Contents
Lesson Goals
This lesson introduces Uniform Resource Locators (URLs) and explains how to use Python to download and save the contents of a web page to your local hard drive.
About URLs
A web page is a file that is stored on another computer, a machine known as a web server. When you “go to” a web page, what is actually happening is that your computer, (the client) sends a request to the server (the host) out over the network, and the server replies by sending a copy of the page back to your machine. One way to get to a web page with your browser is to follow a link from somewhere else. You also have the ability, of course, to paste or type a Uniform Resource Locator (URL) directly into your browser. The URL tells your browser where to find an online resource by specifying the server, directory and name of the file to be retrieved, as well as the kind of protocol that the server and your browser will agree to use while exchanging information (like HTTP, the Hypertext Transfer Protocol). The basic structure of a URL is
protocol://host:port/path?query
Let’s look at a few examples.
http://oldbaileyonline.org
The most basic kind of URL simply specifies the protocol and host. If
you give this URL to your browser, it will return the main page of The
Old Bailey Online website. The default assumption is that the main
page in a given directory will be named index, usually index.html.
The URL can also include an optional port number. Without getting into too much detail, the network protocol that underlies the exchange of information on the Internet allows computers to connect in different ways. Port numbers are used to distinguish these different kinds of connection. Since the default port for HTTP is 80, the following URL is equivalent to the previous one.
http://oldbaileyonline.org:80
As you know, there are usually many web pages on a given website. These are stored in directories on the server, and you can specify the path to a particular page. The “About” page for The Old Bailey Online has the following URL.
http://oldbaileyonline.org/static/Project.jsp
Finally, some web pages allow you to enter queries. The Old Bailey Online website, for example, is laid out in such a way that you can request a particular page within it by using a query string. The following URL will take you to a search results page for criminal record trials containing the word “arsenic”.
https://www.oldbaileyonline.org/search.jsp?form=searchHomePage&_divs_fulltext=arsenic&kwparse=and&_persNames_surname=&_persNames_given=&_persNames_alias=&_offences_offenceCategory_offenceSubcategory=&_verdicts_verdictCategory_verdictSubcategory=&_punishments_punishmentCategory_punishmentSubcategory=&_divs_div0Type_div1Type=&fromMonth=&fromYear=&toMonth=&toYear=&ref=&submit.x=0&submit.y=0
The snippet after the “?” represents the query. You can learn more about building queries in Downloading Multiple Records Using Query Strings.
Opening URLs with Python
As a digital historian you will often find yourself wanting to use data held in scholarly databases online. To get this data you could open URLs one at a time and copy and paste their contents to a text file, or you can use Python to automatically harvest and process webpages. To do this, you’re going to need to be able to open URLs with your own programs. The Python language includes a number of standard ways to do this.
As an example, let’s work with the kind of file that you might encounter while doing historical research. Say you’re interested in race relations in eighteenth century Britain. ‘The Old Bailey Online’ (OBO) is a rich resource that provides trial transcripts from 1674 to 1913 and is one good place to seek sources.
The Old Bailey Online Homepage
For this example, we will be using the trial transcript of Benjamin Bowsey, a “black moor” who was convicted of breaking the peace during the Gordon Riots of 1780. The URL for the entry is
http://www.oldbaileyonline.org/browse.jsp?id=t17800628-33&div=t17800628-33
By studying the URL we can learn a few things. First, The OBO is written
in JSP (JavaServer Pages, a web programming language which outputs
HTML), and it’s possible to retrieve individual trial entries by making
use of the query string. Each is apparently given a unique ID number
(id=t in the URL), built from the date of the trial session in the
format (YYYYMMDD) and the trial number from within that court session,
in this case: 33. If you change the two instances of 33 to 34 in
your browser and press Enter, you should be taken to the next trial.
Unfortunately, not all websites have such readable and reliable URLs.
