
Conteúdos
- Pré-requisitos
- O que é a Análise de Correspondência?
- Comités Parlamentares Canadenses (CPCs)
- Preparando o R para a CA
- Os dados
- Análise de Correspondência dos Comités Parlamentares Canadenses 2006 e 2016
- Interpretando a Análise de Correspondência (CA)
- Trudeau ampliou a Agenda para a Igualdade das Mulheres no Parlamento?
- Análise
- Conclusão
- Apêndice: A Matemática por trás da Análise de Correspondência
- Notas
A análise de correspondência (correspondence analysis ou CA) produz um gráfico bidimensional ou tridimensional baseado nas relações entre duas ou mais categorias de dados. Essas categorias poderiam ser “membros e clubes”, “palavras e livros” ou “países e acordos comerciais”. Por exemplo, um membro do clube pode ser equivalente a outro membro com base nos clubes compartilhados aos quais ele pertence. Os membros que frequentam os mesmos clubes provavelmente têm mais em comum do que aqueles que frequentam clubes diferentes. Da mesma forma, os clubes que compartilham membros provavelmente terão mais em comum do que aqueles que compartilham membros diferentes.1
Discernir essas correspondências significativas pode ser muito difícil de fazer quando há muitos elementos em cada uma de suas categorias (por exemplo, se tivermos centenas de membros espalhados por dezenas de clubes.) A CA mede as correspondências mais fortes em um dataset e as projeta em um espaço multidimensional, possibilitando sua visualização e interpretação. Normalmente, as duas principais dimensões são mostradas de uma só vez, embora seja possível mostrar três dimensões em um display 3D.
Uma vez que a CA visualiza as relações entre elementos de seus dados como distâncias em um gráfico, muitas vezes é possível descobrir padrões amplos com base em que elementos de uma categoria aparecem próximos a elementos da outra. Assim, a CA pode ser um bom primeiro passo para filtrar os principais padrões de um grande dataset. É uma ferramenta particularmente poderosa para entender informações históricas dentro de coleções digitais.
Depois de ler este tutorial, deve ser possível:
- Saber o que é a CA e para que é usada.
- Saber como executar a CA usando o pacote FactoMineR do R.
- Descrever com exatidão os resultados de uma CA.
Pré-requisitos
Este tutorial é para historiadores e pesquisadores com habilidades intermédias em programação. Pressupõe que já se tem um conhecimento básico de R e alguns conhecimentos básicos de estatística.
O tutorial Noções básicas de R com dados tabulares tem informações sobre como organizar e configurar o R e o tutorial Processamento Básico de Texto em R também pode ser útil como treinamento.
Como a CA é uma espécie de social network analysis (análise de redes sociais), pode ser interessante olhar a lição From Hermeneutics to Data to Networks: Data Extraction and Network Visualization of Historical Sources (em inglês), que também tem algumas informações úteis sobre a estruturação de dados para análise de redes.
O que é a Análise de Correspondência?
A análise de correspondência (CA), também chamada “escala multidimensional” ou “análise bivariada de rede”, permite observar a inter-relação de dois grupos em um gráfico de dispersão com dois eixos (two-way graph plot). Por exemplo, foi utilizada pelo sociólogo francês Pierre Bourdieu para mostrar como categorias sociais como a ocupação influenciam a opinião política.2 É especialmente poderosa como ferramenta para encontrar padrões em grandes datasets.
A CA funciona com qualquer tipo de dados categóricos (datasets que foram agrupados em categorias). Vamos começar com um exemplo simples. Se quisesse entender o papel dos acordos internacionais de livre comércio na interconexão das nações do G8, seria possível criar uma tabela para os países e as relações de livre comércio que eles mantinham em um determinado momento.
Uma pequena seleção de acordos comerciais (em azul) incluindo o Espaço Económico Europeu (European Economic Area ou EEA), o Acordo Comercial Canadá-UE (Canada-EU Trade Agreement ou CETA), o Acordo de Livre Comércio Norte-Americano (North American Free Trade Agreement ou NAFTA), a Parceria Trans-Pacífico (Trans Pacific Partnership ou TPP) e a Associação das Nações do Sudeste Asiático (Association of Southeast Asian Nations ou ASEAN) corresponde aos países do G8. Os países (de cor vermelha) agrupam-se geograficamente, com países do Pacífico à direita, países europeus à esquerda e países da América do Norte ao centro. O Canadá e os Estados Unidos, como previsto, estão juntos. Alemanha, Itália, França e Reino Unido pertencem todos aos mesmos dois acordos (CETA e EEA), portanto todos caem exatamente no mesmo ponto.
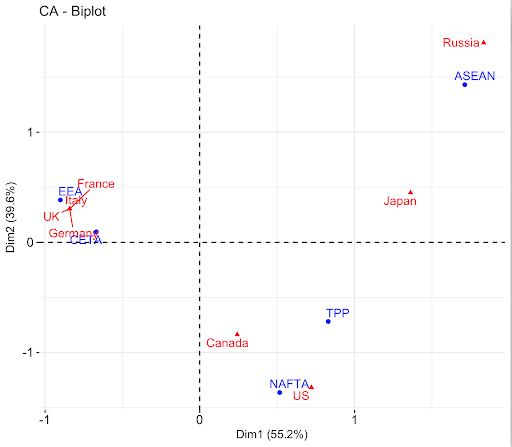
Figura 1. Análise de correspondência de países selecionados do G8 e seus acordos comerciais
Por outro lado, enquanto a Rússia e os Estados Unidos estão um pouco próximos no eixo horizontal, estão em polos opostos no eixo vertical. A Rússia só compartilha um acordo de comércio com um outro país (Japão) e os Estados Unidos com dois (Japão e Canadá). Em um gráfico de CA, unidades com poucas correlações ficarão nos arreadores, enquanto aquelas unidades com maior quantidade de correlações ficarão mais próximo do centro do gráfico. A conexão relativa ou falta de conexão de um datapoint é quantificada como inertia (inércia) na CA. A falta relativa de conexão produz uma inércia maior.
Um ponto mais substancial sobre a Rússia e os Estados Unidos é que a Rússia é um país do Pacífico que não pertence à TPP. Observando esta relação, um historiador poder-se-ia perguntar se isto ocorre por causa de uma relação comercial tensa entre a Rússia e os Estados Unidos em comparação com outros países do G8, ou por atitudes gerais em relação a acordos comerciais para estes países.3
Com mais dados, a CA pode descobrir distinções mais subtis entre grupos dentro de uma categoria particular. Neste tutorial, analisaremos a vida política canadense - especificamente, como representantes políticos são organizados em comités durante um ou outro governo. Semelhante aos acordos comerciais, esperaríamos que os comités que têm membros semelhantes estivessem mais próximos uns dos outros. Além disso, os comités que têm poucos representantes em comum se encontrarão nos cantos do gráfico.
