
Contenidos
- Objetivos del módulo
- ¿Para quién es útil esto?
- Cómo aplicar nuestro conocimiento histórico
- La búsqueda avanzada en el OBO
- Comprender las consultas en URLs
- Descarga sistemática de archivos
- Próximos pasos: usar una interfaz de programación de aplicaciones (API)
- Notas
Objetivos del módulo
Descargar un solo registro de un sitio web es fácil, aunque la descarga de muchos registros a la vez —una necesidad cada vez más frecuente para personas de humanidades— es mucho más eficiente si se utiliza un lenguaje de programación como Python. En esta lección escribiremos un programa para descargar una serie de registros del Old Bailey Online (OBO) utilizando criterios de búsqueda personalizados y luego guardarlos en un directorio de nuestro computador.1 Este proceso conlleva la interpretación y manipulación de cadenas de consulta (query strings, en inglés) en la URL. En este caso, el programa tratará de descargar fuentes que contengan referencias a personas de ascendencia africana, publicadas en el Old Bailey Proceedings entre 1700 y 1750.
¿Para quién es útil esto?
Automatizar el proceso de descarga de registros de una base de datos en línea será útil para cualquier persona que trabaje con fuentes históricas almacenadas en línea de manera ordenada y accesible, y que desea guardar copias de esas fuentes en su propio computador. Es particularmente útil para quien quiera descargar muchos registros específicos, en lugar de solo unos cuantos. Si deseas descargar todos o la mayoría de los registros de una base de datos determinada, el tutorial de Ian Milligan sobre Descarga automatizada con Wget puede ser más adecuado.
El presente tutorial te permitirá descargar registros específicos de manera selectiva, aislando aquellos que satisfagan tus necesidades. La descarga automática de varias fuentes ahorra un tiempo considerable. Lo que hagas con las fuentes descargadas depende de tus objetivos de investigación. Es posible que quieras crear visualizaciones, aplicar diversos métodos de análisis de datos o simplemente reformatearlos para facilitar la navegación. O quizá solo desees guardar una copia de seguridad para acceder a ellos cuando no tengas acceso a Internet.
Esta lección está dirigida a usuarios intermedios de Python. Si aún no has revisado las lecciones de Programación básica en Python, puedes encontrar en ellas un punto de partida útil.
Cómo aplicar nuestro conocimiento histórico
En esta lección crearemos nuestro propio corpus de casos relacionados con personas de ascendencia africana. A partir del caso de Benjamin Bowsey en el OBO en 1780, notamos que la voz “black”2 es una palabra clave útil para localizar otros casos que involucren a acusados de ascendencia africana. Sin embargo, cuando buscamos “black” en el sitio web del OBO, encontramos que a menudo se refiere a otros usos de la palabra: caballos negros, tela negra, etc. La tarea de desambiguar este uso del lenguaje tendrá que esperar a otra lección. Por ahora vayamos a los casos más fáciles. Como historiadores e historiadoras, probablemente podamos pensar en palabras clave relacionadas con los descendientes de africanos que valdría la pena explorar. La infame n-word3 no es útil, por supuesto, ya que ese término no entró en uso regular sino hasta mediados del siglo XIX. Pero negro y mulatto eran voces muy utilizadas a principios del siglo XVIII. Estas palabras clave son menos ambiguas que “black” y es mucho más probable que sean referencias inmediatas a personas de nuestro grupo demográfico objetivo. Si intentamos buscar por separado estos dos términos en el sitio web del OBO, obtenemos resultados como en estas capturas de pantalla:
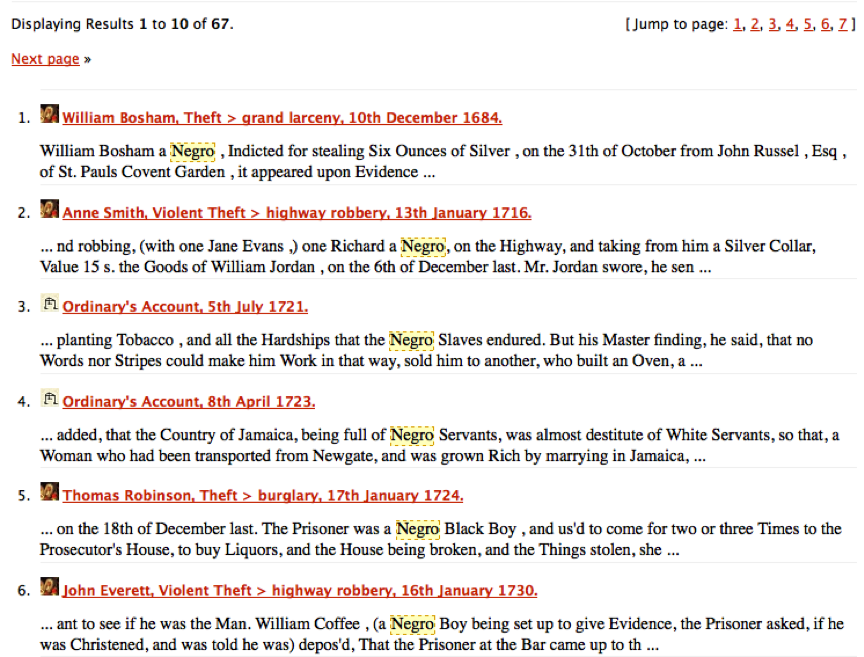
Resultados de búsqueda para ‘negro’ en el OBO

Resultados de búsqueda para ‘mulatto’ en el OBO
Después de analizar estos resultados, resulta evidente que se trata de referencias a personas y no a caballos, ropa u otras cosas que pueden ser de color negro. Queremos tener todos estos registros en nuestro computador para usarlos en nuestro análisis así que podríamos descargarlos manualmente uno por uno. Pero encontremos una manera programática de automatizar esta tarea.
La búsqueda avanzada en el OBO
Las características de búsqueda de cada sitio web funcionan de manera diferente.
Si bien las búsquedas funcionan de manera similar, la complejidad en la que están estructuradas las búsquedas en bases de datos pueden no ser del todo obvias.
Por lo tanto, es importante pensar críticamente sobre las opciones de búsqueda en la base de datos y leer la documentación proporcionada en el sitio web, cuando esta esté disponible.
El historiador o historiadora prudente siempre critica sus fuentes, por lo que los procedimientos que hay detrás de las casillas de búsqueda deben recibir la misma atención de nuestra parte.
El formulario de búsqueda avanzada del OBO te permite refinar tus búsquedas en diez campos diferentes, incluyendo palabras clave simples, un rango de fechas y un tipo de delito.
Como la función de búsqueda de cada sitio web es diferente, siempre vale la pena tomarse un tiempo para experimentar con ella y leer acerca de las opciones disponibles.
Como ya hemos hecho una búsqueda simple de los términos “negro” y “mulatto”, sabemos que obtendremos resultados.
Usaremos la búsqueda avanzada para limitar nuestros resultados a los registros de procesos judiciales publicados en los Old Bailey Proceedings entre 1700 y 1750 solamente.
Desde luego, puedes ajustar la búsqueda como quieras; pero si sigues el ejemplo aquí presentado, será más fácil comprender la lección.
Ejecuta la búsqueda que se muestra en la imagen de abajo.
Asegúrate de marcar el botón de opción Advanced (“Avanzado”) y usa los comodines * para incluir entradas en plural o aquellas con una “e” adicional al final.