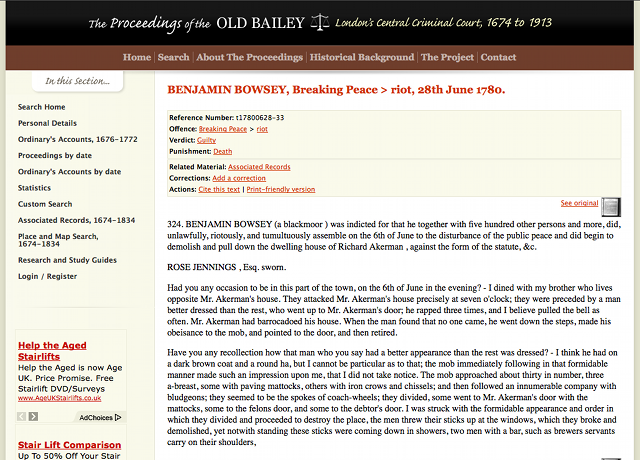
Trial Transcript Page of Benjamin Bowsey, 1780
Spend a few minutes looking at Benjamin Bowsey’s trial page. Here we are not so much interested in what the transcript says, but what features the page has. Notice the View as XML link at the bottom that takes you to a heavily marked up version of the text which may be useful to certain types of research. You can also look at a scan of the original document, which was transcribed to make this resource.
Now let’s try opening the page using Python. Copy the following program
into Komodo Edit and save it as open-webpage.py. When you execute the
program, it will open the trial file, read its contents into a Python
string called webContent and then print the first three hundred
characters of the string to the “Command Output” pane. Use the
View -> Web Developer -> View Page Source command in Firefox to verify
that the HTML source of the page is the same as the source that your
program retrieved. Each browser has a different shortcut key to open the
page source. In Firefox on PC it is CTRL+u. If you cannot find it on
your browser, try using a search engine to find where it is. (See the
Python library reference to learn more about urllib.)
# open-webpage.py
import urllib.request, urllib.error, urllib.parse
url = 'http://www.oldbaileyonline.org/browse.jsp?id=t17800628-33&div=t17800628-33'
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
print(webContent[0:300])
These five lines of code achieve an awful lot very quickly. Let us take a moment to make sure that everything is clear and that you can recognize the building blocks that allow us to make this program do what we want it to do.
url, response, and webContent are all variables that we have named ourselves.
url holds the URL of the web page that we want to download. In this case, it is the trial of Benjamin Bowsey.
On the following line, we call the function urlopen, which is stored in
a Python module named urllib.py, and we have asked that function to
open the website found at the URL we just specified. We then saved the
result of that process into a variable named response. That variable now
contains an open version of the requested website.
We then use the read method, which we used earlier, to copy the contents
of that open webpage into a new variable named webContent.
Make sure you can pick out the variables (there are 3 of them), the modules (1), the methods (2), and the parameters (1) before you move on.
In the resulting output, you will notice a little bit of HTML markup:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Browse - Central Criminal Court</title>
<meta http-equiv="content-type" content=
The content of the trial itself is much further down the page. What we see here is the HTML code at the top of the document. This is not quite what we need for historical research, but don’t worry; you will soon learn how to remove that excess markup and get the content you are after.
Saving a Local Copy of a Web Page
Given what you already know about writing to files, it is quite easy to
modify the above program so that it writes the contents of the
webContent string to a local file on our computer rather than to the
“Command Output” pane. Copy the following program into Komodo Edit, save
it as save-webpage.py and execute it. Using the File -> Open File
command in Firefox, open the file on your hard drive that it creates
(obo-t17800628-33.html) to confirm that your saved copy is the same as
the online copy.
# save-webpage.py
import urllib.request, urllib.error, urllib.parse
url = 'http://www.oldbaileyonline.org/browse.jsp?id=t17800628-33&div=t17800628-33'
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
f = open('obo-t17800628-33.html', 'w')
f.write(webContent)
f.close
So, if you can save a single file this easily, could you write a program to download a bunch of files? Could you step through trial IDs, for example, and make your own copies of a whole bunch of them? Yep. You can learn how to do that in Downloading Multiple Files using Query Strings, which we recommend after you have completed the introductory lessons in this series.
Suggested Readings
- Lutz, Mark. “Ch. 4: Introducing Python Object Types”, Learning Python (O’Reilly, 1999).
Code Syncing
To follow along with future lessons it is important that you have the right files and programs in your “programming-historian” directory. At the end of each lesson you can download the “programming-historian” zip file to make sure you have the correct code.
- programming-historian-1 (zip)