Comités Parlamentares Canadenses (CPCs)
No sistema parlamentar canadense, os cidadãos elegem representantes chamados membros do Parlamento, ou deputados, para a Câmara dos Comuns. Os parlamentares são responsáveis por votar e propor alterações à legislação no Canadá. Os Comités Parlamentares (CPCs) (em inglês) consistem de parlamentares que informam à Câmara sobre detalhes importantes da política em uma área temática. Exemplos de tais comités incluem os CPCs sobre Finanças, Justiça e Saúde.
Usaremos abreviações para os comités parlamentares, porque os nomes podem ficar longos, tornando-os difíceis de ler em um gráfico. É possível usar esta tabela como um guia de referência para as abreviações e seus respectivos nomes de comités:
| Abbreviation (Abreviação) | Committee Name (Tradução do Nome do Comité) |
|---|---|
| INAN | Indigenous and Northern Affairs (Assuntos Indígenas e do Norte) |
| HUMA | Human Resources, Skills and Social Development and the Status of Persons with Disabilities (Recursos Humanos, Habilidades e Desenvolvimento Social e o Status das Pessoas com Deficiência) |
| FINA | Finance (Finanças) |
| FAAE | Foreign Affairs and International Development (Relações Exteriores e Desenvolvimento Internacional) |
| ETHI | Access to Information, Privacy and Ethics (Acesso à Informação, Privacidade e Ética) |
| ENVI | Environment and Sustainable Development (Meio Ambiente e Desenvolvimento Sustentável) |
| CHPC | Canadian Heritage (Herança Canadense) |
| CIMM | Citizenship and Immigration (Cidadania e Imigração) |
| ACVA | Veterans Affairs (Assuntos de Veteranos) |
| HESA | Health (Saúde) |
| TRAN | Transport, Infrastructure and Communities (Transporte, Infraestrutura e Comunidades) |
| FOPO | Fisheries and Oceans (Pesca e Oceanos) |
| RNNR | Natural Resources (Recursos Naturais) |
| FEWO | Status of Women (Status das Mulheres) |
| ESPE | Pay Equity (Igualdade de Remuneração) |
| IWFA | Violence against Indigenous Women (Violência Contra as Mulheres Indígenas) |
| BILI | Library of Parliament (Biblioteca do Parlamento) |
| AGRI | Agriculture and Agri-food (Agricultura e Agroalimentação) |
| JUST | Justice and Human Rights (Justiça e Direitos Humanos) |
O autor da lição, o historiador Ryan Deschamps, suspeitava que os deputados estariam organizados de acordo com os tópicos do comité de forma diferente de governo para governo. Por exemplo, os comités formados durante o primeiro gabinete do governo conservador de Stephen Harper podem ser organizados de forma diferente do gabinete inicial do Liberal de Justin Trudeau. Há uma série de razões para esta suspeita. Primeiro, os CPCs são formados por lideranças partidárias e as decisões dos comités precisam de coordenação entre os membros da Câmara. Em outras palavras, os partidos políticos usarão os CPCs como ferramentas para marcar pontos políticos, e os governos devem garantir que as pessoas certas sejam membros dos comités certos para proteger suas agendas políticas. Em segundo lugar, os dois governos têm um enfoque político diferente. O governo conservador de Harper se concentrou mais em questões de desenvolvimento económico, enquanto os Liberais de Trudeau enfatizaram, em primeiro lugar a igualdade social. Em resumo, pode haver algumas decisões calculadas sobre quem entra em que comité, fornecendo evidências sobre as atitudes do governo em relação ou contra certos tópicos.
Preparando o R para a CA
Para fazer uma CA, precisaremos de um pacote de álgebra linear. Para os mais inclinados à matemática, há um apêndice com alguns detalhes sobre como isto é feito. Em R, há várias opções para CA, mas usaremos o pacote FactoMineR (em inglês), focado na “análise de dados exploratórios multivariados”.4 A FactoMineR pode ser usada para conduzir todos os tipos de análises multivariadas diferentes, incluindo clusters hierárquicos, análise fatorial e assim por diante.
Mas, primeiro, aqui está como instalar e puxar os pacotes, depois colocá-los em um objeto R para que possam ser discutidos.
## Estes comandos só precisam ser feitos na primeira vez que se realiza uma análise.
## FactoMineR é um pacote bastante grande, portanto pode levar algum tempo para ser carregado.
install.packages("FactoMineR") # Inclui um módulo para a condução de CA.
install.packages("factoextra") # Pacote para embelezar os nossos gráficos de CA.
# Importar os pacotes:
library(FactoMineR)
library(factoextra)
# set.seed(189981) # Opcional para reprodução.
# Leia os ficheiros csv:
harper_df <- read.csv("http://programminghistorian.org/assets/correspondence-analysis-in-R/HarperCPC.csv", stringsAsFactors = FALSE)
Os dados
Se quiser ver os dados brutos, os dados para este tutorial podem ser encontrados no Zenodo (em inglês). Foram convenientemente incluídos também no formato tabular (nota: não é necessário baixar estes ficheiros manualmente. Usaremos o R para baixá-los diretamente):
1) CPCs do Harper
2) CPCs do Trudeau’s
Uma amostra dos dados para a primeira sessão do governo de Stephen Harper. As filas representam comités e as colunas são membros específicos. Se um membro pertence a um comité, a célula terá um 1; se não, terá um 0.
harper_df
C Bennett D Wilks DV Kesteren G Rickford J Crowder K Block K Seeback
FAAE 0 0 1 0 0 0 0
FEWO 0 0 0 0 0 0 0
FINA 0 0 1 0 0 0 0
HESA 0 1 0 0 0 1 0
INAN 1 0 0 1 1 0 1
IWFA 1 0 0 1 1 1 0
JUST 0 1 0 0 0 0 1
L Davies N Ashton R Goguen R Saganash S Ambler S Truppe
FAAE 0 0 0 1 0 0
FEWO 0 1 0 0 1 1
FINA 0 0 0 0 0 0
HESA 1 0 0 0 0 0
INAN 0 0 0 0 1 0
IWFA 1 1 1 1 1 1
JUST 0 0 1 0 0 0
Estruturado de outra forma (através de uma tabela R) podemos mostrar que os comités têm muitos deputados e alguns deputados são membros de vários comités. Por exemplo, a deputada liberal Carolyn Bennett era membro do “INAN” (Assuntos Indígenas e do Norte) e do “IWFA” (Violência contra Mulheres Indígenas) e o “HESA” (Comité Parlamentar de Saúde) incluía tanto o D Wilks como o K Block. Em geral, os comités têm entre nove e doze membros. Alguns parlamentares são membros de apenas um comité, enquanto outros podem pertencer a vários comités.
