
Conteúdos
- Introdução
- Pré-requisitos
- Objetivos de Aprendizagem
- Arquivo.pt
- Conta-me Histórias
- Conclusões
- Prémios
- Financiamento
- Bibliografia
Introdução
Ao longo dos séculos a comunicação evoluiu paralelamente à evolução do homem. Esta, que antes se fazia a partir de meios físicos, é hoje digital e tem presença online. A “culpa” é da web, que desde o final dos anos 90 do século passado, se tornou na principal fonte de informação e comunicação do século XXI. Porém, cerca de 80% da informação disponível na web desaparece ou é alterada no prazo de apenas 1 ano (em inglês). Este facto origina a perda de informação fundamental para documentar os eventos da era digital.
A mudança para um paradigma de comunicação baseado na internet obrigou a uma alteração profunda na forma como as informações publicadas são preservadas. Os arquivos da web assumem especial relevância, ao preservarem as informações publicadas online desde a década de 1990.
Apesar dos avanços recentes na preservação de informações arquivadas a partir da web, o problema de explorar de forma eficiente o património histórico preservado por estes arquivos permanece por resolver devido às enormes quantidades de dados históricos arquivados ao longo do tempo e à inexistência de ferramentas que possam processar automaticamente esse volume de dados. Neste contexto, as timelines (sistemas automáticos de sumarização temporal) surgem como a solução ideal para a produção automática de resumos de eventos ao longo do tempo e para a análise das informações publicadas online que os documentam, como é o caso das notícias.
Neste tutorial, pretendemos mostrar como explorar o Arquivo.pt, o arquivo da web portuguesa, e como criar automaticamente resumos de eventos do passado a partir de conteúdos históricos arquivados da web. Mais concretamente, demonstraremos como obter resultados relevantes ao combinar o uso da API (Interface de Programação de Aplicações) do Arquivo.pt com a utilização do Conta-me Histórias, um sistema que permite criar automaticamente narrativas temporais sobre qualquer tema objeto de notícia. Para a concretização desse objetivo disponibilizamos um Jupyter Notebook que os usuários poderão usar para interagir com ambas as ferramentas.
Na primeira parte do tutorial, iremos apresentar sumariamente as funções de pesquisa e acesso disponibilizadas pelo Arquivo.pt. Demonstraremos como podem ser utilizadas de forma automática através da invocação dos métodos disponibilizados pela API do Arquivo.pt, recorrendo a exemplos simples e práticos. A pesquisa automática de palavras em páginas arquivadas ao longo do tempo é o serviço base para desenvolver rapidamente aplicações informáticas inovadoras, que permitem explorar e tirar maior partido da informação histórica preservada pelo Arquivo.pt, como é caso do projeto Conta-me Histórias.
Na segunda parte, recorremos ao Conta-me Histórias para exemplificar o processo de sumarização temporal de um evento. Nesse sentido, demonstraremos a forma como os usuários podem obter informações históricas resumidas sobre um determinado tópico (por exemplo, sobre Jorge Sampaio, presidente da República Portuguesa entre 1996 e 2006), que envolva notícias do passado preservadas pelo Arquivo.pt. Uma tal infraestrutura permite aos usuários ter acesso a um conjunto de informações históricas a partir de páginas web que, muito provavelmente, já não existirão naquela que convencionalmente designamos como a web atual.
Pré-requisitos
A participação neste tutorial pressupõe conhecimentos básicos de programação (nomeadamente Python) bem como familiarização com a instalação de pacotes python (via git (em inglês)), com o formato JSON (em inglês) e com o consumo de APIs. A execução do código pressupõe o recurso ao Jupyter Notebook. Para a instalação deste software recomendamos o tutorial Introduction to Jupyter Notebooks (em inglês) ou, em alternativa, o recurso ao Google Colab. Este tutorial foi testado com a versão 3.6.5 do Python.
Objetivos de Aprendizagem
No final deste tutorial os participantes devem estar aptos a:
- Extrair informação relevante a partir do Arquivo.pt fazendo uso da Arquivo.pt API (Full-text & URL search) (em inglês)
- Saber usar a biblioteca Python do Conta-me Histórias (em inglês) no contexto da sumarização temporal automática de eventos a partir de elevados volumes de dados preservados no arquivo da web portuguesa
Arquivo.pt
O Arquivo.pt é um serviço público e gratuito disponibilizado pela Fundação para a Ciência e a Tecnologia I.P., que permite a qualquer pessoa pesquisar e aceder a informação histórica preservada da web desde os anos 90. Embora se foque na preservação de informação de interesse para a comunidade portuguesa, contém também páginas escritas em várias línguas de interesse para a comunidade internacional e cerca de metade dos seus usuários são oriundos de fora de Portugal.
