
Contenus
- Prérequis
- Objectifs de la leçon
- Introduction
- Un exemple du fonctionnement de dplyr
- L’opérateur Pipe
- Il nous faut un nouveau jeu de données
- Qu’est-ce que dplyr ?
- Et si nous compilions ces fonctions ?
- Conclusion
Prérequis
Cette leçon nécessite quelques prérequis sur votre compréhension de R. Si vous n’avez pas été au bout de la leçon sur les bases de R avec des données tabulées, je vous suggère de le faire d’abord. Avoir une expérience dans un autre langage de programmation peut aussi vous aider. Si vous souhaitez savoir par où commencer, je vous recommande de parcourir les excellentes leçons de Programming Historian sur Python.
Objectifs de la leçon
À la fin de cette leçon, vous serez en mesure de :
- Comprendre comment organiser vos données pour qu’elles soient « propres », et pourquoi c’est important.
- Comprendre le paquet (« package » en anglais) dplyr et l’utiliser pour manipuler et administrer les données.
- Se familiariser avec l’opérateur pipe dans R et observer comment il peut vous aider à créer du code plus lisible.
- Apprendre à travailler sur des exemples de base de manipulation de données pour acquérir les fondements de l’analyse exploratoire des données.
Introduction
Les données que vous rencontrerez « dans la nature » sont rarement présentées dans un format qui rend possible une analyse. Vous aurez donc à les traiter avant d’explorer les questions qui vous intéressent. Ce traitement peut prendre plus de temps que l’analyse elle-même ! Dans cette leçon, nous apprendrons quelques techniques de base pour manipuler, gérer et administrer nos données dans R. Nous nous fonderons notamment sur la philosophie des « données propres » (tidy data) telle que l’a présentée Hadley Wickham.
Selon Wickham, la donnée est « propre » quand elle répond à ces trois critères :
- Chaque observation dans une ligne.
- Chaque variable dans une colonne.
- Chaque valeur a sa propre cellule.
Remplir ces critères nous permet de juger si la donnée est organisée ou pas. Ces critères nous fournissent également un schéma standard et un ensemble d’outils pour gérer les formes les plus communes de désordre dans les données :
- Les entêtes de colonnes sont des valeurs et pas des noms de variables.
- Plusieurs variables sont stockées dans une même colonne.
- Des variables sont présentes à la fois dans les colonnes et dans les lignes.
- Plusieurs unités d’observation sont présentes dans une même table.
- Une même unité d’observation est présente dans plusieurs tables.
Un avantage peut-être encore plus important est de garder nos données dans ce format propre, qui nous permet d’utiliser une galerie de paquets dans le « tidyverse », spécifiquement conçus pour fonctionner avec des données bien structurées. En nous assurant que nos données en entrée et en sortie sont bien structurées, nous n’aurons qu’un nombre limité d’outils à utiliser pour répondre à un grand nombre de questions. De plus, nous pourrons combiner, manipuler et séparer des jeux de données comme bon nous semble.
Dans cette leçon, nous nous intéresserons particulièrement au paquet dplyr du tidyverse. Mais cela vaut la peine de mentionner brièvement quelques autres paquets que nous utiliserons :
-
magittr : donne accès à l’opérateur pipe et rend le code plus facile à lire.
-
ggplot2 : utilise la « grammaire des graphiques » permettant de réaliser des visualisations simples de vos données.
- readr : met à disposition un import plus rapide et intuitif de données tabulées, comme des fichiers CSV.
- tibble : donne accès à une nouvelle conceptualisation des tableaux de données qui seront plus simples à traiter et à imprimer.
Si vous ne l’avez pas déjà fait, vous devez installer et charger le tidyverse avant de commencer. Assurez-vous en outre que vous disposez de la dernière version de R et de la dernière version de Rstudio installées sur votre système d’exploitation (Windows, Mac OS, Linux).
Copiez le code ci-dessous dans la zone d’édition de fichiers de Rstudio. Pour l’exécuter, il faut mettre ces lignes en surbrillance et appuyer sur Ctrl+enter (ou Cmd+enter sur Mac OS) :
# Installer les bibliothèques tidyverse et charger ces bibliothèques
# Ne vous inquiétez pas si cela prend un peu de temps
install.packages("tidyverse", repos = "http://cran.us.r-project.org")
library(tidyverse)
Un exemple du fonctionnement de dplyr
Utilisons un exemple pour voir comment dplyr peut aider les historien·nes, ainsi que les autres chercheur·euses en sciences humaines et sociales : importez les données de recensement décennal des États-Unis entre 1790 et 2010. Téléchargez les données depuis le dépot de Programming Historian et placez le fichier téléchargé dans le dossier que vous utiliserez pour traiter les exemples présentés dans cette leçon.
