
Contenus
- Objectifs du cours
- Présentation de Heurist
- Quelques éléments techniques
- Organisation de la leçon
- Données utilisées pour le cours
- Modélisation des données
- Créer une base de données sur Heurist
- Importer des données dans Heurist
- Explorer et modifier les données
- Mettre en ligne les données gérées dans Heurist
- Conclusion
- Ressources utiles
- Notes
Objectifs du cours
Ce cours est une introduction à l’utilisation d’Heurist, logiciel open source développé par l’université de Sydney afin de permettre aux chercheurs et chercheuses en sciences humaines et sociales (SHS) de gérer leurs données acquises sur le terrain.
Présentation de Heurist
Heurist est un système de gestion de base de données (SGBD). Élaboré en 2005 par le professeur Ian Johnson1 en collaboration avec des dizaines de projets de recherche en sciences humaines, il vise à redonner à la communauté de recherche le contrôle sur ses données plutôt que de le déléguer aux personnes en charge des développements informatiques2. Si Heurist peut être utilisé pour gérer tous types de données, il a été pensé pour résoudre des problématiques liées aux recherches en SHS. Il intègre donc nativement la gestion et la visualisation de données spatiales et temporelles ainsi que des éléments permettant de décrire de façon fine des lieux ou des personnes. Ses fonctionnalités sont nombreuses, elles comprennent entre autres :
- La modélisation
- L’import
- La visualisation
- La publication
- L’export dans un format ouvert
- Le travail collaboratif
- L’analyse
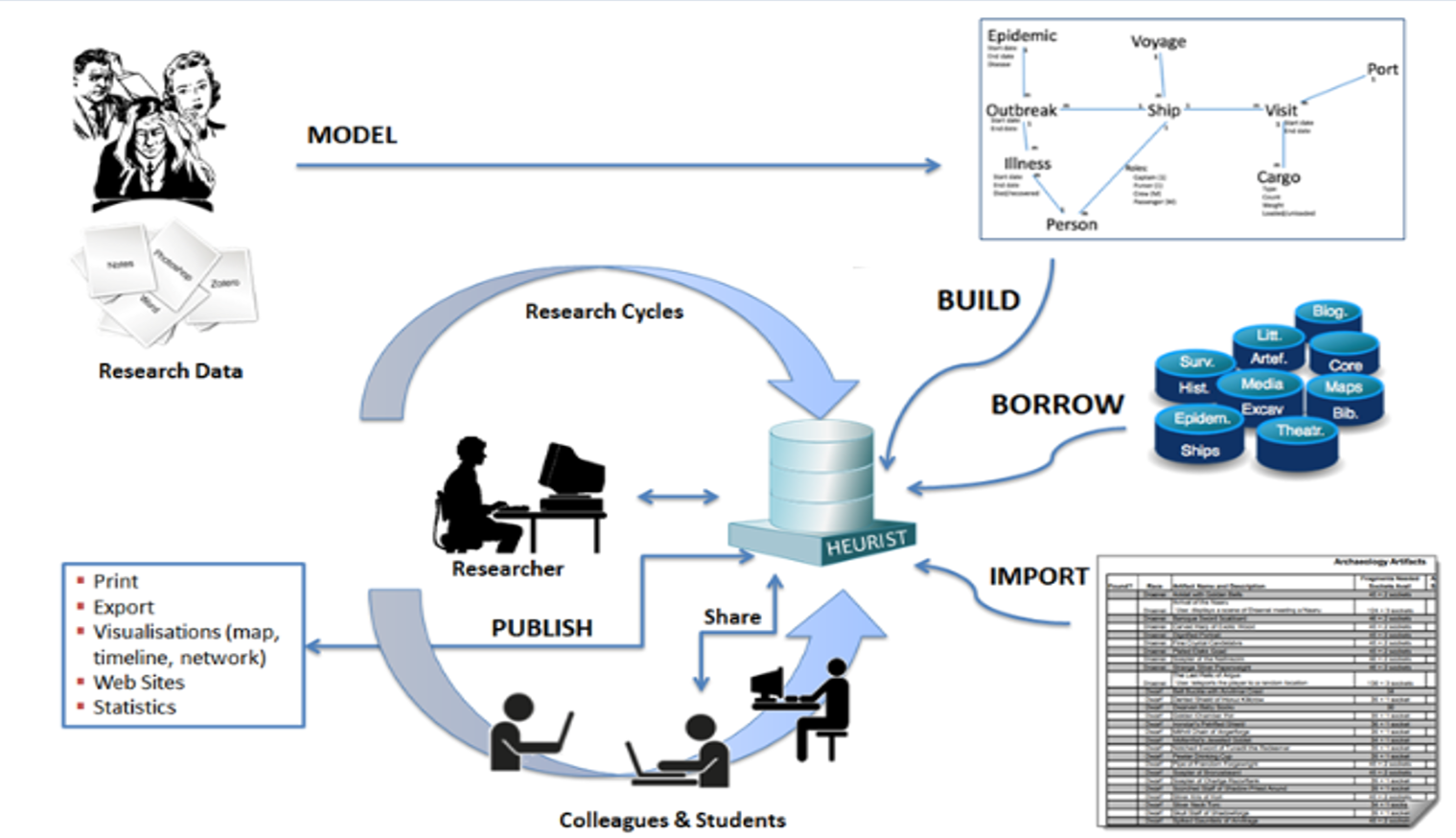
Fig. 1. Cycle de recherche Heurist.
En outre, Heurist offre un dispositif parfaitement compatible avec les objectifs de la science ouverte34 :
- En donnant la possibilité de décrire les données à travers des ontologies et des standards (DCMI-TERMS, BIBO, BIO, FOAF, DOAP, RDF, SKOS)
- En exportant des données sous des formats ouverts (CSV, XML, JSON, GEOJSON, KML) et réexploitables par de nombreux autres logiciels et protocoles (GEPHI, IIIF, MySQL)
- En liant les vocabulaires sur Heurist à des référentiels exposés sur le web à l’aide d’identifiants URI
- En rendant accessibles et interopérables les données sur le web via la publication d’un site web ou la génération de feeds ou flux web
- En permettant la récupération de données exportées depuis d’autres systèmes de gestion de base de données (par exemple MySQL, FileMaker ou Access) en s’appuyant sur des formats ouverts (CSV, XML)
Quelques éléments techniques
Heurist est un logiciel open source, il se base sur une infrastructure serveur de type LAMP très utilisée dans le développement web. Les chercheurs et chercheuses peuvent y avoir accès moyennant la création d’un compte sur un serveur hébergeant Heurist. Dans le cadre de cette leçon, nous utiliserons une instance hébergée par la TGIR Huma-Num qui met à disposition Heurist pour la communauté francophone de recherche en SHS.
Pour les personnes souhaitant tester le logiciel hors ligne, il est également possible d’héberger Heurist localement sur un ordinateur. Les informations pour son installation sont disponibles en anglais sur le site officiel d’Heurist.
Heurist s’appuie sur une conception relationnelle des données, mais simplifie certains aspects de cette modélisation afin de faciliter son utilisation. Nous abordons brièvement quelques concepts clés du modèle relationnel dans la partie « Modélisation des données ».
Organisation de la leçon
Dans cette leçon, nous partirons d’un jeu de données brut, discuterons sa modélisation et répercuterons cette modélisation dans Heurist afin d’importer les données pour enfin les publier en ligne.
Données utilisées pour le cours
Nous utiliserons tout au long du cours le jeu de données de « Localisation des sites de fouille archéologiques de l’INRAP », libre de droits et recensant 625 sites de fouilles en France.
Comme son nom l’indique, ce jeu de données localise des sites de fouilles archéologiques de l’Institut national de recherches archéologiques préventives (INRAP) et est enrichi d’informations de localisation précises comme :
- Les coordonnées géographiques du site de fouilles
- Un nom de site
- Des informations de localisation utilisant le découpage administratif français
- Région
- Département
- Commune
- Des données temporelles concernant l’intervention archéologique
- Des thèmes et des périodes historiques relatifs à ce qui a été découvert sur le site
Il s’agit d’un tableau de données CSV (format ouvert) dont les colonnes sont séparées par des points-virgules. Il peut être lu et édité avec un simple éditeur de texte ou un tableur.
Ces données, bien que relativement limitées et peu complexes, nous permettront d’utiliser les fonctionnalités de visualisation cartographique et chronologique de Heurist. Comme nous le verrons plus loin, Heurist porte bien son nom, car il permet, par la visualisation et une exploration différente de ses données (notamment via des fonctionnalités de visualisation cartographiques et de graphes), de découvrir et de corriger très rapidement des erreurs ou encore d’approfondir une analyse. Ces données peuvent par la suite être exportées vers d’autres logiciels spécialisés comme par exemple QGIS5 et Gephi. De surcroît, il facilite également la recherche et la navigation dans les données à travers de nombreux filtres configurables à des fins de recherche individuelle, de travail collaboratif ou encore de diffusion à destination d’un plus large public.
Pour les besoins de l’exercice et l’intégration correcte des données, certaines opérations de consolidation et de transformation ont été effectuées à l’aide de l’outil OpenRefine pour :
- La création de nouvelles colonnes Coordonnées décimales lat/long et la conversion des coordonnées géospatiales, notées initialement en Lambert 93, en notation décimale latitude/longitude afin de permettre leur intégration dans Heurist et de les référencer précisément, indépendamment de la période concernée ou des évolutions toponymiques
- L’ajout d’une colonne Id pour identifier de façon non ambiguë une intervention archéologique
- Le renommage de la colonne Nom de site en Nom d’intervention après avoir observé que les informations qu’elle contenait pouvaient concerner des éléments autres que ceux du site proprement dit, comme par exemple la date de l’intervention
- La désambiguïsation des noms de site afin d’identifier un lieu d’intervention de façon unique en procédant à :
- La création d’une nouvelle colonne Nom de site à partir de la colonne Nom d’intervention
- L’extraction d’informations, comme l’année d’intervention, relatives à l’intervention plutôt qu’au site
- L’homogénéisation orthographique des noms de lieux possédant les mêmes coordonnées géographiques
L’ensemble des données que nous utiliserons pour cette leçon sont à télécharger sur le répertoire GitHub de l’auteur ainsi que sur le dépôt du Programming Historian. Vous y trouverez quatre fichiers :
donnees_inrap_ph.csvperiodes.csvthemes.csvtype_intervention.csv
Ces fichiers CSV contiennent les informations descriptives d’une intervention incorporant les modifications nécessaires à une intégration dans Heurist, ainsi que la liste des termes décrivant les périodes, les thèmes et les types d’intervention tels qu’ils ont été définis dans le fichier source de l’INRAP.
Modélisation des données
Heurist s’appuie sur une conception relationnelle des données, il est ainsi important de rappeler certains éléments théoriques afin de comprendre son fonctionnement. Nous ne ferons pas un cours sur la modélisation relationnelle des données6, retenons néanmoins que celle-ci permet de garantir :
-
L’unicité de chaque enregistrement : un site archéologique ne sera renseigné qu’une seule fois dans la base de données. La création d’un doublon provoquera une erreur.
-
La non-redondance des données saisies : si un site fait l’objet de plusieurs interventions archéologiques, il ne sera pas nécessaire de saisir à chaque fois les données le concernant. De même, en cas de correction concernant ce site, il suffira de la réaliser une seule fois pour la voir répercutée sur toute la base.
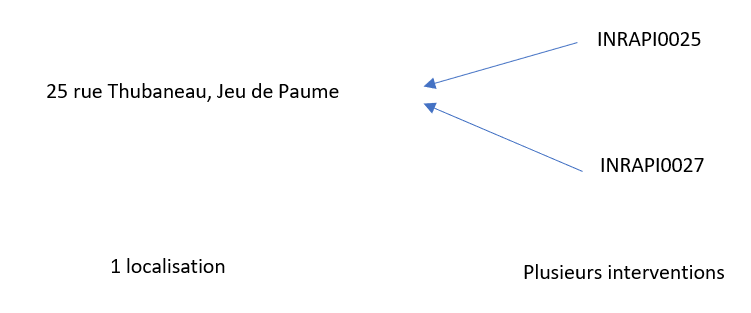
Fig. 2. Modélisation de l’unicité.
- Une organisation structurée des connaissances : les éléments d’une base de données sont organisés entre eux à travers des concepts descriptifs définis qui peuvent prendre la forme de vocabulaires contrôlés ou d’ontologies. Cela permet une cohérence dans la manière de décrire les objets au sein d’une même base de données ou d’un collectif de travail.
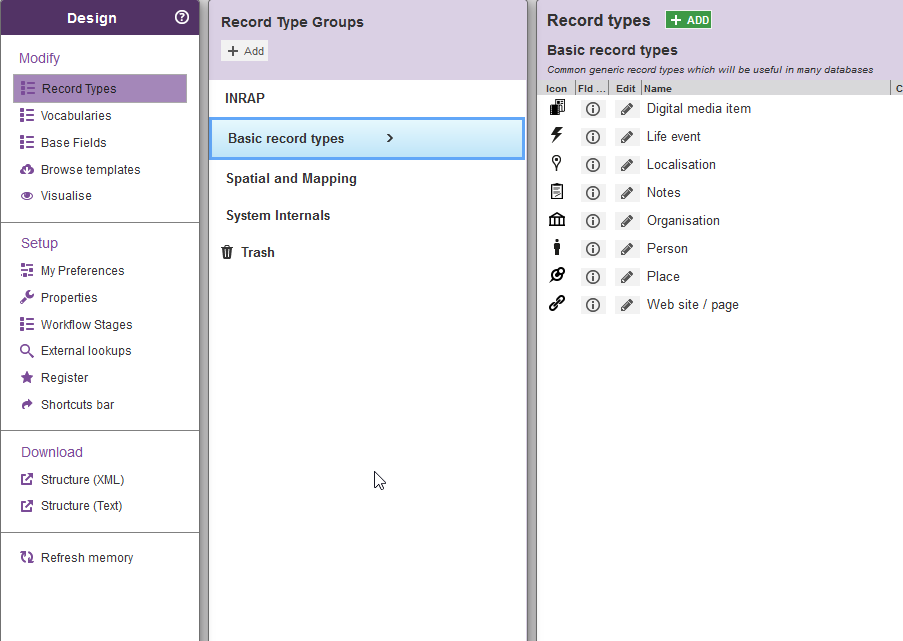
Fig. 3. Types d’enregistrement proposés par Heurist pour toutes nouvelles bases de données.
Entités et champs
Ouvrez le fichier donnees_inrap_ph.csv avec le tableur de votre choix (par exemple OpenOffice Calc ou MS Excel). Ce tableau reprend les noms de colonnes du fichier CSV source de l’INRAP avec quelques colonnes supplémentaires nécessaires à l’import dans Heurist.
