
Contenidos
- Objetivos de la lección
- Introducción general a la lección
- Elementos básicos del Análisis de Redes Sociales
- Paso 1. Creación del corpus de análisis
- Paso 2. Conseguir los datos
- Recapitulación final de la primera parte
- Bibliografía
- Notas
Objetivos de la lección
- Conocer los elementos básicos del análisis de redes sociales y de la teoría de grafos en su aplicación a la literatura
- Aprender a extraer y estructurar los datos necesarios para llevar a cabo un análisis de redes sociales de un texto teatral
- Introducirse en el programa Gephi, especializado en visualización y análisis de redes
- Entender la utilidad y posibilidades del análisis de redes sociales para el estudio de los personajes de un texto teatral
Introducción general a la lección
Dice Miguel Escobar Varela en su libro Theater as Data que el teatro depende de relaciones1. Las relaciones entre intérpretes y público dan lugar al hecho teatral como acto comunicativo, las relaciones entre los distintos agentes de producción dan lugar al teatro como espectáculo artístico (directores y directoras, figurinistas, escenógrafos y escenógrafas, etc.) y las relaciones entre los personajes configuran la acción y el drama en su sentido literario. Todas estas relaciones (las ficcionales y las que se dan en espacios de colaboración artística) pueden ser modeladas, representadas y analizadas en forma de red o de grafo.
En esta lección trabajaremos las relaciones entre los personajes de los textos teatrales, las cuales, como planteó Franco Moretti, nos sirven para representar y estudiar la estructura interna del drama a través de su sistema de personajes, capturando en una red lo que en el teatro siempre ocurre en el presente del escenario pero que termina desapareciendo en el pasado2. Moretti habló de este proceso como la transformación del tiempo en espacio. Este espacio no es otro que el espacio interpersonal de los personajes, aquél que construyen relacionádose entre sí a través de la palabra durante sus intervenciones a lo largo del texto teatral.
Para poder estudiar las relaciones entre personajes nos serviremos del Análisis de Redes Sociales (ARS), un campo de estudio interdisciplinario que toma elementos de la sociología, la psicología, la estadística, las matemáticas y las ciencias computacionales3. Gracias al análisis de redes podemos abstraer y representar cualquier sistema formado por elementos relacionados y estudiarlo aplicando conceptos y medidas de la teoría de grafos. La informática, la física, la biología o la sociología, son disciplinas que tradicionalmente han identificado en sus campos de investigación sistemas susceptibles de estudiarse a través de redes, y recientemente también lo han hecho las humanidades, especialmente la historia4 y los estudios literarios. Del interés de la historia por el análisis de redes dan cuenta las lecciones de Programming Historian Análisis de redes temporal en R o De la hermenéutica a las redes de datos: Extracción de datos y visualización de redes en fuentes históricas. Por otro lado, los estudios literarios han utilizado el análisis de redes para el estudio de los sistemas de personajes, de las redes de producción literaria, para representar los resultados del análisis estilométricos de autoría, etc5. Por ejemplo, sobre el estudio de personajes tetrales a través del análisis de redes sociales, podemos destacar los trabajos del grupo de investigación HDAUNIR a partir del corpus BETTE6; y sobre el estudio de la novela y sus personajes los trabajos de Isasi7.
El análisis de redes sociales es para la crítica literaria una metodología de tipo “distant reading” (lectura distante) en términos de Moretti8, o “macroanlysis” si preferimos el concepto de Matthew L. Jockers9. Es decir, nos permite estudiar grandes cantidades de textos a través de sus formas, relaciones, estructuras y modelos10, al cambiar el foco de atención de las características individuales a las tendencias o patrones de repetidas en un corpus 11. Más recientemente, Escobar Varela ha investigado las posibilidades de estudiar el teatro a través de datos como parte de lo que denomina “computational theater research”12. Este concepto refiere a los estudios teatrales computacionales en su sentido más amplio; incluye los enfoques escénicos además de los literarios. Desde un enfoque puramente textual, dentro de los “Computational Literary Studies”(CLS), está en proceso de conformación un área especializada en teatro, denominada “Computational Drama Analysis”, que integra el análisis de redes sociales, junto a otras metodologías cuantitativas y computacionales, tal como la estilometría, el análisis de sentimientos o el modelado de tópicos13.
Para llevar a cabo un análisis de redes sociales de personajes teatrales debemos seguir una serie de pasos consecutivos:
- Paso 1. Creación del corpus de análisis
- Paso 2. Conseguir los datos
- Toma de decisiones para la extracción de datos
- Extracción y estructuración de datos
- El proceso de vaciado
- Paso 4. Visualización y análisis de grafos con Gephi
- Paso 5. Interpretación de los resultados
En esta primera parte de la lección vamos a ver el Paso 1 y el Paso 2. En la segunda parte, profundizaremos en el Paso 3 y el Paso 4. Si te interesa más la creación de visualizaciones y aplicación de medidas, puedes pasar a la segunda parte de la lección y utilizar el “dataset” (conjunto de datos) que acompaña la lección; sin embargo, recomendamos seguir la lección completa, ya que el proceso de recogida de datos es fundamental para comprender el análisis de redes sociales como metodología de análisis cuantitativo.
Elementos básicos del Análisis de Redes Sociales
Antes de comenzar, es necesario conocer algunos elementos y conceptos del ARS:
Una red o grafo (son términos sinónimos) es, en su forma representada, un grupo de puntos unidos por líneas. A los puntos se les llama nodos o vértices y a las líneas se las conoce como aristas o enlaces. En esta lección preferiremos los términos nodos y aristas, respectivamente, pues son los que comunmente encontramos en la literatura en español.
