
Contenidos
- Requisitos
- Objetivos de la lección
- Introducción
- Un ejemplo de dplyr en acción
- Línea de operaciones
- Necesitamos un nuevo conjunto de datos
- ¿Qué es Dplyr?
- Poniéndolo todo junto
- Conclusión
- Recursos adicionales en español
Requisitos
En esta lección asumimos que tienes cierto conocimiento sobre R. Si no has completado el tutorial de datos tabulares básicos con R, te recomendamos hacerlo. Saber otro lenguaje de programación también te será útil. Si necesitas un lugar donde empezar, recomendamos trabajar con los excelentes tutoriales sobre Python en The Programming Historian en español.
Objetivos de la lección
Al final de la lección,
- sabrás cómo trabajar con datos ordenados y su importancia.
- entenderás el paquete
dplyry podrás usarlo para manipular y administrar datos. - conocerás la línea de operaciones de R y observarás su utilidad para crear código más legible.
- aprenderás las bases del análisis exploratorio de datos a través de algunos ejemplos básicos de manipulación de datos.
Introducción
Los datos que puedes encontrar disponibles en red raramente están en el formato necesario para su análisis y necesitarás manipularlos antes de explorar las preguntas que te interesan. ¡Esto puede llevar más tiempo que el análisis! En este tutorial vamos a aprender algunas técnicas básicas de manipulación, manejo y administración de tus datos en R. Más específicamente, vamos a seguir la filosofía de “datos limpios” o “tidy data” articulada por Hadley Wickham.
Según Wickham, los datos están “limpios” cuando cumplen tres criterios:
- Cada observación está en una fila.
- Cada variable está en una columna.
- Cada valor tiene su propia celda.
Prestar atención a estos criterios nos permite identificar datos organizados o desorganizados. También nos ofrece un esquema estándar y un conjunto de herramientas para limpiar alguna de las formas más comunes en que un conjunto de datos puede estar “desordenado”, como por ejemplo si:
- los títulos de las columnas son valores en vez de nombres de variables.
- hay múltiples variables en una columna.
- las variables están en las filas y en las columnas.
- hay unidades observacionales de diferente tipo guardadas en la misma tabla.
- una única unidad observacional está guardada en varias tablas.
Tal vez lo más importante sea que tener nuestros datos en este formato nos permite usar una colección de paquetes del “tidyverse” que están diseñados para trabajar específicamente con datos limpios. Asegurándonos de que nuestros datos de entrada y de salida están ordenados, podemos usar un pequeño conjunto de herramientas para resolver un amplio número de preguntas. Además, podemos combinar, manipular y dividir conjuntos de datos ordenados como creamos más conveniente.
En este tutorial nos enfocamos en el paquete dplyr de tidyverse pero merece la pena mencionar otros que nos encontraremos por el camino:
magittr: Este paquete nos da acceso al el operador %>% y hace nuestro código más fácilmente de leer.
ggplot2: Este paquete utiliza “la gramática de gráficos”1 para ofrecer una manera fácil de visualizar nuestros datos.
readr: Este paquete da acceso a un método más rápido y racionalizado para importar datos rectangulares (una tabla), como son los archivos CSV (valores separados por comas).
tibble: Este paquete nos permite reconceptualizar el formato data frame (marco o tabla de datos) para que sea más fácil trabajar con ellos e imprimirlos.
Si todavía no lo has hecho, deberías instalar y cargar “tidyverse” antes de empezar. Además, asegúrate de tener la versión más reciente de R y de la plataforma R Studio correspondientes a tu sistema operativo.
Copia el siguiente código en R Studio. Para ejecutarlo tienes que marcar las líneas y clicar Ctrl+Intro (Cmd+Intro en Mac OS):
# Instala y carga la biblioteca tidyverse
# No te preocupes si esto toma un tiempo
> install.packages("tidyverse")
> library(tidyverse)
Un ejemplo de dplyr en acción
Veamos un ejemplo de cómo dyplr nos puede ayudar a los historiadores. Vamos a cargar los datos del censo decenal de 1790 a 2010 de Estados Unidos. Descarga los datos haciendo click aquí2 y ponlos en la carpeta que vas a utilizar para trabajar en los ejemplos de este tutorial.
Como los datos están en un archivo CSV, vamos a usar el comando de lectura read_csv() en el paquete readr de “tidyverse”.
La función read_csv (leer archivo de valores separados por comas) toma la ruta del archivo que queremos importar como una variable, así que asegúrate de escribirlo correctamente.