Les colonnes de ce tableau peuvent être regroupées en deux types d’objets distincts :
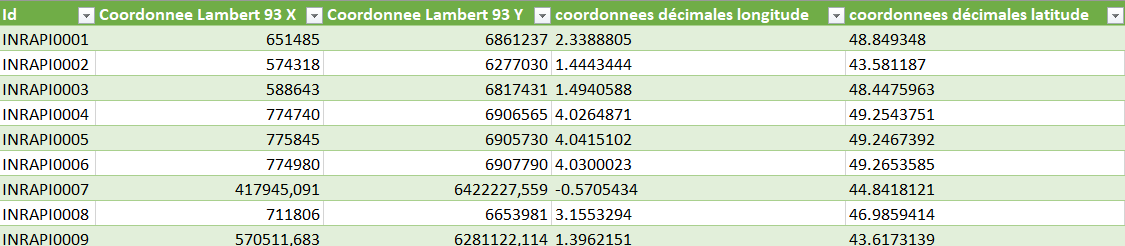
Fig. 4. Tableau INRAP
- Localisation
- Nom du site
- Coordonnées Lambert 93 X
- Coordonnées Lambert 93 Y
- Coordonnées décimales longitude
- Coordonnées décimales latitude
- Région
- Département
- Commune
- Intervention
- Id
- Nom d’intervention
- Date de début
- Date de fin
- Type d’intervention
- Thèmes
- Périodes
Nous appellerons ces objets des « entités ». Dans Heurist, elles portent le nom de « types d’enregistrement » (record types). Les colonnes qui composent ces types d’enregistrement y sont appelées « champs » (fields).
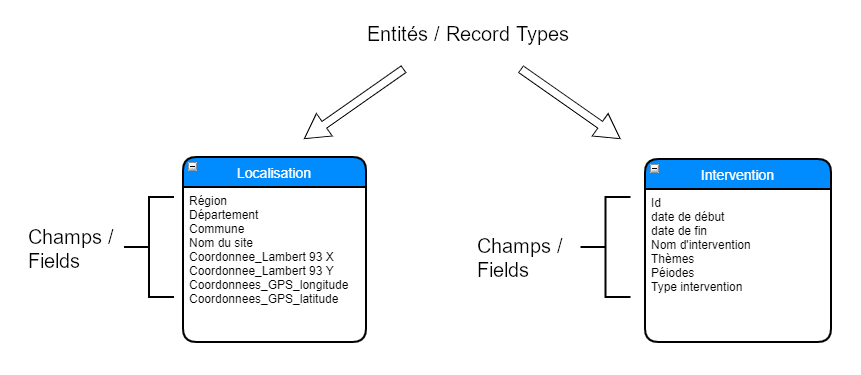
Fig. 5. Modélisation des entités et de leurs champs descriptifs.
Dans notre exemple, Intervention serait donc un type d’enregistrement, soit une entité, tandis qu’une intervention précise, par exemple celle d’Id INRAP0002, sera une instance de cette entité et sera appelée un « enregistrement » (record) dans Heurist.
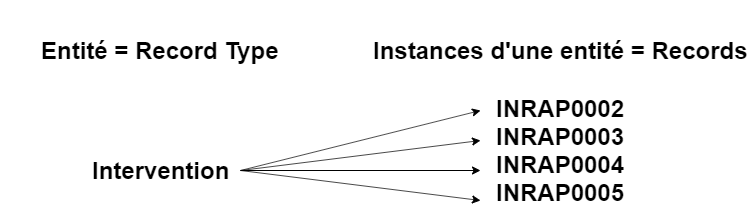
Fig. 6. Modélisation des instances d’une entité.
Parmi ses attributs, chaque entité dispose d’un identifiant unique permettant d’y faire référence de façon non ambiguë. Cet identifiant peut être un simple nombre incrémenté pour chaque occurrence de l’entité ou être construit de façon plus élaborée en fonction des besoins et du volume d’occurrences. Dans le cadre de nos données, l’attribut Id identifie une intervention de façon non ambiguë et Nom de site fait référence à une et une seule localisation. En pratique, nous pouvons donc générer un identifiant de deux façons : soit en le construisant de façon arbitraire pour la cohérence de notre modèle conceptuel (champ Id) soit en sélectionnant un attribut qui porte déjà ce rôle dans notre base de données (champ Nom de site).
Les relations
Les entités ne sont pas des objets isolés dans notre base de données. Au contraire, elles sont reliées entre elles afin de décrire des événements ou des objets complexes. Par exemple, étant donné que nous souhaitons conserver le lien entre un lieu et une opération archéologique spécifique, une intervention archéologique sera liée à une localisation. Nous verrons plus loin comment Heurist gère ce type de relations en pratique.
Champs multivalués et cardinalité
Les cellules des colonnes Thèmes et Périodes de notre fichier donnees_inrap_ph.csv, peuvent comporter plusieurs thèmes ou périodes séparés par le symbole « # ». Pour permettre l’interrogation de celles-ci de façon fine, nous devons les séparer tout en maintenant leur relation respective avec l’opération archéologique qu’elles décrivent. Cela veut donc dire que l’intervention d’Id INRAP0002 sera reliée aux thèmes « Antiquité » et « Protohistoire » et non au thème « #Antiquité#protohistoire ».
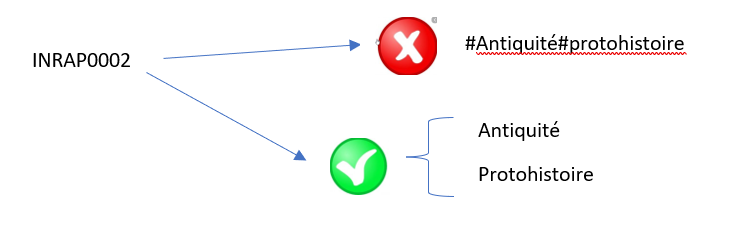
Fig. 7. Modélisation des champs multivalués.
Il faut indiquer quelque part dans notre modèle qu’une intervention peut avoir plusieurs thèmes: c’est la cardinalité, qui permet de préciser si l’entité décrite peut être reliée à d’autres entités ou encore si des informations descriptives du même type peuvent être répétées. En outre, elle détermine le caractère obligatoire ou optionnel de cette relation. Essentiellement, elle répond aux questions du type :
- Une intervention est-elle obligatoirement liée à un thème ? (information descriptive)
- Une intervention est-elle liée à plusieurs thèmes ? (information descriptive)
- Une intervention est-elle obligatoirement liée à un site ? (relation à une autre entité)
- une intervention est-elle liée à plusieurs sites ? (relation à une autre entité)
Nous ne détaillerons pas ici la formalisation de la notation de ces cardinalités, mais en pratique dans Heurist cela sera défini pour un champ donné par les paramètres Repeatability et Requirement (fig. 8) :
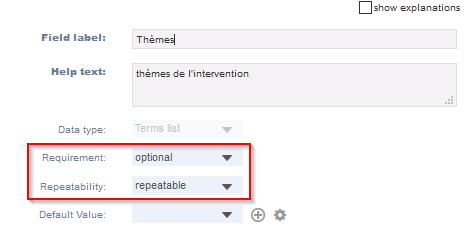
Fig. 8. Champs multivalués dans Heurist.
Vocabulaires contrôlés
Nous venons de rencontrer le cas des thèmes ou périodes qui pouvaient décrire une même intervention. De même, Type d’intervention fait référence à un vocabulaire, même si celui-ci compte uniquement deux termes.
Nous avons déjà abordé rapidement ce point dans la partie sur la cohérence des données. Fonctionnellement, les vocabulaires contrôlés s’opposent à une saisie textuelle libre. Concrètement, il s’agit de lister, de catégoriser et de hiérarchiser des concepts, en nombre fini, afin d’éviter certains biais courants lors des saisies textuelles libres tels que :
- L’incohérence orthographique (M ≠ m, Moyen-Âge ≠ Moyen Âge)
- La synonymie (habitats ≈ édifices ≈ architecture)
- L’inclusion (pratiques funéraires ⊆ cultes)
L’utilisation de vocabulaires contrôlés permet ainsi d’optimiser les requêtes et l’analyse sur des données : d’une part, elle réduit le nombre de termes descriptifs, en supprimant les synonymies et en corrigeant les incohérences orthographiques, d’autre part, elle organise hiérarchiquement les concepts, une requête pouvant par exemple se limiter à une branche hiérarchique au sein d’un même vocabulaire contrôlé.
C’est aussi une façon de se mettre d’accord, au sein d’un collectif de travail, sur une certaine description du monde comme le font les thésaurus ou les ontologies. Par ailleurs, dans une optique de science ouverte, utiliser des vocabulaires partagés par une communauté scientifique plus large, surtout lorsqu’ils sont normalisés, est également un gage d’interopérabilité et de compréhension mutuelle.
Afin de gérer ces listes de termes, Heurist utilise des « vocabulaires » (vocabularies). Chaque vocabulaire (vocabulary) contient des « termes » (terms). Heurist intègre nativement un certain nombre de vocabulaires, dont certains sont issus de standards du web de données et pourront être très utiles à la communauté de recherche en SHS.
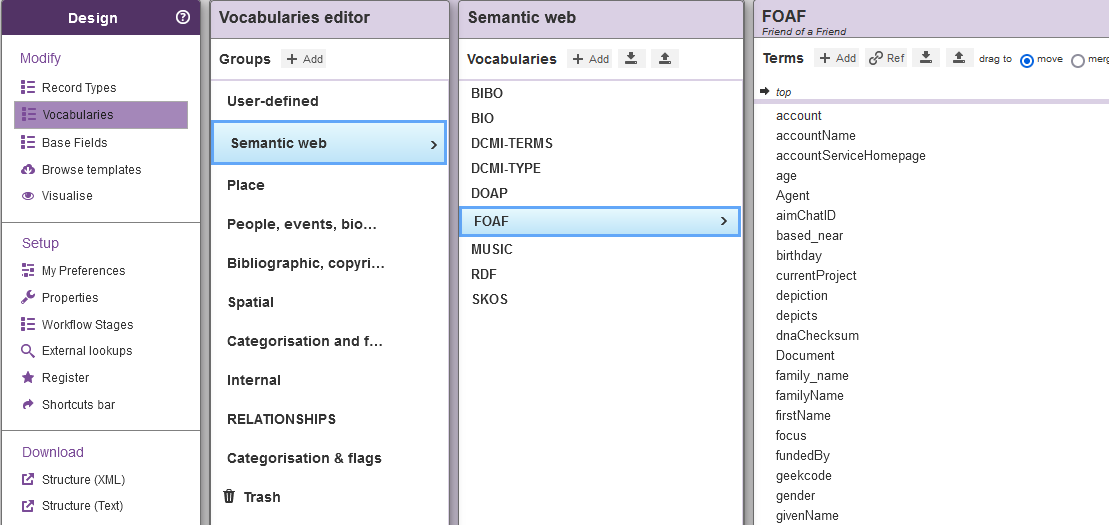
Fig. 9. Vocabulaires contrôlés.
Heurist propose également un système de modèles préétablis de types d’enregistrement via l’onglet Browse templates du mode Design, organisés thématiquement, et que n’importe qui peut utiliser dans sa propre base. C’est aussi une source d’inspiration très intéressante, car, en plus des modèles proposés par Heurist, il est possible de consulter et d’importer des modèles de bases de données d’autres personnes utilisant le logiciel.
En complément d’Heurist, des outils comme Opentheso, soutenus notamment par le Consortium MASA, ou encore Loterre, de l’Institut de l’information scientifique et technique du Centre national de la recherche scientifique (Inist CNRS), peuvent être très utiles pour organiser ou consulter des thésaurus scientifiques multilingues et multihiérarchiques compatibles conformes aux standards du web des données ouvertes.
Créer une base de données sur Heurist
Une fois ces quelques informations théoriques rappelées, nous pouvons passer à leur mise en pratique dans Heurist.
Création d’un compte utilisateur
Rendez-vous sur l’instance d’Heurist hébergée sur Huma-Num puis suivez les instructions pour créer un compte ainsi qu’une base de données.
Une fois connectés à cette nouvelle base, vous êtes redirigés vers l’interface de Heurist.
Fig. 10. Page d’accueil de Heurist.
La colonne de navigation à gauche est organisée par groupes fonctionnels :
- Explore donne accès à la navigation dans les données, c’est la fonction clef de l’exploitation d’une base Heurist
- Design permet la modélisation des données
- Populate donne la possibilité d’ajouter de nouveaux enregistrements
- Publish permet de gérer la publication de vos données en ligne via un site web ou une page dédiée
- Admin offre la possibilité de gérer vos bases de données ainsi que les utilisateurs et utilisatrices
Une rubrique d’aide est accessible pour chaque mode via le « ? » entouré d’un cercle.
Création de notre modèle de données
- Cliquez sur Design
- Puis sur Record types
- Par défaut, le premier groupe de types d’enregistrement est sélectionné
- Chaque type d’enregistrement est résumé sur une ligne dans la fenêtre de visualisation de droite
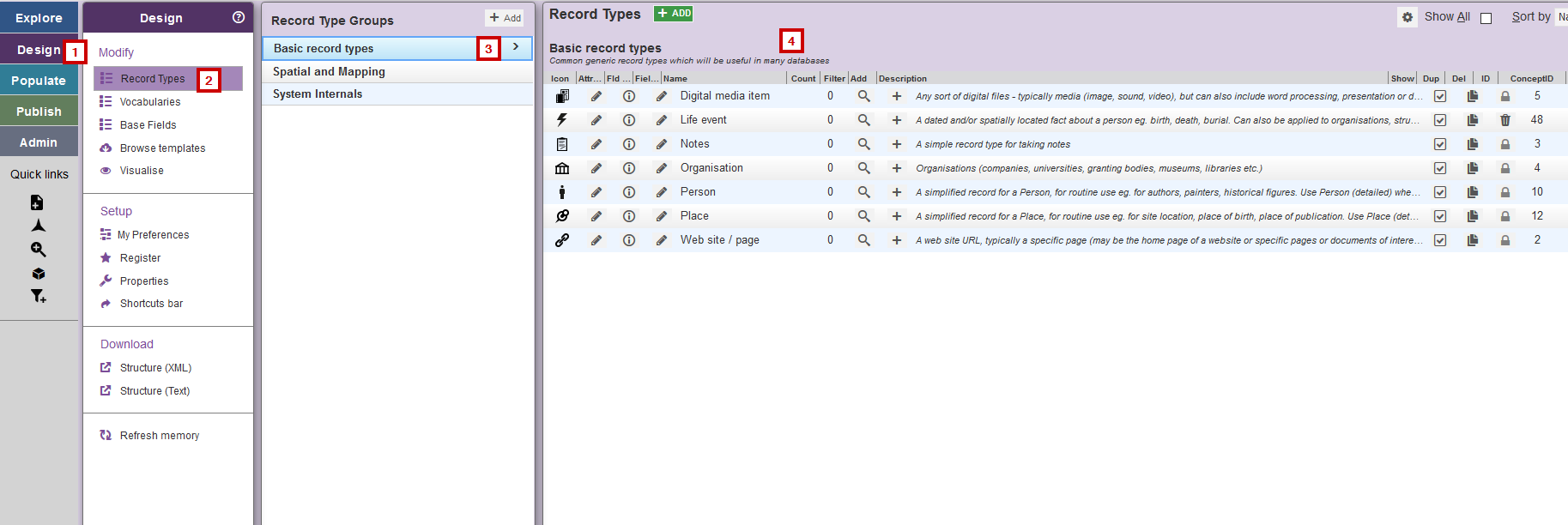
Fig. 11. Record types.
