
Conteúdos
- Estrutura do estudo e objetivos da lição
- Introdução
- O caso das línguas e grafias não latinas
- Dados sim, mas para quê?
- Cadeia de processamento: produção de conjuntos de dados e processamento de documentos
- Que anotações de layout realizar?
- Abertura do manuscrito e conclusão
- Notas de fim
Estrutura do estudo e objetivos da lição
Este tutorial apresenta estratégias e boas práticas para criar dados relevantes e em quantidade suficiente em projetos de reconhecimento de caracteres para reconhecimento de texto em grafias geralmente pouco recorrentes. O tutorial é aplicado no tratamento de um documento impresso, a Patrologia Grega (PG), e propõe uma aproximação ao tratamento de um documento manuscrito da Bibliothèque Universitaire des Langues et Civilisations (BULAC) escrito em árabe magrebino. Estes dois exemplos são bastante específicos, mas a estratégia global apresentada e as ferramentas e abordagens introduzidas podem ser adaptadas ao tratamento de todo o tipo de documentos digitais, em particular de línguas não latinas, às quais uma abordagem em massa é difícil de aplicar.
A PG é uma coleção de reimpressões de textos patrísticos, teológicos e historiográficos publicados em Paris por Jacques Paul Migne (1800-1875) entre 1857 e 1866. Conta com 161 volumes e reúne textos produzidos entre os século I e XV, iniciando com os escritos de Clemente de Roma (papa entre 92 e 99) e terminando com os escritos do Cardeal Jean Bessarion (1403-1472). A PG não contém apenas textos teológicos – longe disso – mas também muitos textos exegéticos, históricos, hagiográficos, legislativos, enciclopédicos, poéticos e, até, românticos. Na realidade, nela encontramos grande parte da literatura bizantina, que constitui a síntese entre a cultura grega e a herança cristã. Não obstante o seu interesse inquestionável para a pesquisa, uma parte destes textos não foram reeditados após o final do século XIX ou não estão atualmente acessíveis numa versão digital.1 O projeto Calfa GREgORI Patrologia Graeca (CGPG) foi criado para preencher esta lacuna. A associação Calfa e o projeto GREgORI, academicamente coordenado pelo Professor Jean-Marie Auwers (Université Catholique de Louvain), comprometeram-se em tornar estes textos acessíveis online e em aumentar o seu conteúdo, num formato interoperável, através de abordagens automáticas de OCR e de análises lexicais e morfossintáticas.2

Figura 0. Exemplo da PG (PG 125, c. 625-626) |

Figura 0. Exemplo da PG (PG 125, c. 1103-1104) |
No final desta lição, o leitor será capaz de estabelecer uma estratégia e especificações adaptadas ao reconhecimento de caracteres de documentos atualmente não cobertos pelos modelos standard de OCR e HTR geralmente disponíveis. Esta estratégia poderá ser desenvolvida em projetos colaborativos. A lição introdu-lo também ao funcionamento de uma plataforma de anotação de documentos, a Calfa Vision, sem no entanto excluir outras plataformas. O leitor encontrará, portanto, metodologias transponíveis. Por fim, a lição introduz, por exemplo, conceitos de “machine learning”. Esta não necessita de pré-requisitos particulares: são apresentados alguns exemplos em python e em XML, mas que são adicionados a esta lição como forma de ilustração. Da mesma forma, os princípios subjacentes a machine learning são introduzidos do zero, por vezes vulgarizados e não precisam de conhecimentos prévios. No entanto, é recomendável aprender sobre as suas noções básicas para treinar redes neurais (noções de conjuntos de dados, treinamento e teste de conjuntos) para aproveitar o máximo desta lição.3
Introdução
O reconhecimento de caracteres
A transcrição automática de documentos é, atualmente, uma etapa recorrente nos projetos de humanidades digitais ou de valorização de coleções de bibliotecas digitais. Tal insere-se numa grande dinâmica internacional de digitalização dos documentos, facilitada pelo IIIF (International Image Interoperability Framework4), que permite a troca, comparação e estudo de imagens através de um único protocolo implementado entre bibliotecas e interfaces compatíveis. Se esta dinâmica dá um acesso privilegiado e instantâneo a fundos, até então de acesso restrito, a grande quantidade de dados atrapalha as abordagens que podemos ter aos documentos textuais. Processar tal quantidade manualmente é de difícil previsão e esta é a razão pela qual muitas abordagens em humanidades digitais surgiram nos últimos anos: além do reconhecimento de caracteres, permite o conhecimento em larga escala de padrões iluminados,5 a classificação automática de páginas de manuscritos6 e, ainda, tarefas de codificação como a identificação de um autor, a datação de um manuscrito ou a sua origem de produção,7 para mencionar os exemplos mais evidentes. No reconhecimento de caracteres, como na filologia computacional, as numerosas abordagens e metodologias produzem resultados que já podem ser utilizados, desde que existam dados de qualidade para treinar os sistemas.
A lição apresenta uma abordagem baseada em “deep learning”, amplamente utilizada em inteligência artificial. No nosso caso, consiste simplesmente em fornecer a uma rede neural uma grande amostra de exemplos de textos transcritos com o objetivo de treinar e acostumar a rede ao reconhecimento de uma caligrafia. A aprendizagem, no nosso caso dita supervisionada uma vez que fornecemos ao sistema todas as informações necessárias ao seu processamento (ou seja, uma descrição completa dos resultados esperados), é alcançada por exemplo e por frequência.
Hoje, é certamente possível treinar redes neurais para analisar um modelo muito específico ou para processar um conjunto de documentos particular, fornecendo exemplos espectáveis por essas redes. Assim, será suficiente fornecer a uma rede neural a transcrição exata de uma página de manuscrito ou a localização precisa das zonas de interesse num documento, para que a rede reproduza essa tarefa (veja a figura 1).
No estado da arte existe uma grande variedade de arquiteturas e abordagens utilizadas. No entanto, para haver eficácia e robustez, essas redes neurais devem ser treinadas com grandes conjuntos de dados. É preciso, portanto, anotar, muitas vezes manualmente, os documentos semelhantes àqueles que desejamos reconhecer (aquilo a que podemos chamar de “ground truth”).
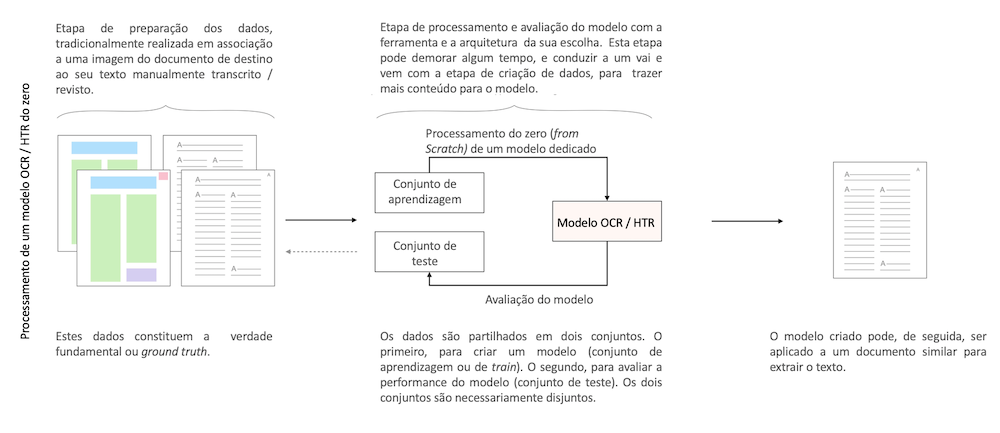
Figura 1: Detalhe das etapas clássicas para treinamento de um modelo OCR ou HTR.
O caso das línguas e grafias não latinas
Anotar documentos manualmente, escolher uma arquitetura neural adaptada às suas necessidades e observar/avaliar a aprendizagem de uma rede neural para criar um modelo pertinente, etc., são atividades caras e demoradas que, com frequência, necessitam de investimento e de experiência em machine learning, condições pouco adaptadas a um processamento de documentos em massa e rápido. O deep learning é, portanto, uma abordagem que necessita intrinsecamente da constituição de um “corpus” substancial, que nem sempre é fácil de obter, não obstante a multiplicidade de plataformas dedicadas (ver abaixo). Como tal, outras estratégias devem ser colocadas em prática, em particular no caso das línguas ditas pouco usuais.
De facto, se a massa crítica dos dados para tratamento de manuscritos ou documentos impressos em alfabeto latino parece ser bem conseguida,8 com uma variedade de formas, fontes e modelos representados e representativos das necessidades clássicas das instituições em matéria de HTR e de OCR, tal torna-se menos evidente para outros alfabetos. Encontramo-nos, assim, numa situação em que as instituições patrimoniais digitalizam e disponibilizam cópias digitais de documentos, mas onde estas permanecem “adormecidas” porque não podem ou dificilmente podem ser pesquisadas por sistemas automáticos. Por exemplo, várias instituições, como a Biblioteca Nacional de França (BnF) através do seu interface Gallica, oferecem versões textuais dos documentos escritos maioritariamente em alfabeto latino de forma a permitir a pesquisa no texto completo, funcionalidade infelizmente indisponível para documentos em árabe.
Hoje, uma língua ou uma grafia ainda podem ser consideradas pouco usuais a vários níveis:
-
uma falta de disponibilidade ou de existência de dados: trata-se do ponto mais evidente. Muitas grafias não são representadas digitalmente, no sentido de dados utilizáveis, mesmo que se formem redes institucionais para integrá-las nessa transição digital9
-
uma grande especialização num conjunto de dados: pelo contrário, se existirem dados para um determinado idioma, estes podem ser muito especializados, focados no objetivo da equipa que os produziu (por exemplo: modernização da ortografia de uma grafia antiga ou, ainda, utilização de uma noção de linha específica), limitando a sua reprodutibilidade e a sua exploração num novo projeto. Como consequência, ainda que existam modelos gratuitos e abertos (ver abaixo) para uma língua ou documento, tal pode não ser imediatamente conveniente de acordo com as necessidades do novo projeto
-
um número potencialmente reduzido de especialistas capazes de transcrever e anotar os dados rapidamente. Ainda que as iniciativas de “crowdsourcing” sejam muitas vezes colocadas em prática para grafias latinas,10 dificilmente se poderá aplicar a mesma metodologia para manuscritos antigos que necessitam de uma elevada experiência, frequentemente paleográfica, limitando consideravelmente o número de pessoas que podem produzir os dados
-
uma superespecialização das tecnologias existentes para o alfabeto latino, resultando em abordagens menos adaptadas a outras grafias. Por exemplo, os documentos árabes beneficiarão intuitivamente do reconhecimento global das palavras, em vez de se tentar reconhecer cada caracter de forma independente
-
a necessidade de dispor de conhecimentos de machine learning para fazer um melhor uso das ferramentas de reconhecimento automático de documentos atualmente disponíveis
Estes limites estão ilustrados na figura 2 que evidencia os componentes essenciais para o processamento eficaz de uma grafia ou de uma língua, e que falta, em parte, para aquelas que não são latinas.
