30 et 50 pages pour mesurer l’impact sur la détection de ces régions de texte.
| mean IoU | 0 image | 10 images | 30 images | 50 images |
|---|---|---|---|---|
| Paragraph | 0.94 | - | - | - |
| Col_greek | - | 0.86 | 0.91 | 0.95 |
| Col_latin | - | 0.78 | 0.88 | 0.93 |
Nous observons dans le tableau 5 que la distinction des zones de texte s’opère correctement dès dix images annotées, au niveau des régions. Dès 50 images, le modèle classifie à 95 % les colonnes grecques et à 93 % les colonnes latines. Les erreurs sont localisées sur les textes traversants, et sur la détection superfétatoire de notes de bas de page, respectivement en grec et en latin. Pour ce dernier cas de figure, il ne s’agit donc pas à proprement parler d’erreurs, même si cela entraîne un contenu non souhaité dans le résultat.

Figure 18 : Évolution de la détection des zones et lignes de textes
Avec ce nouveau modèle, l’annotation de la mise en page est donc beaucoup plus rapide. La correction progressive de nouvelles images permettra de surmonter les erreurs observées.
| F1-score | |
|---|---|
| 0 image | 0.976 |
| 10 images | 0.982 |
| 30 images | 0.981 |
| 50 images | 0.981 |
Nous n’allons pas développer davantage sur la métrique utilisée ici41. Concernant la détection des lignes, contrairement à ce que nous pouvions observer avec la détection des régions (figure 18), ici dix images suffisent à obtenir immédiatement un modèle très performant. L’absence d’annotation des notes de base de page conduit en particulier à créer une ambiguïté dans le modèle, d’où la stagnation des scores obtenus, pour lesquels on observe une précision « basse » – toutes les lignes détectées – mais un rappel élevé – toutes les lignes souhaitées détectées. En revanche, cela n’a pas d’incidence sur le traitement des pages pour la suite, puisque seul le contenu des régions ciblées est pris en compte.
Annotation du texte
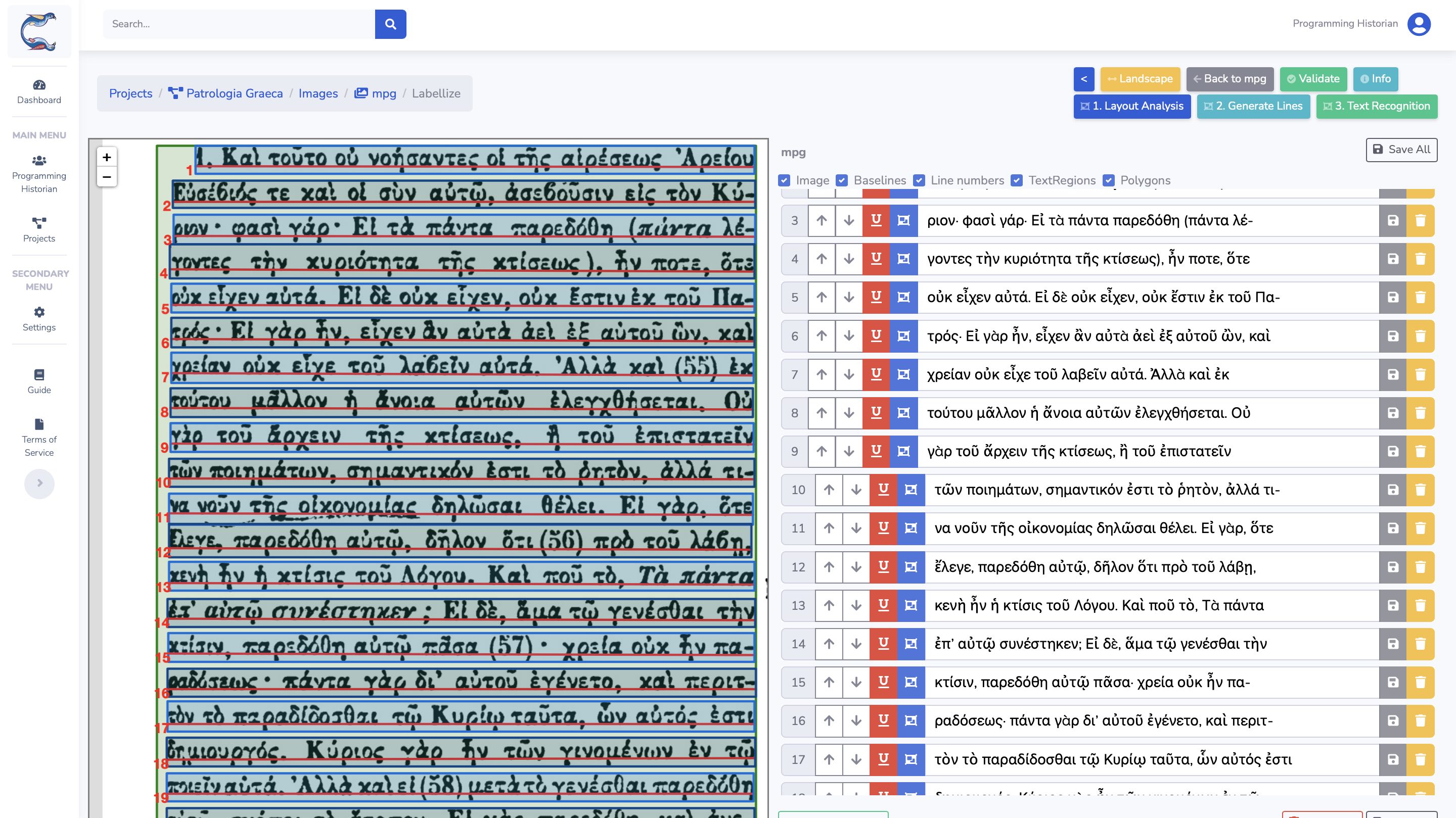