Análise de Correspondência dos Comités Parlamentares Canadenses 2006 e 2016
O nosso data frame harper_df consiste em nomes completos de comités e nomes de deputados, mas alguns dos nomes dos comités (por exemplo, “Recursos Humanos, Habilidades e Desenvolvimento Social” e o “Status das Pessoas com Deficiência”) são muito longos para serem bem mostrados em um gráfico: vamos usar as abreviações.
harper_table <- table(harper_df$abbr, harper_df$membership)
O comando table (tabela) faz um dataset de dados cruzados de duas categorias no data frame. As colunas são MPs individuais e as linhas são comités. Cada célula contém um 0 ou um 1 baseado na existência ou não de uma conexão. Se olhássemos a presença real em cada reunião, poderíamos também incluir valores ponderados (por exemplo, 5 para um membro do parlamento que participa de uma reunião de comité 5 vezes). Como regra geral, usar valores ponderados quando as quantidades importam (quando as pessoas investem dinheiro, por exemplo), e usar 0s e 1s quando não importam.
Infelizmente, temos mais um problema. Muitos deputados são membros de apenas 1 comité. Isso fará com que esses deputados se sobreponham quando criarmos o gráfico, tornando-o menos legível. Vamos exigir que os parlamentares pertençam a pelo menos 2 comités antes de executarmos o comando CA da FactoMineR.
harper_table <- harper_table[,colSums(harper_table) > 1]
CA_harper <- CA(harper_table)
plot(CA_harper)
O comando colSums soma os valores para cada coluna da tabela. rowSums poderia ser usado para somar as linhas se isso fosse necessário (não é para nós, porque todos os comités têm mais de um deputado).
O comando CA traça os resultados para as duas dimensões superiores e armazena o resumo dos dados em uma variável chamada CA_harper. Na maioria das vezes, CA faz a maior parte do trabalho. Como discutido, mais detalhes sobre a matemática por trás da CA são fornecidos no apêndice.
Deve-se obter um gráfico que se parece com isto:
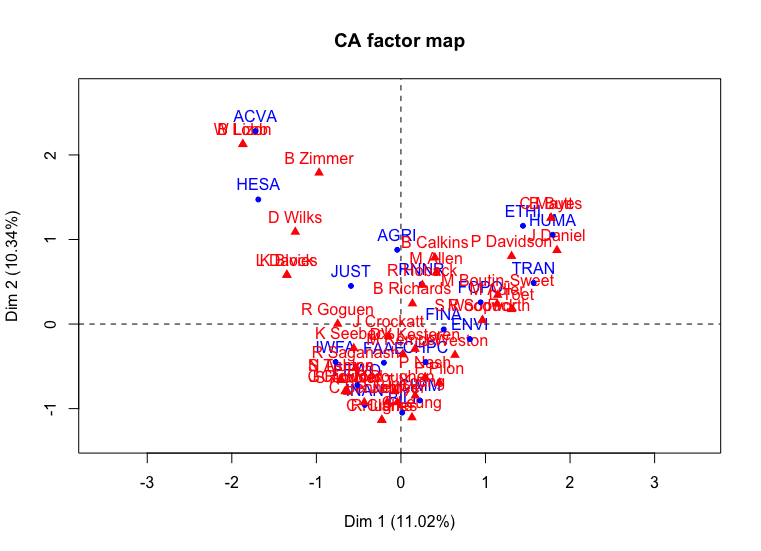
Figura 2. Análise de correspondência dos Comités Parlamentares para a 1ª Sessão do Governo Harper
Vamos tratar os dados do governo Trudeau exatamente da mesma maneira.
trudeau_df <- read.csv("http://programminghistorian.org/assets/correspondence-analysis-in-R/TrudeauCPC.csv", stringsAsFactors = FALSE)
trudeau_table <- table(trudeau_df$abbr, trudeau_df$membership)
trudeau_table <- trudeau_table[,colSums(trudeau_table) > 1]
CA_trudeau <- CA(trudeau_table)
plot(CA_trudeau)
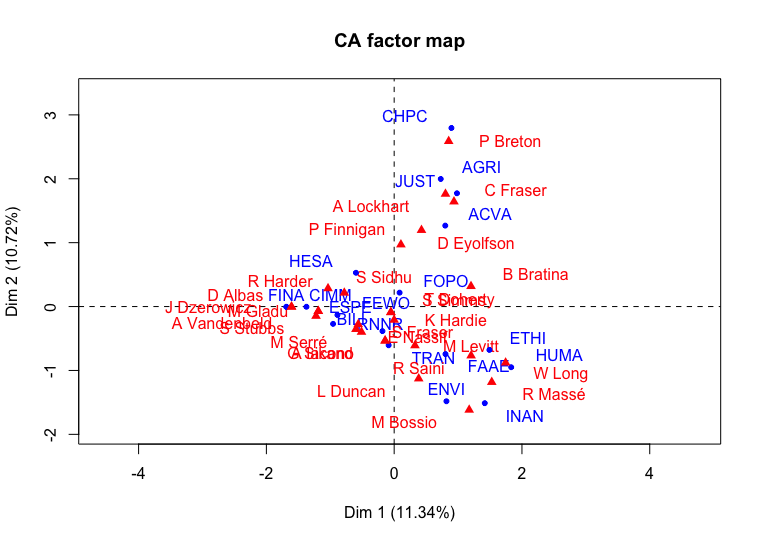
Figura 3. Análise de correspondência dos Comités Parlamentares para a 1ª Sessão do Governo de Justin Trudeau
As nossas etiquetas de dados não são muito legíveis no momento. Mesmo com a mudança para abreviações, as etiquetas estão sobrepostas. O pacote factoextra (em inglês) tem uma característica de repelir que ajuda a mostrar as coisas mais claramente.5
fviz_ca_biplot(CA_harper, repel = TRUE)
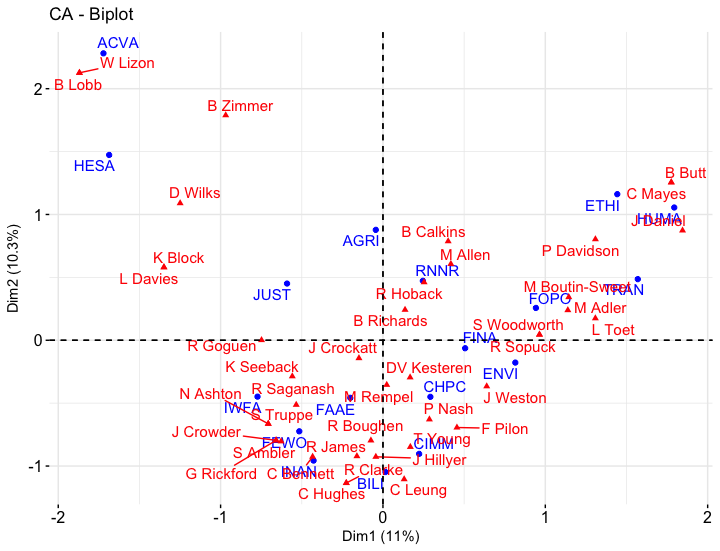
Figura 4. Análise de correspondência dos Comités Parlamentares para a 1ª Sessão do Governo Harper
fviz_ca_biplot(CA_trudeau, repel = TRUE)
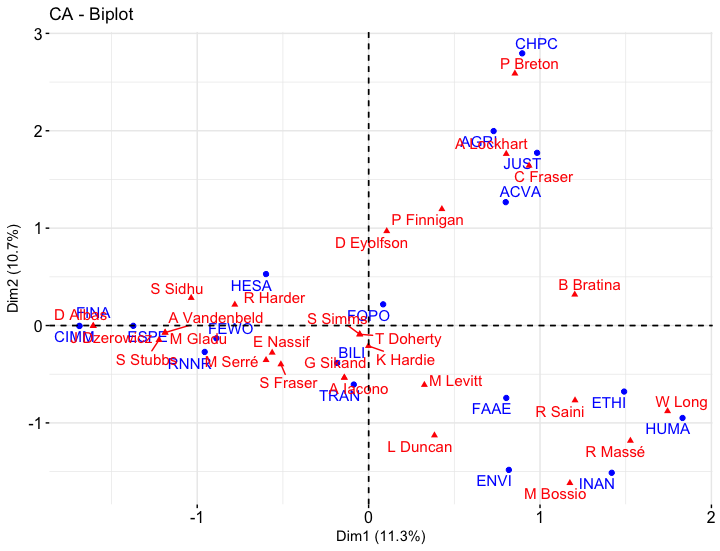
Figura 5. Análise de correspondência dos Comités Parlamentares para a 1ª Sessão do Governo de Justin Trudeau
Em vez de se sobrepor, as etiquetas agora usam setas para mostrar sua localização onde for apropriado.
Interpretando a Análise de Correspondência (CA)
