
Contenidos
- Nota del editor
- Objetivos de la lección
- Primer paso: la instalación
- Segundo paso: Aprender acerca de la estructura de Wget - Descargar un conjunto específico de archivos
- Una herramienta flexible para descargar fuentes de Internet
Nota del editor
Esta lección requiere que uses la línea de comandos. Si no tienes experiencia previa en el uso de la línea de comandos, será útil estudiar la lección Introducción a la línea de comandos en Bash, en The Programming Historian en español.
Objetivos de la lección
Esta lección está diseñada para usuarias/os intermedias/os, aunque pueden seguirla principiantes.
Wget es un programa útil, que se ejecuta a través de la línea de comandos de tu computadora y sirve para recuperar material en línea.
Intérprete de línea de comandos, Terminal, en Mac
Puede ser de utilidad en las siguientes situaciones:
- Recuperar o duplicar (crear una copia exacta) de un sitio web completo. Este sitio web puede contener documentos históricos, o simplemente puede ser tu propio sitio web personal del que deseas hacer una copia de seguridad. Un comando u orden puede descargar todo el sitio en tu computadora.
- Descargar archivos específicos de la jerarquía de un sitio web (cierta parte del sitio web como, por ejemplo, cada página que se encuentre dentro del directorio
/papeles/del sitio).
En esta lección trabajaremos con tres ejemplos rápidos de cómo puedes usar wget en tu trabajo. Al final de la lección podrás descargar rápidamente grandes cantidades de información de Internet de manera automatizada. Si encuentras un repositorio de información histórica en línea, en lugar de hacer clic con el botón derecho en cada archivo y guardarlo para construir tu conjunto de datos, tendrás las habilidades para elaborar un solo comando que descargue todo.
Primero, algunas precauciones. Debes tener cuidado de cómo usas wget. Si consultas el manual en caso de duda y repasas la lección aquí, está bien. Siempre debes generar un retraso en tus comandos para no sobrecargar los servidores y también debes poner un límite a la velocidad de descarga. Todo esto es parte del ser un buen ciudadano de Internet. Podemos pensar en la analogía de utilizar una toma de agua con prudencia en vez de abrir todas las llaves al mismo tiempo (no es bueno para ti ni para la compañía de agua).
Trata de específicar de la mejor manera posible la formulación de tu descarga. Hay por ahí un chiste que sugiere que puedes descargar accidentalmente ¡todo Internet con wget! Es un poco exagerado, ¡pero no está demasiado lejos!
Comencemos.
Primer paso: la instalación
Instrucciones para Linux
Si usas Linux ya debes tener instalado wget. Compruébalo abriendo tu línea de comandos. Escribe wget y presiona enter. Si tienes instalado wget el sistema responderá:
-> Missing URL.
si no está instalado verás:
-> command not found.
Si usas OS X o Windows tienes que descargar el programa. Usuarias/os de Linux sin wget deben seguir las instrucciones para OS X a continuación.
Instrucciones para OS X
Opción uno en OS X: el método preferido
En OS X hay dos formas de obtener wget e instalarlo. Lo más fácil es instalar un administrador de paquetes y usarlo para instalar wget automáticamente. Hay un segundo método, que se discute más adelante, que involucra compilarlo.
Sin embargo, para un correcto funcionamiento de ambos métodos se requiere que instales las ‘Herramientas para línea de comandos’ de Apple. Esto implica descargar XCode. Si tienes el ‘App Store’, puedes descargar XCode a través de este enlace. Si no, las siguientes instrucciones funcionarán.
Para descargar XCode, ve al sitio web de desarrolladores de Apple, regístrate como desarrollador y luego en la sección descargas para desarrolladores de Apple necesitarás encontrar la versión correcta. Si estás en la versión más reciente, Lion a partir de julio de 2012,1 puedes utilizar el enlace principal. De lo contrario, deberás hacer clic en el enlace: “¿Está buscando herramientas de desarrollador adicionales? Ver descargas”.
Después de iniciar sesión con tus credenciales de desarrollador gratuitas verás una larga lista. Escribe “xcode” en la barra de búsqueda y encuentra la versión que sea compatible con la versión de tu sistema operativo. Encontrar la versión correcta para ti puede tomar algunos clics. Por ejemplo, Xcode 3.2 es la versión para OS X 10.6 Snow Leopard, 3.0 es la versión para OS X 10.5 Leopard, etc.
Es una descarga muy grande y tomará algún tiempo en completarse. Una vez que tengas el archivo, instálalo.
