
Contenidos
- Objetivos de la lección
- Prerrequisitos
- Introducción
- Buscar colecciones digitales para su reutilización
- Extracción y visualización de datos
- Crear mapas a partir de Linked Open Data
- Discusión
- Conclusiones
- Glosario
- Notas
Objetivos de la lección
Esta lección muestra cómo reutilizar colecciones digitales publicadas por instituciones de patrimonio cultural y tiene como objetivos principales los siguientes:
- Conocer qué es un Lab en el marco de una institución GLAM
- Reutilizar de forma innovadora y creativa colecciones digitales
- Enriquecer los datos a través de diferentes técnicas
Prerrequisitos
En esta lección asumimos que tienes cierto conocimiento sobre Python. Si conoces otro lenguaje de programación también te será útil. Si necesitas un lugar donde empezar, te recomendamos trabajar con los excelentes tutoriales sobre Python con los que cuenta Programming Historian en español. También necesitarás conocimientos sobre Jupyter Notebooks, para ello te recomendamos la lección Introduction to Jupyter Notebooks. Además, para los ejemplos de reutilización, será necesario tener algunos conocimientos sobre MARCXML, Linked Open Data y SPARQL; para esto te recomendamos la lección de datos abiertos enlazados.
Introducción
Tradicionalmente las instituciones de patrimonio cultural conocidas como GLAM (del inglés, Galleries, Libraries, Archives and Museums) han publicado colecciones digitales que incluyen todo tipo de materiales con el objetivo de facilitar a la sociedad el acceso a la información. El avance de las tecnologías ha favorecido un nuevo contexto en el que las colecciones digitales pueden ser utilizadas en investigación por medio de diferentes métodos, como visión por computador o técnicas de aprendizaje automático. Actualmente, las instituciones GLAM promueven e incentivan la reutilización de sus colecciones digitales a través de programas de colaboración directa con investigadores pero también con empresas e instituciones académicas.
Las instituciones de patrimonio cultural han comenzado a experimentar de forma creativa e innovadora con las colecciones digitales, que tradicionalmente han puesto a disposición del público, lo que ha favorecido la creación de nuevos espacios en el seno de las instituciones, conocidos como “Labs”. Uno de los primeros, líder en este ámbito, y que ha establecido las bases para el resto, es el de la Biblioteca Británica, financiado por la Mellon Foundation. Como resultado de dos encuentros de carácter internacional en la sede de la Biblioteca Británica y en la Biblioteca Real de Dinamarca, en Copenhague, se creó la Comunidad Internacional GLAM Labs compuesta por numerosas instituciones, que se muestran en la Figura 1.
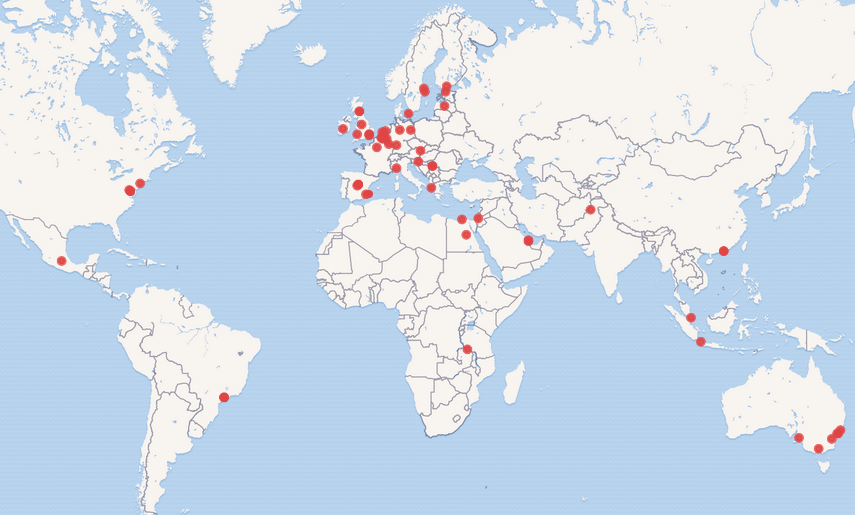
Mapa que representa las instituciones de la Comunidad Internacional GLAM Labs
En septiembre de 2019, dieciséis personas pertenecientes a dicha comunidad se reunieron en Doha, Catar, para escribir, a partir de la metodología Book Sprint, el libro Open a GLAM Lab que actualmente ha sido traducido a diversos idiomas, entre ellos español y árabe.
Una colección digital publicada por una institución GLAM puede estar formada por cualquier tipo de contenido incluyendo metadatos, textos, imágenes, mapas, videos o audios. En este sentido, reutilizar una colección digital consiste en analizar el contenido para adquirir nuevo conocimiento. El análisis puede constar de fases tales como extracción, transformación y enriquecimiento. Como resultado podemos obtener una nueva colección descrita con otro vocabulario más expresivo y rico, una visualización que facilite el descubrimiento de conocimiento, o una agregación de diferentes colecciones digitales basadas en un tema específico.
A la hora de reutilizar una colección digital existen diferentes aspectos que deben ser tenidos en cuenta, como por ejemplo la licencia o el tipo de material. Las instituciones han comenzado a utilizar licencias abiertas, pero en algunos casos la licencia no es evidente, lo que impide su reutilización. Dependiendo del método de investigación a aplicar será necesario un tipo específico de material. Por ejemplo, si deseamos realizar reconocimiento de formas necesitaremos un repositorio que se base en imágenes.