# Importar el archivo CSV y guardarlo como importacion_poblacion_estados_eeuu
# Asegúrate de tener la ruta correcta al archivo
importacion_poblacion_estados_eeuu <-read_csv("ejemplo_introductorio_estados.csv")
Una vez que importas los datos, verás que hay tres columnas: una para la población, otra para el año y otra para el estado. Estos datos ya están en un formato limpio y nos dan multitud de opciones para explorarlos.
Para el particular, vamos a visualizar el crecimiento de la población de California y Nueva York para conocer mejor de la migración del oeste.3 Vamos a usar dplyr para filtrar los datos que contienen solo la información de los estados que nos interesan y ggplot2 para visualizar dichos datos. Este ejercicio es solo un ejemplo para que te hagas una idea de lo que puede hacer dplyr, así que no te preocupes si no entiendes el código en este momento.
# Filtrar solo los estados de California y Nueva York
poblacion_california_nueva_york <- importacion_poblacion_estados_eeuu %>%
filter(estado %in% c("California", "Nueva York"))
# Visualizar las poblaciones de California y Nueva York
ggplot(data=poblacion_california_nueva_york, aes(x=año, y=poblacion, color=estado)) +
geom_line() +
geom_point()
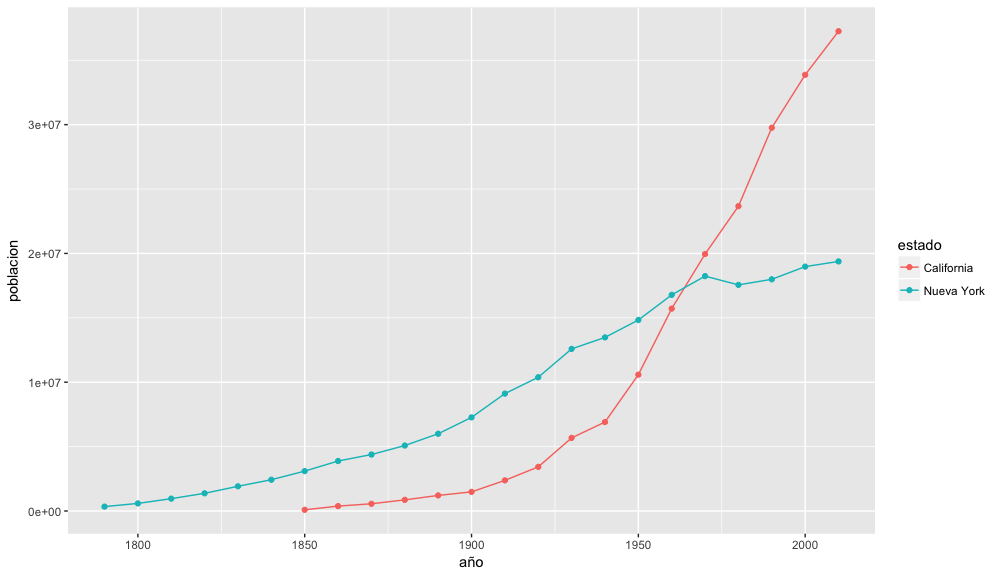
Gráfico de la población de los estados de California y de Nueva York
Como podemos ver, la población de California ha crecido de forma considerable en comparación con la de Nueva York. Aunque este ejemplo pueda parecer obvio si conoces la historia de migración en los Estados Unidos, el código nos ofrece la base sobre la que podemos elaborar multitud de preguntas similares. Por ejemplo, con un cambio rápido en el código podemos crear un gráfico similar con dos estados diferentes como Mississippi y Virginia.