Os gráficos de dados parecem mais bonitos, mas quão bem podemos confiar na validade desses dados? A nossa primeira dica é olhar para as dimensões. Nos dados Harper, apenas onze e dez por cento de valor explicativo aparecem no eixo horizontal e vertical respectivamente para um total de 21%!6 Isso não soa promissor para a nossa análise. Lembrando que o número total de dimensões é igual ao número de filas ou colunas (o que for menor), isto pode ser preocupante. Quando tais valores baixos ocorrem, geralmente significa que os pontos de dados são distribuídos de forma bastante uniforme, e que os MPs são distribuídos de forma uniforme nos CPCs é uma convenção bastante bem estabelecida do parlamento.
Outra maneira de olhar para os dados é através de valores de inércia.7 Mais detalhes sobre inércia podem ser encontrados no apêndice mas, no gráfico, os pontos de dados distantes da origem têm maior inércia. Pontos de inércia elevados sugerem outliers (valores atípicos) - atores ou eventos que têm menos conexões do que aqueles próximos ao centro. Os baixos valores de inércia sugerem pontos de dados que têm mais em comum com o grupo como um todo. Como uma ferramenta de análise, pode ser útil para encontrar atores ou subgrupos renegados no dataset. Se todos os pontos tiverem alta inércia, pode ser um indicador de alta diversidade ou fragmentação para as redes. A baixa inércia geral pode ser um indicador de maior coesão ou convergência geral. O que isso significa dependerá do dataset. Para os nossos gráficos, nenhum projeto de datapoint vai muito além de 2 passos da média. Mais uma vez, este é um indicador de que as relações estão relativamente distribuídas de maneira uniforme.
Vamos analisar os dados mais de perto:
summary(CA_harper)
Isto nos retorna
HARPER
O qui-quadrado da independência entre as duas variáveis é igual a 655.6636
(p-value = 0.7420958 ).
Eigenvalues
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5 Dim.6
Variance 0.831 0.779 0.748 0.711 0.666 0.622
% of var. 11.024 10.342 9.922 9.440 8.839 8.252
Cumulative % of var. 11.024 21.366 31.288 40.729 49.568 57.820
Dim.7 Dim.8 Dim.9 Dim.10 Dim.11 Dim.12
Variance 0.541 0.498 0.463 0.346 0.305 0.263
% of var. 7.174 6.604 6.138 4.591 4.041 3.488
Cumulative % of var. 64.995 71.599 77.736 82.328 86.368 89.856
Dim.13 Dim.14 Dim.15 Dim.16 Dim.17
Variance 0.240 0.195 0.136 0.105 0.088
% of var. 3.180 2.591 1.807 1.396 1.170
Cumulative % of var. 93.036 95.627 97.434 98.830 100.000
O cabeçalho Eigenvalues do resumo apresenta métricas sobre as dimensões recém computadas, listando a percentagem de variância contida em cada uma delas. Infelizmente, a percentagem de variância encontrada nas duas dimensões superiores é muito baixa. Mesmo se conseguíssemos visualizar 7 ou 8 dimensões dos dados, capturaríamos apenas uma percentagem acumulada de cerca de 70%. O teste de independência do qui-quadrado nos diz que não podemos rejeitar a hipótese de que nossas duas categorias (CPCs e MPs) são independentes. O valor p (ou p-value) é 0,74, bem acima do 0,05 comumente usado como um recorte para rejeitar uma hipótese nula.8 Um valor p menor ocorreria, por exemplo, se todos ou a maioria dos deputados fossem membros de um ou dois comités. A propósito, o valor de p quadrado de chi da amostra de Trudeau é menor em 0,54, mas ainda não o suficiente para rejeitar a hipótese de categorias mutuamente independentes.
Como discutido, este resultado não é muito surpreendente. Esperamos que os deputados sejam distribuídos de forma relativamente uniforme entre os comités. Se optarmos por ponderar as nossas medidas com base na participação dos parlamentares em cada reunião de comité ou em seu desejo de 1-100 de ser membro de cada comité, poderemos ver resultados diferentes (por exemplo, pode ser mais comum que os parlamentares participem regularmente nas reuniões financeiras em comparação com outras reuniões).