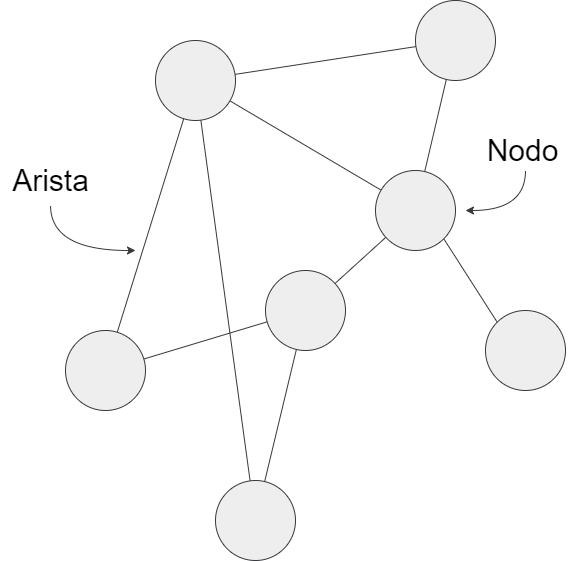
Figura 1. Red o grafo formado por nodos y aristas
Un grafo no es más que la representación de un sistema cualquiera formado por elementos (nodos) relacionados entre sí (a través de las aristas). Gracias al ARS podemos estudiar estos sistemas de elementos y relaciones y, aunque no es necesario llegar a crear las representaciones propiamente dichas, la visualización de los datos en redes suele estar siempre presente en estos análisis.
Los grafos pueden ser de dos tipos: no dirigidos, cuando la relación entre los elementos del sistema es siempre bidireccional en igualdad de condiciones o la direccionalidad no es relevante; y dirigidos, cuando la relación entre los elementos del sistema tiene una direccionalidad explícita, relevante, o en un solo sentido (aunque puede darse una bidireccionalidad dirigida entre dos nodos: A con B y B con A). En este segundo caso, la dirección de las aristas se representa en los grafos a través de flechas o de líneas curvas en el sentido de las agujas del reloj.
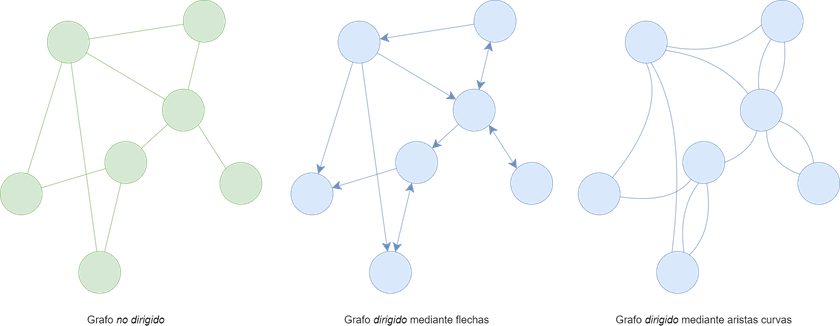
Figura 2. (a) Grafo no dirigido; (b) grafo dirigido mediando flechas; (c) grafo dirigido mediante aristas curvas
En una red social cada nodo corresponde a una persona (o personaje) del sistema. El número de otros nodos con los que un nodo concreto está conectado a través de aristas, se conoce como grado. En el caso de los grafos dirigidos (no ocurre en los no dirigidos), el grado tiene dos subtipos: de entrada y de salida. Si tomamos como referencia un nodo concreto, la cantidad de nodos cuyas flechas dirigen hacia él sería el grado de entrada y la cantidad de nodos a los que estas dirige sería el grado de salida. Por tanto, la suma del grado de salida y el de entrada nos da el grado (a secas), pero estos pueden diferir.
Por otro lado, las aristas suelen tener un valor numérico asociado que representa la frecuencia de la relación entre los nodos que conecta. Este valor se conoce como peso de la arista y generalmente se representa a través del grosor de las líneas:
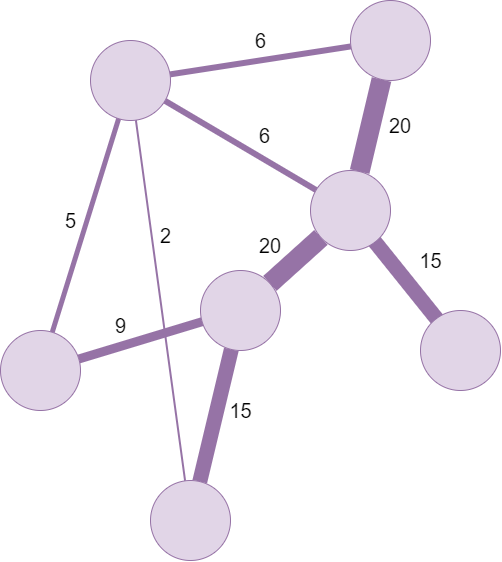
Figura 3. Grafo con las aritas pesadas, indicándose a través de su grosor
Paso 1. Creación del corpus de análisis
Un corpus de análisis puede estar formado por un solo texto o por muchos, en principio, sin ningún límite. Centrándonos en el análisis de redes sociales de personajes teatrales, puede darse el caso de que nos interese estudiar las relaciones de los personajes de una obra concreta: entender quién habla más con quién, quién está más tiempo en el escenario, quién menos, y qué relación tiene eso con el desarrollo de la trama, localizar si hay algún personaje que nunca habla o comparte escena con otro, etc. También podría interesarnos realizar un análisis literario comparado, y localizar similitudes y diferencias en la concepción de las relaciones de los personajes en todas las obras de un mismo autor, o en las obras de un cierto periodo o pertenecientes a un mismo subgénero teatral. Al final, el corpus debe responder a nuestras necesidades, a nuestras preguntas y objetivos de investigación. En esta lección trabajaremos con una sola obra, Las bizarrías de Belisa de Lope de Vega. Si quisieras construir un corpus de análisis más grande, mi recomendación sería consultar el artículo de José Calvo Tello “Diseño de corpus literario para análisis cuantitativo”14, en el que se explican las diferencias entre los conceptos estadísticos de población y muestra, y cómo crear un corpus de análisis que sea más o menos representativo según el tipo de muestra que elijamos: (1) la población completa, (2) una muestra aleatoria, (3) una muestra balanceada según un criterio preestablecido (temporal, autorial, etc.) o (4) un corpus oportunístico.