Création de l’entité de localisation
Comme nous l’avons vu précédemment, nous avons :
- Deux entités principales
- Localisation
- Intervention
- Trois vocabulaires
- Thèmes
- Périodes
- Type d’intervention
Afin de mieux organiser les données, ajoutez un nouveau groupe de types d’enregistrement en cliquant sur Add et nommez-le « INRAP ».
Les champs dont nous avons besoin pour l’entité localisation sont les suivants :
- Localisation
- Nom du site (champ texte)
- Coordonnées Lambert 93 X (champ texte)
- Coordonnées Lambert 93 Y (champ texte)
- Coordonnées décimales longitude (champ lat/long)
- Coordonnées décimales latitude (champ lat/long)
- Région (champ texte)
- Département (champ texte)
- Commune (champ texte)
Ajoutez un type d’enregistrement pour définir l’entité de localisation.
- Cliquez sur Add
- Dans la fenêtre vous prévenant que vous pouvez importer des record types existants, cliquez sur Continue
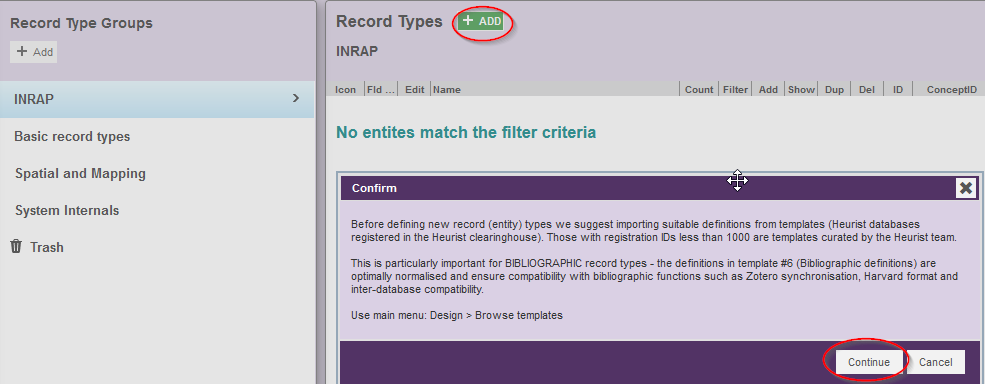
Fig. 12. Ajout d’un record type.
Remplissez les informations concernant le type d’enregistrement de localisation auquel vous donnerez le nom de Site.
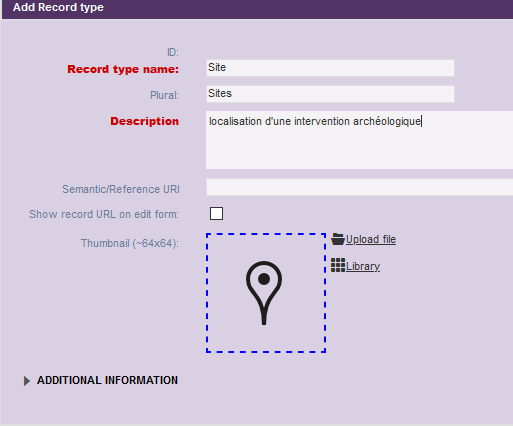
Fig. 13. Entité de localisation.
Il vous est ensuite demandé de choisir le champ par défaut de ce type d’enregistrement. Laissez le choix par défaut et continuez.
Dans Heurist, chaque champ est décrit à l’aide des informations suivantes :
- Un nom
- Un type de données
- Texte libre
- Liste de vocabulaires
- Information géospatiale
- Zone de texte
- Une taille (field width), soit une limite dans le nombre de caractères du formulaire de saisie
- Un statut
- Caché (grisé)
- Optionnel
- Obligatoire (génère une erreur si l’information n’est pas remplie)
- Recommandé
- Une répétabilité, une seule ou plusieurs occurrences de ce champ (par exemple il peut y avoir plusieurs thèmes ou périodes pour une même intervention)
Renommez le champ Name/title par défaut en Nom du site. Conservez les autres paramètres avec leur nom par défaut (required, single, field width).
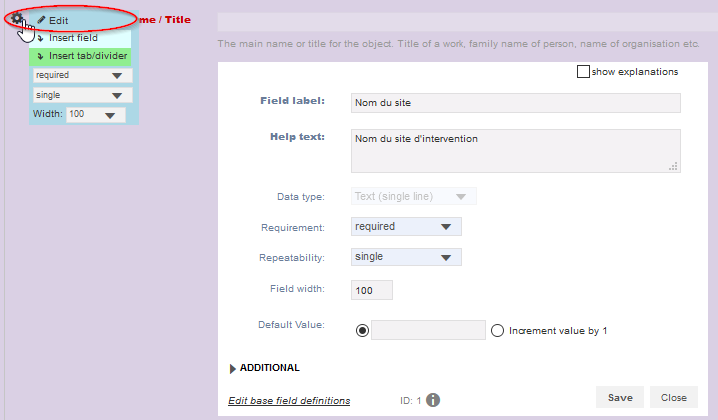
Fig. 14. Champ nom du site.
Il y a cinq autres champs textuels dans notre type d’enregistrement. Nous allons en créer un ensemble et vous pourrez créer les autres vous-mêmes en suivant la même procédure.
Cliquez sur Insert field.
Remplissez les éléments obligatoires en rouge :
- Field name
- Help text
- Data type
Sélectionnez le type de données (data type) suivant : Text (single line), car dans notre cas il correspond aux champs textuels attendus.
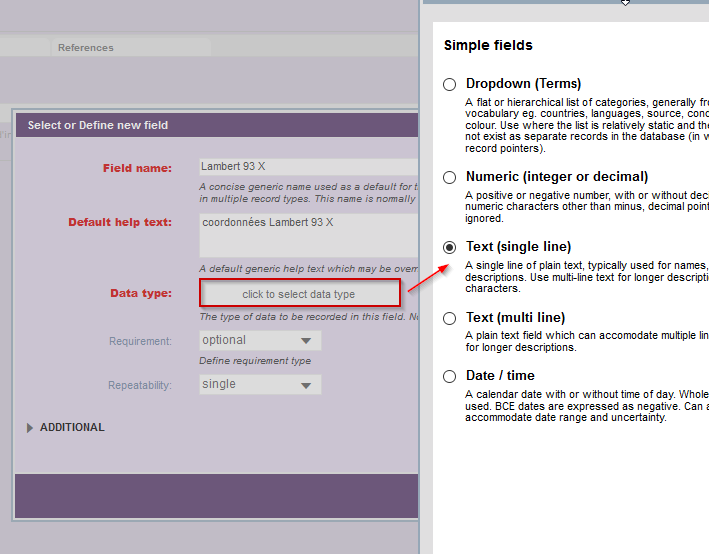
Fig. 15. Champ Lambert 93 X.
Gardez les autres valeurs par défaut et sauvegardez.
Répétez la même opération pour les champs :
- Coordonnées Lambert 93 Y
- Région
- Département
- Commune
Cela vous donne l’organisation suivante :
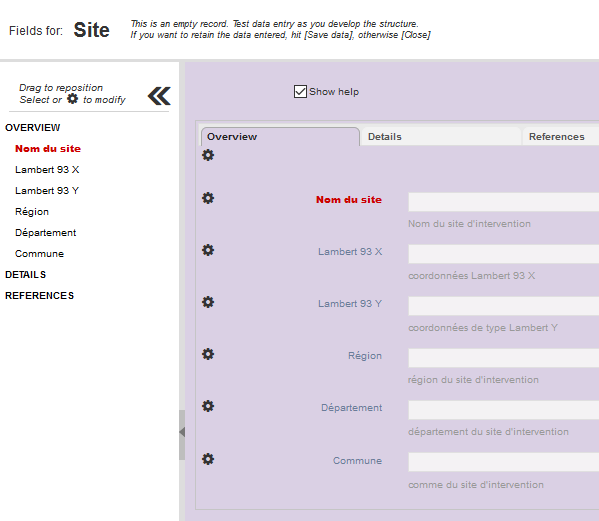
Fig. 16. Champ textuel.
Il ne reste que les informations géoréférencées. La démarche sera la même, seul le type de données sera différent. Le type géospatial de Heurist prend des données en format lat/long, un seul champ permettra donc d’intégrer les deux valeurs latitude et longitude de notre fichier CSV :
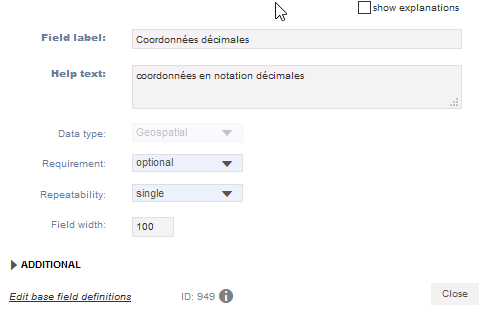
Fig. 17. Champ géoréférencé.
Ajoutez le champ suivant avec le type de données suivant : Coordonnées décimales.
La création de l’ensemble des champs du type d’enregistrement Site est ainsi terminée.
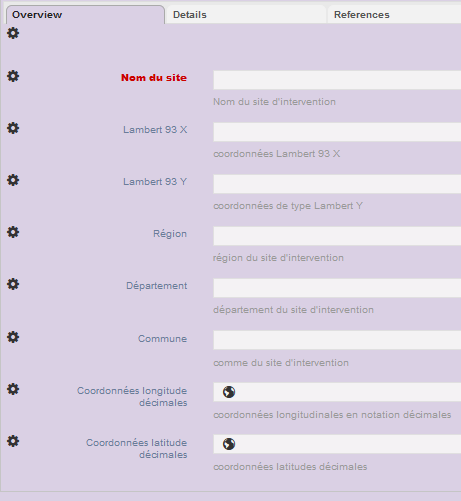
Fig. 18. Ensemble des champs du type d’enregistrement Site.
Création des vocabulaires
- Cliquez sur Vocabularies
- La deuxième colonne en partant de la gauche liste les catégories ou groupes de vocabulaires et se trouve par défaut sur la catégorie User-defined
- La colonne suivante liste les vocabulaires de ce groupe, ici deux vocabulaires
- Country
- Place type
- Enfin, la partie la plus à droite liste l’ensemble des termes de ce vocabulaire
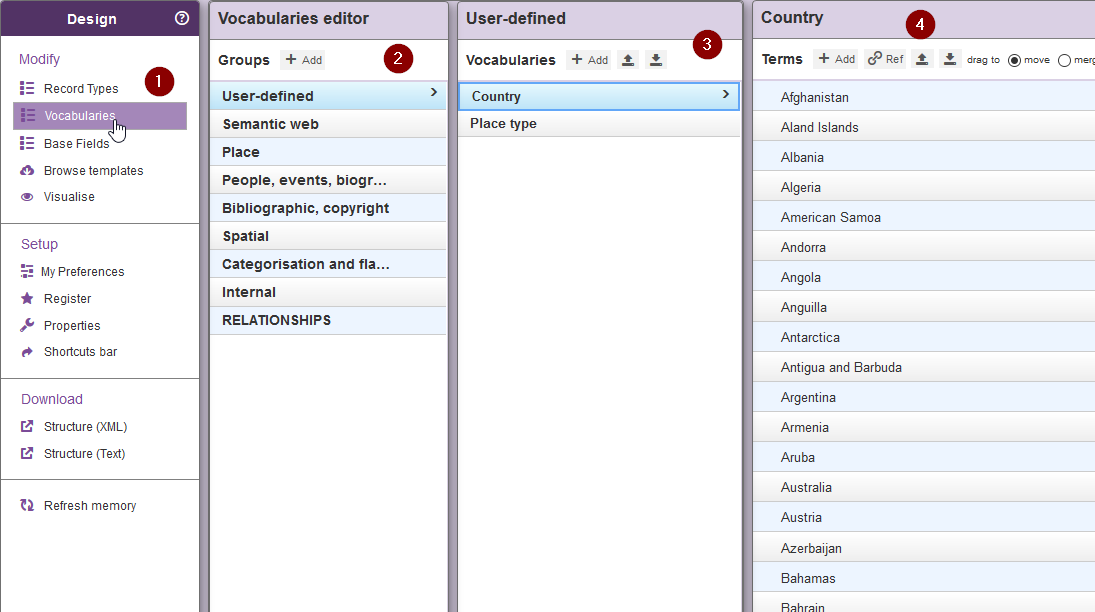
Fig. 19. Vocabulaires.
Le groupe User-defined convient bien, vous allez donc créer les trois vocabulaires dans celui-ci en cliquant sur Add.
Fig. 20. Ajouter un vocabulaire.
- Renseignez le label Thèmes ainsi qu’une courte description
- Il est également possible d’ajouter une URI relative à un terme de vocabulaire ou d’une ontologie, ce n’est pas nécessaire dans le cas présent
- Sauvegardez
Une fois le vocabulaire créé, plusieurs fonctionnalités sont disponibles :
- Ajouter un terme de vocabulaire manuellement
- Ajouter une liste de termes par référence à un autre vocabulaire
- Exporter les termes
- Importer les termes
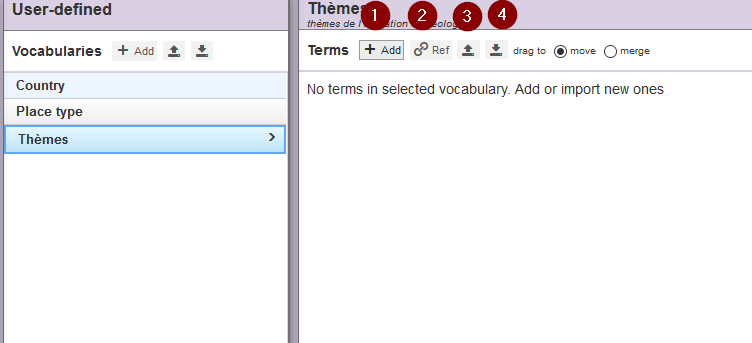
Fig. 21. Éditer un vocabulaire.