Recientemente se publicó el estudio Collections as data, que proporciona un nuevo enfoque para publicar las colecciones digitales que facilitan el procesamiento por parte de las computadoras. Por ejemplo, es posible utilizar un corpus de miles de textos para identificar personas o lugares de forma automática. Las computadoras permiten la aplicación de métodos de investigación en Humanidades Digitales como minería de textos, visualización de datos o el uso de Sistemas de Información Geográfica (SIG), como también procesamiento de lenguaje natural, inteligencia artificial y visión por computador.
La combinación de las colecciones digitales proporcionadas por las instituciones GLAM, junto a código y narrativa, proporcionan el marco ideal para la reproducción de los resultados de investigación. En este sentido, los Jupyter Notebooks permiten integrar estos tres elementos y se han convertido en un recurso muy popular tanto en la comunidad investigadora como en la educativa. Numerosos proyectos se centran en la publicación de colecciones de notebooks, como por ejemplo GLAM Workbench o GLAM Jupyter Notebooks. Los Labs favorecen un espacio para poner de manifiesto estas nuevas tendencias para mejorar y mantener la relevancia de las instituciones de patrimonio cultural.
En esta lección se incluyen varias opciones para localizar colecciones digitales publicadas por instituciones GLAM para su reutilización. A continuación, se introducen dos ejemplos implementados como Jupyter Notebooks que muestran de forma reproducible cómo reutilizar las colecciones digitales a través de diferentes técnicas que se encuentran disponibles en Zenodo1. El último apartado corresponde a las conclusiones.
Buscar colecciones digitales para su reutilización
Actualmente existen numerosos sitios web donde es posible localizar colecciones digitales para su reutilización. Muchos de ellos corresponden al espacio Lab dentro de una institución GLAM. En otros casos, la colección digital se puede localizar en plataformas como Zenodo que permite la publicación de datasets. La siguiente tabla proporciona un resumen de instituciones GLAM, donde podemos localizar sus colecciones digitales con licencias abiertas para su reutilización.
| Institución | Colección | URL |
|---|---|---|
| Bibliotèque Nationale de France | BnF API et jeux de données | http://api.bnf.fr/ |
| Bibliothèque Nationale du Luxembourg | BnL Open Data | https://data.bnl.lu/ |
| British Library | BL Labs | [temporalmente no disponible] |
| Biblioteca Virtual Miguel de Cervantes | BVMC Labs | http://data.cervantesvirtual.com/blog/labs |
| Det Kgl. Bibliotek | KB Labs | https://labs.kb.dk/ |
| Europeana | Europeana IIIF APIs | https://pro.europeana.eu/page/iiif |
| History Trust of South Australia | Learn section | https://history.sa.gov.au/ |
| National Library of Netherlands | KB Lab | https://lab.kb.nl/ |
| National Library of Scotland | Data Foundry | https://data.nls.uk/ |
| Library of Congress | LC Labs | https://labs.loc.gov/data-for-exploration |
| Österreichische Nationalbibliothek | ONB Labs | https://labs.onb.ac.at/en/ |
| Staatsbibliothek zu Berlin | SBB Labs | https://lab.sbb.berlin/ |
| State Library New South Wales | DX Lab | https://dxlab.sl.nsw.gov.au |
Las instituciones GLAM publican colecciones digitales en diferentes formatos. Tradicionalmente han publicado diversos tipos de materiales como imágenes, textos y mapas. Recientemente, han aparecido nuevas formas de publicación que utilizan tecnologías basadas en la Web Semántica. Estas técnicas permiten el enriquecimiento con repositorios externos a partir de la creación de enlaces. Wikidata se ha convertido en un repositorio muy popular en el ámbito de las instituciones GLAM y muchas de ellas ya disponen de propiedades específicas para enlazar sus recursos como autores y obras. Por ejemplo, la Biblioteca Virtual Miguel de Cervantes dispone de la propiedad P2799 para enlazar autores desde su repositorio de datos abiertos hacia Wikidata.
Extracción y visualización de datos
Para este ejemplo vamos a utilizar la colección Moving Image Archive proporcionada por el Data Foundry de la Biblioteca Nacional de Escocia, publicada bajo dominio público y que contiene alrededor de 6.000 registros descritos con el estándar MARC 21 XML. Esta colección contiene información sobre imágenes en movimiento como vídeos, películas y documentales, que están relacionadas con Escocia y que fueron creadas por aficionados o profesionales. Este ejemplo está disponible en Zenodo y puede ser ejecutado en MyBinder.
Para poder procesar de forma sencilla la colección digital vamos a cambiar de MARCXML a un formato más sencillo de manipular como el CSV. Posteriormente, haciendo uso de varias librerías, es posible identificar y obtener un listado de los temas, favoreciendo así el descubrimiento de nuevo conocimiento.
En primer lugar, importamos las librerías que vamos a necesitar para trabajar con la colección, incluyendo librerías para el manejo de MARC2, CSV, expresiones regulares, visualización y empaquetado de datos. El uso de Binder nos facilita la ejecución sin necesidad de instalar ningún software; sin embargo, si deseamos ejecutar la colección de Jupyter Notebooks en nuestro ordenador es necesario instalar cada librería mediante el comando pip (por ejemplo, pip install pymarc). Si quieres conocer más detalles sobre este comando, te recomendamos la lección instalar módulos de Python con pip.
