
Contents
- Introduction
- What is Neo4j and why use it?
- Installing and creating a Neo4j database
- Using Cypher
- Putting it all together: A working example
- Conclusion
Introduction
In this lesson we will learn how to use a graph database to store and analyze complex networked information. Networks are all around us. Social scientists use networks to better understand how people are connected. This information can be used to understand how things like rumors or even communicable diseases can spread throughout a community of people.
The patterns of relationships that people maintain with others captured in a network can also be used to make inferences about a person’s position in society. For example, a person with many social ties is likely to receive information more quickly than someone who maintains very few connections with others. Using common network terminology, one would say that a person with many ties is more central in a network, and a person with few ties is more peripheral in a network. Having access to more information is generally believed to be advantageous. Similarly, if someone is very well-connected to many other people that are themselves well-connected than we might infer that these individuals have a higher social status.
Network analysis is useful to understand the implications of ties between organizations as well. Before he was appointed to the Supreme Court of the United States, Louis Brandeis called attention to how anti-competitive activities were often organized through a web of appointments that had directors sitting on the boards of multiple ostensibly competing corporations. Since the 1970s sociologists have taken a more formal network-based approach to examining the network of so-called corporate interlocks that exist when directors sit on the boards of multiple corporations. Often these ties are innocent, but in some cases they can be indications of morally or legally questionable activities. The recent release of the Paradise Papers by the International Consortium of Investigative Journalists and the ensuing news scandals throughout the world shows how important understanding relationships between people and organizations can be.
This tutorial will focus on the Neo4j graph database, and the Cypher query language that comes with it.
- Neo4j is a free, open-source graph database written in java that is available for all major computing platforms.
- Cypher is the query language for the Neo4j database that is designed to insert and select information from the database.
By the end of this lesson you will be able to construct, analyze and visualize networks based on big — or just inconveniently large — data. The final section of this lesson contains code and data to illustrate the key points of this lesson.
Although beyond the scope of this tutorial, those interested in trying to better understand social networks can refer to a number of sources. Sociologists Robert A. Hanneman and Mark Riddle maintain an on-line textbook on network analysis. There are also regular conferences hosted and useful resources available from the International Network for Social Network Analysis.
What is Neo4j and why use it?
Neo4j is a specialized database that manages graphs. Traditional database software stores information in tables – much like data is displayed in Excel spreadsheets except on a much larger scale. Neo4j is also concerned with storing large amounts of data but it is primarily designed to capture the relationship between items of information. Therefore, the organizing principle underlying Neo4j is to store information as a network of relationships rather than a table. Networks contain nodes and nodes are connected through ties. (Nodes are also referred to as “vertices” and ties are referred to as “edges” or links. Networks are also frequently referred to as graphs.)
Databases are designed for dealing with large amounts of data. However, when working with small datasets it is often more efficient not to use a database. The Programming Historian has excellent tutorials for dealing with network data. For an introduction, see Exploring and Analyzing Network Data with Python.
Installing and creating a Neo4j database
Neo4j is currently the most popular graph database on the market. It is also well documented and open-source so this tutorial will focus on it. Accessing information within this type of database is as easy as following connections across the nodes of the graph.
Installation
The first step to install Neo4j is to download the community edition of Neo4j. The software you want is called Neo4j Desktop.

Neo4j Desktop download
Neo4j has recently changed the way the database is installed. Once you download the desktop and install it you will be prompted to enter your user name and password. At this point, you can choose to log in with an existing social media account or create a new login name and password.
Once you start the Neo4j Desktop installation process, the software will take care of installing all of the software it depends on including the latest Java Runtime Environment it depends on. This step requires that you have a connection to the Internet.
Neo4j Desktop installation
Creating a new project
When the Neo4j Desktop starts for the first time, you will see a list of icons on the far left. The topmost icon is a small file folder. This is the projects tab. You can edit projects by simply clicking on a project in the project list. When you do so, the contents of the project will be displayed on the far right of the application (the part with the white background).
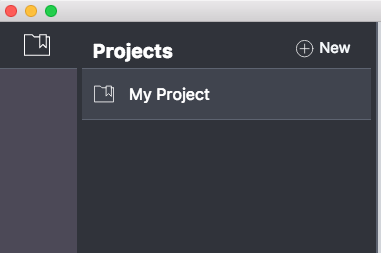
Neo4j Desktop - Projects tab
Adding a database to the project
Adding a new database to a project is simply a matter of clicking “New Database”. Choose the “Local” option because we will store an example database to your local machine. You will then have the option to change the name of your database, the Neo4j version that runs the database, and add a description. We will simply stay with the defaults, but you can change these options later.
