
Conteúdos
- Objetivos de aprendizagem
- Pré-requisitos
- O Sistema de Controlo de Versões (SCV) como ferramenta metodológica
- Considerações finais
- Agradecimentos
- Leituras adicionais
Objetivos de aprendizagem
No final deste tutorial os participantes deverão estar aptos a:
- Compreender os sistemas de controlo de versões e as suas implicações metodológicas para a pesquisa
- Aplicar as funcionalidades básicas do fluxo de trabalho do Git a ficheiros variados
- Desenvolver metodologia consistente de registo e documentação das etapas da pesquisa através do Git
Pré-requisitos
Computador ligado à internet. Terminal (Linux e Mac) ou Git Bash (Windows).
O Sistema de Controlo de Versões (SCV) como ferramenta metodológica
Quem nunca passou por isto?

Figura 1. Cham, Jorge. ‘PHD Comics: notFinal.doc’. Acessado a 26 de setembro de 2022.
No nosso processo de escrita, é bastante comum alterarmos ficheiros constantemente. Inclusões, exclusões e revisões acompanham o nosso trabalho académico, não apenas ao escrevermos um manuscrito, mas também durante a elaboração e execução de projetos de pesquisa: incluímos fontes digitalizadas, imagens, criamos documentos com ideias e fragmentos de análises, geramos dados tabulares e bancos de dados, etc.
Todos estes procedimentos são modificados ao longo do tempo a partir de escolhas e decisões construídas no decorrer da pesquisa. É fundamental que estas alterações sejam registadas, organizadas e preservadas para o futuro: seja para a sua própria pesquisa e processo de escrita, seja para a avaliação de pares ou para desdobramentos em novas pesquisas.
Portanto, é importante termos algum método explícito para controlar as diferentes versões de nosso trabalho. E, de certa forma, cada um de nós tende a desenvolver caminhos para manter esses registos. Contudo, estes métodos costumam ser pouco formalizados e sem uma documentação precisa que possibilite que outros pesquisadores possam compreender o processo de desenvolvimento da pesquisa1. Existem várias formas de realizar um controlo e registo eficiente dos caminhos de uma pesquisa. Na lição Preservar os seus dados de investigação, James Baker apresenta maneiras de documentar e estruturar dados de pesquisa que também servirão de inspiração aqui.
O que é um sistema de controlo de versões?
Ao invés de criarmos um método do zero, proponho a utilização de uma categoria de programas criados especificamente para o registo de alterações em ficheiros: os Sistemas de Controlo de Versão (SCV). Um SCV consiste em um sistema que regista as mudanças de um ficheiro ou conjunto de ficheiros ao longo do tempo. Cada uma destas mudanças é acompanhada de um conjunto de metadados (ou seja, informações sobre os dados), e permite recuperar tanto esses dados quanto o estado em que se encontrava o seu projeto há época.
É como se possuísse uma máquina do tempo capaz de o levar de volta a qualquer ponto da história de mudanças da sua pesquisa.
O uso de SCV é mais comum entre desenvolvedores de código e programas de computador. Entretanto, as suas características o tornam em uma importante ferramenta para as Ciências Humanas e Sociais: ao utilizar um SCV é capaz de acompanhar, documentar, recuperar e corrigir as etapas do projeto de pesquisa. Também é possível acompanhar trabalhos de alunos ou equipes que compõem um projeto2.
Centralizado X Distribuído
Os primeiros SCV possuíam um modelo centralizado. Ou seja, o repositório principal era hospedado em um único servidor que armazenava todos os ficheiros versionados. Quem trabalhava no projeto enviava e recuperava todas as informações diretamente no servidor central. Este sistema possui algumas vantagens, como a capacidade dos administradores controlarem e filtrarem os acessos e atribuições de cada membro da equipe, conseguindo ainda saber quais são eles3 (tradução minha).
Porém, as desvantagens principais consistem, justamente, no seu caráter centralizado: caso o servidor tenha algum problema, todos os dados podem ser perdidos, visto que toda a história do projeto está preservada em um único local.
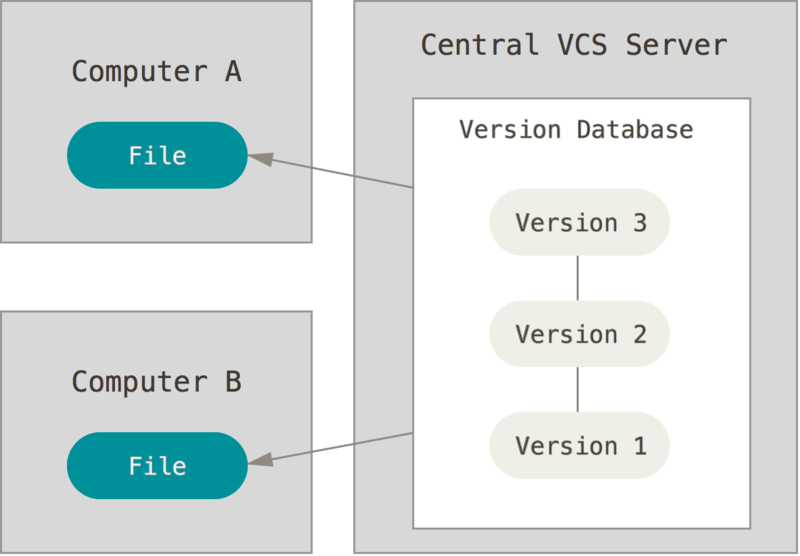
Figura 2. Controlo de versão centralizado. A partir de ‘Chacon e Straub, Pro Git, 2014’. Acessado a 10 de janeiro de 2023.
Os SCV distribuídos têm outra abordagem. Nas palavras de Chacon e Straub, “cada clone [de um repositório de SCV distribuído] é realmente um backup completo de todos os dados”3.
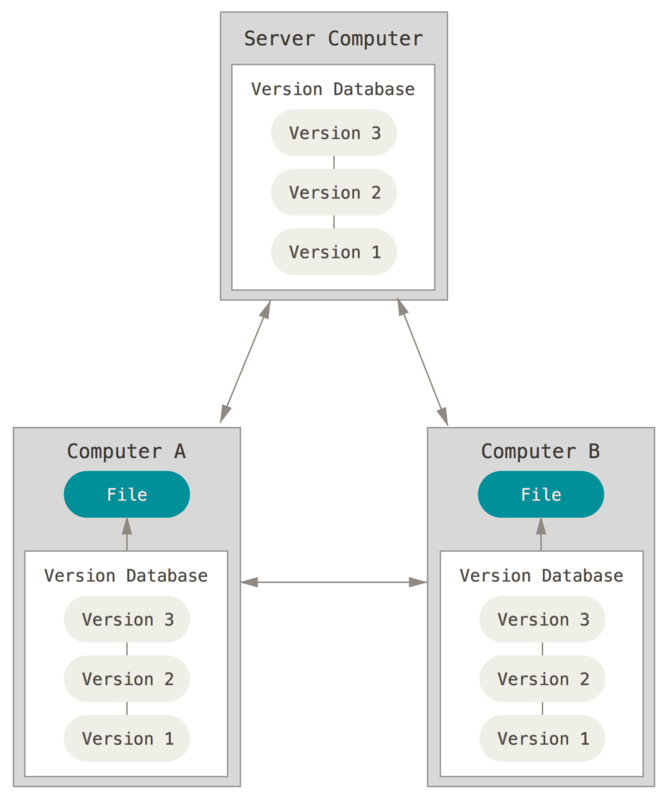
Figura 3. Controlo de versão distribuído. A partir de ‘Chacon e Straub, Pro Git, 2014’. Acessado a 10 de janeiro de 2023.
O que é o Git?