# importamos las librerías
# pymarc
import pymarc, re, csv
import pandas as pd
from pymarc import parse_xml_to_array
Después, creamos un fichero CSV con el contenido de la colección descrito en MARCXML y que previamente hemos descargado. El fichero CSV debe incluir la cabecera con los campos que vamos a extraer.
with open('registros_marc.csv', 'w') as csv_fichero:
csv_salida = csv.writer(csv_fichero, delimiter = ',', quotechar = '"', quoting = csv.QUOTE_MINIMAL)
csv_salida.writerow(['titulo', 'autor', 'lugar_produccion', 'fecha', 'extension', 'creditos', 'materias', 'resumen', 'detalles', 'enlace'])
A continuación, comenzamos a extraer la información del fichero MARCXML. El formato MARC21 facilita la descripción de los registros bibliográficos, estructurándolos en campos (que identifica mediante números) y subcampos (que identifica por caracteres). Por ejemplo, el campo 245 $a corresponde al título principal de una obra y el campo 100 $a representa su autor principal. Como se observa en el siguiente fragmento de código, mediante la librería pymarc recorremos los registros y localizamos los campos que deseamos recuperar mediante sus identificadores para generar y almacenar el resultado en el fichero CSV.
registros = parse_xml_to_array(open('Moving-Image-Archive/Moving-Image-Archive-dataset-MARC.xml'))
for registro in registros:
titulo = autor = lugar_produccion = fecha = extension = creditos = materias = resumen = detalles = enlace =''
# título
if registro['245'] is not None:
titulo = registro['245']['a']
if registro['245']['b'] is not None:
titulo = titulo + " " + registro['245']['b']
# autor
if registro['100'] is not None:
autor = registro['100']['a']
elif registro['110'] is not None:
autor = registro['110']['a']
elif registro['700'] is not None:
autor = registro['700']['a']
elif registro['710'] is not None:
autor = registro['710']['a']
# lugar de producción
if registro['264'] is not None:
lugar_produccion = registro['264']['a']
# fecha
for f in registro.get_fields('264'):
fechas = f.get_subfields('c')
if len(fechas):
fecha = fechas[0]
if fecha.endswith('.'): fecha = fecha[:-1]
# descripción física - extensión
for f in registro.get_fields('300'):
extension = f.get_subfields('a')
if len(extension):
extension = extension[0]
# TODO cleaning
detalles = f.get_subfields('b')
if len(detalles):
detalles = detalles[0]
# créditos
if registro['508'] is not None:
creditos = registro['508']['a']
# resumen
if registro['520'] is not None:
resumen = registro['520']['a']
# materias
if registro['653'] is not None:
materias = ''
for f in registro.get_fields('653'):
materias += f.get_subfields('a')[0] + ' -- '
materias = re.sub(' -- $', '', materias)
# enlace
if registro['856'] is not None:
enlace = registro['856']['u']
csv_salida.writerow([titulo,autor,lugar_produccion,fecha,extension,creditos,materias,resumen,detalles,enlace])
Una vez que ya hemos generado el fichero CSV, podemos cargarlo mediante la librería Pandas3, que permite cargar y manipular datos tabulados por medio de su estructura básica: el DataFrame.
# Este comando añade el contenido del fichero a un Pandas DataFrame
df = pd.read_csv('registros_marc.csv')
Para ver el contenido del DataFrame debemos mostrar la variable df, como se ilustra en la Figura 2. También podemos comprobar las columnas existentes, así como el número de registros.
df
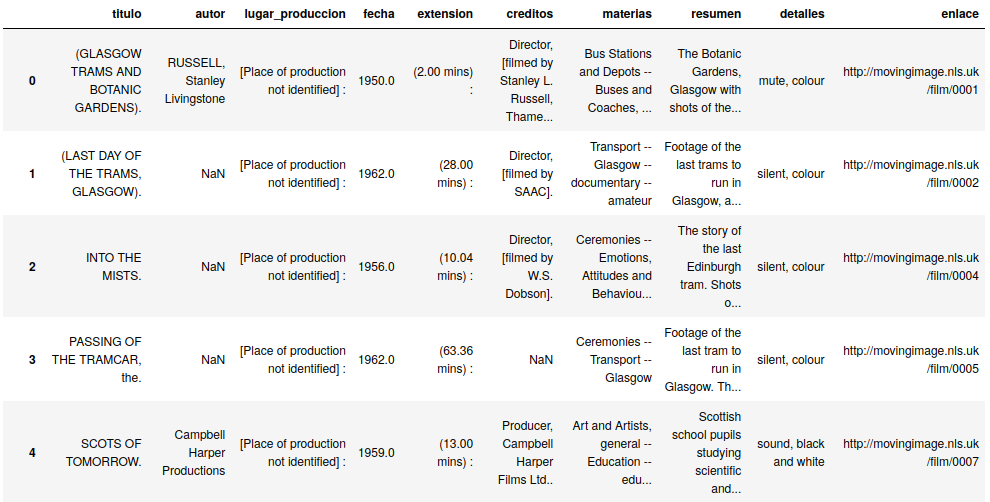
Primeras cinco filas del contenido del DataFrame
También podemos mostrar las columnas que tiene nuestro fichero CSV con el método df.columns, como se observa en la Figura 3. Para obtener el número de registros en nuestro DataFrame ejecutamos el comando len(df).
df.columns

Nombres de las columnas incluidas en el DataFrame
Pandas permite la manipulación y visualización del DataFrame de diferentes formas. Por ejemplo, podemos identificar la lista de materias (corresponde a la columna materias) y ordenarla alfabéticamente.
