
Contenidos
- Objetivos de la lección
- Estructura de la lección
- Lectura escalable: una puerta de entrada para las personas que están llegando a los métodos digitales
- La lectura escalable
- Datos y prerrequisitos
- Obtener un pequeño conjunto de datos de prueba sobre la marcha
- Paso 1: exploración cronológica de un conjunto de datos
- Paso 2: Explorando un conjunto de datos mediante la creación de categorías analíticas-binarias
- Paso 3: Selección sistemática y reproducible de datos individuales para la lectura atenta
- Ejemplo de selección reproducible y sistemática para una lectura atenta: datos de Twitter
- Creando un nuevo conjunto de datos con los 20 tweets con más likes (cuentas verificadas y no verificadas)
- Examinando el nuevo dafaframe
- Exportando el nuevo conjunto de datos en un archivo JSON
- Creando un nuevo conjunto de datos con los 20 tweets con más likes (solo cuentas no verificadas)
- Examinando nuestro nuevo dataframe (solo de cuentas no verificadas)
- Exportando el nuevo conjunto de datos como un archivo JSON
- Ejemplo de selección reproducible y sistemática para una lectura atenta: datos de Twitter
- Conclusión: continuando con la lectura atenta
- Consejos para trabajar con datos de Twitter
- Referencias
Objetivos de la lección
Esta lección te permitirá:
- Establecer un flujo de trabajo en el que la lectura distante y exploratoria sea utilizada como un contexto que guie la selección de datos específicos para la lectura atenta
- Realizar análisis exploratorios para encontrar patrones en datos estructurados
- Aplicar y combinar funciones básicas de filtro y organización en R (si no tienes ningún o poco conocimiento de R, te recomendamos que revises la lección Datos tabulares en R).
Estructura de la lección
En esta lección presentamos un flujo de trabajo para realizar una lectura escalable de datos estructurados, combinando la interpretación atenta de datos individuales con el análisis estadístico del conjunto de datos completo. La lección está organizada en dos rutas paralelas:
- Una ruta general, que propone una forma de trabajar analíticamente con datos estructurados, en la que usamos la lectura distante de un gran conjunto de datos como contexto para realizar una lectura atenta de datos individuales diferenciados.
- Una ruta de ejemplo, en la cual usamos funciones del lenguaje de programación R para analizar datos de Twitter.
Combinando estas dos rutas demostraremos que la lectura escalable puede ser usada para analizar una amplia variedad de datos estructurados. Nuestro flujo de trabajo de lectura escalable incluye dos tipos de lecturas distantes que te ayudarán a explorar y analizar características generales de grandes conjuntos de datos (cronológicamente y con relación a estructuras binarias), así como una forma de usar la lectura distante para seleccionar datos individuales con el objetivo de realizar una lectura atenta de una manera sistemática y reproducible.
Lectura escalable: una puerta de entrada para las personas que están llegando a los métodos digitales
La combinación de la lectura atenta con la distante introducida en esta lección busca ser una puerta de entrada a los métodos digitales para estudiantes y personas del universo académico que están comenzando a integrar el pensamiento computacional a su trabajo. Al conectar la lectura distante de grandes conjuntos de datos con la lectura atenta de datos individuales, creamos un puente entre los métodos computacionales y los métodos utilizados habitualmente en tópicos de las humanidades. En nuestra experiencia, la lectura escalable – un tipo de lectura en la que el análisis de los conjuntos de datos representa una serie de contextos para la lectura atenta – alivia las dificultades que pueden experimentar los principiantes a la hora de hacer preguntas sobre su material, las cuales pueden ser exploradas y respondidas utilizando el pensamiento computacional. La forma reproducible de seleccionar casos individuales para una revisión más detallada dialoga atentamente con, por ejemplo, cuestiones centrales de la historia y la sociología sobre la relación entre un contexto general y un estudio de caso, pero también puede ser aplicada a otras disciplinas humanísticas que operan con marcos analíticos similares.
La lectura escalable
Inicialmente, utilizamos el flujo de trabajo que presentamos a continuación para analizar en Twitter el recuerdo del programa de televisión infantil norteamericano Plaza Sésamo. Usamos una combinación de la lectura atenta y la distante para averiguar cómo ciertos acontecimientos generaron discusiones sobre la historia de Plaza Sésamo, qué usuarios de Twitter dominaron la discusión sobre la historia de Plaza Sésamo, y qué partes de la historia del programa fueron enfatizadas. Nuestro ejemplo también utiliza un pequeño conjunto de datos de tweets sobre Plaza Sésamo. Sin embargo, el mismo marco analítico puede utilizarse para analizar otros tipos de datos estructurados. Para demostrar la aplicabilidad del flujo de trabajo a otros tipos de datos, discutimos cómo este podría aplicarse a un conjunto de datos estructurados procedente de las colecciones digitalizadas de la Galería Nacional de Dinamarca. Los datos de la Galería Nacional son muy diferentes de los datos de Twitter utilizados en el ejemplo principal de la lección, pero la idea general, utilizar la lectura a distancia para contextualizar la lectura atenta, funciona de la misma manera que con los datos de Twitter.
El flujo de trabajo para la lectura escalable de datos estructurados que sugerimos a continuación tiene tres pasos:
-
Exploración cronológica de un conjunto de datos
En el conjunto de datos de Twitter, exploramos cómo un fenómeno específico gana tracción en la plataforma durante un cierto período de tiempo. En el caso de los datos de la National Gallery, podríamos haber analizado la distribución temporal de sus colecciones, por ejemplo, según el año de adquisición o la fecha de creación de las obras de arte. -
Exploración de un conjunto de datos mediante la creación de categorías binarias-analíticas
Este paso sugiere utilizar las categorías de metadatos existentes en un conjunto de datos para realizar preguntas de naturaleza binaria, es decir, preguntas que puedan responderse con una lógica de sí/no o verdadero/falso. Utilizamos la creación de una estructura analítica binaria como una forma de analizar algunas de las tendencias generales del conjunto de datos. En el conjunto de datos de Twitter, exploramos el uso de hashtags (versus su ausencia); la distribución de tweets en cuentas verificadas frente a cuentas no verificadas; y el nivel de interacción entre estos dos tipos de cuentas. En el caso de los datos de la National Gallery, podríamos haber utilizado los metadatos registrados sobre el tipo de obra de arte, el género y la nacionalidad de las artistas para explorar la representación de la colección de artistas danesas frente a la de artistas internacionales; pinturas frente a no pinturas; o artistas identificadas como mujeres o no identificadas frente a artistas identificados como hombres, etc. -
Selección sistemática de datos individuales para una lectura atenta
Este paso presenta una forma sistemática y reproducible de seleccionar datos individuales para una lectura atenta. En el conjunto de datos de Twitter, seleccionamos los 20 tweets con más likes para hacer una lectura atenta. Si hubiéramos trabajado con datos de la National Gallery, podrían ser, por ejemplo, los 20 objetos más expuestos, prestados o anotados.