O Git é um SCV de arquitetura distribuída. Foi criado em 2005, por Linus Torvalds4, e é, atualmente, o mais popular do mundo (em inglês). É um software livre e gratuito, com uma grande comunidade de usuários, que oferece documentação extensa e detalhada. O Git “gerencia a evolução de um conjunto de ficheiros - chamado repositório ou repo - de uma forma consciente e altamente estruturada”5 (tradução minha). Todas as mudanças são registadas (em inglês, commited), assim como um conjunto de metadados para cada commit (em português, submissões): identificação única, autoria, mensagem, e data. Estes mecanismos e informações permitem a compreensão geral da história do desenvolvimento de um projeto6.
O Git compreende os seus dados como “uma série de snapshots de um sistema de ficheiros em miniatura”, ou seja, sempre que submete uma alteração ao repositório, o “Git basicamente tira uma fotografia de como todos os seus ficheiros são naquele momento e armazena uma referência para aquele snapshot” (Chacon e Straub, 2014, p. 15). Se um ficheiro não foi modificado, o Git não o armazenará novamente, apenas cria um link atualizado para ele, o que o torna mais leve e rápido. Estas características garantem a integridade do Git, visto que é impossível alterar o conteúdo de qualquer ficheiro ou diretório sem o Git saber3. Praticamente todas estas operações acontecem localmente, minimizando problemas relativos à conexão com servidores, violação de dados e segurança.
O Git também favorece o trabalho em equipe, pois cada membro de um projeto, ao mesmo tempo que tem acesso a todo o histórico de mudanças, também pode empreender alterações específicas em seu repositório local e, posteriormente, submetê-lo a repositórios remotos, hospedados em servidores ou plataformas on-line como o GitHub.7
Apesar destas vantagens, é importante refletir sobre as limitações do Git. A primeira questão é a elevada curva de aprendizagem, em comparação com outros programas. Apesar de possuir uma série de IDEs e programas que trazem interfaces gráficas para sua utilização, o Git é um programa de linha de comandos e compreender os seus principais recursos e aplicá-los de forma correta e eficiente requer a dedicação de horas de estudo e prática.
O Git também apresenta dificuldades em lidar com ficheiros compactados (como ficheiros em formato pdf, docx, ipynb, etc.), pois não é capaz de diferenciar as mudanças internas desses documentos. Ou seja, o Git será capaz de perceber que o ficheiro foi alterado, mas não poderá listar as diferenças, como faria em ficheiros de texto simples, como txt, tex, md, csv, json, etc. Esta característica é coerente com os objetivos dos seus desenvolvedores: o Git foi criado, principalmente, para lidar com ficheiros com códigos de programação e estes são, comumente, leves e de texto simples. Ainda assim, o Git apresenta mais vantagens para acompanhar as mudanças em ficheiros em formatos gerados pelo Microsoft Word do que a utilização do recurso de rastrear mudanças (em inglês, track changes), do próprio Microsoft Word: neste último, enquanto os registos das alterações desaparecem após serem resolvidos pelo usuário, no Git permanecerão integralmente, registados em outros ficheiros no histórico, podendo ser recuperados e reestabelecidos a qualquer momento.
Também é necessário atentar no armazenamento de ficheiros muito grandes e que mudam constantemente. Estes podem gerar históricos muito pesados e, nesse caso, é recomendada a exclusão desses ficheiros do histórico, mantendo apenas o registo de mudanças nos metadados1. É possível informar o Git quais diretórios, ficheiros ou tipos de extensão de ficheiros devem ser ignorados do registo no histórico. Isto é feito através da criação de um ficheiro de texto simples nomeado .gitignore, que deve ser salvo na pasta raiz do repositório local. Nele podemos inserir uma lista de padrões de nomes de ficheiros que o Git deve ignorar, ou seja, não rastrear. Isto é útil para evitar a inclusão de ficheiros muito pesados no seu histórico, ou ainda de ficheiros de texto que não correspondem à pesquisa ou ficheiros que não têm licença para serem publicados. Veremos com mais detalhe esse recurso na parte dois da lição. Para saber mais, veja a documentação do Git (em inglês).
Usando o Git
Se ainda está aqui, acredito que esteja interessado em ver a aplicação prática do Git, mesmo após esta longa introdução. Vamos utilizar o Git e refletir sobre as possibilidades para o seu uso em pesquisas e projetos de história.
Fluxo de trabalho
Podemos resumir o fluxo de trabalho básico do Git da seguinte forma, a partir de Chacon e Straub (2014):
- Modifica algum ficheiro no seu diretório de trabalho (em inglês, working tree)
- Seleciona as mudanças que pretende submeter/registar no histórico do Git (ou repositório local)
- Envia as mudanças para a área de preparação (em inglês, staging area)
- Realiza a submissão (em inglês, commit), incluindo uma mensagem explicativa associada às mudanças realizadas
- O Git, então, pega nos ficheiros exatamente como estão na área de preparação (em inglês, staging area) e armazena esse snapshot permanentemente no seu repositório local do Git, juntamente com o conjunto de metadados associado ao commit
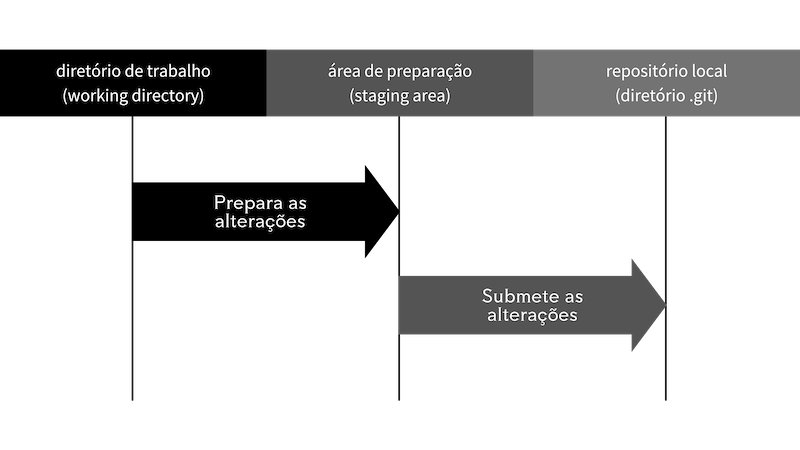
Figura 4. Estrutura básica do fluxo de trabalho no Git. Criado pelo autor no Canva.
Com isto, é possível recuperar e analisar todos os passos realizados desde a criação do repositório local até ao presente.
Instalação
Windows
Para instalar o Git no Windows, acesse este link (em inglês) e faça o download da versão mais recente do ficheiro executável correspondente à arquitetura do seu computador (provavelmente 64-bits). Após a conclusão do download, clique com o botão direito do mouse no ficheiro executável e selecione a opção “Executar como Administrador”.
É preciso aceitar os termos de uso e definir a pasta de instalação. Em seguida, é possível definir os componentes que serão instalados e se serão adicionados ícones no menu iniciar.
Figura 5. Instalação no Windows: componentes a serem instalados.
Na sequência, o Git pergunta qual será o seu editor de texto padrão (manterei o Vim,8 mas pode escolher o de sua preferência).
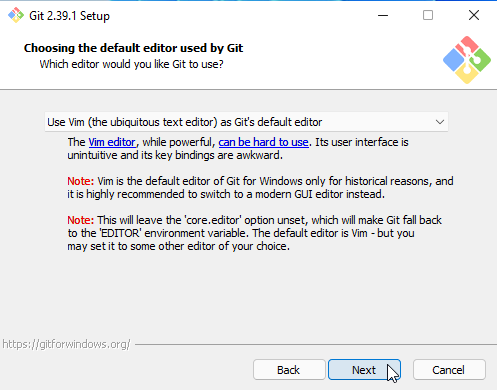
Figura 6. Instalação no Windows: selecione o editor de texto.