Comme les données sont stockées dans un fichier CSV, utilisez la commande read_CSV() incluse dans le paquet readr du tidyverse.
La fonction read_csv() doit comporter le chemin d’un fichier qu’on veut importer en tant que variable, par conséquent il faut s’assurer que ce chemin soit correctement renseigné :
# Importer le fichier CSV et le sauvegarder dans la variable us_state_populations_import
# Assurez-vous que le chemin vers le fichier est bien défini
library(tidyverse)
us_state_populations_import<-read_csv("introductory_state_example.csv")
Après avoir importé les données, vous remarquerez qu’elles sont disposées en trois colonnes : une pour la population, une pour l’année et une pour l’État. Ces données sont d’emblée dans un format propre, ce qui nous permet de nous livrer à une multitude d’explorations.
Pour cet exemple, nous voulons visualiser la croissance de la population en Californie et dans l’État de New York afin d’avoir une meilleure compréhension des migrations vers l’Ouest. Nous allons utiliser dplyr pour filtrer nos données, de telle sorte qu’elles ne contiennent que les informations relatives aux États qui nous intéressent et nous aurons recours à ggplot2 pour visualiser cette information. Cet exercice a pour but de nous donner une idée de ce que dplyr peut faire – ne vous en faites pas si vous ne comprenez pas le code utilisé à ce stade :
# Filtrer le jeu pour ne traiter que les données relatives à la Californie et à l'État de New York
california_and_new_york_state_populations<-us_state_populations_import %>%
filter(state %in% c("California", "New York"))
# Éditer le graphique des courbes de population de la Californie et de l'État de New York
ggplot(data=california_and_new_york_state_populations, aes(x=year, y=population, color=state)) +
geom_line() +
geom_point()
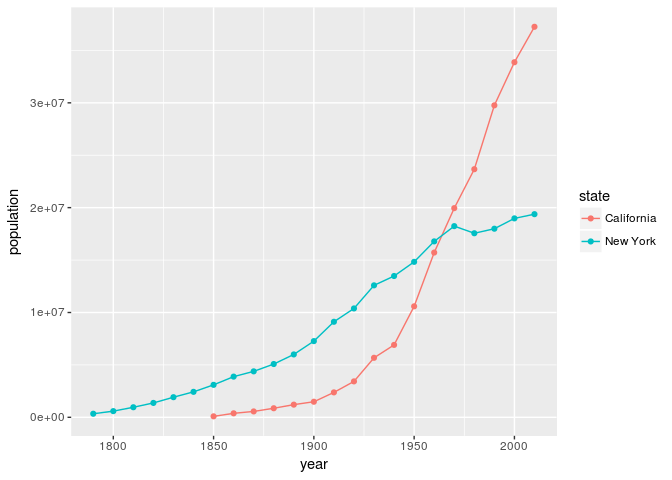
Figure 1. Vue graphique de la population de la Californie et de l’État de New York.
Comme nous pouvons le voir, la population de la Californie a augmenté de façon considérable si nous la comparons à celle de l’État de New York. Cet exemple en particulier peut sembler évident au regard de l’histoire des migrations aux États-Unis, mais le code en lui-même nous fournit une base pour poser de nombreuses questions similaires. Ainsi, avec une modification rapide du code, on peut créer un graphique équivalent pour deux autres États comme le Mississippi et la Virginie.
# Filtrer le jeu pour ne traiter que les données relatives au Mississippi et à la Virginie
mississippi_and_virginia_state_populations<-us_state_populations_import %>%
filter(state %in% c("Mississippi", "Virginia"))
# Éditer le graphique des courbes de population du Mississippi et de la Virginie
ggplot(data=mississippi_and_virginia_state_populations, aes(x=year, y=population, color=state)) +
geom_line() +
geom_point()
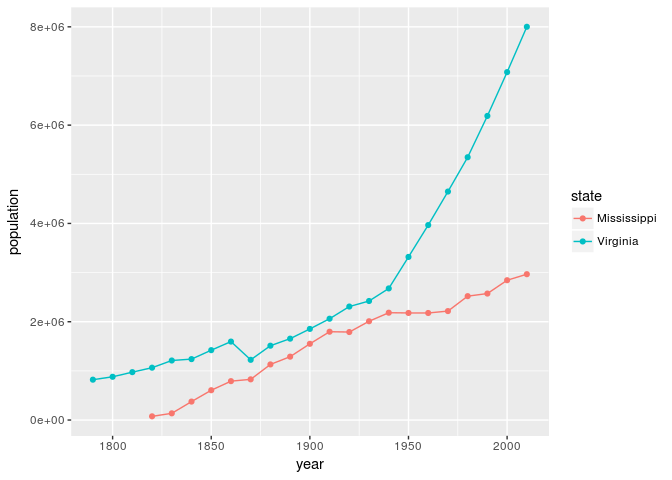
Figure 2. Vue graphique de la population du Mississippi et de la Virginie.