Figure 19 : Calfa Vision - Transcription du texte
La transcription est réalisée ligne à ligne pour correspondre à la vérité terrain dont nous disposons déjà (voir supra). Cette transcription peut être réalisée entièrement manuellement, ou être assistée par l’OCR intégré, ou encore provenir d’une transcription existante et importée. Les lignes 1 et 7 mettent en évidence l’absence de transcription des chiffres dans cet exercice. Les données sont exportées dans un format compatible avec les données précédentes, paire image-texte, sans distorsion des images.
Info -- et en choisissant le format d'export qui convient. Comme détaillé précédemment, afin de bénéficier des données pré-existantes pour renforcer notre apprentissage, nous choisissons l'export par paire image-texte. Aucune distorsion de la baseline n'est appliquée, celle-ci, lorsqu'elle est réalisée, pouvant entraîner une complexité supplémentaire à surmonter, nécessitant davantage de données.
Nous allons donc ici transcrire une, puis deux, puis cinq et enfin dix images, en profitant itérativement d’un nouveau modèle de transcription automatique.
| 0 | 1 | 2 | 5 | 10 | |
|---|---|---|---|---|---|
| CER (%) | 68,13 | 38,45 | 6,97 | 5,42 | 4,19 |
Deux images suffisent à obtenir un CER inférieur à 7 % et une transcription automatique exploitable. Le modèle n’est bien sûr pas encore très polyvalent à toute la variété de la PG mais la transcription de nouvelles pages s’en trouve accélérée. Dans les simulations réalisées à plus grande échelle, en conservant cette approche itérative, nous aboutissons à un CER de 1,1 % après 50 pages transcrites.

Figure 20 : Résultat final sur la PG
Ouverture sur le manuscrit et conclusion
La transcription de documents manuscrits – mais aussi celle de manuscrits anciens, d’archives modernes, etc. – répond tout à fait à la même logique et aux mêmes enjeux : partir de modèles existants, que l’on va spécialiser aux besoins d’un objectif, selon un certain cahier des charges.