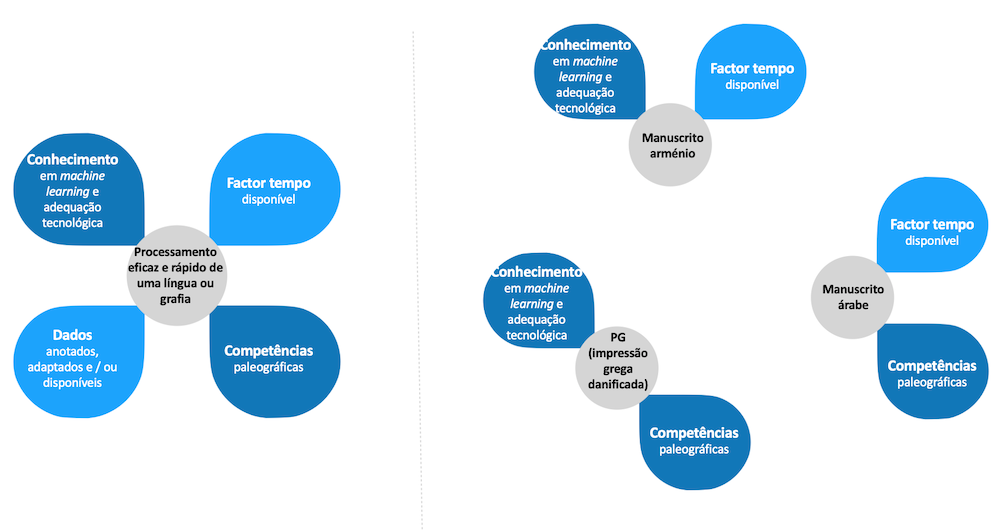
Figura 2: Componentes essenciais para o processamento eficaz de um documento (à esquerda), de que as línguas não latinas são desprovidas (à direita alguns exemplos tratados classicamente na Calfa Vision)
Mas nada disto é insuperável. Se o “pipeline” (cadeia de processamento) clássico, que consiste em trazer massivamente os dados (manualmente) anotados para uma arquitetura neural, se mostra claramente pouco adequado ao processamento em certas línguas, muitas plataformas foram implementadas para facilitar o acesso ao OCR e ao HTR nos últimos anos. Cada uma delas procura jogar com os componentes da figura 2, por exemplo, integrando modelos pré-treinados para realizar o trabalho de transcrição.11 O objetivo dessas plataformas consiste em compensar um dos componentes em falta de forma a permitir o processamento da língua e grafia alvo.
A plataforma mais conhecida é a Transkribus (READ-COOP (em inglês)), utilizada num amplo espectro de línguas, grafias e tipologias documentais. Existem também plataformas institucionais, como a eScriptorium (Université Paris Sciences & Lettres (em inglês)), dedicada a documentos históricos, e a OCR4all (Universität Wurtzbourg (em inglês)), particularmente adaptada a documentos impressos antigos. Por fim, plataformas privadas como a Calfa Vision (Calfa (em inglês)), completam as anteriores com uma multiplicidade de arquiteturas. Esta última integra uma abordagem de especialização iterativa para, a partir de pequenas amostras, superar os problemas mencionados no tratamento de grafias não latinas.12
O objetivo metodológico é aproveitar as funcionalidades de especialização da plataforma de anotação Calfa Vision. Esta integra diferentes arquiteturas neurais de acordo com a língua alvo, de forma a minimizar o investimento em dados, sem esperar que os usuários tenham uma competência particular em machine learning para avaliar os modelos (ver abaixo). O desafio é, portanto, superar o problema da falta de dados através de estratégias de especialização e definição de necessidades.
Dados sim, mas para quê?
O reconhecimento automático de documentos não é possível sem a associação do conhecimento humano à capacidade de processamento do computador. Portanto, fica a nosso cargo um importante trabalho científico para definir os objetivos e os resultados de uma transcrição automática. Assim, muitas questões se colocam no momento de partirmos para a anotação dos nossos documentos:
- Criar dados: qual o volume possível, para que necessidades, para que público e qual a compatibilidade?
- Criador de dados: por quem e em que cronologia?
- Abordagem generalista ou abordagem especializada
- Abordagem quantitativa ou qualitativa
O nosso objetivo é conseguir transcrever automaticamente um conjunto homogéneo de documentos, minimizando o investimento humano na criação de modelos. Portanto, pretendemos criar um modelo especializado (e não generalista) para superar as especificidades do nosso documento. Estas podem ser de várias ordens e podem justificar a criação de um modelo especializado: mão nova, fonte nova, estado de conservação do documento variável, “layout” inédito, necessidade de um conteúdo específico, etc.
“Pipeline” clássico de um OCR/HTR
Etapas de reconhecimento
O trabalho de um OCR ou de um HTR divide-se em várias etapas: análise e compreensão de um layout, reconhecimento do texto e formatação do resultado. A figura 3 resume a maioria das tarefas habitualmente presentes e sobre as quais o usuário tem controlo para adaptar o modelo às suas necessidades. Todas estas funcionalidades podem ser testadas na plataforma Calfa Vision, que nos permite um controlo total do pipeline de reconhecimento.
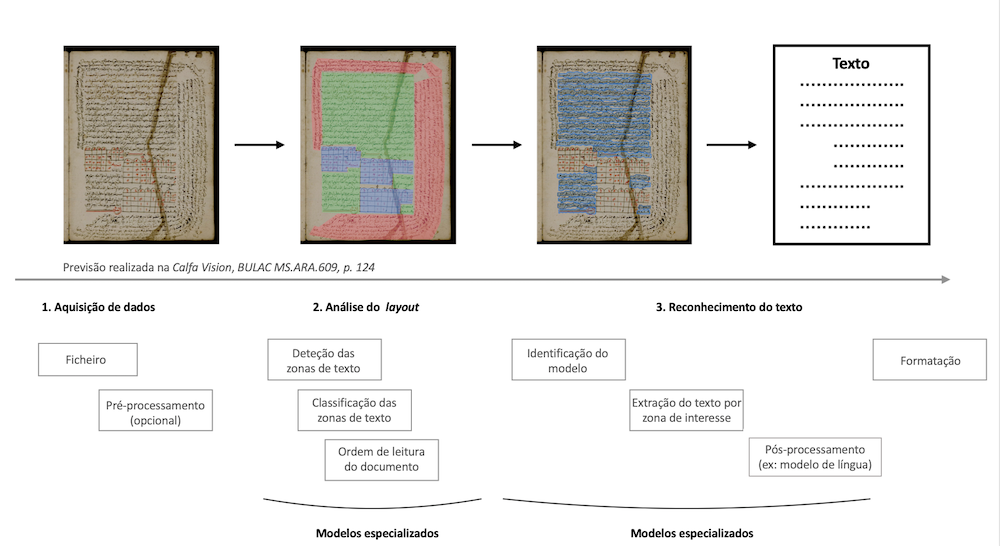
Figura 3: Pipeline comum de um processamento OCR/HTR. As etapas 2 e 3 são especializadas de acordo com as necessidades de um projeto; e a etapa 3 integra abordagens específicas a uma língua/grafia para maximizar os resultados minimizando o investimento.
A figura 3 destaca uma das grandes lacunas do reconhecimento de caracteres: a análise do layout, que pode ser especializada para reconhecer apenas uma ou mais regiões de interesse num documento e concentrar a extração de linhas nessas regiões. A construção de um modelo de análise eficiente do layout é um dos grandes desafios do processamento de novas coleções (ver abaixo).
A especialização de modelos (ou “fine-tuning”)
O fine-tuning de um modelo consiste em refinar e adaptar os parâmetros de um modelo pré-treinado numa tarefa semelhante à nossa problemática. Esta abordagem permite limitar consideravelmente o número de dados necessários, por oposição à criação de um modelo do zero (“from scratch”), uma vez que o essencial do modelo já se encontra construído. Por exemplo, podemos partir de um modelo treinado em latim – uma língua para a qual dispomos de um grande número de dados – para obter rapidamente um modelo para o francês médio – para o qual os os conjuntos de dados são mais limitados. Uma vez que estas duas línguas partilham um grande número de representações gráficas, esse trabalho de especialização permitirá conduzir a modelos OCR/HTR rapidamente utilizáveis.13
A diferença entre um modelo treinado do zero e uma estratégia de fine-tuning está descrita nas figuras 4 e 5.
Figura 4: Treinamento de um modelo OCR/HTR do zero.
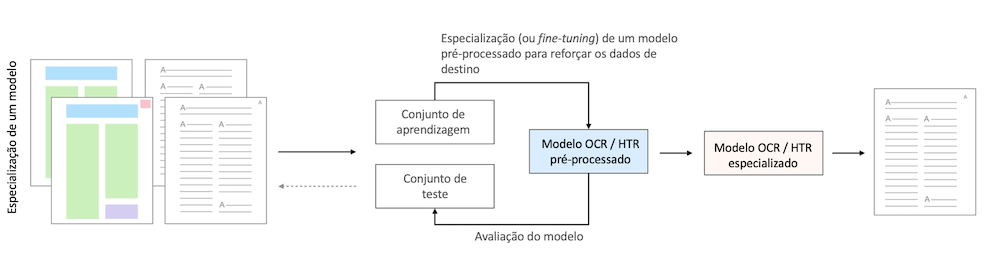
Figura 5: Fine-tuning de um modelo OCR/HTR pré-treinado.
A estratégia de fine-tuning é amplamente desenvolvida e utilizada nos projetos que recorrem ao reconhecimento de caracteres.14
O fine-tuning iterativo dos modelos na Calfa Vision
Na prática, é difícil prever o volume de dados necessários ao fine-tuning ou no treinamento do zero de um modelo (ver abaixo). Treinar, avaliar, re-anotar documentos e assim por diante, até que um modelo satisfatório seja obtido, consome tempo e requer, também, uma sólida experiência em machine learning. De forma a ultrapassar este problema, a plataforma Calfa Vision integra nativamente uma estratégia de fine-tuning iterativa autónoma (ver a figura 6) conforme o usuário faz correções.
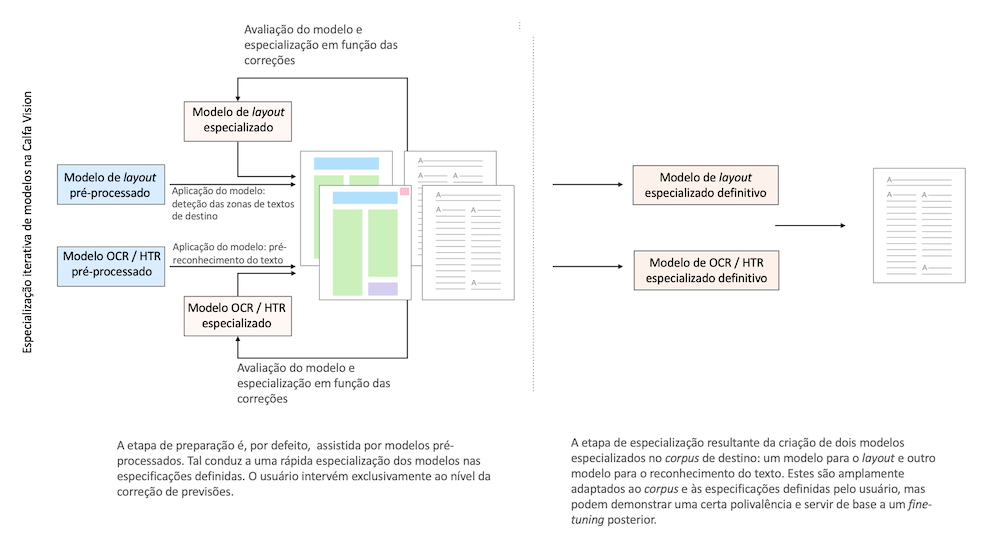
Figura 6: Estratégia de fine-tuning iterativa na Calfa Vision.