Cada registro contiene el metadato materia que consiste en un listado de elementos separados por dos guiones. Por ejemplo, Ceremonies -- Emotions, Attitudes and Behaviour -- Local Government -- Transport -- Edinburgh -- amateur. Pandas permite dividir este tipo de cadenas para tratar los elementos individuales mediante el comando split, que recibe como parámetros el carácter a usar para dividir la cadena de texto y mediante la opción expand=True crea una nueva columna para cada elemento. El método stack, por su parte, permite convertir las columnas a un índice. El resto de código ordena alfabéticamente los elementos, como se puede observar en la Figura 4.
# Obtener valores únicos
materias = pd.unique(df['materias'].str.split(' -- ', expand=True).stack()).tolist()
for materia in sorted(materias, key=str.lower):
print(materia)

Listado de materias ordenadas alfabéticamente
Con el objetivo de demostrar que el código se puede adaptar y modificar a otras colecciones digitales, se ha incluido un ejemplo adicional basado en la Bibliografía Española de Cartografía de la Biblioteca Nacional de España, que incluye mapas, planos, cartas náuticas, atlas, etcétera, tanto en formato impreso como electrónico. Tras el análisis de las materias se obtiene que la mayoría de los registros tratan sobre mapas, excursionismo, carreteras, senderismo, planos y comercio.
De forma adicional y para quienes quieran profundizar en la reutilización de estas dos colecciones, los ejemplos proporcionan la documentación necesaria para identificar y visualizar la frecuencia de tópicos, lo que puede ser interesante para una primera exploración de los metadatos. Para realizar el proceso completo es necesario consultar los Jupyter Notebooks dedicados a estos dos ejemplos que se encuentran en Zenodo y que se pueden ejecutar en Binder.
Crear mapas a partir de Linked Open Data
Para el segundo ejemplo nos vamos a basar en un repositorio creado mediante tecnologías avanzadas, como Linked Open Data. Puedes consultar más información sobre Linked Open Data y SPARQL en la lección de datos abiertos enlazados.
La plataforma BNB Linked Data provee acceso a la British National Bibliography (BNB) como Linked Open Data proporcionando acceso a través de SPARQL. Este ejemplo se basa en la recuperación de localizaciones geográficas relacionadas con las obras de un autor. La localización corresponde al lugar de publicación original de una obra en particular. Una vez recuperadas las localizaciones, y gracias a que los datos están enlazados a GeoNames, es posible obtener información adicional sobre esa localización, como por ejemplo la latitud y longitud, que nos servirá para representarla en un mapa.
En este sentido, este ejemplo pretende introducir los pasos necesarios para reutilizar una colección digital publicada, siguiendo los principios de Linked Open Data que facilitan el establecimiento de enlaces a repositorios externos. Los repositorios semánticos publicados por instituciones GLAM son una fuente de información de gran valor que se encuentran a disposición de los investigadores sin ningún tipo de restricción para su uso. Sin embargo, su reutilización no es sencilla ya que requiere conocimientos avanzados en tecnologías como RDF (del inglés Resource Description Framework) o SPARQL para poder realizar las consultas.
Este ejemplo utiliza los metadatos del repositorio que indican localizaciones, como por ejemplo las propiedades blt:publication y blt:projectedPublication que indican lugares de publicación. Gracias a que los registros están enlazados a GeoNames, vamos a poder acceder a Wikidata para recuperar las coordenadas geográficas de las localizaciones y mostrar los beneficios de Linked Open Data. El vocabulario utilizado por BNB Linked Data es Bibliographic Ontology (BIBO) que es un vocabulario sencillo que permite describir los metadatos de un repositorio bibliográfico.
En primer lugar, importamos las librerías necesarias para procesar esta colección: folium4 para visualizar información geográfica en un mapa; csv y json para el procesamiento de los formatos de entrada y salida; request para la realización de peticiones HTTP; pandas para la gestión de datos tabulares con columnas de tipo heterogéneo y matplotlib5 para la creación de gráficas.
import folium
import requests
import pandas as pd
import json
import csv
import matplotlib.pyplot as plt
from pandas.io.json import json_normalize
A continuación, vemos un ejemplo de consulta SPARQL que recupera las obras publicadas en un lugar en concreto: “York”. Las sentencias SPARQL de este apartado las podemos ejecutar en el punto de acceso SPARQL, como se observa en la Figura 5.
SELECT ?libro ?isbn ?titulo WHERE {
?lugar rdfs:label "York" .
?publicacion event:place ?lugar.
?libro blt:publication ?publicacion;
bibo:isbn10 ?isbn;
dct:title ?titulo.