La plateforme a ainsi été éprouvée sur un nouvel ensemble graphique, celui des écritures maghrébines, écritures arabes qui représentent classiquement un écueil majeur pour les HTR. L’approche itérative qui a été appliquée a permis d’aboutir à la transcription de 300 images, constituant le dataset RASAM42, sous la supervision du Groupement d’Intérêt Scientifique Moyen-Orient et mondes musulmans (GIS MOMM), de la BULAC et Calfa. En partant de zéro pour les écritures maghrébines, cette approche de fine-tuning à l’aide d’une interface de transcription comme celle présentée dans ce tutoriel a démontré sa pertinence : le temps nécessaire à la transcription est ainsi réduit de plus de 42 % en moyenne (voir figure 21).
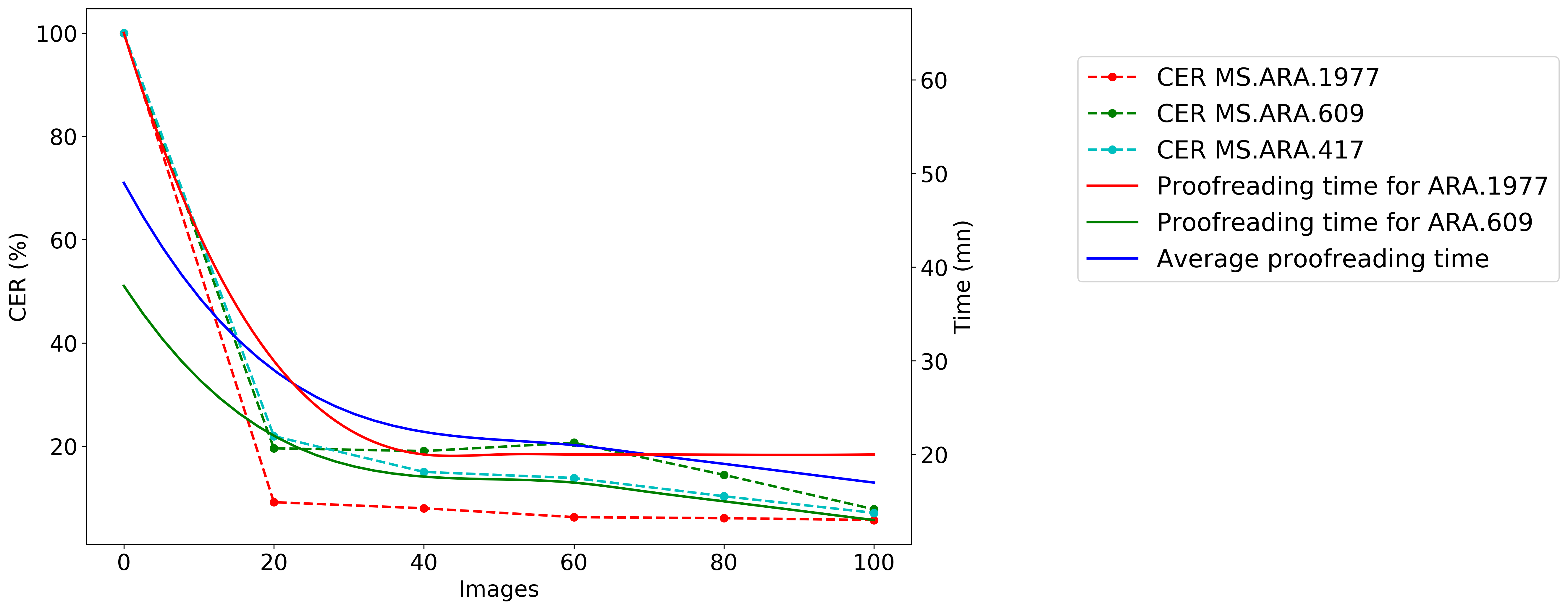
Figure 21 : RASAM Dataset, Springer 2021 - Évolution du CER et du temps de relecture
Dans ce tutoriel, nous avons décrit les bonnes pratiques pour la transcription rapide de documents en systèmes graphiques ou en langues peu dotés via la plateforme Calfa Vision. La qualification de « peu dotée » peut concerner un grand nombre et une large variété de documents, y compris, comme ce fut le cas ici, dans des langues pour lesquelles il existe pourtant déjà des données. La qualité des données ne doit pas être négligée par rapport à la quantité, et l’utilisateur ou l’utilisatrice pourra dès lors envisager une transcription, y compris pour des documents inédits.