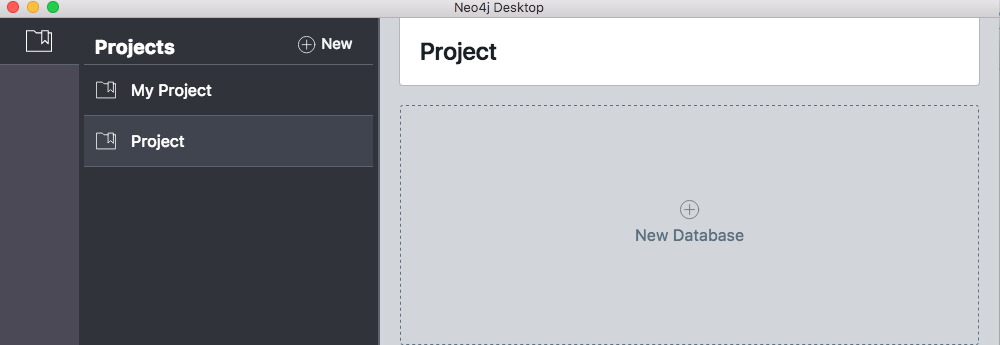
Neo4j Desktop - Adding a new database to a project.
After the database is created you will see two buttons underneath.
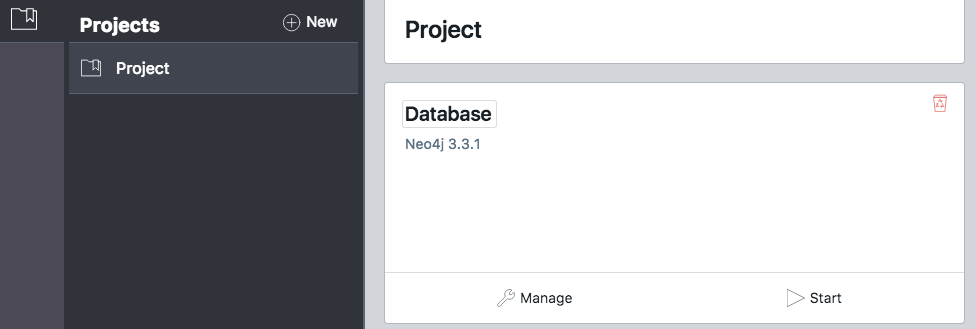
Manage options of your database
Click on “Manage” and you will be presented with a series of options to customize your database. Now that we have the Neo4j database installed, we need to add some example data so we can use it.
Loading Data into Neo4j
The easiest way to load data into the Neo4j database is to load the information you are interested in using comma separated value (CSV) files. You will need to separate your data into data for nodes and data for edges. This is a common way for network information to be separated. In this lesson we will use some example data that has already been formatted.
Using the CSV batch loading mechanism in Neo4j is the fastest way to import data into your new database. In this section I am going to talk about the process more generally for simple cases. This process assumes that you have an empty database.
If you want to follow along, you can download the example data files nodes_companies.csv and edges_director_duration.csv. The canonical guide to loading data from CSV is on the Neo4j website.
Now that we have the example CSV files downloaded, we will use the Cypher query language to load them into our empty Neo4j database. Cypher is a specialized query language that is designed to load and manipulate data in the Neo4j database.
Formatting CSV files for loading into Neo4j
The columns in each CSV will have to be properly named to tell the import tools how to properly create relationships.
Let’s examine the basic format of the two CSV files we downloaded.
nodes_nodes_companies.csv
| companyId | name |
|---|---|
| 1 | CANADIAN BANK OF COMMERCE |
| 2 | SHAWINIGAN WATER AND POWER |
| … | … |
edges_director_duration.csv
| START_ID | years_served | END_ID |
|---|---|---|
| 1 | 2 | 2 |
| 281 | 10 | 422 |
| … | … | … |
By looking at the two data files we can see that the Canadian Bank of Commerce and Shawinigan Water and Power have both employed the same director for 2 years. (The first row of edges_director_duration.csv shows the start node with the Canadian Bank of Commerce ID and the Shawinigan Water and Power ID as the end node.) This director effectively acts as a tie (also known as a corporate interlock) between the two companies.