Un poco de contexto: Las bizarrías de Belisa es una comedia perteneciente al subgénero urbano o “de capa y espada” escrita por el dramaturgo español Lope de Vega (1562-1635) en 1634, lo que la convierte en una de sus últimas obras y la última dentro de este subgénero15. Por lo tanto, es una obra que pertenece al llamado Siglo de Oro del teatro español y más concretamente a la “comedia nueva”, fórmula dramática desarrollada principalmente por Lope de Vega. Por tanto, en la obra podemos observar características típicas como la división en tres actos o jornadas, presencia de personajes tipo como la dama, el galán y el gracioso-criado, una polimetría que relaciona tipo de estrofas con situaciones concretas… Las bizarrías de Belisa se enmarca dentro del subgénero urbano o “de capa y espada” por su tema amoroso y trama construida a partir de los juegos de enredo, por su ambientación urbana y gran protagonismo de la ciudad y sus habitantes, por su localización temporal contemporánea y por la ruptura de la verosimilitud con recursos como escondites y disfraces varoniles. La crítica la ha considerado como una de las obras más perfectas de Lope, ya que supo integrar en ella todo lo aprendido en sus más de cincuenta años como dramaturgo y además adaptar alguna de las novedades del momento: “Lope procede a una estilización y revisión de las convenciones genéricas creando una comedia capaz de rivalizar con las de los jóvenes dramaturgos que le roban en su opinión el aplauso del público”16.
¿Y por qué trabajaremos con esta obra? El teatro como género literario se presta especialmente al Análisis de Redes Sociales por su clara estructura: intervenciones de personajes y acotaciones. Así, encontramos ya delimitada (a diferencia de la novela, por ejemplo) la participación de los personajes en la red social general (el conjunto total de personajes que intervienen) y solo tendremos que extraer la información que está ya ahí. En el párrafo anterior he mencionado que Las bizarrías de Belisa, como las demás obras del subgénero urbano, está construida a partir de juegos de enredo: personajes disfrazados, engaños, tretas, personajes ocultos… La acción enmarañada de estas comedias puede ser algo compleja de entender, pero el Análisis de Redes Sociales nos puede ayudar a desenredar la acción al plasmar gráficamente las complejas relaciones que se establecen entre los personajes, ofreciéndonos a la vez datos cuantitativos sobre la red social que sustenta dicha acción.
Paso 2. Conseguir los datos
Toma de decisiones: ¿qué datos necesitamos?
Una vez tenemos el texto o textos que queremos analizar, lo siguiente es conseguir los datos. Si pensamos un texto teatral como una red de nodos y aristas, los nodos serían los personajes y las aristas las relaciones entre estos. ¿Pero qué entendemos por relación entre personajes? ¿Cómo cuantificamos esta relación para poder darle un peso a las aristas?
En los estudios de ARS de teatro se utilizan dos criterios para cuantificar la relación entre personajes:
- Coaparición de personajes en escena
- Interacción lingüística directa entre personajes
Ambos criterios son perfectamente válidos y tienen numerosos trabajos que los respaldan, pero cada uno permite construir un tipo de grafo concreto. Por lo tanto, en función de nuestras preguntas y objetivos de investigación, deberemos elegir un criterio u otro. En esta lección vamos a explicar los dos para que después, cuando trabajes con tus textos, puedas decidirte por uno u otro.
Según el criterio de la coaparición de personajes en escena, dos personajes están relacionados si intervienen en una misma escena. Así, cuantificaremos todas las veces que un personaje dado coincide en escena con cada uno de los demás, indepedientemente si interactúan o no. Por lo tanto, este criterio solo nos permite construir grafos no dirigidos, en los que la relación entre nodos es neceariamente bidireccional.
Según el criterio de la interacción lingüística directa entre personajes, estos están relacionados si hablan entre sí, por lo que se anota y cuantifica cada vez que un personaje se dirige a otro. Por lo tanto, este criterio nos permite construir grafos dirigidos, en los que la relación entre nodos es en las dos direcciones o en una sola: el personaje 1 puede dirigirse al personaje 2, pero el personaje 2 puede no responder al 1.
Como vemos, en ambos criterios trabajamos solo con los personajes que intervienen verbalmente en la obras, a pesar de que con el criterio de coaparición en escena sí podríamos tener en cuenta también a los personajes que están presentes pero no hablan. Sin embargo, esto a veces no es fácil de determinar con la lectura del texto y es durante el montaje de la representación que se descubre qué personajes pueden o deben estar en escena en cada momento. Además, cuando se realizan ARS de personajes utilizando métodos de extracción automática (utilizando un “script” (guión)), primero se lleva a cabo una anotación de las intervenciones de personajes, por ejemplo codificando el texto en XML-TEI y haciendo uso etiquetas como <sp> para marcar cada intervención y el atributo who para identificar a cada personaje de forma inequívoca. Por esta razón, y para tratar de que nuestros análisis puedan compararse con los de otras personas, lo mejor es centrarse en los personajes que sí hablan.
Bien, sabemos quiénes son los nodos (los personajes, que podemos extraer del dramatis personae) y podemos identificar las aristas y su peso (las relaciones entre personajes, según uno u otro criterio de cuantificación, y el número de veces que se relacionan). Estos son los datos mínimos para realizar un análisis de redes sociales. Sin embargo, aún podríamos extraer más datos de un texto teatral en función de nuestros intereses y de cuánto queramos enriquecer el análisis. Tanto los nodos como las aristas pueden tener una serie de atributos, como si fueran metadatos de los personajes y de sus relaciones. Estos atributos son informaciones cualititativas que posteriormente nos pueden servir para enriquecer las visualizaciones y para el análisis de los datos resultantes. Por ejemplo, podría interesarnos recoger el género de los personajes (mujer, hombre, no binario, no aplicable, etc.) y su función dentro de la obra (por ejemplo: dama, galán, criado, etc.); o el tipo de relación entre los personajes (romántica, familiar, etc.). Volveremos sobre ello en los siguientes apartados.
Extracción y estructuración de datos: ¿Cómo estructuramos los datos?
Lo primero que necesitamos recoger son los datos sobre los nodos, y lo haremos en lo que se conoce como “lista de nodos”. En ella se recogen los nombres de los personajes (“label” (etiqueta)), un identificador (id) numérico individual que le otorgamos a cada personaje y sus atributos (en caso de que quisiésemos registrar metadatos). Así se vería una lista de nodos:
id,label,atributo1,atributo2
1,Nodo1,______,______
2,Nodo2,______,______
3,Nodo3,______,______
Como ves, los datos están estructurados utilizando saltos de línea y comas. Es lo que se conoce como CSV (del inglés “Comma Separated Values”). CSV es un formato abierto que representa datos tabulados de manera más sencilla, en donde los valores de cada columna se separan por comas y los de cada fila por un salto de línea. Este es el formato que todos los programas de análisis de redes pueden importar, por lo que será el formato final de nuestros datos. Sin embargo, para facilitar el trabajo de extracción y estructuración, vamos a recoger nuestros datos utilizando hojas de cálculo en el programa de tu preferencia (como Microsoft Excel, LibreOffice Calc o Google Sheets). Estos programas trabajan con documentos en los que se estructuran datos usando tablas, con filas y columnas que forman una matriz de celdas, y posteriormente nos permiten exportar dichas tablas en el formato CSV que necesitamos.
