
Contenidos
- Objetivos
- Introducción
- Obtener los atributos extraídos de un volumen
- Trabajar con colecciones de HathiTrust
- Cómo usar una colección de Hathitrust para minería textual
- Limitaciones y recomendaciones
- Notas
Objetivos
El propósito de esta lección es difundir el uso de conjuntos de datos con atributos extraídos (“extracted features”) que proporciona el Centro de Investigación de HathiTrust (o HTRC, por sus siglas en inglés) como una manera rápida y accesible de comenzar a estudiar tendencias históricas y culturales a gran escala en textos literarios. Si bien esta lección se enfoca en los estudios literarios, podrás aplicar sin mayor problema las herramientas y estrategias que se presentan aquí a otras disciplinas.
Al finalizar esta lección, habrás aprendido a:
- Usar el lenguaje de programación R para acceder a datos de miles de libros en español disponibles a través del HathiTrust
- Crear y utilizar las colecciones de HathiTrust para obtener un conjunto de datos de los textos que estés interesado en estudiar
- Aplicar técnicas de minería textual para seleccionar, filtrar y explorar los datos obtenidos
Esta lección se compone de dos secciones principales: la primera es una introducción en la cual se dan detalles sobre cómo explorar los contenidos de un libro en el Hathitrust y la segunda explica cómo crear y usar colecciones de documentos.
Introducción
Uno de los mayores obstáculos para avanzar en el estudio de las humanidades digitales fuera del mundo anglosajón es la escasez de textos digitalizados a escala masiva. De los más de 15 millones de volúmenes que posee HathiTrust más de la mitad no está en inglés. Estos números pueden representar para muchos investigadores, más de lo que hay disponible en su idioma en otros sitios. Por ejemplo, un 6% de los volúmenes en HathiTrust están en español, lo que significa que hay más de medio millón de textos disponibles. En el caso de la literatura, esto significa que existen miles de volúmenes de diferentes géneros literarios producidos en los diferentes países de habla hispana.
El Centro de Investigación ha puesto a tu alcance los datos de todos los volúmenes que posee, gratis y ya pre-procesados. Esto incluye tanto los volúmenes cuyos derechos de autor han expirado como los que aún no. Es decir, aunque no puedas tener acceso directo a muchos de los textos debido a la ley de derechos de autor, el Centro te proporcionará conjuntos de datos que contienen los atributos extraídos (“extracted features”) de esos volúmenes, incluyendo las frecuencias con las que aparecen los “tokens” (palabras y símbolos) en cada página.
Requisitos
Esta lección requiere que tengas nociones básicas de R. De no ser así, te recomendamos completar primero las lecciones Datos tabulares básicos con R de Taryn Dewar y Administración de datos en R de Nabeel Siddiqui, ambas traducidas al español por Jennifer Isasi.
Durante la lección, tendrás que instalar y cargar paquetes de R necesarios para obtener y manipular datos del sitio Hathitrust, e importar archivos en formatos de Excel y CSV. Necesitas también saber manipular datos usando el paquete de dplyr.
Si bien puedes practicar el código de este tutorial en una línea de comandos de R, estaremos usando el entorno de desarrollo RStudio en nuestros ejemplos y te recomendamos que lo instales. Si no lo tienes aún, en este video encontrarás una guía sobre cómo descargarlo e instalarlo en Windows y en este otro video para hacer lo mismo en una Mac.
Instalar y cargar paquetes
Para comenzar esta lección necesitas instalar el paquete de R llamado hathiTools, el cual te proporcionará una interfaz para poder obtener los atributos extraídos y los metadatos de los libros en HathitTrust. Este paquete no es parte de CRAN, así que instalarlo requiere un paso adicional: tener instalado primero el paquete remotes y utilizarlo para instalar hathiTools.
install.packages("remotes")
remotes::install_github("xmarquez/hathiTools")
library(hathiTools)
Para manipular nuestros datos e importar algunos archivos, necesitas además tener instalados y cargados dplyr, readr, readxl, y stringr.
#instalar paquetes
install.packages("dplyr")
install.packages("readr")
install.packages("readxl")
install.packages("stringr")
#para manipular datos y archivos
library(dplyr)
library(readr)
library(readxl)
library(stringr)
Obtener los atributos extraídos de un volumen
Cada libro o volumen en HathiTrust posee un número de identificación único (o el “htid”), el cual permite que obtengamos datos sobre el volumen. Cuando el libro no está limitado por los derechos de autor, puedes verlo añadiendo su número de identificación a un URL de la siguiente manera: http://hdl.handle.net/2027/{número de identificación}. Por ejemplo, el número que identifica una de las primeras ediciones de la clásica novela colombiana, María de Jorge Isaacs, es uc1.31175010656638 y al visitar el enlace http://hdl.handle.net/2027/uc1.31175010656638 accedemos a una copia de la obra.
Figura 1. ‘María’ de Jorge Isaacs
Si estás buscando un libro escribiendo su título o autor en el cuadro de búsqueda de HathiTrust, tienes que asegurarte de seleccionar la opción de “Full View” (vista completa) para encontrar su número de identificación. El mismo número de identificación te permite utilizar hathiTools para acceder a los atributos extraídos. El comando get_hathi_counts va a guardar en la variable maria un tibble, que es un dataframe (o marco de datos) y que contiene varios tipos de datos sobre la novela.
maria<-get_hathi_counts("uc1.31175010656638")
head(maria)
# A tibble: 6 × 6
htid token POS count section page
<chr> <chr> <chr> <int> <chr> <int>
1 uc1.31175010656638 ww UNK 1 body 4
2 uc1.31175010656638 - UNK 1 body 4
3 uc1.31175010656638 NMARÍA UNK 1 body 7
4 uc1.31175010656638 II PROPN 1 body 8
5 uc1.31175010656638 Plaza PROPN 1 body 8
6 uc1.31175010656638 Isabel PROPN 1 body 8
Es muy probable que te encuentres con casos en los que el número no funcione y no obtengas los datos extraídos como esperabas. Este es un problema conocido y la única solución es encontrar otra versión del volumen que te interesa y utilizar ese número nuevo.