# Filtrar solo los estados de Mississippi y Virginia
poblacion_mississipi_y_virginia <- importacion_poblacion_estados_eeuu %>%
filter(estado %in% c("Mississippi", "Virginia"))
# Visualizar las poblaciones de Mississippi y Virginia
ggplot(data=poblacion_mississipi_y_virginia, aes(x=año, y=poblacion, color=estado)) +
geom_line() +
geom_point()
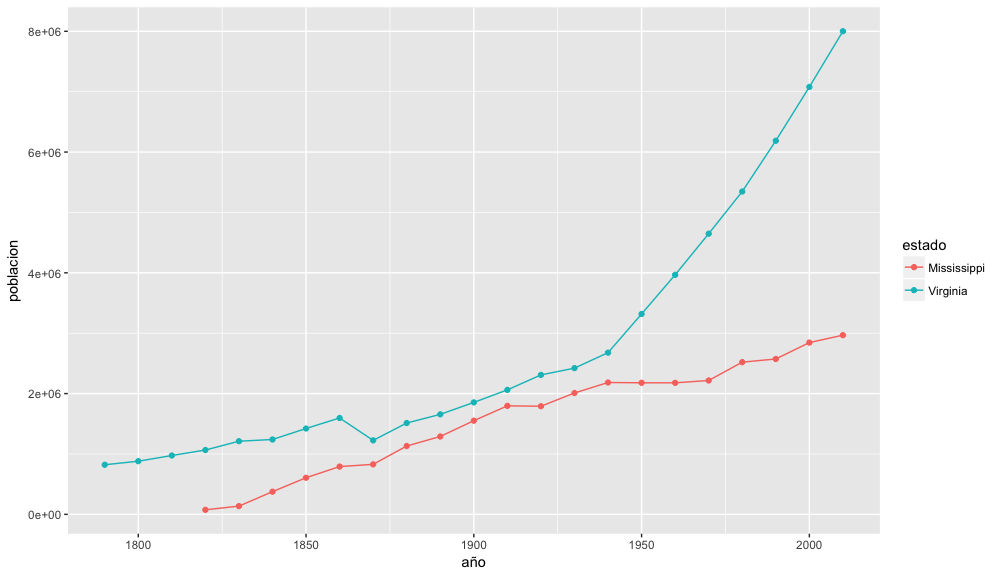
Gráfico de la población de los estados de Mississippi y de Virginia
Hacer cambios rápidos en el código y reanalizar nuestros datos es una parte fundamental del análisis exploratorio de datos (AED, o EDA por sus siglas en inglés). En vez de tratar de “probar” una hipótesis, el análisis exploratorio de datos nos ayuda a entender nuestros datos mejor y a hacernos preguntas sobre ellos. Para los historiadores el AED ofrece una forma de saber cuándo indagar más en un tema y cuando dejarlo a un lado, y esto es en el área en el que R sobresale.
Línea de operaciones
Antes de ver dplyr, tenemos que entender lo que es la línea de operaciones %>% en R porque la vamos a utilizar mucho en nuestros ejemplos. Como decíamos, la línea de operaciones es parte del paquete magittr creado por Stefan Milton Bache y Hadley Wickham y está incluida en tidyverse. Su nombre es un homenaje al pintor surrealista Rene Magritte y su famosa obra “La traición de las imágenes”, que muestra una pipa con las palabras “esto no es una pipa” debajo, en francés.
La línea de operaciones te permite pasar lo que está a su izquierda como la primera variable en una función especificada a la derecha. Aunque pueda parecer extraño al principio, una vez que lo aprendas verás que hace tu código más fácil de leer al evitar declaraciones anidadas. No te preocupes si esto te resulta un poco complicado ahora. Será más fácil una vez que trabajemos con ejemplos.
Digamos que nos interesa saber la raíz cuadrada del valor de cada población y luego queremos sumar todas las raíces cuadradas antes de calcular la media. Obviamente, esto no es una medida útil pero demuestra cuán rápido puede complicarse la lectura del código de R. Normalmente, anidaríamos las siguientes declaraciones:
mean(sum(sqrt(importacion_poblacion_estados_eeuu$poblacion)))
## [1] 1256925
Como ves, con tantos comandos anidados es difícil recordar cuántos paréntesis necesitas y hace que el código sea complicado de leer. Para mitigar esto algunas personas crean vectores temporales entre la llamada a cada función.
# Calcular la raíz cuadrada de la población de cada estado
vector_raiz_cuadrada_poblacion_estados <- sqrt(importacion_poblacion_estados_eeuu$poblacion)
# Calcular la suma de las raíces cuadradas de la variable temporal
suma_del_vector_raices_cuadradas_poblacion_estados <- sum(vector_raiz_cuadrada_poblacion_estados)
# Calcular la media de la variable temporal
media_suma_del_vector_raices_cuadradas_poblacion_estados <- mean(suma_del_vector_raices_cuadradas_poblacion_estados)
# Mostrar la mediana
media_suma_del_vector_raices_cuadradas_poblacion_estados
## [1] 1256925
Aunque vas a obtener la misma respuesta, esto es mucho más legible. Sin embargo, puede llenar tu espacio de trabajo con basura si olvidas borrar los vectores temporales. La línea de operaciones hace todo esto por ti. Aquí está el mismo código con la línea de operador pipe:
importacion_poblacion_estados_eeuu$poblacion%>%sqrt%>%sum%>%mean
## [1] 1256925
Esto es mucho más fácil de leer e incluso lo podrías hacer más claro escribiéndolo en diferentes líneas
# Asegúrate de poner el operador al final de la línea
importacion_poblacion_estados_eeuu$poblacion%>%
sqrt%>%
sum%>%
mean
## [1] 1256925
Por favor, nota que los vectores o marcos de datos que la línea de operación crea son descartados cuando se completa la operación. Si quieres guardarlos, tienes que pasarlos a una nueva variable:
vector_raiz_y_suma_permanente_poblacion_estados <- importacion_poblacion_estados_eeuu$poblacion%>%sqrt%>%sum%>%mean
vector_raiz_y_suma_permanente_poblacion_estados
## [1] 1256925
Necesitamos un nuevo conjunto de datos
Ahora que entendemos la línea de operaciones, estamos preparados para empezar a mirar y administrar otro conjunto de datos. Desafortunadamente, para los historiadores, solo hay unos pocos conjuntos disponibles - ¡a lo mejor tú nos puedas ayudar a cambiar esto haciendo los tuyos públicos! Aquí contamos con el paquete history data (datos históricos) creado por Lincoln Mullen.