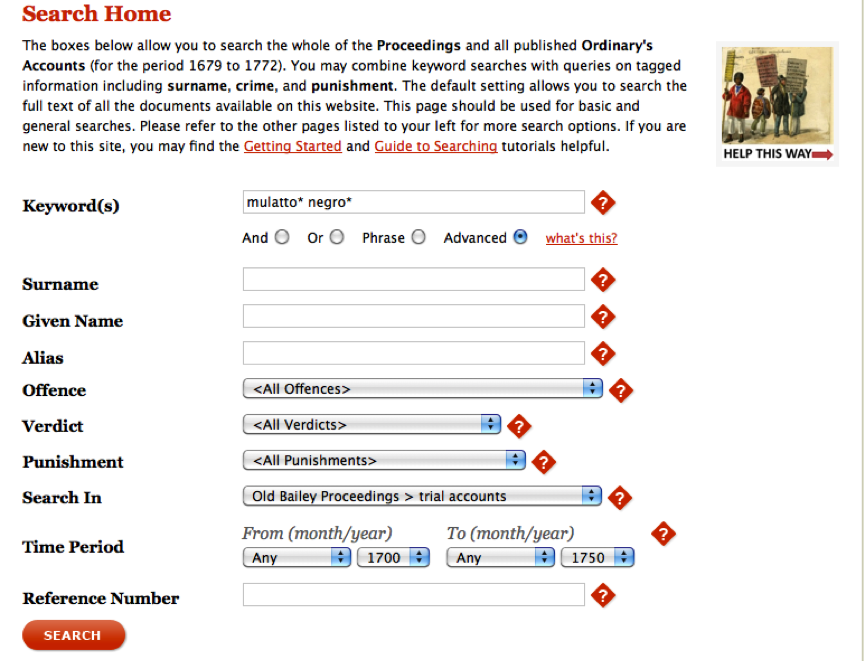
Ejemplo de búsqueda avanzada en el OBO
Realiza la búsqueda y luego haz clic en el enlace Calculate total (“Calcular el total”) para ver cuántas entradas hay. Debe haber 13 resultados (si tienes un número diferente, vuelve atrás y asegúrate de haber copiado exactamente el ejemplo anterior). Vamos a descargar estas transcripciones de procesos judiciales para analizarlas más a fondo. Por supuesto, puedes descargar cada uno de los 13 registros manualmente. Sin embargo, a medida queb más datos están disponibles en línea, será necesario manejar descargas de 1,300 o incluso 130,000 registros. La descarga de registros individuales resulta poco práctica y saber cómo automatizar el proceso es una herramienta muy valiosa. Para automatizar el proceso de descarga debemos retroceder y aprender cómo se crean las URLs de búsqueda en el sitio web del OBO, un método común en muchas bases de datos y sitios web en línea.
Comprender las consultas en URLs
Echa un vistazo a la URL producida con la última página de resultados de búsqueda. Debe tener un aspecto como este:
https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext=mulatto*+negro*&kwparse=advanced&_divs_div0Type_div1Type=sessionsPaper_trialAccount&fromYear=1700&fromMonth=00&toYear=1750&toMonth=99&start=0&count=0
Ya hemos estudiado las URLs en la lección Para entender páginas web y HTML y este parece mucho más complicado. Pero, aunque es más largo, en realidad no es mucho más complejo. Es sencillo entenderlo al observar cómo se representan nuestros criterios de búsqueda en la URL:
https://www.oldbaileyonline.org/search.jsp?
gen=1&
form=searchHomePage&
_divs_fulltext=mulatto*+negro*&
kwparse=advanced&
_divs_div0Type_div1Type=sessionsPaper_trialAccount&
fromYear=1700&
fromMonth=00&
toYear=1750&
toMonth=99&
start=0&
count=0
Aquí observamos más claramente los 12 datos que necesitamos para realizar nuestra búsqueda (uno en cada línea).
Tenemos la URL del sitio web del OBO seguido de una consulta (introducida por el carácter ?),
seguida de 11 pares nombre/valor acompañados cada uno del carácter &.
Cada par contiene el nombre de una variable de servidor (por ejemplo, toYear),4
unido con el signo de asignación =
al valor de dicha variable (en nuestro ejemplo, 1750).
Finalmente, el carácter ‘&’ le indica al servidor que a continuación siguen más pares nombre/valor en la URL.
Todo esto forma la cadena de consulta que le dice al motor de búsqueda qué variables utilizar en etapas específicas de la búsqueda.
En nuestro caso, la variable de servidor más importante de la cadena de consulta es _divs_fulltext, a la que se le ha dado el valor mulatto*+negro*.
Este valor contiene el término de consulta que hemos escrito en el cuadro de búsqueda.
(La aplicación web ha agregado automáticamente un signo + en lugar de un espacio en blanco ya que las URLs no pueden contener espacios.)
Esto es exactamente lo que le hemos pedido al buscador del OBO que nos encuentre.
Las otras variables de servidor tienen valores que también establecimos en la caja de búsqueda.
fromYear y toYear contienen nuestro intervalo de fechas.
Nota que en nuestro ejemplo el valor de toMonth es 99.
Como ningún año tiene 99 meses,
podemos conjeturar que así es como el algoritmo de búsqueda garantiza que se incluyan todos los registros de un mismo año.
No hay reglas estrictas para determinar qué hace cada variable porque las personas que construyeron el sitio les han asignado un nombre arbitrario.
A menudo podemos hacer una conjetura basada en nuestra experiencia y conocimiento.
Todos los campos de búsqueda posibles en la página de búsqueda avanzada tienen su propio par de nombre/valor. Si deseas averiguar el nombre de la variable de servidor para poder usarla, busca de nuevo y asegúrate de poner un valor en el campo de tu interés. Después de enviar tu búsqueda, verás el valor y el nombre asociado a él como parte de la URL de la página de resultados. Con el OBO, al igual que con muchos otros sitios web, el formulario de búsqueda te ayuda esencialmente a construir URLs que le indiquen a la base de datos qué debe buscar. Si comprendes cómo se representan los campos de búsqueda en la URL, lo que a menudo es bastante sencillo, entonces es relativamente fácil construir las URLs mediante programación y, por lo tanto, automatizar el proceso de descarga de registros.
Entre las variables de servidor hay una que será importante en nuestra búsqueda programática.
La variable start le indica al servidor en cuál número de registro debe iniciar la página de resultados.
Por ejemplo, si cambias start=0 por start=10 en la URL y presionas enter,
deberás obtener los resultados del 11 al 13.
Y si la cambias por start=5, obtendrás del 6 al 13.
Sería ideal que pudiéramos elegir mostrar todos los resultados en una sola página,
pues ello facilitará su procesamiento;
pero la aplicación web del OBO despliega los resultados en páginas de 10 registros cada una.
Ahora aprovecharemos este conocimiento para crear una serie de URLs que nos permitirá descargar los 13 archivos.
Descarga sistemática de archivos
En Descargar páginas web con Python aprendimos que Python puede descargar una página web siempre que tengamos la URL.
En dicha lección usamos la URL para descargar la transcripción del proceso de Benjamin Bowsey.
En la presente lección estamos intentando descargar varias transcripciones de procesos judiciales que cumplan con los criterios de búsqueda que describimos anteriormente, sin tener que volver a ejecutar el programa repetidamente.
Así pues, queremos un programa que descargue todo lo que necesitamos de una sola vez.
En este punto, tenemos la URL de una página de resultados de búsqueda que contiene las diez primeras entradas de nuestra consulta.
También sabemos que al modificar el valor de la variable start en la URL, podemos llamar secuencialmente cada página de resultados de búsqueda y así al fin recuperar todos los registros de procesos judiciales.
Por supuesto, las páginas de resultados no nos dan los los registros de los procesos judiciales sino enlaces a ellos.
Así que necesitamos extraer el enlace a los registros contenidos en los resultados de búsqueda.
En el sitio web del OBO, los de los registros individuales (los archivos de transcripción de los procesos judiciales) se pueden encontrar como enlaces en las páginas de resultados de búsqueda.
Sabemos que todas las URLs de transcripciones contienen una identificación formada por una t seguida de al menos 8 números (por ejemplo, t17800628-33).
Al buscar los enlaces que contengan ese patrón, podemos identificar las URLs de las transcripciones de los procesos judiciales.
Al igual que en las lecciones anteriores, desarrollaremos un algoritmo para abordar el problema de tal manera que el computador lo pueda manejar.
Al parecer, esta tarea se puede lograr en cuatro pasos.