Note that we could just as easily make the directors the nodes and the companies the edges that connect them. This would give us a clearer picture of the professional network that unites individual directors.
Another alternative would be to represent both Companies and Directors as node types. Directors would still act to tie the boards of companies together but there would be a different relationship between the nodes.
We’ll talk more about defining relationships and nodes below.
Using Cypher
In order to create a network in Neo4j we will load the nodes into the database followed by the information about the edges that connect these nodes together. The process of loading data from a CSV file into Neo4j is relatively straightforward. We are going to:
- Place our CSV files so they can be accessed by Neo4j
- Start the database.
- Open the browser and connect to the database so we can run a Cypher command.
- Using Cypher, we will load our specially formatted CSV files into the database.
This process assumes that your data is cleanly separated into node and edge CSV files.
Moving the CSV files to the import directory
Click on the “Manage” button in the database pane, then the drop down menu next to “Open Folders” and select “Import.” A window will appear with a directory.
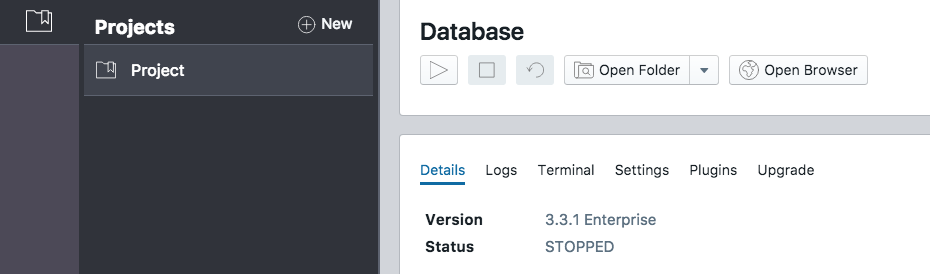
Pressing the Open Folders button
You now need to copy the
nodes_nodes_companies.csv and the edges_director_duration.csv files there.
Now we can use a Cypher command to load the files.
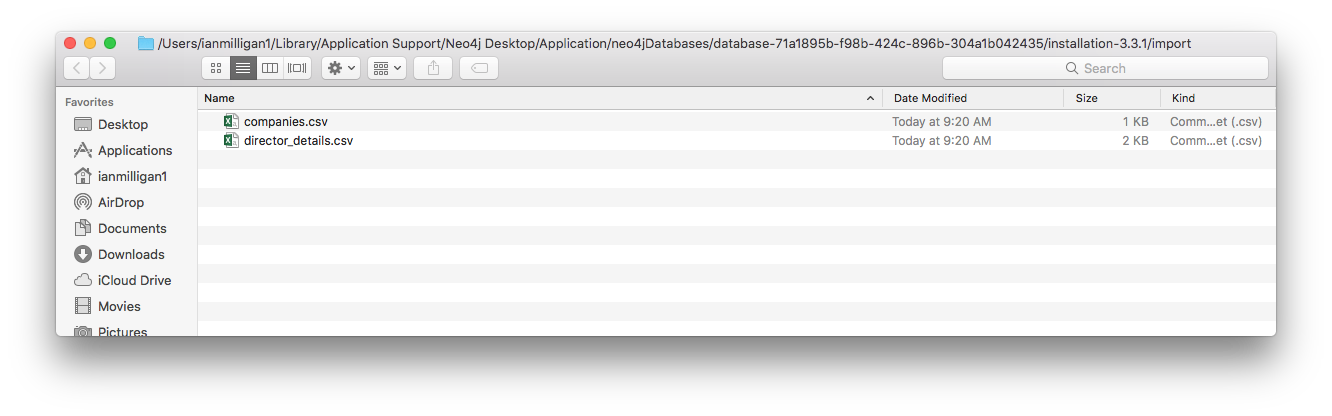
Moving the files to this directory
Start the database
In order to start the database, press the triangular play icon.
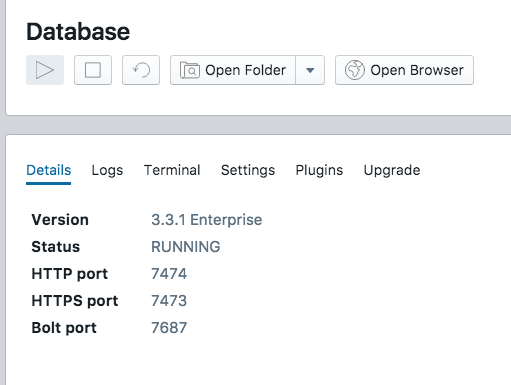
Pressing the start database button
In the “Details” tab beneath, you will see information about the database starting. You’ll notice that the database server is running on “HTTP port 7474”. Neo4j allows access to the database through a web server. In the next step, we will open a browser to connect to the database.