Com efeito, a plataforma propõe um grande número de modelos pré-treinados em diversas tarefas (estudo de documentos impressos, análise de documentos manuscritos orientais, leitura de documentos em xilogravura chinesa, etc.) que estão prontos para serem especializados nas tarefas do usuário, ao nível do layout e do reconhecimento de texto.
Definição de necessidades
Se hoje pudermos considerar o reconhecimento de caracteres como um problema amplamente resolvido para as grafias latinas, documentos numa única língua e layout simples, com taxas de erro inferiores a 2%,15 o resultado final pode não ser utilizável (ver a figura 7).

Figura 7: Reconhecimento de caracteres e do texto. BER ms or. quart. 304, 101v, Staatsbibliothek zu Berlin.
A figura 7 destaca este fenómeno: treinando uma arquitetura especializada em reconhecimento de caracteres, obtemos um CER (Character Error Rate. Em português Taxa de Erro de Caracter) de 0%, ou seja, trata-se de um reconhecimento perfeito. Em contrapartida:
- O layout por colunas não foi detetado corretamente, ficando-se apenas com um bloco de texto
- A scriptio continua do manuscrito, muito respeitada pelo HRT, resulta num texto desprovido de espaço e dificilmente acessível a um humano
- O texto, em arménio clássico, compreende uma grande quantidade de abreviaturas que não são desenvolvidas no resultado final. Ainda que o texto produzido corresponda à imagem do manuscrito, a pesquisa neste torna-se de facto extremamente limitada
Áreas de interesse
No âmbito do tratamento da PG, estamos interessados apenas no texto grego dos PDF à nossa disposição (a encarnado nas figuras 8a e 8b). Felizmente, somos confrontados com um layout relativamente denso e complexo, com uma alternância de colunas em grego e em latim, de textos, por vezes, abrangendo duas colunas (aqui a azul), títulos corridos, notas de rodapé e marcas de parágrafos.

Figura 8a: Layout da PG (PG 123, c. 359-360).

Figura 8b: Layout da PG (PG 125, c. 625-626).
Este layout não seria um problema maior se não estivéssemos interessados com a discriminação das áreas de texto. No entanto, não nos preocupamos com o texto em latim e queremos obter um resultado o mais fiel possível, sem misturar as línguas ou sem prováveis confusões do modelo. Portanto, identificamos a necessidade de criação de um modelo de layout especializado.
Escolha de transcrição e codificação
Somos totalmente livres para escolhermos uma transcrição que não corresponda exatamente ao conteúdo da imagem. Por exemplo, as experiências no manuscrito em latim demonstraram que arquiteturas de reconhecimento “word-based” (em português, baseada em palavra),16 como aquelas integradas na Calfa Vision, conseguem desenvolver formas abreviadas com uma taxa de erro inferior a 3%.17
Aqui, estamos a trabalhar com grego antigo, com muitos diacríticos.
| Sinais | Códigos | Nomes em inglês | |
|---|---|---|---|
| Spiritus (Espíritos) | |||
| spiritus lenis | ᾿ | U+1FBF | Greek Psili |
| spiritus asper | ῾ | U+1FFE | Greek Dasia |
| Acentos | |||
| Acento agudo | ´ | U+1FFD | Greek Oxia |
| Acento grave | ` | U+1FEF | Greek Varia |
| Til | ῀ | U+1FC0 | Greek Perispomeni |
| Outros | |||
| Trema | ¨ | U+00A8 | Greek Dialytika |
| Iota subscrito | ι | U+1FBE | Greek Hypogegrammeni |
| Coroa | ᾽ | U+1FBD | Greek Koronis |
| … |
Os diacríticos combinam-se acima das vogais ou imediatamente antes das vogais maiúsculas, por exemplo: Ἄ, Ἆ. Os espíritos também podem aparecer acima da consoante ρ (rho) - ῤ, ῥ e Ῥ. O iota é colocado sob as vogais α (alfa), η (eta), ω (omega) - ᾆ, ῃ, ῷ, etc. -, encimadas ou não por outros diacríticos. Tendo em consideração as combinações possíveis desses diacríticos e a mudança no caso das letras do alfabeto grego, a letra α (alfa) pode reagrupar até 44 glifos: Α, α, Ἀ, ἀ, Ἁ, ἁ, Ἂ, ἂ, Ἃ, ἃ, Ἄ, ἄ, Ἅ, ἅ, Ἆ, ἆ, Ἇ, ἇ, Ὰ, ὰ, Ά, ά, ᾈ, ᾀ, ᾉ, ᾁ, ᾊ, ᾂ, ᾋ, ᾃ, ᾌ, ᾄ, ᾍ, ᾅ, ᾎ, ᾆ, ᾏ, ᾇ, ᾲ, ᾼ, ᾳ, ᾴ, ᾶ e ᾷ (tabela completa do Unicode do grego antigo (em inglês e grego)).
Consequência: dependendo da normalização Unicode (em francês) considerada, um caracter grego pode ter vários valores diferentes, os quais podemos facilmente converter em python.
char1 = "ᾧ"
char1
>>> ᾧ
len(char1)
>>> 1
char2 = "\u03C9\u0314\u0342\u0345" #O mesmo caracter, mas com diacriticos explicitamente descritos em Unicode.
char2
>>> ᾧ
len(char2)
>>> 4
char1 == char2
>>> False
Consequentemente, o problema do reconhecimento de caracteres não é o mesmo dependendo da normalização o aplicada. Num caso, temos apenas uma classe a ser reconhecida, o caracter Unicode ᾧ, enquanto noutro caso queremos obter quatro reconhecimentos - ω + ̔ + ͂ + ͅ-, como podemos verificar abaixo.
print(u'\u03C9', u'\u0314', u'\u0342', u'\u0345')
>>> ω ̔ ͂ ͅ
Existem vários tipos de normalização Unicode: NFC (Normalization Form Canonical Composition), NFD (Normalization Form Canonical Decomposition), NFKC (Normalization Form Compatibility Composition) e NFKD (Normalization Form Compatibility Decomposition), cujos efeitos podem ser vistos com o código abaixo.
from unicodedata import normalize, decomposition
len(normalize("NFC", char1))
>>> 1
len(normalize("NFD", char1))
>>> 4
len(normalize("NFC", char2))
>>> 1
normalize("NFC", char1) == normalize("NFC", char2)
>>> True
## O que nos dá em detalhe:
decomposition(char1)
>>> '1F67 0345'
print(u'\u1F67')
>>> ὧ
decomposition(u'\u1F67')
>>> '1F61 0342'
print(u'\u1F61')
>>> ὡ
decomposition(u'\u1F61')
>>> '03C9 0314'
print(u'\u03C9')
>>> ω
No nosso exemplo, parece que a normalização NFC (e NFKC) permite recombinar um caracter num único caracter Unicode, enquanto a normalização NFD (e NFKD) realiza a decomposição inversa.18 A vantagem destas últimas normalizações é reagrupar todas as materializações de uma letra numa única sigla para tratar a variedade apenas ao nível dos diacríticos.
Assim, que normalização devemos escolher?
Além do aspeto técnico de um caracter isolado, a abordagem ao problema é significativamente diferente dependendo da escolha.
phrase = "ἀδιαίρετος καὶ ἀσχημάτιστος. Συνάπτεται δὲ ἀσυγ-"
len(normalize("NFC", phrase))
>>> 48
len(normalize("NFD", phrase))
>>> 56
As imagens da PG apresentam uma qualidade muito variável, indo dos caracteres legíveis a outros praticamente apagados ou, pelo contrário, muito grossos (ver a figura 9 e a tabela 2). Há, igualmente, presença de resíduo pontual, por vezes ambíguo, com os diacríticos ou pontuações do grego.

Figura 9: Exemplos de gravuras da PG.
Considerar uma normalização NFD ou NFDK permitiria reagrupar cada caracter numa meta classe (por exemplo, α para ά, ᾶ, ou ὰ) e, assim, suavizar a grande variedade na qualidade das imagens. No entanto, parece-nos ambicioso querer considerar o reconhecimento de cada diacrítico separadamente, dada a grande dificuldade em distingui-los, mesmo que apenas para nós mesmos. A nossa escolha é amplamente condicionada por (i) a qualidade da tipografia da PG, muitas vezes medíocre, e (ii) a qualidade da digitalização, como mostra a tabela 2.
| Imagem | Transcrição | Variação de α |
|---|---|---|
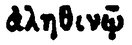
|
ἀληθινῷ | ἀ |
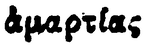
|
ἁμαρτίας | ἁ |

|
μεταφράσαντος | ά |
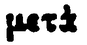
|
μετὰ | ὰ |
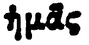
|
ἡμᾶς | ᾶ |
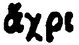
|
ἄχρι | ἄ |
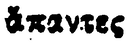
|
ἅπαντες | ἅ |
A tabela 2 mostra a forte ambiguidade presente na PG. Por exemplo, as linhas 1 e 2 parecem incluir erroneamente a letra α, encimada pelo mesmo espírito. O mesmo acontece nas linhas 3 e 4 e nas linhas 6 e 7. Com poucos dados, parece difícil poder reconhecer estes espíritos sem erro, independentemente da letra. Pelo contrário, o reconhecimento direto da letra acentuada pode ser facilitado pelo contexto da sua aparição.