A próxima opção é sobre o padrão de nomeação dos branches (em português, ramos) em novos repositórios.9 Escolheremos a opção Override the default branch name for new repositories (em português, substituir o nome do ramo padrão para novos repositórios) e definiremos o nome do branch (em português, ramo) principal como main (em português, principal).10
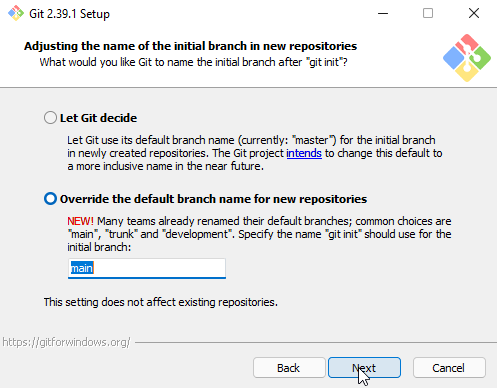
Figura 7. Instalação no Windows: nome do branch principal.
Por fim, é importante definir que o Git será incluído no PATH do sistema, para que possa ser executado a partir de qualquer diretório. Para isso vamos escolher a segunda opção, Git from the command line and also from 3rd-party software (em português, git da linha de comandos e, também, de software terceiro).
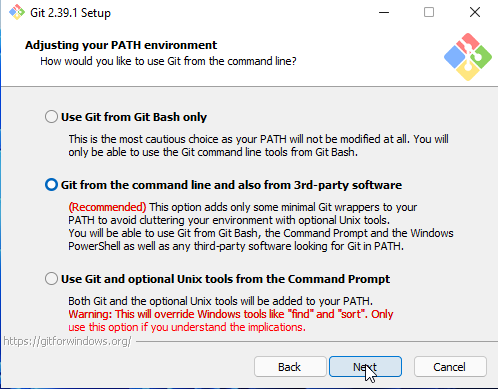
Figura 8. Instalação no Windows: incluir no PATH.
Nas opções seguintes, manteremos as definições padrão, e clicaremos “Next” (em português, seguinte) até aparecer na tela a opção “Install” (em português, instalar).
Linux/MacOS
A instalação do Git em sistemas Linux e MacOs é muito simples, mas ao mesmo tempo oferece menos opções de configuração e é feita diretamente pelo terminal,11 sem o auxílio de uma interface gráfica.
Muitas distribuições Linux já têm o Git instalado. Ainda assim, é muito fácil instalá-lo a partir do seu gerenciador de pacotes. Por exemplo, em distribuições baseadas no Ubuntu, a última versão estável pode ser instalada executando o seguinte comando no terminal:
~$ sudo apt install git
Para uma lista completa de comandos para variadas distribuições Linux, clique aqui (em inglês).
Assim como no Linux, a instalação do Git no MacOs pode ser realizada de maneira simples com o seu gerenciador de pacotes. Para instalar utilizando o homebrew (em inglês), basta executar o seguinte comando no terminal:
~$ brew install git
Para instalar utilizando o MacPorts (em inglês), o comando é o seguinte:
~$ sudo port install git
Para informações gerais e mais opções de instalação no MacOs, clique aqui (em inglês).
Após concluída a instalação, podemos perguntar ao nosso sistema qual a versão do Git que temos instalada. Para Linux e MacOs, abra o Terminal e, para Windows, abra o Git Bash. Em seguida, digite o seguinte comando:
~$ git --version
No meu computador, aparece a seguinte informação:
git version 2.34.1
Todas as ações desta lição serão realizadas a partir de comandos diretamente no terminal de um sistema operacional Linux, pois o objetivo é apresentar o Git a partir da sua base, sem a necessidade de outros programas. Isto é importante para que a lógica do programa, o seu fluxo de trabalho e possibilidades de uso sejam compreendidas de forma completa.
Então, abra o seu terminal, no Linux ou no MacOs, ou o Git Bash no Windows, e vamos começar!
Configuração global
É importante configurar o Git com os dados de autoria e email. Com essas informações, o Git é capaz de registar quem realizou as alterações em dado momento. Neste tutorial, aprenderemos como definir essas informações globalmente para o computador utilizado. O Git possui um ficheiro de configuração intitulado .gitconfig. Este armazena uma série de informações importantes, como a autoria, o email, os padrões de nomeação, e o editor de texto a ser utilizado.12 Para definir o nome do autor e o email, é necessário executar os seguintes comandos:
- Autor
~$ git config --global user.name "Edward Palmer Thompson"
~$ git config --global user.email epthompson@hist.com
Em user.name e user.email use os seus dados pessoais, em vez do historiador inglês, obviamente!
Estes comandos solicitam que o Git acesse o ficheiro de configuração global (git config). Em seguida, passamos à opção --global, definindo que as configurações valem para todos os que utilizarem esse computador; por fim, indicamos o parâmetro que queremos alterar, neste caso, o nome e o email do autor: user.name e user.email.
- Configurar o editor de texto
O Git permite definir o editor a ser utilizado para a escrita das mensagens de commit. Normalmente, o Git utilizará o editor padrão do seu sistema operacional. No meu exemplo, definirei o Vim como editor padrão.
~$ git config --global core.editor "vim"
Também é possível definir o nome do branch principal para novos repositórios. Aqui, seguindo o padrão adotado com maior frequência atualmente, vamos defini-lo como main.
~$ git config --global init.defaultbranch main
Lembrando que, no Windows, o processo de instalação do Git já nos permitiu configurar o editor de texto e o nome do branch principal. Caso queira alterar essas configurações, basta executar os comandos acima no Git Bash.
Pode listar todas as configurações globais do seu computador com o comando git config --global --list.
Uma saída parecida com esta deve ser exibida em sua tela:
user.name=Edward Palmer Thompson
user.email=epthompson@hist.com
init.defaultbranch=main
core.editor=vim
Iniciar um repositório local Git
Nesta lição, vamos criar um diretório vazio em nossa máquina chamado projeto-de-pesquisa. É nele que irá testar os comandos do Git e acompanhar o seu fluxo de trabalho. Para isso, deve abrir o seu Terminal, no Linux e MacOS, ou Git Bash no Windows, e criar o diretório no caminho que escolher. Por exemplo, se pretende criar o diretório projeto-de-pesquisa no interior do diretório Documentos, deve utilizar o comando cd (em inglês, change directory; em português, mudar diretório) e especificar esse caminho. Sobre os comandos básicos que serão utilizados aqui, como cd, mkdir, etc., veja a lição do Programming Historian sobre Bash (em inglês).
~$ cd ~/Documentos/
Em seguida, pode executar o comando para criar um diretório: mkdir (em inglês, make directory; em português, criar diretório).
~/Documentos$ mkdir projeto-de-pesquisa
Lembrando que é possível criar o diretório normalmente através do seu explorador de ficheiros.
Agora, pode entrar no diretório recém-criado e verificar se está vazio, utilizando o comando ls (em inglês, list; em português, lista).
~/Documentos$ cd projeto-de-pesquisa
~/Documentos/projeto-de-pesquisa$ ls
Não deve aparecer nada na sua tela, pois o diretório ainda está vazio.
Para iniciar este diretório como um repositório local Git, deve executar o comando para inicialização: git init.
~/Documentos/projeto-de-pesquisa$ git init
Repositório vazio Git inicializado em /home/proghist/Documentos/projeto-de-pesquisa/.git/
A partir de agora, o seu diretório projeto-de-pesquisa será um repositório submetido ao controlo de versões do Git. Para o verificar, pode executar o comando ls -a (em inglês, list all; em português, lista total), que lista todos os ficheiros e diretórios, inclusive os ocultos.