Deberás instalar el kit ‘Command Line Tools’ de XCode. Abre la pestaña ‘Preferencias’, haz clic en ‘Descargas’ y luego en ‘Instalar’ junto a ‘Herramientas de línea de comandos’. Ahora estamos listos para instalar un gestor de paquetes.
El gestor de paquetes más fácil de instalar es Homebrew. Ve a https://brew.sh/es/ y revisa las instrucciones. Hay muchos comandos importantes, como wget, que no están incluidos de forma predeterminada en OS X. Este programa facilita la descarga y la instalación de todos los archivos necesarios.
Para instalar Homebrew, abre la ventana de Terminal y escribe:
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Esta instalación de Hombrew utiliza el lenguaje de programación Ruby, integrado en OS X. Para ver si la instalación fue correcta, escribe la siguiente orden en la ventana de tu Terminal:
brew
Si se ha instalado bien, debe aparecer una lista de opciones de documentación. Pero aún tenemos que ejecutar otro comando para asegurarnos de que todo funcione:
brew doctor
Con Homebrew listo podemos instalar wget, que ahora será un paso fácil.
brew install wget
Se procederá a descargar la versión más reciente de wget, que es wget 1.14.2 Después de que la secuencia de comandos deje de ejecutarse y vuelva a la ventana principal, escribe el siguiente comando en la terminal:
wget
Si se instaló verás:
-> Missing URL.
Si no, verás:
-> command not found.
En este punto, deberías haber instalado wget correctamente. ¡Ahora todo está listo para seguir!
Opción dos para OS X
Si por alguna razón no deseas instalar un administrador de paquetes, puedes descargar solo wget. Esto será apropiado si estás utilizando un administrador de paquetes diferente (como Mac Ports) o si deseas mantener tu infraestructura al mínimo. Sigue las mismas instrucciones para instalar Xcode y el conjunto de herramientas de línea de comandos.
Luego puedes descargar una versión no compilada de wget desde el sitio web de GNU. Yo elegí descargar el archivo wget-1.13.tar.gz, que puedes encontrar siguiendo el enlace a cualquier página de descarga, ya sea HTTP o FTP). Descomprime haciendo doble clic en el archivo en tu directorio de inicio. En una Mac, este será su directorio: /user/; por ejemplo, mi nombre de usuario es ianmilligan y aparece junto a un icono de casa en mi Finder. Luego abre Terminal. Para este tutorial, hemos descargado wget-1.13.
Tenemos que navegar primero al directorio en el que se encuentran los archivos wget. En la terminal, escribe:
cd wget-1.13
Ten en cuenta que si has descargado una versión diferente de wget, los siguientes pasos funcionarán pero tendrás que reemplazar el número de la versión (aquí 1.13) por el tuyo.
Ahora necesitamos generar las instrucciones, o makefile, para el archivo. Esto es una especie de boceto del aspecto que tendrá el archivo final. Escribe:
./configure –with-ssl=openssl
Ahora que tenemos el proyecto abocetado, ordenemos a la computadora que lo siga. Escribe:
make
Ahora necesitas crear el archivo final. Al escribir antes el comando sudo, estás ejecutando los comandos siguientes con los privilegios de seguridad más altos. Esto le permite a la computadora instalar el archivo en tu sistema.
sudo make install
En este punto del proceso tendrás que introducir la contraseña de tu computadora en el prompt que aparezca. Escríbela.
Deberás haber instalado wget.
Instrucciones para Windows
La forma más fácil es descargar una versión funcional. Para hacerlo, visita este sitio web y descarga la última versión de wget.exe utilizando los archivos de instalación adecuados para tu computadora. Puedes averiguar si necesitas el binario de 32 o 64 bits comprobando las especificaciones de tu dispositivo o realizando una búsqueda en Internet.
Si colocas wget.exe en tu directorio C:\Windows, puedes usar wget desde cualquier lugar de tu computadora. Esto hará tu vida más fácil ya que no tendrás que preocuparte por ejecutar siempre wget desde un solo lugar en tu sistema. Si está en este directorio, Windows sabrá que el comando se puede usar en cualquier parte en el que se encuentra la ventana de tu terminal.
Segundo paso: Aprender acerca de la estructura de Wget - Descargar un conjunto específico de archivos
En este punto, las personas usuarias de las tres plataformas deben estar en la misma página. Usamos wget a través de la interfaz de línea de comandos de nuestro sistema operativo (introducido anteriormente como Terminal para usuarios de Mac y Linux, donde ha estado jugando con algunos comandos de Python). Debes usar su línea de comandos en lugar de Komodo Edit que puedes haber usado en otras lecciones.