Parte de la información que obtenemos de HathiTrust pertenece a los tokens y las páginas en las que aparecen. Dado que recibes los datos en forma de marco de datos, puedes utilizar las técnicas del paquete dplyr que has aprendido en otras lecciones, como filtrar (filter) y resumir (summarise). Puedes así filtrar todos los tokens según la página asociada y contar cuántos tokens existen por página.
tokens_maria <- maria %>%
group_by(page) %>%
summarise(num_tokens = sum(count))
head(tokens_maria)
# A tibble: 6 × 2
page num_tokens
<int> <int>
1 4 2
2 7 1
3 8 12
4 9 25
5 11 304
6 12 434
Si visualizas los resultados verás que el número de palabras por página es bastante uniforme, a excepción del comienzo y el final del volumen donde hay muchas páginas en blanco o con información que no es parte de la narración principal.
plot(tokens_maria$page,
tokens_maria$num_tokens, col = "blue",
type = "l", lwd = 1, xlab = "páginas", ylab = "tamaño")
Tu resultado debe ser similar a este:
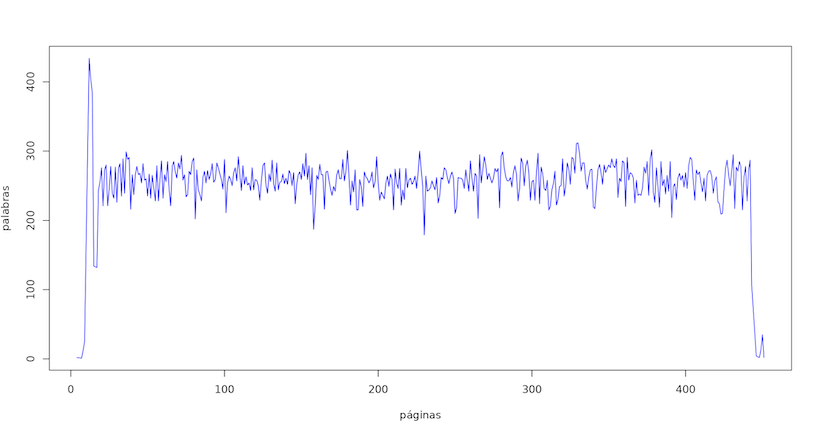
Figura 2. Tokens por página en ‘María’
Podemos filtrar nuestros datos para encontrar las divisiones entre capítulos y añadirlos al gráfico. Para lograrlo, debes saber la palabra exacta que el texto utiliza para dividirse en partes. En este caso, la palabra es CAPÍTULO en letras mayúsculas.
capitulos<-maria %>% filter(token == "CAPÍTULO")
#gráfico
plot(tokens_maria$page,
tokens_maria$num_tokens, col = "blue",
type = "l", lwd = 1,
xlab = "páginas por capítulo", ylab = "palabras")
abline(v = capitulos$page, col = "red", lwd = 1, lty = 1)
Como ves en la Figura 3, es interesante que la novela comienza con una serie de capítulos cortos y los más extensos aparecen después de casi el primer cuarto del texto.
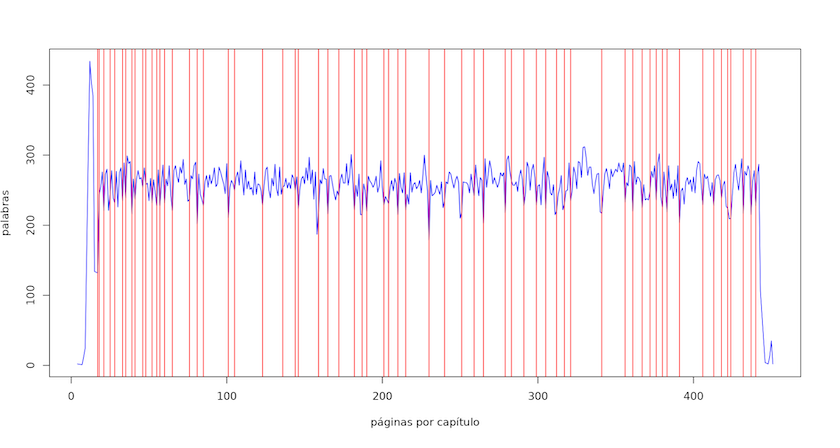
Figura 3. Tokens por capítulo en ‘María’
Es una buena idea eliminar la sección del volumen que viene antes del primer capítulo, ya que contiene, entre otras cosas, un prólogo que no es parte de la narración. Sabemos que la novela comienza en la página 17; ahora necesitamos encontrar la página donde se acaba la historia y eliminar lo que venga después, ya sean índices o glosarios.
maria %>%
filter(token == "FIN") %>%
select(page)
# A tibble: 1 × 1
page
<int>
1 443
Ya que sabes dónde comienza y termina el texto narrativo, puedes eliminar las páginas que no se necesitan (incluyendo los tokens que están en ellas). Para verificar el cambio, cuenta cuántos tokens hay en el marco de datos antes y después de la operación.