~/Documentos/projeto-de-pesquisa$ ls -a
O resultado deve ser o seguinte:
. .. .git
O comando git init solicitou ao Git que o diretório projeto-de-pesquisa recebesse uma série de ficheiros e diretórios específicos para o registo e controlo de alterações. Esses ficheiros são ocultos, alocados no interior do diretório .git e têm a função de garantir que todas as modificações ocorridas no interior do diretório de trabalho sejam percebidas, registadas, e apresentadas. O Git reúne uma série de recursos para que possa não apenas registar esse histórico de alterações, mas também analisá-lo, recuperá-lo, e trabalhar de forma mais coesa e segura.
A estrutura de diretórios criada pelo Git é complexa e não será abordada a fundo nesta lição. Se listarmos os ficheiros presentes na recém-criada pasta .git, com o comando ls -a .git, obteremos o seguinte resultado:
. .. branches config description HEAD hooks info objects refs
Neste conjunto de diretórios e ficheiros, o Git armazena as informações sobre o repositório: desde as alterações realizadas até aos dados de configuração e fluxo de trabalho.
Comandos básicos
Após iniciar o seu repositório com o comando git init, podemos criar um novo ficheiro e iniciar o registo das alterações. Assim, poderemos compreender com mais clareza o funcionamento do programa.
Vamos criar um ficheiro markdown chamado README.md, com o conteúdo # Exemplo para a lição, no interior de nosso diretório de trabalho (em inglês, working directory) projeto-de-pesquisa. Pode fazer isto de várias formas - com editores de texto, por exemplo. Aqui utilizarei o terminal e o comando echo.13 Pode fazer o mesmo no Git Bash.
~/Documentos/projeto-de-pesquisa$ echo "# Exemplo para a lição" > README.md
Solicitei que o programa echo incluísse a frase # Exemplo para a lição no ficheiro README.md. Como o ficheiro ainda não existia, foi criado. Se executar o comando ls, verá que o ficheiro foi criado com sucesso.
~/Documentos/projeto-de-pesquisa$ ls
README.md
Git status
Portanto, realizámos uma alteração em nosso repositório. Vamos verificar se o Git percebeu a mudança? Para isso, executamos o comando git status.
~/Documentos/projeto-de-pesquisa$ git status
A mensagem retornada pelo Git é a seguinte:
No ramo main
No commits yet
Arquivos não monitorados:
(utilize "git add <arquivo>..." para incluir o que será submetido)
README.md
nada adicionado ao envio mas arquivos não registrados estão presentes (use "git add" to registrar)
Vamos entender o que o Git está nos dizendo. Ao passarmos o comando status para o Git, somos informados da situação atual do repositório. Neste momento, o Git informa que estamos no ramo (em inglês, branch) main: No ramo main. Em seguida, informa que ainda não existem submissões (em inglês, commits): No commits yet.14 Mais abaixo veremos o que são commits e sua importância metodológica para as nossas pesquisas.
Em seguida temos a mensagem:
Arquivos não monitorados: (utilize "git add <arquivo>..." para incluir o que será submetido)
README.md
nada adicionado ao envio mas arquivos não registrados estão presentes (use "git add" to registrar)
O Git informa que existe um ficheiro chamado README.md dentro do nosso diretório de trabalho que ainda não está a ser monitorado pelo sistema de controlo de versões. Ou seja, o ficheiro ainda precisa de ser adicionado ao repositório Git para que as alterações nele efetuadas sejam registadas.
Git add
O próprio Git informa qual o comando que devemos utilizar para registar o ficheiro: git add <arquivo>. No nosso caso, devemos executar o seguinte:
~/Documentos/projeto-de-pesquisa$ git add README.md
Agora, ao solicitarmos o status do repositório, receberemos uma mensagem diferente:
~/Documentos/projeto-de-pesquisa$ git status
No ramo main
No commits yet
Mudanças a serem submetidas:
(utilize "git rm --cached <arquivo>..." para não apresentar)
new file: README.md
Mais uma vez, percebemos que estamos no ramo main e ainda não realizámos nenhuma submissão (em inglês, commit) neste ramo. Entretanto, não existem mais ficheiros no estado não monitorados (em inglês, untracked files). O nosso ficheiro README.md mudou de status: agora está como um novo ficheiro (em inglês, new file) no estado Mudanças a serem submetidas (em inglês, Changes to be commited).
Git commit
Commits servem como pontos de verificação, onde ficheiros individuais ou um projeto inteiro podem ser revertidos com segurança quando necessário1 (tradução minha).
Agora, as alterações que realizámos estão preparadas para serem submetidas (em inglês, commited) no repositório. Para isso, usámos o comando git commit. É importante destacar a necessidade de incluir uma mensagem para cada commit. São essas mensagens que servirão de base para a documentação de cada etapa do seu projeto de pesquisa. Ou seja, todas as alterações realizadas e selecionadas para serem registadas na linha do tempo gerenciada pelo Git deverão receber uma mensagem explicativa sobre tais alterações. Este procedimento permite tanto a criação de um histórico detalhado das mudanças e decisões, suas razões e sentidos, como fomenta uma metodologia organizada e controlada, visto que cada passo tomado deve receber uma reflexão por parte do pesquisador.
Existem duas formas de incluir uma mensagem no commit. A primeira é mais simples e realizada diretamente com o comando commit:
~/Documentos/projeto-de-pesquisa$ git commit -m "Commit inicial"
[main (root-commit) 254e395] Commit inicial
1 file changed, 1 insertion(+)
create mode 100644 README.md
Neste caso, adicionámos a opção -m (de mensagem) ao comando commit e, em seguida, escrevemos o conteúdo da mensagem entre aspas duplas ("). Essa opção é mais prática, mas possui limitações: a impossibilidade de criar mensagens mais detalhadas, com mais de 50 caracteres e com quebras de linha.
Se desejarmos uma mensagem mais elaborada - o que para os objetivos desta lição é mais coerente -, utilizamos o comando git commit, sem a inclusão da opção -m. Neste caso, o Git abrirá o editor de texto definido nas configurações para que possamos escrever a mensagem.
Como já havíamos realizado o commit das alterações antes e não realizámos nenhuma nova mudança, se executarmos o comando git commit, o Git informa que não há nada a ser submetido:
~/Documentos/projeto-de-pesquisa$ git commit
nothing to commit, working tree clean
Mas, se ainda assim quisermos corrigir a mensagem do último commit, podemos utilizar a opção --amend:
~/Documentos/projeto-de-pesquisa$ git commit --amend
O Git abrirá o editor de texto para que possamos editar a mensagem do último commit. Após a edição, basta salvar e fechar o editor. No meu caso, o editor é o vim. Para sair do editor, basta digitar ESC + :wq e pressionar a tecla Enter.8 É importante destacar que, ao configurar a mensagem de commit com o editor de texto, é possível definir o título e o corpo da mensagem.
O Git considera a primeira linha da mensagem como título, o qual deve ter no máximo 50 caracteres. A restante mensagem é considerada o corpo e deve ser separada do título por uma linha vazia, como no exemplo abaixo:
Criação de README.md
Este commit cria o ficheiro README.md com o objetivo de explicar o funcionamento do Git.
Após salvar e fechar o editor, o Git informa que o commit foi realizado com sucesso:
[main d3fc906] Criação de README.md
Date: Thu Jan 26 11:49:25 2023 +0000
1 file changed, 1 insertion(+)
create mode 100644 README.md
Pronto! Criámos o nosso ficheiro README.md e adicionámos ao repositório Git com sucesso. Para isso, utilizámos o comando git add para adicionar o ficheiro ao index do Git [^git-index], e o comando git commit para submeter as alterações ao repositório. Vimos também como incluir a mensagem de commit diretamente na linha de comandos (git commit -m "mensagem") e como editar a mensagem do último commit realizado (git commit --amend).