Entonces, la lista de nodos de arriba se vería así en una hoja de cálculo:
| id | label | atributo1 | atributo2 |
|---|---|---|---|
| 1 | Nodo1 | — | — |
| 2 | Nodo2 | — | — |
| 3 | Nodo3 | — | — |
Por otro lado, para estructurar los datos relativos a las aristas existen dos métodos distintos:
- Lista de aristas
- Matriz de adyacencia
En una lista de aristas se anota el nodo de origen (“source”), el nodo de destino (“target”), el peso de la arista que les une (“weight”)17 y el tipo de relación (“type”), que como hemos visto puede ser dirigida (“directed”) o no dirigida (“undirected”). Además, podríamos anotar atributos de las aristas utilizando una etiqueta (“label”). Una lista de aristas para un grafo no dirigido quedaría de esta forma:
Source,Type,Target,Weight,label
Nodo1,Undirected,Nodo2,7,______
Nodo1,Undirected,Nodo3,3,______
Nodo2,Unidrected,Nodo3,6,______
Si quisiésemos generar un grafo dirigido, en cambio, deberíamos doblar cada relación: una para el Nodo1 hacia el Nodo2 y otra para el Nodo2 hacia el Nodo1. Mira un ejemplo:
Source,Type,Target,Weight,label
Nodo1,Directed,Nodo2,7,______
Nodo2,Directed,Nodo1,6,______
Nodo2,Directed,Nodo3,6,______
Nodo3,Directed,Nodo2,5,______
Nodo1,Directed,Nodo3,8,______
Nodo3,Directed,Nodo1,8,______
De nuevo, estructuramos los datos en formato CSV, pero es más fácil si lo hacemos en una hoja de cálculo que después exportamos. Para ello, cada valor separado por coma se corresponderá con una columna y cada línea de valores con una fila.
En una “matriz de adyacencia” recogemos los datos referentes a las aristas en una matriz cuadrada, en donde la primera columna representa los nodos de origen y la primera fila los nodos de destino, siempre numerando cada fila y columna con los identificadores (id) que les otorgamos a los personajes al crear la lista de nodos. En las intersecciones entre columnas y filas anotaríamos el peso de la arista entre nodos, la cuantificación de la relación entre dos personajes. Así se vería una matriz de adyacencia vacía, solo con los id de los personajes (ten en cuenta que las relaciones no existentes deben de tener siempre valor 0):
1 2 3 4 5 6
1 0 0 0 0 0 0
2 0 0 0 0 0 0
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 0 0 0 0 0
6 0 0 0 0 0 0
Si estamos estructurando los datos de un “grafo no dirigido” (pensemos en la coaparición de escenas), anotaríamos el peso de la relación entre dos personajes tanto en el lugar en el que se interseca el Nodo1 con el Nodo2 como Nodo2 con el Nodo1. Por ejemplo, en esta matriz leemos que 1 y 2 comparten 4 escenas:
1 2 3 4 5 6
1 0 4 0 0 0 0
2 4 0 0 0 0 0
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 0 0 0 0 0
6 0 0 0 0 0 0
En cambio, si vamos a construir un grafo dirigido (pensemos en la interacción lingüística entre personajes), podemos anotar valores distintos en cada intersección. Por ejemplo, en esta matriz leemos que el Nodo1 dirige nueve de sus intervenciones al Nodo2 pero el Nodo2 solo habla cuatro veces al Nodo1.
1 2 3 4 5 6
1 0 9 0 0 0 0
2 4 0 0 0 0 0
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 0 0 0 0 0
6 0 0 0 0 0 0
Las matrices de adyacencia también las necesitamos en formato CSV, por lo que cada número debería ir separado por comas, así:
,1,2,3,4,5,6
1,0,9,0,0,0,0
2,4,0,0,0,0,0
3,0,0,0,0,0,0
4,0,0,0,0,0,0
5,0,0,0,0,0,0
6,0,0,0,0,0,0
Una vez más, para facilitar el trabajo de recogida de datos, utilizaremos hojas de cálculo en las que, numerando las filas y columnas, anotamos los pesos de las relaciones en las celdas que se encuentran en las intersecciones. Es muy importante que hagamos coincidir la numeración de la matriz de adyacencia con el id que le hemos asignado a cada personaje en la lista de nodos, de forma que el programa de análisis de redes pueda vincular a cada nodo con sus relaciones. Así se vería una matriz de adyacencia en una hoja de cálculo:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | 0 | 9 | 0 | 0 | 0 | 0 |
| 2 | 4 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 |
En las matrices de adyacencia no podemos etiquetar (“label”) las aristas, pero los programas de análisis de redes permiten modificar los datos y añadir dicha información después de la importación.
El proceso de vaciado
Ya sabemos qué datos necesitamos extraer del texto teatral y cómo estructurarlos para poder realizar un análisis de redes. Ahora, pasemos a la práctica. Vamos a analizar Las bizarrías de Belisa basándonos en los dos criterios explicados. Así podremos comprender bien cómo se aplica cada uno y sus diferencias, lo que te ayudará después a decidirte por uno u otro criterio. Para seguir la lección, puedes encontrar este texto en formato .txt.
Los nodos
Vamos a empezar creando la lista de nodos, que nos funciona tanto para un ARS basado en la coaparición en escena como para uno basado en las interacciones lingüísticas. Podemos extraer la lista de personajes del dramaties personae, ¡pero recuerda hacer una lectura atenta de la obra para comprobar que no falta ninguno! En nuestro caso, la edición de la obra con la que trabajamos recoge bien todos los personajes, así que no debes preocuparte en este sentido.