Este vídeo introduz brevemente o Arquivo.pt.
Contributos
O Arquivo.pt contém milhares de milhões de ficheiros recolhidos ao longo do tempo a partir de websites em várias línguas que documentam eventos nacionais e internacionais. Os serviços de pesquisa que fornece incluem a pesquisa de texto integral, a pesquisa de imagens, a listagem do histórico de versões, a pesquisa avançada e APIs, que facilitam o desenvolvimento por terceiros de aplicações de valor acrescentado.
Ao longo dos anos, o Arquivo.pt tem sido utilizado como recurso para suportar trabalhos de pesquisa em áreas como as Humanidades ou as Ciências Sociais. Desde 2018, o Prémio Arquivo.pt distingue anualmente trabalhos inovadores baseados na informação histórica preservada pelo Arquivo.pt. Os pesquisadores e cidadãos têm vindo a ser sensibilizados para a importância da preservação da informação publicada na web através da realização de sessões de formação gratuitas, por exemplo, sobre a utilização das APIs disponibilizadas pelo Arquivo.pt.
Todo o software desenvolvido está disponível como projetos de código-aberto gratuitos (em inglês) e, desde 2008, tem sido documentado através de artigos técnicos e científicos. No decorrer das suas atividades, o Arquivo.pt gera dados que podem ser úteis para suportar novos trabalhos de pesquisa, como por exemplo a lista de Páginas do Governo de Portugal nas redes sociais ou de websites de partidos políticos. Estes dados estão disponíveis em acesso aberto.
Este vídeo detalha os serviços públicos disponibilizados pelo Arquivo.pt. Pode também aceder diretamente aos slides da apresentação. Para saber mais detalhes acerca dos serviços disponibilizados pelo Arquivo.pt consulte:
- Módulo A: Arquivo.pt: uma nova ferramenta para pesquisar o passado (módulo A) do programa de “Formação acerca de preservação da Web” do Arquivo.pt.
Onde posso encontrar o Arquivo.pt?
O serviço Arquivo.pt encontra-se disponível a partir dos seguintes apontadores:
- Interfaces de usuário em português e inglês para aceder aos serviços de pesquisa de páginas, imagens e histórico de versões
- Website informativo acerca do Arquivo.pt
- Documentação acerca das APIs do Arquivo.pt (em inglês)
Como funciona a pesquisa automática via API?
Periodicamente, o Arquivo.pt recolhe e armazena automaticamente a informação publicada na web. A infraestrutura de hardware do Arquivo.pt está alojada no seu próprio centro de dados e é gerida por pessoal a ela dedicado a tempo inteiro.
O fluxo de trabalho de preservação é realizado através de um sistema de informação distribuído de grande escala. A informação web armazenada é processada automaticamente para realizar atividades de pesquisa sobre grandes volumes de dados (em inglês, big data), através de uma plataforma de processamento distribuído para dados não estruturados (Hadoop). Tal permite, por exemplo, a deteção automática de spam na web ou avaliar a acessibilidade web para pessoas com deficiências.
Os serviços de pesquisa e acesso via APIs permitem que os pesquisadores tirem partido desta infraestrutura de processamento e dos dados históricos preservados sem terem de endereçar a complexidade do sistema que suporta o Arquivo.pt. Este vídeo apresenta a Arquivo.pt API (Full-text & URL search) (em inglês). Pode também aceder diretamente aos slides da apresentação.
Neste tutorial iremos abordar apenas a utilização da API Full-text & URL Search do Arquivo.pt. Porém, este disponibiliza também outras APIs:
- Image Search API v1.1 (beta version) (em inglês)
- CDX-server API (URL search): international standard (em inglês)
- Memento API (URL search): international standard (em inglês)
Para saber detalhes acerca de todas as APIs disponibilizadas pelo Arquivo.pt (em inglês) consulte os conteúdos de formação disponíveis em:
- Módulo C: Acesso e processamento automático de informação preservada da Web através de APIs do programa de “Formação acerca de preservação da Web” do Arquivo.pt.
Utilização
Em seguida, apresentaremos exemplos de como utilizar a Arquivo.pt API (Full-text & URL search) (em inglês) para pesquisar, de forma automática, páginas da web arquivadas entre determinados intervalos de tempo. Como exemplo, executaremos pesquisas acerca de “Jorge Sampaio“(1939-2021), antigo Presidente da Câmara Municipal de Lisboa (1990-1995) e antigo Presidente da República Portuguesa (1996-2006).