Opening the browser
Click on the “Open Browser” button. A new browser window will appear.
First, you will need to login to your new database. By default,
the username and password are both neo4j. After you log in the
first time, you will be prompted to create a new password.
At the top of the window is a prompt with a blinking cursor. We can add our Cypher command to load our data here
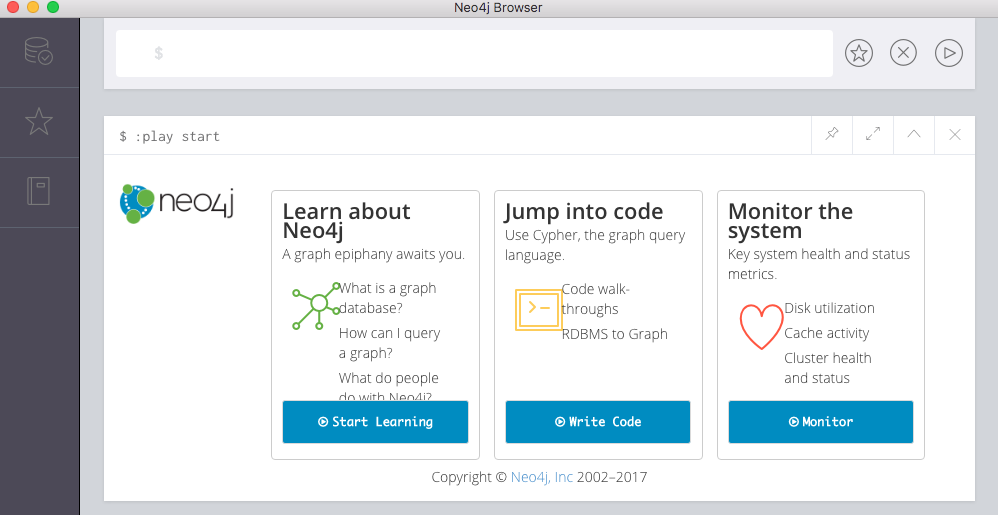
Browser window
Using Cypher to load the CSV files into the database
Again, press the trianglar run icon “>” in order to execute the command. An example can be seen in the screenshot below:

Cypher command window: loading nodes into the database
LOAD CSV with headers FROM "file:///nodes_companies.csv" as nodes
CREATE (n:COMPANY { id:toInteger(nodes.companyId), name:nodes.name })
The Cypher command LOADs the CSV file that contains informative headers (i.e. the first line) from the file we placed in the import directory. (By default, Neo4j can only load files from this directory.) The results will be stored as an object called nodes.
The second line CREATEs data in our database. In particular, we create a series of node objects of the type COMPANY
that contain a name and an id. We set the name of this new company node to the name stored in the nodes.name object and the id to the same as stored in the nodes.companyID.
Notice that the fields that are stored in the nodes object corresponds to the headers we set in the CSV files.
We also use the toInteger() function to make sure our numbers are represented as integers and not as text.
Next we need to load the edge data.
This command does something similar. However, a new command called MATCH has been introduced.
The first line loads the CSV file from the import directory and assigns it to a variable called edges.
The next two lines use MATCH. The first line goes to the existing database and finds a COMPANY node with
an id the same as START_ID. The next line does the same thing, except looks for a match with the END_ID column
in the CSV file. These results are assigned to the variables a and b, respectively.
The final line CREATES a relationship between these nodes. In this case, the relationship type is called INTERLOCK. There is a field called years within the INTERLOCK that is set to the years_served value from the CSV.
LOAD CSV WITH HEADERS FROM "file:///edges_director_duration.csv" AS edges
MATCH (a:COMPANY { id: toInteger(edges.START_ID) })
MATCH (b:COMPANY { id: toInteger(edges.END_ID) })
CREATE (a)-[r:INTERLOCK{weight:toInteger(edges.years_served)}]->(b);
Note: If you have difficulties during the loading process, you can delete all of the nodes and edges in your database using the following command.