A CA falhou conosco? Bem, na verdade não. Isto significa apenas que não podemos simplesmente lançar dados em um algoritmo e esperar responder a perguntas reais de história. Mas nós não somos apenas programadores, mas historiadores de programação. Vamos colocar nossos bonés da história e ver se podemos refinar as nossas pesquisas!
Trudeau ampliou a Agenda para a Igualdade das Mulheres no Parlamento?
Uma das primeiras medidas políticas que Justin Trudeau tomou foi garantir que o Canadá tinha um gabinete com 50% de mulheres. É discutível que o objetivo deste anúncio era professar uma agenda de igualdade de género. Na sua primeira sessão, o governo de Trudeau também criou um novo Comité Parlamentar sobre igualdade de remuneração para as mulheres. Além disso, o governo de Trudeau apresentou uma moção para que houvesse um inquérito sobre Mulheres Indígenas Desaparecidas e Assassinadas, substituindo o mandato do comité parlamentar de Harper para a Violência Contra as Mulheres Indígenas.
Se Trudeau tivesse a intenção de levar a igualdade das mulheres a sério, poderíamos esperar que mais membros do comité do Status da Mulher estivessem ligados a pastas maiores, como Justiça, Finanças, Saúde e Relações Exteriores, em comparação com o governo de Harper. Como o regime de Harper não tinha um CPC de salário igual, incluiremos o CPC para “Violência contra Mulheres Indígenas”.
# Inclua apenas os comités desejados:
# HESA: Health, JUST: Justice, FEWO: Status of Women
# INAN: Indigenous and Northern Affairs, FINA: Finance
# FAAE: Foreign Affairs and International Trade
# IWFA: Violence against Indigenous Women
harper_df2 <- harper_df[which(harper_df$abbr %in%
c("HESA", "JUST", "FEWO", "INAN", "FINA", "FAAE", "IWFA")),]
harper_table2 <- table(harper_df2$abbr, harper_df2$membership)
# Remova os singles de novo.
harper_table2 <- harper_table2[, colSums(harper_table2) > 1]
CA_Harper2 <- CA(harper_table2)
plot(CA_Harper2)
Isto produz o seguinte gráfico:
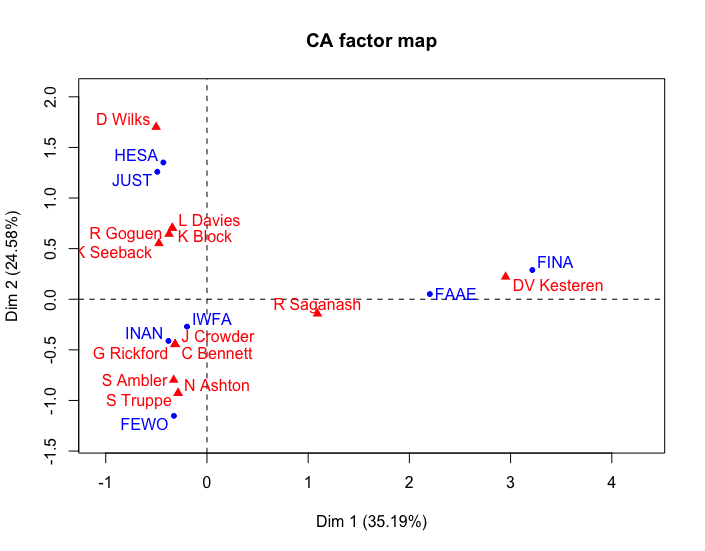
Figura 6. Análise de correspondência de Comités Parlamentares selecionados para a 1ª Sessão do Governo de Stephen Harper
O valor p do qui-quadrado para este resultado se move apenas ligeiramente em direção a zero, para 0,71. Ainda não podemos tirar nenhuma conclusão quantitativa sobre uma relação clara entre CPCs e MPs. Para os nossos dados, este não é um resultado muito importante. Se pesquisássemos os CPCs sobre qual CPC era o mais produtivo ou importante, talvez encontrássemos valores p mais baixos. A inércia no eixo horizontal praticamente dobrou, sugerindo que o FINA (Finance) é um valor mais baixo no gráfico em comparação com os outros portfólios.
O significado de um CA depende de uma interpretação qualitativa da trama. Por exemplo, observando os elementos do gráfico Harper podemos dizer que as preocupações económicas caem para a direita do eixo y e as preocupações sociais caem para a esquerda. Portanto, uma das “razões” para escolher os parlamentares para participar de comités no governo Harper parece ser a distinção entre preocupações sociais e económicas.
Entretanto, quando fazemos a mesma análise com o governo de Trudeau…
trudeau_df2 <- trudeau_df[which(trudeau_df$abbr %in%
c("HESA", "JUST", "FEWO", "INAN", "FINA", "FAAE", "ESPE")),]
trudeau_table2 <- table(trudeau_df2$abbr, trudeau_df2$membership)
trudeau_table2 <- trudeau_table2[, colSums(trudeau_table2) > 1] # remova os singles de novo
CA_trudeau2 <- CA(trudeau_table2)
plot(CA_trudeau2)
Produzimos um gráfico incompleto e esta mensagem aparece:
Warning message:
In CA(trudeau_table2) :
The rows FAAE, INAN, JUST sum at 0. They were suppressed from the analysis.
Isto significa que o gráfico produzido não nos mostra as colunas FAEE, INAN e JUST. Como o valor de cada uma delas é 0, elas foram suprimidas da análise. Olhando para a tabela trudeau_table2, vemos que:
A Vandenbeld D Albas M Gladu R Harder S Sidhu
ESPE 1 1 1 0 1
FAAE 0 0 0 0 0
FEWO 1 0 1 1 0
FINA 0 1 0 0 0
HESA 0 0 0 1 1
INAN 0 0 0 0 0
JUST 0 0 0 0 0
Não há nenhuma associação cruzada para FAEE, INAN ou JUST! Bem, isso é um resultado em si mesmo. Podemos concluir, em geral, que as agendas dos dois governos são bastante diferentes, e que houve uma abordagem diferente utilizada para organizar os parlamentares em comités.
Para um historiador canadense, o resultado faz algum sentido, dado que a Violência contra as Mulheres Indígenas (IWFA) tem muito mais probabilidade de estar ligada aos Assuntos Indígenas e do Norte (INAN), e à Justiça e Direitos Humanos (JUST), do que à Igualdade de Remuneração (ESPE). Afinal, a história da Violência contra as Mulheres Indígenas está ligada a uma série de casos criminais de alto nível no Canadá. Como discutido anteriormente, a análise de CA requer uma quantidade de interpretação para se tornar significativa.