#cuenta los tokens que nos han llegado de HathiTrust
maria %>% summarise(num_tokens = sum(count))
# A tibble: 1 × 1
num_tokens
<int>
1 111886
#elimina las secciones no deseadas
maria<-maria %>% filter(page >= 17 & page <=443)
#cuenta otra vez
maria %>% summarise(num_tokens = sum(count))
# A tibble: 1 × 1
num_tokens
<int>
1 110130
El nuevo marco de datos maria solo contiene lo que se encuentra entre las páginas 17 y 443. En esta digitalización de la novela fue muy fácil encontrar dónde estaban los capítulos y el fin de la narración con solo filtrar los datos, pero no todos los volúmenes que tiene HathiTrust están en tan buenas condiciones. A veces será necesario que vayas a la página en su web para encontrar lo que necesitas y eso solo será posible si el libro no está protegido por los derechos de autor.
Una mirada global a nuestro marco de datos
Además de la información sobre tokens y páginas, en los atributos extraídos del volumen encontrarás varios otros detalles. Cada columna del marco de datos posee un nombre que describe un atributo extraído. El primero, htid, es el número de identificación del volumen, el cual usaste para obtener sus datos. El segundo es token, o una palabra o símbolo en el texto. POS es la categoría gramatical a que corresponde cada token – etiquetado siguiendo los “universal dependencies” (en inglés). Le siguen count o la frecuencia de cada palabra en la página, section o la sección de la página en la que se encuentra el token, y por último, el número de página.
Los valores posibles en la columna section incluyen “header” (encabezado), “body” que es el cuerpo principal de la página, y “footer” (el pie de la página). Por ejemplo, podemos leer en la tabla de abajo que la palabra dulce es un adjetivo que aparece una vez en el cuerpo de la página 37 y Salomón es un nombre propio que aparece tres veces en la misma página. Ten en cuenta que el número de página no coincide necesariamente con el número impreso en las páginas del libro que encuentras como reproducción de imagen en el sitio web. El número que nos da HathiTrust como parte de los datos corresponde a las páginas creadas en el proceso de escanear el volumen.
| htid | token | POS | count | section | page |
|---|---|---|---|---|---|
| uc1.31175010656638 | sentada | ADJ | 1 | body | 37 |
| uc1.31175010656638 | Salomón | PROPN | 3 | body | 37 |
| uc1.31175010656638 | arreglar | VERB | 1 | body | 37 |
| uc1.31175010656638 | poniéndo | VERB | 1 | body | 37 |
| uc1.31175010656638 | dulce | ADJ | 1 | body | 37 |
| uc1.31175010656638 | sollozando | VERB | 1 | body | 37 |
| uc1.31175010656638 | derramando | VERB | 1 | body | 37 |
| uc1.31175010656638 | pies | NOUN | 3 | body | 37 |
Número de tokens por página
Las opciones para clasificar los tokens que te proporciona este marco de datos son muchas. Digamos que solamente quieres contar los tokens en el cuerpo principal del texto. Para ello, puedes filtrar la tabla indicando la sección que te interesa.
maria %>%
filter(section == "body") %>%
group_by(page) %>%
summarise(num_tokens = sum(count))
# A tibble: 427 × 2
page num_tokens
<int> <int>
1 17 132
2 18 242
3 19 253
4 20 274
5 21 219
6 22 271
7 23 278
8 24 219
9 25 245
10 26 275
Algunas páginas tienen ahora una cantidad menor de tokens. Si, ademas de esto, quieres eliminar todo lo que no sea una palabra (números, signos) o errores que hayan sido introducidos al texto como resultado del proceso de digitalización, ésta es una de las muchas maneras en que puedes hacerlo. Para ello, puedes filtrar todos los tokens del cuerpo principal (“body”) que sean caracteres de tipo alfabético.
maria %>%
filter(section == "body", str_detect(token, "[:alpha:]")) %>%
group_by(page) %>%
summarise(num_tokens = sum(count))
# A tibble: 427 × 2
page num_tokens
<int> <int>
1 17 118
2 18 217
3 19 227
4 20 242
5 21 199
6 22 239
Notarás que ahora el número de tokens por página se ha reducido todavía más.
Análisis de las categorías gramaticales por página
La columna POS que clasifica las palabras según las categorías gramaticales a las que se refiere, será muy útil en casos en que trabajes con textos publicados después de 19291 a los que no tienes acceso completo, y en los que necesites saber el contexto en que una palabra está siendo utilizada. Por ejemplo, digamos que te interesa localizar la frecuencia con la que aparecen en María las palabras que aluden a las enfermedades, no sólo de la protagonista sino de otros personajes en la historia. Con frecuencia, el autor utiliza la palabra mal (“había muerto de un mal”, “síntomas de su mal”) para referirse a las enfermedades, pero en otras ocasiones, la misma palabra podría ser un adjetivo o un adverbio. Los siguientes comandos ayudan a solucionar este problema.