Definição dos parâmetros de pesquisa
O parâmetro query define a(s) palavra(s) a pesquisar: Jorge Sampaio.
Para facilitar a leitura dos resultados de pesquisa obtidos iremos limitá-los a um máximo de 5 através do parâmetro maxItems.
A totalidade dos parâmetros de pesquisa disponíveis estão definidos na secção Request Parameters da documentação da API do Arquivo.pt (link em inglês. Em português, parâmetros requeridos).
import requests
query = "jorge sampaio"
maxItems = 5
payload = {'q': query,'maxItems': maxItems}
r = requests.get('http://arquivo.pt/textsearch', params=payload)
print("GET",r.url)
Percorrer os resultados obtidos no Arquivo.pt
O seguinte código mostra os resultados de pesquisa obtidos no seu formato original (JSON):
import pprint
contentsJSon = r.json()
pprint.pprint(contentsJSon)
Sumário dos resultados obtidos
É possível extrair, para cada resultado, a seguinte informação:
- Título (campo
title) - Endereço para o conteúdo arquivado (campo
linkToArchive) - Data de arquivo (campo
tstamp) - Texto extraído da página (campo
linkToExtractedText)
Todos os campos obtidos como resposta a pesquisas disponíveis estão definidos na secção Response fields da documentação da API do Arquivo.pt (link em inglês. Em português, campos de resposta).
for item in contentsJSon["response_items"]:
title = item["title"]
url = item["linkToArchive"]
time = item["tstamp"]
print(title)
print(url)
print(time)
page = requests.get(item["linkToExtractedText"])
# Note a existencia de decode, para garantirmos que o conteudo devolvido pelo Arquivo.pt (no formato ISO-8859-1) e impresso no formato (UTF-8)
content = page.content.decode('utf-8')
print(content)
print("\n")
Definir o intervalo temporal da pesquisa
Uma das mais-valias do Arquivo.pt é fornecer o acesso a informação histórica publicada na web ao longo do tempo.
No processo de acesso à informação os usuários podem definir o intervalo temporal das datas de arquivo das páginas a serem pesquisadas, através da especificação das datas pretendidas nos parâmetros de pesquisa da API from e to. Estas devem seguir o formato: ano, mês, dia, hora, minuto e segundo (aaaammddhhmmss). Por exemplo, a data 9 de março de 1996 seria representada por:
- 19960309000000
O seguinte código executa uma pesquisa por “Jorge Sampaio” de páginas arquivadas entre março de 1996 e março de 2006, período durante o qual este foi Presidente da República Portuguesa.
query = "jorge sampaio"
maxItems = 5
fromDate = 19960309000000
toDate = 20060309000000
payload = {'q': query,'maxItems': maxItems, 'from': fromDate, 'to': toDate}
r = requests.get('http://arquivo.pt/textsearch', params=payload)
print("GET",r.url)
print("\n")
contentsJSon = r.json()
for item in contentsJSon["response_items"]:
title = item["title"]
url = item["linkToArchive"]
time = item["tstamp"]
print(title)
print(url)
print(time)
page = requests.get(item["linkToExtractedText"])
# Note a existencia de decode, para garantirmos que o conteudo devolvido pelo Arquivo.pt (no formato ISO-8859-1) e impresso no formato (UTF-8)
content = page.content.decode('utf-8')
print(content)
print("\n")
Restringir a pesquisa a um determinado website
Se os usuários apenas tiverem interesse na informação histórica publicada por um determinado website, podem restringir a pesquisa através da especificação no parâmetro de pesquisa da API siteSearch. O seguinte código executa uma pesquisa por “Jorge Sampaio” de páginas arquivadas apenas a partir do website com o domínio “www.presidenciarepublica.pt”, compreendidas entre março de 1996 e março de 2006, e apresenta os resultados obtidos.
query = "jorge sampaio"
maxItems = 5
fromDate = 19960309000000
toDate = 20060309000000
siteSearch = "www.presidenciarepublica.pt"
payload = {'q': query,'maxItems': maxItems, 'from': fromDate, 'to': toDate, 'siteSearch': siteSearch}
r = requests.get('http://arquivo.pt/textsearch', params=payload)
print("GET",r.url)
print("\n")
contentsJSon = r.json()
for item in contentsJSon["response_items"]:
title = item["title"]
url = item["linkToArchive"]
time = item["tstamp"]
print(title)
print(url)
print(time)
page = requests.get(item["linkToExtractedText"])
# Note a existencia de decode, para garantirmos que o conteudo devolvido pelo Arquivo.pt (no formato ISO-8859-1) e impresso no formato (UTF-8)
content = page.content.decode('utf-8')
print(content)
print("\n")
Restringir a pesquisa a um determinado tipo de ficheiro
Além de páginas da web, o Arquivo.pt também preserva outros formatos de ficheiro vulgarmente publicados online, como por exemplo documentos do tipo PDF. Os usuários podem definir o tipo de ficheiro sobre o qual a pesquisa deverá incidir através da especificação no parâmetro de pesquisa type da API.