A continuación explicamos los tres pasos tanto en términos generales como específicos usando nuestro ejemplo de Twitter.
Datos y prerrequisitos
Si deseas reproducir el análisis que presentamos a continuación, usando no solo el marco conceptual general sino también el código, asumimos que ya tienes un conjunto de datos que contiene datos de Twitter en formato JSON. Si todavía no tienes un conjunto de datos, puede conseguir uno de las siguientes maneras:
- Utilizando una de las API de Twitter, por ejemplo, su API denominada “Essential” (Esencial), disponible gratuitamente, que usamos para construir el conjunto de datos utilizado en el ejemplo (ver más información sobre las API en esta sección Introduction to Populating a Website with API Data). Este enlace te llevará a las Opciones de API de Twitter. Puedes utilizar el paquete rtweet, con tu propia cuenta de Twitter para acceder a la API de Twitter a través de R, como describimos más adelante.
- Usando la Beginner’s Guide to Twitter Data de Programming Historian (en inglés). En lugar de elegir CSV como formato de “output” (salida), elige JSON.
En R se trabaja con paquetes, cada uno de los cuales añade numerosas funcionalidades a sus elementos básicos. Los paquetes suelen ser códigos creados por la comunidad, que se colocan a disposición para su reutilización. Cuando usamos paquetes nos estamos apoyando sobre los hombros de otros programadores. En nuestro ejemplo los paquetes relevantes son los siguientes: rtweet, tidyverse, lubridate y jsonlite. Para instalar paquetes en R consulta esta sección de la lección Procesamiento básico de textos en R. Para utilizar los paquetes en R hay que cargarlos con la función library() como se indica a continuación:
library(rtweet)
library(tidyverse)
library(lubridate)
library(jsonlite)
Para seguir los ejemplos de código, asegúrate de haber instalado y cargado los siguientes paquetes en R:
tidyverse
El paquete tidyverse es un paquete paraguas que carga varias bibliotecas que son muy útiles para trabajar con datos. Para obtener más información sobre el paquete y aprender a usar tidyverse consulta https://www.tidyverse.org.1
lubridate
El paquete lubridate se utiliza para manejar diferentes formatos de fecha en R y realizar operaciones sobre ellos. El paquete fue creado por el mismo grupo que desarrolló tidyverse, pero no es un paquete central en el tidyverse.2
jsonlite
El paquete jsonlite sirve para manejar el formato de datos Javascript Object Notation (JSON), que es un formato utilizado para el intercambio de datos en internet. Para obtener más información sobre el paquete jsonlite, consulta https://cran.r-project.org/web/packages/jsonlite/index.html.3
Si ya tienes un archivo JSON con tus datos de Twitter, puedes utilizar la función fromJSON del paquete jsonlite para cargar los datos en tu ambiente R.
Obtener un pequeño conjunto de datos de prueba sobre la marcha
rtweet
El paquete rtweet es una implementación de solicitudes diseñada para recopilar y organizar los datos de Twitter a través del REST de Twitter y la Application Program Interface (API, en inglés), que se puede encontrar en la siguiente URL: https://developer.twitter.com/en/docs.4
Si aún no has obtenido datos de Twitter y deseas seguir los ejemplos de código paso a paso, puedes utilizar tu cuenta de Twitter y la función search_tweets() del paquete rtweet para importar los datos de Twitter a tu ambiente de R. Esta acción retornará hasta 18000 tweets de los últimos 9 días. Los datos estarán estructurados en forma de “dataframe”. Al igual que una hoja de cálculo, un dataframe organiza los datos en una tabla bidimensional de filas y columnas. Al copiar el fragmento de código que aparece a continuación podrás generar un dataframe basado en una búsqueda de texto del término “plazasesamo” para seguir nuestro ejemplo. El parámetro q representa tu consulta. Aquí es donde debes escribir el contenido que te interesa. El parámetro n indica el número de tweets que queremos de vuelta.
plazasesamo_datos <- search_tweets(q = "plazasesamo", n = 18000)
Paso 1: exploración cronológica de un conjunto de datos
La exploración de las dimensiones cronológicas de un dataset puede facilitar la primera revisión analítica de tus datos. Si estás estudiando la evolución de un único fenómeno a lo largo del tiempo (como nuestro caso de estudio sobre los acontecimientos específicos que estimularon los debates en torno a Plaza Sesamo), entender cómo este fenómeno ganó tracción y/o cómo disminuyó el interés puede ser revelador en cuanto a su importancia. Este puede ser el primer paso para comprender cómo se relacionan todos los datos compilados con el fenómeno a lo largo del tiempo. El interés por la dispersión temporal también puede estar relacionado no con un acontecimiento, sino con la distribución total de un conjunto de datos basado en una serie de categorías.
Por ejemplo, si estuvieras trabajando con los datos de la National Gallery, podrías explorar la distribución de sus colecciones según los diferentes períodos de la historia del arte para establecer qué períodos están mejor representados en el conjunto de datos de la National Gallery. El conocimiento de la dispersión temporal del conjunto de datos puede ayudar a contextualizar los datos seleccionados para una lectura atenta en el Paso 3, pues te dará una idea de cómo un dato específico se relaciona con la cronología del conjunto de datos completo.
Ejemplo de dispersión temporal de un dataset: datos de Twitter
En este ejemplo, descubrirás cuánto se habló de Plaza Sésamo en Twitter durante un periodo de tiempo determinado. También podrás ver cuántos tweets utilizaron el hashtag oficial #plazasesamo durante ese período.