Portanto, optamos por uma normalização de tipo NFC, que terá como consequência uma multiplicação do número de classes. Esta escolha pode resultar na necessidade de transcrição de mais linhas.19
Além disso, não estamos interessados nas notas de rodapé presentes no texto (ver a figura 9) e, portanto, estas não estão presentes na transcrição. Tal criará uma ambiguidade adicional no modelo OCR. Identificamos aqui a necessidade de um modelo de OCR especializado.20
Abordagens arquiteturais e compatibilidade dos dados
Nesta fase, identificámos duas necessidades que condicionam a qualidade esperada dos modelos, o trabalho de anotação e os resultados esperados. Em termos de OCR do grego antigo, também não começamos do zero, pois já existem imagens que foram transcritas e disponibilizadas,21 para um total de 5.100 linhas. Um dataset mais recente, GT4HistComment,22 está igualmente disponível, com imagens de 1835-1894, e layouts mais próximos da PG. O formato dos dados é o mesmo dos conjuntos de dados anteriores (ver abaixo). Não nos reteremos neste dataset devido à presença de uma variedade de alfabetos na ground truth (ver a tabela 3, linha GT4HistComment).
| Fonte | Dados |
|---|---|
greek_cursive |

|
| Ground truth | Αλῶς ἡμῖν καὶ σοφῶς ἡ προηγησαμένη γλῶσσα τοῦ σταυροῦ τὰς ἀκτῖ- |
gaza-iliad |
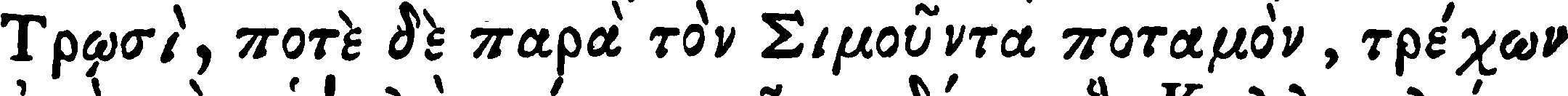
|
| Ground truth | Τρῳσὶ, ποτὲ δὲ παρὰ τὸν Σιμοῦντα ποταμὸν, τρέχων |
voulgaris-aeneid |
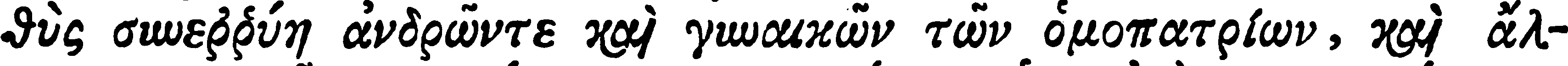
|
| Ground truth | θὺς συνεῤῥύη ἀνδρῶντε καὶ γυναικῶν τῶν ὁμοπατρίων, καὶ ἄλ- |
GT4HistComment |
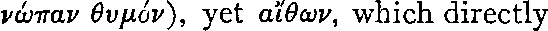
|
| Ground truth | νώπαν θυμόν), yet αἴθων, which directly |
Os dados da tabela 3 mostram uma clara diferença de qualidade e fonte entre esses dados e a PG (ver a tabela 2). Os dados greek cursive apresentam formas gráficas muito diferentes das formas da PG, enquanto os outros documentos são muito mais “limpos”. No entanto, isto fornece um complemento lexical que poderá ser útil mais tarde. A integração e avaliação desses dados na Calfa Vision dá um modelo com uma taxa de erro de 2,24%23 num teste no domínio, modelo no qual se baseará o fine-tuning para o modelo da PG. No entanto, é indispensável considerar um modelo especializado para a PG, de forma a gerir as dificuldades destacadas na figura 9.
Os dados estão disponíveis no formato originalmente proposto por OCRopus,24 ou seja, um par composto por uma imagem de linha e a sua transcrição (ver a tabela 3).
├── dataset
│ ├── 000001.gt.txt
│ ├── 000001.png
│ ├── 000002.gt.txt
│ ├── 000002.png
│ ├── 000003.gt.txt
│ └── 000003.png
Trata-se de um formato antigo, com a linha de texto contida numa “bounding-box” perfeitamente adaptada aos documentos sem curvatura, o que não é bem o caso da PG, cujas digitalizações estão, por vezes, curvadas nas bordas (ver a figura 10). Esses dados também não permitirão treinar um modelo de análise do layout, pois apenas são propostas as imagens das linhas sem precisão da sua localização no documento.

Figura 10: Gestão da curvatura das linhas na Calfa Vision.
Justifica-se uma abordagem por “baselines” (a encarnado na figura 10 encontra-se a “baseline”, em português linha de base), uma vez que permite ter em conta essa curvatura, a fim de se extrair a linha de texto com um polígono de enquadramento (a azul nas figuras 8a e 8b) e não apenas uma bounding-box.25 Desta vez, os dados não são exportados explicitamente como arquivos de linhas, mas sim a informação contida num XML com as coordenadas de cada linha. Atualmente, esta metodologia é universalmente utilizada por todas as ferramentas de anotação de documentos textuais: portanto, pode ser aplicada neste caso.
<?xml version="1.0" ?>
<PcGts xmlns="http://schema.primaresearch.org/PAGE/gts/pagecontent/2013-07-15" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://schema.primaresearch.org/PAGE/gts/pagecontent/2013-07-15 http://schema.primaresearch.org/PAGE/gts/pagecontent/2013-07-15/pagecontent.xsd">
<Metadata>
<Creator>Calfa</Creator>
<Created>2022-08-23T14:48:18+00:00</Created>
</Metadata>
<Page imageFilename="grc_grna_or_409.jpg" imageHeight="3506" imageWidth="1686">
<TextRegion id="52467" custom="structure {type:col_greek;}">
<Coords points="193,225 147,667 171,3259 1525,3269 1505,246"/>
<TextLine id="629162">
<Coords points="241,264 241,317 239,331 1465,344 1469,329 1467,278 241,264"/>
<Baseline points="243,319 1471,331"/>
<TextEquiv>
<Unicode>Βʹ. Καὶ ἵνα γε καθ´ ὁδὸν ὁ λόγος ἡμῖν προΐῃ, περὶ</Unicode>
</TextEquiv>
</TextLine>
<TextLine id="629163">
<Coords points="1479,407 1479,368 1036,348 1034,348 185,354 185,395 183,401 1475,412 1479,407"/>
<Baseline points="187,396 1480,409"/>
<TextEquiv>
<Unicode>τῆς δειλίας προτέρας οὔσης καὶ διαλέξομαι· οὐδὲ γὰρ</Unicode>
</TextEquiv>
</TextLine>
<TextLine id="629164">
<Coords points="194,420 194,469 192,484 1477,490 1481,484 1481,446 194,420"/>
<Baseline points="196,470 1482,485"/>
<TextEquiv>
<Unicode>ἀνέχομαι πλήττεσθαί τινας ἐν ἐμοὶ τῶν πάντα τη-</Unicode>
</TextEquiv>
</TextLine>
Exemplo de estrutura do formato Página (XML) (em francês), descrevendo toda a árvore de anotações - a região do texto e o seu tipo, as coordenadas da linha, a baseline e a transcrição. Existem outros formatos do mesmo tipo, como o ALTO (XML) (em francês).
Geralmente, a mistura de formatos leva, nos OCR disponíveis, a uma perda de qualidade, dada a diferente gestão da informação de acordo com o formato. Assim, na figura 11 observamos que não só uma bounding-box não consegue capturar adequadamente a curvatura do texto, sobrepondo-se à linha superior, como também os dados poligonais não são, por defeito, compatíveis com os dados de tipo bounding-box dada a presença da máscara. Todavia, é possível combiná-los na Calfa Vision para extrair não um polígono, mas uma bouding-box da baseline. Essa funcionalidade foi implementada, precisamente, para converter conjuntos de dados habitualmente incompatíveis para explorar os dados mais antigos e assegurar uma continuidade na criação de dados26.

Figura 11: Diferença do processamento entre uma bounding-box vs um polígono vs um polígono na Calfa Vision.
E agora?
Em resumo, no final desta etapa de descrição das necessidades, verificamos que:
- Zonas de texto: queremos concentrar a deteção e o reconhecimento do texto nas colunas principais em grego, excluindo o texto em latim, os títulos corridos, as notas entre colunas, o aparato crítico e todas as notas marginais.
- Linhas de texto: temos de levar em consideração as linhas curvas e escolher, portanto, uma abordagem por baseline.
- Modelo de base: está disponível um modelo de base, mas treinado com dados mais antigos. Utilizaremos uma abordagem que combina a baseline com o bounding-box para tirar o máximo proveito dos dados existentes.
- Escolha de transcrição: partimos de uma transcrição com normalização do tipo NFC, sem integrar os eventuais sinais de edição e as notas. A complexidade oferecida pela PG deixa supor que terá de ser produzido um grande conjunto de dados. Veremos na próxima secção como limitar os dados necessários, considerando uma arquitetura dedicada e não genérica.
Pequena diferença nas métricas
Para entender os resultados oferecidos pelo OCR/HTR, tanto ao nível do layout como do reconhecimento de caracteres, precisamos de definir algumas métricas normalmente utilizadas para quantificar o erro desses modelos.
CER
Já abordámos discretamente o CER, que nos dá a taxa de erro ao nível do caracter na previsão de um texto. O CER calcula-se simplesmente contando o número de operações necessárias para passar da previsão ao texto esperado. Este utiliza a distância de Levenshtein e é dado pela seguinte fórmula:
\[CER = \frac{S+D+I}{N}\]onde S = número de substituições, D = número de eliminações, I = número de adições, e N = número total de caracteres a prever.
Por exemplo, se o meu OCR prevê a palavra Programm*m*ingHisto*y*an em vez de ProgrammingHistorian, em outras palavras:
- Foi adicionado um m supérfluo
- O i foi substituído por um y
- O r não foi reconhecido
Assim, temos os seguintes valores: S = 1, I = 1 D = 1 e N = 20.
\[CER = \frac{1+1+1}{20} = 0,15\]Em outras palavras, obtemos uma taxa de erro ao nível do caracter de 15%.
Existe uma variável aplicável à palavra, o WER (ou Word Error Rate, em português, Taxa de Erro por Palavra), cujo funcionamento é muito semelhante.
O CER e o WER são muito práticos e intuitivos para quantificar a percentagem de erro numa previsão. No entanto, de acordo com as especificações adotadas, estas métricas podem-se revelar menos relevantes ou até mesmo ambíguas. O exemplo mais evidente é o de uma leitura automática de abreviaturas onde não é pertinente contabilizar as adições e as substituições - por exemplo em vez de p. ex..27
Precisão e lembrete
A precisão (em inglês, precision) e o lembrete (em inglês, recall) são métricas incontornáveis para avaliar a adequação e a precisão das previsões. Estas são utilizadas, particularmente, na análise do layout da página. A precisão corresponde ao número total de resultados relevantes entre todos os resultados obtidos. O lembrete corresponde ao número total de resultados relevantes de todos os resultados entre todos os resultados relevantes esperados.
Vamos estudar estas duas métricas para a taxa de deteção de linhas (ver a figura 12, onde a encarnado estão as linhas corretamente detetadas e, a verde, as linhas incorretamente detetadas, ou seja, com erros de deteção e linhas omitidas).

Figura 12: Comparação da previsão e do lembrete no manuscrito BULAC.MS.ARA.1947, imagem 178658 (conjunto de dados RASAM).
-
GT (ground truth): desejamos detetar 23 baselines - decidimos ignorar as glosas interlineares.
-
No caso 1, detetamos 37 baselines. Entre estas, as 23 baselines esperadas estão presentes. O modelo proposto oferece resultados pertinentes, mas é globalmente pouco preciso. Tal traduz-se num lembrete elevado, mas numa baixa precisão. Em detalhe:
- No caso 2, detetamos 21 baselines, das quais 10 são corretas. O modelo é pouco preciso e bastante irrelevante, uma vez que faltam mais de 50% das linhas desejadas. Isto traduz-se num lembrete baixo e numa baixa precisão. Em detalhe:
- No caso 3, detetamos 12 baselines, todas elas boas. O modelo é bastante irrelevante, uma vez que apenas metade das linhas foram detetadas, mas é muito preciso porque as linhas encontradas são efetivamente boas. Isto traduz-se numa alta precisão e num baixo lembrete. Em detalhe:
A precisão e o lembrete são, frequentemente, resumidos ao F1-score, que corresponde à sua média harmónica (sendo que o objetivo é estar o mais próximo possível de 1).
Interseção na União (em inglês, Intersection over Union, ou IoU)
Esta métrica aplica-se à deteção de objetos num documento, ou seja, é utilizada para medir a qualidade da análise e da compreensão do layout: identificação dos títulos, dos números das páginas, das colunas de textos, etc. Na prática, medimos o número de pixéis comuns à ground truth e à previsão, divididas pelo número total de pixéis.
\[IoU = \frac{GT \cap Previsão}{GT \cup Previsão}\]Esta métrica é calculada separadamente para cada classe a detetar, e uma média geral (em inglês, mean) de todas as classes é calculada para fornecer um resultado global, a mean IoU.