Se executarmos git status novamente, veremos que não há mais nada a ser submetido:
~/Documentos/projeto-de-pesquisa$ git status
No ramo main
nothing to commit, working tree clean
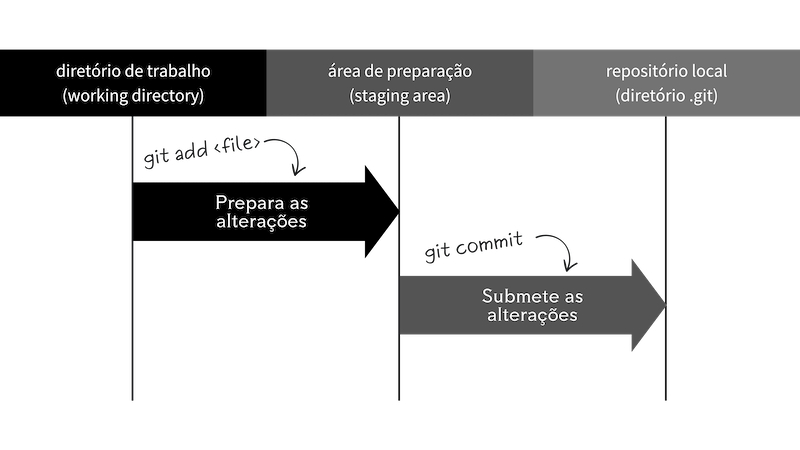
Figura 9. Função dos comandos git add e git commit no fluxo de trabalho no Git. Criado pelo autor no Canva.
Status de um ficheiro
Agora que já sabemos como adicionar um ficheiro ao repositório Git e como submeter alterações acompanhadas de mensagens, vamos detalhar e analisar os diferentes status de um ficheiro no Git. Para isso vamos criar um ficheiro novo chamado resumo.txt e salvá-lo no diretório projeto-de-pesquisa. Repetiremos o mesmo método utilizado para criar o ficheiro README.md, com o comando echo (veja o tópico Comandos Básicos). No entanto, pode criar este ficheiro utilizando qualquer outro método.
~/Documentos/projeto-de-pesquisa$ echo "Resumo" >> resumo.txt
Se listarmos o conteúdo do diretório projeto-de-pesquisa veremos que agora existem dois ficheiros:
~/Documentos/projeto-de-pesquisa$ ls
README.md resumo.txt
Como vimos anteriormente, um ficheiro recém criado no nosso diretório de trabalho tem o status não monitorado (em inglês, untracked) e precisa de ser preparado (em inglês, staged) para ser submetido (em inglês, commited). Podemos ver a sua situação com um git status.
~/Documentos/projeto-de-pesquisa$ git status
No ramo main
Arquivos não monitorados:
(utilize "git add <arquivo>..." para incluir o que será submetido)
resumo.txt
nada adicionado ao envio mas arquivos não registrados estão presentes (use "git add" to registrar)
Ou seja, o ficheiro resumo.txt tem o status não monitorado (em inglês, untracked) e precisa de ser preparado (em inglês, staged). Para preparar o ficheiro, utilizamos git add <nome do arquivo>. Ou seja, solicitamos ao Git que inclua o ficheiro no seu index.
~/Documentos/projeto-de-pesquisa$ git add resumo.txt
A partir do momento em que o ficheiro foi preparado (em inglês, staged) no Git, muda de status e está pronto para ser submetido (em inglês, commit), como podemos ver executando um git status.
~/Documentos/projeto-de-pesquisa$ git status
No ramo main
Mudanças a serem submetidas:
(use "git restore --staged <file>..." to unstage)
new file: resumo.txt
Ou seja, resumo.txt é um novo ficheiro que está pronto para ser submetido ao Git através do commando git commit.
~/Documentos/projeto-de-pesquisa$ git commit
O editor de texto será aberto e poderá inserir, por exemplo, a mensagem “Criação do ficheiro para o resumo do tutorial”. Após salvar e fechar o editor, o Git informa que o commit foi realizado com sucesso:
[main 29ffe51] Criação do ficheiro para o resumo do tutorial
1 file changed, 1 insertion(+)
create mode 100644 resumo.txt
A mensagem retornada informa que um ficheiro foi alterado, e uma inserção realizada em seu conteúdo.
A partir de agora, o ficheiro resumo.txt, assim como o README.md, está inserido no repositório Git que realiza o controlo de versões, ou seja, regista e avalia todas as mudanças que são realizadas.
Vamos alterar o conteúdo dos dois ficheiros para entendermos este processo.
Primeiro, vamos inserir uma frase no ficheiro resumo.txt. Para isso pode abri-lo em qualquer editor de texto, escrever a frase “Este tutorial procura apresentar as funções básicas do Git.” e salvá-lo. Depois, abra o ficheiro README.md e inclua a frase “Lição para o Programming Historian.”, salvando em seguida.
Realizámos alterações em dois ficheiros do nosso diretório de trabalho, ambos registados e monitorados pelo Git. Vejamos as informações que o comando status apresenta agora:
~/Documentos/projeto-de-pesquisa$ git status
No ramo main
Changes not staged for commit:
(utilize "git add <arquivo>..." para atualizar o que será submetido)
(use "git restore <file>..." to discard changes in working directory)
modified: README.md
modified: resumo.txt
nenhuma modificação adicionada à submissão (utilize "git add" e/ou "git commit -a")
A mensagem informa que dois ficheiros foram modificados e ainda não foram preparados para submissão (em inglês, changes not staged for commit). Para inserir estas mudanças e prepará-las para o commit, devemos utilizar o comando git add <nome do arquivo>. É possível incluir mais de um ficheiro no mesmo comando, por exemplo:
~/Documentos/projeto-de-pesquisa$ git add README.md resumo.txt
Podemos ainda especificar que queremos que todos os ficheiros presentes no diretório de trabalho sejam preparados ao mesmo tempo, utilizando git add ..
Agora que preparámos as mudanças para submissão, os ficheiros aparecem com o status Mudanças a serem submetidas (em inglês, Changes to be commited):
~/Documentos/projeto-de-pesquisa$ git status
No ramo main
Mudanças a serem submetidas:
(use "git restore --staged <file>..." to unstage)
modified: README.md
modified: resumo.txt
Para submeter estas mudanças é preciso utilizar o comando commit. Podemos fazer um único commit para as mudanças em todos os ficheiros e escrever uma mensagem detalhada. Por exemplo:
~/Documentos/projeto-de-pesquisa$ git commit
O editor de texto padrão do sistema operacional será aberto e poderá escrever a seguinte mensagem:
Atualização dos dados da lição
- Inclusão do nome do Programming Historian no README.md
- Atualização do texto em resumos.txt
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# No ramo main
# Mudanças a serem submetidas:
# modified: README.md
# modified: resumo.txt
#
Após salvar e fechar o editor, o Git informa que o commit foi realizado com sucesso:
[main 5904720] Atualização dos dados da lição
2 files changed, 3 insertions(+), 1 deletion(-)
Resumindo: sempre que um novo ficheiro for criado, precisa de ser preparado (git add) e submetido (git commit). As submissões devem ser acompanhadas de uma mensagem explicativa sobre o que foi feito. Cada alteração realizada em qualquer ficheiro presente no diretório de trabalho que já esteja sendo monitorado pelo Git deve ser também preparada e submetida com uma mensagem clara e explicativa. É possível consultar a situação do diretório de trabalho com o git status, o que nos possibilita perceber com clareza quais os ficheiros novos, quais foram modificados, e quais foram preparados ou não para submissão.