En la siguiente operación vas a comenzar el procesamiento de los datos antes de pasar a crear tu visualización. Lo que le estás preguntando a los datos es una pregunta en dos partes:
- Primero que todo, quieres saber la dispersión de los tweets en el tiempo.
- En segundo lugar, quieres saber cuántos de ellos contienen el hashtag #plazasesamo.
La segunda pregunta, específicamente, necesita un poco de limpieza de datos antes de que sea posible responderla.
plazasesamo_datos %>%
mutate(tiene_psesamo_ht = str_detect(text, regex("#plazasesamo", ignore_case = TRUE))) %>%
mutate(fecha = date(created_at)) %>%
count(fecha, tiene_psesamo_ht)
## # A tibble: 20 x 3
## fecha tiene_psesamo_ht n
## <date> <lgl> <int>
## 1 2021-12-04 FALSE 99
## 2 2021-12-04 TRUE 17
## 3 2021-12-05 FALSE 165
## 4 2021-12-05 TRUE 53
## 5 2021-12-06 FALSE 373
## 6 2021-12-06 TRUE 62
## 7 2021-12-07 FALSE 265
## 8 2021-12-07 TRUE 86
## 9 2021-12-08 FALSE 187
## 10 2021-12-08 TRUE 93
## 11 2021-12-09 FALSE 150
## 12 2021-12-09 TRUE 55
## 13 2021-12-10 FALSE 142
## 14 2021-12-10 TRUE 59
## 15 2021-12-11 FALSE 196
## 16 2021-12-11 TRUE 41
## 17 2021-12-12 FALSE 255
## 18 2021-12-12 TRUE 44
## 19 2021-12-13 FALSE 55
## 20 2021-12-13 TRUE 35
El proceso anterior crea una nueva columna con el valor TRUE si el tweet contiene el hashtag y FALSE si no lo tiene. Esto se hace con la función mutate(), que crea una nueva columna llamada tiene_psesamo_ht. Para incluir los valores TRUE/FALSE en esta columna utilizamos la función str_detect(). A esta función se le pregunta qué está detectando en la columna text, que contiene el tweet. Aquí utilizamos la función regex() dentro de str_detect() y al hacerlo puedes especificar si estás interesado en todas las variantes del hashtag (por ejemplo #PlazaSesamo, #Plazasesamo, #plazasesamo, #PLAZASESAMO, etc.). Esto se logra estableciendo ignore_case = TRUE en la función regex(), que aplica una expresión regular a tus datos. Las expresiones regulares pueden entenderse como una función de búsqueda y reemplazo ampliada. Si quieres explorar en detalle las expresiones regulares puedes leer más en el artículo Understanding Regular Expressions.
El siguiente paso aplica otra función mutate(), con la que se crea una nueva columna: fecha. Esta columna solo incluye la fecha de los tweets en lugar de la marca de tiempo completa de Twitter, que no solo contiene la fecha, sino también la hora, el minuto y el segundo del tweet. Esto se obtiene con la función date() del paquete lubridate, la cual extrae la fecha de la columna created_at. Por último, utilizamos la función count del paquete tidyverse para contar los valores TRUE/FALSE por día en la columna tiene_psesamo_ht. La función “pipe” (%>%) se utiliza para encadenar comandos de código y está explicada más adelante.
Por favor ten en cuenta que tus datos serán diferentes, ya que no se recopilaron en la misma fecha que los nuestros, y la conversación sobre Plaza Sésamo representada en tu conjunto de datos será diferente de la que había justo antes del 13 de diciembre, cuando recopilamos los datos para este ejemplo.
plazasesamo_datos%>%
mutate(tiene_psesamo_ht = str_detect(text, regex("#plazasesamo", ignore_case = TRUE))) %>%
mutate(fecha = date(created_at)) %>%
count(fecha, tiene_psesamo_ht) %>%
ggplot(aes(date, n)) +
geom_line(aes(linetype=tiene_psesamo_ht)) +
scale_linetype(labels = c("No #plazasesamo", "#plazasesamo")) +
scale_x_date(date_breaks = "1 día", date_labels = "%b %d") +
scale_y_continuous(breaks = seq(0, 400, by = 50)) +
theme(axis.text.x=element_text(angle=40, hjust=1)) +
labs(y=Número de tweets", x="Fecha", caption="Número total de tweets: 2432") +
guides(linetype = guide_legend(title = "Si el tweet contiene #plazasesamo"))
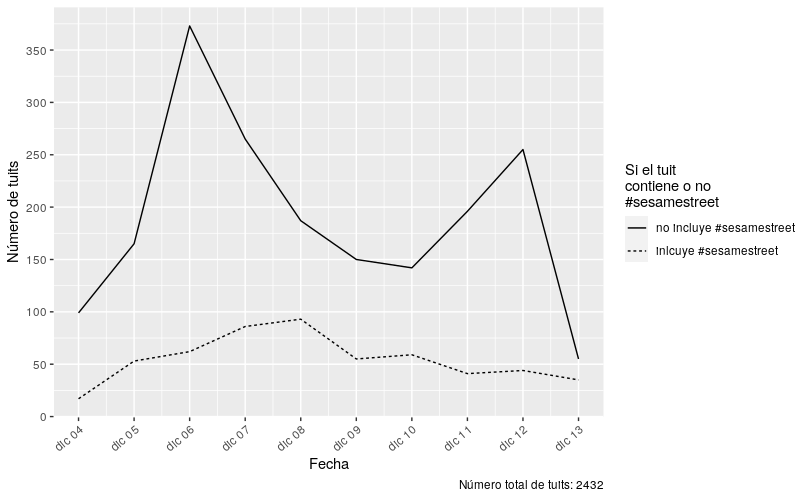
Figura 1. Tweets diarios en el periodo entre el 4 diciembre de 2021 y el 13 de diciembre del mismo año, distribuidos de acuerdo a si contienen o no el hashtag oficial #plazasesamo. Los tweets de este periodo fueron recopilados mediante una búsqueda de texto libre del término ‘plazasesamo’ sin el hashtag. El número total de tweets retornardos fue de 2432.