Des questions plus techniques peuvent se poser selon la plateforme utilisée et un accompagnement dans les projets de transcription peut alors être proposé. Définir précisément les besoins d’un traitement OCR/HTR est essentiel au regard des enjeux, la transcription automatique étant une porte d’entrée à tout projet de valorisation et de traitement de collections.
Les données générées pour cet article et dans le cadre du projet CGPG sont disponibles sur Zenodo (https://doi.org/10.5281/zenodo.7296539). La rédaction de cet article a été réalisée en utilisant la version 1.0.0 du jeu de données. Le modèle d’analyse de la mise en page reste disponible sur Calfa Vision sous l’appellation Greek printed (Patrologia Graeca), modèle régulièrement renforcé.
Notes de fin
-
Les volumes de la PG sont disponibles au format PDF, par exemple sous les adresses https://patristica.net/graeca et https://www.roger-pearse.com/weblog/patrologia-graeca-pg-pdfs. Mais une partie seulement de la PG est encodée sous un format « textes », par exemple dans le corpus du Thesaurus Linguae Graecae. ↩
-
L’association Calfa (Paris, France) et le projet GREgORI (université catholique de Louvain, Louvain-la-Neuve, Belgique) développent conjointement des systèmes de reconnaissance de caractères et des systèmes d’analyse automatique des textes : lemmatisation, étiquetage morphosyntaxique, POS_tagging. Ces développements ont déjà été adaptés, testés et utilisés pour traiter des textes en arménien, en géorgien et en syriaque. Le projet CGPG poursuit ces développements dans le domaine du grec en proposant un traitement complet – OCR et analyse – de textes édités dans la PG. Pour des exemples de traitement morphosyntaxique du grec ancien menés conjointement : Kindt, Bastien, Chahan Vidal-Gorène, et Saulo Delle Donne. « Analyse automatique du grec ancien par réseau de neurones. Évaluation sur le corpus De Thessalonica Capta ». BABELAO 10-11 (2022), 525-550. https://doi.org/10.14428/babelao.vol1011.2022.65073. ↩
-
Voir par exemple Alex Graves et Jürgen Schmidhuber. (2008). « Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks ». In Advances in Neural Information Processing Systems 21 (NIPS 2008), dirigé par Daphne Koller et al. (S.l. : Curran Associates, 2009) https://papers.nips.cc/paper/2008/file/66368270ffd51418ec58bd793f2d9b1b-Paper.pdf. ↩
-
Stuart Snydman, Robert Sanderson, et Tom Cramer. « The International Image Interoperability Framework (IIIF) : A community & technology approach for web-based images ». Archiving Conference, 2015, 16‑21. ↩
-
Ryad Kaoua, Xi Shen, Alexandra Durr, Stavros Lazaris, David Picard, et Mathieu Aubry. « Image Collation : Matching Illustrations in Manuscripts ». In Document Analysis and Recognition – ICDAR 2021, dirigé par Josep Lladós, Daniel Lopresti, et Seiichi Uchida. Lecture Notes in Computer Science, vol. 12824. Cham : Springer, 2021, 351‑66. https://doi.org/10.1007/978-3-030-86337-1_24. ↩
-
Emanuela Boros, Alexis Toumi, Erwan Rouchet, Bastien Abadie, Dominique Stutzmann, et Christopher Kermorvant. « Automatic Page Classification in a Large Collection of Manuscripts Based on the International Image Interoperability Framework ». In Document Analysis and Recognition - ICDAR 2019, 2019, 756‑62, https://doi.org/10.1109/ICDAR.2019.00126. ↩
-
