
Conteúdos
- Resumo
- Objetivos
- Introdução
- Pré-requisitos
- Os dados explorados
- Processamento e limpeza de dados com R
- Explorando os dados
- Visualização de tabelas com ggplot2
- Animando a visualização dos dados com gganimate
- Conclusão
- Notas
Resumo
Esta lição lhe mostrará como cruzar, traçar e animar um conjunto de dados históricos. Vamos aprender como importar dados disponíveis em uma tabela eletrônica em RStudio e como utilizar funções que permitam transformar esses dados para representá-los como uma tabela de contingência. Também veremos como utilizar funções de novas bibliotecas que lhe permitirão visualizar os seus dados cruzados em forma gráfica e até mesmo animá-los em perspectiva de tempo.
Objetivos
Nesta lição, aprenderemos a:
- Classificar e transformar tabelas históricas para realizar análises exploratórias;
- Gerar gráficos estáticos e animados para visualizar dados históricos.
Introdução
Não há dúvida de que em uma disciplina como a História, predomina o tratamento qualitativo dos documentos e das fontes que o passado nos legou. Mas, como Roderick Floud salientou, “embora estejamos basicamente mais interessados nas questões ‘qualitativas’ do que nas ‘quantitativas’, as duas estão inextricavelmente ligadas”1. Ou seja, elas não competem, não se substituem, mas se complementam. Uma maneira de combinar ambas as metodologias é através da busca de regularidades ou padrões ocultos ou, inversamente, de anomalias. Isto aproxima aqueles que fazem pesquisa histórica de uma melhor compreensão das coordenadas nas quais situar as suas interpretações. Se esta compreensão global dos dados puder ser visualizada graficamente, é possível “que o pesquisador descubra facilmente as relações, semelhanças e diferenças entre os seus casos”. Desde que Floud escreveu - em meados dos anos 70 - a tecnologia e a programação de computadores avançaram de tal forma que é muito fácil cruzar perspectivas metodológicas. Assim, se um trabalho histórico qualitativo visa aprofundar aspectos dos fenômenos que aconteceram no passado, um trabalho quantitativo permitirá saber com que frequência eles aconteceram, observar padrões e anomalias, e estabelecer relações temporais entre as diferentes categorias de análise existentes.
Quem pretende realizar uma análise histórica quantitativa deve começar com um exercício de codificação das fontes documentais que o passado nos legou e traduzi-las em uma matriz de dados. Em outras palavras, isto requer um processo de conversão de nossas fontes de informação, a fim de transformar dados textuais (palavras) em dados simbólicos (números) operáveis digitalmente. Isto consiste de várias etapas: 1) classificar os documentos que foram acessados de forma a permitir que sejam reunidos de acordo com determinados critérios, 2) categorizar o conteúdo das fontes de forma descritiva, interpretativa ou analítica, com ideias, categorias ou conceitos, 3) codificar, dando às diferentes expressões particulares de cada caso um símbolo (números, palavras), 4) tabular, ou seja, representar os casos organizados sob a forma de uma matriz em um meio de computador, geralmente uma tabela de cálculo.
Nesta lição, mostraremos uma das muitas maneiras pelas quais ficheiros que reúnem informações sistemáticas e seriadas (como casos de produtores de documentação permanente como o Estado, empresas ou a imprensa) podem ser analisados quantitativamente usando a linguagem de programação R. O objetivo é que se adquira conhecimentos que lhe permitam realizar uma análise exploratória dos dados, trabalhando principalmente na distribuição de frequências de diferentes variáveis através de tabelas de contingência, para depois visualizá-las, gerar gráficos e, finalmente, criar uma animação das mesmas em perspectiva temporal.
Pré-requisitos
Esta lição exige um entendimento básico de R, que pode ser obtido nas lições Noções básicas de R com dados tabulares de Trayn Dewar e Manipulação e transformação de dados em R (em inglês) de Nabeel Siddiqui.
Além do R, será necessário possuir o ambiente de desenvolvimento RStudio instalado. Se ainda não o tiver, este vídeo fornece um guia sobre como baixá-lo e instalá-lo.
Os dados explorados
O conjunto de dados aqui apresentado nos ajudará a ver como R pode ajudá-lo a analisar a dinâmica da violência política na Argentina no final dos anos 50, com base em documentos de espionagem policial. Normalmente estes ficheiros de inteligência têm sido utilizados para o estudo histórico de casos particulares, mas raramente o objetivo tem sido alcançar graus de agregação que permitam fazer comparações entre diferentes casos. Dispor de alguns elementos básicos de programação facilita a tomada de medidas nessa direção.