La possibilité de faire des changements rapides dans le code et de visualiser nos données est un élément fondamental de l’analyse exploratoire de données (AED). Plutôt que d’essayer de « prouver » une hypothèse, l’analyse exploratoire de données nous aide à mieux comprendre nos données et à les interroger. L’AED fournit aux historien·nes et aux spécialistes des sciences humaines et sociales un moyen simple de déterminer quand approfondir un sujet ou quand prendre du recul, et c’est un domaine dans lequel R excelle.
L’opérateur Pipe
Avant d’aborder dplyr, nous devons examiner ce qu’est l’opérateur pipe (%>%) dans R, car nous l’utiliserons souvent dans nos exemples. Comme mentionné plus haut, l’opérateur pipe fait partie du paquet magrittr mis au point par Stefan Milton Bache et Hadley Wickham et est inclus dans le tidyverse. Son nom rend hommage au peintre surréaliste René Magritte, connu pour son œuvre « La trahison des images » où l’on peut voir une pipe accompagnée de la légende « ceci n’est pas une pipe ».
L’opérateur pipe nous permet déclarer ce qui est à gauche du pipe comme le premier élément de la fonction qui est indiquée à droite. Cela peut sembler étrange au premier abord, mais une fois appris, vous trouverez qu’il rend votre code plus lisible en évitant l’imbrication des opérations. Ne vous inquiétez pas si tout cela vous semble encore confus pour le moment ; cela deviendra plus clair progressivement avec des exemples.
Supposons que nous souhaitions calculer la racine carrée de la population de chaque État, puis en calculer la somme et enfin la moyenne. À l’évidence, cette mesure ne nous sert à rien, mais elle permet de montrer à quel point un code réalisé avec R peut rapidement devenir difficile à lire. Normalement, nous pourrions imbriquer ces opérations :
mean(sum(sqrt(us_state_populations_import$population)))
## [1] 1256925
Comme on peut le voir, l’utilisation de commandes imbriquées rend difficile de se rappeler combien de parenthèses doivent être fournies et cela donne un code assez pataud. Pour minimiser cela, certains vont créer des vecteurs temporaires entre chaque appel de commandes.
# Obtenir la racine carrée de la population de chaque État
sqrt_state_populations_vector<-sqrt(us_state_populations_import$population)
# Obtenir la somme de toutes les racines carrées des variables temporaires
sum_sqrt_state_populations_vector<-sum(sqrt_state_populations_vector)
# Obtenir la moyenne de la variable temporaire
mean_sum_sqrt_state_populations_vector<-mean(sum_sqrt_state_populations_vector)
# Afficher la moyenne
mean_sum_sqrt_state_populations_vector
## [1] 1256925
Vous obtenez certes la même réponse, mais de façon beaucoup plus lisible. En revanche, cela peut rapidement encombrer votre espace de travail si vous oubliez de supprimer les vecteurs temporaires. L’opérateur pipe fait tout cela pour vous. Voici le même code, mais avec l’opérateur pipe :
us_state_populations_import$population%>%sqrt%>%sum%>%mean
## [1] 1256925
C’est bien plus simple à lire, et vous pourriez même rendre cette commande encore plus claire en l’écrivant sur plusieurs lignes :
# Assurez-vous que l'opérateur soit à la fin de la ligne
us_state_populations_import$population%>%
sqrt%>%
sum%>%
mean
## [1] 1256925
Notez que les vecteurs ou les tableaux que crée l’opérateur pipe sont supprimés lorsque le processus est achevé. Si vous souhaitez les conserver, vous devrez en faire de nouvelles variables :
permanent_sqrt_and_sum_state_populations_vector <- us_state_populations_import$population%>%sqrt%>%sum%>%mean
permanent_sqrt_and_sum_state_populations_vector
## [1] 1256925
Il nous faut un nouveau jeu de données
Maintenant que nous comprenons comment fonctionne le pipe, nous sommes en mesure d’examiner et manipuler des données. Heureusement, aujourd’hui, de plus en plus de jeux de données sont mis à la disposition des historien·nes et des spécialistes des sciences humaines et sociales. Nous allons partir du paquet de données historiques créé par Lincoln Mullen