Necesitaremos:
- Generar las URLs para cada página de resultados de búsqueda incrementando en una cantidad fija la variable de servidor
startpor un número apropiado de veces. - Descargar cada página de resultados de búsqueda como un archivo HTML.
- Extraer las URLs de cada procesos judiciales (utilizando la ID de proceso, como se describió anteriormente) contenidos en los archivos HTML de los resultados de la consulta.
- Recorrer esos URLs extraídos para descargar cada transcripción de prueba y guardarlas en una carpeta en nuestro computador.
Recordarás que esto es bastante similar a las tareas que realizamos en Descargar páginas web con Python y De HTML a lista de palabras (parte 2). Primero descargamos y luego analizamos la información que buscamos; y, en el presente caso, descargamos un poco más.
Descargar las páginas de resultados de consulta
Primero necesitamos generar las URLs para descargar cada página de resultados de consulta. Ya tenemos el primero utilizando el formulario en el sitio web:
https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext=mulatto*+negro*&kwparse=advanced&_divs_div0Type_div1Type=sessionsPaper_trialAccount&fromYear=1700&fromMonth=00&toYear=1750&toMonth=99&start=0&count=0
Escribamos un programa que funcione sin importar cuántas páginas de resultados de búsqueda o registros tengamos que descargar, y sin importar qué decidamos buscar.
Estudia el siguiente código y luego agrega esta función a un módulo llamado obo.py (crea un archivo con ese nombre y guárdalo en el directorio donde deseas hacer tu trabajo).
Los comentarios en el código (las líneas que empiezan con un #) están destinados a ayudarte a descifrar las distintas partes.
# obo.py
from urllib.request import urlopen
def obtener_resultados_consulta(consulta, kwparse, from_year, from_month, to_year, to_month):
start_value = 0
# separa cada parte de la URL para leerla mejor
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += consulta
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + from_year
url += '&fromMonth=' + from_month
url += '&toYear=' + to_year
url += '&toMonth=' + to_month
url += '&start=' + str(start_value)
url += '&count=0'
# descarga y guarda el resultado
respuesta = urlopen(url)
contenido_web = respuesta.read()
nombre_archivo = 'resultado_consulta' + '.html'
with open(nombre_archivo, 'w', encoding='utf-8') as f: # ①
f.write(contenido_web.decode('utf-8')) # ②
En esta función hemos dividido los diversos componentes de la cadena de consulta y hemos utilizado argumentos de función para que pueda reutilizarse más allá de nuestras necesidades específicas del momento.
Cuando llamamos esta función, reemplazamos los argumentos con los valores que queremos buscar.
Luego, descargamos la página de resultados de búsqueda de una manera similar a como se hace en Descargar páginas web con Python.
La línea que hemos marcado con ① crea el archivo resultado_consulta.html, asegurándonos de estar usando la codificación de caracteres UTF-8.
Y la línea ② guarda en dicho archivo el valor de la variable contenido_web, también asegurándose de usar esa misma codificación.
(No necesitas cerrar explícitamente el archivo con la instrucción close, ya que el bloque with se encarga de ello.)
Ahora crea un nuevo programa de Python llamado descarga_consultas.py
y copia en él el siguiente código.
Ten en cuenta que los valores que hemos utilizado como argumentos son exactamente los mismos del ejemplo anterior.
Siéntete libre de jugar con estos para obtener diferentes resultados o ver cómo funcionan.
# descarga_consultas.py
import obo
consulta = 'mulatto*+negro*'
obo.obtener_resultados_consulta(consulta, 'advanced', '1700', '00', '1750', '99')
Cuando ejecutes este programa
(con python3 descarga_consultas.py desde el terminal, o desde tu editor de código preferido),
encontrarás un nuevo archivo llamado resultado_consulta.html en tu carpeta de trabajo.
Este archivo contiene la primera página de los resultados de búsqueda.
Comprueba que se haya descargado correctamente y luego bórralo, pues ya no lo necesitaremos.
Vamos a adaptar nuestro programa para descargar la otra página que contiene las otras 3 entradas al mismo tiempo, por lo que debemos asegurarnos de obtener ambas.
Refinemos ahora nuestra función de Python obtener_resultados_consulta.
Primero agregaremos otro argumento de función llamado entradas
para que podamos decirle al programa cuántas páginas de resultados necesitamos descargar.
Usaremos el valor de las entradas y algunos cálculos matemáticos simples para determinar cuántas páginas de resultados de búsqueda hay.
Esto es bastante sencillo ya que sabemos que en el OBO hay 10 transcripciones enumeradas por página.
Podemos calcular el número de páginas de resultados dividiendo el valor de las entradas por 10.
Guardaremos este resultado en una variable entera llamada contar_paginas.
Será algo como lo siguiente:
# determina la cantidad de archivos a descargar
contar_paginas = entradas // 10
Debido a que en Python 3 el operador // es de división entera, y por lo tanto redondea hacia el menor número entero el resultado de la división, el valor de contar_palabras siempre será un número entero.
Prueba lo siguiente ejecutando el siguiente código en el intérprete REPL de Python en tu terminal (en Mac y Linux),
o en cmd o PowerShell (en Windows).
(Nota, de aquí en adelante, usaremos la palabra “terminal” para referirnos al intérprete de línea de comandos.)
# en el REPL de Python
entradas = 13
contar_paginas = entradas // 10
print(contar_paginas)
-> 1
Ahora bien, lo que queremos obtener es “2”:
una página que contiene las entradas 1 a 10, y otra que contiene las entradas 11 a 13.
Pero dado que hay un residuo en esta operación (de 3 en este caso, aunque no importa cuál sea), los últimos 3 resultados no se descargarán ya que solo capturaremos 1 página de 10 resultados.
Para solucionar este problema utilizaremos el operador modulo (%), que divide el primer valor por el segundo y nos devuelve el residuo.
Así, si el residuo es mayor que 0, sabemos que hay una página adicional de resultados y necesitamos aumentar el valor de la variable de Python contar_paginas en una unidad.
El código ahora debería verse así:
# determina la cantidad de archivos a descargar
entradas = 13
contar_paginas = entradas // 10
residuo = entradas % 10
if residuo > 0:
contar_paginas += 1
Si agregamos este código a nuestra función obtener_resultados_consulta, justo debajo de la línea start_value = 0, nuestro programa podrá calcular el número de páginas que deben descargarse.
Sin embargo, en esta etapa solo se descargará la primera página, ya que hemos indicado, en la sección de la función de descarga, que se ejecute solamente una vez.
Para corregirlo, debemos encerrar en un bucle for el código de descarga que trabajará una vez por cada número que se indique en la variable de Python contar_paginas.
Si el valor de dicha variable es 1, entonces descargará una vez; si obtiene 5 descargará cinco veces, y así sucesivamente.
(El valor de pagina irá aumentando en cada iteración de bucle for: 1, 2, 3, etc. hasta una unidad menos que el valor de contar_páginas)
Inmediatamente después de la línea que contiene la expresión contar_paginas += 1, que acabas de escribir, agrega la siguiente línea y todo lo que está debajo de la línea que contiene f.write(contenido_web.decode('utf-8')) (cuida de sangrar a la derecha todo el código para que este se incluya en el bucle for):
for pagina in range(contar_paginas):
print(pagina)
# acá añadimos el código
# ...
Dado que este es un bucle for, debemos planear bien todo el código que queremos ejecutar repetidamente ahí.
Puedes saber si lo has hecho correctamente al ver el ejemplo del código terminado a continuación.
Este bucle aprovecha la función range (“rango”) de Python.
Para entender esto, es mejor pensar que la variable de Python contar_paginas es igual a 2 como se muestra en el ejemplo.
Estas dos líneas de código significan:
“Comienza a ejecutarlo con un valor de bucle inicial de 0, y cada vez que ejecutes agrega 1 más a ese valor. Cuando el valor del bucle es el mismo que contar_paginas, ejecuta una vez más y luego para.”5
Esto es particularmente valioso en nuestro caso, porque podemos decirle a nuestro programa que se ejecute exactamente una vez para cada página de resultados, lo que proporciona una nueva habilidad flexible para controlar cuántas veces se ejecuta el bucle for.