A fonte que propomos codificar é um ficheiro muito especial do acervo da antiga Diretoria de Inteligência da Polícia de Buenos Aires (Argentina). Ele contém vários relatórios de inteligência que dão conta de “atos terroristas” durante os anos do período de conflito político e social conhecido na história argentina como a “Resistência Peronista”2. Uma imagem digitalizada de um dos ficheiros é apresentada na Figura 1. O interessante é que a informação bruta é apresentada de uma forma que facilita sua tabulação.

Figura 1. Imagem de um ficheiro com dados sobre os ataques
Este documento foi transformado em um conjunto de dados quantitativamente processáveis. Uma tabela foi construída a partir de informações sobre algumas localidades da província de Buenos Aires em 1959, um ano em que o número de “atos terroristas” ou ataques foi muito alto. Os dados representam os valores de certas variáveis de análise comuns a todos os registros, tais como a ciudad (onde) e a fecha do ataque (quando). A partir das informações descritivas da polícia (atributos do ataque), foi possível gerar variáveis como: objeto utilizado no ataque (com que elemento foi realizado), sitio (lugar/espaço) e objetivo (contra quem). Com esta categorização, procuramos salvar um passo, pois a tabela segue os preceitos de “dados ordenados” (tidy data): cada variável forma uma coluna, cada observação forma uma linha, cada valor tem a sua própria célula, cada tipo de unidade observacional forma uma tabela3.
| fecha | ciudad | objeto | sitio | objetivo |
|---|---|---|---|---|
| 18/01/1959 | La Plata | bomba | sede | institucion extranjera |
| 19/01/1959 | La Plata | petardo | vias ffcc | ferrocarril |
| 19/01/1959 | Matanza | bomba | vias ffcc | ferrocarril |
| 20/01/1959 | Avellaneda | molotov | comercio | comercio |
| 20/01/1959 | Avellaneda | bomba | vias ffcc | ferrocarril |
| 20/01/1959 | Lomas | bomba | vias ffcc | ferrocarril |
| 20/01/1959 | Matanza | bomba | vias ffcc | ferrocarril |
Para esta lição usaremos a tabela correspondente aos ataques em cinco cidades da Argentina durante 1959, que está disponível no ficheiro atentados1959.xlsx.
Processamento e limpeza de dados com R
Nesta seção mostraremos como carregar os dados no RStudio para começar a processá-los. Não espere que tudo esteja pronto para funcionar uma vez que a tabela tenha sido importada; sempre precisaremos ajustar seus dados para que R possa interpretá-los. Neste caso, por exemplo, após a importação, precisaremos atribuir um tipo às variáveis, convertê-las, fazer algumas modificações nos dados e, em seguida, ordená-las temporariamente.
O primeiro passo é importá-los de seu formato de tabela para o ambiente RStudio. Para fazer isso, será necessário primeiro instalar o pacote que lhe dará os recursos necessários: readxl^[4]. Este pacote faz parte da coleção de pacotes conhecidos como Tidyverse^[5], um dos mais utilizados para o tipo de análise que estamos propondo, pois permite realizar facilmente tarefas como leitura, transformação, processamento, manipulação, organização e visualização de diferentes tipos de dados. Além do readxl, ele contém vários dos pacotes que talvez sejam necessários mais tarde.
install.packages("tidyverse")
A seguir, precisamos carregar tanto o pacote readxl quanto o pacote tidyverse. Embora o pacote readxl esteja contido dentro do último, ele precisa ser carregado separadamente.
library(readxl)
library(tidyverse)
Agora temos condições de importar o conjunto de dados, usando a função read_excel(). Esta função toma como argumento o nome do ficheiro onde está armazenada a tabela, assumindo que ela esteja em seu diretório de trabalho atual. Se não estiver em seu diretório de trabalho, será necessário especificar o caminho completo para o ficheiro. O conteúdo do ficheiro será atribuído a um novo objeto chamado at59:
at59 <- read_excel("atentados1959.xlsx")
É essencial entender de que forma as informações foram armazenadas. Em R tudo é um objeto e, dependendo das características dos dados importados, ele corresponderá a uma certa estrutura de dados. R lida com várias estruturas que diferem por terem diferentes números de dimensões e por poderem ou não armazenar dados de diferentes tipos. O mais conhecido é o vetor, que é uma coleção unidimensional de dados do mesmo tipo. Outra estrutura é a matriz, que é semelhante ao vetor, mas permite trabalhar em duas dimensões.