Allons-y, installons et chargeons ce paquet :
# Installer le paquet historydata
install.packages("historydata", repos = "http://cran.us.r-project.org")
# Charger le paquet historydata
library(historydata)
Ce paquet contient un échantillon de données historiques sur les États-Unis. Les données de recensement que nous avons utilisées précédemment font partie de cet échantillon. Jusqu’à la fin de cette leçon, nous allons surtout travailler avec un jeu de données en particulier : early_colleges, qui contient des données sur les universités (« colleges » dans le monde anglophone) fondées avant 1848. Commençons par charger les données et les observer :
# Vérifiez avant d'exécuter ce code que le paquet historydata a bien été installé et chargé
data(early_colleges)
early_colleges
## # A tibble: 65 × 6
## college original_name city state established sponsorship
## <chr> <chr> <chr> <chr> <int> <chr>
## 1 Harvard <NA> Cambridge MA 1636 Congregational; after 1805 Unitarian
## 2 William and Mary <NA> Williamsburg VA 1693 Anglican
## 3 Yale <NA> New Haven CT 1701 Congregational
## 4 Pennsylvania, Univ. of <NA> Philadelphia PA 1740 Nondenominational
## 5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian
## 6 Columbia King's College New York NY 1754 Anglican
## 7 Brown <NA> Providence RI 1765 Baptist
## 8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed
## 9 Dartmouth <NA> Hanover NH 1769 Congregational
## 10 Charleston, Coll. Of <NA> Charleston SC 1770 Anglican
## # ... with 55 more rows
Comme vous pouvez le remarquer, ce jeu de données contient le nom actuel de chaque université, son nom à l’origine, la ville et l’État dans lequel il a été fondé, la date de sa fondation et l’organisation qui le parraine. Comme on l’a vu plus haut, avant de commencer à travailler sur ce jeu de données, il est important de penser à la façon dont on va organiser ces données. Voyons si certaines de nos données ne se trouveraient pas dans un format « impropre ». Voyez-vous des cellules qui ne répondraient pas aux trois critères que remplissent les données « propres » ?
Si vous avez répondu le parrainage de Harvard, vous avez la bonne réponse. En plus de mentionner le premier parrainage de cette université, la cellule comporte l’information de son changement de parrainage en 1805. Habituellement, on veut conserver dans nos données autant d’information que possible, mais pour rester dans la perspective de cette leçon, nous allons modifier la colonne pour ne conserver que les parrainages lors de la fondation.
early_colleges[1,6] <- "Congregational"
early_colleges
## # A tibble: 65 × 6
## college original_name city state established sponsorship
## <chr> <chr> <chr> <chr> <int> <chr>
## 1 Harvard <NA> Cambridge MA 1636 Congregational
## 2 William and Mary <NA> Williamsburg VA 1693 Anglican
## 3 Yale <NA> New Haven CT 1701 Congregational
## 4 Pennsylvania, Univ. of <NA> Philadelphia PA 1740 Nondenominational
## 5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian
## 6 Columbia King's College New York NY 1754 Anglican
## 7 Brown <NA> Providence RI 1765 Baptist
## 8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed
## 9 Dartmouth <NA> Hanover NH 1769 Congregational
## 10 Charleston, Coll. Of <NA> Charleston SC 1770 Anglican
## # ... with 55 more rows
À présent que nos données se présentent dans un format propre, nous pouvons leur donner forme avec le paquet dplyr.
Qu’est-ce que dplyr ?
dplyr est un autre élément du tidyverse qui met à disposition des fonctions utiles pour manipuler et transformer des données. Parce que nous gardons nos données propres, nous n’avons besoin que d’un nombre réduit d’outils pour les explorer.