Si deseas practicar con esta nueva y poderosa forma de escribir bucles, puedes abrir tu terminal y jugar con el REPL de Python:
# en el REPL de Python:
contar_paginas = 2
for pagina in range(contar_paginas):
print(pagina)
-> 0
-> 1
Ahora bien, antes de agregar todo este código a nuestra función obtener_resultados_consulta, tenemos que hacer dos ajustes.
Primero, al final del bucle for (pero aún dentro del bucle) y después de que se haya ejecutado nuestro código de descarga, necesitaremos modificar la variable de servidor startValue en la URL de la página que queremos descargar.
(Esto lo hacemos modificando la variable de Python correspondiente start_value, que es la que nuestro programa usa para general el valor de la variable de servidor startValue en la URL.)
Si no lo hacemos, nuestro programa descargará repetidamente la primera página de resultados pues no estamos cambiando nada en la URL inicial.
Por lo tanto, podemos solicitar la siguiente página de resultados de búsqueda aumentando su valor en 10, una vez que se haya completado la descarga inicial.
Si no sabes exactamente dónde colocar esta línea, puedes echar un vistazo al ejemplo de código terminado, más abajo.
Segundo, debemos asegurarnos de que el nombre del archivo con los datos que hemos descargado sea diferente para cada página registrada.
De lo contrario, cada descarga se guardará sobrescribiendo la descarga anterior, lo que nos dejará con un solo archivo de resultados.
Para resolver esto, debemos ajustar el contenido de la variable nombre_archivo para incluir el valor contenido en la variable pagina.
Así, cada vez que descarguemos una nueva página, obtendremos un nombre diferente:
resultado_consulta0.html, resultado_consulta1.html, resultado_consulta2.html y así sucesivamente.
Como pagina contiene un número entero, tendremos que convertir su valor en una cadena (con la función str() de Python) antes de poder agregarlo a la variable de cadena nombre_archivo.
(De lo contrario obtendremos un error, pues el operador +, usado como concatenador, requiere necesariamente datos de tipo de cadena, no de tipo numérico.)
Ajusta la línea en tu programa que pertenece a la variable nombre_archivo para que se vea así:6
nombre_archivo = 'resultado_consulta' + str(pagina) + '.html'
Ahora ya puedes agregar estas nuevas líneas de código a tu función obtener_resultados_consulta.
Recordemos que hasta el momento hemos añadido lo siguiente:
- agregamos la variable de Python
entradascomo un argumento de función adicional justo después deto_month; - calculamos el número de páginas de resultados e incluimos esto inmediatamente después de la línea que comienza con
start_value = 0(antes de crear la URL y comenzar a descargar); - inmediatamente después de esto añadimos un bucle
for, que le indicará al programa que se ejecute una vez para cada página de resultados de búsqueda (es importante sangrar a la derecha el resto del código de la función para que quede dentro del nuevo bucle); - ajustamos la variable
nombre_archivoexistente para que cada vez que se descargue una página de resultados se le dé un nombre único al archivo; y - finalmente, en la última línea del bloque de
foraumentamos el valor de la variable de Pythonstart_value(en 10 unidades) cada vez que se ejecute el bucle.
Ahora bien, antes de proseguir, hagamos una última cosa.
Nota que en el código de la función obtener_resultados_consulta la variable de Python entradas, que contiene el número de registros que han de ser obtenidos, está predefinida con un valor fijo (13 en nuestro ejemplo).
Como queremos que nuestra función sea más flexible y no esté necesariamente atada a un número predeterminado de registros, vamos incluir un argumento o parámetro adicional en nuestra definición de función: entradas. Lo añadiremos al final de la lista de argumentos: def obtener_resultados_consulta(..., entradas).
Así las cosas, el código de la función terminada en el archivo obo.py deberá verse de la siguiente manera:
# obo.py
# ...
def obtener_resultados_consulta(consulta, kwparse, from_year, from_month, to_year, to_month, entradas):
start_value = 0
# elimina los caracteres no alfanuméricos
directorio = re.sub(r'\W', '', consulta)
# crea un directorio con un nombre seguro si no existe ya
if not os.path.exists(directorio):
os.makedirs(directorio)
# determina la cantidad de archivos que debemos descargar
contar_paginas = entradas // 10
residuo = entradas % 10
if residuo > 0:
contar_paginas += 1
for pagina in range(contar_paginas):
# separa cada parte del URL para leerlo mejor
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += consulta
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + from_year
url += '&fromMonth=' + from_month
url += '&toYear=' + to_year
url += '&toMonth=' + to_month
url += '&start=' + str(start_value)
url += '&count=0'
# descarga y guarda el resultado
respuesta = urlopen(url)
contenido_web = respuesta.read()
nombre_archivo = 'resultado_consulta' + str(pagina) + '.html'
with open(nombre_archivo, 'w', encoding='utf-8') as f:
f.write(contenido_web.decode('utf-8'))
start_value += 10
Como hemos añadido la variable entradas en la definición de la función, debemos añadir un argumento adicional cuando la llamemos en el programa descarga_consultas.py:
# descarga_consultas.py
import obo
consulta = 'mulatto*+negro*'
obo.obtener_resultados_consulta(consulta, "advanced", "1700", "00", "1750", "99", 13)
¡Estupendo!
Corre el programa y verás que ahora tenemos dos páginas de resultados de búsqueda:
resultado_consulta0.html y resultado_consulta1.html.
Pero antes de avanzar al siguiente paso en el algoritmo, vamos a ocuparnos de algunas tareas de limpieza. Nuestra carpeta de trabajo se volverá difícil de manejar si descargamos varias páginas de resultados y transcripciones de procesos judiciales en ella.
Por lo tanto, con Python crearemos un nuevo directorio con el nombre de nuestros términos de búsqueda.
Queremos añadir esta nueva funcionalidad en obtener_resultados_consulta, para que nuestras páginas de resultados de búsqueda se descarguen en un directorio con el mismo nombre que nuestra consulta de búsqueda.
Esto mantendrá nuestro directorio de trabajo más organizado.
Para ello crearemos un nuevo directorio utilizando el módulo de Python os, (abreviatura de operating system, “sistema operativo”).
Esa biblioteca contiene una función llamada makedirs cuya función es crear un nuevo directorio.
Puedes probar esto usando el REPL de Python.
# REPL de Python
import os
consulta = "mi_directorio_nuevo"
if not os.path.exists(consulta):
os.makedirs(consulta)
Este código verifica si tu computador ya tiene un directorio con este nombre.
Si no lo tenías, ahora deberás tener un directorio llamado mi_directorio_nuevo.
(El directorio se creará como subdirectorio del directorio donde hayas llamado originalmente al REPL de Python.)
Si esto funciona, puedes eliminar el directorio de tu disco duro, ya que esto fue solo para practicar.
Como queremos crear un nuevo directorio con el nombre de la consulta que ingresamos en el sitio web del OBO, haremos uso directamente del argumento de función consulta en la función obtener_resultados_consulta.
Para hacer esto, importa el módulo os (debajo de las otra instrucción de importación, from urllib.request import urlopen).
Ahora bien, como estamos usando los caracteres * y + en nuestra búsqueda en el OBO, y como estos tienen una significación importante en el modo como los sistemas operativos navegan los directorios, es conveniente que los reemplacemos por otros más seguros antes de crear nuestro directorio.
Usaremos expresiones regulares en Python para excluir del nombre de directorio todos los caracteres que no sean alfanuméricos.
Python dispone del potente módulo re (que deberemos importar al inicio del archivo obo.py, debajo de las otras instrucciones de importación) para ello.
Nuestro código “seguro” será entonces el siguiente:
# obo.py
# ...
import re
#...
directorio = re.sub(r'\W', '', consulta)
if not os.path.exists(directorio):
os.makedirs(directorio)
En la primera línea, la función re.sub busca la expresión regular \W (que significa: “cualquier carácter no alfanumérico”) en el valor de la variable consulta y lo reemplaza por la cadena vacía '', es decir, lo elimina.7
El resultado de este reemplazo se almacena en la variable directorio.