Além disso, R tem uma forma particular de estrutura de dados, que tem duas dimensões e nos dá a possibilidade de conter dados de diferentes tipos (inteiros junto com datas, caracteres, etc.). Esta estrutura é chamada data frame, e é composta de linhas e colunas; cada linha corresponde a uma observação ou registro, enquanto cada coluna é um vetor representando uma variável de análise. O data frame é uma das estruturas mais utilizadas em R e os dados que importamos de tabelas serão armazenados desta forma. É importante notar que muitas das funções Tidyverse (como read_excel()) retornam um tipo particular de quadro de dados chamado tibble. A principal diferença entre os dois tipos é a forma como os dados são exibidos no console. O tibble, por exemplo, mostra abaixo do nome de cada variável qual é o seu tipo. É possível ver isso usando a função head(), que exibe os seis primeiros registros de at59. Então vemos que a data está no formato datetime (data e hora) e o resto das colunas são do tipo character (caractere).
> head(at59)
# A tibble: 6 x 5
fecha ciudad objeto sitio objetivo
<dttm> <chr> <chr> <chr> <chr>
1 1959-06-23 00:00:00 Almirante Brown bomba via publica ns
2 1959-06-30 00:00:00 Almirante Brown bomba domicilio ns
3 1959-07-30 00:00:00 Almirante Brown bomba domicilio ns
4 1959-08-02 00:00:00 Almirante Brown bomba domicilio ns
5 1959-09-15 00:00:00 Almirante Brown bomba taller industria
6 1959-01-20 00:00:00 Avellaneda molotov comercio comercio
Com a tabela já carregada no RStudio, podemos começar a processar os dados. Assim, por exemplo, podemos começar a substituir certos valores da estrutura de dados para corrigir ou alterar maciçamente o conteúdo. Para este fim, usaremos a função ifelse(), que permite selecionar elementos de uma estrutura de dados de acordo com o cumprimento ou não de uma condição. Esta função tira proveito da vetorização da linguagem R e permite que, ao aplicar uma função a um objeto, ela o faça em todos os seus elementos. Isto evita a necessidade de usar estruturas de repetição (for ou while, por exemplo) para atravessar as linhas. Recomenda-se realizar estas operações sobre os dados antes de realizar qualquer conversão sobre seu tipo.
Suponha que desejamos substituir todos os casos em que o objeto é listado como ”bomba” pelo termo “explosivo”. Para este fim, podemos usar a função ifelse(), passando por apenas três argumentos. Primeiro, indicamos a condição a ser preenchida, neste caso, os valores “bomba” na coluna de objeto de at59, que é selecionada com o símbolo $. O segundo argumento corresponde ao que a função atribuirá caso a condição seja cumprida: ela a substituirá por ”explosivo”. O terceiro argumento é o valor atribuído no caso negativo. Neste caso, manteremos o valor original:
at59$objeto <- ifelse(at59$objeto == "bomba", "explosivo", at59$objeto)
Caso se arrependa das mudanças, é possível fazer a mesma operação ao contrário:
at59$objeto <- ifelse(at59$objeto == "explosivo", "bomba", at59$objeto)
Em seguida, seria conveniente transformar os tipos de variáveis. Nesse caso, as alterações permitirão que se aproveite melhor as funções de visualização. Primeiro, como não importa que as datas também tenham a hora, podemos ajustar essa variável usando a função as.Date() na coluna de data. Em segundo lugar, podemos transformar o resto das variáveis de análise em fatores, que é o tipo de dados que R fornece para trabalhar com variáveis categóricas, ou seja, aqueles que representam um conjunto fixo e conhecido de valores possíveis. Em seguida, devemos fazer algo idêntico com cada uma das quatro colunas restantes (ciudad, objeto, sitio e objetivo) e aplicar a função factor() a elas. Em princípio, isso envolveria escrever cinco afirmações (uma para cada variável): variável <- factor (variável). Se houver interesse em escrever um código limpo, um dos preceitos é evitar a repetição de sentenças caso elas não sejam necessárias e aproveitar o potencial oferecido pela linguagem que estamos usando. No caso de R, podemos fazer isso com funções que permitem que outras funções sejam aplicadas de forma generalizada a uma estrutura de dados.