Comparé au langage R de base, utiliser dplyr est souvent plus rapide et vous garantit que si les données en entrée sont propres, les données transformées le seront aussi. Ce qui est peut-être encore plus important, dplyr facilite la lecture de votre code et utilise des « verbes » qui sont intuitifs la plupart du temps. Chaque fonction dans dplyr correspond à l’un de ces verbes, dont les plus importants sont : filtrer(filter), sélectionner(select), arranger(arrange), recoder(mutate) et résumer(summarise, avec le s de l’orthographe britannique). Parcourons-les un à un pour voir comment ils fonctionnent dans la pratique.
select
Si on regarde les données comprises dans early_colleges, on peut observer qu’il y a un grand nombre de « NA » dans la colonne des noms originaux. NA (Not Available) signifie qu’on n’a aucune donnée correspondante. On pourrait donc vouloir visualiser nos données en soustrayant cette colonne. La fonction select() de dplyr nous donne la possibilité de le faire. Nous prenons le tableau de données que nous voulons manipuler comme premier argument, suivi d’une liste qui indique quelles colonnes on souhaite conserver :
# Supprime la colonne des noms originaux en utiliser select()
# Notez que vous n'avez pas à préfixer le nom de la colonne par un $
# dplyr traite automatiquement la virgule comme un AND
select(early_colleges, college, city, state, established, sponsorship)
## # A tibble: 65 × 5
## college city state established sponsorship
## <chr> <chr> <chr> <int> <chr>
## 1 Harvard Cambridge MA 1636 Congregational
## 2 William and Mary Williamsburg VA 1693 Anglican
## 3 Yale New Haven CT 1701 Congregational
## 4 Pennsylvania, Univ. of Philadelphia PA 1740 Nondenominational
## 5 Princeton Princeton NJ 1746 Presbyterian
## 6 Columbia New York NY 1754 Anglican
## 7 Brown Providence RI 1765 Baptist
## 8 Rutgers New Brunswick NJ 1766 Dutch Reformed
## 9 Dartmouth Hanover NH 1769 Congregational
## 10 Charleston, Coll. Of Charleston SC 1770 Anglican
## # ℹ 55 more rows
Allons encore plus loin et voyons comment on peut écrire ceci en utilisant l’opérateur pipe (%>%) :
early_colleges%>%
select(college, city, state, established, sponsorship)
## # A tibble: 65 × 5
## college city state established sponsorship
## <chr> <chr> <chr> <int> <chr>
## 1 Harvard Cambridge MA 1636 Congregational
## 2 William and Mary Williamsburg VA 1693 Anglican
## 3 Yale New Haven CT 1701 Congregational
## 4 Pennsylvania, Univ. of Philadelphia PA 1740 Nondenominational
## 5 Princeton Princeton NJ 1746 Presbyterian
## 6 Columbia New York NY 1754 Anglican
## 7 Brown Providence RI 1765 Baptist
## 8 Rutgers New Brunswick NJ 1766 Dutch Reformed
## 9 Dartmouth Hanover NH 1769 Congregational
## 10 Charleston, Coll. Of Charleston SC 1770 Anglican
## # ℹ 55 more rows
Devoir référencer toutes les colonnes qu’on veut conserver juste pour se débarrasser d’une seule est un peu fastidieux. Nous pouvons à la place utiliser le symbole moins (-) pour signifier que nous voulons enlever une colonne.
early_colleges%>%
select(-original_name)
## # A tibble: 65 × 5
## college city state established sponsorship
## <chr> <chr> <chr> <int> <chr>
## 1 Harvard Cambridge MA 1636 Congregational
## 2 William and Mary Williamsburg VA 1693 Anglican
## 3 Yale New Haven CT 1701 Congregational
## 4 Pennsylvania, Univ. of Philadelphia PA 1740 Nondenominational
## 5 Princeton Princeton NJ 1746 Presbyterian
## 6 Columbia New York NY 1754 Anglican
## 7 Brown Providence RI 1765 Baptist
## 8 Rutgers New Brunswick NJ 1766 Dutch Reformed
## 9 Dartmouth Hanover NH 1769 Congregational
## 10 Charleston, Coll. Of Charleston SC 1770 Anglican
## # ℹ 55 more rows
filter
La fonction filter() réalise une opération similaire à la fonction select() à ceci près qu’au lieu de choisir une colonne, on peut utiliser filter() pour sélectionner les lignes qui remplissent une certaine condition. Par exemple, on peut visualiser toutes les universités qui ont existé avant la fin du 18e siècle.