Pour ne pas avoir à saisir manuellement les termes de vocabulaire, vous allez utiliser la fonctionnalité d’import proposée par Heurist afin d’intégrer les contenus des fichiers periodes.csv, themes.csv et type_intervention.csv téléchargés en début de leçon.
Cliquez sur Import.
- Copiez et collez la liste des thèmes du fichier
themes.csvdu dossier zip que vous venez de télécharger dans la fenêtre prévue à cet effet en étape 1 - Cochez la case Labels in line 1 puis cliquez sur Analyse
- Vérifiez que la liste importée ne présente pas d’erreur
- Vérifiez que Term (label) est bien rempli avec le nom du vocabulaire (ici Thèmes) et cliquez sur Import
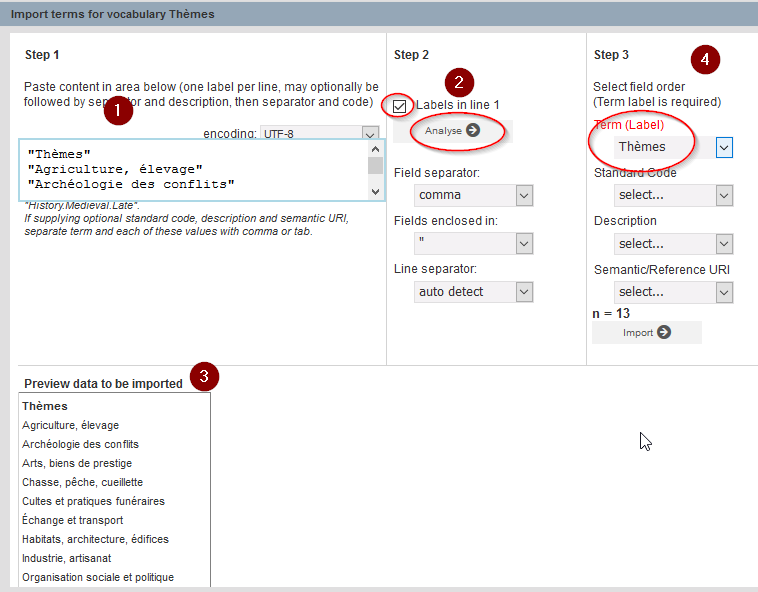
Fig. 22. Import des thèmes INRAP dans Heurist.
Suivez exactement la même opération que précédemment avec le vocabulaire Périodes en utilisant le fichier periodes.csv.
Pour Type d’intervention, la liste ne contenant que deux termes (« Diagnostic » et « Fouille »), vous pouvez soit réitérer la même opération, soit les insérer manuellement un par un en cliquant sur Add dans le vocabulaire Type d’intervention que vous aurez créé.
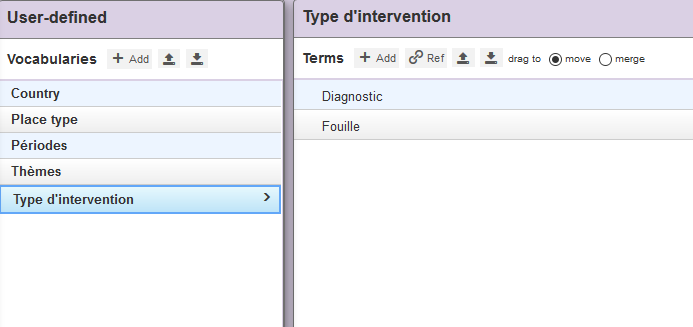
Fig. 23. Liste des vocabulaires.
Création de l’entité Intervention
- Retournez sur Record Type > INRAP
- Pour ajouter un type d’enregistrement, cliquez sur Add comme précédemment avec le type d’enregistrement Site
Sélectionnez les champs par défaut pour notre entité : Name/title, Start date, End date.
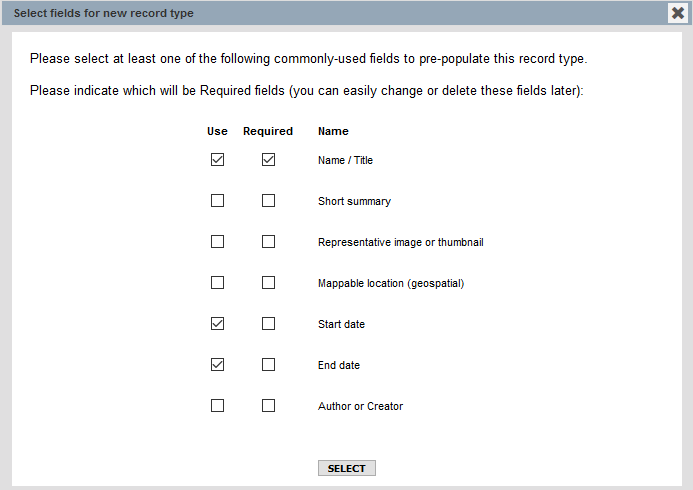
Fig. 24. Création de l’entité Intervention.
Pour rappel, nous avons besoin des champs suivants :
- Intervention
- Identifiant d’intervention
- Nom d’intervention
- Date de début
- Date de fin
- Type d’intervention (se réfère au vocabulaire du même nom)
- Thèmes (se réfère au vocabulaire du même nom)
- Périodes (se réfère au vocabulaire du même nom)
- Localisation (se réfère à l’entité du même nom)
Renommez les champs comme suit :
- Name/title devient Identifiant d’intervention
- Start date devient Date de début
- End date devient Date de fin
Vous allez ajouter les trois champs de vocabulaires contrôlés.
- Cliquez sur Insert
- Renseignez le label du champ ainsi que sa description et sélectionnez le type de champ
- Par défaut, Dropdown (Terms) est sélectionné. Cliquez sur Use this field type.
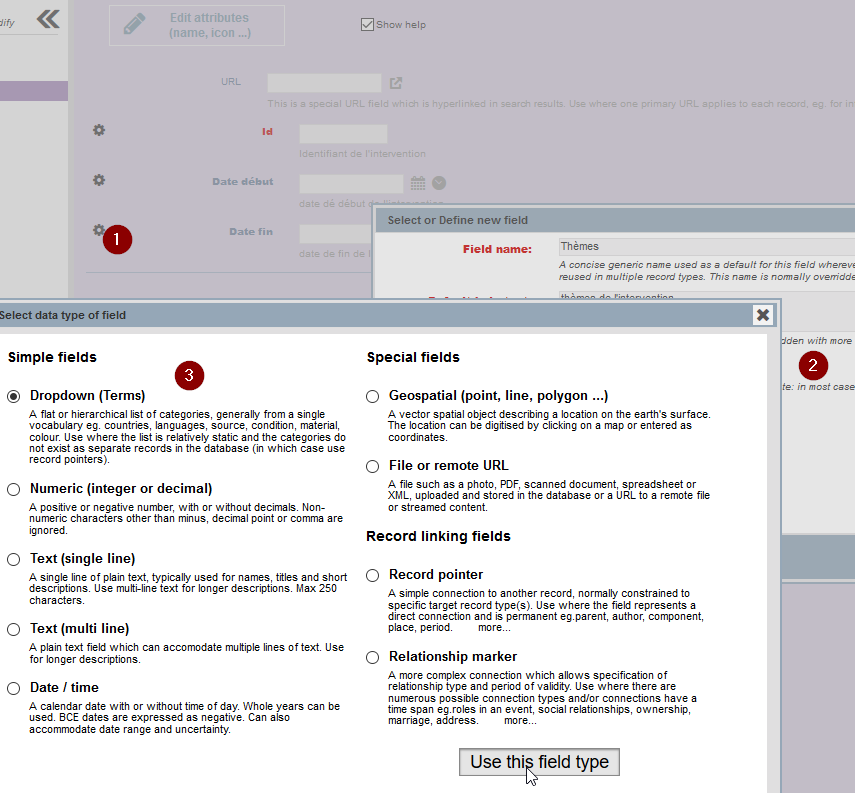
Fig. 25. Ajout d’un champ de vocabulaire.
Enfin, sélectionnez le vocabulaire Thèmes, rendez le répétable (repeatable) et sauvegardez.
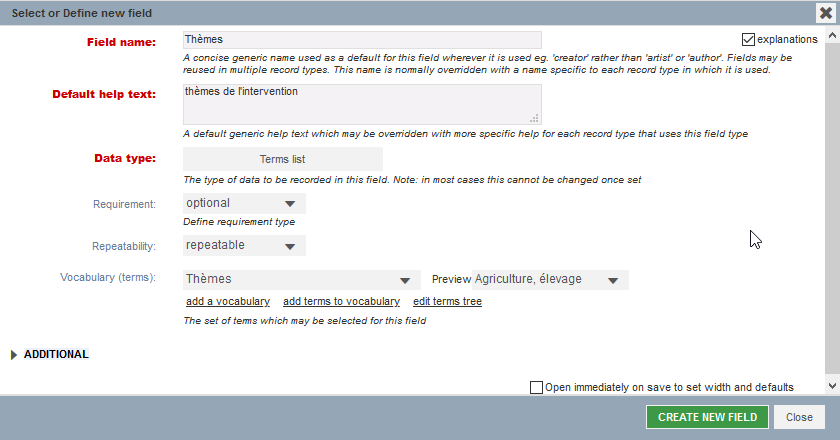
Fig. 26. Ajout du champ Thèmes.
Effectuez la même opération pour Périodes et Type d’intervention à la seule différence que Type d’intervention ne sera pas répétable.
Ajoutez maintenant la référence à Site en sélectionnant le data type suivant : Record pointer.
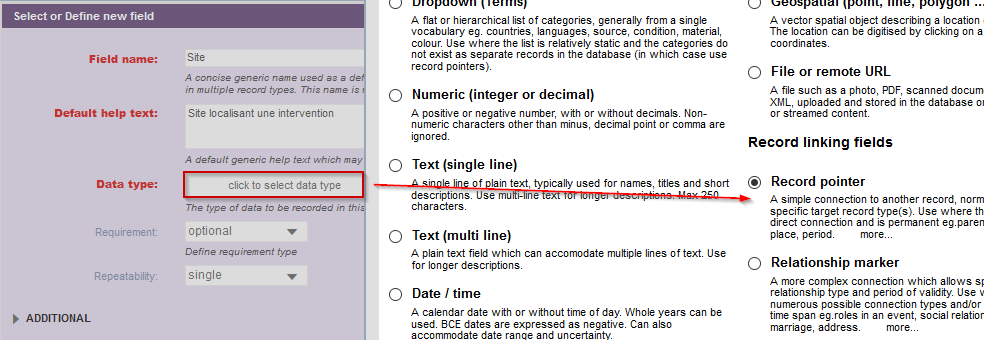
Fig. 27. Ajout du champ Site.
Pour finaliser la création de ce champ, sélectionnez le type d’enregistrement que nous souhaitons référencer, soit le type d’enregistrement Site dans le groupe de types d’enregistrement INRAP.
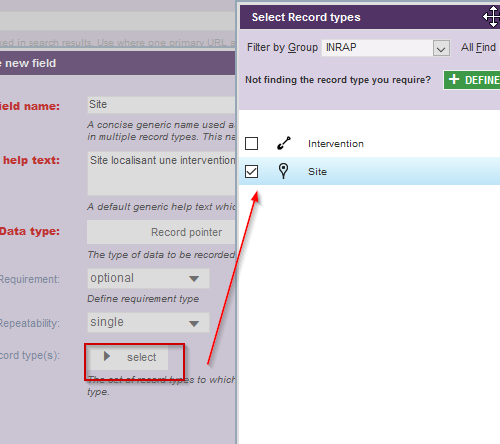
Fig. 28. Sélection de l’entité Site.
Pour terminer, ajoutez le champ Nom de l’intervention qui sera de type text single line en suivant la même procédure que pour les champs textuels du type d’enregistrement Site.
Vous obtenez un type d’enregistrement Intervention composée des champs définis plus haut ou précédemment mentionnés.
Importer des données dans Heurist
Le modèle Heurist est terminé, vous allez pouvoir l’alimenter avec les données INRAP à votre disposition.
Import des données de localisation
Pour ce faire, nous allons changer de mode, à partir du menu principal en haut à gauche de l’interface de notre base, et passer dans l’onglet Populate.
Comme son nom l’indique, ce mode regroupe les fonctionnalités permettant d’alimenter le modèle que nous avons élaboré dans la partie Design.
À partir de Populate, il est possible soit d’ajouter un enregistrement individuel, soit d’effectuer des imports de données en lots via des fichiers structurés au format CSV (ou encore HML qui correspond au format XML d’Heurist). La possibilité est également offerte d’effectuer une synchronisation avec une collection Zotero pour importer des données bibliographiques le cas échéant.
Dans notre cas, le fichier source étant un fichier CSV, cliquez sur Delimited text/CSV puis sur Upload new file (CSV/TSV) et chargez le fichier donnees_inrap_ph.csv téléchargé en début de leçon.
Fig. 29. Import CSV.
-
Conservez les quatre premiers paramètres par défaut et modifiez Multivalue separator en « # » via la liste déroulante afin de séparer les occurrences multiples de périodes et de thèmes tels qu’ils sont représentés dans notre fichier CSV
-
Cliquez sur Analyse data pour afficher une visualisation des données, vérifiez que ces données sont correctement interprétées et cliquez sur Continue (cf. Fig. 30)
-
Dans Select record type, choisissez Site et cliquez sur OK.
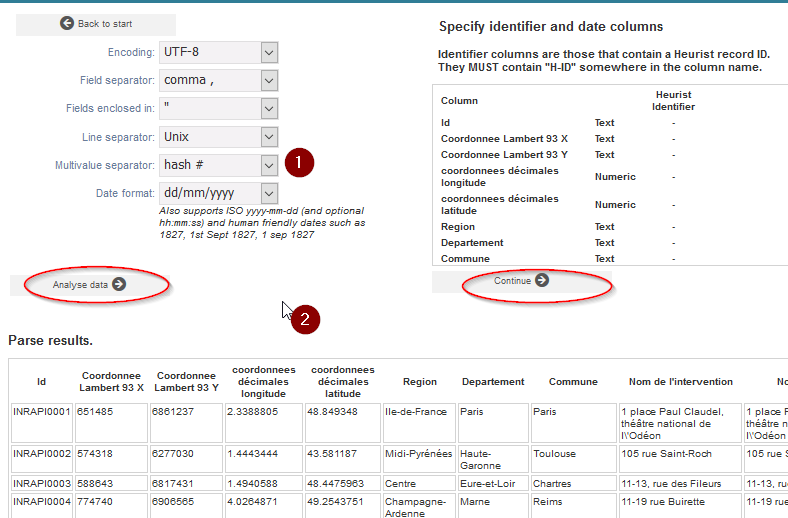
Fig. 30. Analyse du fichier CSV.