#crea un vector con las palabras que quieres encontrar
palabras_a_buscar <- c("enfermar", "enferma",
"enfermedad", "enfermedades",
"mal", "enfermo", "enfermos", "enfermas")
#busca esas palabras filtrando nuestra columna de tokens
enfermedad_maria <- maria %>%
filter((str_to_lower(token) %in% palabras_a_buscar))
#elimina la palabra "mal" si aparece como un adjetivo o un adverbio
enfermedad_maria<-enfermedad_maria %>%
filter(!(token == "mal" & POS %in% c("ADJ", "ADV")))
#observa los resultados
head(enfermedad_maria)
# A tibble: 6 × 6
htid token POS count section page
<chr> <chr> <chr> <int> <chr> <int>
1 uc1.31175010656638 mal NOUN 1 body 58
2 uc1.31175010656638 mal NOUN 1 body 59
3 uc1.31175010656638 enfermedad NOUN 1 body 61
4 uc1.31175010656638 enferma ADJ 2 body 65
5 uc1.31175010656638 enfermar PROPN 1 body 66
6 uc1.31175010656638 enfermedad NOUN 1 body 67
Trabajar con colecciones de HathiTrust
Aventurarse en el mundo de estudiar tendencias culturales o literarias requiere que uses mucho más que un par de volúmenes. Si vas a sacar provecho de los recursos de HathiTrust, necesitarás una manera eficaz de obtener los libros que quieras para tu estudio, sus números de identificación y los metadatos correspondientes. En inglés, existen conjuntos de datos que ya contienen los números de identificación de HathiTrust para varios grupos de textos, tanto dentro de este sitio web, como en otros lugares de internet. Véase por ejemplo este conjunto de datos que contiene los libros de ficción en inglés publicados entre 1700 y 2009, o este otro, exclusivamente enfocado en las listas de libros más vendidos publicadas por el New York Times. En español, lamentablemente, todavía no contamos con colecciones similares.
La escasez de recursos hace indispensable que crees tus propias listas de volúmenes y sus números de identificación. Por eso, recomiendo que empieces tu investigación creando una colección de los libros que te interese estudiar. El primer paso consiste en crear una cuenta en el portal de HathiTrust. En la página principal vas a ir a la sección de Log in (Iniciar sesión), en la parte superior derecha, y allí encontrarás dos opciones:
- Si perteneces a una de las instituciones afiliadas a HathiTrust puedes seleccionar esa opción y continuar.
- Crear una cuenta como usuario invitado siguiendo el enlace See options to log in as guest que aparece en el mensaje. Esa es la opción que usaremos en esta lección.
Figura 4. Enlace para usuarios invitados
El enlace que verás en la Figura 4 te llevará a la página donde podrás crear tu cuenta y también conectarla a alguna de tus cuentas de redes sociales como Facebook o Google. Selecciona lo que prefieras. Una vez creada la cuenta, te encontrarás de nuevo en la página principal.
En la parte superior de la página principal verás un menú pequeño llamado The Collection (Figura 5) y de él vas a seleccionar la opción Featured Collections (colecciones destacadas) o puedes utilizar este enlace para ir allí directamente.
Figura 5. Menú para ver las colecciones
En Featured Collections tendrás la opción de mirar colecciones que otros hayan hecho o puedes crear la tuya. Un apartado a la izquierda te dará varias opciones. Puedes, por ejemplo, buscar entre las más de ocho mil Shared Collections (colecciones que los usuarios han hecho públicas y las puedes ver, copiar o usar), o dentro de Featured Collections (las colecciones más destacadas, seleccionadas por los que trabajan para HathiTrust), y finalmente, una sección dedicada a colecciones creadas por ti, My Collections, que estará vacía en este momento.
Crear tu propia colección