Vamos a instalar y cargar el paquete:
# Instalar el paquete historydata
install.packages("historydata")
# Cargar el paquete historydata
library(historydata)
Este paquete contiene ejemplos de conjuntos de datos históricos - el ejemplo anterior con datos del censo del EEUU fue tomado de este paquete (y modificado por la traductora). A lo largo de este tutorial, vamos a trabajar con el conjunto de early_colleges (primeras_universidades) que contiene datos sobre las universidades fundadas antes de 1848.4 Lo primero que vamos a hacer es cargar los datos y leerlos:
# Asegúrate de que has instalado y cargado el paquete historydata antes de nada
data(early_colleges)
early_colleges
# A tibble: 65 x 6
college original_name city state established sponsorship
<chr> <chr> <chr> <chr> <int> <chr>
1 Harvard NA Cambridge MA 1636 Congregational; after 1805 …
2 William and Mary NA Williamsburg VA 1693 Anglican
3 Yale NA New Haven CT 1701 Congregational
4 Pennsylvania, Univ. of NA Philadelphia PA 1740 Nondenominational
5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian
6 Columbia King's College New York NY 1754 Anglican
7 Brown NA Providence RI 1765 Baptist
8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed
9 Dartmouth NA Hanover NH 1769 Congregational
10 Charleston, Coll. Of NA Charleston SC 1770 Anglican
# ... with 55 more rows
Como puedes ver, este conjunto de datos contiene el nombre actual de la universidad (original_name), la ciudad (city) y el estado (state) en que fue fundada, la fecha en que se fundó (established), y la entidad responsable de su patrocinio (sponsorship). Como ya hemos dicho, antes de poder trabajar con un conjunto de datos, es importante pensar en cómo organizar los datos. Veamos si alguno de estos datos no está en formato “limpio” (“tidy”). ¿Puedes ver alguna celda que no concuerde con los tres criterio de datos limpios?
Si piensas que se trata deel patrocinio de Harvard, estás en lo cierto. Además de señalar el patrocinio original, también menciona que cambió de patrocinador en 1805. Normalmente uno quiere mantener toda la información posible sobre los datos, pero para propósitos de este tutorial, vamos a cambiar la columna para tener solo el patrocinador inicial.
early_colleges[1,6] <- "Congregational"
early_colleges
# A tibble: 65 x 6
college original_name city state established sponsorship
<chr> <chr> <chr> <chr> <int> <chr>
1 Harvard NA Cambridge MA 1636 Congregational
2 William and Mary NA Williamsburg VA 1693 Anglican
3 Yale NA New Haven CT 1701 Congregational
4 Pennsylvania, Univ. of NA Philadelphia PA 1740 Nondenominational
5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian
6 Columbia King's College New York NY 1754 Anglican
7 Brown NA Providence RI 1765 Baptist
8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed
9 Dartmouth NA Hanover NH 1769 Congregational
10 Charleston, Coll. Of NA Charleston SC 1770 Anglican
# ... with 55 more rows
Ahora que tenemos nuestros datos en formato limpio, podemos formatearlos a través del paquete dplyr.
¿Qué es Dplyr?