Une fois les données analysées et chargées dans Heurist, la première étape consiste à vérifier si des enregistrements de type Site existent déjà dans le système. Heurist effectue une recherche via un ou des champs que vous pouvez sélectionner lors de la procédure d’import (par exemple un champ de type identifiant n’amenant pas d’ambiguïté). Si Heurist trouve des valeurs dans sa base correspondant à celles présentes dans le fichier CSV, il les met à jour si nécessaire ou bien les crée s’il ne trouve rien.
Pour ce faire, à partir de la boîte de dialogue qui apparaît lorsque Heurist effectue cette opération :
- Cochez la case Nom du site dans la colonne de gauche correspondant aux données du fichier CSV et sélectionnez Nom du site dans la colonne correspondant au type d’enregistrement Site dans Heurist
- Cliquez sur Match against existing records
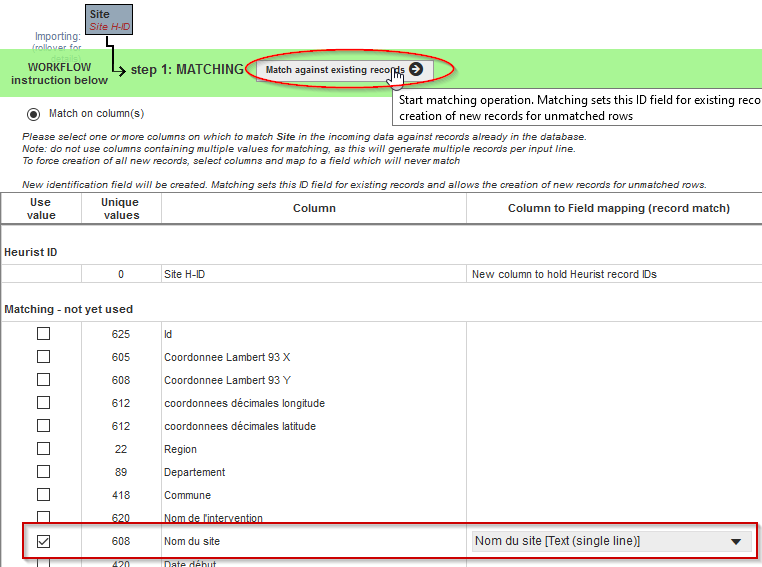
Fig. 31. Correspondance avec des enregistrements existants.
La deuxième étape consiste à indiquer à Heurist quelle colonne du tableau va renseigner quel champ dans le type d’enregistrement Site. Il suffit donc de cocher les cases des colonnes à importer et de renseigner dans la colonne de droite les champs auxquels elles correspondent :
- Cochez les champs du fichier CSV à importer et sélectionnez en face les champs qu’ils doivent alimenter
- Vous pouvez visualiser et naviguer dans les enregistrements qui vont être créés dans la colonne de droite
- Cliquez sur Prepare puis Start insert
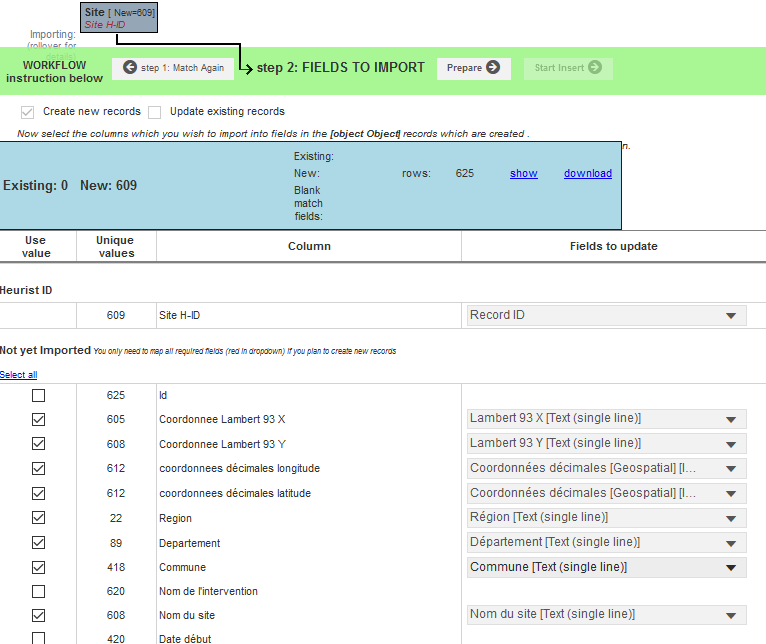
Fig. 32. Insertion des données CSV.
L’ensemble des entrées ont été créées et une fenêtre de résumé vous indique les opérations effectuées :
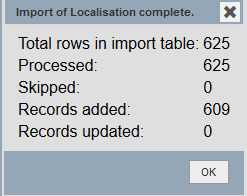
Fig. 33. Résumé des opérations effectuées.
Import des données relatives aux interventions sur site
Après avoir chargé nos données de localisation, il nous reste à importer les interventions. Pour ce faire, cliquez sur Back to start pour retourner au chargement du fichier CSV.
Fig. 34. Retour au chargement du fichier.
Pour finir ce projet, nous devons charger le reste des données liées aux interventions. Nous allons effectuer les mêmes opérations de chargement du fichier que précédemment.
Arrivés à Select record type, choisissez cette fois-ci Intervention, cochez la case Site pour gérer les dépendances entre les enregistrements puis validez.
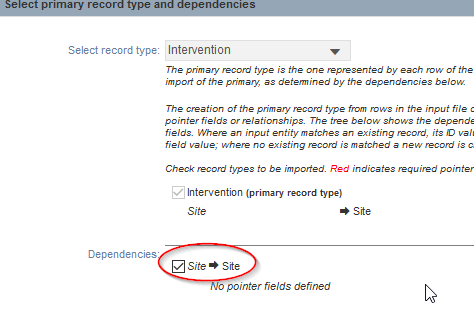
Fig. 35. Sélection de l’entité Intervention pour import.
Comme à chaque import, Heurist vérifie d’abord si des enregistrements existent déjà. Sachant qu’une Intervention est liée à un Site, Heurist vérifie en premier si les sites qui sont dans le fichier CSV sont déjà présents dans la base de données. Il faut donc faire correspondre le champ Nom du site du fichier CSV avec le champ Nom du site du type d’enregistrement Site dans Heurist.
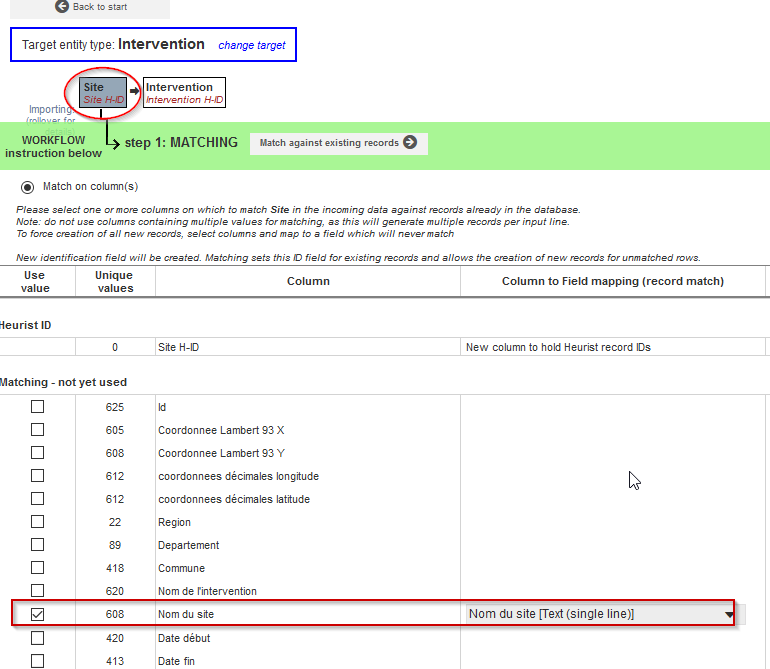
Fig. 36. Correspondance avec des sites déjà présents dans la base de données.
Heurist vérifie les éléments et, chose relativement classique, le fichier source n’étant pas parfait, trouve des doublons dans les noms de site et propose de nous aider à lever les ambiguïtés. En l’occurrence, il s’agit de la même chaîne de caractères, mais avec une majuscule à l’initiale pour un site et sans majuscule pour l’autre. Cliquez sur Resolve ambiguous matches puis vérifiez les enregistrements déjà intégrés dans la base de données pour enfin aligner les enregistrements avec les données trouvées dans le fichier CSV.
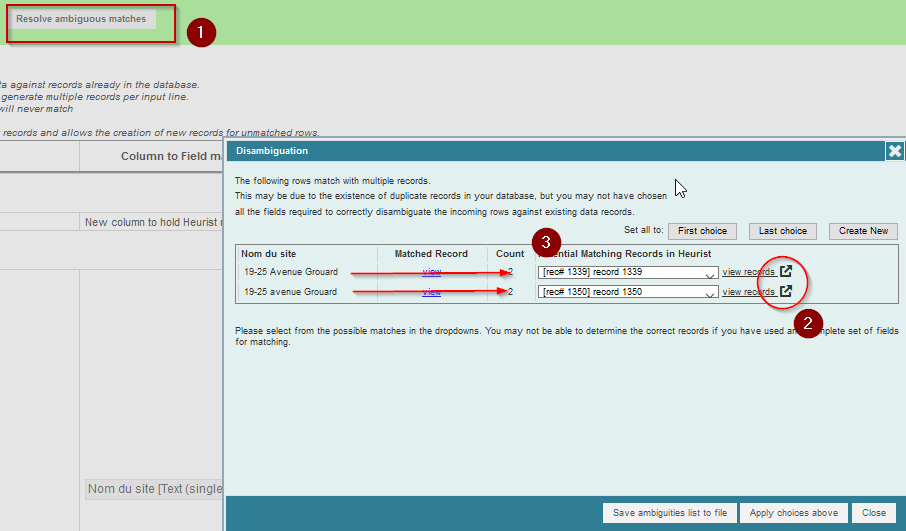
Fig. 37. Résolution des ambiguïtés.
Une fois les doublons résolus, nous effectuons la même opération pour les données de l’entité Intervention. Prenez soin de renseigner, comme nous venons de le faire pour l’import des données de localisation, les champs d’Intervention que vous souhaitez remplir via votre fichier CSV, avant de valider la préparation et de finir l’import. À la fin de l’opération, vous devez obtenir une fenêtre vous indiquant l’insertion de 625 nouveaux enregistrements.
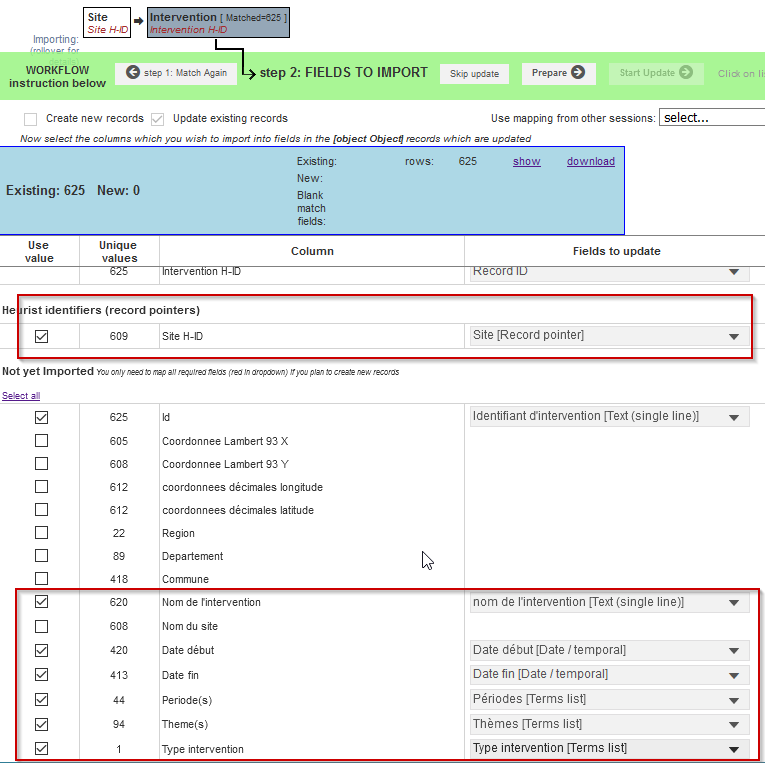
Fig. 38. Import des données d’Intervention.
Explorer et modifier les données
Explorer les données de localisation
Nous avons bien importé nos données. Quittons à présent Populate et revenons au menu principal pour nous rendre cette fois à l’onglet Explore qui présente un panel de fonctionnalités permettant d’explorer et de filtrer les données chargées dans la base Heurist.
Pour afficher les sites que vous venez d’importer, cliquez sur l’onglet Explore dans la colonne de gauche, placez votre curseur sur Entities puis sélectionnez Site.
Les sites sont listés par leur identifiant Heurist (H-ID), ce qui donne un label du type Record 1250. Nous allons voir comment modifier ce label peu intelligible plus loin dans la leçon.
En cliquant sur un enregistrement, les données le concernant apparaissent dans le volet de visualisation de droite, y compris la relation avec une intervention archéologique. Par défaut, le mode Record View est sélectionné. Il affiche l’ensemble des informations d’un enregistrement et donne accès à son édition.
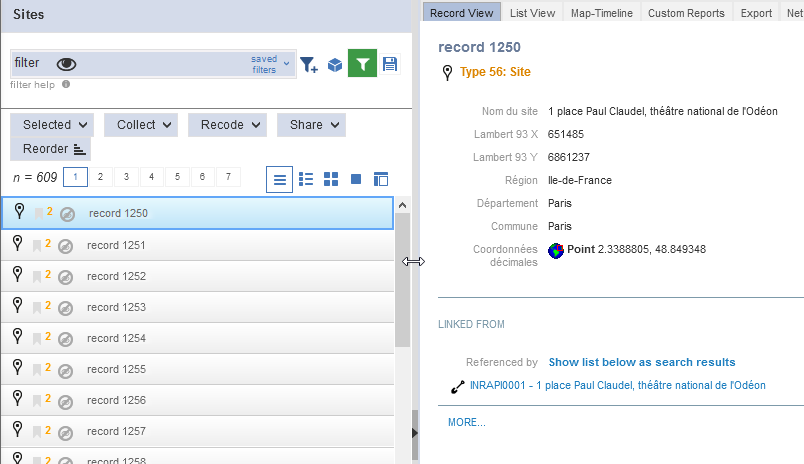
Fig. 39. Afficher le détail d’un enregistrement.