Ahora vas a crear una visualización de tus resultados. Al usar el código ggplot(aes(date, n)) +, estás creando una visualización para las cuatro líneas de código anteriores (que transforman los datos para ayudarnos a explorar la cronología de los tweets con y sin el hashtag oficial #plazasesamo). Retomando desde donde terminó el bloque de código anterior, continua con la función ggplot(), que es el paquete de gráficos de tidyverse. A esta función se le pide que etiquete al eje x como “Fecha” y al eje y como “Número de Tweets”, basado en valores de verdadero/falso. La siguiente función necesaria para generar la visualización es geom_line(), especificando linetype=tiene\_psesamo\_ht, que traza dos líneas en la visualización, una representando a TRUE y otra a FALSE.
Las líneas de código que le siguen al argumento geom_line() modifican la estética de la visualización. En este contexto, la estética significa la representación visual de los datos en tu visualización. El argumento scale_linetype() le indica a R cuáles líneas deben etiquetarse. scale_x_date() y scale_y_continuous() cambia el aspecto de los ejes x e y, respectivamente. Por último, los argumentos labs() y guides() se utilizan para crear un texto descriptivo de la visualización.
Recuerda cambiar los textos descriptivos dentro de labs() para que coincidan con tu conjunto de datos específico. Si quieres modificar directamente los títulos en tu gráfico, puedes incluir title= y subtitle= junto a las otras etiquetas.
En este momento deberías tener un gráfico que representa la dispersión puntual de los tweets de tu conjunto de datos. Este gráfico muestra la distribución de los tweets recopilados durante el periodo investigado. En el caso de los tweets de Plaza Sésamo, nuestro gráfico muestra que la mayoría fueron tuiteados sin el hashtag #plazasesamo. Adicionalmente, podemos ver que hay dos picos en el gráfico: uno el 6 de diciembre y otro el 12 de diciembre. Esto indica que hubo más actividad sobre Plaza Sésamo en Twitter durante esas dos fechas que durante las otras recopiladas. Ahora continuaremos con la exploración binaria de algunas de las características distintivas de tu conjunto de datos.
Paso 2: Explorando un conjunto de datos mediante la creación de categorías analíticas-binarias
Utilizar una lógica binaria para explorar un conjunto de datos puede ser una forma relativamente sencilla, en comparación con otros métodos digitales, de encontrar relaciones importantes en tu conjunto de datos. Las relaciones binarias son fáciles de contar usando código computacional, y pueden revelar estructuras sistemáticas y definitorias de tus datos. En nuestro caso, nos interesaban las relaciones de poder en Twitter, y en la esfera pública de forma general. Por lo tanto, exploramos las diferencias entre las cuentas verificadas y las no verificadas, ya que las cuentas verificadas son designadas de esa forma debido a su estatus público fuera de la plataforma. Sin embargo, puede que a ti te interese otra cosa, como saber cuántos tweets eran originales o retweets. En ambos casos puedes utilizar los metadatos existentes registrados en tu conjunto de datos para formular una pregunta que pueda responderse utilizando una lógica binaria: el tweet procede de una cuenta verificada, ¿sí o no?; el tweet es un retweet, ¿sí o no?. Ahora supongamos que estás trabajando con datos de la National Gallery. En este caso podrías explorar el sesgo de género en las colecciones y si la institución ha favorecido la adquisición de obras de arte de personas registradas como hombres en su catálogo. Para responder esa pregunta, podrías organizar tu conjunto de datos de manera que puedas artistas hombres (este artista está registrado como un hombre, ¿sí o no?). O, por ejemplo, si te interesa la distribución de las colecciones de las artistas danesas frente a las artistas internacionales, los datos podrían organizarse en una estructura binaria que te permitiría responder si tal artista está registrada como danesa, ¿sí o no?
Las relaciones binarias pueden formar un contexto para tu lectura atenta de los datos seleccionados en el Paso 3. Conocer la distribución de los datos en dos categorías también te permitirá establecer la representatividad de un dato específico con respecto a la distribución de esta categoría en el conjunto de datos completo. Por ejemplo, si en el paso 3 eliges trabajar con los 20 tweets con más likes, podrás ver que aunque haya muchos tweets de cuentas verificadas en este grupo seleccionado, estas cuentas no están bien representadas en el conjunto de datos; los 20 tweets con más likes que has seleccionado no son, por tanto, representativos de los tweets de la mayoría de las cuentas de tu conjunto de datos, sino que representan un porcentaje pequeño, pero muy “likeado”. Si decides trabajar con las 20 obras de arte más expuestas en un conjunto de datos de la National Gallery, una exploración binaria de las artistas danesas frente a las no danesas podría mostrarte que, aunque las 20 obras más expuestas eran de artistas internacionales, en general estas artistas estaban poco representadas en las colecciones de la National Gallery.
Ejemplo de una exploración binaria: datos de Twitter
En este ejemplo demostraremos el flujo de trabajo que puedes usar en el caso de estar interesada en explorar la distribución de las cuentas verificadas frente a las no verificadas que tuitean sobre Plaza Sésamo.
Recomendamos procesar los datos paso a paso, siguiendo la lógica del pipe (%>%) en R. Una vez entiendas esta idea, el resto del procesamiento de datos será más fácil de leer y comprender. El objetivo general de esta sección es averiguar cómo los tweets recopilados están dispersos entre cuentas verificadas y no verificadas, y mostrarte cómo puedes visualizar el resultado.
plazasesamo_datos %>%
count(verified)
## # A tibble: 2 x 2
## verified n
## * <lgl> <int>
## 1 FALSE 2368
## 2 TRUE 64
Usando el pipe %>% pasas los datos hacia abajo, ¡imagina que los datos están fluyendo por una tubería como el agua! Aquí tienes que verter los datos en la función count y luego le pides que cuente los valores de la columna verificada. El valor será TRUE (verdadero), si la cuenta está verificada, o bien FALSE (falso), lo que significa que no lo está.