Uma IoU de 0,5 é geralmente considerada como um bom resultado, pois significa que pelo menos metade dos pixéis foram corretamente atribuídos à classe, o que geralmente é suficiente para identificar de forma exata um objeto. Uma IoU de 1 significa que a previsão e a grount truth se sobrepõem complemente. Já uma IoU de 0 significa que nenhum pixel é comum à previsão e à ground truth.
Cadeia de processamento: produção de conjuntos de dados e processamento de documentos
Metodologia técnica
A Calfa Vision é uma plataforma que integra um grande número de modelos pré-treinados para diferentes tarefas manuscritas e impressas, de variadas grafias não latinas:28 deteção e classificação de zonas de textos, deteção e extração de linhas, reconhecimento de texto - arménio, georgiano, sírio, grafias árabes, grego antigo, etc.29 O trabalho de anotação e de transcrição pode ser realizado em colaboração entre vários membros de uma equipa e suporta diferentes formatos. A tabela 4 apresenta uma lista não exaustiva dos modelos pré-treinados disponíveis. A língua associada a cada nome corresponde à língua dominante e ao caso clássico de utilização, sem no entanto excluir qualquer outro idioma. Os projetos especializados podem ser desenvolvidos e disponibilizados por usuários da plataforma, para benefício de toda a comunidade, como acontece no caso do projeto Arabic manuscripts (Zijlawi) (em português, Manuscritos árabes (Zijlawi)).
| Tipo de projeto | Descrição |
|---|---|
| Projetos genéricos | |
| Manuscritos árabes (por defeito) | Modelos de layout genéricos para uma grande variedade de manuscritos históricos árabes, simples e complexos, com numerosos conteúdos marginais dobrados e danificados. |
| Arquivos arménios | Modelos de layout genéricos para documentos de arquivos, principalmente, em língua arménia - layouts simples a muito complexos, sobretudo, as letras, com classificação semântica dos conteúdos - destinatário, signatário, data, conteúdo, margens, etc.). |
| Impressos chineses | Modelos de layout genéricos para o processamento de textos verticais impressos antigos, com layouts simples a muito densos. |
| Por defeito | Modelos de layout genéricos treinados numa grande variedade de documentos antigos e modernos, impressos e manuscritos, com classificação semântica de conteúdos. Capazes de uma grande polivalência e de uma especialização rápida num grande número de casos. |
| Arquivos etíopes | Modelos de layout genéricos para documentos de arquivos extremamente densos, com uma grande variedade de layouts, com classificação semântica dos conteúdos. |
| Periódicos | Modelos de layout genéricos para a análise, compreensão e segmentação de periódicos antigos e novos. Classificação semântica de conteúdos em arménio e em árabe. |
| Documentos impressos | Modelos de layout genéricos para o processamento de documentos impressos antigos, modernos e contemporâneos, com uma grande variedade de layouts e de idiomas. |
| Projetos especializados (lista não exaustiva) | |
| Manuscritos árabes (Zijlawi) | Modelos de layout especializados para os manuscritos Zijlawi - árabe, layout complexo com um texto muito denso e marginalia vertical. Disponibilizados por um usuário da plataforma. |
| Impressos gregos (Patrologia Graeca) | Modelos de layout especializados para a PG - deteção de informações gregas em documentos multilingues. Tipo de modelo utilizado para a lição do Programming Historian. |
Estes modelos, capazes de processar um grande espectro não exaustivo de documentos, podem não se adaptar perfeitamente ao nosso projeto de anotação da PG. Em contrapartida, a plataforma é baseada no fine-tuning iterativo dos seus modelos em função das anotações dos usuários, podendo rapidamente especializar-se num novo caso. Assim, partindo, por exemplo, de um modelo de layout, as nossas releituras e esclarecimentos serão progressivamente integrados no modelo de forma a corresponder à necessidades do nosso projeto. As diferentes plataformas mencionadas anteriormente integram abordagens mais ou menos semelhantes ao fine-tuning dos seus modelos, pelo que o leitor poderá realizar trabalhos semelhantes nas mesmas. Todavia, a Calfa Vision tem a vantagem de limitar o comprometimento do usuário na análise das suas necessidades, sendo o fine-tuning realizado de forma autónoma das anotações.

Figura 13. Calfa Vision – Análise automática do layout em dois exemplos da PG. Na parte superior, o modelo deteta bem as várias zonas de texto, sem distinção, e a ordem de leitura está correta. Abaixo, a compreensão do documento não é tão satisfatória e provocou uma fusão das diferentes colunas e linhas.
Na figura 13, observamos que o modelo pré-treinado a partir do tipo de projetos Printed Documents (em português, documentos impressos) da plataforma oferece resultados que variam muito entre o muito satisfatórios (superior) a mistos (abaixo). Além de colocar todos os tipos de zonas no mesmo plano, categorizadas como paragraph (em português, parágrafo), o modelo nem sempre consegue compreender a disposição por colunas. Por outro lado, não obstante uma fusão de todas as linhas no segundo caso, todas as zonas e linhas são detetadas corretamente, não havendo perda de informação. Portanto, podemos supor que a criação de um novo modelo especializado na PG será rápida.
Que anotações de layout realizar?
Para as páginas onde a segmentação de zonas é satisfatória, devemos especificar a que tipo cada zona de texto corresponde, precisando o que é um texto em grego (a encarnado nas figuras 8a e 8b) e aquele que está em latim (a azul) e remover o restante conteúdo considerado desnecessário no nosso processamento. No caso das páginas insatisfatórias, devemos corrigir as anotações erradas.
Ao nível da transcrição do texto, o modelo construído anteriormente apresenta uma taxa de erro na PG ao nível do caracter de 68,13% (teste fora do domínio30) , ou seja, é inutilizável tal como está devido à grande diferença existente entre os dados do processamento e os documentos visados. Encontramo-nos perante um cenário de uma grafia não latina dada a extrema particularidade das impressões da PG.
Considerando as dificuldades encontradas na figura 9 e a grande degradação do documento, uma arquitetura ao nível do caracter poderá não ser a mais adequada. Podemos supor a existência de um vocabulário recorrente, pelo menos à escala de um volume da PG. O problema do reconhecimento pode, assim, ser simplificado com uma aprendizagem por palavra em vez de caracter. Existe uma grande variedade de arquiteturas neurais que são implementadas nas diversas plataformas de última geração.31 Estas têm as suas vantagens e inconvenientes em termos de polivalência e de volume de dados necessário. No entanto, uma arquitetura única para qualquer tipo de problema pode conduzir a um investimento muito maior do que o necessário.
Neste contexto, a plataforma que utilizamos realiza uma escolha entre arquiteturas por caracter ou por palavra, de forma a simplificar o reconhecimento dando maior peso ao contexto em que o caracter ou a palavra aparecem. Trata-se de uma abordagem que tem bons resultados para a leitura de abreviaturas do latim (ou seja, numa forma gráfica abreviada de um manuscrito conseguimos transcrever uma palavra inteira)32 ou no reconhecimento de grafias árabes magrebinas (ou seja, na gestão do vocabulário com diacríticos ambíguos e ligações importantes).33
Qual o volume de dados?
É muito difícil antecipar o número de dados necessários para o fine-tuning dos modelos. Uma avaliação da plataforma mostra uma adaptação relevante da análise do layout e da classificação de zonas de texto de 50 páginas para layouts complexos de manuscritos árabes.34 O problema aqui é mais simples - menor variabilidade do conteúdo. Para a deteção de linhas, 25 páginas são suficientes.35 Todavia, não é expectável esperar atingir estes resultados para ganhos na análise e na deteção.
Ao nível da transcrição, o estado da arte destaca uma necessidade mínima de 2.000 linhas para treinar um modelo OCR/HTR,36 o que pode corresponder a uma média entre 75 e 100 páginas para documentos manuscritos em scripta não latina. Para a PG, dada a densidade particular do texto, tal corresponde a uma média de 50 páginas.
Ströbel et al.37 mostram que para além das 100 páginas não existe uma grande diferença entre os modelos para um problema específico. Portanto, o importante não é apostar num grande volume de dados mas, pelo contrário, concentrar a nossa atenção na qualidade dos dados produzidos e na sua adequação ao objetivo da pesquisa.
No entanto, esses volumes correspondem às necessidades dos modelos processados do zero. Num caso de fine-tuning, os volumes são muito inferiores. Através da plataforma Calfa Vision, demonstrámos uma redução de 2,2% do CER para o manuscrito arménio38 com apenas três páginas transcritas, passando de 5,42% para 3,22% para novas especificações ou, ainda, um CER de 9,17% após a transcrição de 20 páginas do árabe magrebino para um novo modelo - redução de 90,83% do volume de dados necessários por comparação ao modelo treinado do zero.39
Na sua generalidade, as últimas experiências mostram uma especialização relevante dos modelos após a transcrição de apenas 10 páginas.
Introdução à plataforma de anotação
O detalhe das principais etapas na plataforma Calfa Vision é apresentado nas figuras 14 e 15. O foco principal está na gestão dos projetos, que permite ao usuário criar, gerir e supervisionar os projetos de anotação, sozinho ou em equipe. A figura 14 ilustra o processo de criação de um novo projeto, em particular, a seleção de um tipo de projeto e a adição de novas imagens.
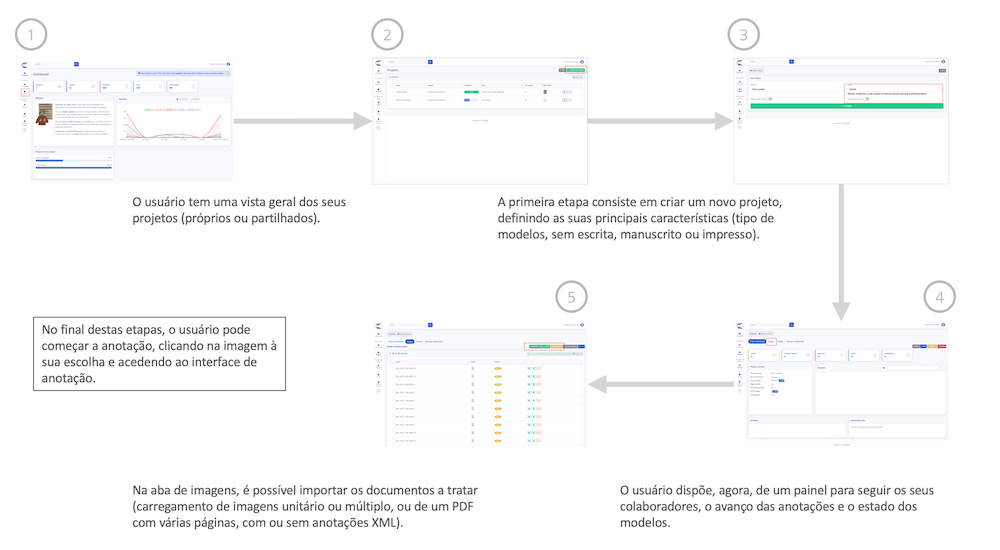
Figura 14: Calfa Vision – Resumo do Interface e das etapas de criação de projetos.