}
LIMIT 50
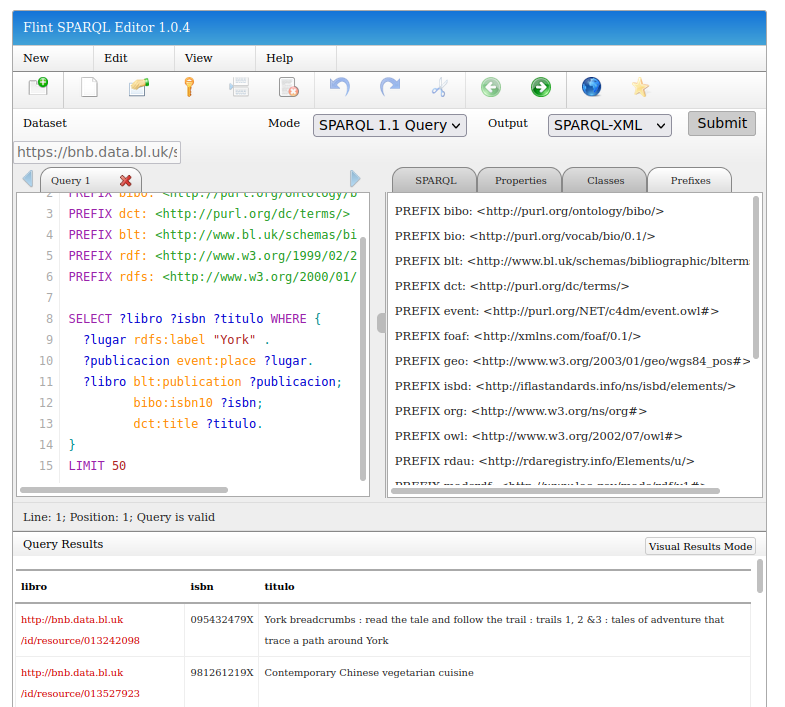
Punto de acceso SPARQL para la plataforma BNB Linked Data
En el modelo de la plataforma BNB Linked Data, un recurso de tipo publicación contiene una propiedad c4dm:place que enlaza a GeoNames en alrededor de cuatro millones de registros (un 50% del catálogo completo). Sin embargo, el resultado de la sentencia SPARQL anterior no proporciona las coordenadas geográficas, a pesar de que algunos datos se encuentren enlazados a GeoNames.
Con la siguiente sentencia SPARQL recuperamos las obras relacionadas con el autor Miguel de Cervantes Saavedra que tienen un lugar de publicación y que además este está enlazado a GeoNames. En este caso, la variable ?p que se usa en la tripleta que filtra los resultados del autor puede ser cualquier rol, como por ejemplo colaborador, creador o autor en el caso de la BNB. En este sentido, podría ser interesante filtrar por un rol en concreto para obtener resultados más específicos.
PREFIX blt: <http://www.bl.uk/schemas/bibliographic/blterms#>
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX schema: <http://schema.org/>
PREFIX c4dm: <http://purl.org/NET/c4dm/event.owl#>
SELECT DISTINCT ?resource ?title ?date ?place WHERE {
?recurso ?p <http://bnb.data.bl.uk/id/person/CervantesSaavedraMiguelde1547-1616> ;
dct:title ?titulo ;
schema:datePublished ?fecha .
?recurso blt:publication ?publicacion .
?publicacion c4dm:place ?lugar .
FILTER regex(?lugar, "geonames", "i")
} LIMIT 500
Para poder ejecutar esta sentencia SPARQL en Python, necesitamos especificar el punto de acceso SPARQL y la sentencia SPARQL a ejecutar:
url = 'https://bnb.data.bl.uk/sparql'
sentencia = """
PREFIX blt: <http://www.bl.uk/schemas/bibliographic/blterms#>
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX schema: <http://schema.org/>
PREFIX c4dm: <http://purl.org/NET/c4dm/event.owl#>
SELECT DISTINCT ?recurso ?titulo ?fecha ?lugar WHERE {
?recurso ?p <http://bnb.data.bl.uk/id/person/CervantesSaavedraMiguelde1547-1616> ;
dct:title ?titulo ;
schema:datePublished ?fecha .
?recurso blt:publication ?publicacion .
?publicacion c4dm:place ?lugar .
FILTER regex(?lugar, "geonames", "i")
} LIMIT 500
"""
A continuación, recuperamos el resultado mediante la configuración de la cabecera de la petición para que devuelva un objeto JSON. La Figura 6 muestra un ejemplo del resultado de la petición.
cabeceras = {'Accept': 'application/sparql-results+json'}
r = requests.get(url, params = {'format': 'application/sparql-results+json', 'query': sentencia}, headers=cabeceras)
print(r.text)

Resultados de la petición a la plataforma BNB Linked Data
Y almacenamos el resultado en un fichero CSV más sencillo de manipular. En primer lugar cargamos en un objeto JSON el resultado obtenido.
bnbdatos = json.loads(r.text)
Después creamos el fichero CSV y volcamos el contenido del objeto JSON a este fichero. Para ello, recorreremos cada ítem del listado de resultados dentro del objeto JSON con la variable bnbdatos y accederemos a los atributos ['results']['bindings']. Cada propiedad tiene un atributo value que contiene el valor que necesitamos recuperar.
with open('bnb_registros.csv', 'w', newline='') as file:
csv_salida = csv.writer(file, delimiter = ',', quotechar = '"', quoting = csv.QUOTE_MINIMAL)
csv_salida.writerow(['recurso', 'lugar', 'titulo', 'fecha'])
for i in bnbdatos['results']['bindings']:
recurso = place = title = date =''
recurso = i['recurso']['value']
lugar = i['lugar']['value']
titulo = i['titulo']['value']
fecha = i['fecha']['value']
csv_salida.writerow([recurso,lugar,titulo,fecha])
Una vez que tenemos creado el fichero CSV, podemos cargarlo en un objeto DataFrame de Pandas que nos facilita el análisis y tratamiento. La Figura 7 muestra el DataFrame con las filas y columnas.