D’autres options de visualisation sont disponibles :
-
Map-Timeline permet une visualisation spatiale et temporelle des données
-
List view permet de lister les enregistrements sous forme de tableau et de les exporter sous forme de tableurs ou en format PDF
-
Custom reports (pour utilisateurs et utilisatrices plus avancés) permet de gérer la mise en page des résultats d’une requête à l’aide de templates gérés par le moteur PHP Smarty7, la page ainsi générée peut ensuite être mise en ligne
-
Export permet l’export de l’ensemble des résultats de la requête en cours sous différents formats pouvant être réutilisés par d’autres logiciels (CSV, GEPHI, XML, JSON, GEOJSON, KML, IIIF)
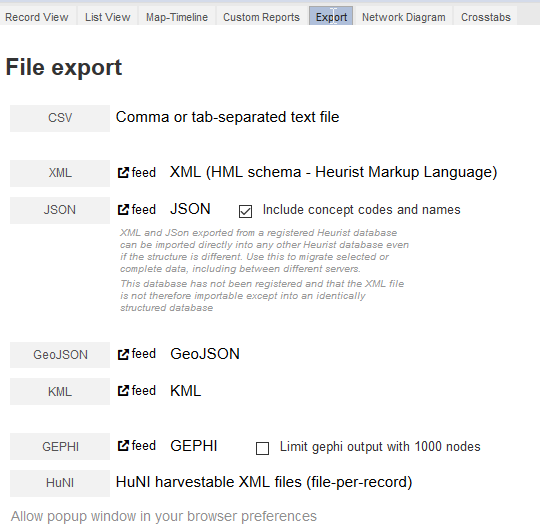
Fig. 40. Formats d’export.
-
Network diagram affiche un diagramme montrant les liens entre les enregistrements
-
Crosstabs permet d’effectuer des requêtes croisées sur les données
Modifier les données
Cliquez sur l’onglet Map-Timeline pour visualiser l’ensemble des sites géolocalisés sous forme de carte. Ce faisant, vous pouvez observer que certaines données semblent manifestement erronées. En effet, bien que tous les sites de notre jeu de données se situent en France, la visualisation en révèle un au Mali et deux autres près des côtes africaines. Le rôle de la visualisation des données spatiales à des fins correctives est ici évident. Voyons maintenant comment corriger ce type d’erreur. En cliquant sur le drapeau d’un site sur la carte, vous pouvez afficher, à l’aide d’une fenêtre secondaire (popup), l’ensemble des informations concernant cette enregistrement. Ici, cliquez sur le site situé au Mali. Le nom du site apparaît dans une nouvelle fenêtre et l’enregistrement correspondant est automatiquement sélectionné. Ainsi, vous pouvez voir que le site dont il est question est celui de Boulazac situé en Dordogne. Directement, depuis cette fenêtre, passez en mode édition, en cliquant sur l’icône du crayon, pour corriger les informations liées à cet enregistrement.
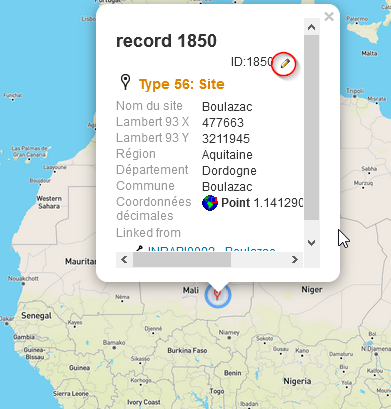
Fig. 41. Édition des coordonnées du site de Boulazac.
Pour modifier ou entrer une donnée GPS, Heurist propose deux solutions :
- Rechercher dans la base de données d’OpenStreetMap un nom de lieu et lui attribuer un marqueur de point permettant de définir ses coordonnées
- Insérer les coordonnées, qui auront été récupérées par le moyen de votre choix, directement
Option 1
- Cliquez sur le champ de saisie de Coordonnées GPS
- Dans la fenêtre qui s’ouvre, effectuez une recherche sur Boulazac dans la base d’OpenStreetMap (cf. Fig. 42)
- Le site est trouvé sur OpenStreetMap, il faut y adjoindre un marqueur pour enregistrer les coordonnées du point dans Heurist
- Cliquez sur le marqueur et déplacez-le jusque sur le pointeur du site trouvé via le moteur de recherche, puis sauvegardez (cf. Fig. 43)
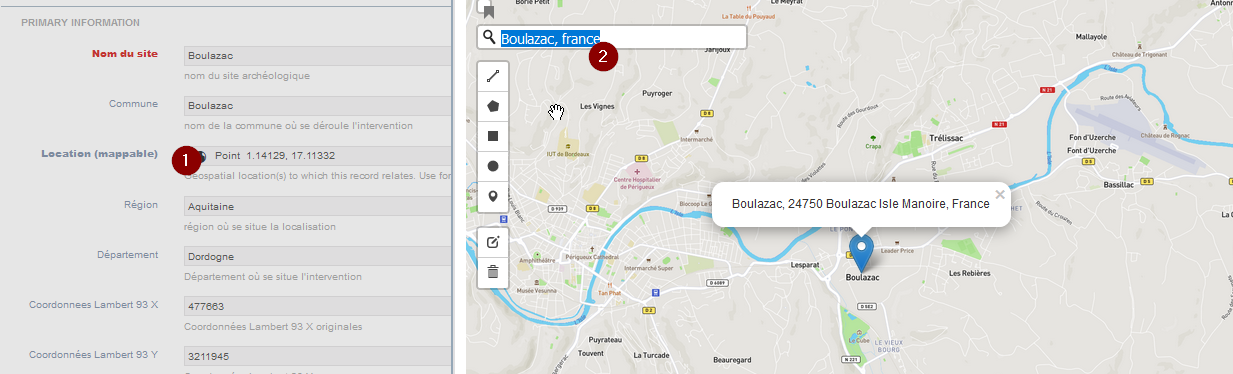
Fig. 42. Recherche des coordonnées GPS de Boulazac.
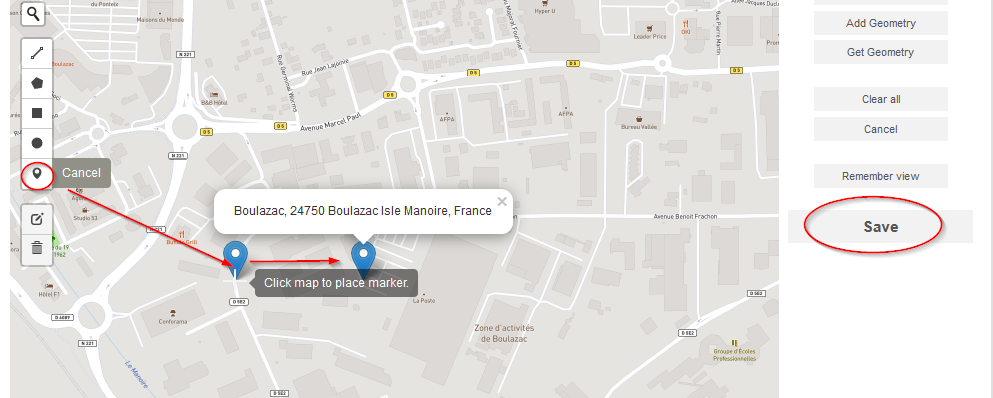
Fig. 43. Validation des coordonnées GPS à l’aide du marqueur.
Option 2
- Cliquez sur le champ de saisie de Coordonnées GPS
- Puis sur Add Geometry dans la colonne de droite de la carte
- Insérez les coordonnées dans le format indiqué, par exemple ici pour un simple point la syntaxe est 0.7679869062166365 45.178199165946225, puis sauvegardez les modifications
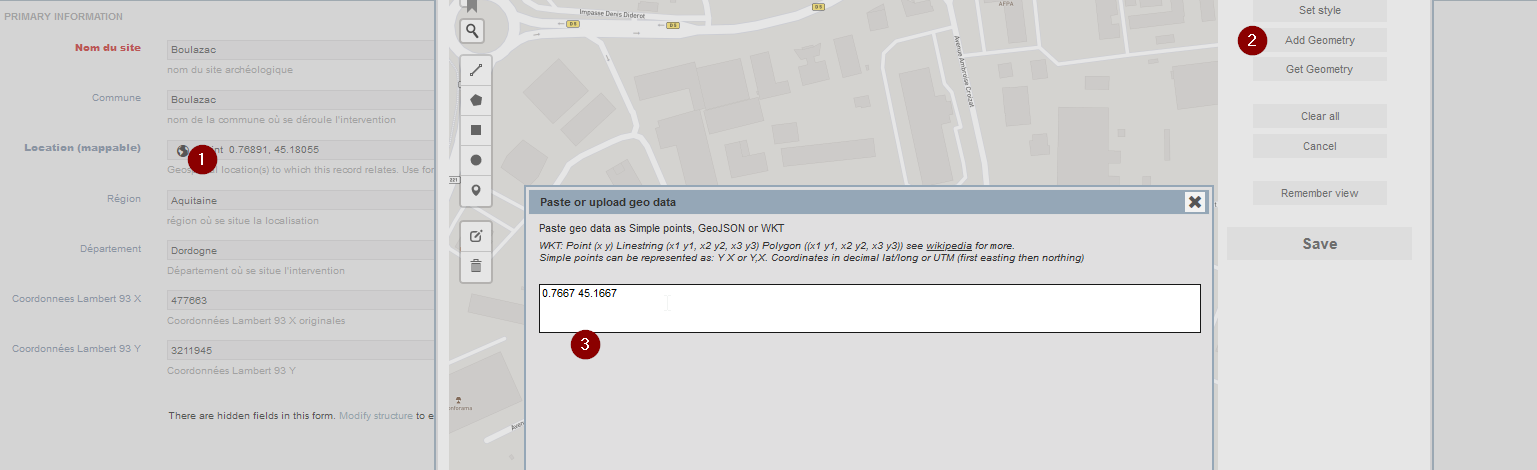
Fig. 44. Renseigner les coordonnées manuellement.
Afin de vérifier que les modifications des coordonnées GPS ont bien été prises en compte, nous allons utiliser l’assistant de filtre. Dans notre cas, nous utilisons le nom de la commune :
- Ajoutez un filtre
- Dans la fenêtre de paramètres qui s’ouvre, saisissez les informations nécessaires pour trouver notre enregistrement
- Filtrez
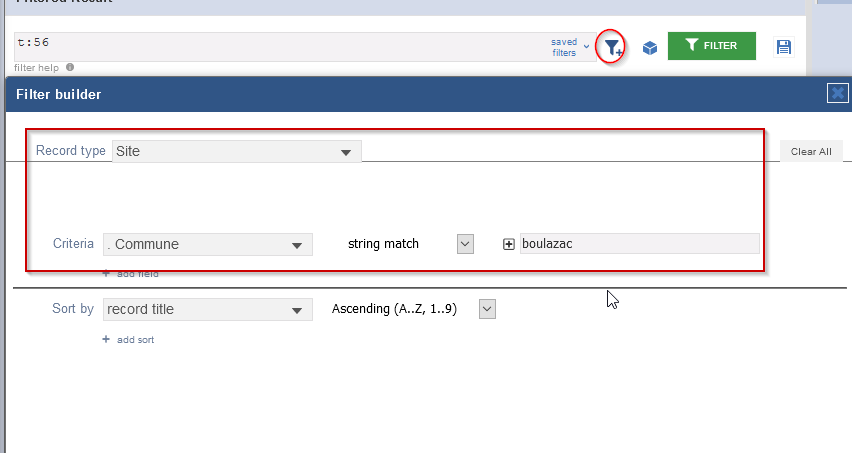
Fig. 45. Rechercher un enregistrement en filtrant les données.
Un seul élément est trouvé et vous pouvez observer que la modification du lieu a bien été effectuée.
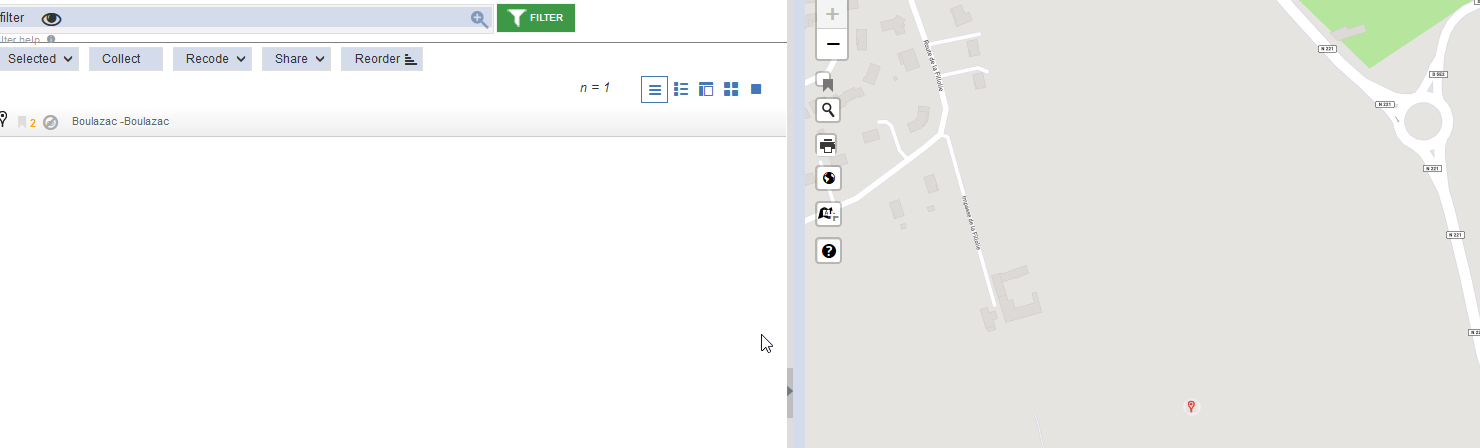
Fig. 46. Vérification de l’enregistrement de la modification cartographique.
Modifier l’étiquette des enregistrements
Nous avons trouvé Boulazac, mais son étiquette (title mask) dans la liste des enregistrements est peu intelligible. Nous pouvons l’éditer depuis n’importe quel enregistrement. Dans la fenêtre d’édition d’un site, cliquez sur Edit title mask.