early_colleges%>%
filter(established < 1800)
## # A tibble: 20 × 6
## college original_name city state established sponsorship
## <chr> <chr> <chr> <chr> <int> <chr>
## 1 Harvard <NA> Cambridge MA 1636 Congregational
## 2 William and Mary <NA> Williamsburg VA 1693 Anglican
## 3 Yale <NA> New Haven CT 1701 Congregational
## 4 Pennsylvania, Univ. of <NA> Philadelphia PA 1740 Nondenominational
## 5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian
## 6 Columbia King's College New York NY 1754 Anglican
## 7 Brown <NA> Providence RI 1765 Baptist
## 8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed
## 9 Dartmouth <NA> Hanover NH 1769 Congregational
## 10 Charleston, Coll. Of <NA> Charleston SC 1770 Anglican
## 11 Hampden-Sydney <NA> Hampden-Sydney VA 1775 Presbyterian
## 12 Transylvania <NA> Lexington KY 1780 Disciples of Christ
## 13 Georgia, Univ. of <NA> Athens GA 1785 Secular
## 14 Georgetown <NA> Washington DC 1789 Roman Catholic
## 15 North Carolina, Univ. of <NA> Chapel Hill NC 1789 Secular
## 16 Vermont, Univ. of <NA> Burlington VT 1791 Nondenominational
## 17 Williams <NA> Williamstown MA 1793 Congregational
## 18 Tennessee, Univ. of Blount College Knoxville TN 1794 Secular
## 19 Union College <NA> Schenectady NY 1795 Presbyterian with Congregational
## 20 Marietta <NA> Marietta OH 1797 Congregational
mutate
La commande mutate vous permet d’ajouter une colonne à votre tableau de données. Ici nous avons la ville et l’État qui se trouvent dans deux colonnes séparées. Nous pouvons utiliser la commande paste (coller) pour combiner ces deux chaînes de caractères en une seule tout en gardant un séparateur. Plaçons ces deux informations dans une seule et même colonne intitulée location (localisation).
early_colleges%>%mutate(location=paste(city,state,sep=","))
## # A tibble: 65 × 7
## college original_name city state established sponsorship location
## <chr> <chr> <chr> <chr> <int> <chr> <chr>
## 1 Harvard <NA> Cambridge MA 1636 Congregational Cambridge,MA
## 2 William and Mary <NA> Williamsburg VA 1693 Anglican Williamsburg,VA
## 3 Yale <NA> New Haven CT 1701 Congregational New Haven,CT
## 4 Pennsylvania, Univ. of <NA> Philadelphia PA 1740 Nondenominational Philadelphia,PA
## 5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian Princeton,NJ
## 6 Columbia King's College New York NY 1754 Anglican New York,NY
## 7 Brown <NA> Providence RI 1765 Baptist Providence,RI
## 8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed New Brunswick,NJ
## 9 Dartmouth <NA> Hanover NH 1769 Congregational Hanover,NH
## 10 Charleston, Coll. Of <NA> Charleston SC 1770 Anglican Charleston,SC
## # ... with 55 more rows
Rappelez-vous que dplyr ne conserve pas les données ni ne transforme le document original. À la place, il crée un tableau de données temporaire à chaque étape. Si vous souhaitez le conserver, vous devez lui associer une variable permanente.
early_colleges_with_location <- early_colleges%>%mutate(location=paste(city,state, sep=","))
# Voir le nouveau tableau avec la colonne "location" ajoutée
early_colleges_with_location
## # A tibble: 65 × 7
## college original_name city state established sponsorship location
## <chr> <chr> <chr> <chr> <int> <chr> <chr>
## 1 Harvard <NA> Cambridge MA 1636 Congregational Cambridge,MA
## 2 William and Mary <NA> Williamsburg VA 1693 Anglican Williamsburg,VA
## 3 Yale <NA> New Haven CT 1701 Congregational New Haven,CT
## 4 Pennsylvania, Univ. of <NA> Philadelphia PA 1740 Nondenominational Philadelphia,PA
## 5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian Princeton,NJ
## 6 Columbia King's College New York NY 1754 Anglican New York,NY
## 7 Brown <NA> Providence RI 1765 Baptist Providence,RI
## 8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed New Brunswick,NJ
## 9 Dartmouth <NA> Hanover NH 1769 Congregational Hanover,NH
## 10 Charleston, Coll. Of <NA> Charleston SC 1770 Anglican Charleston,SC
## # ... with 55 more rows
arrange
La fonction arrange() permet de changer l’ordre des colonnes. Pour l’instant, les universités sont organisées par année de fondation en ordre croissant. Plaçons-les par ordre décroissant (descending en anglais). Dans notre cas, à partir de la fin de la guerre américano-mexicaine :
early_colleges%>%
arrange(desc(established))
## # A tibble: 65 × 6
## college original_name city state established sponsorship
## <chr> <chr> <chr> <chr> <int> <chr>
## 1 Wisconsin, Univ. of <NA> Madison WI 1848 Secular
## 2 Earlham <NA> Richmond IN 1847 Quaker
## 3 Beloit <NA> Beloit WI 1846 Congregational
## 4 Bucknell <NA> Lewisburg PA 1846 Baptist
## 5 Grinnell <NA> Grinnell IA 1846 Congregational
## 6 Mount Union <NA> Alliance OH 1846 Methodist
## 7 Louisiana, Univ. of <NA> New Orleans LA 1845 Secular
## 8 U.S. Naval Academy <NA> Annapolis MD 1845 Secular
## 9 Mississipps, Univ. of <NA> Oxford MI 1844 Secular
## 10 Holy Cross <NA> Worchester MA 1843 Roman Catholic
## # ... with 55 more rows
summarise
La dernière fonction clé de dplyr est summarise() (n’oubliez pas, avec un s comme dans la forme britannique). summarise() est une fonction habituellement utilisée pour créer un tableau de données statistiques récapitulatives destinées à fournir des graphiques. Nous allons l’utiliser pour calculer la date de fondation moyenne des universités avant 1848.