La documentación completa para wget se puede encontrar en la página del Manual de wget de GNU.
Tomemos un ejemplo de conjunto de datos. Digamos que deseas descargar todos los documentos alojados en el sitio web ActiveHistory.ca. Todos están ubicados en: http://activehistory.ca/papers/; en el sentido de que están todos contenidos en el directorio /papers/. Por ejemplo, el noveno documento publicado en el sitio web es http://activehistory.ca/papers/historypaper-9/. Piensa en esta estructura de la misma forma que los directorios en tu propia computadora. Si tienes una carpeta con la etiqueta /Historia/, es probable que contenga varios archivos dentro de ella. La misma estructura es válida para los sitios web y estamos usando esta lógica para decirle a nuestra computadora qué archivos queremos descargar.
Si deseas descargarlos todos manualmente deberás escribir un programa personalizado o hacer clic derecho en cada papel para hacerlo. Si los archivos están organizados de una manera que se ajuste a tus necesidades de investigación, wget es el abordaje más rápido.
Para asegurarte que wget está trabajando, prueba lo siguiente.
En tu directorio de trabajo, crea un nuevo directorio. Llamémoslo wget-activehistory. Puedes hacer esto utilizando tu Finder / Windows, o si estás en una ventana de Terminal en esa ruta, puedes escribir:
mkdir wget-activehistory
Ahora tienes un directorio en el que trabajaremos. Abre la interfaz de la línea de comandos y navega al directorio wget-activehistory. Como recordatorio, recuerda que puedes escribir:
cd [directory]
… para navegar a un directorio determinado. Si has creado este directorio en tu directorio de inicio, al escribir cd wget-activehistory podrás moverte a tu nuevo directorio.
Escribe la orden siguiente:
wget http://activehistory.ca/papers/
Después de algunos mensajes iniciales, verás algo parecido a lo siguiente (por supuesto que las cifras, las fechas y algunos detalles serán diferentes):
Saving to: `index.html.1'
[] 37,668 --.-K/s in 0.1s
2012-05-15 15:50:26 (374 KB/s) - `index.html.1' saved [37668]
Wget descargó la primera página de http://activehistory.ca/papers/, que contiene el índice de los documentos, a tu nuevo directorio. Si lo abres, verás el texto principal en la página de inicio de ActiveHistory.ca. Así que de un golpe ya hemos descargado algo rápidamente.
Pero lo que queremos hacer ahora es descargar cada uno de los papeles. Así que necesitamos agregar algunos comandos a wget.
Wget opera sobre las siguientes bases generales:
wget [options] [URL]
Acabamos de aprender cosas sobre el componente [URL] en el ejemplo anterior, ya que le indica al programa a dónde ir. Sin embargo, las opciones le dan al programa un poco más de información sobre lo que queremos hacer. El programa sabe que una opción es una opción por la presencia de un guión antes de la variable. Esto le permite saber la diferencia entre la URL y las opciones. Así que vamos a aprender algunos comandos ahora:
-r
La recuperación recursiva es la parte más importante de wget. Lo que esto significa es que el programa comienza siguiendo los enlaces del sitio web y también los descarga. Entonces, por ejemplo, http://activehistory.ca/papers/ tiene un enlace a http://activehistory.ca/papers/historypaper-9/, por lo que también se descargará si utilizamos la recuperación recursiva. Sin embargo, también seguirá a cualquier otro enlace: si hubiera un enlace a http://uwo.ca en algún lugar de esa página, seguiría eso y lo descargaría también. De forma predeterminada, -r envía wget a una profundidad de cinco sitios después del primero. Esto es siguiendo los enlaces, hasta un límite de cinco clics después del primer sitio web. En este punto, será bastante indiscriminado. Así que necesitamos más comandos:
--no-parent
(El doble guión indica el texto completo de un comando. Todos los comandos también tienen una versión corta, éste podría iniciarse usando -np).
Esto es muy importante. Quiere decir que wget debe seguir los enlaces pero no más allá del último directorio principal. En nuestro caso, eso significa que no irá a ninguna sitio que no sea parte de la jerarquía de http://activehistory.ca/papers/. Si se tratara de una ruta larga como http://niche-canada.org/projects/events/new-events/not-yet-happened-events/, solo encontraría archivos en la carpeta /not-yet-happened-events/. Es un comando crítico para delimitar tu búsqueda.