Vamos a crear una colección. Usa el botón New Collection (Figura 6) de la parte derecha de esta página que te llevará a una ventana donde podremos darle un nombre a la colección, añadir información descriptiva sobre la misma (lo que hará que sea más fácil que otros la encuentren), y declarar la lista como privada o pública. La mía se va a llamar “Novelas de Ecuador (Siglo XIX y XX)”. Una vez creada la nueva categoría o colección, podrás buscar los volúmenes que quieras incluir en tu grupo. Para este ejemplo, vamos a buscar un par de novelas. La primera será Huasipungo de Jorge Icaza, la cual podemos encontrar usando el catálogo. Visita la siguiente página: https://catalog.hathitrust.org/Record/001051962.
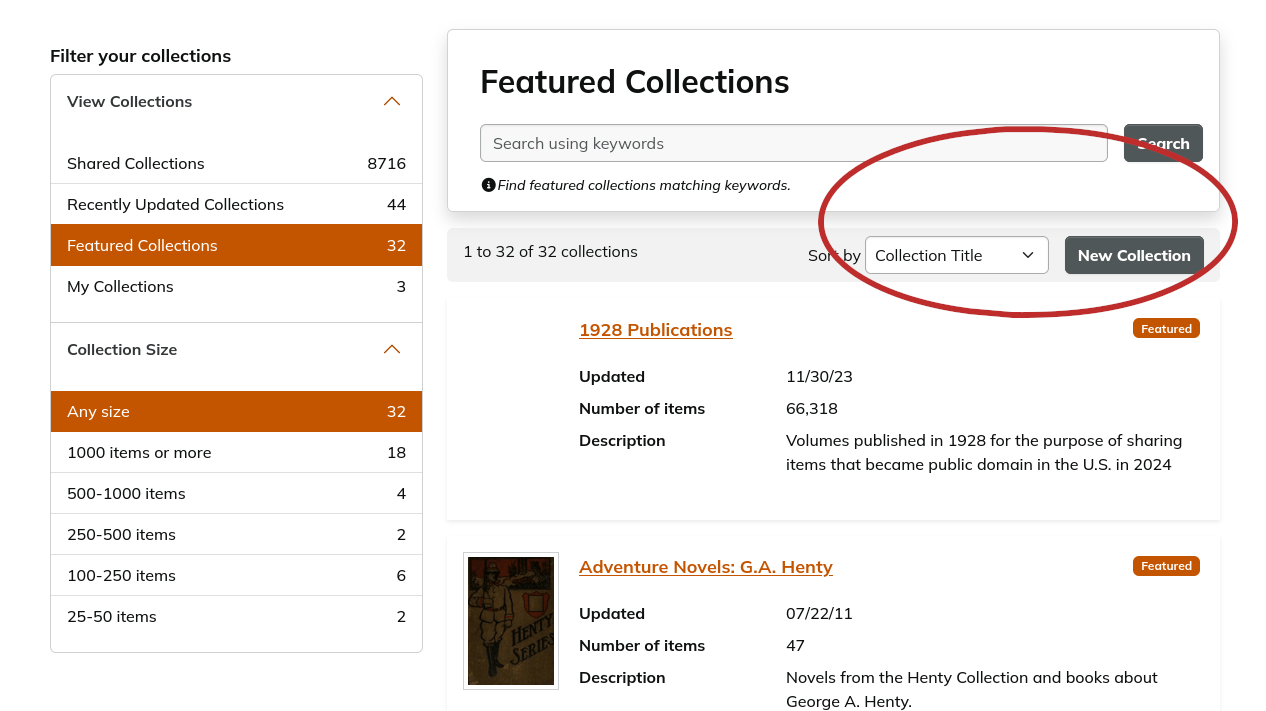
Figura 6. Nueva colección
Vale notar un par de detalles importantes de esta sección que contiene la información sobre el libro de Icaza (Figura 7). El primero es que nos informa que no podemos ver este volumen, como hicimos en el caso de María, y que sólo tenemos un acceso limitado de búsqueda (“Limited (search only)”). Esto, como ya he explicado, no afecta el acceso a los tokens y los metadatos sobre el libro a través del lenguaje R. Tenemos dos enlaces que dicen “Limited” lo cual significa que hay dos copias digitales de esta misma impresión de 1940 y que vienen de dos universidades diferentes. Esto no significa que no hayan otras versiones de Huasipungo publicadas en otros años en la biblioteca de HathiTrust. Tener tantas copias disponibles es beneficioso para los usuarios, dado que si una de las copias es de mala calidad (o por razones técnicas no está disponible), podrás utilizar otr – o una edición de fecha diferente.
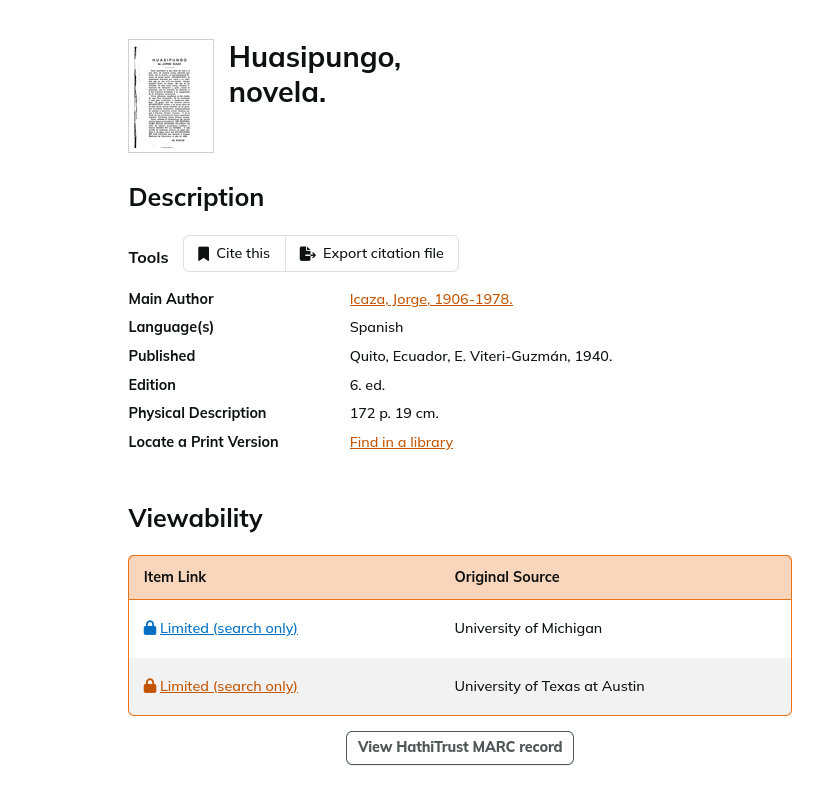
Figure 7. Huasipungo de Jorge Icaza
Si sigues uno de los dos enlaces de Limited (search only) te encontrarás con una nueva página. A la izquierda, verás el menú Collections. Como ya has creado tu colección para estas novelas, ahora tendrás la opción de fácilmente añadirla al grupo. Hagamos eso antes de continuar. Si te fijas en el URL que te ha traído a esta sección del sitio (https://babel.hathitrust.org/cgi/pt?id=mdp.39015000554751), verás que contiene también el número de identificación de HathiTrust (mdp.39015000554751) para ese volumen.
Vamos a añadir dos novelas más a la colección. Visita los próximos enlaces y tal como hiciste con Huasipungo, usando el enlace Limited (search only), añade cada uno de estos libros a la colección.
-
Las cruces sobre el agua de Joaquín Gallegos Lara https://catalog.hathitrust.org/Record/101206130
-
Más allá de las islas de Alicia Yánez Cossío https://catalog.hathitrust.org/Record/006716936
Puedes añadir otros libros que te interesen. Una vez que hayas terminado de incluir todo lo que quieras, regresa a la página de Featured Collections. El menú The Collection (Figura 5) se encuentra en todas las páginas de HathiTrust y siempre podrás usarlo para encontrar tu camino de vuelta a tus colecciones. La sección My Collections va a contener el grupo que acabas de crear, “Novelas de Ecuador (Siglo XIX y XX)” (Figura 8). Selecciona la colección, te llevará a una página donde podrás modificar (añadir o eliminar elementos, etcétera) su contenido. A mano izquierda, te encontrarás con una sección llamada Download Metadata donde podrás descargar a tu computadora los metadatos asociados con los volúmenes en esta colección. Vas a notar que entre las opciones de formato de lo que vas a descargar se encuentra “Tab-Delimited Text (TSV)” que es un tipo de archivo donde los valores se encuentran separados por tabuladores (puede ser leído por programas de hojas de cálculo). Si lo descargas obtendrás un archivo de terminación .txt cuyo nombre tiene más de veinte números. Cada vez que descargues el archivo poseerá un número diferente. Es una buena idea darle a este archivo un nombre relacionado a su contenido.