(Es importante que recordemos, en todo caso, que el valor que nuestro programa pasará a la variable de servidor en la URL aún contiene los caracteres * y +.
Este reemplazo solo es para el nombre del directorio.)
Así las cosas, la función obtener_resultados_consulta deberá quedar así:
# crea URLs para las paginas de resultados de consulta y guarda los archivos
def obtener_resultados_consulta(consulta, kwparse, from_year, from_month, to_year, to_month, entradas):
start_value = 0
# elimina los caracteres no alfanuméricos
directorio = re.sub(r'\W', '', consulta)
# crea un directorio con un nombre seguro si no existe ya
if not os.path.exists(directorio):
os.makedirs(directorio)
# determina la cantidad de archivos que debemos descargar
contar_paginas = entradas // 10
residuo = entradas % 10
if residuo > 0:
contar_paginas += 1
for pagina in range(contar_paginas):
# separa cada parte del URL para leerlo mejor
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += consulta
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + from_year
url += '&fromMonth=' + from_month
url += '&toYear=' + to_year
url += '&toMonth=' + to_month
url += '&start=' + str(start_value)
url += '&count=0'
# descarga y guarda el resultado
respuesta = urlopen(url)
contenido_web = respuesta.read()
nombre_archivo = 'resultado_consulta' + str(pagina) + '.html'
with open(nombre_archivo, 'w', encoding='utf-8') as f:
f.write(contenido_web.decode('utf-8'))
start_value += 10
Muy bien.
Ahora debemos asegurarnos de que guardemos nuestras páginas de resultados de búsqueda en este nuevo directorio.
Podemos hacerlo de muchas maneras, pero la más sencilla es agregar el nuevo nombre del directorio más una barra al nombre del archivo (en la variable nombre_archivo):
nombre_archivo = directorio + '/' + 'resultado_consulta' + str(start_value) + '.html'
Nota, sin embargo, que este código solo funcionará adecuadamente en MacOS y en Linux,
no en Windows, pues este usa la barra invertida \ para demarcar rutas de directorio.
Para asegurarnos de que funcione también en Windows, usaremos la función os.path.join de Python.
Esta función une adecuadamente las rutas, teniendo en cuenta el sistema operativo donde se corre el programa.
Arriba en obo.py la importaremos así:
from os.path import join as pjoin
(la importaremos como pjoin porque de lo contrario habría una colisión con la función de concatenación join, que es más fundamental en Python).
La línea modificada será entonces esta:
nombre_archivo = pjoin(directorio, 'resultado_consulta' + str(pagina) + '.html')
Así pues, el código completo del programa obo.py deberá quedar así:
# obo.py
from urllib.request import urlopen
import os
import join from os.path as pjoin
import re
# crea URLs para las paginas de resultados de consulta y guarda los archivos
def obtener_resultados_consulta(consulta, kwparse, from_year, from_month, to_year, to_month, entradas):
start_value = 0
# elimina los caracteres no alfanuméricos
directorio = re.sub(r'\W', '', consulta)
# crea un directorio con un nombre seguro si no existe ya
if not os.path.exists(directorio):
os.makedirs(directorio)
# determina la cantidad de archivos que debemos descargar
contar_paginas = entradas // 10
residuo = entradas % 10
if residuo > 0:
contar_paginas += 1
for pagina in range(contar_paginas):
# separa cada parte del URL para leerlo mejor
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += consulta
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + from_year
url += '&fromMonth=' + from_month
url += '&toYear=' + to_year
url += '&toMonth=' + to_month
url += '&start=' + str(start_value)
url += '&count=0'
# descarga y guarda el resultado
respuesta = urlopen(url)
contenido_web = respuesta.read()
nombre_archivo = pjoin(directorio, 'resultado_consulta' + str(pagina) + '.html')
with open(nombre_archivo, 'w', encoding='utf-8') as f:
f.write(contenido_web.decode('utf-8'))
start_value += 10
Ejecuta el programa descarga_consultas.py una vez más para asegurarte de que funcione
y entiendas cómo guardar archivos en un directorio particular usando Python.
Descargar las entradas individuales de los procesos judiciales
A estas alturas hemos creado una función capaz de descargar todos los archivos HTML con los resultados de consulta del sitio web del OBO, para realizar la búsqueda avanzada que hemos definido. Todo esto lo hemos hecho usando Python. Para el siguiente paso del algoritmo, debemos extraer las URLs de cada proceso judicial de los archivos HTML. En las lecciones que preceden a esta (por ejemplo, Descargar páginas web con Python), hemos trabajado con versiones para impresión (printer friendly) de los procesos judiciales, por lo que continuaremos haciéndolo así aquí. Sabemos que la versión para impresión del proceso judicial contra Benjamin Bowsey se encuentra en la URL:
https://www.oldbaileyonline.org/print.jsp?div=t17800628-33
Así como al cambiar las cadenas de consulta en las URLs se producen resultados de búsqueda diferentes, así también al cambiar la URL por registros de procesos judiciales —es decir, sustituyendo la ID de un proceso judicial por otra—, obtendremos la transcripción de otro proceso.
(En este caso, la ID del proceso judicial se pasa con la variable de servidor div, cuyo valor en el caso del ejemplo es t17800628-33.)
Esto significa que para descargar los 13 archivos coincidentes, todo lo que necesitamos son las IDs de los procesos judiciales.
Como sabemos que las páginas de resultados de búsqueda en los sitios web generalmente contienen un enlace a las páginas descritas, es muy probable que podamos encontrar estos enlaces, incrustados en el código HTML.
Si en otras lecciones pudimos eliminar esta información de la página que descargamos, ahora podemos usar esa misma información para generar una URL que nos permita descargar cada transcripción del proceso judicial.
Esta técnica de web scraping se puede usar en la mayoría de las páginas de resultados de búsqueda, no solo la del OBO.
Para hacerlo, primero deberemos encontrar dónde están las IDs de cada proceso judicial en medio del código HTML de los archivos descargados.
Luego determinaremos una forma de aislarlos consistentemente usando Python,
de modo que siempre podamos encontrar las transcripciones de los procesos judiciales,
sin importar qué página de resultados de búsqueda descarguemos del sitio.
Abre el documento resultado_consulta0.html en tu editor de código y dale un vistazo a la lista de los procesos judiciales.
La primera entrada comenzará con las palabras “Anne Smith”, por lo que puedes usar la herramienta de búsqueda de texto de tu editor de código para ir inmediatamente al lugar correcto.
Fíjate que el nombre “Anne” está en el contenido de un enlace (un elemento de <a> de HTML):
<a href="browse.jsp?id=t17160113-18&div=t17160113-18&terms=mulatto*_negro*#highlight">
Anne Smith, Violent Theft > highway robbery, 13th January 1716.
</a>
En el lenguaje HTML, el destino de un enlace (el elemento <a>) se especifica en el valor del atributo href,
que en este caso es:
browse.jsp?id=t17160113-18&div=t17160113-18&terms=mulatto*_negro*#highlight
Saber esto es magnífico, pues podemos ver que el enlace contiene la ID del proceso judicial: t17160113-18.
¡Excelente!
Desplázate por las entradas restantes y encontrarás lo mismo en todas ellas.
Por suerte para nosotros, el sitio está bien construido y parece que cada enlace comienza con browse.jsp?id=,
seguido de la ID del proceso judicial, luego un & y luego el resto de variables de servidor.
En el caso de Anne Smith: browse.jsp?id=t17160113-18&.
Vamos entonces a escribir unas líneas de código que capturen estas IDs.
Las pondremos al final de nuestro programa de Python obo.py.
Echa un vistazo al código de la función obtener_procesos_individuales a continuación.
Esta función también utiliza el módulo os de Python, en este caso para enumerar el contenido del directorio que creamos en la sección anterior.