Ahora ya tienes los valores contados, pero tal vez sería mejor tener estas cifras como porcentajes. Por lo tanto, el siguiente paso es añadir otro pipe y un fragmento de código para crear una nueva columna que contenga el número de total de tweets en el conjunto de datos. Este paso es necesario para calcular el porcentaje más adelante.
plazasesamo_data %>%
count(verificada) %>%
mutate(total = nrow(plazasesamo_datos))
## # A tibble: 2 x 3
## verificada n total
## * <lgl> <int> <int>
## 1 FALSE 2368 2432
## 2 TRUE 64 2432
Puedes encontrar el número total de tweets usando la función nrow(), la cual retorna el número de filas de un dataframe. En tu conjunto de datos, una fila equivale a un tweet.
Usando otro pipe, ahora crearás una nueva columna llamada porcentaje, en la que puedes calcular y almacenar el porcentaje de dispersión entre tweets verificados y no verificados:
plazasesamo_datos %>%
count(verificada) %>%
mutate(total = nrow(plazasesamo_datos)) %>%
mutate(porcentaje = (n / total) * 100)
## # A tibble: 2 x 4
## verified n total porcentaje
## * <lgl> <int> <int> <dbl>
## 1 FALSE 2368 2432 97.4
## 2 TRUE 64 2432 2.63
El siguiente paso se ejecuta para visualizar el resultado. Aquí debes utilizar el paquete ggplot2 para crear un gráfico de columnas:
plazasesamo_datos %>%
count(verified) %>%
mutate(total = nrow(plazasesamo_datos)) %>%
mutate(porcentaje = (n / total) * 100) %>%
ggplot(aes(x = verificada, y = porcentaje)) +
geom_col() +
scale_x_discrete(labels=c("FALSE" = "No verificada", "TRUE" = "Verificada"))+
labs(x = "Estado de verificación",
y = "Porcentaje",
title = "Figura 2 - Porcentaje de tweets de cuentas verificadas y no verificadas en el conjunto de datos plazasesamo_datos",
subtitle = "Periodo: 4 de diciembre de 2021 - 13 de diciembre de 2021",
caption = "Número total de tweets: 243") +
theme(axis.text.y = element_text(angle = 14, hjust = 1))
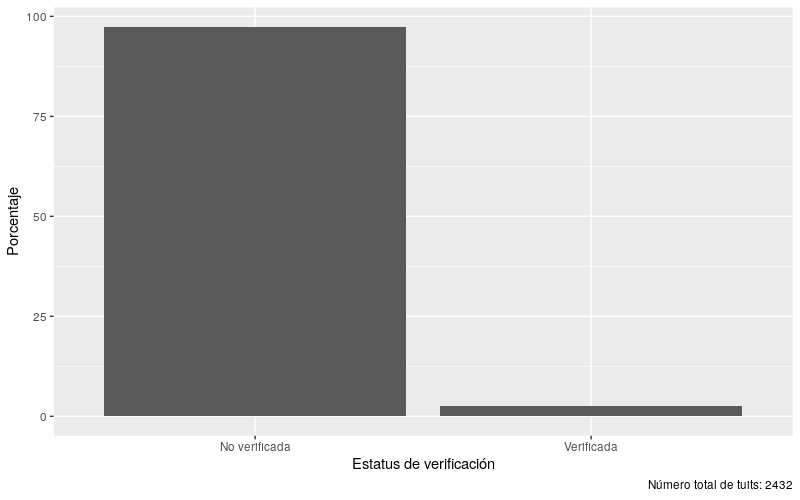
Figura 2. Porcentaje de tweets publicados por cuentas verificadas y no verificadas en el conjunto de datos plazasesamo_datos, durante el periodo del 4 de diciembre de 2021 y el 13 de diciembre de 2021. El número total de tweets fue 2432
A diferencia de las anteriores visualizaciones, que mostraban los tweets a lo largo del tiempo, ahora usaste la función geom_col para crear columnas. Date cuenta de que en ggplot el pipe (%>%) se sustituye por un +. Esta imagen ilustra que la mayoría de los tweets sobre Plaza Sésamo son creados por usuarios no verificados. Este hallazgo puede mostrar que Plaza Sésamo es un tópico popular, politizado y público en Twitter, en cuya discusión están participando personas con cuentas no verificadas.
Interacción con cuentas verificadas frente a las no verificadas
En esta parte del ejemplo demostramos el flujo de trabajo que usamos para investigar la cantidad de interacciones que existen con los tweets de las cuentas verificadas frente a las interacciones con los tweets de cuentas no verificadas. Hemos elegido contar los likes como una forma de medir la interacción. Contrastar el nivel de interacción de estos dos tipos de cuentas te ayudará a estimar si menos cuentas verificadas poseen mucho poder a pesar de su baja representación en general, ya que las personas interactúan mucho más con los tweets de usuarios verificados que con los tweets de cuentas no verificadas.
plazasesamo_datos %>%
group_by(verificada) %>%
summarise(promedio = mean(favorite_count))
## # A tibble: 2 x 2
## verificada promedio
## * <lgl> <dbl>
## 1 FALSE 0.892
## 2 TRUE 114.
Usando el código anterior agruparás el conjunto de datos en función de su estado: verificado = TRUE y no verificado = FALSE. Después de usar la función de agrupamiento, todas las operaciones posteriores se harán sobre los grupos. En otras palabras, todos los tweets procedentes de cuentas no verificadas y todos los tweets procedentes de cuentas verificadas serán tratados como grupos. El siguiente paso es utilizar la función de summarise para calcular el promedio de favorite_count para los tweets de cuentas no verificadas y verificadas (“favorite” es el nombre dado para un like en nuestro conjunto de datos).