O seguinte código executa uma pesquisa por “Jorge Sampaio”:
- Sobre ficheiros do tipo PDF
- Arquivados apenas a partir do website com o domínio “www.presidenciarepublica.pt”
- Entre março de 1996 e março de 2006
E apresenta os resultados obtidos. Quando o usuário abrir o endereço do conteúdo arquivado fornecido pelo campo de resposta linkToArchive terá acesso ao ficheiro PDF.
query = "jorge sampaio"
maxItems = 5
fromDate = 19960309000000
toDate = 20060309000000
siteSearch = "www.presidenciarepublica.pt"
fileType = "PDF"
payload = {'q': query,'maxItems': maxItems, 'from': fromDate, 'to': toDate, 'siteSearch': siteSearch, 'type': fileType}
r = requests.get('http://arquivo.pt/textsearch', params=payload)
print("GET",r.url)
print("\n")
contentsJSon = r.json()
for item in contentsJSon["response_items"]:
title = item["title"]
url = item["linkToArchive"]
time = item["tstamp"]
print(title)
print(url)
print(time)
Conta-me Histórias
O projeto Conta-me Histórias é desenvolvido por pesquisadores do Laboratório de Inteligência Artificial e Apoio a Decisão (LIAAD) — INESCTEC) e afiliados às instituições Instituto Politécnico de Tomar — Centro de Investigação em Cidades Inteligentes (CI2), Universidade do Porto e Universidade de Innsbruck (em inglês). O projeto visa oferecer aos usuários a possibilidade de revisitarem tópicos do passado através de uma interface semelhante ao Google que, dada uma pesquisa, devolve uma sumarização temporal das notícias mais relevantes preservadas pelo Arquivo.pt acerca desse tópico. Um vídeo promocional do projeto pode ser visualizado aqui.
Contributos
Nos últimos anos, o crescente aumento na disponibilização de conteúdos online tem colocado novos desafios àqueles que pretendem entender a estória de um dado evento. Mais recentemente, fenómenos como o media bias (em português, viés mediático), as fake news (em português, notícias falsas) e as filter bubbles (link em inglês. Em português, filtro de bolha), vieram adensar ainda mais as dificuldades já existentes no acesso transparente à informação. O Conta-me Histórias surge, neste contexto, como um importante contributo para todos aqueles que pretendem ter acesso rápido a uma visão histórica de um dado evento, criando automaticamente narrativas resumidas a partir de um elevado volume de dados coletados no passado. A sua disponibilização em 2018, é um importante contributo para que estudantes, jornalistas, políticos, pesquisadores, etc, possam gerar conhecimento e verificar factos de uma forma rápida, a partir da consulta de timelines automaticamente geradas, mas também pelo recurso à consulta de páginas web tipicamente inexistentes na web mais convencional, a web do presente.
Onde posso encontrar o Conta-me Histórias?
O projeto Conta-me Histórias encontra-se disponível, desde 2018, a partir dos seguintes endereços:
- Página web (versão PT): https://contamehistorias.pt
- Biblioteca Python: https://github.com/LIAAD/TemporalSummarizationFramework (em inglês)
Outros endereços de relevância:
- Conta-me Histórias front-end: https://github.com/LIAAD/contamehistorias-ui (em inglês)
- Conta-me Histórias back-end: https://github.com/LIAAD/contamehistorias-api (em inglês)
Mais recentemente, em setembro de 2021, o Arquivo.pt passou a disponibilizar a funcionalidade “Narrativa”, através de um botão adicional na sua interface que redireciona os usuários para o website do Conta-me Histórias, para que a partir deste possam criar automaticamente narrativas temporais sobre qualquer tema. A funcionalidade “Narrativa” resulta da colaboração entre a equipa do Conta-me Histórias, vencedora do Prémio Arquivo.pt 2018, e a equipa do Arquivo.pt.