(Este módulo contiene una gama de funciones útiles que reflejan los tipos de tareas que podrías realizar con tu ratón en el Finder de Mac o el Explorador de Windows, como abrir, cerrar, crear, eliminar y mover archivos y directorios.
Es un módulo magnífico que deberíamos dominar o, al menos, familiarizarnos con él.)
def obtener_procesos_individuales(consulta):
consulta_limpia = re.sub(r'\W', '', consulta)
resultados_busqueda = os.listdir(consulta_limpia)
print(resultados_busqueda)
Ahora crea y ejecuta un nuevo programa de Python llamado extraer_id_proceso.py con el siguiente código:
# extraer_id_proceso.py
import obo
obo.obtener_procesos_individuales('mulatto*+negro*')
Asegúrate de introducir el mismo valor en el argumento de consulta como en el ejemplo anterior (mulatto*+negro*).
Si todo sale bien, Python imprimirá una lista con los nombres de todos los archivos que están en la nueva carpeta, algo como:
['resultado_consulta0.html', 'resultado_consulta1.html']
Por ahora deberán ser solamente las dos páginas con los resultados de búsqueda.
Asegúrate de que esto funcione antes de seguir adelante.
Dado que hemos guardado todas las páginas de resultados usando nombres de archivo que contienen la expresión resultado_consulta, podemos abrir cada uno de ellos y extraer todas las IDs de los procesos judiciales que se encuentran en él.
En este caso, sabemos que solo hay dos, aunque queremos que nuestro código sea lo más flexible posible, desde luego.
Al restringir esta acción exclusivamente a los archivos cuyos nombres contienen la expresión resultado_consulta, nuestro programa funcionará como lo esperamos, incluso si el directorio contiene muchos otros archivos no relacionados porque el programa saltará cualquier cosa con un nombre diferente.
Agrega el siguiente código a la función obtener_procesos_individuales (en el programa obo.py).
El código pasará por cada archivo contenido en el directorio creado anteriormente
y comprobará si su nombre contiene la expresión resultado_consulta.
En caso positivo, el archivo se abrirá y los contenidos se guardarán en una variable llamada texto.
El contenido de dicha variable se analizará luego para aislar la ID del proceso judicial,
que sabemos que siempre está ubicada a la derecha de la expresión browse.jsp?id= en la URL.
Cuando el programa encuentre la ID del proceso judicial, se guardará en una lista de Python y se imprimirá en pantalla.
def obtener_procesos_individuales(consulta):
consulta_limpia = re.sub(r'\W', '', consulta)
resultados_busqueda = os.listdir(consulta_limpia)
urls = []
# encuentra las paginas de resultados de búsqueda
for nombre_archivo in resultados_busqueda:
if 'resultado_consulta' in nombre_archivo: # ①
with open(consulta_limpia + '/' + nombre_archivo, 'r') as f:
texto = f.read().split(' ') # ②
# busca las IDs de los procesos judiciales
for palabra in texto: # ③
if 'browse.jsp?id=' in palabra: # ④
# aísla la ID
captura = re.search(r'id=(.+?)&', palabra) # ⑤
url = captura.group(1) # ⑥
urls.append(url) # ⑦
print(urls)
Este código puede parecer algo complicado a primera vista, pero vamos a desmenuzarlo y verás que no es tan difícil.
Las líneas ① y ④ usan el operador de continencia in de Python, en este caso entre cadenas.
La expresión:
<cadena1> in <cadena2>
es verdadera solo si <cadena1> es una subcadena de <cadena2>,
es decir, si los caracteres de la primera cadena están contenidos, en el mismo orden, en la segunda cadena.
Por ejemplo, lo siguiente es verdadero:
'resultado_consulta' in 'resultado_consulta0.html'
pero esto es falso:
'resultado_consulta' in 't17310428-72.html'
En ese sentido, lo que las líneas ① y ④ hace es verificar que estemos seleccionando el archivo apropiado (según nuestra convención de denominación), en el primer caso; y si la “palabra” que estamos procesando contiene la expresión browse.jsp?id=, en el segundo.
Veamos ahora la importancia de esa expresión, para lo cual pasemos al bucle for en ③.
Este bucle iterará por cada una de las “palabras” del documento HTML que estamos procesando.
La línea ② ha guardado una lista enorme de palabras en la variable texto.
Python ha partido todo el archivo con la función split, cuyo argumento es un espacio en blanco (' ').
Esto quiere decir que Python separará todo el documento donde haya espacios.
Estas serán nuestras “palabras”, si se nos permite la expresión:
Anne, Smith, href="browse.jsp?id=t17160113-18&div=t17160113-18&terms=mulatto*_negro*#highlight">, etc.
Nuestro for pasará por cada una de ellas.
Como vimos, la línea ④ examinará si la expresión browse.jsp?id= está contenida en la “palabra”.
Es decir, determinará si ahí es donde está guardada la ID del proceso judicial que estamos buscando.
Si esto es el caso, en la línea ⑤ aislaremos la parte de la expresión capturada en la palabra, la ID. Para esto usamos un grupo de captura de expresiones regulares, que se indican entre paréntesis. Miremos en el documento HTML una de estas “palabras” que nos interesan:
href="browse.jsp?id=t17160113-18&div=t17160113-18&terms=mulatto*_negro*#highlight">
Subrayemos la parte que nos interesa únicamente:
href="browse.jsp?id=t17160113-18&div=t17160113-18&terms=mulatto*_negro*#highlight">
------------
Nuestro grupo de captura tomará el texto que va desde id= hasta el primer & (excluyéndolos en el texto capturado).
Eso es justo lo que significa la expresión regular id=(.+?)&.
En efecto, .+? significa:
captura cualquier carácter (.) una o más veces (+),
pero hazlo sin codicia (?),
es decir, detén la búsqueda apenas encuentres el primer &;
y finalmente guarda el texto hallado en un grupo de captura ((, )).
Python enumera secuencialmente los grupos de captura.
En nuestra expresión regular solo hay un grupo; por lo tanto, será el grupo 1.
La línea ⑥ guarda el contenido de ese grupo —nuestra ID— en la variable url.
Finalmente, la línea ⑦ la añade como un ítem adicional en nuestra lista urls, que luego aprovecharemos.
Cuando vuelvas a ejecutar el programa extraer_id_procesos.py, verás una lista de todas las ID de los procesos judiciales.
Podemos agregar un par de líneas adicionales para convertirlas en URLs adecuadas y descargar la lista completa en nuestro nuevo directorio.
Asimismo, usaremos el módulo time de Python para pausar nuestro programa durante tres segundos entre las descargas.
Esta técnica es llamada “regulación” o “limitación” (throttling, en inglés).
Se considera una buena forma de no golpear el servidor de alguien con muchas solicitudes por segundo;
y el ligero retraso hace que sea más probable que todos los archivos se descarguen antes de agotar nuestro tiempo de conexión (véase time out).
Elimina la línea que dice print(urls) y pon en su lugar el código de abajo (ten en cuenta que quede sangrado exactamente donde estaba esa línea).
Agrega el siguiente código al final de la función obtener_procesos_individuales, luego de la línea que tiene urls.append(url).
Este código generará la URL de cada página individual, la descargará en tu computador en directorio ya creado,
guardará el archivo y se detendrá durante 3 segundos antes de pasar al siguiente proceso judicial.
Todo lo siguiente está contenido en un bucle for que se ejecutará una vez por cada proceso en tu lista de URLs.
# ...
from time import sleep
# ...
def obtener_procesos_individuales(consulta):
# ...
# aquí estaba antes `urls.append(url)`
for item in urls:
# genera la URL
url = "https://www.oldbaileyonline.org/print.jsp?div=" + item
# descarga la pagina
respuesta = urlopen(url)
contenido_web = respuesta.read()
# crea el nombre de archivo con la ruta del directorio nuevo
nombre_archivo = pjoin(consulta_limpia, item + '.html')
# guarda el archivo
with open(nombre_archivo, 'w', encoding='utf-8') as f2:
f2.write(contenido_web.decode('utf-8'))
# pausa durante 3 segundos
sleep(3)
(Nota que en la instrucción with open usamos la variable f2 en lugar de f.