Primero, crea una hoja de cálculo en el programa que tú prefieras18. Puedes llamar al documento datos_bizarrias.(xlsx/gsheet/odf) y a la primera hoja “Lista de nodos”. En esta hoja, escribe en la primera fila:
iden la primera colummnalabelen la segunda columnagéneroen la tercera columnafunciónen la cuarta columna
género y función son atributos de los nodos, metadatos de los personajes. Recuerda que puedes anotar todos los que quieras en las siguientes columnas.
Lo siguiente es rellenar las celdas:
- Recoge los nombres de los personajes en la columna
label - Numera las celdas
iddel 1 al 11 (once personajes intervienen verbalmente en Las bizarrías de Belisa, dejando deliberadamente fuera a los músicos, criados, lacayos, y a los dos hombres. Unos se considera personajes no computables, por lo que al no estar individualizados no nos interesan, y otros sí aparecen en escena pero no hablan - Anota el género (mujer/hombre) de los personajes en la columna correspondiente
- Anota la función de los personajes en la comedia según esta clasificación: dama, galán, criado, criada, figura de autoridad (padre, madre, tía, hermano de la dama, etc.), figura de poder (rey, gobernador, etc.)
Debería quedarte una tabla así:
| id | label | género | función |
|---|---|---|---|
| 1 | Belisa | Mujer | Dama |
| 2 | Finea | Mujer | Criada |
| 3 | Celia | Mujer | Dama |
| 4 | Lucinda | Mujer | Dama |
| 5 | Fabia | Mujer | Criada |
| 6 | Don Juan | Hombre | Galán |
| 7 | Tello | Hombre | Criado |
| 8 | Octavio | Hombre | Galán |
| 9 | Julio | Hombre | Criado |
| 10 | Conde Enrique | Hombre | Galán |
| 11 | Fernando | Hombre | Criado |
Ahora exporta la hoja en formato CSV y llama al archivo nodos_bizarrias.csv:
- En Google Sheets ve a Archivo>Descargar>Valores separados por comas (
.csv) - En Micrososft Excel ve a Archivo>Guardar como>Tipo>CSV (delimitado por comas) (
\*.csv) o Exportar>Cambiar el tipo de archivo>CSV (delimitado por comas) (\*.csv) - En LibreOffice Calc ve a Archivo>Guardar como>Tipo>Texto CSV (
\*.csv)
¡Ya tienes preparada la lista de nodos!
Las aristas
Para extraer los datos de las aristas recuerda que primero debes elegir el criterio de cuantificación, en función de lo que te interese investigar. Para estructurar los datos obtenidos al aplicar ambos criterios a un texto teatral, podemos usar tanto el método de la lista de aristas, como el de la matriz de adyacencia, aunque en general resulta más cómodo usar la lista de aristas para los grafos no dirigidos y la matriz de adyacencia para los dirigidos. Así lo haremos en esta lección.
Lista de aristas para grafos no dirigidos basados en la coaparición de personajes en escena utilizando Easy Linavis
En el mismo archivo en el que creaste la lista de nodos, datos_bizarrias, crea una nueva hoja y llámala “Lista de aristas”. En esta hoja debes escribir en la primera fila lo siguiente, tal y como está en la plantilla :
Sourceen la primera columnaTypeen la cuarta columnaTargeten la segunda columnaWeigthen la tercera columnaLabelen la quinta columna
Lo siguiente es rellanar las celdas, para cual deberías ir anotando cada vez que un personaje (source) comparte escena con otro (target) y la cantidad de escenas que comparten (weight). Como usaremos la lista de aristas para generar un grafo no dirigido, en todas las celdas type escribiremos “undirected” (no dirigido). Después, anotaremos el tipo de relación (label) según una clasificación preestablecida.
Como puedes estar imaginando, se trata de un proceso tedioso. Pero no te preocupes, utilizaremos una herramienta web de libre acceso que nos va a facilitar mucho el trabajo: Easy Linavis, desarrollada y alojada por el proyecto DraCor (DramaCorpora). Esta herramienta nos permite introduccir cada acto y escena y los nombres de los personajes que en ellas intervienen, y a partir de estos datos nos genera un lista de aristas que podremos descargar en formato CSV. Además, mientras introducimos los datos, Easly Linavis va generando un grafo de la obra que nos ayuda en el proceso.
Puedes acceder a Easy Linavis a través de la web de DraCor (desde el menú desplegable TOOLS) o directamente utilizar este enlace: https://ezlinavis.dracor.org/. Una vez dentro (no hace falta registrarse para poder usarla) verás una disposición en tres columnas. En la primera introduciremos los datos, en la segunda se generará la lista de aristas y en la tercera el grafo. Además, en el menú arriba a la izquierda encontrarás un desplegable con ejemplos, tipos de grafos (tres algoritmos de distribución distintos, más adelante veremos qué es esto), y un “about” con información sobre la herramienta y su uso (solo en inglés, pero puedes utilizar una extensión de traducción del navegador para traducirlo automáticamente).
El formato en el que tenemos que introducir los datos es muy sencillo. Puedes hacerlo directamente en la columna correspondiente o escribirlo en un documento aparte y luego copiar y pegar. Mi recomendación es que comiences a escribir en la herramienta, ya que con colores rojo y verde te indica si estás respentando el formato correcto. Una vez aprendas, continúa en un documento aparte que puedas guardar: ¡si se cierra la página o el navegador perderás tu trabajo! Este documento aparte debería ser un archivo de texto simple sin formato (texto plano) como un TXT, pues así contendrá solamente caracteres y no deberás preocuparte al copiar y pegar del archivo a la herramienta Easy Linavis. Para ello, utiliza el Bloc de notas que viene nativo en Windows, TextEdit en Mac o tu editor de texto (no procesador como Word o Pages) preferido: VS Code, Atom, Sublime Text, NotePad++, etc.
El formato de datos que implementa Easy Linavis es muy sencillo:
1. Escribe el título de la obra, su autor y otros datos que te interesen (año de escritura o publicación, edición seguida, tu nombre, etc.) sin dejar saltos de línea en blanco. Esta información no es obligatoria pero puede servirte para identificar cada obra si estás analizando un corpus grande y terminas teniendo muchos archivos:
"Las bizarrías de Belisa" (1634) de Lope de Vega
Criterio: coaparición de personajes en escena
Edición seguida: https://artelope.uv.es/biblioteca/textosAL/AL0525_LasBizarriasDeBelisa.php
Responsable: David Merino Recalde
Fecha: 12-09-2022
2. Seguido, dejando ahora sí un salto de línea, anota la estructura básica de la obra (actos y escenas) utilizando asteriscos para jerarquizar las divisiones:
# ACTO 1
## Escena 1
## Escena 2
## Escena 3
etc.