Aquí una representación gráfica:
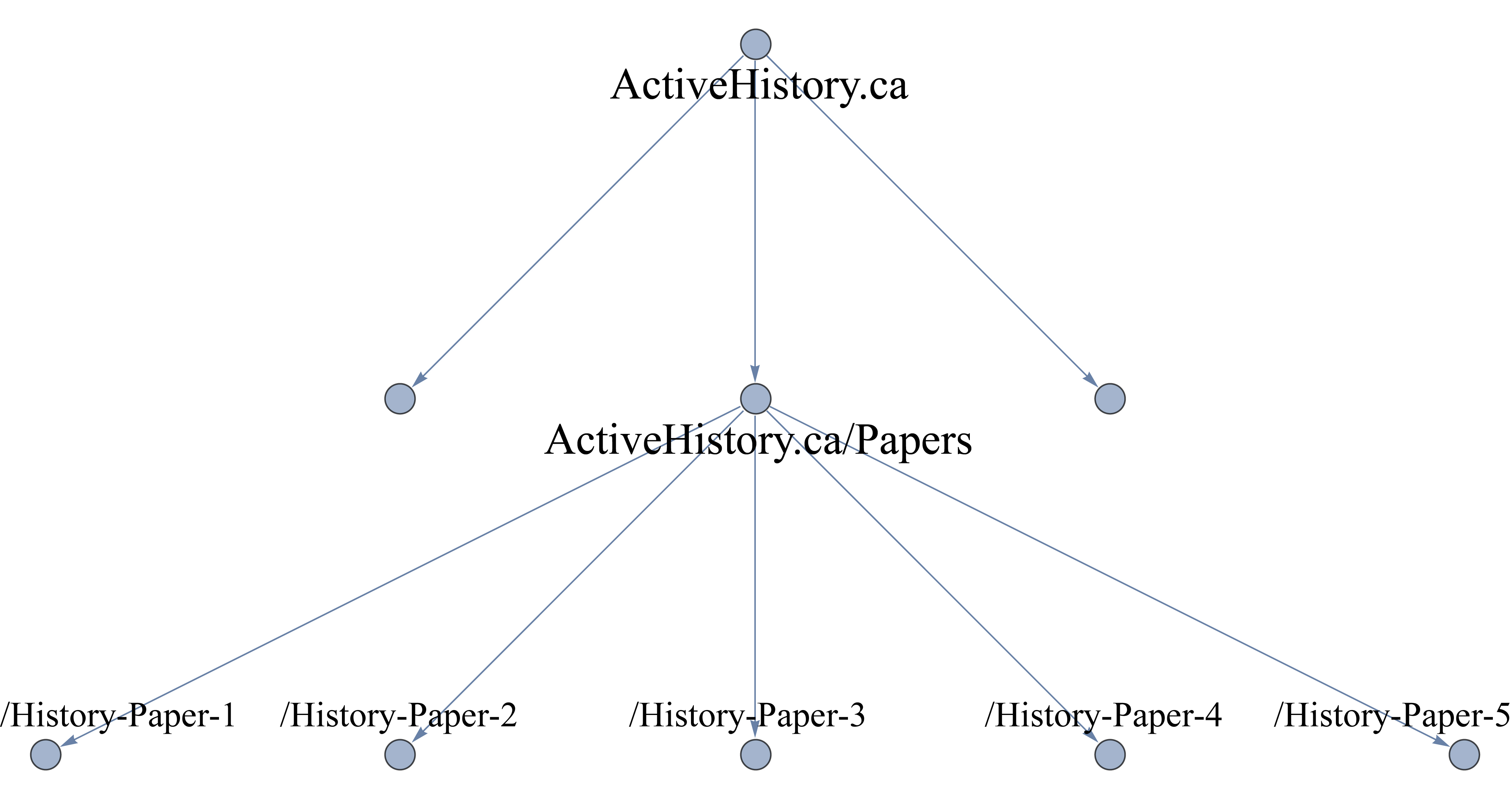
Representación gráfica de cómo trabaja el comando ‘no-parent’ en wget
Finalmente, si deseas navegar fuera de una jerarquía, es mejor delimitar qué tan lejos quieres ir. El valor predeterminado es seguir cada enlace y mantener un límite de cinco páginas desde la primera página. Sin embargo, tal vez solo quieras seguir un enlace y detenerte allí. En ese caso, podría escribir -l 2, lo cual nos lleva a una profundidad de dos páginas web. Ten en cuenta que esto es una ‘L’ minúscula, no un número 1.