df = pd.read_csv('bnb_registros.csv')
df
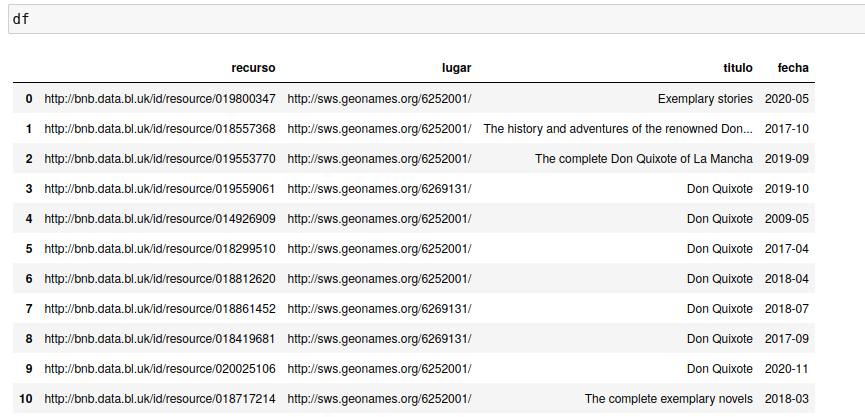
Visualización del objeto DataFrame con los resultados
A continuación, podemos analizar cuántos enlaces diferentes tenemos a GeoNames en el listado de resultados. Pandas permite acceder a las columnas del objeto DataFrame mediante el operador groupby. En este ejemplo agrupamos por la columna lugar de publicación (lugar) y en la segunda posición marcamos la columna que queremos utilizar para realizar la agregación, en este caso, la obra (recurso). La Figura 8 muestra el resultado.
lugares_por_recurso = df.groupby("lugar")["recurso"].count()
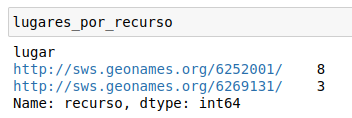
Enlaces a GeoNames en el listado de resultados
La plataforma BNB Linked Data proporciona los enlaces a GeoNames pero no contiene las coordenadas geográficas. Sin embargo, esta información puede ser recuperada de otros repositorios, como por ejemplo Wikidata. Las entidades en Wikidata disponen de un conjunto de propiedades que las describen y también incluyen un segundo apartado para identificadores externos. La Figura 9 corresponde a la entidad Londres en Wikidata y en ella podemos observar el identificador de GeoNames.
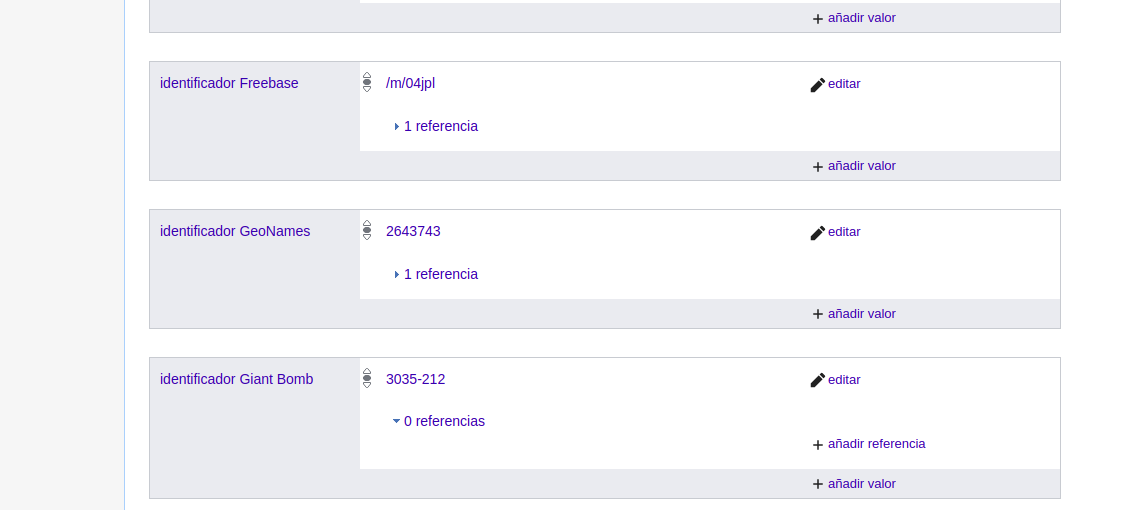
Enlace a GeoNames desde Wikidata
Hasta ahora disponemos de las URIs de cada elemento de GeoNames. Para poder enlazar a Wikidata necesitamos únicamente el identificador. El siguiente código extrae los identificadores haciendo tratamiento de cadenas, como se puede observar en la Figura 10.
lugares = pd.unique(df['lugar']).tolist()
cadena_lugares = ''
for a in sorted(lugares):
print(a)
cadena_lugares = cadena_lugares + ' \"' + a.replace("http://sws.geonames.org/", "").replace("/", "") + '\"'
print(cadena_lugares)

Extracción de identificadores de GeoNames
Una vez tenemos preparado nuestro listado de identificadores a GeoNames, vamos a recuperar las coordenadas geográficas de Wikidata. Para ello es necesario crear una consulta SPARQL. Vamos a utilizar la instrucción VALUES que permite especificar los valores para una determinada variable, en nuestro caso, los identificadores de GeoNames. La propiedad P1566 corresponde al identificador de GeoNames en Wikidata y la propiedad P625 corresponde a las propiedades geográficas.