Eso es porque todo este código está incluido en bloque with open abierto,
que ya ha definido la variable f.)
Si juntamos todo en una sola función, debería verse algo como lo que sigue.
Hemos añadido también un par de prints para ir viendo cómo avanza nuestro programa:
ef obtener_procesos_individuales(consulta):
# elimina los caracteres no alfanuméricos de la consulta
directorio = re.sub(r'\W', '', consulta)
resultados_busqueda = os.listdir(directorio)
archivos_descargados = 0
# encuentra las paginas de resultados de búsqueda
for nombre_archivo in resultados_busqueda:
urls = []
if 'resultado_consulta' in nombre_archivo:
print(f'Examinando el documento {nombre_archivo}...')
nombre_archivo_completo = pjoin(directorio, nombre_archivo)
with open(nombre_archivo_completo, 'r') as f:
texto = f.read().split(' ')
# busca las IDs de los procesos judiciales
for palabra in texto:
# if re.search(r'browse\.jsp\?id=', palabra):
if 'browse.jsp?id=' in palabra:
# aísla la ID
captura = re.search(r'id=(.+?)&', palabra)
url = captura.group(1)
urls.append(url)
for item in urls:
# genera la URL
url = "https://www.oldbaileyonline.org/print.jsp?div=" + item
# descarga la pagina
respuesta = urlopen(url)
contenido_web = respuesta.read()
# crea el nombre de archivo con la ruta del directorio nuevo
nombre_archivo = pjoin(directorio, item + '.html')
# guarda el archivo
with open(nombre_archivo, 'w', encoding='utf-8') as f2:
f2.write(contenido_web.decode('utf-8'))
print(f' {nombre_archivo} ha sido guardado.')
archivos_descargados += 1
# pausa durante 3 segundos
sleep(3)
print(f'{archivos_descargados} archivos descargados')
Ahora agreguemos la misma pausa de tres segundos a nuestra función obtener_resultados_consulta para ser amables con los servidores del OBO:
# crea URLs para las paginas de resultados de consulta y guarda los archivos
def obtener_resultados_consulta(consulta, kwparse, from_year, from_month, to_year, to_month, entradas):
start_value = 0
# elimina los caracteres no alfanuméricos
directorio = re.sub(r'\W', '', consulta)
# crea un directorio con un nombre seguro si no existe ya
if not os.path.exists(directorio):
os.makedirs(directorio)
# determina la cantidad de archivos que debemos descargar
contar_paginas = entradas // 10
residuo = entradas % 10
if residuo > 0:
contar_paginas += 1
for pagina in range(contar_paginas):
# separa cada parte del URL para leerlo mejor
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += consulta
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + from_year
url += '&fromMonth=' + from_month
url += '&toYear=' + to_year
url += '&toMonth=' + to_month
url += '&start=' + str(start_value)
url += '&count=0'
# descarga y guarda el resultado
respuesta = urlopen(url)
contenido_web = respuesta.read()
nombre_archivo = pjoin(directorio, 'resultado_consulta' + str(pagina) + '.html')
with open(nombre_archivo, 'w', encoding='utf-8') as f:
f.write(contenido_web.decode('utf-8'))
start_value += 10
# pausa durante 3 segundos
sleep(3)
Finalmente, llama a la función desde el programa descarga_consultas.py.
# descarga_consultas.py
import obo
consulta = 'mulatto*+negro*'
obo.obtener_resultados_consulta(consulta, 'advanced', '1700', '00', '1750', '99', 13)
obo.obtener_procesos_individuales(consulta)
Has creado un programa que puede solicitar y descargar archivos del sitio web del OBO, según los parámetros de búsqueda que definiste, ¡todo sin visitar manualmente el sitio!
Si los archivos no se descargan
Comprueba que los 13 archivos se hayan descargado correctamente. Ábrelos en tu navegador web y verifica que estén bien. Si es así, ¡genial! Sin embargo, existe la posibilidad de que el programa se atore en el proceso. Esto se debe a que, aunque el programa se ejecute en nuestra propia máquina, se basa en dos factores que están fuera de nuestro control inmediato: la velocidad de Internet y el tiempo de respuesta del servidor del OBO en ese momento. Una cosa es pedirle a Python que descargue un solo archivo; pero cuando le pedimos que descargue un archivo cada 3 segundos, existe una gran probabilidad de que el servidor agote el tiempo de conexión o no nos envíe el archivo que buscamos.
Si estuviéramos usando un navegador web para hacer estas solicitudes, eventualmente recibiríamos un mensaje diciendo: “La conexión se ha agotado” o algo por el estilo. Todos vemos esto de vez en cuando. Sin embargo, nuestro programa no está diseñado para manejar o transmitir dichos mensajes de error. En su lugar, te darás cuenta de que algo malo pasa, cuando descubras que el programa no ha devuelto el número esperado de archivos o que simplemente no hace nada. Para evitar la frustración y la incertidumbre, queremos un programa a prueba de fallas que intente descargar cada proceso judicial. Si por alguna razón falla, lo anotaremos y pasaremos al siguiente proceso.
Para hacer esto, haremos uso del mecanismo de manejo de errores y excepciones (try/except) de Python (ver errores y excepciones),
así como otro módulo de Python socket.
try/except se parece mucho a una declaración if/else.
Cuando le pides a Python que pruebe algo (try), intentará ejecutar el código.
Si el código no logra hacer lo que se ha definido, ejecutará el código except.
Esto se conoce como manejo de errores y se usa con mucha frecuencia.
Podemos tomar ventaja de esto diciéndole a nuestro programa que intente descargar una página.
Si esto falla, le pediremos que nos informe qué archivo no se pudo descartar y luego seguiremos adelante.
Para esto necesitamos usar el módulo socket, que nos permitirá poner un límite de tiempo en un intento de descarga antes de continuar. Esto implica alterar la función obtener_procesos_individuales.
Primero debemos importar el módulo socket, lo que debe hacerse de la misma manera que todas nuestras importaciones de módulos anteriores.
También tendremos que establecer la duración predeterminada del tiempo de espera de socket:
cuánto tiempo intentaremos descargar una página antes de darnos por vencidos.
Esto debe escribirse inmediatamente después del comentario # descarga la página
# ...
import socket
#...
# descarga la página
socket.setdefaulttimeout(10)
A continuación, agregaremos la declaración try/except.
En este caso, pondremos todo el código diseñado para descargar y guardar los procesos judiciales en la declaración try, y en la declaración except le diremos al programa lo que queremos que haga si eso falla.
Aunque podríamos dejar la línea de la excepción de manera genérica (simplemente con un except:),
Python recomienda
especificar el tipo de excepción ocurrida.
Para ello usamos except OSError as msg:.
Esto nos dice que la excepción es de tipo OSError y guardará los detalles en la variable msg.
#...
for item in urls:
# genera la URL
url = "https://www.oldbaileyonline.org/print.jsp?div=" + item
# descarga la pagina
socket.setdefaulttimeout(10)
try:
respuesta = urlopen(url)
contenido_web = respuesta.read()
# crea el nombre de archivo con la ruta del directorio nuevo
nombre_archivo = pjoin(directorio, item + '.html')
# guarda el archivo
with open(nombre_archivo, 'w', encoding='utf-8') as f2:
f2.write(contenido_web.decode('utf-8'))
print(f' {nombre_archivo} ha sido guardado.')
archivos_descargados += 1
except OSError as msg:
print(msg)
print(f'Ha habido un error descargando el archivo {url}')
# pausa durante 3 segundos
sleep(3)
Si surge un problema al descargar un determinado archivo, recibirás un mensaje en el terminal. Si solo hay uno o dos archivos no descargados, probablemente sea más rápido visitar las páginas manualmente y usar la función “Guardar como…” de tu navegador. Pero si tienes espíritu de aventura puedes modificar el programa para descargar automáticamente los archivos restantes.