Como Funciona?
Quando um usuário insere um conjunto de palavras acerca de um tema na caixa de pesquisa do Arquivo.pt e clica no botão “Narrativa”, é direcionado para o serviço Conta-me Histórias que, por sua vez, analisa automaticamente as notícias de 26 websites arquivados pelo Arquivo.pt ao longo do tempo e apresenta-lhe uma cronologia de notícias relacionadas com o tema pesquisado.
Por exemplo, se pesquisarmos por “Jorge Sampaio” e carregarmos no botão “Narrativa”,
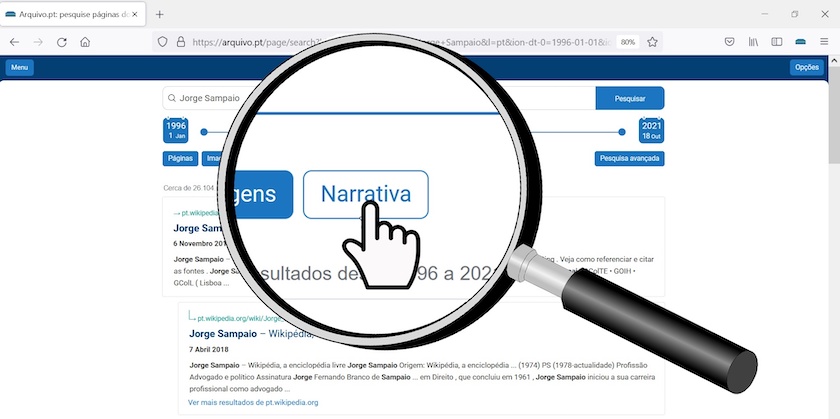
Figura 1: Pesquisa por ‘Jorge Sampaio’ através da componente narrativa do Arquivo.pt.
seremos direcionados para o Conta-me Histórias, onde obteremos, automaticamente, uma narrativa de notícias arquivadas. Na figura seguinte é possível observar a linha de tempo e o conjunto de notícias relevantes no período compreendido entre 2016-04-07 e 2016-11-17. O último período temporal é referente ao ano de 2019.
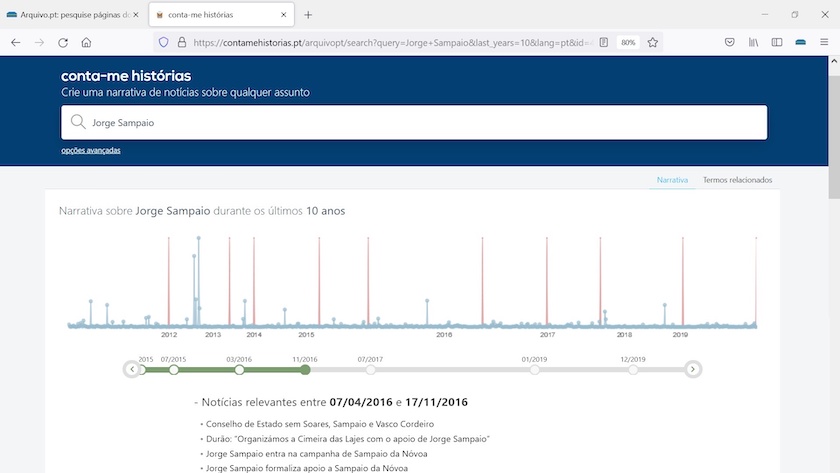
Figura 2: Resultados da pesquisa por ‘Jorge Sampaio’ no Conta-me Histórias para o periodo compreendido entre 2016-04-07 e 2016-11-17.
Para a seleção das notícias mais relevantes recorremos ao YAKE! (em inglês), um extrator de palavras relevantes (desenvolvido pela nossa equipa de pesquisa) e que, neste contexto, é utilizado para selecionar os excertos mais importantes de uma notícia (mais concretamente os seus títulos) ao longo do tempo.