Entre várias opções, lhe convidamos a usar map_df() do pacote purrr^[6], que também faz parte do Tidyverse. map_df() permite que se atribua uma função - que neste caso será a de alterar o tipo de dado - a vários elementos de um data frame e armazenar o resultado em um objeto dessa mesma classe. Como argumentos da função, primeiro indicamos o nome das colunas - em um formato vetorial com c() - e, em seguida, a função que deseja aplicar a essas colunas. Para juntar o código de ambas as transformações em uma única instrução, usamos a função tibble(). Isso resultará em um tibble com as colunas convertidas e organizadas como estavam originalmente:
at59 <- tibble(map_df(at59[,c("fecha")], as.Date), map_df(at59[,c("ciudad", "objeto", "sitio","objetivo")], factor))
Para terminar esta etapa de limpeza e transformação de dados, é necessário organizar os dados cronologicamente. Para fazer isso, existe a função arrange(), do pacote dplyr^[7], também parte do Tidyverse, o que lhe permitirá reordenar as linhas do quadro de dados. Por padrão, ele o faz em ordem ascendente, embora, como a maioria das funções em R, ele seja parametrizável e permita variações. Neste caso, a ordem ascendente é relevante, portanto não é possível usar a função diretamente. O primeiro argumento é o seu objeto de dados e o segundo argumento é a variável a ser usada como critério computacional. Se fizer isso por data, será necessário entrar:
at59 <- arrange(at59, fecha)
Com head() podemos ver como o conjunto de dados está reorganizado e pronto para que possamos começar a analisá-lo.
# A tibble: 6 x 5
fecha ciudad objeto sitio objetivo
<date> <fct> <fct> <fct> <fct>
1 1959-01-18 La Plata bomba sede institucion extranjera
2 1959-01-19 La Plata petardo vias ffcc ferrocarril
3 1959-01-19 Matanza bomba vias ffcc ferrocarril
4 1959-01-20 Avellaneda molotov comercio comercio
5 1959-01-20 Avellaneda bomba vias ffcc ferrocarril
6 1959-01-20 Lomas bomba vias ffcc ferrocarril
Explorando os dados
Faremos agora uma análise exploratória básica de nossos dados históricos a fim de encontrar relações entre os casos de ataque incluídos no conjunto de dados. A ideia deste tipo de metodologia é identificar as principais características de um conjunto de dados (padrões, diferenças, tendências, anomalias, descontinuidades e distribuições), a fim de compreender sua variabilidade. Ao representar esta variabilidade numericamente, e especialmente na forma de gráficos e visualizações, a análise exploratória de dados torna-se um meio para desenvolver novos insights analíticos, perguntas ou hipóteses: num relance podemos estar cientes das concentrações de dados, valores atípicos, saltos e assim por diante.
Com nosso banco de dados, vamos trabalhar com uma das principais formas pelas quais a variabilidade das informações se manifesta: a distribuição de frequência. Faremos isso em modo bivariado, ou seja, veremos como tabelas de contingência podem ser construídas para contar os casos resultantes do cruzamento de duas variáveis dentro do conjunto de ataques realizados durante 1959.
Para este fim, há uma função simples chamada table() que toma as variáveis de fatores como parâmetros e retorna a frequência de ocorrência das categorias da variável. Um aspecto interessante desta função é que ela também permite que se passe uma única coluna como argumento. Por exemplo, se quisermos saber quantos ataques existem por cidade, podemos descobrir o número com a declaração:
table(at59$ciudad)
Almirante Brown Avellaneda La Plata Lomas Matanza
5 54 52 9 14
Se quiser começar a testar as capacidades gráficas que a base R lhe oferece, é possível transformar essa tabela unidimensional em um gráfico de barras, com uma função chamada barplot():
barplot(table(at59$ciudad))
O gráfico resultante (Figura 2) vai aparecer na aba Plots da janela de utilidades.
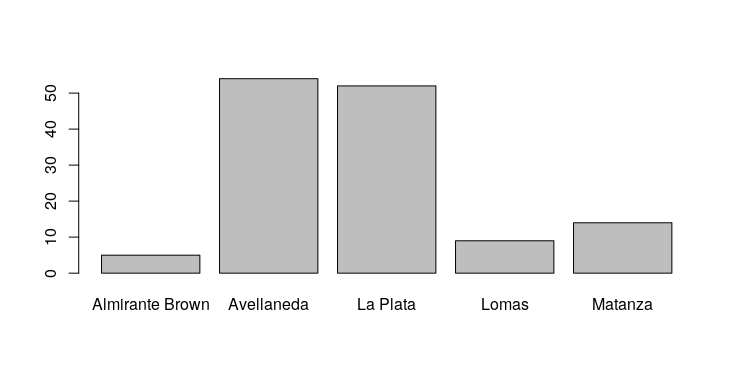
Figura 2. Gráfico de barras mostrando a frequência dos ataques por cidade. Neste caso, Avellaneda e La Plata têm o maior número de ataques.