El archivo obo.py terminado deberá verse como esto:
# obo.py
from urllib.request import urlopen
import os
from os.path import join as pjoin
from time import sleep
import re
import socket
# crea URLs para las paginas de resultados de consulta y guarda los archivos
def obtener_resultados_consulta(consulta, kwparse, from_year, from_month, to_year, to_month, entradas):
start_value = 0
# elimina los caracteres no alfanuméricos
directorio = re.sub(r'\W', '', consulta)
# crea un directorio con un nombre seguro si no existe ya
if not os.path.exists(directorio):
os.makedirs(directorio)
# determina la cantidad de archivos que debemos descargar
contar_paginas = entradas // 10
residuo = entradas % 10
if residuo > 0:
contar_paginas += 1
for pagina in range(contar_paginas):
# separa cada parte del URL para leerlo mejor
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += consulta
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + from_year
url += '&fromMonth=' + from_month
url += '&toYear=' + to_year
url += '&toMonth=' + to_month
url += '&start=' + str(start_value)
url += '&count=0'
# descarga y guarda el resultado
respuesta = urlopen(url)
contenido_web = respuesta.read()
# cadena_pagina = ''
# if 0 <= pagina <= 9:
# cadena_pagina = '00' + str(pagina)
# elif 10 <= pagina <= 99:
# cadena_pagina = '0' + str(pagina)
nombre_archivo = pjoin(directorio, 'resultado_consulta' + str(pagina) + '.html')
with open(nombre_archivo, 'w', encoding='utf-8') as f:
f.write(contenido_web.decode('utf-8'))
start_value += 10
# pausa durante 3 segundos
sleep(3)
def obtener_procesos_individuales(consulta):
# elimina los caracteres no alfanuméricos de la consulta
directorio = re.sub(r'\W', '', consulta)
resultados_busqueda = os.listdir(directorio)
archivos_descargados = 0
# encuentra las paginas de resultados de búsqueda
for nombre_archivo in resultados_busqueda:
urls = []
if 'resultado_consulta' in nombre_archivo:
print(f'Examinando el documento {nombre_archivo}...')
nombre_archivo_completo = pjoin(directorio, nombre_archivo)
with open(nombre_archivo_completo, 'r') as f:
texto = f.read().split(' ')
# busca las IDs de los procesos judiciales
for palabra in texto:
# if re.search(r'browse\.jsp\?id=', palabra):
if 'browse.jsp?id=' in palabra:
# aísla la ID
captura = re.search(r'id=(.+?)&', palabra)
url = captura.group(1)
urls.append(url)
for item in urls:
# genera la URL
url = "https://www.oldbaileyonline.org/print.jsp?div=" + item
# descarga la pagina
socket.setdefaulttimeout(10)
try:
respuesta = urlopen(url)
contenido_web = respuesta.read()
# crea el nombre de archivo con la ruta del directorio nuevo
nombre_archivo = pjoin(directorio, item + '.html')
# guarda el archivo
with open(nombre_archivo, 'w', encoding='utf-8') as f2:
f2.write(contenido_web.decode('utf-8'))
print(f' {nombre_archivo} ha sido guardado.')
archivos_descargados += 1
except OSError as msg:
print(msg)
print(f'Ha habido un error descargando el archivo {url}')
# pausa durante 3 segundos
sleep(3)
print(f'{archivos_descargados} archivos descargados')
Próximos pasos: usar una interfaz de programación de aplicaciones (API)
Para usuarias/os más avanzadas/os, o para adquirir más destreza, vale la pena leer acerca de cómo lograr este mismo proceso utilizando las interfaces de programación de aplicaciones (API). Un sitio web con una API generalmente proporcionará instrucciones sobre cómo solicitar ciertos documentos. Es un proceso muy similar al que acabamos de hacer interpretando las cadenas de consulta de URL, pero sin el trabajo adicional de detective que hicimos para descifrar el comportamiento de cada variable. Si tienes interés en el OBO, el sitio cuenta con una buena API y su documentación es muy útil.
Notas
-
El Tribunal Penal Central de Inglaterra y Gales es conocido también como el OBO, por la calle en la que está ubicada en Londres. El sitio web del OBO contiene los registros judiciales de dicho tribunal desde 1674 hasta* 1913. (N. de T.) ↩
-
Hemos dejado los términos de búsqueda en inglés, ya que son los que arrojan resultados en la página web de Old Bailey Online. (N. de T.) ↩
-
El eufemismo “n-word” se refiere a una de las palabras más ofensivas que existe en lengua inglesa para designar a los afrodescendientes. Puede verse una explicación aquí. (N. de T.) ↩
-
Aquí usaremos el término “variable de servidor” para las variables que se asignan en un URL y que son procesados por el servidor (PhP, Ruby on Rails, Flask, etc.). En el caso del OBO, los nombres de estas siguen la convención del camelCase o letra de caja camello; por ejemplo:
fromYear,toYear,fromMonth,toMonth, etc. Por el contrario, llamaremos simplemente “variables” a las variables de Python. La convención de Python es no usar camelCase para sus nombres sino usar guiones bajos_para mejorar la legibilidad; en nuestro caso,from_year,to_year,from_month,to_month, etc. ↩ -
La función
rangede Python crea una secuencia inmutable de números que puede ser usada como iterador en un buclefor.rangetoma un argumento obligatorio: el valor de parada. Este valor siempre es una unidad menor que el valor de parada. El valor inicial de la secuencia es por defecto 0. Así, por ejemplo,range(3)creará la siguiente secuencia inmutable:0, 1, 2, puesto que 2 es una unidad menor que el valor de parada 3.rangetambién puede tomar un valor inicial distinto como primer argumento de función (aunque es opcional). Por ejemplo,range(1, 3)creará la secuencia:1, 2. Es por esto que en el ejemplo del código de la lección necesitamos la expresiónrange(1, contar_paginas + 1). Esta expresión crea una secuencia que empieza en 1 y se detiene e incluye el valor de la variablecontar_paginas. Por ejemplo, sicontar_paginases 3, la expresiónrange(1, contar_paginas + 1)equivaldrá arange(1, 4), que en efecto creará la secuencia1, 2, 3. Por lo tanto, el buclefor pagina in range(1, contar_paginas + 1)iterará tres veces: una vez por cada página de resultados. ↩ -
Más adelante, en la función
obtener_procesos_individuales, procesaremos una a una las páginas descargadas, buscando las URLs de los procesos judiciales en la OBO. Será importante que los procesemos en el mismo orden en que los descargamos:resultado_consulta0.html,resultado_consulta1.html,resultado_consulta2.html, etc. Cuando lleguemos aresultado_consulta10.htmlnos encontraremos con un problema. Como el orden de procesamiento de archivos ocurre por orden alfabético (pues así se ordenan por defecto en los directorios),resultado_consulta10.htmlserá procesado luego deresultado_consulta1.htmly antes deresultado_consulta2.html. Para el ejemplo de esta lección eso no será un problema, porque solo tenemos dos páginas de consulta (dado que hay 13 registros). Si quisiéramos blindar nuestro código para búsquedas con más de 99 registros, debemos asegurarnos de que el orden de procesamiento sea el correcto. Una forma sencilla de hacerlo así:cadena_pagina = '' if 0 <= pagina <= 9: cadena_pagina = '00' + str(pagina) elif 10 <= pagina <= 99: cadena_pagina = '0' + str(pagina) nombre_archivo = 'resultado_consulta' + str(cadena_pagina) + '.html'Básicamente, lo que hace es añadir la cadena “00” para los primeros diez archivos (de
resultado_consulta000.htmlaresultado_consulta009.html) y la cadena “0” para los siguientes 90 archivos (deresultado_consulta010.htmlaresultado_consulta099.html). ↩ -
La
ren la expresiónr'\W'establece que'\W'es una “cadena cruda” (raw string), lo que facilita en general el trabajo con expresiones regulares. Al respecto véasen https://docs.python.org/3/library/re.html y https://blog.devgenius.io/beauty-of-raw-strings-in-python-fa627d674cbf ↩