Talvez possamos observar alguns comités diferentes em seu lugar. Ao retirar “JUST”, “INAN” e “FAAE” (Relações Exteriores) e substituí-los por “CIMM” (Imigração), “ETHI” (Ética e Acesso à Informação) e “HUMA” (Recursos Humanos), podemos obter uma imagem melhor da estrutura dos comités parlamentares neste contexto.
trudeau_df3 <- trudeau_df[which(trudeau_df$abbr %in%
c("HESA", "CIMM", "FEWO", "ETHI", "FINA", "HUMA", "ESPE")),]
trudeau_table3 <- table(trudeau_df3$abbr, trudeau_df3$membership)
trudeau_table3 <- trudeau_table3[, colSums(trudeau_table3) > 1] # remova os singles de novo
CA_trudeau3 <- CA(trudeau_table3)
plot(CA_trudeau3)
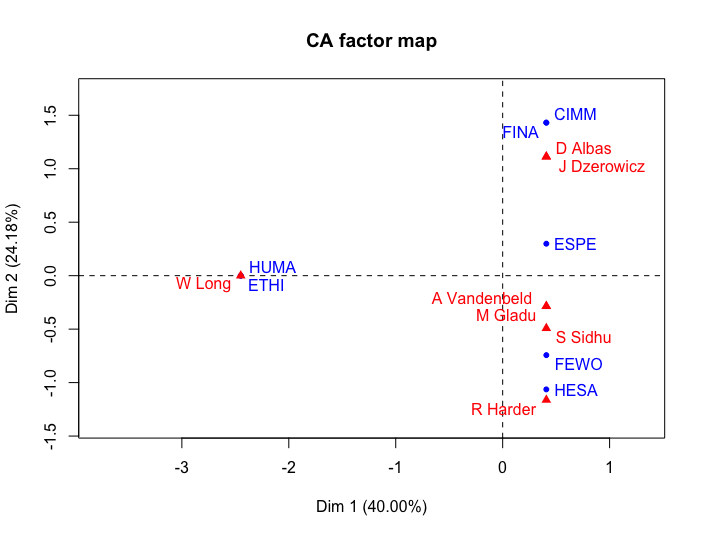
Figura 7. Análise de correspondência de Comités Parlamentares selecionados para a 1ª Sessão do Governo de Justin Trudeau
Em geral, a inércia no eixo horizontal é menor que a do governo de Harper, mas a separação tem “HUMA” (Recursos Humanos) e “ETHI” (Ética) contra os outros portfólios à direita. A delimitação entre questões sociais e económicas não é tão evidente como para Harper, sugerindo uma filosofia diferente para a seleção. Dito isto, também há menos deputados compartilhando as posições. Isto pode ser outro mistério para uma maior exploração. No entanto, o processo CA nos fornece uma visão sólida das relações que ocorrem dentro dos comités com um olhar rápido e com muito poucos comandos.
Análise
Como na maioria das pesquisas interpretativas, não obtemos uma resposta direta à nossa pergunta sobre o poder para as mulheres nos governos parlamentares. No caso Harper, vemos uma divisão no eixo horizontal entre questões sociais como Saúde e Justiça e questões económicas como Finanças e Relações Exteriores, respondendo por 35% da variação. Pela visualização, podemos adivinhar que Finanças (FINA) e Relações Exteriores (FAAE) têm um membro comum e que Relações Exteriores (FAAE) tem um membro comum com Violência contra Mulheres Indígenas (IWFA). Este resultado é, possivelmente, uma preocupação, pois as agendas mais divulgadas de Stephen Harper tendiam a se concentrar em preocupações económicas como o comércio e a contenção fiscal. A separação dos comités implica que a filosofia de governança de Harper separava as preocupações económicas das sociais e que os direitos das mulheres eram principalmente uma preocupação social. A própria pasta Status da Mulher (FEWO) é separada do resto das pastas, encontrando-se ligada às outras pastas somente através de parlamentares comuns com os comités Violência contra Mulheres Indígenas (IWFA) e Assuntos Indígenas e do Norte (INAN).
O gráfico do governo de Trudeau não mostra conexões cruzadas do Status da Mulher com a Justiça, Relações Exteriores e Povos Indígenas, mas conexões mais fortes com Finanças, Cidadania, Recursos Humanos e Ética. Os Direitos da Mulher estão ligados às Finanças e à Imigração através da carteira de Igualdade de Remuneração.
É discutível que o regime do governo Harper alinhou os Direitos das Mulheres às pastas sociais como Justiça e Saúde, enquanto Trudeau elevou o perfil do Status da Mulher até certo ponto ao incluir o comité de Igualdade de Remuneração. A conexão entre os comités focados nos Direitos da Mulher e fortes carteiras como Saúde, Finanças e Cidadania e Imigração no governo Trudeau é digna de uma análise mais detalhada. Neste contexto, o Status da Mulher parece ter uma posição mais central (mais próxima da origem) do que o comité Status da Mulher no governo de Harper. Dito isto, o número de pontos de dados neste caso ainda é bastante pequeno para se chegar a uma conclusão definitiva. Talvez outras fontes de evidência possam ser visualizadas de maneira semelhante para confirmar ou negar este ponto.
A agenda anteriormente mantida entre as mulheres e os povos indígenas foi deslocada no caso Trudeau. Como discutido anteriormente, o National Inquiry into Missing and Murdered Indigenous Women and Girls (Inquérito Nacional sobre Mulheres Indígenas Desaparecidas e Assassinadas) (em inglês) deslocou o mandato para o comité Violência contra as Mulheres Indígenas que existia durante o mandato de Harper. A história desta transição é complexa, mas a pressão política foi aplicada ao governo Harper para criar o Inquérito Nacional sobre Mulheres Indígenas Desaparecidas e Assassinadas após o julgamento de Robert Pickton e relatos de investigações policiais insuficientes para mulheres indígenas desaparecidas. Harper recusou-se a conduzir um inquérito citando que o CPC era a melhor abordagem.9 Trudeau fez uma promessa eleitoral de incluir o inquérito, deslocando assim o comité. Até certo ponto, Harper parece ter dado à violência contra as mulheres indígenas um papel bastante central no planejamento do Comité Parlamentar. Esta evidência é um contraponto às críticas de que Harper não levou a sério a questão das Mulheres Indígenas Desaparecidas e Assassinadas.
As diferenças entre as duas relações levantam questões importantes sobre o papel do Status da Mulher no discurso político e suas interconexões entre identidade racial, finanças públicas, saúde e justiça social, a serem exploradas talvez em um trabalho qualitativo mais detalhado. Também levanta questões importantes sobre o foco no género em geral (de acordo com a carteira do Status da Mulher) ou mais especificamente, uma vez que se aplica a um grupo marginalizado (Mulheres Indígenas Desaparecidas e Assassinadas). Um documento de política relacionado aos benefícios de um Inquérito versus discussão do Comité Parlamentar parece razoável após examinar esta evidência. Talvez haja um argumento de que a troca do “IWFA” por “ESPE” é uma espécie de teto de vidro, colocando artificialmente uma cota em questões de mulheres enquanto as carteiras estabelecidas permanecem intocadas. Como uma ferramenta exploratória, a CA nos ajuda a identificar tais temas a partir da observação empírica, em vez de confiar na teoria ou em preconceitos pessoais.