A figura 15 resume as etapas essenciais para a anotação automática de uma imagem. Os detalhes são dados mais à frente nesta lição através da sua aplicação na PG. O usuário é livre de utilizar os modelos de análise de layout e de geração de linhas, sem limite quanto ao volume, ainda que o reconhecimento do texto seja condicionado pelo tipo de perfil.
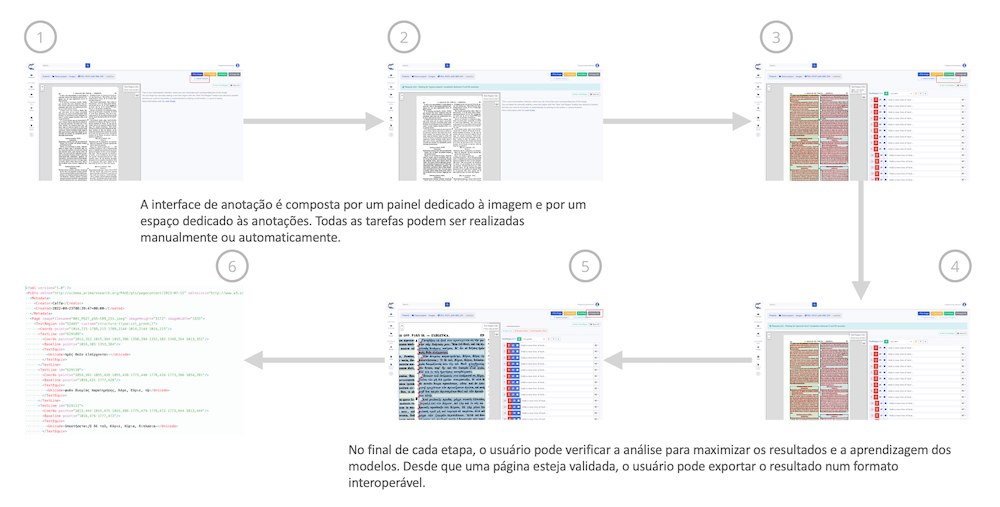
Figura 15: Calfa Vision - Resumo do Interface e das etapas de anotação e documentos.
Na plataforma poderá encontrar um tutorial completo (em inglês) de cada etapa, disponível após o login. Aqui o leitor encontrará detalhes sobre os formatos de importação e exportação, os scripts automáticos, a gestão do projeto, a adição de colaboradores e muitas outras funcionalidades próprias da plataforma que não é possível abordar nesta lição mais genérica. A abordagem clássica consiste em:
- Criar uma conta na plataforma;
- Criar um projeto para cada documento alvo;
- Importar as respetivas imagens e as suas anotações caso já disponha das mesmas e iniciar os scripts de análise automática;
- Verificar as previsões obtidas.
Etapas de anotação
Construímos um primeiro conjunto de dados composto por 30 páginas representativas de diferentes volumes da PG. Essas 30 páginas servem de conjunto de teste para avaliar, precisamente, os modelos ao longo de toda a anotação. As anotações produzidas no resto desta parte constituem o conjunto de aprendizagem (ver as figuras 5 e 6).
Figura 16: Calfa Vision - Lista das imagens de um projeto de transcrição.
Gestão do projeto de anotação
Após ter criado o projeto “Patrologia Graeca” do tipo Printed Documents (v. 2022/01, em português, documentos impressos), juntamos os documentos que queremos anotar ao nível do layout e do texto. A importação pode ser realizada com uma imagem, um ficheiro .zip de imagens, com um manifesto IIIF (o ficheiro .JSON é disponibilizado pelas bibliotecas compatíveis IIIF, contendo metadados do documento e links para cada imagem) ou, no nosso caso, importando um ficheiro PDF. A figura 16 mostra o interface do usuário com as imagens a aguardar a anotação.
Uma vez perante o interface de transcrição de uma imagem (ver a figura 15), dispomos de várias ações para realizar as análises automáticas dos nossos documentos:
Layout Analysis(em português, layout de análise), que vai detetar e classificar as zonas e linhas de texto;Generate Polygons(em português, gerador de polígonos), que vai extrair das linhas detetadas a linha inteira a transcrever - deteção da bouding-box ou do polígono de enquadramento, sujeito às linhas detetadas;Text Recognition(em português, reconhecimento de texto), que vai proceder ao reconhecimento das linhas detetadas e extraídas.
As três etapas são dissociadas a fim de permitir ao usuário ter o controlo completo do pipeline de reconhecimento, incluindo a possibilidade de corrigir qualquer previsão incompleta ou errónea. Procedemos, nesta fase, à análise massiva do layout, em todas as imagens do projeto.
Anotação do layout
Acedendo à interface de anotação, as previsões estão prontas para serem revistas. Este projeto possui três níveis de anotação:
├── A região do texto (a verde), com um tipo associado;
│ └── A linha de texto, composta:
| ├── Por uma baseline (a encarnado)
| └── Por um polígono ou por uma bounding-box (a azul)
| └── A transcrição.
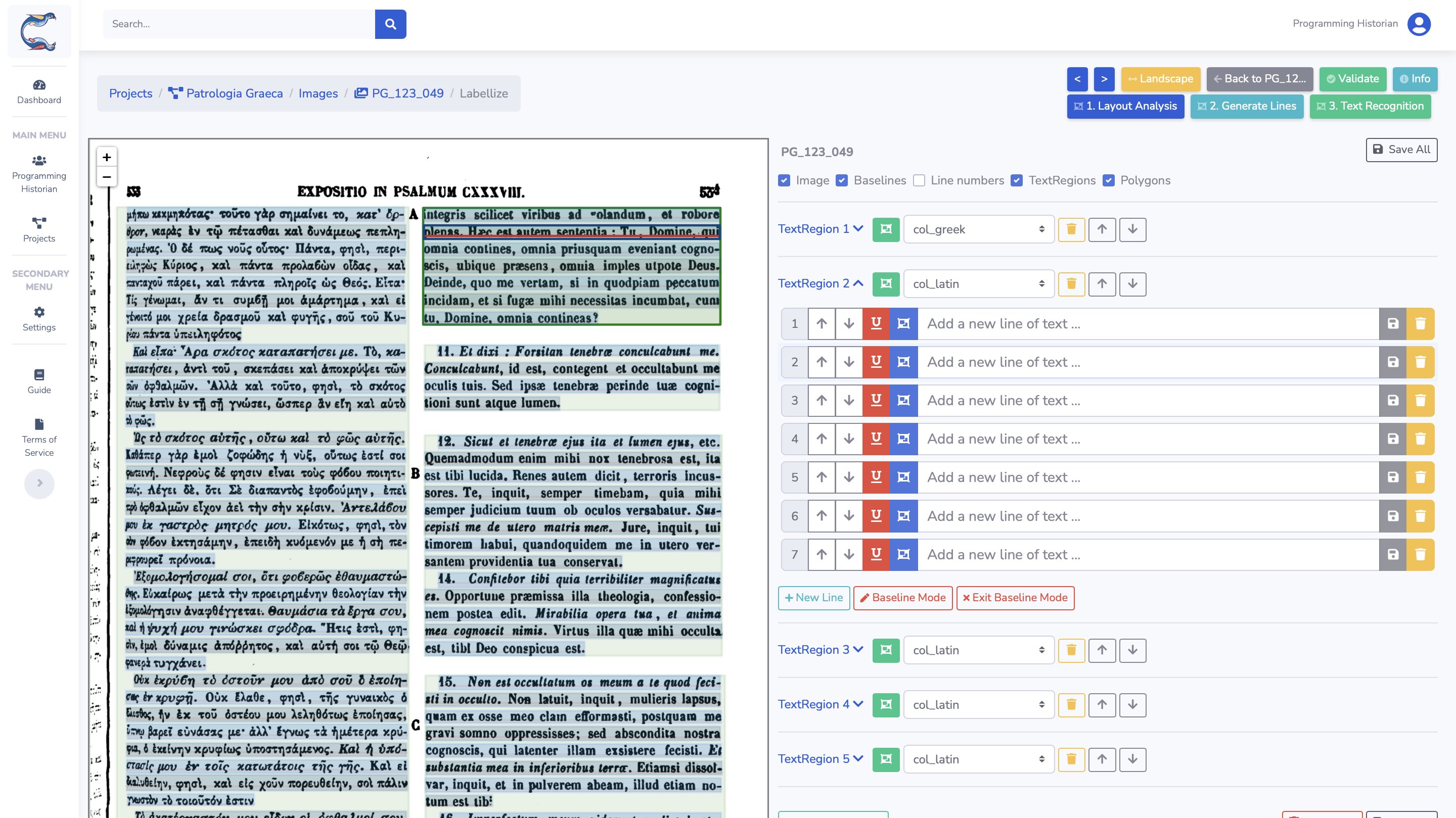
Figura 17: Calfa Vision - Interface de anotação e layout.
Não é necessário realizar um pré-processamento das imagens e fazer-lhes qualquer melhoria (endireitamento, limpeza, etc.).
Cada objeto - região, linha e texto - pode ser manualmente modificado, movido, suprimido, etc., em função do nosso objetivo. Aqui, asseguramo-nos que apenas iremos conservar as zonas que desejamos reconhecer, a saber, col_greek e col_latin, às quais juntamos essa informação semântica. É igualmente a oportunidade para verificar se as linhas foram bem detetadas, especialmente nas páginas que possuem problemas.
Realizamos este controlo para 10, 30 e 50 páginas de forma a medir o impacto na deteção de texto nessas regiões.
| média IoU | 0 imagens | 10 imagens | 30 imagens | 50 imagens |
|---|---|---|---|---|
| Parágrafo | 0.94 | - | - | - |
| Col_greek | - | 0.86 | 0.91 | 0.95 |
| Col_latin | - | 0.78 | 0.88 | 0.93 |
Na tabela 5 observamos que a distinção de zonas de texto se opera corretamente a partir de 10 imagens anotadas, ao nível das regiões. A partir de 50 imagens, o modelo classifica 95% das colunas gregas e 93% das colunas latinas. Os erros estão localizados nos textos transversais e na deteção superficial de notas de rodapé, respetivamente em grego e em latim. Para este último caso, não se trata propriamente de um erro, ainda que leve a um conteúdo indesejado no resultado.

Figura 18: Evolução da deteção das zonas e linhas de texto.
Com este novo modelo, a anotação do layout é, portanto, muito mais rápida. A correção progressiva de novas imagens permitirá superar os erros observados.
| F1-score | |
|---|---|
| 0 imagens | 0.976 |
| 10 imagens | 0.982 |
| 30 imagens | 0.981 |
| 50 imagens | 0.981 |
Não iremos desenvolver mais a métrica aqui utilizada.40 No que diz respeito à deteção de linhas, contrariamente ao que podemos observar na deteção de zonas (figura 18), 10 imagens são suficientes para obter de imediato um modelo muito poderoso. A falta de anotação das notas de rodapé conduz, em particular, à criação de uma ambiguidade no modelo, onde a estagnação de resultados obtidos, para os quais observamos uma “baixa” precisão - todas as linhas detetadas - mas um alto lembrete - todas as linhas desejadas detetadas. Em contrapartida, isso não afeta o processamento das páginas seguintes, uma vez que apenas é tido em consideração o conteúdo das zonas segmentadas.