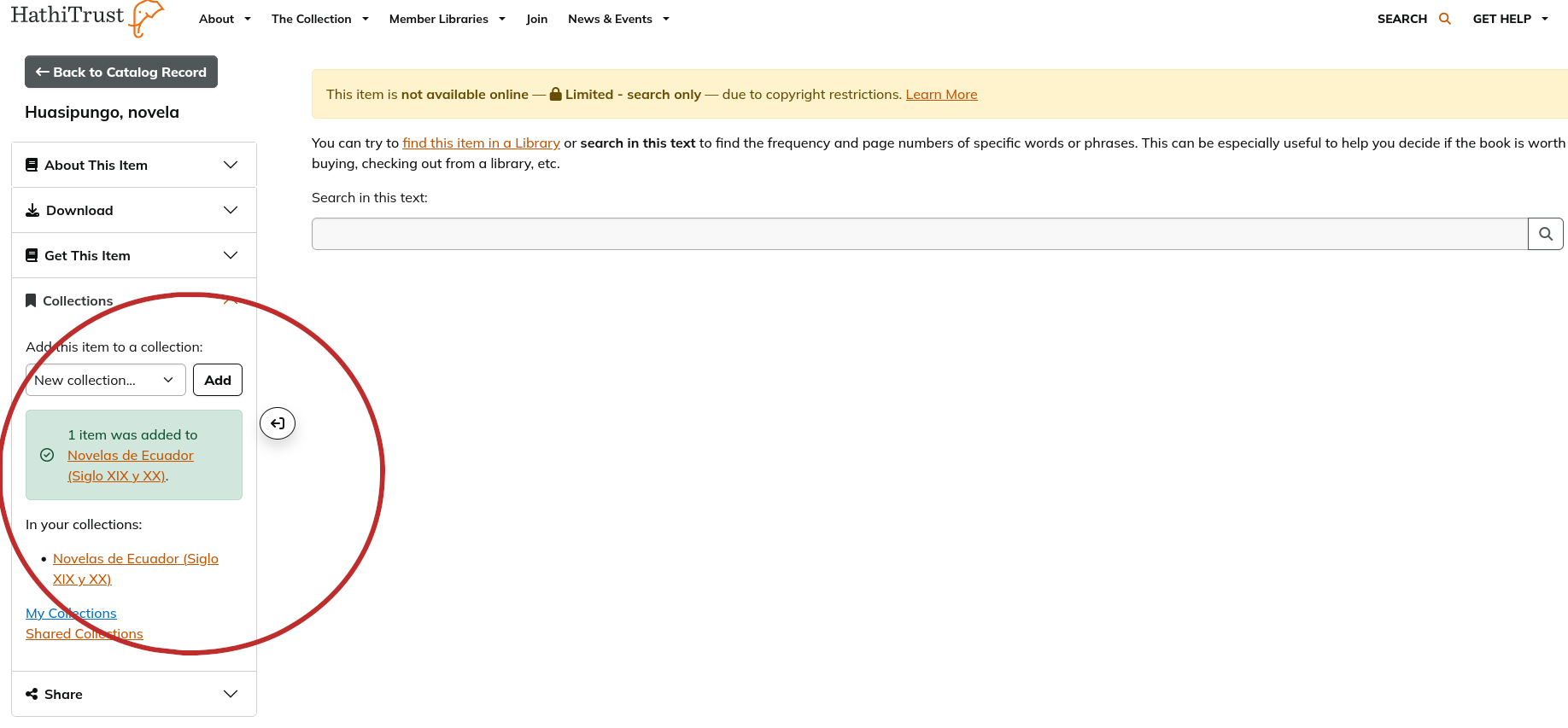
Figura 8. Añade a tu colección
Cómo usar una colección de Hathitrust para minería textual
Para esta sección vamos a utilizar una colección que ya hemos preparado de antemano y clasificado de “pública” para que cualquier persona pueda tener acceso a ella y lo que es más importante para este tutorial, para descargar los metadatos. Construir una colección dependerá del conocimiento que poseas sobre tu tema, previo a la búsqueda de los libros que incluirás en ella. Por ejemplo, sería imposible usar las opciones de búsqueda disponibles en HathiTrust para encontrar novelas ecuatorianas, ya que es una categoría demasiado específica. Lo mismo sucederá con la mayoría de los temas que te interese estudiar. Utilizar libros de consulta o artículos de investigación especializada sobre tu tema es lo más apropiado, aunque puede tener la desventaja de que tu colección se limite a los libros más conocidos o a lo que los expertos han decidido que es importante.
Vamos a comenzar esta sección de la lección siguiendo este enlace que te llevará a nuestra colección de novelas ecuatorianas. En Download Metadata descarga el archivo con los datos y cambia su nombre a 100_Novelas_de_Ecuador.tsv (también puedes obtenerlo como parte de los archivos incluidos para esta lección). Una vez tengas una copia descargada, podrás importar este archivo a R.