Conclusão
Agora que este tutorial está completo, é possível ter alguma noção do que é a CA e como pode ser usada para responder perguntas exploratórias sobre dados. Usamos o comando CA do FactoMineR para criar a análise e traçar os resultados em duas dimensões. Quando as etiquetas se cruzaram, aplicamos o comando viz_ca_biplot do pacote factoextra para exibir os dados em um formato mais legível.
Também aprendemos como interpretar uma CA e como detectar potenciais armadilhas analíticas, incluindo casos em que as relações entre categorias são distribuídas de forma muito uniforme e têm baixo valor explicativo. Neste caso, refinamos a nossa pergunta e os dados de pesquisa para fornecer uma imagem mais significativa do que aconteceu.
Em geral, o benefício desta análise é fornecer uma rápida visão geral do dataset de duas categorias, como um guia para questões históricas mais substantivas. O uso de membros e reuniões ou eventos em todas as áreas da vida (negócios, sem fins lucrativos, reuniões municipais, hashtags de twitter, etc.) é uma abordagem comum para tal análise. Os grupos sociais e as suas preferências são outro uso comum para a CA. Em cada caso, a visualização oferece um mapa com o qual se pode observar um retrato da vida social, cultural e política.
Os próximos passos podem incluir a adição de outras dimensões categóricas à nossa análise, como a incorporação do partido político, idade ou sexo. Quando se faz CA com mais de duas categorias, é chamada de Análise de Correspondência Múltipla ou MCA (em inglês). Enquanto a matemática para a MCA é mais complicada, os resultados finais são bastante semelhantes aos da CA.
Esperamos que, agora, estes métodos sejam aplicados aos seus próprios dados, ajudando a descobrir perguntas e hipóteses que enriquecem a sua pesquisa histórica. Boa sorte!
Apêndice: A Matemática por trás da Análise de Correspondência
Como a matemática da CA será interessante para alguns e não para outros, optamos por discuti-la neste Apêndice. A secção também contém um pouco mais de detalhes sobre outros tópicos, tais como inércia (inertia), dimensões (dimensions) e decomposição de valores singulares (singular value decomposition ou SVD).
A fim de facilitar a compreensão, começaremos com apenas alguns comités. “FEWO” (Status das Mulheres ou Status of Women), “HESA” (Saúde ou Health), “INAN” (Assuntos Indígenas e do Norte ou Indigenous and Northern Affairs), “IWFA” (Violência contra as Mulheres Indígenas ou Violence Against Indigenous Women) e “JUST” (Justiça ou Justice).
C Bennett D Wilks G Rickford J Crowder K Block K Seeback L Davies N Ashton
FEWO 0 0 0 0 0 0 0 1
HESA 0 1 0 0 1 0 1 0
INAN 1 0 1 1 0 1 0 0
IWFA 1 0 1 1 1 0 1 1
JUST 0 1 0 0 0 1 0 0
R Goguen S Ambler S Truppe
FEWO 0 1 1
HESA 0 0 0
INAN 0 1 0
IWFA 1 1 1
JUST 1 0 0
A CA é feita em um dataset “normalizado” que é criado pela divisão do valor de cada célula pela raiz quadrada do produto da coluna e totais de linhas, ou célula \(\frac{1}{\sqrt{column total \times row total}}\). Por exemplo, a célula de “FEWO” e S Ambler é \(\frac{1}{\sqrt{3 \times 3}}\) ou 0.333.10
A tabela “normalizada” se parece com isto:
C Bennett D Wilks G Rickford J Crowder K Block K Seeback L Davies N Ashton
FEWO 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.408
HESA 0.000 0.408 0.000 0.000 0.408 0.000 0.408 0.000
INAN 0.316 0.000 0.316 0.316 0.000 0.316 0.000 0.000
IWFA 0.235 0.000 0.235 0.235 0.235 0.000 0.235 0.235
JUST 0.000 0.408 0.000 0.000 0.000 0.408 0.000 0.000
R Goguen S Ambler S Truppe
FEWO 0.000 0.333 0.408
HESA 0.000 0.000 0.000
INAN 0.000 0.258 0.000
IWFA 0.235 0.192 0.235
JUST 0.408 0.000 0.000
O processo de normalização faz algo interessante. Aqueles que são membros de múltiplos comités e/ou que pertencem a comités com muitos membros tendem a ter notas de normalização mais baixas, sugerindo que são mais centrais para a rede. Estes membros serão colocados mais próximos do centro da matriz. Por exemplo, a célula pertencente a S Ambler e “IWFA” tem a pontuação mais baixa de 0,192 porque S Ambler é membro de três comités e o comité “IWFA” tem nove membros no gráfico representado.
A próxima etapa é encontrar a decomposição de valor singular destes dados normalizados. Isto envolve álgebra linear bastante complexa que não será abordada aqui, mas pode-se aprender mais com este tutorial de Single Value Decomposition (Decomposição de Valores Singulares) (em inglês) ou com mais detalhes neste pdf sobre SVD (em inglês). Vou tentar resumir o que acontece em termos leigos.
- Duas novas matrizes são criadas que mostram pontuações de “dimensão” para as linhas (comités) e as colunas (MPs) baseadas em vetores próprios.
- O número de dimensões é igual ao tamanho das colunas ou filas menos 1, que é sempre menor. Neste caso, há cinco comités em comparação com as MPs onze, portanto o número de dimensões é 4.
- Uma outra matriz mostra os valores singulares (valores próprios ou eigenvalues), que podem ser usados para mostrar a influência de cada dimensão na análise.
- Um dos vários “tratamentos” é aplicado aos dados para facilitar a plotagem. O mais comum é a abordagem de “coordenadas padrão”, que compara cada pontuação normalizada de forma positiva ou negativa com a pontuação média.