# ACTO 2
## Escena 1
## Escena 2
## Escena 3
etc.
# ACTO 3
## Escena 1
## Escena 2
## Escena 3
etc.
3. Recoge los nombres de los personajes que intervienen (no los que simplemente aparecen) en cada escena bajo el epígrafe correspondiente.
# ACTO 1
## Escena 1
Finea
Belisa
## Escena 2
Belisa
Celia
## Escena 3
Don Juan
Tello
etc.
Sigamos:
- Si has terminado de recoger la coaparición de personajes en el fichero
datos_bizarrias-easylinavis.txt, copia y pégalo en Easy Linavis. Una vez tengas el listado en la herramienta, comprueba que hay una línea verde a la izquierda de la columna. Si está de color rojo te está indicando que hay un error en el formato (un salto de línea donde no debe, un asterisco mal situado, etc.). A la derecha te aparecerá un grafo: revisa también que no haya personajes repetidos con nombres distintos (por ejemplo un Conde y un Conde Enrique, o una Lucinda y una Luncinda). Una vez tengas claro que todo está correcto, en la columna del centro, haz clic en download CSV y guarda el archivo comodatos_bizarrias-easylinavis.csv. - Este archivo que has descargado ya podrías importarlo en un programa de análisis de redes, pero queremos introducir un atributo a las relaciones. Ve a la hoja de cálculo en la que hemos estado trabajando y borra la hoja que primero nombramos “Lista de aristas”. Ahora importa el archivo CSV creando una nueva hoja dentro del mismo documento:
- En Google Sheets: Archivo>Importar>Seleccionar el CSV de Google Drive o Subir/Arrastrar>Ubicación de importación:Insertar nuevas hojas>Tipo de separador:Coma>Importar datos
- En Microsoft Excel: Datos>Obtener datos>De un archivo>De texto/CSV>Seleccionar el CSV y Abrir>Delimitador:Coma>Cargar
- En LibreOffice Calca: Hoja>Insertar hoja desde archivo>Seleccionar el CSV y Abrir>Separado por: Coma>Aceptar>Posición:Detrás de la hoja actual/Hoja:Desde Archivo>Aceptar
- Ahora cambia el nombre de la nueva hoja a “Lista de aristas” y añade de nuevo la columna después de
WeightllamadaLabel. Vuelves a tener la misma lista que creamos antes pero con la mayoría de datos completados. Solo te falta clasificar cada relación según esta tipología: amor recíproco, amor no correspondido, rivalidad, amistad, relación efímera, familiar, servidumbre, etc. - Una vez hayas terminado de completar datos, utilizando la opción “Buscar y reemplazar”, reemplaza los nombres de los personajes por el número
idque les otorgaste en la lista de nodos - Por último, exporta la hoja actual y llama al archivo
aristas-coaparicion_bizarrias.csv.
¡Ya tienes preparada la lista de aristas!
Matriz de adyacencia para grafos dirigidos basados en las interacciones lingüísticas entre personajes
Si escoges analizar el texto teatral basándote en las interacciones lingüísticas directas y construir un grafo dirigido, lo mejor es utilizar una matriz de adyacencia para estructurar los datos que necesitas extraer. Para ello, crea un nueva página en la hoja de cálculo base en la que estás trabajando y llámala “Matriz de adyacencia”.
En esta nueva página, deberías numerar la primera columna y fila del uno al once, dejando libre la primera celda, tal y como vimos más arriba en el ejemplo. Para facilitarnos el trabajo, en vez de utilizar números escribiremos los nombres de los personajes en el mismo orden que en la “Lista de nodos”. Más tarde, simplemente sustituiremos cada nombre por su id como hemos hecho con la lista de aristas.
Así una tabla en la que se ve la matriz de adyacencia vacía preparada para introducir los datos de Las bizarrías de Belisa, con los nombres de los personajes en la primera columna y fila:
| Belisa | Finea | Celia | Lucinda | Fabia | Don Juan | Tello | Octavio | Julio | Conde Enrique | Fernando | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Belisa | |||||||||||
| Finea | |||||||||||
| Celia | |||||||||||
| Lucinda | |||||||||||
| Fabia | |||||||||||
| Don Juan | |||||||||||
| Tello | |||||||||||
| Octavio | |||||||||||
| Julio | |||||||||||
| Conde Enrique | |||||||||||
| Fernando |
Una vez tengas la matriz base debes comenzar a recoger los datos contando las interacciones lingüísticas. El criterio básico es el siguiente: si el personaje 1 habla con el personaje 2, sumamos 1 en la celda que se encuentra en la intersección entre la fila de 1 y la columna de 2. Habrá intervenciones muy claras y otras que generen ambigüedad, intervenciones que no van dirigidas necesariamente a ningún personaje (por ejemplo: a sí mismo, al público, un ruego a una divinidad, etc.), intervenciones de un personaje a varios… Por esta razón debemos fijar primero unos criterios de extracción y anotación que tengan en cuenta todas estas posibles situaciones (detectables solo a través de una lectura atenta del texto). La idea es que estos criterios nos guíen en la toma de decisiones y siempre resolvamos de la misma forma las situaciones complejas, posibilitando el análisis comparado de textos que hayan sido analizados siguiendo nuestros criterios de extracción y anotación.