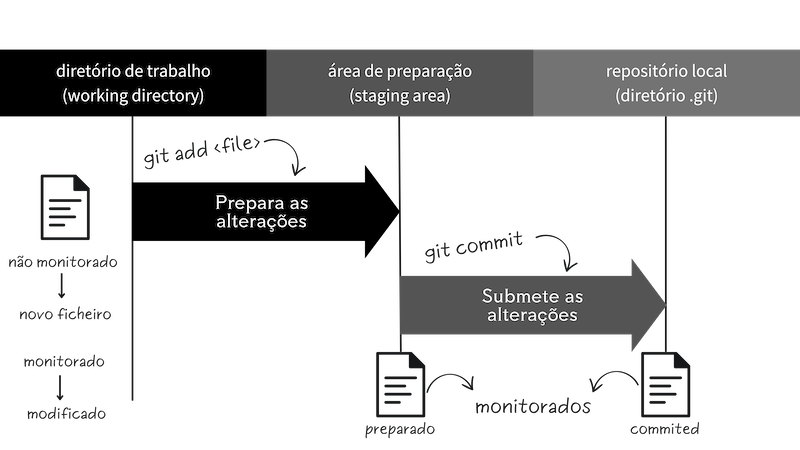
Figura 10. Status de um ficheiro no fluxo de trabalho no Git. Criado pelo autor no Canva.
Como escrever uma mensagem de commit eficiente?
Atualmente, uma parte significativa do nosso trabalho de pesquisa, escrita e ensino é mediada por ferramentas digitais, ao mesmo tempo que dados digitais se tornam cada vez mais centrais para as Ciências Sociais e Humanas. Sejam pesquisas on-line em repositórios, trocas de mensagens através de aplicativos, leitura de informações com editores de texto e de dados tabulares, seja a aplicação de linguagem de programação para análise textual, visualização de dados, entre tantas outras possibilidades. A seleção, coleta, organização e tratamento dos dados que pretendemos utilizar em pesquisas, artigos ou aulas exigem cuidados diferentes e adicionais daqueles para os quais fomos treinados na nossa formação anterior à virada digital. Nas palavras de Fridlunnd, Oiva e Paju:
“Os métodos de pesquisa digital criam exigências novas e às vezes mais rigorosas de precisão, pensamento metodológico, auto-organização e colaboração do que a pesquisa histórica tradicional” (Fridlund; Oiva; Paju, 2020, pos. 543, tradução minha).
Um caminho importante para colmatar estas exigências é a transparência metodológica. Nas palavras de Gibbs e Owens:
“novos métodos usados para explorar e interpretar dados históricos exigem um novo nível de transparência metodológica na escrita histórica. Exemplos incluem discussões de consultas de dados, fluxos de trabalho com ferramentas específicas e a produção e interpretação de visualizações de dados. No mínimo, as publicações de pesquisa dos historiadores precisam de refletir novas prioridades que explicam o processo de interfacear, explorar e, em seguida, compreender as fontes históricas de uma forma fundamentalmente digital - ou seja, a hermenêutica dos dados”15 (tradução minha).
É fundamental criar um plano para organizar, documentar, preservar e compartilhar os dados, métodos e resultados da pequisa (ver a lição de James Baker). É necessário não apenas ficarmos atentos, mas também dedicar tempo no nosso cronograma de trabalho para uma reflexão em torno de:
- Metadados (como descrever os seus dados, tanto internamente quanto externamente)
- Documentação (uma descrição narrativa do projeto)
- Preservação (como os dados podem ser mantidos para uso no futuro)
Segundo Baker, é preciso produzir uma documentação “que capture de maneira precisa e consistente o conhecimento tácito em torno do processo de pesquisa”, que esse processo seja simplificado em “formatos de ficheiro e práticas de notação independentes da plataforma e legíveis por máquina.” Ao mesmo tempo é fundamental que isso seja inserido no fluxo de trabalho, para que não se torne uma tarefa exterior à pesquisa. Entendo que podemos enfrentar boa parte destes desafios utilizando programas de controlo de versões, como o Git.
Com o Git assumimos o controlo na produção de documentação precisa e consciente, produzida de forma integrada no desenvolvimento da pesquisa, gerando tanto metadados bem definidos quanto mensagens capazes de descrever a história do projeto.
Portanto, ao escrever uma mensagem de commit lembre-se que esta servirá como documentação do seu processo de pesquisa/escrita. Cada alteração ou conjunto de alterações realizada(s) nos ficheiros de seu diretório deve(m) ser acompanhada(s) de uma mensagem que registe as mudanças efetuadas. Essas informações são registadas pelo Git com um conjunto de metadados importantes para o acompanhamento metodológico de seu trabalho: nome do autor da mudança, data e hora, mensagem, e uma identificação única - um hash de 40 caracteres - que permite verificar a versão do ficheiro.
Como visto anteriormente, a melhor forma de escrever a mensagem de commit é utilizar o git commit sem a opção -m, pois permite escrever mensagens mais longas do que 50 caracteres (limite da opção -m) e incluir quebras de linha e um título na nossa mensagem. O git commit abre o editor de texto padrão do seu sistema operacional - ou o editor que configurou no Git - para que possa escrever a mensagem de commit.
Commits atómicos e boas práticas
Nesta lição, como estamos a entender os commits e os seus metadados como parte central no processo de documentação e transparência metodológica na pesquisa, devemos adotar medidas concientes de boas práticas. É importante que seja definido com clareza que padrão de mensagens será adotado e qual a frenquência dos commits. Assim, a sua pesquisa terá um conjunto coerente e estável de metadados e documentação padronizada, facilanto a sua recuperação, visualização, e possíveis correções necessárias.
Pode optar por padronizar as suas mensagens de commit contendo sempre um título e uma linha explicativa, padronizar se a mensagem será escrita em tópicos, se vai explicar os motivos das alterações ou apenas listá-los, etc.
Uma prática interessante que pode ajudar a definir o nosso método de trabalho são os commits atómicos. Estes consistem em um commit para cada mudança, a menor mudança possível, acompanhado de uma mensagem de apenas uma linha. Segundo Samuel-Zacharie Faure, esta prática favorece: a solução de problemas e a correção de erros inesperados com mais precisão, permitindo a reversão de commits no ponto exato; que o seu histórico do Git seja mais limpo e conciso; e que o seu fluxo de trabalho fique mais eficiente, pois permite trabalhar de forma atomizada, avançando passo-a-passo16.
Adotando ou não a prática de commits atómicos, o mais relevante é ter clareza e consciência de qual método e padrões de commit serão adotados em toda a pesquisa. Pessoalmente, sugiro que cada alteração ou, pelo menos, cada conjunto de alterações em um mesmo ficheiro seja submetida separadamente, com uma mensagem concisa, que evidencia à primeira leitura as mudanças efetuadas.
Manter um histórico do Git padronizado, seja ele atomizado ou mais prolixo, é muito importante tanto para a recuperação de informações (e sua visualização e compreensão) quanto para o trabalho colaborativo, revisões, e desdobramentos futuros da pesquisa.
Recuperar informações
Agora que aprendemos a criar um repositório local controlado pelo Git, a preparar e a submeter alterações em seu histórico, e a registar mensagens de documentação em cada uma das alterações, precisamos de aprender a recuperar esses dados.
Este processo é tão importante quanto o registo das mudanças. O Git permite visualizar todas as mudanças realizadas, com todos os dados associados a elas, e também possibilita retornar a um determinado ponto no passado dessa linha do tempo.
Isto é muito importante em, pelo menos, dois aspectos:
- É possível, com rapidez e transparência, ter acesso às informações do processo da pesquisa. Podemos visualizar toda a linha do tempo de mudanças, ler cada mensagem de commit, e saber quem realizou cada mudança e quando
- Podemos reverter mudanças e recuperar o projeto num ponto específico da sua história. Por exemplo, caso algum ficheiro tenha sido eliminado por engano ou alguma correção tenha sido perdida, é possível solicitar ao Git para retornar o seu repositório para um snapshot anterior específico
Git log
Os logs de commits do Git podem fornecer uma maneira altamente granular de rastrear e avaliar as contribuições de autores individuais para um projeto. Quando os projetos são rastreados usando o Git, cada ação (como adições, exclusões e alterações) é atribuída a um autor1 (tradução minha).