-l 2
Si estos comandos ayudan a dirigir wget, también debemos agregar algunos más para ser amables con los servidores y para evitar que las contramedidas automáticas del sitio detecten que el servidor está siendo atacado. Para ello, hay dos comandos esenciales adicionales:
-w 10
No es correcto solicitar demasiadas peticiones a la vez a un servidor web. También hay otras personas que esperan información, por lo que es importante compartir la carga. El comando -w 10 marca una espera de diez segundos entre las solicitudes que hacemos al servidor. Puedes acortar esto, ya que diez segundos es bastante largo. En mis propias búsquedas, a menudo uso una espera de 2 segundos. En raras ocasiones, puede encontrarse con un sitio que bloquee la descarga automática por completo. Los términos de servicio del sitio web, que debes consultar, pueden no mencionar una política de descarga automatizada. Pero los pasos para prohibirlo pueden incorporarse en la arquitectura de su sitio web. En casos tan raros, puede usar el comando ––random-wait que variará la espera entre 0,5 y 1,5 veces el valor que proporciones aquí.
Otro aspecto crítico es limitar el ancho de banda que utilizarás en la descarga:
--limit-rate=20k
Este es otro comando importante y “educado”. No deseas utilizar demasiado ancho de banda de los servidores. Por lo tanto, este comando limitará la velocidad máxima de descarga a 20kb por segundo. La opinión varía acerca de cuál es una tasa límite adecuada. Probablemente podríamos llegar hasta unos 200 kb por segundo para archivos pequeños. Sin embargo, para no cargar demasiado al servidor, vamos a mantentenerlo en 20k. ¡Esto también nos mantendrá felices en ActiveHistory.ca!
Tercer paso: copia (mirror) de un sitio completo
Considerando todo esto descarguemos todos los documentos de ActiveHistory.ca. Ten en cuenta que la barra diagonal final en la URL es crítica. Si la omites, wget pensará que los documentos son un archivo en lugar de un directorio. Los directorios terminan en barras. Los archivos no lo hacen. El comando descargará la página completa de ActiveHistory.ca. El orden de las opciones no importa.
wget -r --no-parent -w 2 --limit-rate=20k http://activehistory.ca/papers/
Va a ser más lento que antes, pero tu terminal comenzará a descargar todos los documentos de ActiveHistory.ca. Cuando haya terminado, debes tener un directorio etiquetado como ActiveHistory.ca que contendrá el subdirectorio /papers/ perfectamente reflejado en tu sistema. Este directorio aparecerá en la ubicación desde la que ejecutaste el comando en tu línea de comandos, por lo que es probable que esté en tu directorio USER. Los enlaces serán reemplazados por enlaces internos a las otras páginas que ha descargado, por lo que realmente puedes tener un sitio ActiveHistory.ca completamente operativo en tu computadora. Esto te permite comenzar a jugar con él sin preocuparte por tu velocidad de internet.
Para saber si la descarga fue un éxito, también tendrás un registro en la pantalla de comandos. Echa un vistazo para asegurarte de que todos los archivos se descargaron correctamente. Si no se han descargado, te avisará que has fallado.
Si quieres descargar un sitio web completo, hay un comando incorporado para wget que te lo permite.
-m
Este comando significa “espejo” (mirror) y es muy útil para hacer copias de seguridad de un sitio web completo. Introduce el siguiente conjunto de comandos: marcado de tiempo(time stamping), que analiza la fecha del sitio y no lo reemplaza si ya tienes esa versión en tu sistema (que es muy útil para descargas repetidas), así como una recursión infinita (irá por tantas capas en el sitio como sea necesario). El comando para copiar completo el sitio ActiveHistory.ca sería:
wget -m -w 2 --limit-rate=20k http://activehistory.ca
Una herramienta flexible para descargar fuentes de Internet
A medida que tengas más comodidad usando la línea de comandos, verás que wget es un agregado útil a tu conjunto de herramientas digitales. Si hay un corpus completo de documentos de archivo que deseas descargar para minería de texto, si están organizados en un directorio y están todos juntos (lo que no es tan común como podría pensarse), con un comando wget rápido esto será más eficaz que hacer scraping en los enlaces con Python. Asimismo, puedes comenzar a descargar cosas directamente desde tu línea de comandos: programas, archivos, copias de seguridad, etc.
Otras lecturas
Aquí solo he dado una instantánea de algunas de las funcionalidades de wget. Para más información, consulta el manual de wget.