early_colleges%>%summarise(mean(established))
## # A tibble: 1 × 1
## `mean(established)`
## <dbl>
## 1 1810.
Et si nous compilions ces fonctions ?
Maintenant que nous avons exploré les cinq verbes principaux de dplyr, nous pouvons les utiliser pour créer rapidement une visualisation de nos données. Créons un graphique en barres pour représenter le nombre d’universités laïques ou religieuses fondées avant la guerre de 1812 :
secular_colleges_before_1812<-early_colleges%>%
filter(established < 1812)%>%
mutate(`est laïque`=ifelse(sponsorship!="Secular", "non", "oui"))
ggplot(secular_colleges_before_1812) +
geom_bar(aes(x=`est laïque`, fill=`est laïque`))+
labs(x="est-ce que l'université est laïque ?") +
ylab("nombre d'établissements")
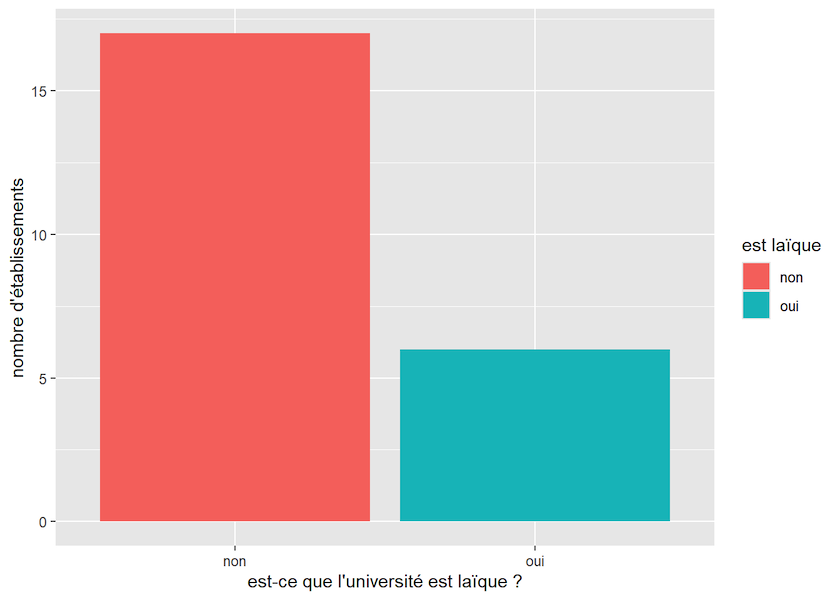
Figure 3. Nombre d’universités religieuses et laïques avant la guerre de 1812.
est laïque est mise entre apostrophes arrière (backticks). Cela permet à la fois de gérer le fait qu’elle occupe deux termes séparés par un espace, au lieu d’un seul, et le i trema présent dans le mot laïque. Ce caractère ne fait pas partie des 128 présents dans la table ASCII et peut donc poser problème dans l’exécution de certains programmes.