Ao usar coordenadas padrão, a nossa tabela de dados mostra o seguinte:
Columns (MPs):
Dim 1 Dim 2 Dim 3 Dim 4
C Bennett -0.4061946 -0.495800254 0.6100171 0.07717508
D Wilks 1.5874119 0.147804035 -0.4190637 -0.34058221
G Rickford -0.4061946 -0.495800254 0.6100171 0.07717508
J Crowder -0.4061946 -0.495800254 0.6100171 0.07717508
K Block 0.6536800 0.897240970 0.5665289 0.04755678
K Seeback 0.5275373 -1.245237189 -0.3755754 -0.31096392
L Davies 0.6536800 0.897240970 0.5665289 0.04755678
N Ashton -0.8554566 0.631040866 -0.6518568 0.02489229
R Goguen 0.6039463 -0.464503802 -0.6602408 0.73424971
S Ambler -0.7311723 -0.004817303 -0.1363437 -0.30608465
S Truppe -0.8554566 0.631040866 -0.6518568 0.02489229
$inertia
[1] 0.06859903 0.24637681 0.06859903 0.06859903 0.13526570 0.17971014 0.13526570
[8] 0.13526570 0.13526570 0.08438003 0.13526570
Rows (Committees):
Dim 1 Dim 2 Dim 3 Dim 4
FEWO -1.0603194 0.6399308 -0.8842978 -0.30271466
HESA 1.2568696 0.9885976 0.4384432 -0.28992174
INAN -0.3705046 -0.8359969 0.4856563 -0.27320374
IWFA -0.2531830 0.1866016 0.1766091 0.31676507
JUST 1.1805065 -0.7950050 -0.8933999 0.09768076
$inertia
[1] 0.31400966 0.36956522 0.24927536 0.09017713 0.36956522
Cada pontuação para uma “dimensão” pode ser usada como uma coordenada nesse gráfico. Como não podemos visualizar em quatro dimensões, as saídas CA normalmente se concentram nas primeiras duas ou três dimensões para produzir um gráfico (por exemplo, “HESA” será plotado em [1.245, 0.989] ou [1.245, 0.989, 0.438] em um gráfico 3D).
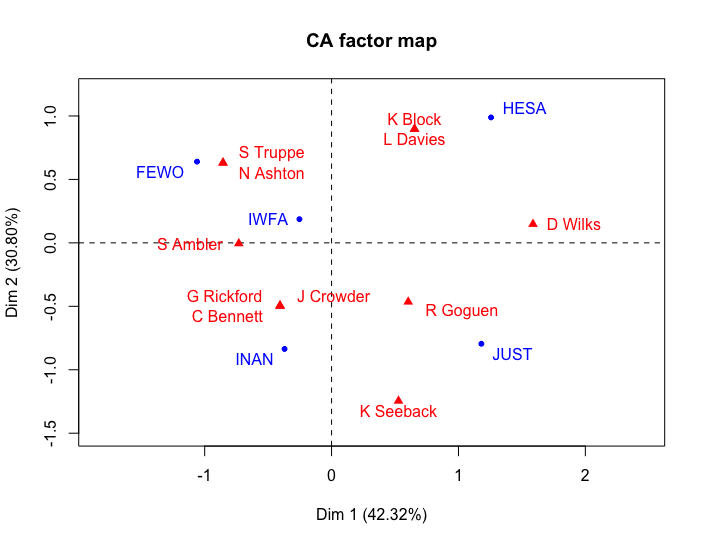
Figura 8. Análise de correspondência de Comités Parlamentares selecionados para a 1ª Sessão do Governo Stephen Harper, 2006
As pontuações de inércia são uma forma de mostrar a variação nos dados. Saúde e Justiça possuem a menor quantidade de membros com uma alta pontuação de inércia, enquanto o comité mais popular - “IWFA” - tem uma pequena inércia. Assim, a inércia é uma forma de quantificar a distância dos pontos em relação ao centro do gráfico.
Outra pontuação importante é visível no gráfico de CA - a percentagem do valor explicativo para cada dimensão. Isto significa que o eixo horizontal explica 42,32% da variação no gráfico, enquanto o eixo vertical explica quase 31%. O que estes eixos significam deve ser interpretado com base no gráfico. Por exemplo, podemos dizer que o lado esquerdo representa questões relativas à identidade social e os do lado direito são mais reguladores. Uma análise histórica mais aprofundada das atas destes comités poderia, por sua vez, oferecer uma maior compreensão sobre o significado da participação destes membros na época.
Notas
-
A CA tem uma história ramificada de várias disciplinas e, assim, a terminologia pode ser confusa. Para simplificar, as categorias se referem aos tipos de dados que estão sendo comparados (por exemplo, membros e clubes) enquanto cada item dentro dessas categorias (por exemplo, “The Tennis Club” ou “John McEnroe”) será um elemento dentro dessa categoria. A localização quantitativa dos elementos (coordenadas x e y) são datapoints. ↩
-
Brigitte Le Roux and Henry Rouanet, Multiple Correspondence Analysis (Los Angeles: SAGE Publications, 2010): 3. ↩
-
Não pretendemos sugerir que esta análise seja de forma alguma conclusiva sobre os laços comerciais entre os EUA e a Rússia. A questão é que, como a Rússia não faz parte da TPP neste acordo, ela se separa dos EUA. Por outro lado, se a adesão à TPP pudesse ser comprovada como representando laços tensos entre os EUA e a Rússia, apareceria no gráfico de CA. ↩
-
Sebastien Le, Julie Josse, Francois Husson (2008). FactoMineR: An R Package for Multivariate Analysis. Journal of Statistical Software, 25(1), 1-18. 10.18637/jss.v025.i01. ↩
-
Alboukadel Kassambara and Fabian Mundt (2017). factoextra: Extract and Visualize the Results of Multivariate Data Analyses. R package version 1.0.4. https://CRAN.R-project.org/package=factoextra. ↩
-
O valor explicativo é a distância dos datapoints afastados do centro do gráfico. Cada dimensão é responsável por parte da distância que os datapoints divergem do centro. ↩
-
Em geral, a inércia nas estatísticas refere-se à variação ou “disseminação” de um dataset. Esta é análoga ao desvio padrão nos dados de distribuição. ↩
-
Ver Laura Kane (3 de abril de 2017), “Missing and murdered women’s inquiry not reaching out to families, say advocates.” CBC News Indigenous. http://www.cbc.ca/news/indigenous/mmiw-inquiry-not-reaching-out-to-families-says-advocates-1.4053694. ↩
-
Em estatística, um valor p (p-value), abreviação de valor de probabilidade, é um indicador de quão provável um resultado teria ocorrido em circunstâncias aleatórias. Um baixo valor de p sugere uma probabilidade baixa de que o resultado teria ocorrido ao acaso e, portanto, fornece algumas evidências de que uma hipótese nula (neste caso, que os MPs e CPCs são categorias independentes) é improvável. ↩
-
Katherine Faust (2005) “Using Correspondence Analysis for Joint Displays of Affiliation Network” in Models and Methods in Social Network Analysis eds. Peter J. Carrington, John Scott and Stanley Wasserman. ↩