Dplyr es otra parte de tidyverse que proporciona funciones para manipular y transformar tu datos. Dado que nuestros datos van a seguir estando ordenados (tidy), solamente necesitamos un conjunto pequeño de herramientas para explorarlo. Comparándolo con el R Base, el uso de dplyr es más rápido y garantiza que si los datos introducidos (input) están ordenados los datos que obtendremos (output) también lo estarán. Quizás de manera más importante, dplyr hace nuestro código fácil de leer y utiliza “verbos” que son, en su mayoría, intuitivos (para el hablante de inglés). Cada función en dplyr corresponde a estos verbos, siendo los cinco principales filtrar (filter), seleccionar (select), ordenar (arrange), mutar (mutate) y resumir (summarise - con ortografía de inglés británico- o summarize - con ortografía de inglés de EEUU-). Vamos a ver cada una de ellas para entender su funcionamiento en la práctica.
select (seleccionar)
Si miramos el conjunto early_colleges (primeras_universidades), podemos ver que hay muchos “NA” en la columna de nombres originales. NA significa que los datos no están disponibles (del inglés not available), y quizás queramos ver nuestros datos sin esta columna. La función select() de dplyr nos posibilita esto precisamente. Toma el marco de datos que quieres manipular como el primer argumento, seguido de la lista indicando qué columnas queremos mantener:
# Deshazte de la columna de nombres originales ("original_name") usando select()
# Nota que no tienes que añadir el símbolo $ (dólar) al nombre de la columna al final de early_colleges porque `dplyr` asume que "," (una coma) representa Y (AND en inglés) automáticamente
select(early_colleges, college, city, state, established, sponsorship)
# A tibble: 65 x 5
college city state established sponsorship
<chr> <chr> <chr> <int> <chr>
1 Harvard Cambridge MA 1636 Congregational
2 William and Mary Williamsburg VA 1693 Anglican
3 Yale New Haven CT 1701 Congregational
4 Pennsylvania, Univ. of Philadelphia PA 1740 Nondenominational
5 Princeton Princeton NJ 1746 Presbyterian
6 Columbia New York NY 1754 Anglican
7 Brown Providence RI 1765 Baptist
8 Rutgers New Brunswick NJ 1766 Dutch Reformed
9 Dartmouth Hanover NH 1769 Congregational
10 Charleston, Coll. Of Charleston SC 1770 Anglican
# ... with 55 more rows
Escribamos también esto mismo usando la línea de operador %>%:
early_colleges%>%
select(college, city, state, established, sponsorship)
# A tibble: 65 x 5
college city state established sponsorship
<chr> <chr> <chr> <int> <chr>
1 Harvard Cambridge MA 1636 Congregational
2 William and Mary Williamsburg VA 1693 Anglican
3 Yale New Haven CT 1701 Congregational
4 Pennsylvania, Univ. of Philadelphia PA 1740 Nondenominational
5 Princeton Princeton NJ 1746 Presbyterian
6 Columbia New York NY 1754 Anglican
7 Brown Providence RI 1765 Baptist
8 Rutgers New Brunswick NJ 1766 Dutch Reformed
9 Dartmouth Hanover NH 1769 Congregational
10 Charleston, Coll. Of Charleston SC 1770 Anglican
# ... with 55 more rows
Hacer referencia a cada una de las columnas que queremos mantener para deshacernos de una es un tanto tedioso. Podemos usar el símbolo de restar (-) para indicar que queremos descartar una columna, con su nombre.
early_colleges%>%
select(-original_name)
# A tibble: 65 x 5
college city state established sponsorship
<chr> <chr> <chr> <int> <chr>
1 Harvard Cambridge MA 1636 Congregational
2 William and Mary Williamsburg VA 1693 Anglican
3 Yale New Haven CT 1701 Congregational
4 Pennsylvania, Univ. of Philadelphia PA 1740 Nondenominational
5 Princeton Princeton NJ 1746 Presbyterian
6 Columbia New York NY 1754 Anglican
7 Brown Providence RI 1765 Baptist
8 Rutgers New Brunswick NJ 1766 Dutch Reformed
9 Dartmouth Hanover NH 1769 Congregational
10 Charleston, Coll. Of Charleston SC 1770 Anglican
# ... with 55 more rows
filter (filtrar)
La función filter() hace lo mismo que la función select pero en vez de escoger el nombre de la columna, la podemos usar para filtrar filas usando un test de requisitos. Por ejemplo, podemos ver todas las universidades que existían antes del cambio de siglo:
early_colleges%>%
filter(established < 1800)
# A tibble: 20 x 6
college original_name city state established sponsorship
<chr> <chr> <chr> <chr> <int> <chr>
1 Harvard NA Cambridge MA 1636 Congregational
2 William and Mary NA Williamsburg VA 1693 Anglican
3 Yale NA New Haven CT 1701 Congregational
4 Pennsylvania, Univ. of NA Philadelphia PA 1740 Nondenominational
5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian
6 Columbia King's College New York NY 1754 Anglican
7 Brown NA Providence RI 1765 Baptist
8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed
9 Dartmouth NA Hanover NH 1769 Congregational
10 Charleston, Coll. Of NA Charleston SC 1770 Anglican
11 Hampden-Sydney NA Hampden-Sydney VA 1775 Presbyterian
12 Transylvania NA Lexington KY 1780 Disciples of Christ
13 Georgia, Univ. of NA Athens GA 1785 Secular
14 Georgetown NA Washington DC 1789 Roman Catholic
15 North Carolina, Univ. of NA Chapel Hill NC 1789 Secular
16 Vermont, Univ. of NA Burlington VT 1791 Nondenominational
17 Williams NA Williamstown MA 1793 Congregational
18 Tennessee, Univ. of Blount College Knoxville TN 1794 Secular
19 Union College NA Schenectady NY 1795 Presbyterian with Congre…
20 Marietta NA Marietta OH 1797 Congregational
mutate (mutar)
El comando mutate nos permite añadir una columna al conjunto de datos. Ahora mismo, tenemos la ciudad y el estado en dos columnas diferentes. Podemos usar el comando de pegar (paste) para combinar dos cadenas de caracteres y especificar un separador. Pongámoslas en una única columna llamada “location” (lugar):
early_colleges%>%mutate(location=paste(city,state,sep=","))
# A tibble: 65 x 7
college original_name city state established sponsorship location
<chr> <chr> <chr> <chr> <int> <chr> <chr>
1 Harvard NA Cambridge MA 1636 Congregational Cambridge,MA
2 William and Mary NA Williamsburg VA 1693 Anglican Williamsburg,VA
3 Yale NA New Haven CT 1701 Congregational New Haven,CT
4 Pennsylvania, Univ. of NA Philadelphia PA 1740 Nondenominational Philadelphia,PA
5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian Princeton,NJ
6 Columbia King's College New York NY 1754 Anglican New York,NY
7 Brown NA Providence RI 1765 Baptist Providence,RI
8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed New Brunswick,NJ
9 Dartmouth NA Hanover NH 1769 Congregational Hanover,NH
10 Charleston, Coll. Of NA Charleston SC 1770 Anglican Charleston,SC
# ... with 55 more rows
Recuerda que dplyr no guarda los datos ni manipula el original. Al contrario, crea marcos de datos temporales en cada paso. Si quieres guardarlos, tienes que crear una variable permanente con <-:
primeras_universidades_con_localizacion <- early_colleges%>%
mutate(location=paste(city, state, sep=","))
# Observa la nueva tabla con la localización añadida
primeras_universidades_con_localizacion
# A tibble: 65 x 7
college original_name city state established sponsorship location
<chr> <chr> <chr> <chr> <int> <chr> <chr>
1 Harvard NA Cambridge MA 1636 Congregational Cambridge,MA
2 William and Mary NA Williamsburg VA 1693 Anglican Williamsburg,VA
3 Yale NA New Haven CT 1701 Congregational New Haven,CT
4 Pennsylvania, Univ. of NA Philadelphia PA 1740 Nondenominational Philadelphia,PA
5 Princeton College of New Jersey Princeton NJ 1746 Presbyterian Princeton,NJ
6 Columbia King's College New York NY 1754 Anglican New York,NY
7 Brown NA Providence RI 1765 Baptist Providence,RI
8 Rutgers Queen's College New Brunswick NJ 1766 Dutch Reformed New Brunswick,NJ
9 Dartmouth NA Hanover NH 1769 Congregational Hanover,NH
10 Charleston, Coll. Of NA Charleston SC 1770 Anglican Charleston,SC
# ... with 55 more rows
arrange(ordenar)
La función arrange nos permite ordenar nuestras columnas de una nueva forma. Ahora mismo, las universidades están organizadas por año en orden ascendiente. Pongámoslas en el orden descendiente de fundación desde, en este caso, el fin de la guerra con México en 1848.5
early_colleges %>%
arrange(desc(established))
# A tibble: 65 x 6
college original_name city state established sponsorship
<chr> <chr> <chr> <chr> <int> <chr>
1 Wisconsin, Univ. of NA Madison WI 1848 Secular
2 Earlham NA Richmond IN 1847 Quaker
3 Beloit NA Beloit WI 1846 Congregational
4 Bucknell NA Lewisburg PA 1846 Baptist
5 Grinnell NA Grinnell IA 1846 Congregational
6 Mount Union NA Alliance OH 1846 Methodist
7 Louisiana, Univ. of NA New Orleans LA 1845 Secular
8 U.S. Naval Academy NA Annapolis MD 1845 Secular
9 Mississipps, Univ. of NA Oxford MI 1844 Secular
10 Holy Cross NA Worchester MA 1843 Roman Catholic
# ... with 55 more rows
summarise (resumir)
La última función clave en dplyr es summarise() - en ortografía británica (con ‘s’) o en estadounidense (con ‘z’). summarise() toma una función u operación y generalmente se usa para crear un data frame que contiene los datos estadísticos de resumen y que podemos visualizar en forma de gráfico. Aquí la vamos a usar para calcular el año promedio en que se fundaron las universidades antes de 1848.