Um aspeto interessante da aplicação é o facto desta facilitar o acesso à página web arquivada que dá nome ao título selecionado como relevante. Por exemplo, ao clicar em cima do título “Jorge Sampaio formaliza apoio a Sampaio da Nóvoa” o usuário poderá visualizar a seguinte página web:
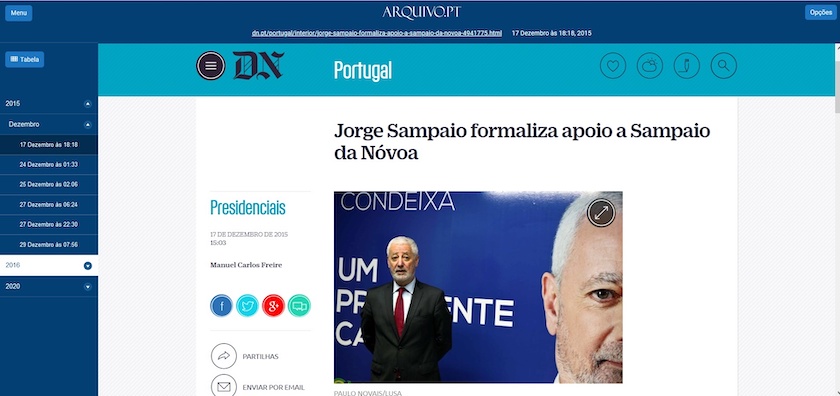
Figura 3: Jorge Sampaio formaliza apoio a Sampaio da Nóvoa.
Paralelamente, poderá ter acesso a um conjunto de “termos relacionados” com o tópico de pesquisa. Na figura abaixo é possível observar, entre outros, a referência aos antigos presidentes da República Mário Soares e Cavaco Silva, bem como aos ex-primeiro-ministros Santana Lopes e Durão Barroso.
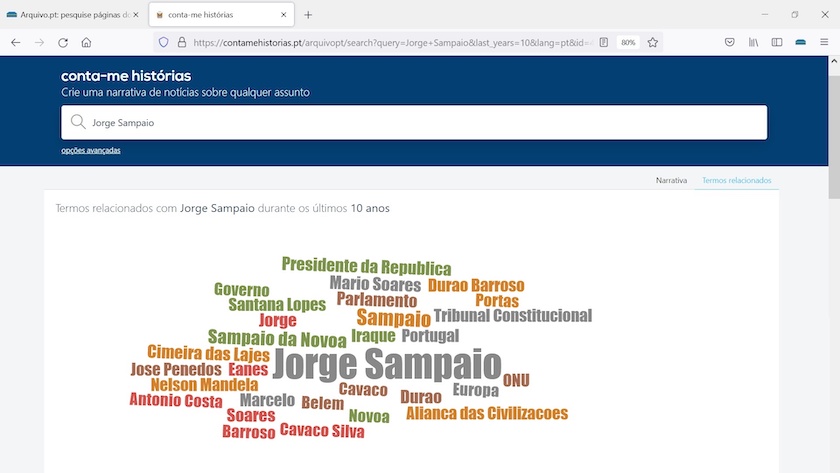
Figura 4: Nuvem de palavras com os termos relacionados com a pesquisa por ‘Jorge Sampaio’ ao longo de 10 anos.
O Conta-me Histórias pesquisa, analisa e agrega milhares de resultados para gerar cada narrativa acerca de um tema. Recomenda-se a escolha de palavras descritivas sobre temas bem definidos, personalidades ou eventos para obter boas narrativas. No seção seguinte descrevemos a forma como, através da biblioteca Python, os usuários podem interagir e fazer uso dos dados do Conta-me Histórias.
Instalação
Para a instalação da biblioteca Conta-me Histórias (em inglês) necessita de ter o git (em inglês) instalado. Após a sua instalação proceda à execução do seguinte código:
!pip install -U git+https://github.com/LIAAD/TemporalSummarizationFramework
Utilização
Definição dos parâmetros de pesquisa
No próximo código o usuário é convidado a definir o conjunto de parâmetros de pesquisa. A variável domains lista o conjunto de 24 websites objeto de pesquisa. Um aspeto interessante desta variável é a possibilidade do usuário definir a sua própria lista de fontes noticiosas. Um exercício interessante passa por definir um conjunto de meios de comunicação de âmbito mais regional, por oposição aos meios de comunicação nacionais ali listados.
Os parâmetros from e to permitem estabelecer o espectro temporal da pesquisa. Finalmente, na variável query o usuário é convidado a definir o tema da pesquisa (e.g., “Jorge Sampaio”) para o qual pretende construir uma narrativa temporal. Uma vez executado o código o sistema inicia o processo de pesquisa junto do Arquivo.pt. Para tal, recorre à utilização da Arquivo.pt API (Full-text & URL search) (em inglês).