Encore une fois, en n’apportant qu’une modification rapide à notre code, nous pouvons aussi visualiser le nombre d’universités laïques par rapport au nombre d’universités religieuses fondées depuis le début de la guerre de 1812 :
secular_colleges_after_1812<-early_colleges%>%
filter(established > 1812)%>%
mutate(`est laïque`=ifelse(sponsorship!="Secular", "non", "oui"))
ggplot(secular_colleges_after_1812) +
geom_bar(aes(x=`est laïque`, fill=`est laïque`))+
labs(x="Est-ce que l'université est laïque ?")+
ylab("nombre d'établissements")
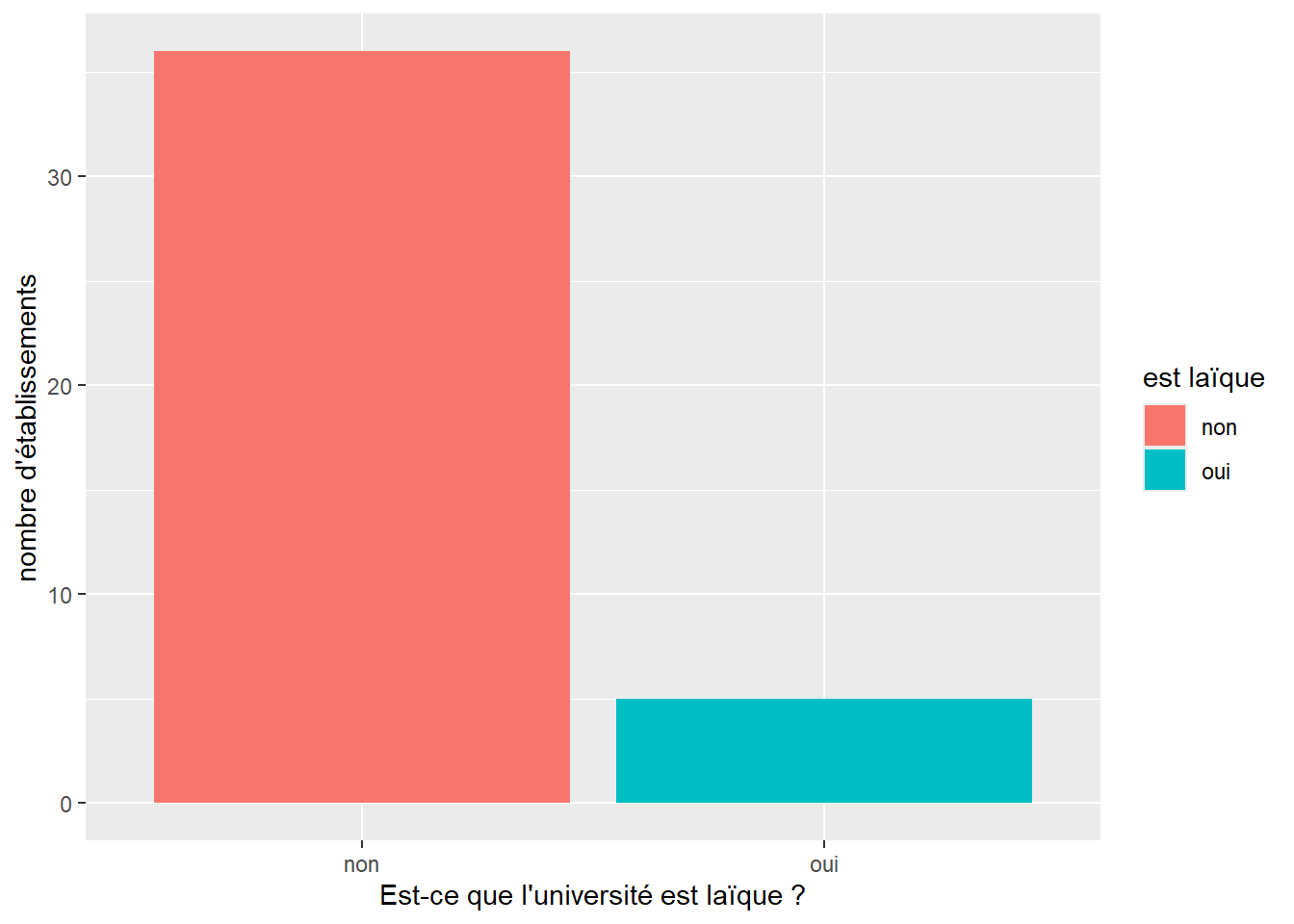
Figure 4. Nombre d’universités religieuses et laïques après la guerre de 1812.
Conclusion
Cette leçon devrait vous mettre sur la bonne voie pour bien concevoir l’organisation et la manipulation de vos données avec R. Plus tard, vous souhaiterez sans doute progresser en visualisation de vos données. Je vous recommande de regarder le paquet ggplot2 pour trouver des fonctions qui seront efficaces avec dplyr. De plus, vous pouvez être tenté d’examiner quelques autres fonctions accessibles dans dplyr pour améliorer vos compétences. Dans les deux cas, ce guide vous fournit une base pour approfondir vos connaissances et vous permet de couvrir les problèmes courants que vous pourriez rencontrer dans la gestion de données.