Mathias Seuret, Anguelos Nicolaou, Dalia Rodríguez-Salas, Nikolaus Weichselbaumer, Dominique Stutzmann, Martin Mayr, Andreas Maier, et Vincent Christlein. « ICDAR 2021 Competition on Historical Document Classification ». In Document Analysis and Recognition – ICDAR 2021, dirigé par Josep Lladós, Daniel Lopresti, et Seiichi Uchida. Lecture Notes in Computer Science, vol 12824. Cham : Springer, 2021, 618‑34. https://doi.org/10.1007/978-3-030-86337-1_41. ↩
-
Il existe une grande variété de jeux de données (ou datasets) existants réalisés dans divers cadres de recherche, les personnes intéressées et à la recherche de données pourront notamment trouver un grand nombre de données disponibles dans le cadre de l’initiative HTR United. Alix Chagué, Thibault Clérice, et Laurent Romary. « HTR-United : Mutualisons la vérité de terrain ! », DHNord2021 - Publier, partager, réutiliser les données de la recherche : les data papers et leurs enjeux, Lille, MESHS, 2021. https://hal.archives-ouvertes.fr/hal-03398740. ↩
-
En particulier, le lectorat pourra trouver un grand nombre de données pour le français médiéval homogènes dans le cadre du projet CREMMA (Consortium pour la Reconnaissance d’Écriture Manuscrite des Matériaux Anciens). Ariane Pinche. « HTR Models and genericity for Medieval Manuscripts ». 2022. https://hal.archives-ouvertes.fr/hal-03736532/. ↩
-
Nous pouvons par exemple citer le programme « Scripta-PSL. Histoire et pratiques de l’écrit » qui vise notamment à intégrer dans les humanités numériques une grande variété de langues et écritures anciennes et rares ; l’Ottoman Text Recognition Network pour le traitement des graphies utilisées lors de la période ottomane ; ou encore le Groupement d’Intérêt Scientifique Moyen-Orient et mondes musulmans (GIS MOMM) qui, en partenariat avec la BULAC et Calfa, produit des jeux de données pour le traitement des graphies arabes maghrébines. ↩
-
Le crowdsourcing peut prendre la forme d’ateliers dédiés avec un public restreint, mais est aussi largement ouvert à tout public bénévole qui souhaite occasionnellement transcrire des documents, comme le propose la plateforme Transcrire déployée par Huma-Num. ↩
-
Christian Reul, Dennis Christ, Alexander Hartelt, Nico Balbach, Maximilian Wehner, Uwe Springmann, Christoph Wick, Christine Grundig, Andreas Büttner, et Frank Puppe. « OCR4all—An open-source tool providing a (semi-)automatic OCR workflow for historical printings ». Applied Sciences 9, nᵒ 22 (2019) : 4853. ↩
-
Chahan Vidal-Gorène, Boris Dupin, Aliénor Decours-Perez, et Thomas Riccioli. « A modular and automated annotation platform for handwritings : evaluation on under-resourced languages ». In International Conference on Document Analysis and Recognition - ICDAR 2021, dirigé par Josep Lladós, Daniel Lopresti, et Seiichi Uchida. 507-522. Lecture Notes in Computer Science, vol. 12823. Cham : Springer, 2021. https://doi.org/10.1007/978-3-030-86334-0_33. ↩
-
Jean-Baptiste Camps, Chahan Vidal-Gorène, Dominique Stutzmann, Marguerite Vernet, et Ariane Pinche, « Data Diversity in handwritten text recognition, Challenge or opportunity? », article présenté lors de la conférence Digital Humanities 2022 (DH 2022), Tokyo, 27 juillet 2022. ↩
-