Antes de hacerlo, deberàs asegurarte estar en la carpeta correcta. Para leer un documento .tsv desde R necesitarás llamar la librería readr primero y después usar el comando read_tsv. Una vez el archivo haya sido importado, podremos ver las diferentes categorías de metadatos que contiene con tan solo leer los nombres de las columnas.
metadatos<- read_tsv("100_Novelas_de_Ecuador.tsv")
colnames(metadatos)
#[1] "htid" "access" "rights"
[4] "ht_bib_key" "description" "source"
[7] "source_bib_num" "oclc_num" "isbn"
[10] "issn" "lccn" "title"
[13] "imprint" "rights_reason_code" "rights_timestamp"
[16] "us_gov_doc_flag" "rights_date_used" "pub_place"
[19] "lang" "bib_fmt" "collection_code"
[22] "content_provider_code" "responsible_entity_code" "digitization_agent_code"
[25] "access_profile_code" "author" "catalog_url"
[28] "handle_url"
La columnas a utilizar en este ejercicio son htid, author, title y rights_date_used. En htid vas a encontrar el número de identificación que asigna HathiTrust al volumen. Las columnas de author (autor) y title (título) poseen la misma información que has visto en la página de Catalog Record. Y, finalmente, rights_date_used (fecha para decidir los derechos) es la fecha en la que esa edición de la obra ha sido publicada. Esta fecha podrá coincidir con la fecha de publicación, si el volumen que se encuentra en HathiTrust es la publicación original. Dicha fecha es la que se utiliza para decidir si los usuarios tienen acceso libre al texto completo del volumen o no.2 Las otras columnas no las usaremos en esta lección, pero podrás encontrar detalles de lo que significan en esta página, por si te interesan en el futuro.
Ahora que tenemos los metadatos de la colección, el próximo paso es “limpiarlos” un poco. Primero, selecciona las columnas que te interesan.
metadatos <-
metadatos %>% select(htid, author, title, rights_date_used)
Para muchos proyectos de minería textual es necesario saber con exactitud cuándo las novelas fueron publicadas. Para esta colección de novelas ecuatorianas hemos creado una tabla con el número de htid de cada novela y su fecha de publicación. El archivo, fechas.xls, lo encuentras en los documentos que acompañan a esta lección. El próximo paso, por lo tanto, será combinar ambas tablas.
fechas <- read_excel("fechas.xls")
#unimos las tablas
metadatos <- left_join(metadatos, fechas) |>
select(-rights_date_used)
Obtener los atributos extraídos para una colección
Como ya sabes, la columna de htid en los metadatos es importante porque te permitirá obtener los archivos que posean atributos extraídos de los volúmenes en tu colección. El primer método para obtener esta información que voy a describir usa el programa Rsync que los sistemas operativos de Linux y Mac ya tienen instalados. Este programa se utiliza para copiar archivos entre computadoras, entre otras funciones, y representa la manera más rápida para obtener grandes cantidades de archivos del sitio de HathiTrust. Si estás utilizando el sistema operativo Windows, podrás instalar Rsync de manera que funcione con R, pero esto puede ser un proceso complicado que va más allá de lo que cubre esta lección. Por ello, para los que trabajan en Windows y los que tengan problemas con el funcionamiento de Rsync en su sistema, en la próxima sección de este tutorial presentamos una manera alternativa de obtener los atributos extraídos.
El primer paso para obtener los datos que necesitamos es designar una carpeta temporal en la que guardarás los archivos que vengan de HathiTrust. En los próximos dos pasos, vas a usar la lista de htids para obtener los archivos con atributos extraídos (“EF files”), vas a guardarlos en tu carpeta y vas a ponerlos en la memoria temporal de tu sistema para que puedas usarlos en tu sesión de R. Para este ejemplo vamos a descargar los cien volúmenes en la colección, pero si sólo quisieras algunos de ellos, puedes indicar los que necesitas usando el número de fila (por ejemplo, si solo quieres los primeros diez, metadatos$htid[1:10]). Finalmente, guardaremos todos los resultados en una variable. Ten paciencia, el tiempo que los próximos pasos se tomen en tu computadora dependerá de factores como la capacidad de tu máquina y el tamaño de tu colección. Procedamos a ejecutar los siguientes comandos:
#selecciona una carpeta temporal donde guardar los archivos
tmpdir<-"~/documentos/tmp"
#adquiere los archivos
rsync_from_hathi(metadatos$htid, dir = tmpdir)
#pon los archivos en la memoria temporal para usarlos con Rstudio
cache_htids(metadatos$htid, dir = tmpdir)
#guarda los atributos extraídos (EF) en una variable
novelas <-
read_cached_htids(metadatos$htid, dir = tmpdir, cache_type = "ef")
Concluido el proceso revisaremos las dimensiones de nuestro marco de datos y veremos que contiene más de cuatro millones de filas y seis columnas.
dim(novelas)
#[1] 4110351 6
Podremos reducir su tamaño si eliminamos todo lo que no sean palabras o que forme parte del cuerpo principal de los libros:
novelas <- novelas %>% filter(section == "body", !str_detect(token, "[^[:alpha:]]"))
dim(novelas)
#[1] 3810243 6
Ahora puedes obtener la frecuencia de los tokens, y el resultado será un marco de datos con tres variables: el número de identificación de cada novela, el token y su frecuencia en ese texto.
novelas <- novelas %>%
group_by(token, htid) %>%
summarise(num_tokens = sum(count))
dim(novelas)
#[1] 1041775 3
head(novelas)
# A tibble: 6 × 3
# Groups: token [1]
token htid num_tokens
<chr> <chr> <int>
1 A hvd.32044018906883 197
2 A inu.30000027536063 46
3 A inu.32000004726644 64
4 A inu.32000004730166 130
5 A inu.32000004794600 291
6 A inu.32000004798858 88
Con este marco de datos y los metadatos que descargaste de HathiTrust estarás listo para analizar y visualizar tus datos.