url = 'https://query.wikidata.org/sparql'
sentencia = """
PREFIX bibo: <http://purl.org/ontology/bibo/>
SELECT ?idgeonames ?lat ?lon ?x ?xLabel
WHERE {{
values ?idgeonames {{ {0} }}
?x wdt:P1566 ?idgeonames ;
p:P625 [
psv:P625 [
wikibase:geoLatitude ?lat ;
wikibase:geoLongitude ?lon ;
wikibase:geoGlobe ?globe ;
];
ps:P625 ?coord
]
SERVICE wikibase:label {{ bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }}
}}
"""
sentencia = sentencia.format(cadena_lugares)
print(sentencia)
r = requests.get(url, params = {'format': 'json', 'query': sentencia})
puntos_geo = r.json()
A continuación, creamos un objeto folium para implementar un mapa y añadir las coordenadas recuperadas desde Wikidata en el paso anterior. Recuperamos cada coordenada geográfica (variables lat y lon) y montamos el texto (popup) que se mostrará al hacer click sobre cada localización en el mapa. Finalmente, añadimos al mapa cada elemento (marker).
mapa = folium.Map(location=[0,0], zoom_start=1.5)
for geo in puntos_geo['results']['bindings']:
idwikidata = geo['x']['value']
lat = geo['lat']['value']
lon = geo['lon']['value']
idgeonames = geo['idgeonames']['value']
etiqueta = geo['xLabel']['value']
print(lat, lon)
# insertar el texto en el popup
count = lugares_por_recurso[['http://sws.geonames.org/' + idgeonames + '/']][0]
texto_popup = str(count) + " registros publicados en <a hreh='" + str(idwikidata) + "'>" + etiqueta + "</a>"
folium.Marker([lat,lon], popup= texto_popup).add_to(mapa)
Y como resultado se obtiene un mapa que se puede consultar en la Figura 11 con los lugares de publicación de las obras del autor seleccionado, en nuestro caso, Miguel de Cervantes Saavedra.
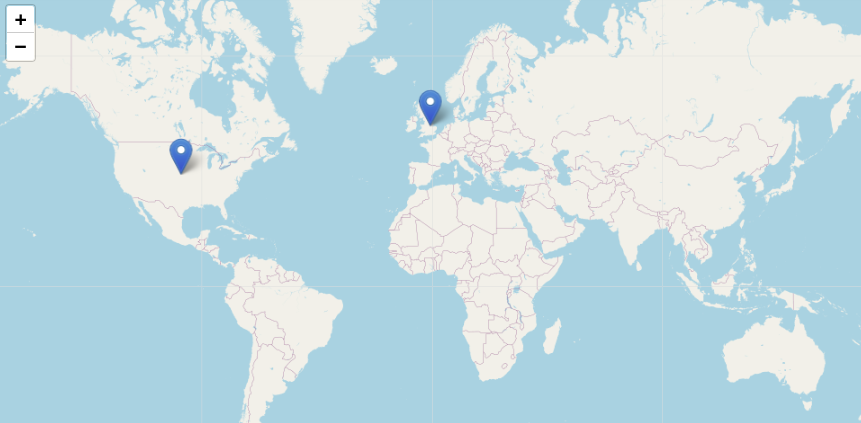
Lugares de publicación de las obras de Miguel de Cervantes
También es posible realizar un estudio de todas las localizaciones geográficas incluidas en el repositorio enlazadas a GeoNames. Para ello podemos calcular el número total de obras por localización geográfica relacionada con GeoNames a través de la propiedad c4dm:place de la siguiente forma:
PREFIX blt: <http://www.bl.uk/schemas/bibliographic/blterms#>
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX c4dm: <http://purl.org/NET/c4dm/event.owl#>
SELECT ?lugar (count(?recurso) as ?total_obras) WHERE {
?recurso dct:title ?titulo .
?recurso blt:publication ?publicacion .
?publicacion c4dm:place ?lugar .
FILTER regex(?lugar, "geonames", "i")
}
GROUP BY ?lugar
De forma similar a como se ha creado el mapa en el ejemplo de Miguel de Cervantes Saavedra, podemos obtener una visualización más representativa a través de un mapa que muestra el total de localizaciones enlazadas a GeoNames incluidas en el repositorio (alrededor de cuatro millones de resultados). Como se puede observar en la Figura 12, la localización más relevante es Inglaterra.
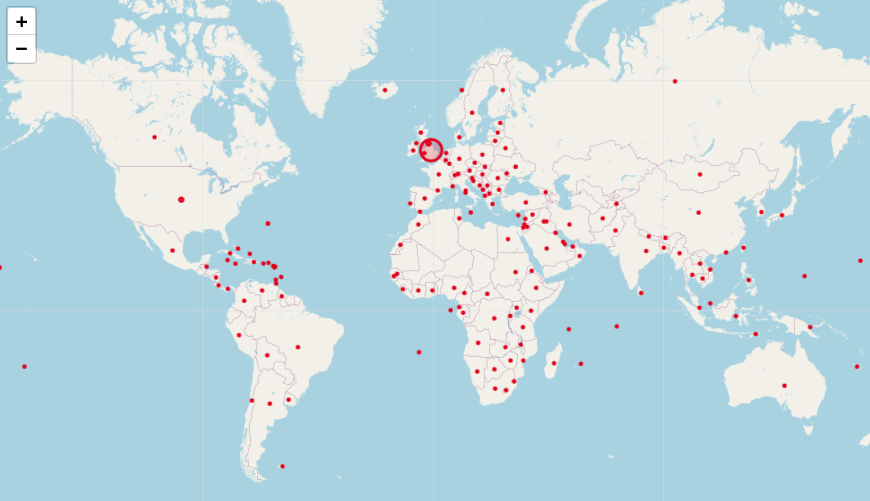
Lugares de publicación enlazados a GeoNames en BNB
Discusión
En el primer ejemplo se han reutilizado dos colecciones digitales descritas con MARCXML. Aunque la mayoría del código es reutilizable para ambos casos, los campos utilizados para describir los metadatos en cada colección son diferentes y por lo tanto es necesario un análisis previo.