early_colleges%>%summarise(mean(established))
# A tibble: 1 x 1
`mean(established)`
<dbl>
1 1809.831
Poniéndolo todo junto
Ahora que hemos aprendido los cinco verbos principales para dplyr, podemos usarlos para crear rápidas visualizaciones de nuestros datos. Vamos a crear un gráfico de barras mostrando el número de universidades laicas y religiosas antes de la Guerra de EEUU de 18126:
universidades_seculares_antes_1812 <- early_colleges%>%
filter(established < 1812)%>%
mutate(es_laica=ifelse(sponsorship!="Secular", "no", "si"))
Primero, se ejecuta la función de filtrado para escoger aquellas universidades establecidas antes de 1812. Luego, en la función mutate la función interna ifelse (if…else… o si…si no…) genera un test de verdadero (TRUE) o falso (FALSE) sobre los valores de la columna “sponsorship” y genera otra columna “es_laica” con los resultados; tal que “si el valor en la columna no es igual a (!=) “Secular” añade un “no” en la nueva columna, si dice “Secular” añade un “si”, repitiendo la operación para cada fila, en este caso para cada universidad [N. de la T.].
Ahora podemos visualizar los datos:
ggplot(universidades_seculares_antes_1812) +
geom_bar(aes(x=es_laica, fill=es_laica))+
labs(title="Tipo de universidad antes de 1812", x="¿Es laica la universidad?", y="Recuento")
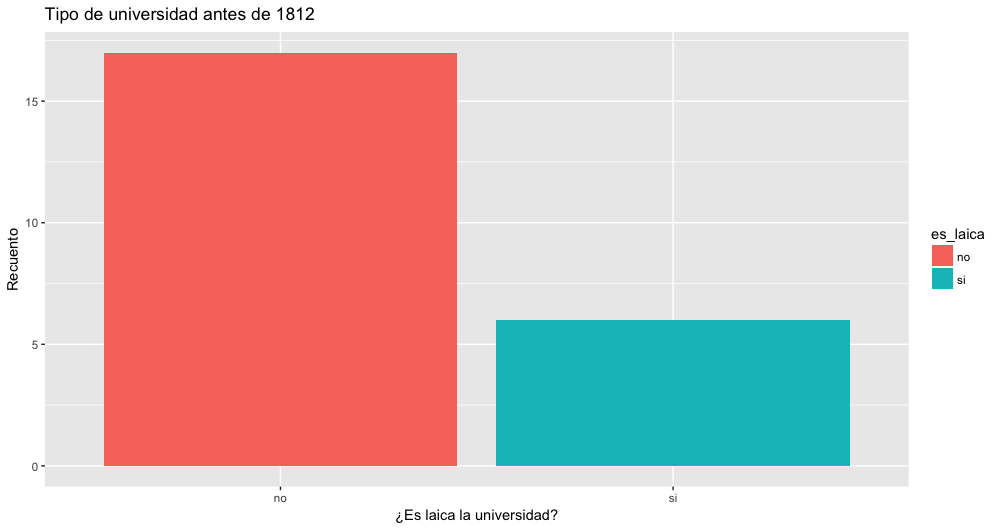
Número de universidades laicas y religiosas antes de la Guerra de 1812
De nuevo, haciendo un cambio rápido en nuestro código, podemos también mirar el número de universidades laicas y religiosas después del comienzo de la Guerra de 1812:
universidades_seculares_despues_1812<-early_colleges%>%
filter(established > 1812)%>%
mutate(es_laica=ifelse(sponsorship!="Secular", "no", "si"))
ggplot(universidades_seculares_despues_1812) +
geom_bar(aes(x=es_laica, fill=es_laica))+
labs(x="¿Es laica la universidad?", y="Recuento")
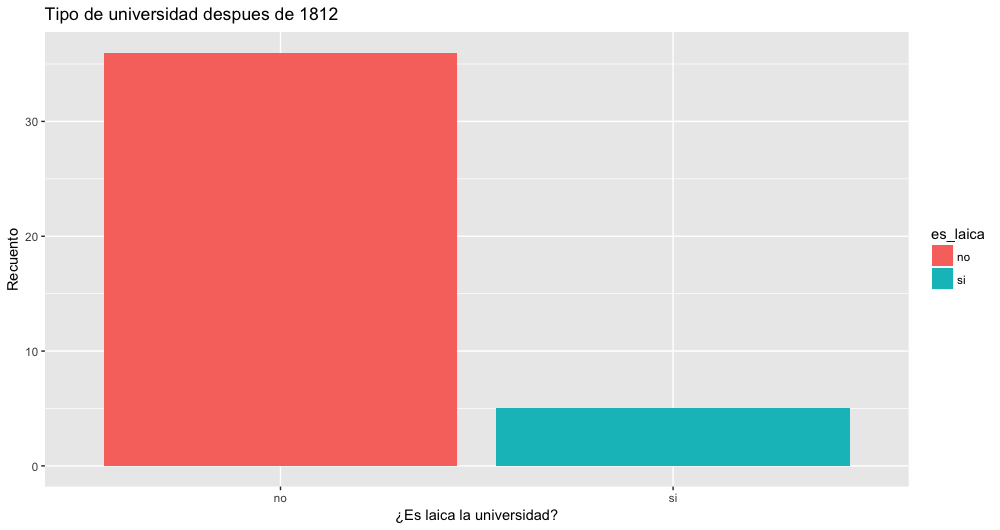
Número de universidades laicas y religiosas después de la Guerra de 1812
Conclusión
Este tutorial debería darte una idea de cómo organizar y manipular tus datos en R. Más adelante quizás quieras visualizar tus datos de alguna otra forma. Te recomiendo que empieces por explorar el paquete ggplot2 (ver abajo) porque su conjunto de herramientas funciona muy bien con dplyr. Además, puede que quieras examinar alguna otra función de las que viene con dplyr para mejorar tus habilidades. En todo caso, esto te proporciona una buena base sobre la que construir para abarcar algunos de los problemas comunes que encontrarás.
Recursos adicionales en español
-