MATCH (n)
DETACH DELETE n
Using the Cypher query language
Cypher is a powerful language to query graph databases. Cypher is a language dedicated to loading, selecting or altering data that is stored in the Neo4j database. The following sections will show examples of these actions.
The key to effectively querying Neo4j is to understand that information in the database is represented as a graph and not a table. Therefore, you need to consider the information you’re working with in terms of nodes and relationships that connect nodes together.
A typical Cypher statement shows the relationship between two nodes.
For example, we can create a new COMPANY node:
CREATE (acompany:COMPANY { id:900, name:"Economical Mutual Fire Insurance Company of Berlin"})
In this example, acompany is the variable name we have given to the node object we created in the database.
We marked the node object as being a COMPANY type.
A COMPANY has an attribute called id which is a unique number assigned to that particular company.
In the examples above, each entry also has a name field.
We can use this unique id to query the database for information about the ties from each firm
Now suppose that the database already contains data and we aren’t sure if there is information about a given company. In this case, we can use the MATCH statement to match a unique node and manipulate it.
In the following example, we MATCH both the companynodes (represented by the variables c and p). The CREATE statement then uses the match for each company and CREATEs a relationship between the two nodes. In this case, the relationship is of the type INTERLOCK.
MATCH (c1:COMPANY {companyId:281})
MATCH (c2:COMPANY {companyId:879})
CREATE (c1)-[r:INTERLOCK{weight:10}]->(c2)
RETURN c1,c2,r;
Note that the relationship (r) here is between the two companies. The relationship between COMPANIES is defined as an INTERLOCK. But it is important to note that we can define multiple different kinds of nodes and relationships.
Finally, the RETURN statement returns the variables for us to further manipulate. For example, we might decide to add another attribute to the company. Here we add a URL attribute to the company object that contains the company’s current web site.
SET c.url = "https://economical.com";
Reviewing the data
The data supplied in the nodes_companies.csv and edges_director_duration.csv files
provides us with the basic corporate interlock network that existed in Canada in 1912.
If we use the web interface that comes with Neo4j we’ll be able to see what parts of this network looks like by using a simple query.
With the Neo4j database running, we can open up the built in browser to make more Cypher queries. (Or we can put the following URL into a browser http://localhost:7474/browser/.
Add the following Cypher query.
MATCH (n:COMPANY) RETURN n LIMIT 40;
This query will request that Neo4j find all nodes that are of the type company and return them. The LIMIT option limits the results to the first 40 nodes.
You should see a network that looks something like this.
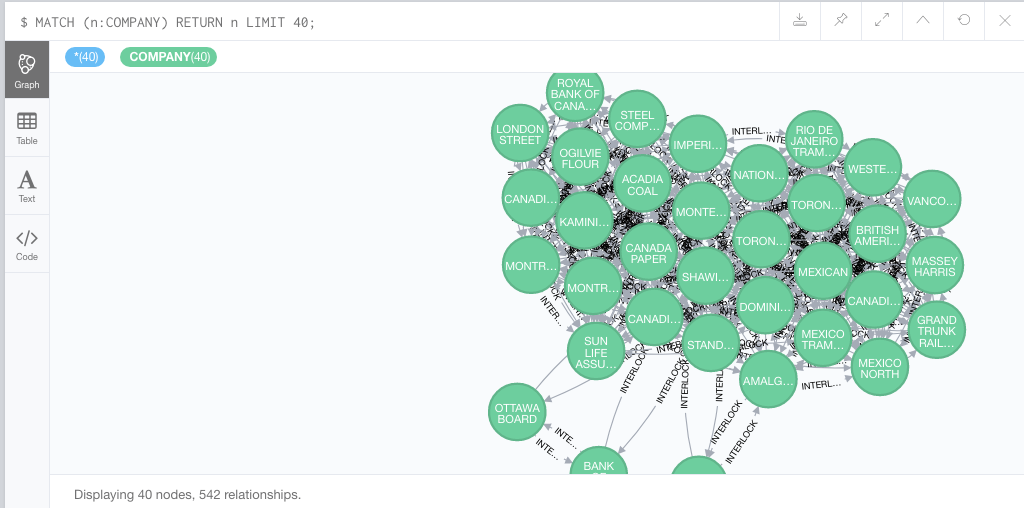
Neo4j results after a simple query
A brief note on INDEX
Creating an index is important for any database to run efficiently. An index is a particular field in a database that is designated for the database to optimize so that lookups are as fast as possible.