En el caso de la BNB, y teniendo en cuenta la forma de representar los distintos roles que se pueden dar en un repositorio bibliográfico, la elección del vocabulario a utilizar puede ser crucial a la hora de dotar de suficiente expresividad a los metadatos. En este sentido, vocabularios ricos en términos semánticos como Resource Description and Access (RDA) proporcionan un listado de elementos para representar numerosos roles con el objetivo de relacionar las obras con los autores como por ejemplo director, ilustrador, impresor o narrador. Además, es relevante resaltar que tan solo alrededor de un 50% de las obras se encuentran enlazadas a GeoNames y que el mapa que obtenemos como resultado no incluye el total de ubicaciones del repositorio.
Conclusiones
En este tutorial se han introducido varios ejemplos de reutilización de colecciones digitales publicadas por instituciones GLAM. Los ejemplos facilitan la reproducción y análisis de los resultados, teniendo en cuenta las limitaciones de los metadatos proporcionados por las instituciones ya sea debido a la forma de utilizar los vocabularios o al número de enlaces externos incluido en la colección. La combinación de los Labs, las colecciones digitales y su acceso computacional a través de Jupyter Notebooks facilita un nuevo entorno en el que es posible reutilizar las colecciones digitales para construir nuevo conocimiento.
Las instituciones GLAM se están adaptando al nuevo entorno proporcionando colecciones aptas para el procesamiento por computador. Los Labs en el seno de las instituciones GLAM desempeñan un papel fundamental en este sentido para promover las colecciones digitales y su reutilización de forma innovadora. La Comunidad Internacional GLAM Labs ha fomentado la creación de Labs por todo el mundo; sin embargo, se observa una escasez de Labs en los países hispanohablates, lo que limita el potencial y la reutilización de las colecciones digitales en español. Además, todavía es posible mejorar en lo que respecta a las licencias para proporcionar colecciones digitales libres de derechos, como también a la publicación de ejemplos y prototipos de uso. En ese sentido, los Jupyter Notebooks pueden promover la creación de prototipos basados en métodos de investigación de Humanidades Digitales facilitando su reproducibilidad en entornos basados en la nube.
Glosario
- Collections as data
- Movimiento para promover el acceso computacional a las colecciones digitales.
- CSV (del inglés Comma Separated Values)
- Un archivo CSV consiste en un fichero de texto que contiene filas formadas columnas y separadas por comas.
- DataFrame
- Estructura que permite almacenar y manipular datos tabulados en filas formadas por columnas de variables.
- Folium
- Biblioteca de software Python que permite crear mapas interactivos.
- GeoNames
- Repositorio geográfico gratuito que proporciona un identificador único para cada recurso.
- GLAM Workbench
- Conjunto de herramientas, tutoriales y ejemplos basados en collectiones digitales publicadas por instituciones GLAM y desarrollado por el australiano Tim Sherratt.
- Jupyter Notebook
- Plataforma de código abierto que permite crear y compartir documentos compuestos por código, gráficas y documentación.
- Linked Open Data
- Publicación de información basada en RDF y conectada con repositorios externos de diferentes fuentes e instituciones.
- MARCXML
- Formato para la codificación de un registro MARC en XML.
- MyBinder
- Plataforma gratuita para la ejecución de Jupyter Notebooks alojados en repositorios como GitHub o Zenodo evitando la instalación de software.
- Pandas
- Biblioteca de software Python que permite crear y manipular conjuntos de datos.
- Python
- Lenguaje de programación interpretado y multiplataforma, de libre uso y con una curva de aprendizaje amigable y corta.
- RDF (del inglés Resource Description Framework)
- Marco de descripción de recursos publicado por el W3C para publicar información en Internet a modo de tripletas.
- SPARQL
- Lenguaje de consulta para información almacenada en formato RDF.
- URI (del inglés Universal Resource Identifier)
- Identificador uniforme de recursos para la web.
Notas
-
Candela, Gustavo, María Dolores Sáez, María Pilar Escobar y Manuel Marco-Such. hibernator11/notebook-ph: Release 1 v1.0 (2021). https://doi.org/10.5281/zenodo.5340157 ↩
-
Summers, Ed. pymarc v4.0.0 (2020). https://pymarc.readthedocs.io/en/stable/ ↩
-
The Pandas Development Team. pandas-dev/pandas: Pandas. v.1.2.2 (2020). https://doi.org/10.5281/zenodo.4524629 ↩
-
Filipe, Martin Journois, Frank, Rob Story, James Gardiner, Halfdan Rump, Andrew Bird, et al. Python-visualization/folium: v0.10.1 (2019). https://doi.org/10.5281/zenodo.3559751. ↩
-
Thomas A Caswell, Michael Droettboom, John Hunter, Eric Firing, Antony Lee, Jody Klymak, David Stansby, et al. Matplotlib/matplotlib v2.2.4 (2019). https://doi.org/10.5281/zenodo.2669103. ↩