Para recuperarmos as informações submetidas no repositório local, podemos utilizar o comando git log. Este comando será muito útil para termos acesso às informações sobre o histórico de alterações em nossos ficheiros e para avaliarmos o progresso do trabalho.
~/Documentos/projeto-de-pesquisa$ git log
commit 59047209f8e53290b2226304a601d15a223af08e (HEAD -> main)
Author: Edward Palmer Thompson <epthompson@hist.com>
Date: Thu Jan 26 11:55:21 2023 +0000
Atualização dos dados da lição
- Inclusão do nome do Programming Historian no README.md
- Atualização do texto em resumos.txt
commit 29ffe5182a8ace0b863392cf23072f5b15db4061
Author: Edward Palmer Thompson <epthompson@hist.com>
Date: Thu Jan 26 11:52:50 2023 +0000
Criação do ficheiro para o resumo do tutorial
commit d3fc9068bd0dd9b3d7c6c464e3db08a6f15c268d
Author: Edward Palmer Thompson <epthompson@hist.com>
Date: Thu Jan 26 11:49:25 2023 +0000
Criação de README.md
Este commit cria o ficheiro README.md com o objetivo de explicar o funcionamento do Git.
Podemos perceber que o git log retorna a lista de commits realizados no repositório local. Os nossos três commits estão detalhados com várias informações importantes. A primeira coisa a destacar é que os commits são listados do mais recente para o mais antigo. Assim, o último commit realizado é o primeiro da lista. Vamos analisá-lo com mais atenção.
Na primeira linha, temos a seguinte informação:
commit 59047209f8e53290b2226304a601d15a223af08e (HEAD -> main)
Encontramos o número de identificação do commit com 40 caracteres (hash). Não se assuste, não há necessidade de ler esse número nem entender como é gerado para utilizar o Git. O importante é saber que cada commit possui um identificador único, possibilitando o seu acesso e recuperação dentro do banco de dados do sistema de controlo de versões. Na verdade, é possível utilizar os sete primeiros caracteres para encontrar e referenciar commits específicos. Por exemplo, este commit pode ser identificado por 5904720 e o Git será capaz de encontrá-lo. A importância desta identificação única para cada alteração reside, justamente, na possibilidade de se ter acesso a cada mudança a qualquer momento e, inclusive, recuperar o repositório na condição em que se encontrava naquele momento no tempo.
A informação que se segue também é importante, mas fará mais sentido na parte dois desta lição. (HEAD -> main) indica que o commit mais recente aponta para o ramo main. Ou seja, atualmente está a trabalhar em uma linha do tempo chamada main, e todas as mudanças que realizar incidirão sobre ela. Na parte dois da lição veremos que é possível criar outras linhas de trabalho ou ramificações, assim como criar alterações nos ficheiros e não afetar as informações contidas em outros ramos.
Nas duas linhas seguintes, temos a autoria e a data do commit:
Author: Edward Palmer Thompson <epthompson@hist.com>
Date: Thu Jan 26 11:55:21 2023 +0000
Os dados do autor - nome e email - são retirados da configuração que realizámos no início da lição com o comado git config --global user.name e git config --global user.mail. A data e a hora estão no padrão do Git, mas também podem ser configuradas.17
Em seguida, podemos ler a mensagem do commit, sendo a primeira linha entendida pelo Git como o seu título:
Atualização dos dados da lição
- Inclusão do nome do Programming Historian no README.md
- Atualização do texto em resumos.txt
O comando git log possui várias opções que são úteis para acompanharmos e recuperarmos dados sobre o processo metodológico do nosso trabalho. Abaixo veremos algumas, mas a lista completa pode ser acessada na página de documentação do Git.
Podemos ver todos os commits listados em apenas uma linha, acrescentando a opção --oneline ao comando git log, o que pode ser útil para uma leitura mais rápida e concisa das alterações:
~/Documentos/projeto-de-pesquisa$ git log --oneline
5904720 (HEAD -> main) Atualização dos dados da lição
29ffe51 Criação do ficheiro para o resumo do tutorial
d3fc906 Criação de README.md
Com essa opção, a lista de commits, do atual ao mais antigo, apresenta os sete caracteres iniciais da identificação e o título da mensagem.
Também é possível aceder a um commit específico dessa lista, informando os sete caracteres iniciais:
~/Documentos/projeto-de-pesquisa$ git log d3fc906
commit d3fc9068bd0dd9b3d7c6c464e3db08a6f15c268d
Author: Edward Palmer Thompson <epthompson@hist.com>
Date: Thu Jan 26 11:49:25 2023 +0000
Criação de README.md
Este commit cria o ficheiro README.md com o objetivo de explicar o funcionamento do Git.
Ainda utilizando o comando git log, também é possível formatar as informações que aparecem na tela. Podemos realizar esta configuração incluindo a opção --pretty=format e formatar a saída do git log para visualizarmos a hash, o autor, a data e o título do commit em uma única linha. Para isso, o comando seria o seguinte:
~/Documentos/projeto-de-pesquisa$ git log --pretty=format:"%h,%an,%ad,%s"
Ou seja, solicitei que o Git apresentasse o log, mas que o formatasse com a opção --pretty. Para tanto, passamos a opção format e passamos uma string - entre aspas duplas - com as informações que desejamos. No exemplo, a string é composta por %h, que representa a hash do commit, %an, que representa o autor do commit, %ad, que representa a data do commit no formato padrão do Git, e %s, que representa o título do commit.
O resultado foi o seguinte:
5904720,Edward Palmer Thompson,Thu Jan 26 11:55:21 2023 +0000,Atualização dos dados da lição
29ffe51,Edward Palmer Thompson,Thu Jan 26 11:52:50 2023 +0000,Criação do ficheiro para o resumo do tutorial
d3fc906,Edward Palmer Thompson,Thu Jan 26 11:49:25 2023 +0000,Criação de README.md
Existem muitas outras opções de formatação que pode ver na página de documentação do Git. Segue uma tabela com algumas delas:
| Formato | Descrição |
|---|---|
| %H | hash do commit |
| %h | abreviação do hash do commit |
| %an | nome do autor |
| %ae | email do autor |
| %al | parte local do email do autor (a parte antes do sinal @) |
| %ad | data do autor (o formato respeita a opção –date=) |
| %aD | data do autor, no padrão RFC2822 |
| %as | data do autor, formato curto (AAAA-MM-DD) |
| %s | assunto |
| %f | linha do assunto higienizado, adequado para um nome de ficheiro |
| %b | corpo |
Com estas informações, podemos criar, por exemplo, um ficheiro tabular com todos os dados de um projeto, registando de forma explícita e organizada o histórico de alterações, os seus responsáveis, as datas e o conteúdo das mensagens. Assim, com apenas uma linha de comando podemos salvar uma tabela contendo todas as informações necessárias para a gestão do projeto, recuperação de dados, e documentação eficiente e transparente.
~/Documentos/projeto-de-pesquisa$ git log --pretty=format:"%h,%an,%ad,'%s','%b'" > log.csv
O comando acima cria um ficheiro chamado log no formato csv com as seguintes informações separadas por vírgulas:
- hash abreviada do commit - %h
- nome do autor - %an
- data do commit - %ad
- título do commit - %s
- conteúdo da mensagem do commit - %b
Perceba que no comando coloquei os últimos dois elementos entre aspas simples, o que serve como um delimitador do texto que será retornado. Ou seja, possíveis vírgulas presentes no título ou no corpo da mensagem não serão entendidas como separadores de uma nova coluna por programas de dados tabulares. Para que esse padrão funcione bem, é preciso lembrar de não incluir aspas simples nos títulos ou mensagens de commits. Esta é uma dica específica para quem deseja gerar ficheiros csv a partir do seu histórico. Por isso, é importante refletir previamente sobre os processos de documentação de seu projeto.