Anotação do texto
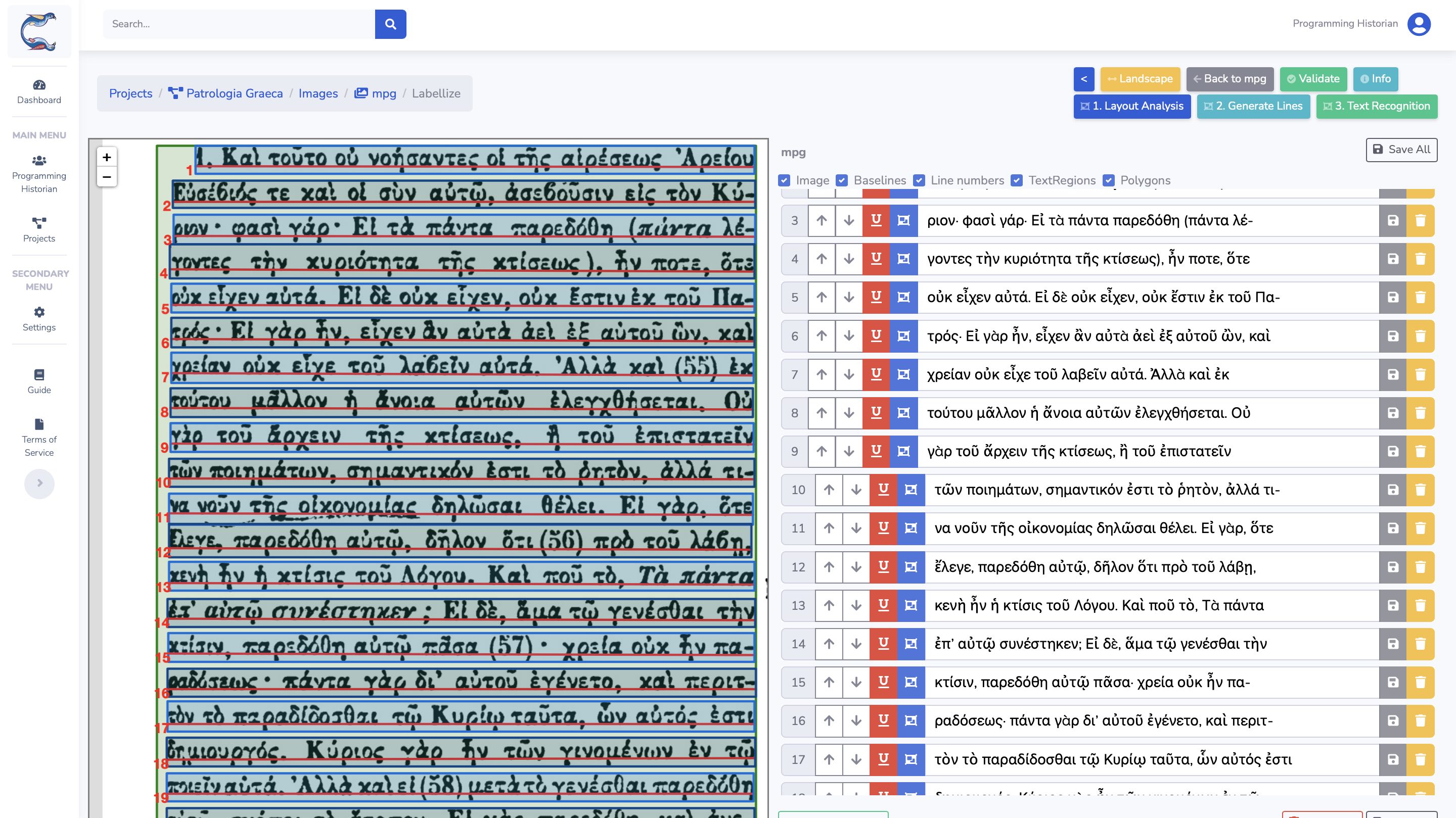
Figura 19: Calfa Vision – Transcrição do texto.
A transcrição é realizada linha a linha para corresponder à ground truth que já temos (ver acima). Essa transcrição pode ser realizada seja inteiramente de forma manual, seja assistida por um OCR integrado, seja sendo importada de uma transcrição existente. As linhas 1 e 7 destacam a falta de transcrição dos números neste exercício. Os dados são exportados num formato compatível com os dados anteriores, par imagem-texto, sem distorção das imagens.
Info) e escolhendo o formato de exportação apropriado. Conforme detalhado anteriormente, para se beneficiar dos dados pré-existentes para reforçar a nossa aprendizagem, devemos escolher a exportação por par imagem-texto. Não é aplicada nenhuma distorção da baseline o que, quando alcançado, pode fazer com que a complexidade adicional seja superada, exigindo mais dados.
Iremos então aqui transcrever um, depois dois, depois cinco e, por fim, dez imagens, aproveitando iterativamente um novo modelo de transcrição automática.
| 0 | 1 | 2 | 5 | 10 | |
|---|---|---|---|---|---|
| CER (%) | 68,13 | 38,45 | 6,97 | 5,42 | 4,19 |
Duas imagens são suficientes para obter um CER inferior a 7% e uma transcrição automática utilizável. É claro que o modelo ainda não é muito versátil para toda a variedade da PG, mas a transcrição de novas páginas é muito mais rápida. Nas simulações realizadas em maior escala, mantendo essa abordagem iterativa, obtemos um CER de 1,1% após 50 páginas transcritas.

Figura 20: Resultado final da PG
Abertura do manuscrito e conclusão
A transcrição de documentos manuscritos (mas também a de manuscritos antigos, arquivos modernos, etc.) responde exatamente à mesma lógica e às mesmas questões: partir de modelos existentes, que vamos especializando às necessidades de um objetivo, de acordo com um determinado conjunto de tarefas.
A plataforma foi, assim, testada num novo conjunto gráfico, o dos escritos magrebinos, escritos árabes que tradicionalmente representam uma armadilha para os HTR. A abordagem iterativa que foi aplicada resultou na transcrição de 300 imagens, constituindo o conjunto de dados RASAM,41 sob a supervisão do Groupement d’Intérêt Scientifique Moyen-Orient et mondes musulmans (GIS MOMM (em francês)), da BULAC (em francês) e da Calfa. Partindo do zero para os escritos magrebinos, esta abordagem de fine-tuning usando um interface de transcrição como a apresentada neste tutorial demonstrou a sua relevância: o tempo necessário para a transcrição foi reduzido, em média, mais de 42% (ver a figura 21).
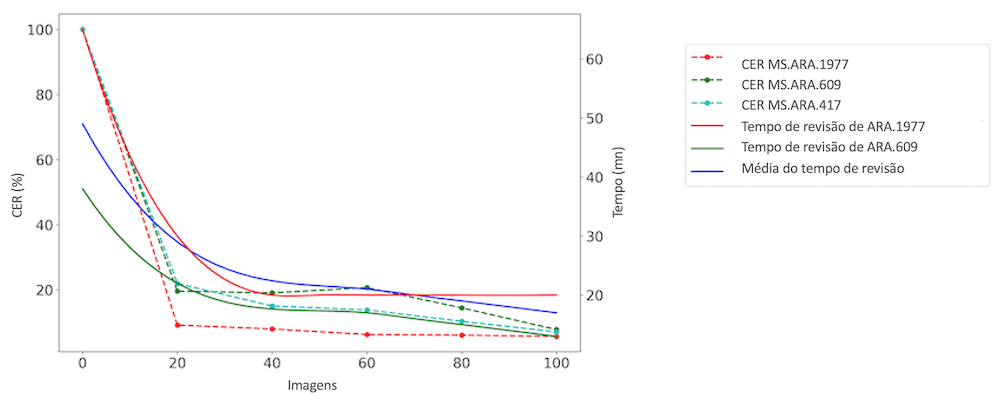
Figura 21: Conjunto de dados RASAM, Springer 2021 – Evolução do CER e do tempo de releitura.
Neste tutorial descrevemos as boas práticas para a transcrição rápida de documentos em grafias ou línguas não latinas, através da plataforma Calfa Vision. A qualificação de “pouco dotada” pode dizer respeito a um grande e variado número de documentos, inclusive, como foi este caso, para línguas para as quais já existem dados. A qualidade dos dados não deve ser negligenciada face à quantidade e o usuário poderá considerar uma transcrição, inclusiva para documentos inéditos.
Questões mais técnicas podem surgir de acordo com a plataforma utilizada e pode-se oferecer um acompanhamento aos projetos de transcrição. É essencial definir de forma precisa as necessidades de um processamento OCR/HTR de acordo com o problema, sendo a transcrição automática uma porta de entrada para qualquer projeto de valorização e processamento de coleções.
Os dados gerados neste artigo e no âmbito do projeto CGPG estão disponíveis no Zenodo (https://doi.org/10.5281/zenodo.7296539). Este artigo foi escrito utilizando a versão 1.0.0. do dataset. O modelo de análise do layout está disponível na Calfa Vision com o nome Greek printed (Patrologia Graeca) e é regularmente atualizado.