Pour un exemple de stratégie de fine-tuning appliquée à des graphies arabes manuscrites. Bulac Bibliothèque, Maxime Ruscio, Muriel Roiland, Sarah Maloberti, Lucas Noëmie, Antoine Perrier, et Chahan Vidal-Gorène. « Les collections de manuscrits maghrébins en France (2/2) », Mai 2022, HAL, https://medihal.archives-ouvertes.fr/hal-03660889. ↩
-
Jean-Baptiste Camps. « Introduction à la philologie computationnelle. Science des données et science des textes : De l’acquisition du texte à l’analyse », présenté dans le cadre de la formation en ligne Étudier et publier les textes arabes avec le numérique, 7 décembre 2020, YouTube, https://youtu.be/DK7oxn-v0YU. ↩
-
Dans une architecture word-based, chaque mot constitue une classe à part entière. Si cela entraîne mécaniquement une démultiplication du nombre de classes, le vocabulaire d’un texte est en réalité suffisamment homogène et réduit pour envisager cette approche. Elle n’est pas incompatible avec une architecture character-based complémentaire. ↩
-
Jean-Baptiste Camps, Chahan Vidal-Gorène, et Marguerite Vernet. « Handling Heavily Abbreviated Manuscripts: HTR engines vs text normalisation approaches ». In International Conference on Document Analysis and Recognition - ICDAR 2021, dirigé par Elisa H. Barney Smith, Umapada Pal. Lecture Notes in Computer Science, vol. 12917. Cham : Springer, 2021, 507-522. https://doi.org/10.1007/978-3-030-86159-9_21. ↩
-
Pour davantage de manipulations Unicode en grec ancien : https://jktauber.com/articles/python-unicode-ancient-greek/ [consulté le 12 février 2022]. ↩
-
À titre d’exemple, concernant la normalisation, avec NFD, nous obtenons un CER (voir plus loin) de 22,91 % avec dix pages contre 4,19 % avec la normalisation NFC. ↩
-
Par défaut, Calfa Vision va procéder au choix de normalisation le plus adapté au regard du jeu de données fourni, afin de simplifier la tâche de reconnaissance, sans qu’il soit nécessaire d’intervenir manuellement. La normalisation est toutefois paramétrable avant ou après le chargement des données sur la plateforme. ↩
-
Pour accéder aux jeux de données mentionnés : greek_cursive, gaza-iliad et voulgaris-aeneid. ↩
-
Matteo Romanello, Sven Najem-Meyer, et Bruce Robertson. « Optical Character Recognition of 19th Century Classical Commentaries: the Current State of Affairs ». In The 6th International Workshop on Historical Document Imaging and Processing (2021): 1-6. Dataset également disponible sur Github. ↩
-
Le modèle n’est pas évalué sur la PG à ce stade. Le taux d’erreur est obtenu sur un ensemble de test extrait de ces trois datasets. ↩
-
Thomas M. Breuel. « The OCRopus open source OCR system ». In Document recognition and retrieval XV, (2008): 6815-6850. International Society for Optics and Photonics. ↩
-
La co-existence de données de type bounding box et de type baseline correspond à une évolution technique et chronologique. Le système OCR OCRopy, pionnier dans les OCR par réseaux de neurones, utilise des bounding box, excluant de fait tout document courbé. Ce système nécessite le pré-traitement des images avant d’envisager toute reconnaissance. ↩
-
Vidal-Gorène, Dupin, Decours-Perez, Riccioli. « A modular and automated annotation platform for handwritings: evaluation on under-resourced languages », 507-522. ↩
-
Camps, Vidal-Gorène, et Vernet. « Handling Heavily Abbreviated Manuscripts: HTR engines vs text normalisation approaches », 507-522. ↩
-