Para esta lección vamos a utilizar los siguientes criterios, diseñados para analizar comedias del siglo Siglo de Oro español como la que estamos utilizando en esta lección:
- Se anotará cada interacción directa de un personaje hacia otro, entendiendo al primero como emisor y al segundo como receptor 1.1 Por norma general, cada intervención marcada en el texto equivale a una interacción, y esta interacción puede tener uno o varios receptores: 1.1.1. Si A se dirige a B, se anotará 1 de A a B 1.1.2. Si A se dirige a B y C, se anotará 1 de A a B y 1 de A a C 1.2. Casos especiales: 1.2.1. Una intervención marcada en el texto puede tener varias partes y, por tanto, contener distintas interacciones si el emisor cambia el personaje a quien se dirige. Así, en una misma intervención, podrían anotarse dos versos de A a B y tres versos de A a C 1.2.2. Una interacción interrumpida por otro personaje que continúa tras el corte (versos partidos) se registrará como una interacción, a pesar de estar distribuida en dos intervenciones
- Del criterio anterior, por tanto, se deduce lo siguiente: 2.1. Si un personaje C está en escena pero no es el receptor directo de la intervención que se está registrando de A a B, dicha intervención no se le anotará a C aunque se entienda que necesariamente ha tenido que escuchar esta interacción por estar presente 2.2. Si un personaje habla en escena pero no hay ningún otro personaje receptor, dicha intervención no se registrará. Es el caso de los monólogos que algunos personajes pronuncian al quedarse solos en escena, muchas veces en forma de soneto 2.3. Si un personaje interviene y, a pesar de haber otros personajes en escena, ninguno de ellos es el receptor directo, dicha intervención no se registrará. Es el caso de los apartes a público, pues los apartes entre personajes entran dentro del caso 1.1.1 2.4. Si un personaje se dirige al público para cerrar la comedia, dicha intervención no se registrará, pues el receptor es el público y no otro personaje19
Una vez tenemos los criterios claros, comenzamos a leer la obra y a anotar. Por ejemplo, el primer acto comienza así:
FINEA: ¿Así rasgas el papel?
BELISA: Cánsame el Conde, Finea.
Finea dirige su primera intervención a Belisa y esta le responde. Por lo tanto, en nuestra matriz de adyacencia deberíamos anotar 1 de Finea a Belisa y 1 de Belisa a Finea:
| Belisa | Finea | Celia | Lucinda | Fabia | Don Juan | Tello | Octavio | Julio | Conde Enrique | Fernando | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Belisa | 1 | ||||||||||
| Finea | 1 | ||||||||||
| Celia | |||||||||||
| Lucinda | |||||||||||
| Fabia | |||||||||||
| Don Juan | |||||||||||
| Tello | |||||||||||
| Octavio | |||||||||||
| Julio | |||||||||||
| Conde Enrique | |||||||||||
| Fernando |
Otro ejemplo, en la escena 13 del acto 3 don Juan dice a Lucinda y al Conde Enrique:
DON JUAN: Huélgome de hallar aquí,
señor, a Vueseñoría,
no para disculpa mía,
si es que anoche le ofendí,
sino porque de Belisa
traigo a los dos un recado.
Esta intervención deberíamos anotarla con doble destinatario, es decir, sumar 1 de don Juan a Lucinda y 1 de don Juan al Conde.
Así continuaríamos haciendo con toda la obra. Mi recomendación es que anotes cada intervención en la que tuviste dudas y cómo la resolviste, por si acaso debes volver atrás en algún momento y revisar tus decisiones.
Una vez que termines, intercambia cada nombre de pesonaje de tu matriz con el id que le asignaste en la lista de nodos, tanto en la primera columna como en la primera fila. Para ello puedes utilizar la opción “Buscar y reemplazar”. Por último, exporta la hoja actual como archivo CSV y llama al archivo resultante aristas-interaccion_bizarrias.csv.
¡Ya tienes tu matriz de adyacencia preparada!
(En esta ocasión no podemos introducir atributos a las relaciones en la hoja de cálculo, pero no te preocupes, lo haremos más adelante.)
Recapitulación final de la primera parte
Hemos terminado la primera parte de la lección. ¿Qué hemos aprendido?
- Qué es el análisis de redes sociales y qué lugar ocupa dentro de los estudios literarios y teatrales computacionales
- Cuáles son los elementos básicos del análisis de redes: partes de un grafo (nodos y aristas), algunos tipos de grafos (dirigidos y no dirigidos) y características básicas como el grado de un nodo y el peso de una arista
- Cómo realizar un análisis de redes sociales de textos teatrales a partir de las relaciones de sus personajes. De los cuatro pasos que establecidos vimos solo los dos primeros: 3.1. La creación del corpus de análisis 3.2. Qué datos necesitamos extraer (personajes y sus relaciones) y cómo debemos extraerlos y estructurarlos en función de dos criterios de análisis: la coaparición de personajes en escena (utilizando el método de la lista de aristas y la herramienta Easy Linavis) y la interacción lingüística directa entre personajes (utilizando el método de la matriz de adyacencia y mucha paciencia).
En la segunda parte de la lección veremos los dos últimos pasos: la creación de visualizaciones y análisis de grafos con el software Gephi, y la interpretación de los resultados del análisis, tanto visual a partir de los grafos como cuantitativa gracias a la aplicación de medidas, métricas y algoritmos.
Bibliografía
Calvo Tello, J. “Diseño de corpus literario para análisis cuantitativos.” Revista de Humanidades Digitales 4 (2019): 115-115. https://doi.org/10.5944/rhd.vol.4.2019.25187.
Escobar Varela, M. Theater as Data: Computational Journeys into Theater Research. Ann Arbor, MI: University of Michigan Press, 2021. https://doi.org/10.3998/mpub.11667458.
Garrot Zambrana, J. C. “Lope se despide de los corrales: “Las bizarrías de Belisa”.” Anuario Lope de Vega Texto literatura cultura, 26 (2020): 379-403. https://doi.org/10.5565/rev/anuariolopedevega.344.
Isasi, J. “Acercamiento al análisis del sistema de los personajes en la narrativa escrita en español: El caso de Zumalacárregui y Mendizabal de Pérez Galdós. Caracteres.” Estudios culturales y críticos de la esfera digital, 6, no. 2 (2017a): 107-137.
Isasi, J. “Posibilidades de la minería de datos digital para el análisis del personaje literario en la novela española: El caso de Galdós y los “Episodios Nacionales”.” (Tesis doctoral, University of Nebraska - Lincoln, 2017b).https://digitalcommons.unl.edu/dissertations/AAI10682923.
Jiménez Fernández, C. M., y Calvo Tello, J. “Grafos de Escenas y Estudios Literarios Digitales: Una Propuesta Computacional Crítica. 452ºF.” Revista de Teoría de la literatura y Literatura Comparada, 23 (2020): 78-101. https://doi.org/10.1344/452f.2020.23.4.