from contamehistorias.datasources.webarchive import ArquivoPT
from datetime import datetime
# Especifica o website e o ambito temporal para restringir a pesquisa
domains = [ 'http://publico.pt/', 'http://www.dn.pt/', 'http://dnoticias.pt/', 'http://www.rtp.pt/', 'http://www.cmjornal.pt/', 'http://www.iol.pt/', 'http://www.tvi24.iol.pt/', 'http://noticias.sapo.pt/', 'http://www.sapo.pt/', 'http://expresso.sapo.pt/', 'http://sol.sapo.pt/', 'http://www.jornaldenegocios.pt/', 'http://abola.pt/', 'http://www.jn.pt/', 'http://sicnoticias.sapo.pt/', 'http://www.lux.iol.pt/', 'http://www.ionline.pt/', 'http://news.google.pt/', 'http://www.dinheirovivo.pt/', 'http://www.aeiou.pt/', 'http://www.tsf.pt/', 'http://meiosepublicidade.pt/', 'http://www.sabado.pt/', 'http://economico.sapo.pt/']
params = { 'domains':domains, 'from':datetime(year=2011, month=1, day=1), 'to':datetime(year=2021, month=12, day=31) }
query = 'Jorge Sampaio'
apt = ArquivoPT()
search_result = apt.getResult(query=query, **params)
Percorrer os resultados obtidos no Arquivo.pt
O objeto search_result devolve o número total de resultados obtidos a partir da chamada à API do Arquivo.pt. O número total de resultados excede facilmente as 10.000 entradas, um volume de dados praticamente impossível de processar por qualquer usuário que, a partir dele, queira retirar conhecimento em tempo útil.
len(search_result)
Para lá do número total de resultados o objeto search_result reúne informação extremamente útil para o passo seguinte do algoritmo, i.e., a seleção das notícias mais relevantes ao longo do tempo. Em concreto, este objeto permite ter acesso a:
datatime: data de coleta do recursodomain: fonte noticiosaheadline: título da notíciaurl: url original da notícia
bastando para tal executar o seguinte código:
for x in search_result:
print(x.datetime)
print(x.domain)
print(x.headline)
print(x.url)
print()
Determinação de datas importantes e seleção das keywords/títulos relevantes
No próximo passo o sistema recorre ao algoritmo do Conta-me Histórias para criar um resumo das notícias mais importantes a partir do conjunto de documentos obtidos no Arquivo.pt. Cada bloco temporal determinado como relevante pelo sistema reúne um total de 20 notícias. Os vários blocos temporais determinados automaticamente pelo sistema oferecem ao usuário uma narrativa ao longo do tempo.
from contamehistorias import engine
language = "pt"
cont = engine.TemporalSummarizationEngine()
summ_result = cont.build_intervals(search_result, language, query)
cont.pprint(summ_result)
Estatísticas da pesquisa
O código seguinte permite ter acesso a um conjunto de estatísticas globais, nomeadamente, ao número total de documentos, de domínios, bem como ao tempo total de execução do algoritmo.
print(f"Número total de documentos: {summ_result['stats']['n_docs']}")
print(f"Número total de domínios: {summ_result['stats']['n_domains']}")
print(f"Tempo total de execução: {summ_result['stats']['time']}")
Obter a lista dos domínios dos resultados da pesquisa
Para listar todos os domínios execute o seguinte código:
for domain in summ_result["domains"]:
print(domain)
Resultados da pesquisa para a “Narrativa”
Finalmente, o código seguinte recorre à variável summ_result ["results"] para apresentar os resultados gerados com a informação necessária à produção de uma timeline, nomeadamente, o período temporal de cada bloco de notícias, as notícias propriamente ditas (um conjunto de 20 notícias relevantes por bloco temporal), a data de coleta, a fonte noticiosa, o url (ligação à página web original) e o título completo da notícia.
for period in summ_result["results"]:
print("--------------------------------")
print(period["from"],"until",period["to"])
# Cabecalhos selecionados
keyphrases = period["keyphrases"]
for keyphrase in keyphrases:
print("headline = " + keyphrase.kw)
# Fontes
for headline in keyphrase.headlines:
print("Date", headline.info.datetime)
print("Source", headline.info.domain)
print("Url", headline.info.url)
print("Headline completa = ", headline.info.headline)
print()
Conclusões
A web é hoje considerada uma ferramenta essencial de comunicação. Neste contexto, os arquivos web surgem como um importante recurso de preservação dos conteúdos aí publicados. Embora o seu uso seja dominado por pesquisadores, historiadores ou jornalistas, o elevado volume de dados aí disponíveis sobre o nosso passado faz deste tipo de infraestrutura uma fonte de recursos de elevado valor e extrema utilidade para os usuários mais comuns. O acesso generalizado a este tipo de infraestrutura obriga, no entanto, à existência de outro tipo de ferramentas capazes de satisfazer as necessidades de informação do usuário, diminuindo, ao mesmo tempo, os constrangimentos associados à exploração de elevados volumes de dados por parte de usuários não especialistas.