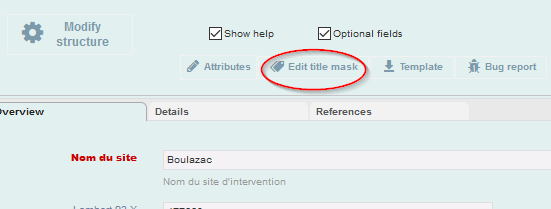
Fig. 47. Modification de l’étiquette d’un type d’enregistrement.
- Sélectionnez le ou les champs que vous souhaitez afficher dans la colonne de gauche
- Cliquez sur Insert field et agencez-les comme vous le souhaitez dans le champ texte
- Sélectionnez des enregistrements et testez l’étiquette ainsi générée
- Sauvegardez les modifications
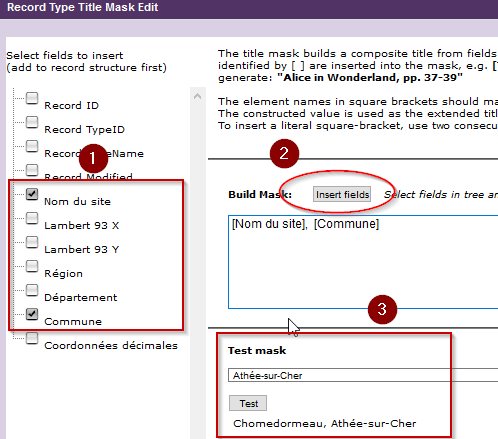
Fig. 48. Édition de l’étiquette.
Rafraîchissez de nouveau la page (CTRL+R ou F5) et visualisez les modifications apportées.
Vous savez donc maintenant comment consulter vos données, les modifier et visualiser à la volée les corrections ou ajouts effectués.
Utilisation des filtres
Toujours en mode Explore, si le dernier filtre inséré est encore actif, utilisez le filtre par entité dans la colonne de gauche pour n’afficher que les entités de type Intervention.
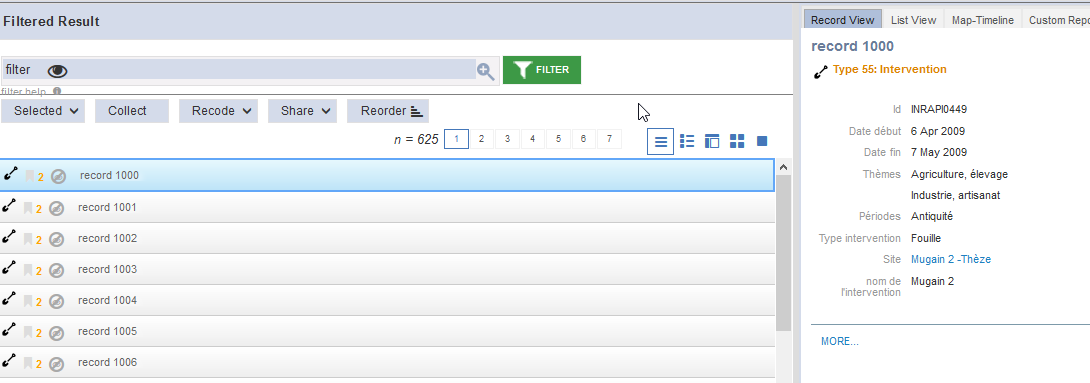
Fig. 49. Lister les interventions.
Comme avec les données de localisation, nous pouvons visualiser les informations de chaque intervention dans la fenêtre de visualisation via l’onglet Record view. Nous observons que les valeurs des champs multivalués comme Thèmes et Périodes sont correctement séparées, le nom du site apparaît bien comme un élément lié et, en cliquant dessus, une fenêtre secondaire affiche les données le concernant.
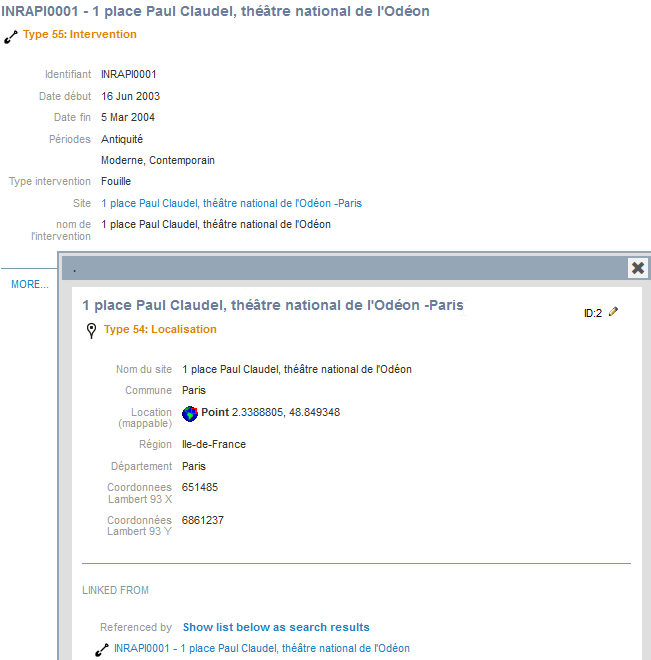
Fig. 50. Visualiser le détail d’une intervention.
En revanche, si vous tentez de visualiser les informations géographiques liées à une intervention via le mode Map-Timeline, cela ne fonctionne pas. Seules les informations temporelles de chaque intervention apparaissent. En effet, actuellement la requête de filtre demande uniquement d’afficher les interventions et de récupérer les données qui y sont directement attachées. En revanche, il n’a pas encore été demandé à Heurist de récupérer le détail des informations géographiques liées à chaque intervention. Pour enrichir notre requête, nous allons créer un filtre spécifique :
- Cliquez sur Save filter
- Renseignez le nom et le type d’enregistrement filtré par défaut (cf. Fig. 51)
- Éditez la règle qui permet de remonter les informations de localisation via la relation de Record pointer entre Intervention et Site, puis sauvegardez la règle et le filtre.
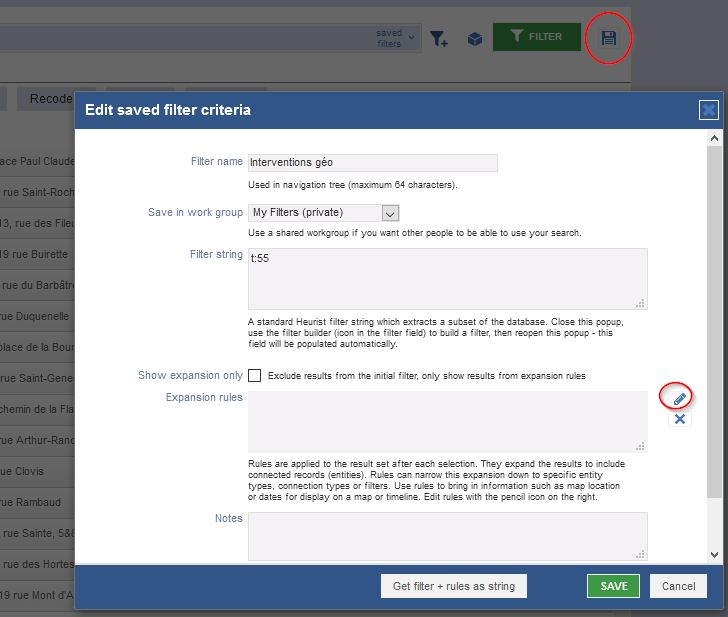
Fig. 51. Création d’un filtre avancé.
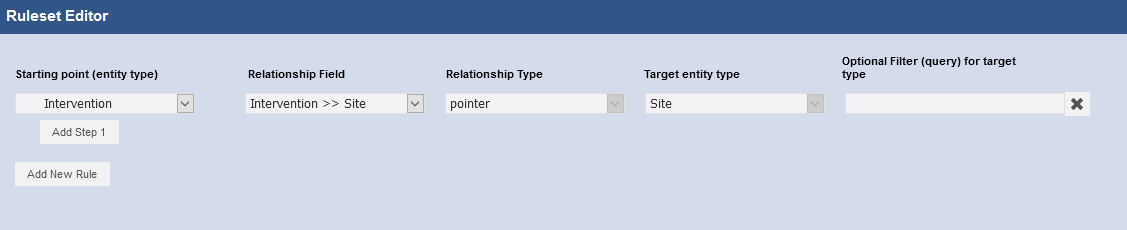
Fig. 52. Afficher les informations du record pointer Site.
Lorsque vous sélectionnez le filtre que vous venez de créer dans la rubrique Saved filters > My filters, vous pouvez maintenant visualiser directement les données spatiales attachées aux interventions.
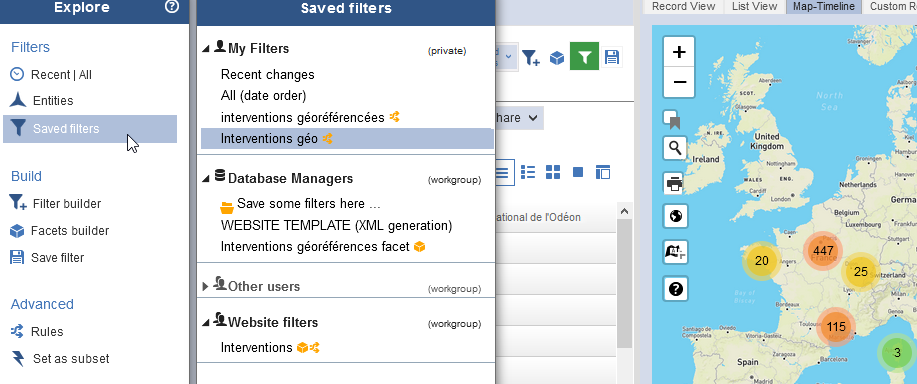
Fig. 53. Visualisation des informations spatiales.
Mettre en ligne les données gérées dans Heurist
Les opérations de modélisation, de visualisation et de modification offrent les outils pour gérer ses données de recherche. Elles œuvrent également à préparer le partage des données dans le cadre de travaux collaboratifs ou encore à les publier auprès d’un public plus large.
Heurist propose plusieurs fonctionnalités de mise en ligne :
- L’intégration d’un filtre de visualisation à facettes dans une page web hébergée sur un autre site comme Wordpress, Drupal, etc. (option qui est présentée dans cette leçon)
- La création d’une page web directement dans Heurist
- La génération d’un site web complet avec gestion du contenu des pages et personnalisation de l’affichage
Ces solutions s’appuient sur la création préalable d’un filtre, que nous venons de découvrir, ou d’une recherche à facettes.
Création d’un filtre de recherche à facettes
Un filtre de recherche à facettes est une interface permettant d’afficher les résultats d’une première recherche ou requête, et de les filtrer, en temps réel, à l’aide de filtres qui peuvent prendre la forme de champs textuels, de listes de sélection ou encore de cases à cocher.
- Sélectionnez l’éditeur de filtre à facettes dans les fonctionnalités du mode Explore
- Dans la fenêtre de paramètres du filtre, remplissez les champs pour indiquer que le filtre porte sur l’entité Intervention et que l’affichage des champs doit se faire sous forme de ligne (cf. Fig. 54)
- Comme pour le filtre de recherche, éditez la règle qui permet de remonter aux informations de localisation via la relation de record pointer entre Intervention et Site, puis sauvegardez la règle et validez
- Sélectionnez les champs sur lesquels vous souhaitez pouvoir effectuer des requêtes. Nous pouvons ici sélectionner les attributs de l’entité Intervention, mais également ceux de l’entité Site, du fait des données liées (cf. Fig. 55).
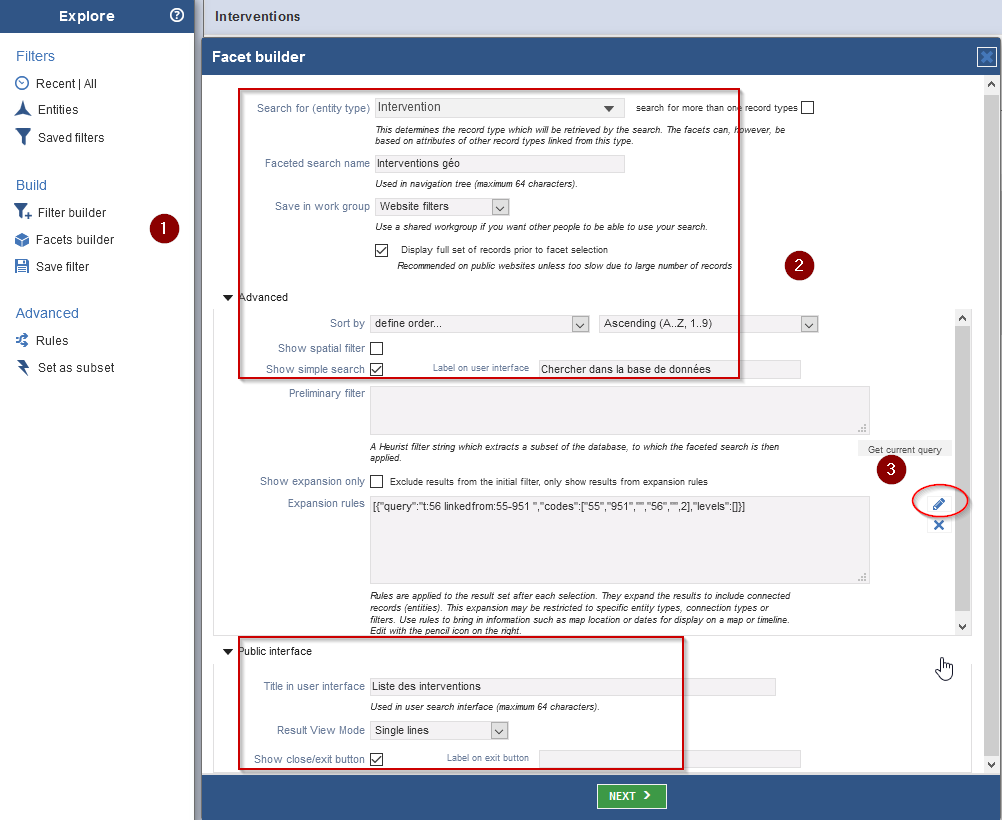
Fig. 54. Création d’un filtre de recherche à facettes.
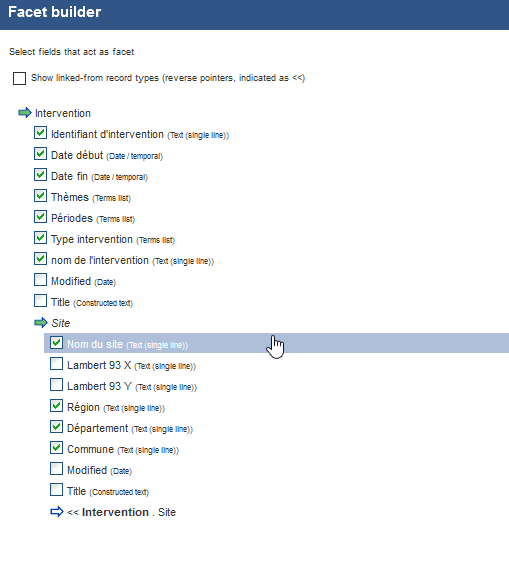
Fig. 55. Construction du filtre de recherche à facettes.