Jockers, M. L. Macroanalysis: Digital Methods and Literary History. University of Illinois Press, 2013.
Merino Recalde, D. “El sistema de personajes de las comedias urbanas de Lope de Vega. Propuesta metodológica y posibilidades del análisis de redes sociales para el estudio del teatro del Siglo de Oro” (Trabajo de Fin de Máster, Universidad Nacional de Educación a Distancia, 2022). http://e-spacio.uned.es/fez/view/bibliuned:master-Filologia-FILTCE-Dmerino.
Martínez Carro, E. “Una interpretación digital de dos tragedias lorquianas: Yerma y Doña Rosita la soltera.” Caracteres: estudios culturales y críticos de la esfera digital 7, no. 2 (2018): 240-267.
Martínez Carro, E. “Aproximación al teatro lorquiano desde la teoría de las redes sociales: La casa de Bernarda Alba.” Artnodes, 24 (2019): 134-141. https://doi.org/10.7238/a.v0i24.3298.
Martínez Carro, E., y Santa María Fernández, T. “Biblioteca Electrónica Textual del teatro español (1868-1936) e investigación con grafos.” Revista de Humanidades Digitales, 3 (2019): 23-45. https://doi.org/10.5944/rhd.vol.3.2019.23144.
Moretti, F. Distant Reading. London - New York: Verso, 2013.
Moretti, F. Graphs, Maps, Trees: Abstract Models for a Literary History. London: Verso, 2005.
Moretti, F. “Network Theory, Plot Analysis”. Stanford Literary Lab Pamphlets 2 (2011): 1-11.
Rodríguez Treviño, Julio César. “Cómo utilizar el Análisis de Redes Sociales para temas de historia.” Signos Históricos 29 (2013): 102-41.
Notas
-
Miguel Escobar Varela, Theater as Data: Computational Journeys into Theater Research (Ann Arbor, MI: University of Michigan Press, 2021), 94. ↩
-
Franco Moretti, Distant Reading (London - New York: Verso, 2013). ↩
-
En realidad se conoce como “análisis de redes” al campo de estudio general, pero lo apellidamos “sociales” cuando los elementos que se estudian son personas y se implementan conceptos y teorías que provienen de la sociología. ↩
-
Sobre el uso del ARS en historia ver Julio César Rodríguez Treviño, “Cómo utilizar el Análisis de Redes Sociales para temas de historia.” Signos Históricos 29 (2013). ↩
-
Puede consultarse una revisión exahustiva de los trabajos en literatura que han implementado el análisis de redes en David Merino Recalde, “El sistema de personajes de las comedias urbanas de Lope de Vega. Propuesta metodológica y posibilidades del análisis de redes sociales para el estudio del teatro del Siglo de Oro” (Trabajo de Fin de Máster, Universidad Nacional de Educación a Distancia, 2022). ↩
-
Ver en la bibliografía: Martínez Carro 2018 y 2019, Martínez Carro y Santa María Fernández 2019, Jiménez Fernández y Calvo Tello 2020. ↩
-
Ver en la bibliografía: Isasi 2019a y 2019b. ↩
-
Franco Moretti, Distant Reading 1. ↩
-
Matthew Lee Jockers, Macroanalysis: Digital Methods and Literary History (University of Illinois Press, 2013). ↩
-
Moretti, Distant Reading, 1. ↩
-
Jockers, Macroanalysis: Digital Methods and Literary History, 24. ↩
-
Escobar Varela, Theater as Data: Computational Journeys into Theater Research, 13. ↩
-
Cabe mencionar, por ejemplo, el trabajo del grupo QuaDramA de la Universität zu Köln y de la Universität Stuttgart. En 2022 organizaron un workshop bajo el título “Computational Drama Analysis: Achievements and Opportunities”, en cuyo “call for papers” destacaban al ARS como una de las metodologías de su interés (ver https://quadrama.github.io/blog/2022/03/14/comp-drama-analysis-workshop). ↩
-
José Calvo Tello, José, “Diseño de corpus literario para análisis cuantitativos.” Revista de Humanidades Digitales 4 (2019). ↩
-
Para más información sobre la obra consultar su ficha de la Base de datos ARTELOPE, en donde encontrarás un resumen, anotaciones pragmáticas sobre la obra, caracterizaciones de personajes y espacios, información bibliográfica, etc. Está disponible en la siguiente direción: https://artelope.uv.es/basededatos/browserecord.php?-action=browse&-recid=53#bibliograficos. ↩
-
Juan Carlos Garrot Zambrana, “Lope se despide de los corrales: “Las bizarrías de Belisa”.” Anuario Lope de Vega Texto literatura cultura 26, (2020): 380. ↩
-
Si no anotamos directamente el peso de las aristas (el número de veces que se relacionan dos personajes), el programa de análisis de redes en el que después importaremos los archivos CSV (Gephi) calculará el peso automáticamente, pero lo hará a partir de los datos que tiene. Es decir, si anotamos una vez A-B, el peso será 1; si anotamos seis veces A-B, el peso de la relación entre A y B será 6. ↩
-
También puedes utilizar las plantillas que he preparado. Encontrarás tres archivos
.csv(plantilla-datos_bizarrias-ListaDeAristas.csv,plantilla-datos_bizarrias-ListaDeNodos.csvyplantilla-datos_bizarrias-MatrizDeAdyacencia.csv) que puedes usar importándolos en una hoja de cálculo y también un archivo.ods(plantilla-datos_bizarrias.ods). ↩ -
Los casos 2, 3 y 4, en los que personajes intervienen pero se dirigen a sí mismos (monólogos) o al público (apartes o menciones directas) no los registraremos porque nos interesa estudiar el espacio interpersonal de la obra, es decir, solamente las relaciones que se establecen entre los personajes a través de los que estos se dicen/comunican directamente. Sería perfectamente válido anotar también los monólogos como intervenciones dirigidas a uno mismo (lo que generaría una arista que sale y entra a un mismo nodo) y las intervencioens dirigidas al público, por ejemplo, creando un nodo más. Esto nos abriría nuevas posibilidades de análisis, como estudiar el espacio intrapersonal de los personajes o las relaciones personajes/actores-público. ↩