R para Análisis Científicos Reproducibles de Software Carpentry (2018) tiene más información sobre cómo utilizar
dplyrpara tus datos. -
Para aprender más sobre el paquete ‘ggplot2’ puedes consultar la sección “Visualización de datos” en el libro R para Ciencia de Datos de Hadley Wickham y Garrett Grolemund.
-
Tanto la Guía para la Presentación de Gráficos Estadísticos, del Instituto Nacional de Estadística e Informática (2009) así como la Gramática de las gráficas: Pistas para mejorar las representaciones de datos de Joaquín Sevilla Moróder ofrecen explicaciones de cómo presentar tus datos y errores a evitar.
-
En el tutorial original se hace referencia al libro “The Grammar of Graphics” (2005) de Wilkinson. ↩
-
Este listado contiene el censo de la población de cada estado desde 1790, es decir, a partir de la formación de los Estados Unidos de América. De esta manera, el listado comienza con 15 estados (los 13 primeros estados eran ya parte del país desde su independencia en 1776, pero no se ratificó su admisión hasta la Constitución de 1787), los del noreste y parte del sureste, a los que se van añadiendo territorios (que luego se convertirán en estado) a lo largo de los siglos XIX y XX, hasta llegar a la actual división territorial del país: 50 estados, un distrito federal y varios territorios no incorporados (Puerto Rico aparece en este censo pero no es un estado como tal, sino un estado libre asociado o territorio). Se han traducido los datos originales (en inglés) al español. [N. de la T.] ↩
-
La migración hacia el oeste de los Estados Unidos se dio durante el siglo XIX a partir de la compra de Luisiana (a Francia) y hasta su llegada a la costa Pacífico, despojando a los norteamericanos nativos de sus tierras mediante la violencia. Nótese, además, que California fue incorporada a los Estados Unidos en 1850, tras su cesión por parte de México al finalizar la guerra entre ambos países (1846-1848) por el Tratado de Guadalupe Hidalgo. ↩
-
No traducimos estos conjunto pero, por suerte, los datos son bastante intuitivos al tratarse de nombres propios, ciudades, años e iglesias cuyos nombres son cognados entre inglés y español (Anglican por anglicana, Presbyterian por presbiteriana, etc.) [N.de la T.] ↩
-
La también llamada Guerra Mexico-Americana fue la guerra librada entre los Estados Unidos y México desde 1846 hasta la firma del Tratado de Guadalupe Hidalgo en 1848 y la cesión mexicana. ↩
-
La Guerra de 1812, o guerra anglo-estadounidense, enfrentó a los EEUU contra el Reino Unido al tratar los primeros de conquistar los territorios coloniales de los segundos. Finalizó en 1815. ↩