En el siguiente paso adicionarás el resultado de arriba a un dataframe. Usa una nueva columna que se llama interacciones para especificar que te estás refiriendo a favorite_count:
interacciones <- plazasesamo_datos %>%
group_by(verificada) %>%
summarise(promedio = mean(favorite_count)) %>%
mutate(interacciones = "favorite_count")
En el siguiente paso vas a calcular el promedio de retweets siguiendo el mismo método aplicado con el conteo de favoritos:
interacciones %>%
add_row(
plazasesamo_datos %>%
group_by(verificada) %>%
summarise(promedio = mean(retweet_count), .groups = "drop") %>%
mutate(interaccion = "retweet_count")) -> interacciones
De esta manera el resultado es un conjunto de datos con los promedios de las diferentes interacciones, permitiendo pasarlo al paquete ggplot para su visualización, la cual realizamos a continuación. Esta visualización se parece bastante a los gráficos de barras anteriores, pero la diferencia aquí es el facet_wrap, que crea tres gráficos de barras para cada tipo de interacción:
interacciones %>%
ggplot(aes(x = verificada, y = promedio)) +
geom_col() +
facet_wrap(~interaccion, nrow = 1) +
labs(caption = "Número total de tweets: 2411",
x = "Estado de verificación",
y = "Promedio de interacciones") +
scale_x_discrete(labels=c("FALSE" = "No verificada", "TRUE" = "Verificada"))
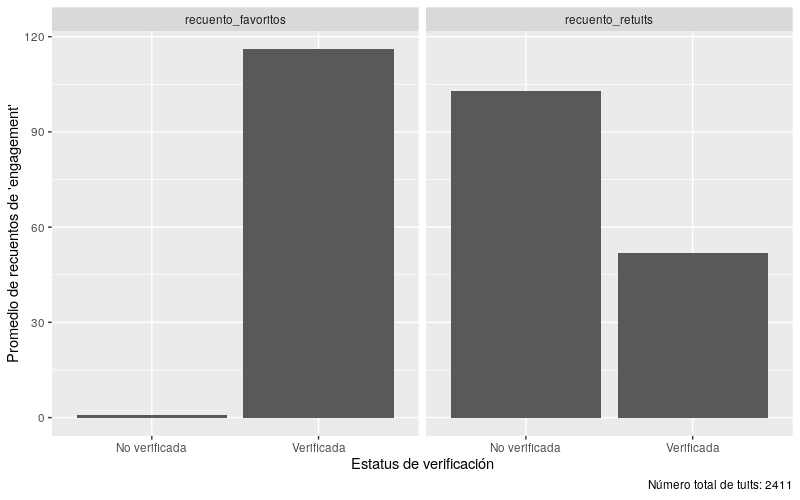
Figura 3. Promedio de interacciones distribuidas según el estado de verificación durante el 4 de diciembre de 2021 al 13 de diciembre de 2021. El número total de tweets fue 2432
Esta visualización se parece mucho a los gráficos de barras anteriores, pero la diferencia aquí es el facet_wrap, que crea dos gráficos de barras para cada tipo de interacción. El gráfico muestra que los tweets de cuentas verificadas reciben más atención que los tweets de cuentas no verificadas.
Paso 3: Selección sistemática y reproducible de datos individuales para la lectura atenta
Una de las grandes ventajas de combinar la lectura atenta con la distante es la posibilidad de hacer una selección sistemática y reproducible de datos específicos para la lectura atenta. Una vez que hayas explorado tu conjunto de datos usando los dos tipos diferentes de lectura distante descritos en el Paso 1 y el Paso 2, podrás utilizar estos conocimientos para seleccionar sistemáticamente datos individuales para una lectura atenta. La lectura atenta te permitirá explorar tendencias interesantes de tus datos, y desentrañar tus tópicos elegidos para investigarlos en profundidad.
El número de datos individuales que decidas leer de forma atenta dependerá del fenómeno que estés investigando, del tiempo que tengas a disposición y de la complejidad de los datos. Por ejemplo, analizar obras de arte individuales puede requerir mucho más tiempo que la lectura de tweets individuales, sin embargo, esto puede cambiar de acuerdo a tu objetivo. Por lo tanto, es importante ser sistemático en la selección de los datos individuales para garantizar su conformidad con las preguntas de la investigación. En nuestro caso, queríamos saber cómo los tweets con más likes representaban a Plaza Sésamo; cómo estos hablaban del programa y su historia, cómo se relacionaban con otros medios, y cómo se representaba el programa visualmente, por ejemplo, con imágenes, enlaces a vídeos, memes, etc. Considerando la interesante relación entre la escasa representación y el alto nivel de interacción de los tweets de las cuentas verificadas, quisimos hacer una lectura atenta de los 20 tweets con más likes (verificados y no verificados), y también del top 20 de tweets publicados por cuentas no verificadas para ver si estas hablaban de la serie y su historia de forma diferente. Elegimos el top 20 porque nos pareció que era una tarea que podíamos llevar a cabo con el tiempo que disponíamos.
Si estuvieras trabajando con los datos de la National Gallery, podrías seleccionar las 5 o 10 obras más exhibidas o prestadas de artistas danesas e internacionales para investigar más a fondo sus diferencias o puntos en común, haciendo una lectura atenta de artistas particulares, tipo de obra, motivos, contenido, tamaño, periodo de la historia del arte, etc.
Ejemplo de selección reproducible y sistemática para una lectura atenta: datos de Twitter
En este ejemplo estamos interesados en seleccionar los 20 tweets con más likes en total. Podemos predecir que muchos de estos tweets probablemente fueron publicados por cuentas verificadas, sin embargo, también debemos seleccionar el top 20 de tweets con más likes publicados por cuentas no verificadas para poder comparar y contrastar las dos categorías.
Para examinar solo los tweets originales, empieza por filtrar todos los tweets que sean retweets.
En la esquina superior derecha de la interfaz de R Studio, un entorno de desarrollo de código abierto para escribir y ejecutar programas en R, encontrarás tu Entorno Global, el cual contiene el dataframe plazasesamo_datos. Al hacer clic en el dataframe podrás ver las filas y columnas que contienen tus datos de Twitter. Al observar la columna is_retweet, verás que esta indica si un tweet es un retweet usando los valores TRUE o FALSE.
Regresa a tu archivo de R Markdown, un tipo de lenguaje de marcado que permite crear documentos dinámicos en R, luego de cerrar la vista del dataframe, y observa que ahora puedes utilizar la función filter para seleccionar unicamente los tweets originales (es decir, mantener las filas en las que el valor del retweet es FALSE). El R-markdown es un formato de archivo que soporta código en R y texto. A continuación puedes ordenar los tweets restantes a partir del número de likes que cada uno recibió. Este número se encuentra en la columna favorite_count.