Notas de fim
-
Os volumes da PG estão disponíveis em formato PDF, por exemplo, nos links http://patristica.net/graeca e https://www.roger-pearse.com/weblog/patrologia-graeca-pg-pdfs (em inglês). Mas apenas parte da PG está codificada em formato de “texto”, por exemplo, no corpus do Thesaurus Linguae Graecae (em inglês). ↩
-
A associação Calfa (Paris, França) e o projeto GREgORI (Université Catholique de Louvain, Louvain-la-Neuve, Bélgica) desenvolvem conjuntamente sistemas de reconhecimento de caracteres e sistemas de análise automática de textos: lematização, rotulagem morfossintática, POS_tagging). Esses desenvolvimentos já foram adaptados, testados e utilizados para processar textos em arménio, em georgiano e em sírio. O projeto CGPG continua esses desenvolvimentos no domínio do grego, propondo um processamento completo (OCR e análise) de textos editados da PG. Para os exemplos de processamento morfossintático do grego antigo realizado em conjunto: Kindt, Bastien, Chahan Vidal-Gorène, Saulo Delle Donne. “Analyse automatique du grec ancien par réseau de neurones. Évaluation sur le corpus De Thessalonica Capta”. BABELAO, 10-11 (2022), 525-550. https://doi.org/10.14428/babelao.vol1011.2022.65073 (em francês). ↩
-
Ver, por exemplo, Alex Graves e Jürgen Schmidhuber. (2008). “Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks”. In Advances in Neural Information Processing Systems 21 (NIPS 2008), dir. Daphne Koller et al. (S.l.: Curran Associates, 2009) https://papers.nips.cc/paper/2008/file/66368270ffd51418ec58bd793f2d9b1b-Paper.pdf (em inglês). ↩
-
Stuart Snydman, Robert Sanderson, e Tom Cramer. “The International Image Interoperability Framework (IIIF): A community & technology approach for web-based images”. Archiving Conference, 2015, 16‑21. ↩
-
Ryad Kaoua, Xi Shen, Alexandra Durr, Stavros Lazaris, David Picard, e Mathieu Aubry. “Image Collation : Matching Illustrations in Manuscripts”. In Document Analysis and Recognition – ICDAR 2021, dir. Josep Lladós, Daniel Lopresti, e Seiichi Uchida. Lecture Notes in Computer Science, vol. 12824. Cham: Springer, 2021, 351‑66. https://doi.org/10.1007/978-3-030-86337-1_24 (em inglês). ↩
-
Emanuela Boros, Alexis Toumi, Erwan Rouchet, Bastien Abadie, Dominique Stutzmann, e Christopher Kermorvant. “Automatic Page Classification in a Large Collection of Manuscripts Based on the International Image Interoperability Framework”. In Document Analysis and Recognition - ICDAR 2019, 2019, 756‑62, https://doi.org/10.1109/ICDAR.2019.00126 (em inglês). ↩
-
Mathias Seuret, Anguelos Nicolaou, Dalia Rodríguez-Salas, Nikolaus Weichselbaumer, Dominique Stutzmann, Martin Mayr, Andreas Maier, e Vincent Christlein. “ICDAR 2021 Competition on Historical Document Classification”. In Document Analysis and Recognition – ICDAR 2021, dir. Josep Lladós, Daniel Lopresti, e Seiichi Uchida. Lecture Notes in Computer Science, vol 12824. Cham : Springer, 2021, 618‑34. https://doi.org/10.1007/978-3-030-86337-1_41 (em inglês). ↩
-
Há uma grande variedade deconjuntos de dados realizados no âmbito de diversos ambientes de pesquisa. As pessoas interessadas conseguirão encontrar um grande número de dados disponíveis no âmbito da iniciativa HTR United (em francês). Alix Chagué, Thibault Clérice, e Laurent Romary. “HTR-Unite: Mutualisons la vérité de terrain!”, DHNord2021 - Publier, partager, réutiliser les données de la recherche: les data papers et leurs enjeux, Lille, MESHS, 2021. https://hal.archives-ouvertes.fr/hal-03398740 (em francês). ↩
-
Podemos, por exemplo, citar o programa “Scripta-PSL. Histoire et pratiques de l’écrit” (em inglês) que procura, em particular, integrar nas humanidades digitais uma grande variedade de línguas e escritos antigos raros; a Rede de Reconhecimento de Texto Otomano (em inglês) para o processamento de grafias utilizadas durante o período otomano; ou, ainda, o Grupo de Interesse Científico no Médio Oriente e Mundo Muçulmano (GIS MOMM) em francês) que, em parceria com a BULAC (em francês) e a Calfa (em inglês), produz conjuntos de dados para o tratamento de grafias árabes magrebinas (em inglês). ↩
-
O crowdsourcing pode ter a forma de ateliers dedicados com um público restrito, mas também podem ser abertos a todo o público voluntário que deseja, ocasionalmente, transcrever documentos, conforme oferecido pela plataforma Transcrire (em francês), proposta por Huma-Num. ↩
-
Christian Reul, Dennis Christ, Alexander Hartelt, Nico Balbach, Maximilian Wehner, Uwe Springmann, Christoph Wick, Christine Grundig, Andreas Büttner, e Frank Puppe. “OCR4all - An open-source tool providing a (semi-)automatic OCR workflow for historical printings”. Applied Sciences 9, nᵒ 22 (2019): 4853 (em inglês). ↩
-
Chahan Vidal-Gorène, Boris Dupin, Aliénor Decours-Perez, e Thomas Riccioli. “A modular and automated annotation platform for handwritings: evaluation on under-resourced languages”. In International Conference on Document Analysis and Recognition - ICDAR 2021, dir. Josep Lladós, Daniel Lopresti, e Seiichi Uchida. 507-522. Lecture Notes in Computer Science, vol. 12823. Cham: Springer, 2021. https://doi.org/10.1007/978-3-030-86334-0_33 (em inglês). ↩
-
Jean-Baptiste Camps, Chahan Vidal-Gorène, Dominique Stutzmann, Marguerite Vernet, e Ariane Pinche, “Data Diversity in handwritten text recognition, Challenge or opportunity?”, Digital Humanities 2022 (DH 2022), Tokyo, 27 juillet 2022. ↩
-
Para um exemplo da estratégia de fine-tuning aplicada às grafias árabes manuscritas: Bulac Bibliothèque, Maxime Ruscio, Muriel Roiland, Sarah Maloberti, Lucas Noëmie, Antoine Perrier, e Chahan Vidal-Gorène. “Les collections de manuscrits maghrébins en France (2/2)”, Mai 2022, HAL, https://medihal.archives-ouvertes.fr/hal-03660889 (em francês). ↩
-
Jean-Baptiste Camps. “Introduction à la philologie computationnelle. Science des données et science des textes: De l’acquisition du texte à l’analyse”, Étudier et publier les textes arabes avec le numérique, 7 de dezembro de 2020, YouTube, https://youtu.be/DK7oxn-v0YU (em francês). ↩
-
Numa arquitetura “word-based” cada palavra constitui uma classe inteira própria. Se tal leva mecanicamente a uma multiplicação do número de classes, o vocabulário de um texto é, na realidade, suficientemente homogéneo e reduzido para considerar essa abordagem. Não é incompatível com uma abordagem complementar “character-based”. ↩
-
Jean-Baptiste Camps, Chahan Vidal-Gorène, e Marguerite Vernet. “Handling Heavily Abbreviated Manuscripts: HTR engines vs text normalisation approaches”. In International Conference on Document Analysis and Recognition - ICDAR 2021, dir. Elisa H. Barney Smith, Umapada Pal. Lecture Notes in Computer Science, vol. 12917. Cham: Springer, 2021, 507-522. https://doi.org/10.1007/978-3-030-86159-9_21 (em inglês). ↩
-
Para mais manipulações Unicode em grego antigo: https://jktauber.com/articles/python-unicode-ancient-greek/ (consultado a 12 de fevereiro de 2022) (em inglês). ↩
-
A título de exemplo, considerando a normalização com NFD, obtemos um CER (para ver mais abaixo) de 22,91% com 10 páginas, contra 4,19% com a normalização NFC. ↩
-
Por defeito, a Calfa Vision escolhe a normalização mais adaptada ao dataset fornecido, de forma a simplificar a tarefa de reconhecimento, sem que seja necessária a intervenção manual. A normalização pode, no entanto, ser configurada antes ou depois do carregamento dos dados na plataforma. ↩
-
Para aceder aos conjuntos de dados mencionados: greek_cursive, gaza-iliad et voulgaris-aeneid. ↩
-
Matteo Romanello, Sven Najem-Meyer, e Bruce Robertson. “Optical Character Recognition of 19th Century Classical Commentaries: the Current State of Affairs”. In The 6th International Workshop on Historical Document Imaging and Processing (2021): 1-6. Dataset igualmente disponível no Github. ↩
-
Nesta etapa, o modelo não é avaliado na PG. A taxa de erro é obtida através de um conjunto de teste extraído desses três conjuntos de dados. ↩
-
Thomas M. Breuel. “The OCRopus open source OCR system”. In Document recognition and retrieval XV, (2008): 6815-6850. International Society for Optics and Photonics (em inglês). ↩
-
A coexistência de dados de tipo bounding-box e de tipo baseline corresponde a uma evolução técnica e cronológica. O sistema OCR OCRopy, pioneiro nos OCR por recursos neurais, utiliza os bounding-box, excluindo efetivamente qualquer documento curvo. Esse sistema necessita de um pré-processamento das imagens antes de considerar qualquer reconhecimento. ↩
-
Vidal-Gorène, Dupin, Decours-Perez, Riccioli. “A modular and automated annotation platform for handwritings: evaluation on under-resourced languages”, 507-522. ↩
-
Camps, Vidal-Gorène, et Vernet. “Handling Heavily Abbreviated Manuscripts: HTR engines vs text normalisation approaches”, 507-522. ↩
-
Vidal-Gorène, Dupin, Decours-Perez, Riccioli. “A modular and automated annotation platform for handwritings: evaluation on under-resourced languages”, 507-522. ↩
-
A etapa de reconhecimento de texto, OCR ou HTR, é oferecida a pedido e no âmbito de projetos dedicados ou parceiros. As duas primeiras etapas do processamento são gratuitas e ilimitadas. ↩
-
Geralmente, distinguimos dois tipos de avaliação de um modelo OCR/HTR: uma avaliação “in-domain” (em português, no domínio), isto é, em que o conjunto de teste é semelhante aos dados de processamento, e uma avaliação “out-of-domain” (em português, fora do domínio), com dados completamente novos ao modelo. Classicamente, um teste “in-domain” dá resultados elevados porque o modelo é processado muito especificamente na tarefa avaliada, mesmo se os dados de processamento e de teste são distintos. Este teste permite avaliar, particularmente, a relevância de um modelo especializado. Um teste “out-of-domain” dá informações sobre a polivalência e a “generalidade” de um modelo, pois este é avaliado com dados ausentes e desconhecidos dos seus dados de processamento - por exemplo, por uma nova mão ou um novo tipo de escrita. ↩
-
Francesco Lombardi, e Simone Marinai. “Deep Learning for Historical Document Analysis and Recognition—A Survey”. J. Imaging 2020, 6(10), 110. https://doi.org/10.3390/jimaging6100110 (em inglês). ↩
-
Camps, Vidal-Gorène, e Vernet. “Handling Heavily Abbreviated Manuscripts: HTR engines vs text normalisation approaches”, 507-522. ↩
-
Chahan Vidal-Gorène, Noëmie Lucas, Clément Salah, Aliénor Decours-Perez, e Boris Dupin. “RASAM–A Dataset for the Recognition and Analysis of Scripts in Arabic Maghrebi”. In International Conference on Document Analysis and Recognition - ICDAR 2021, dir. Elisa H. Barney Smith, Umapada Pal. Lecture Notes in Computer Science, vol. 12916. Cham: Springer, 2021, 265-281. https://doi.org/10.1007/978-3-030-86198-8_19 (em inglês). ↩
-
Ibid. ↩
-
Vidal-Gorène, Dupin, Decours-Perez, Riccioli. “A modular and automated annotation platform for handwritings: evaluation on under-resourced languages”, 507-522. ↩
-
Phillip Benjamin Ströbel, Simon Clematide, e Martin Volk. “How Much Data Do You Need? About the Creation of a Ground Truth for Black Letter and the Effectiveness of Neural OCR”. In Proceedings of the 12th Language Resources and Evaluation Conference, 3551-3559. Marseille: ACL Anthology, 2020. https://aclanthology.org/2020.lrec-1.436.pdf (em inglês). ↩
-
Ibid. ↩
-
Bastien Kindt e Vidal-Gorène Chahan, “From Manuscript to Tagged Corpora. An Automated Process for Ancient Armenian or Other Under-Resourced Languages of the Christian East”. Armeniaca. International Journal of Armenian Studies 1, 73-96, 2022. http://doi.org/10.30687/arm/9372-8175/2022/01/005 (em inglês). ↩
-
Vidal-Gorène, Lucas, Salah, Decours-Perez, e Dupin. “RASAM–A Dataset for the Recognition and Analysis of Scripts in Arabic Maghrebi”, 265-281. ↩
-
Vidal-Gorène, Dupin, Decours-Perez, Riccioli. “A modular and automated annotation platform for handwritings: evaluation on under-resourced languages”, 507-522. ↩
-
O dataset RASAM está disponível em formato PAGE (XML) no Github. Este é o resultado de um “hackathon” participativo que reuniu 14 pessoas organizado pelo GIS MOMM, pela BULAC e pela Calfa, com o apoio do ministério francês do ensino superior e investigação. ↩