To create an index in Neo4j, we would issue the following Cypher command. Creating an index only needs to be done once.
CREATE INDEX ON :COMPANY(id)
Create another index using the company name as well.
CREATE INDEX ON :COMPANY(name)
Creating this index will greatly speed up any queries we make based on the unique keys id and name.
Querying Neo4j: CREATE, MATCH, SET
So far we have used the basic syntax of the Cypher query language. We’ve seen that relationships on a graph are written quite intuitively using Cypher.
(n1:NODE)-[:relationship]->(n2:NODE)
In this section we used Cypher to CREATE entries in the database, MATCH existing data, and we used SET to alter existing data we found.
More on the Cypher query language can be found on the Neo4j web site.
Putting it all together: A working example
If we return to the web interface on your local machine we can query our new database. Let’s look at the firms that have the greatest number of connections (i.e. the highest degree). To calculate degree we can make a simple query with Cypher.
MATCH (c:COMPANY)
set c.degree = size((c)-->());
This code simply matches to each node and counts the size (or degree) of each node. We use the SET command to set the degree value as an attribute of each node.
Now we can examine those nodes with the highest degree. Here we list companies where there are 75 or more connections (via high level employees or directors to other companies).
match (c0:COMPANY)-[r]-(c1) where c0.degree > 75
return DISTINCT c0.name;
This results in the following companies:
- TORONTO AND YORK RADIAL RAILWAY
- MONTREAL ELECTRIC HEAT AND POWER
- CANADIAN PACIFIC RAILWAY
- TORONTO RAILWAY
- DOMINION COAL
- CANADIAN GENERAL ELECTRIC
We can also try to examine all of the interlocks between these well-connected companies.
match (c0:COMPANY)-[r]-(c1) where c0.degree > 75 and c1.degree > 75
return c0, r, c1;
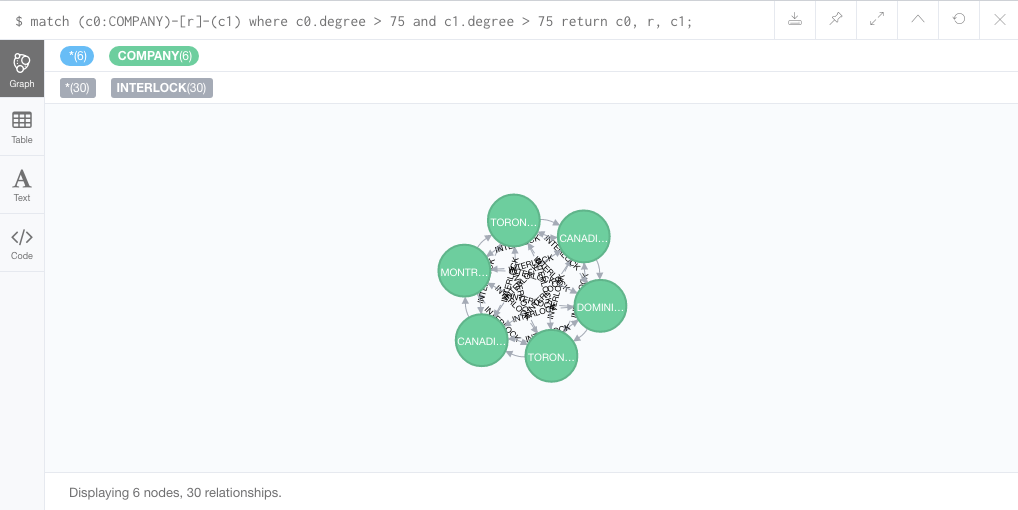
Example graph
You can download the data used in this lesson here (search for the relevant blog posts). If you make use of this data, please cite the following in addition to this lesson:
Mackay, Jon. 2017. “Canadian Regional and National Business Elites in 1912: Who Was Connected, Who Wasn’t and Why” In A History of Socially Responsible Business, c.1600–1950, 189-212. Palgrave Studies in the History of Finance. Palgrave Macmillan. https://doi.org/10.1007/978-3-319-60146-5_8.
Conclusion
In this lesson we’ve introduced the Neo4j graph database. We’ve shown how we can talk directly to the database using the Cypher query language. We’ve also shown how easy it is to visualize different parts of graphs stored in Neo4j using Neo4j’s built in visualization system. Finally, we’ve also included some data and example code that reinforces the key topics of this lesson. Wherever possible this lesson has also linked to primary documents and software to make getting started as easy as possible.