Neste tutorial, procurámos mostrar como criar automaticamente sumários temporais a partir de eventos coletados no passado, fazendo uso dos dados obtidos no Arquivo.pt e da aplicação da biblioteca de sumarização temporal Conta-me Histórias. O tutorial aqui apresentado é um primeiro passo na tentativa de mostrarmos aos interessados na temática uma forma simples de como qualquer usuário pode, utilizando conceitos minímos de programação, fazer uso de APIs e bibliotecas existentes para extrair conhecimento a partir de um elevado volume de dados num curto espaço de tempo.
Prémios
O projeto Conta-me Histórias foi o vencedor do Prémio Arquivo.pt 2018 e o vencedor da Best Demo Presentation na 41st European Conference on Information Retrieval (ECIR-19) (em inglês).
Financiamento
Ricardo Campos foi financiado por fundos nacionais através do Fundação para a Ciência e Tecnologia (FCT) e pela Fundação Portuguesa para Ciência e Tecnologia (I.P.) com o projeto StorySense (2022.09312.PTDC).
Bibliografia
-
Campos, R., Pasquali, A., Jatowt, A., Mangaravite, V., and Jorge, A.. “Automatic Generation of Timelines for Past-Web Events” In The Past Web: Exploring Web Archives, edited by D. Gomes, E. Demidova, J. Winters, and T. Risse, 225-242. Springer: 2021. https://link.springer.com/chapter/10.1007/978-3-030-63291-5_18
-
Campos, R., Mangaravite, V., Pasquali, A., Jorge, A., Nunes, C., and Jatowt, A.. “YAKE! Keyword Extraction from Single Documents using Multiple Local Features”. Information Sciences Journal, vol. 509 (2020): 257-289. https://doi.org/10.1016/j.ins.2019.09.013
-
Campos, R., Mangaravite, V., Pasquali, A., Jorge, A., Nunes, C., and Jatowt, A.. “A Text Feature Based Automatic Keyword Extraction Method for Single Documents” In Advances in Information Retrieval. ECIR 2018 (Grenoble, France. March 26 ? 29). Lecture Notes in Computer Science, edited by G. Pasi, B. Piwowarski, L. Azzopardi, and A. Hanbury, vol. 10772, 684-691. Springer: 2018. https://link.springer.com/chapter/10.1007/978-3-319-76941-7_63
-
Pasquali, A., Mangaravite, V., Campos, R., Jorge, A., and Jatowt, A..”Interactive System for Automatically Generating Temporal Narratives” In Advances in Information Retrieval. ECIR’19 (Cologne, Germany. April 14-18). Lecture Notes in Computer Science, edited by L. Azzopardi, B. Stein, N. Fuhr, P. Mayr, C. Hauff, and D. Hiemstra, vol. 11438, 251 - 255. Springer: 2019. https://link.springer.com/chapter/10.1007/978-3-030-15719-7_34
-
Gomes, D., Demidova, E., Winters, J., and Risse, T. (eds.), The Past Web: Exploring Web Archives. Springer, 2021. https://arquivo.pt/book Pre-print
-
Gomes, D., and Costa M.. “The Importance of Web Archives for Humanities”. International Journal of Humanities and Arts Computing, (April 2014). http://sobre.arquivo.pt/wp-content/uploads/the-importance-of-web-archives-for-humanities.pdf.
-
Alam,Sawood, Weigle, Michele C., Nelson, Michael L., Melo, Fernando, Bicho, Daniel, Gomes, Daniel. “MementoMap Framework for Flexible and Adaptive Web Archive Profiling” In Proceedings of Joint Conference on Digital Libraries 2019. Urbana-Champaign, Illinois, US: June 2019. https://www.cs.odu.edu/~salam/drafts/mementomap-jcdl19-cameraready.pdf.
-
Costa, M.. “Information Search in Web Archives” PhD thesis, Universidade de Lisboa, December 2014. http://sobre.arquivo.pt/wp-content/uploads/phd-thesis-information-search-in-web-archives.pdf
-
Mourão, A., Gomes, D.. The Anatomy of a Web Archive Image Search Engine. Technical Report. Lisboa, Portugal: Arquivo.pt, dezembro 2021. https://sobre.arquivo.pt/wp-content/uploads/The_Anatomy_of_a_Web_Archive_Image_Search_Engine_tech_report.pdf