Windows: Otra manera de construir el marco de datos
Antes de proceder a analizar este conjunto de novelas, veamos una manera alternativa de obtener los atributos extraídos de HathiTrust. Es un poco más lento, probablemente demandará más recursos de tu sistema, pero representará una alternativa si trabajas en Windows y no tienes Rsync, o si por alguna razón tu instalación de Rsync no funciona correctamente. Si regresas al ejemplo con el que empezamos esta lección, la novela María, recordarás que usamos la función get_hathi_counts() y su número de htid para obtener los tokens de ese libro.
Como ese método sólo es capaz de adquirir un volumen a la vez, necesitaremos crear nuestra propia función con un bucle for que vaya guardando la información para cada número htid que tenemos. Para este tutorial hemos incluido una función que no sólo logra este cometido, sino que además te notifica si algunos de tus números de htid no funcionan. El código se encuentra en el archivo obtener_tokens.r y necesitarás ponerlo en la misma carpeta donde tienes tu proyecto de R. Para cargarlo usa el siguiente comando.
source("obtener_tokens.r")
Ahora simplemente puedes usar la lista de números htid que tienes en los metadatos de tu colección y guardar el resultado en una variable:
resultado<-obtener_tokens(metadatos$htid)
El resultado es una lista que contiene dos elementos. El primero son los atributos extraídos y el segundo son los números htid de los archivos que no fueron encontrados por alguna razón.
novelas<- resultado[1]
no_encontrado<-resultado[2]
El primer elemento del resultado se convertirá en nuestro marco de datos con atributos extraídos. Si alguno de tus archivos fuera descargado, podrás ver su número en la variable no_encontrado.
novelas<-as.data.frame(novelas)
Notarás que tu marco de datos posee las mismas dimensiones que cuando usas Rsync, y a partir de este punto, podrás seguir los mismos pasos que en el apartado anterior para limpiar los datos y obtener las frecuencias.
novelas<-novelas %>% filter(section == "body", str_detect(token, "[:alpha:]"))
novelas <- novelas %>%
group_by(token, htid) %>%
summarise(num_tokens = sum(count))
Minería textual y próximos pasos
Ahora tienes un conjunto de datos en un formato que es perfecto para cualquier tipo de proyecto de minería textual que te interese. Como se hizo en el caso de la novela María, podríamos localizar la frecuencia de una palabra en los textos, sólo que en este caso se podría hacer en textos publicados en diferentes fechas. Digamos, por ejemplo, que me interesa saber la frecuencia relativa de las menciones del nombre de la ciudad de Guayaquil en las novelas ecuatorianas. El primer paso sería determinar la extensión de cada texto en la colección y añadir una nueva columna con esa información:
para_frecuencias_relativas <- novelas %>%
group_by(htid) %>%
mutate(total_volumen = sum(num_tokens))
Después, podremos buscar nuestra palabra:
palabra_encontrada<-para_frecuencias_relativas %>% filter(token == "Guayaquil")
Y finalmente dividimos la palabra por la cantidad de tokens en la novela y multiplicamos por la media de la longitud de los documentos.
palabra_encontrada <- palabra_encontrada |>
group_by(htid) %>%
mutate(relativa = (num_tokens / total_volumen)*70000)
> head(palabra_encontrada)
# A tibble: 6 × 5
# Groups: htid [6]
token htid num_tokens total_volumen relativa
<chr> <chr> <int> <int> <dbl>
1 Guayaquil inu.30000027536063 2 38219 3.66
2 Guayaquil inu.32000004730166 6 66686 6.30
3 Guayaquil inu.32000004794600 52 150449 24.2
4 Guayaquil inu.32000004798858 55 61421 62.7
5 Guayaquil inu.32000004799013 31 20472 106.
6 Guayaquil inu.32000004799302 15 22253 47.2
Limitaciones y recomendaciones
El propósito de este tutorial es presentar un ejemplo de cómo obtener y manipular los datos de HathiTrust para la minería textual. A pesar de sus limitaciones, los datos que podemos obtener de HathiTrust son un fantástico recurso para explorar nuevas ideas, desarrollar teorías, o investigar una tesis de manera preliminar a estudios más rigurosos.
Cuando selecciones los volúmenes para crear tu colección, escoge de ser posible la primera edición del libro pues de esa manera no tendrá introducciones, prólogos u otro material que pueda introducir tokens no relacionados con el texto principal. Si estás trabajando con cientos de volúmenes es posible que estos tokens adicionales no representen un gran problema por la escala del proyecto, pero es una buena idea evitarlos ya que no siempre será posible (o práctico) eliminarlos como hicimos en el ejemplo de María. Trabajar con los datos de cientos de volúmenes puede ocasionar que Rstudio deje de funcionar y en esos casos una solución será trabajar directamente en la consola de R, o utilizar un entorno que funcione con pocos recursos como Rcommander, para el cual puedes encontrar varios manuales en internet. En muchos casos, sin embargo, la opción más sensata será dividir los conjuntos de datos en grupos más pequeños, organizados por temas o periodos históricos.
Por último, si creas una colección interesante en HathiTrust, hazla pública y compártela con otros que estén interesados en tu tema.
Notas
-
Es decir, aunque María haya sido publicada inicialmente en 1867, si la edición que estás tratando de ver en HathiTrust fue editada después de 1928, entonces no tendrás acceso directo al texto, pero sí a las características extraídas de antemano. ↩
-
HathiTrust se rige por la ley de derechos de autor de los Estados Unidos, la cual declara que los derechos expiran después de 95 años (es decir 1929 desde nuestro punto de vista en 2024) de una obra haber sido publicada. ↩