Tanto la función filter como la función arrange provienen del paquete dplyr, que hace parte del tidyverse.
plazasesamo_datos %>%
filter(is_retweet == FALSE) %>%
arrange(desc(favorite_count))
(El resultado fue suprimido por motivos de privacidad)
Como puedes observar en el Entorno Global, el conjunto de datos de plazasesamo_datos tienen un total de 2435 observaciones (el número tendrá variaciones dependiendo de cuándo hayas recopilado tus datos). Después de ejecutar el fragmento de código anterior, podrás calcular cuántos tweets originales contiene tu conjunto de datos. El valor estará disponible en el dataframe resultante. En nuestro ejemplo fueron 852 tweets originales, pero recuerda que en el tuyo habrá variaciones.
En la columna favorite_count ahora podrás observar cuántos likes hay en tu top 20. En nuestro ejemplo, el top 20 tenía un número superior a 50. Estos números son variables que cambiarán cuando reproduzcas el ejercicio con tus datos. Asegúrate de comprobar estos valores.
Creando un nuevo conjunto de datos con los 20 tweets con más likes (cuentas verificadas y no verificadas)
Ahora que sabes que el valor mínimo de favorite_count (conteo de favoritos) es 50, añade una segunda función de filtro al anterior fragmento de código, el cual mantiene todas las filas que tengan un valor de favorite_count superior a 50.
Como ya capturaste los 20 tweets con más likes, ahora podrás crear un nuevo conjunto de datos llamado plazasesamo_datos_mas_de_50_favoritos.
sesamestreet_datos %>%
filter(is_retweet == FALSE) %>%
filter(favorite_count > 50) %>%
arrange(desc(favorite_count)) -> plazasesamo_datos_mas_de_50_favoritos
Examinando el nuevo dafaframe
Para crear una perspectiva general rápida de tu nuevo conjunto de datos, utiliza la función select del paquete dplyr para aislar las variables que deseas examinar. En este caso la intención es aislar las columnas favorite_count, screen_name, verified y text.
sesamestreet_datos_mas_de_50_favoritos %>%
select(favorite_count, screen_name, verified, text) %>%
arrange(desc(favorite_count))
(El resultado fue suprimido por motivos de privacidad)
A continuación, ordena los datos a partir del valor de favorite_count utilizando la función arrange.
Este fragmento de código retorna un dataframe que contiene los valores de las variables que buscabas aislar: favorite_count, screen_name, verified y text. Por lo tanto, es mucho más fácil de examinar el resultado que revisar todo el conjunto de datos plazasesamo_datos_mas_de_50_favoritos en el Entorno Global.
Exportando el nuevo conjunto de datos en un archivo JSON
Para exportar tu nuevo conjunto de datos fuera del ambiente de R y guardarlo como un archivo JSON puedes utilizar la función toJSON del paquete jsonlite. Elegimos el formato de archivo JSON porque los datos de Twitter son relativamente complejos, por ejemplo, varios de los hashtags almacenados están listados dentro de una única fila. Esta configuración es difícil de manejar en formatos de datos rectangulares populares como csv, por lo que elegimos el formato JSON.
Para asegurarte de que tus datos está dispuesta de la forma más manejable y estructurada posible, anota todos tus archivos de datos de lectura atenta con la misma información:
- ¿Cuántos tweets/observaciones contiene el conjunto de datos?
- ¿A partir de qué variables están organizados los datos?
- ¿Los tweets publicados provienen de todo tipo de cuentas o solo de cuentas verificadas?
- ¿En que año fueron producidos los datos?
top_20_tweets_con_mas_likes <- jsonlite::toJSON(plazasesamo_datos_mas_de_50_favoritos)
Después de convertir tus datos al formato JSON, puedes utilizar la función write de R base para exportar los datos y guardarlos en tu computador.
write(top_20_tweets_con_mas_likes, "top_20_tweets_con_mas_likes.json")
Creando un nuevo conjunto de datos con los 20 tweets con más likes (solo cuentas no verificadas)
Ahora queremos ver los 20 tweets con más likes de cuentas no verificadas.
plazasesamo_datos %>%
filter(is_retweet == FALSE) %>%
filter(verificada == FALSE) %>%
arrange(desc(favorite_count))
(El resultado fue suprimido por motivos de privacidad)
Para hacer esto debes seguir el mismo flujo de trabajo que antes, pero en el primer bloque de código vas a incluir una función de filtro adicional, del paquete dplyr, la cual retiene todas las filas con el valor FALSE en la columna de verificación, eliminando, de ese modo, todos los tweets que fueron creados por cuentas verificadas.
Aquí podrás ver cuántos de los 2435 tweets en total no eran retweets y fueron creados por cuentas no verificadas. En nuestro ejemplo fueron 809. Sin embargo, este número no será el mismo en tu caso.
Observando de nuevo la columna favorite_count, busca el tweet número 20 en la lista de likes (el veinteavo tweet con más likes). Observa cuántos likes tiene este tweet y ajusta el favorite_count con ese valor. En nuestro ejemplo, el top 20 de tweets de cuentas no verificadas tenían un conteo superior a 15. En esta ocasión, 2 tweets comparten el 20º y 21º lugar. En este caso es mejor ajustar el resultado a los 21 tweets con más likes.
plazasesamo_datos %>%
filter(is_retweet == FALSE) %>%
filter(verified == FALSE) %>%
filter(favorite_count > 15) %>%
arrange(desc(favorite_count)) -> plazasesamo_datos_mas_de_15_favorite_count_no_verificadas
Ahora podrás filtrar los tweets con más de 15 likes, ordenarlos de mayor a menor, y crear un nuevo conjunto de datos en tu Entorno Global llamado plazasesamo_datos_mas_de_15_favoritos_no_verificadas.
Examinando nuestro nuevo dataframe (solo de cuentas no verificadas)
Aquí nuevamente puedes crear un panorama general del nuevo conjunto de datos utilizando las funciones select y arrange, tal y como hicimos anteriormente, y examinar los valores seleccionados en el nuevo dataframe.
plazasesamo_datos_mas_de_15_favoritos_no_verificadas %>%
select(favorite_count, screen_name, verified, text) %>%
arrange(desc(favorite_count))
(El resultado fue suprimido por motivos de privacidad)
Exportando el nuevo conjunto de datos como un archivo JSON
Utiliza otra vez la función toJSON para exportar a tu computador los datos en un archivo JSON.
top_21_tweets_con_mas_likes_no_verificadas <-
jsonlite::toJSON(plazasesamo_datos_mas_de_15_favoritos_no_verificadas)
write(top_21_tweets_con_mas_likes_no_verificadas, "top_21_tweets_con_mas_likes_no_verificadas.json")
En este momento deberías tener dos archivos JSON guardados en tu directorio designado, listos para ser cargados en otro R Markdown para realizar un análisis de lectura atenta, o si prefieres, puedes examinar la columna de texto de los conjuntos de datos en tu Ambiente Global actual de R.