Podemos visualizar o conteúdo do ficheiro log.csv em qualquer software de dados tabulares. Abaixo temos um exemplo de como ficaria o ficheiro:
| hash abreviada do commit | nome do autor | data do commit | título do commit | conteúdo da mensagem do commit |
|---|---|---|---|---|
| 5904720 | Edward Palmer Thompson | Thu Jan 26 11:55:21 2023 +0000 | ‘Atualização dos dados da lição’ | ’- Inclusão do nome do Programming Historian no README.md - Atualização do texto em resumos.txt |
| 29ffe51 | Edward Palmer Thompson | Thu Jan 26 11:52:50 2023 +0000 | ‘Criação do ficheiro para o resumo do tutorial’ | |
| d3fc906 | Edward Palmer Thompson | Thu Jan 26 11:49:25 2023 +0000 | ‘Criação de README.md’ | ‘Este commit cria o ficheiro README.md com o objetivo de explicar o funcionamento do Git. |
Não se esqueça de preparar e submeter as alterações deste novo ficheiro em seu repositório local!
~/Documentos/projeto-de-pesquisa$ git add log.csv
~/Documentos/projeto-de-pesquisa$ git commit -m "Criação do fiheiro log.csv"
[main 7e55f5b] Criação do ficheiro log.csv
1 file changed, 6 insertions(+)
create mode 100644 log.csv
Considerações finais
Com o uso disciplinado do Git, cientistas e laboratórios podem garantir que toda a linha do tempo dos eventos que ocorrem durante o desenvolvimento de um projeto de pesquisa é registada de forma segura em um sistema que oferece segurança contra a perda de dados e incentiva a exploração sem riscos de novas ideias e abordagens1 (tradução minha).
O uso consciente e sistemático do Git, apesar de sua curva de aprendizagem mais acentuada, permite que pesquisadores e equipes possam trabalhar de forma segura e controlada, integrando no processo de pesquisa/escrita os procedimentos metodológicos de documentação e registo de metadados e decisões tomadas. Ao mesmo tempo, garante a criação de uma linha do tempo de todo o processo, permitindo a recuperação das informações e o restauro de ficheiros.
Entendo que, com o Git, no dia a dia de uma pesquisa, ganhamos tempo e tranquilidade para documentar, preservar e recuperar informações, assim como para apresentar, em qualquer momento e de forma transparente, todas as nossas decisões e escolhas.
Na segunda parte dessa lição, procuro apresentar o fluxo de trabalho em múltiplos ramos, as possibilidades de reverter as mudanças de um repositório, a configuração do .gitignore, e o trabalho com repositórios remotos, hospedados em plataformas como o GitHub. Estas outras características do Git são muito úteis para o trabalho com equipes variadas, para a difusão das pesquisa e colaboração entre diferentes pesquisadores.
Agradecimentos
Essa lição não seria possível sem os workshops, webinars, pesquisas e debates realizados no LABHD-UFBA, no Lab_HD da Universidade Nova de Lisboa (IHC, NOVA FCSH/IN2PAST), e no Laboratório de Humanidades Digitais da FGV-CPDOC. E, portanto, agradeço pelo espaço e parceria.
Leituras adicionais
Baker, James, “Preservar os seus dados de investigação”, traduzido por Márcia T. Cavalcanti, Programming Historian em português, 2021, https://doi.org/10.46430/phpt0001.
Brasil, Eric. “Criação, manutenção e divulgação de projetos de História em meios digitais: git, GitHub e o Programming Historian”. Apresentação. Zenodo, 2022. https://doi.org/10.5281/zenodo.6566754.
Loeliger, Jon, e Matthew McCullough. Version Control with Git: Powerful tools and techniques for collaborative software development. 2º edição. Sebastopol, CA: O’Reilly Media, 2012.
-
Ram, Karthik. “Git can facilitate greater reproducibility and increased transparency in science”. Source Code for Biology and Medicine, 8, nº 1, 2013: 7. https://doi.org/10.1186/1751-0473-8-7. ↩ ↩2 ↩3 ↩4 ↩5
-
Guerrero-Higueras, Ángel Manuel, Camino Fernández Llamas, Lidia Sánchez González, Alexis Gutierrez Fernández, Gonzalo Esteban Costales, e Miguel Ángel Conde González. “Academic Success Assessment through Version Control Systems”. Applied Sciences 10, nº 4 (janeiro de 2020): 1492. https://doi.org/10.3390/app10041492. ↩
-
Chacon, Scott, e Ben Straub. Pro Git. 2º edição. New York: Apress, 2014. ↩ ↩2 ↩3
-
Linus Torvald é o criador e desenvolvedor do Kernel Linux, bem como o criador do Git. ↩
-
Bryan, Jennifer. “Excuse Me, Do You Have a Moment to Talk About Version Control?” The American Statistician 72, nº 1, 2018: 20–27. https://doi.org/10.1080/00031305.2017.1399928. ↩
-
Kim, Youngtaek, Jaeyoung Kim, Hyeon Jeon, Young-Ho Kim, Hyunjoo Song, Bohyoung Kim, e Jinwook Seo. “Githru: Visual Analytics for Understanding Software Development History Through Git Metadata Analysis”. IEEE Transactions on Visualization and Computer Graphics 27, nº 2 (fevereiro de 2021): 656–66. https://doi.org/10.1109/TVCG.2020.3030414. ↩
-
O GitHub é uma plataforma de hospedagem de repositórios Git, que permite a colaboração entre pesquisadores e a publicação de projetos de pesquisa, entre diversas outras funcionalidades que serão abordadas na parte dois desta lição. Para saber mais, veja a documentação. ↩
-
Editor de texto altamente configurável, comumente pré-instalado em sistemas Unix e MacOs. Veja a documentação aqui (em inglês). ↩ ↩2
-
Falaremos mais detalhadamente sobre branches (em português, ramos) e respetivo fluxo de trabalho na parte dois desta lição. ↩
-
Seguindo debates públicos recentes, em 2020, o GitHub alterou o padrão de nomeação do ramo principal de
masterparamain. A questão também está a ser discutida no projeto Git, como pode ser visto aqui (em inglês). ↩ -
Para abrir o seu emulador de terminal padrão em distribuições Linux, basta clicar em
Super+te, no MacOs, basta clicar no Launchpad e procurar o “Terminal”. ↩ -
Pode ter acesso através do comando
git config --global --edit. ↩ -
É uma ferramente Unix que permite imprimir texto numa determinada saída. Aqui, utilizamos para inserir texto dentro de um ficheiro. Para mais informações ver a documentação (em inglês). ↩
-
Uma vez que a tradução do Git é feita pela comunidade, a versão portuguesa remete para o português do Brasil (pt_BR) não existindo, até ao momento, uma versão em português de Portugal (pt_PT). Esta ainda apresenta trechos em inglês, o que pode gerar problemas de compreensão. Nesta lição utilizámos o padrão do Git existente para pt_BR. ↩
-
Gibbs, Fred, e Trevor Owens. “The Hermeneutics of Data and Historical Writing”. Em Writing History in the Digital Age, 159–70. Ann Arbor, MI: University of Michigan Press, 2013. ↩
-
Faure, Samuel-Zacharie. “How Atomic Git Commits Dramatically Increased My Productivity - and Will Increase Yours Too”. DEV Community, 7 de março de 2023. https://dev.to/samuelfaure/how-atomic-git-commits-dramatically-increased-my-productivity-and-will-increase-yours-too-4a84. Acesso em: 9 ago. 2023. ↩
-
É possível configurar o modelo de apresentação da data e hora no Git. Para saber mais veja esta documentação (em inglês) ou esta explicação no StackOverflow (em inglês). ↩