Une fois les critères de filtre validés, une nouvelle fenêtre permet de personnaliser la manière de présenter les champs de recherche à facettes. Plusieurs possibilités sont offertes selon l’utilisation souhaitée, et ce, pour chaque champ/critère retenu :
- List présente une liste de l’ensemble des valeurs possibles d’un champ avec leur nombre d’occurrences
- Wrapped présente l’ensemble des valeurs d’un champ sous une forme plus concise
- Search permet la recherche par simple saisie textuelle
- Slider permet la navigation temporelle à l’aide de curseurs
- Dropdown propose une liste sous forme de liste déroulante
Par défaut, tous les champs textuels proposent une recherche par saisie textuelle. Lorsque le nombre de termes le permet, il est possible de proposer une liste ou une présentation plus concise. Modifiez les étiquettes pour les champs liés aux sites, conservez l’affichage par défaut pour chaque champ et validez.
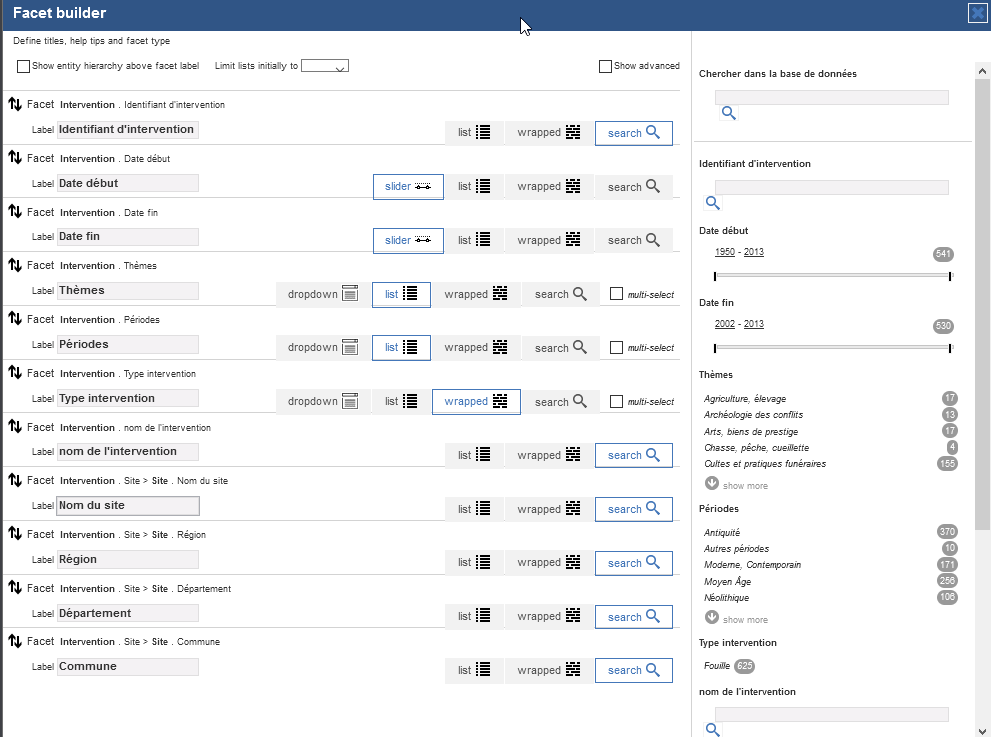
Fig. 56. Modes d’affichage des filtres de champs.
Pour visualiser le résultat de notre filtre :
- Rendez-vous sur les filtres sauvegardés (saved filters) dans Explore ou bien dans Saved filters au bout de la barre de filtre
- Puis sélectionnez le filtre à facettes que nous venons de créer
Fig. 57. Sélection du filtre à facettes précédemment créé.
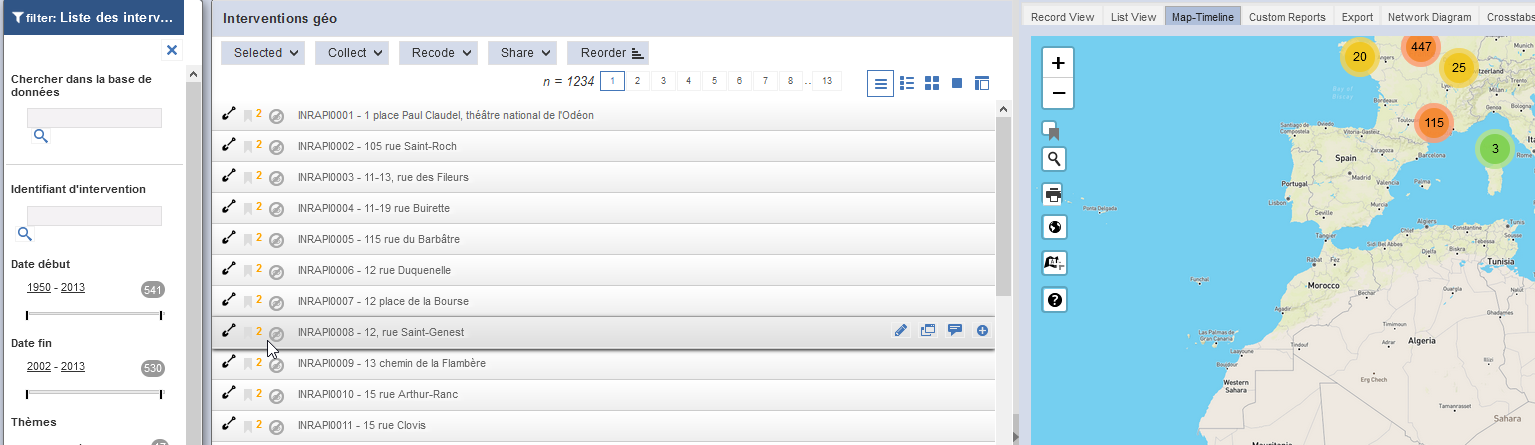
Fig. 58. Visualisation de la recherche à facettes.
Cette recherche à facettes peut être intégrée sur une page dans un autre site web. Cela se fait par des éléments HTML appelés iframe. Pour intégrer notre page web dans une page d’un autre site, tel qu’un article de blog Wordpress, il suffit de copier le code qui est affiché en cliquant sur Embed dans la liste des options du filtre de recherche à facettes, et de le coller dans l’éditeur de texte du site web.
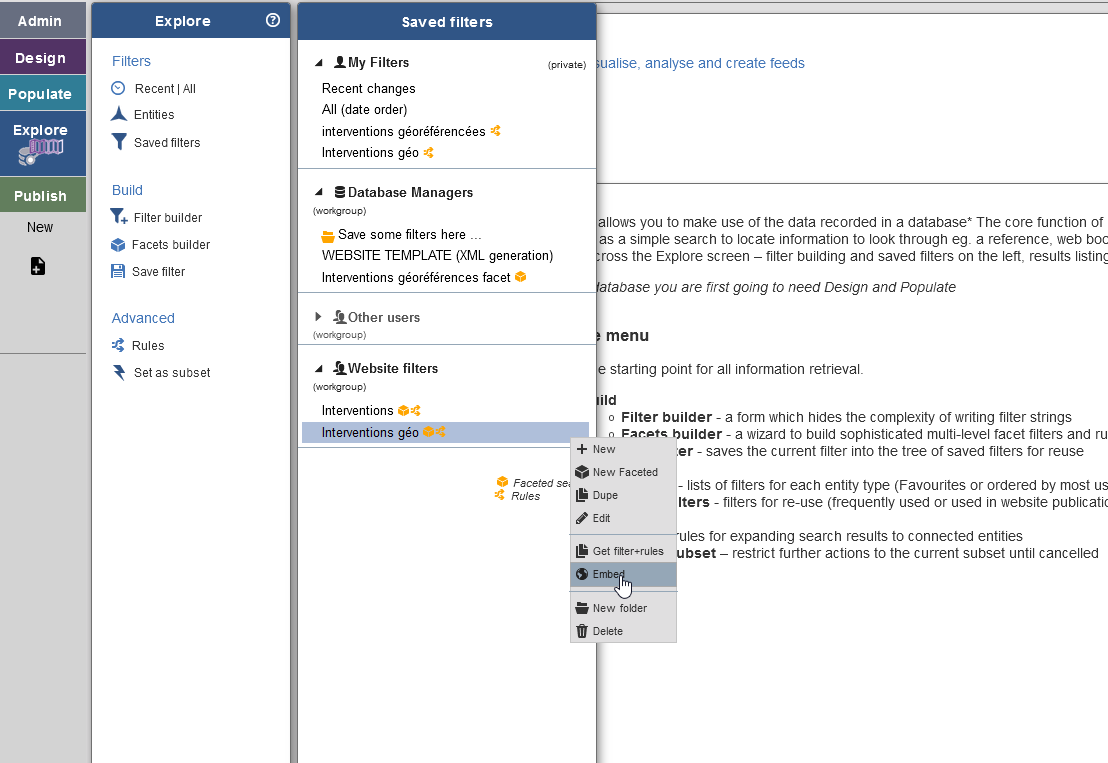
Fig. 59. Intégration du filtre à facettes dans une page web.
Gérer les droits d’accès à vos ressources Heurist
Par défaut, les données d’un enregistrement ne peuvent être modifiées que par le ou la propriétaire de la base et ne sont visibles que par les personnes connectées à Heurist.
Pour modifier ces droits et rendre vos données accessibles publiquement, repassez en mode Explore et, dans la barre d’options figurant au-dessus de la liste des enregistrements, sélectionnez Ownership/Visibility dans le menu de gestion de partage.
Définissez le périmètre de votre choix (ici, nous sélectionnons l’ensemble des enregistrements présents), les utilisateurs et utilisatrices ou les groupes ayant l’autorisation de modifier les données, et enfin, les personnes pouvant visualiser les données. Validez pour appliquer les modifications.
Vous pouvez voir que les modifications ont bien été pris en compte en observant le changement de couleur du chiffre à gauche de chaque enregistrement.
En déplaçant le curseur de la souris sur le chiffre ou sur le symbole barré juste à côté, vous obtenez des informations sur la visibilité et les droits d’édition de chaque enregistrement.
Conclusion
Heurist est un outil en constante évolution depuis 2005, fonctionnellement très riche à destination de la communauté de recherche. Si son accès n’est pas réservé aux spécialistes en informatique, cette richesse fonctionnelle peut rendre son utilisation délicate pour des novices. Nous espérons que ce tutoriel permettra à un plus grand nombre d’utiliser ce logiciel pour répondre à leurs besoins.
L’utilisation avancée de certaines fonctionnalités peut toutefois nécessiter de l’aide extérieure. La rubrique Help est dédiée à cet usage.
Le site web heuristnetwork dispose également d’une page Contact et d’une rubrique Learn permettant de compléter le contenu du présent cours.
Ressources utiles
Sur l’utilisation d’Heurist
- Heurist, « Help System », consulté le 1er avril 2022, https://heuristplus.sydney.edu.au/heurist/?db=Heurist_Help_System&website&id=39&pageid=622. Cette ressource (en anglais) est régulièrement augmentée et à consulter sans modération.
- Ian Johnson, « Concevoir et collaborer sur des bases de données sans réinventer la roue », 22 janvier 2021, Université de Haute-Alsace (plateforme vidéos), consulté le 1er avril 2022 https://e-diffusion.uha.fr/video/3668-j1-ian-johnson-conference-inaugurale/.
- Universalistes par RENATER, « Heurist Utilisateurs », liste de diffusion, page consultée le 1er avril 2022, https://groupes.renater.fr/sympa/info/heurist-utilisateurs.
- Un autre tutoriel sur Heurist rédigé par Régis Witz, ingénieur d’études à la Maison Interuniverstaire des Sciences de l’Homme – Alsace (MISHA) : Régis Witz, « Créer sa base de données avec Heurist », (2021), https://doi.org/10.5281/zenodo.6243955.
Sur la gestion des données de la recherche
- James Baker, « Préserver ses données de recherche », traduction par Anne-Sophie Bessero-Lagarde, Programming Historian en français 2 (2020) https://doi.org/10.46430/phfr0009.
- Urfist Méditerranée, « Format Ouvert ou Fermé », DoRANum, 21 février 2017 (mis á jour le 9 octobre 2020), consulté le 1er avril 2022, https://doranum.fr/stockage-archivage/quiz-format-ouvert-ou-ferme/.
- Centre Informatique National de l’Enseignement Supérieur (CINES), « FACILE - Service de validation de formats », consulté le 1er avril 2022, https://facile.cines.fr/.
Notes
-
Que je remercie tout particulièrement pour la relecture, les conseils et les corrections apportés à la présente leçon. ↩
-
À ce sujet, lire l’article : Paris Time Machine, « Heurist, une base de données généraliste pour les sciences humaines et sociales », sans date, consulté le 1 avril 2022, https://paris-timemachine.huma-num.fr/heurist-une-base-de-donnees-generique-pour-les-sciences-humaines-et-sociales/. ↩
-
Voir les principes des données FAIR : « Fair data », Wikipédia, mis á jour le 19 septembre 2021, consulté le 1er avril 2022, https://fr.wikipedia.org/wiki/Fair_data. ↩
-
Pour en savoir plus : World Wide Web Consortium (W3C), « 5 Star Linked Data », mis á jour le 15 mars 2013, consulté le 1er avril 2022, https://www.w3.org/2011/gld/wiki/5_Star_Linked_Data. ↩
-
Pour aller plus loin avec QGIS, voir la leçon qui lui est dédiée sur Programming Historian en anglais : Justin Colson, « Geocoding Historical Data using QGIS », Programming Historian 6 (2017), https://doi.org/10.46430/phen0066. ↩
-
Pour en savoir plus : Idris Neumann, « Initiation à la conception de bases de données relationnelles avec MERISE », 28 février 2012 (mis á jour le 15 juin 2019), consulté le 1er avril 2022, https://ineumann.developpez.com/tutoriels/merise/initiation-merise/. ↩
-
Pour aller plus loin, voir : Éric Pommereau, « Initiation aux templates en PHP avec Smarty », 2008, consulté le 1er avril 2022, https://eric-pommereau.developpez.com/tutoriels/initiation-smarty/?page=introduction. ↩