Ahora estás lista para copiar las URL del dataframe y examinar los tweets individuales en Twitter. Recuerda observar atentamente los Términos de Servicio de Twitter y actuar acorde a estos. Los términos, por ejemplo, estipulan que no está permitido compartir tu conjunto de datos con otros, excepto como una lista de tweet-ids. Los términos también especifican que la correspondencia fuera de Twitter (es decir, la asociación de cuentas y contenido con individuos) sigue reglas muy estrictas y tiene límites específicos; y además que estás limitado de varias maneras si deseas publicar tus datos o citar los tweets, etc.
Conclusión: continuando con la lectura atenta
Cuando hayas seleccionado los datos individuales que deseas leer atentamente (Paso 3), los métodos iniciales de la lectura distante exploratoria (Paso 1 y Paso 2) podrán utilizarse de forma combinada, como un contexto altamente cualificado para tu análisis en profundidad. Volviendo a la exploración cronológica (Paso 1), podrás observar dónde están situados los datos que seleccionaste para analizar individualmente en tu conjunto total. Con esta información puedes, por ejemplo, considerar qué diferencia puede tener si los datos están situados de forma inicial o tardía en comparación con la distribución general de los datos, o qué significa si los datos individuales seleccionados hacen parte de un pico. Con respecto a las estructuras binarias (Paso 2), la lectura distante puede ayudarte a determinar si un dato individual es un “outlier”, un dato individual que se desvía significativamente del resto en un conjunto, o sí es representativo de una tendencia más amplia en los datos, como también indagar que tan grande es la porción del conjunto de datos que representa con relación a una característica determinada. En el ejemplo de los datos de Twitter, demostramos cómo la lectura atenta de datos individuales seleccionados pueden ser contextualizados con la lectura distante.
La exploración cronológica puede ayudarte a determinar dónde están posicionados los tweets seleccionados para la lectura atenta con relación a un evento que te interese. Tal vez un tweet haya sido publicado antes que la mayoría, lo que indica que fue, tal vez, parte de una primera mirada sobre un determinado tema. Mientras que un tweet “tardío”, tal vez sea más reflexivo o retrospectivo. Para determinar esto tendrás que realizar una lectura atenta y analizar los tweets seleccionados utilizando algunos métodos tradicionales de las humanidades, sin embargo, la lectura distante puede ayudarte a matizar y contextualizar tu análisis. Lo mismo ocurre con las estructuras binarias y los criterios utilizados para seleccionar los 20 tweets con más likes. Si sabes que un tweet proviene de una cuenta verificada o no, y si fue uno de los que más likes tuvo, entonces puedes compararlo con las tendencias generales de estos parámetros en el conjunto de datos cuando hagas tu lectura atenta. Esto te ayudará a robustecer tus argumentos en el caso de un análisis en profundidad de un dato individual, ya que sabrás lo que representa con relación al evento de forma general, al debate o al tema que estés investigando.
Consejos para trabajar con datos de Twitter
Como mencionamos al inicio de esta lección, existen diferentes formas de obtener los datos de Twitter. Esta sección puede ayudarte a aplicar el código de esta lección a datos que no hayan sido recopilados con el paquete rtweet.
Si has recopilado tus datos siguiendo la lección Beginner’s Guide to Twitter Data descubrirás que la fecha de los tweets aparece de una manera que no es compatible con el código de esta lección. Para que el código sea compatible con los datos recopilados con el método explicado en Beginner’s Guide to Twitter Data hay que manipular la columna de fecha con expresiones regulares. Estas son relativamente complejas y se utilizan para decirle al computador qué parte del texto de la columna debe entenderse como día, mes, año y hora del día:
df %>%
mutate(date = str_replace(created_at, "^[A-Z][a-z]{2} ([A-Z][a-z]{2}) (\\d{2}) (\\d{2}:\\d{2}:\\d{2}) \\+0000 (\\d{4})",
"\\4-\\1-\\2 \\3")) %>%
mutate(date = ymd_hms(date)) %>%
select(date, created_at, everything())
df$Time <- format(as.POSIXct(df$date,format="%Y-%m-%d %H:%M:%S"),"%H:%M:%S")
df$date <- format(as.POSIXct(df$date,format="%Y.%m-%d %H:%M:%S"),"%Y-%m-%d")
Otras columnas mencionadas en nuestro ejemplo no comparten los mismos nombres de los datos extraídos con la lección Beginner’s Guide to Twitter Data. En nuestro caso son las columnas verified y texto, las cuales corresponden a user.verified y full_text, respectivamente. Aquí tienes dos opciones: o cambias el código, de modo que en todos los lugares donde aparezca verified o text aparezca user.verified o full_text en su lugar. La otra opción es cambiar los nombres de las columnas en el dataframe, lo cual se puede hacer con el siguiente código:
df %>%
rename(verified = user.verified) %>%
rename(text = full_text) ->
Referencias
-
Wickham et al., (2019). “Welcome to the Tidyverse”, Journal of Open Source Software, 4(43), https://doi.org/10.21105/joss.01686. ↩
-
Garrett Grolemund and Hadley Wickham (2011). “Dates and Times Made Easy with lubridate”, Journal of Statistical Software, 40(3), 1-25, https://doi.org/10.18637/jss.v040.i03. ↩
-
Jeroen Ooms (2014). “The jsonlite Package: A Practical and Consistent Mapping Between JSON Data and R Objects”, https://doi.org/10.48550/arXiv.1403.2805. ↩
-
Michael W.Kearney, (2019). “rtweet: Collecting and analyzing Twitter data”, Journal of Open Source Software, 4(42), 1829, 1-3. https://doi.org/10.21105/joss.01829. ↩