Vidal-Gorène, Dupin, Decours-Perez, Riccioli. « A modular and automated annotation platform for handwritings: evaluation on under-resourced languages », 507-522. ↩
-
L’étape de reconnaissance de texte, OCR ou HTR, est proposée sur demande et dans le cadre de projets dédiés ou partenaires. Les deux premières étapes du traitement sont quant à elles gratuites et utilisables sans limite. ↩
-
On distingue généralement deux types d’évaluation d’un modèle OCR/HTR : une évaluation in-domain, c’est à dire que l’ensemble de test est similaire aux données d’entraînement, et une évaluation out-of-domain, avec des données complètement nouvelles pour le modèle. Classiquement, un test in-domain donne des résultats élevés car le modèle est très spécifiquement entraîné sur la tâche évaluée, même si les données d’entraînement et de test sont bien sûr disjointes. Ce test permet notamment d’évaluer la pertinence d’un modèle spécialisé. Un test out-of-domain donne des informations sur la polyvalence et la « généralité » d’un modèle, car celui-ci est évalué sur des données absentes et inconnues de ses données d’entraînement – par exemple une nouvelle main ou un nouveau type d’écriture. ↩
-
Francesco Lombardi, et Simone Marinai. « Deep Learning for Historical Document Analysis and Recognition—A Survey ». J. Imaging 2020, 6(10), 110. https://doi.org/10.3390/jimaging6100110. ↩
-
Camps, Vidal-Gorène, et Vernet. « Handling Heavily Abbreviated Manuscripts: HTR engines vs text normalisation approaches », 507-522. ↩
-
Chahan Vidal-Gorène, Noëmie Lucas, Clément Salah, Aliénor Decours-Perez, et Boris Dupin. « RASAM–A Dataset for the Recognition and Analysis of Scripts in Arabic Maghrebi ». In International Conference on Document Analysis and Recognition - ICDAR 2021, dirigé par Elisa H. Barney Smith, Umapada Pal. Lecture Notes in Computer Science, vol. 12916. Cham : Springer, 2021, 265-281. https://doi.org/10.1007/978-3-030-86198-8_19. ↩
-
Ibid. ↩
-
Vidal-Gorène, Dupin, Decours-Perez, Riccioli. « A modular and automated annotation platform for handwritings: evaluation on under-resourced languages », 507-522. ↩
-
Phillip Benjamin Ströbel, Simon Clematide, et Martin Volk. « How Much Data Do You Need? About the Creation of a Ground Truth for Black Letter and the Effectiveness of Neural OCR ». In Proceedings of the 12th Language Resources and Evaluation Conference, 3551-3559. Marseille: ACL Anthology, 2020. https://aclanthology.org/2020.lrec-1.436.pdf. ↩
-
Ibid. ↩
-
Bastien Kindt et Vidal-Gorène Chahan, « From Manuscript to Tagged Corpora. An Automated Process for Ancient Armenian or Other Under-Resourced Languages of the Christian East ». Armeniaca. International Journal of Armenian Studies 1, 73-96, 2022. http://doi.org/10.30687/arm/9372-8175/2022/01/005 ↩
-
Vidal-Gorène, Lucas, Salah, Decours-Perez, et Dupin. « RASAM–A Dataset for the Recognition and Analysis of Scripts in Arabic Maghrebi », 265-281. ↩
-
Vidal-Gorène, Dupin, Decours-Perez, Riccioli. « A modular and automated annotation platform for handwritings: evaluation on under-resourced languages », 507-522. ↩
-
Le dataset RASAM est disponible au format PAGE (XML) sur Github. Il est le résultat d’un hackathon participatif ayant regroupé quatorze personnes organisé par le GIS MOMM, la BULAC, Calfa, avec le soutien du ministère français de l’enseignement supérieur et de la recherche. ↩