Para analisar as possíveis relações entre variáveis e categorias, podemos estabelecer uma tabela de contingência. Para isso, precisamos aplicar as duas colunas nas quais estamos interessados em cruzar para a função de table() como um argumento. Por exemplo, se quisermos saber com que tipo de elementos ou objetos os ataques foram perpetrados, de acordo com a cidade de ocorrência do evento, devemos entrar no console:
table(at59$ciudad, at59$objeto)
Como resultado, obteremos a seguinte tabela:
alquitran bomba armas de fuego bomba liquido inflamable molotov petardo proyectil
Almirante Brown 0 0 5 0 0 0 0
Avellaneda 1 0 40 1 5 7 0
La Plata 2 1 37 0 4 7 1
Lomas 0 1 5 2 1 0 0
Matanza 0 0 12 0 2 0 0
Há muitas maneiras de tornar a visualização das tabelas de contingência mais fácil, usando pacotes disponíveis no CRAN. Um que, sem ser complicado, lhe dará tabelas esteticamente melhoradas é o kableExtra^[8]^[9]. O procedimento tem duas partes. Primeiro, é preciso formatar a tabela em formato html com a função kable() e armazená-la em uma variável (por exemplo, a59k). Então, deve-se usar esse objeto como argumento para a função kable_styling(), que lhe permitirá exibir a tabela e lidar com vários atributos de estilo, tais como tamanho da fonte e cor. Dito isto, tente instalar, carregar e testar esse pacote, e aproveite a oportunidade para adicionar um título à sua tabela com o argumento caption:
install.packages("kableExtra")
library(kableExtra)
at59k <- kable(table(at59$ciudad, at59$objeto), caption = "Objeto vinculado ao atentado por cidade")
kable_styling(at59k, font_size = 10)
O resultado aparecerá no Viewer e teremos a possibilidade de salvá-lo como uma imagem ou como código html, através da aba Export.
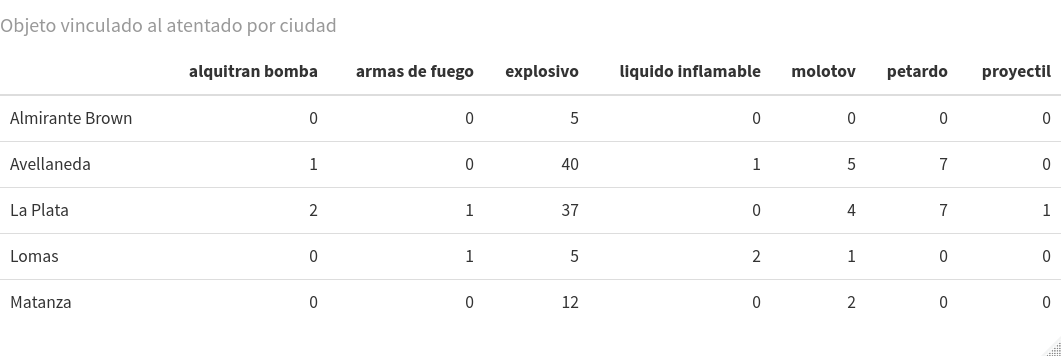
Figura 3. A mesma tabela de contingência criada acima, mas com o formato dado pelo pacote kableExtra.
Visualização de tabelas com ggplot2
Como mostramos com os gráficos gerados nesta lição, R se sobressai na ilustração de conjuntos de dados. O pacote ggplot2 ^[10] é um dos pacotes gráficos mais utilizados para aqueles que usam esta linguagem de programação. Tem uma lógica inspirada na chamada gramática dos gráficos (grammar of graphics) ^[11] , que consiste no uso de camadas (layers), que são ajustadas de acordo com certos parâmetros. Um gráfico é a combinação de camadas, onde cada uma cumpre uma função específica sobre os dados, seus aspectos estéticos (tamanho, forma, cor, etc.), os objetos geométricos que vão representar os dados (pontos, linhas, polígonos, áreas, etc.). Estas três camadas (dados, parâmetros estéticos e representação geométrica) são essenciais, ou seja, não podem estar ausentes. Opcionalmente, é possível modificar os valores padrão de outras camadas, o que lhe permitirá facetar os dados em subgrupos, modificar o tipo de coordenadas, usar funções estatísticas e modificar a aparência geral do gráfico. O pacote ggplot2 está incluído no Tidyverse e é carregado quando se executa library(tidyverse), portanto, nenhuma instalação adicional é necessária.
Em termos abstratos, uma declaração básica desta gramática gráfica tem a seguinte estrutura: ggplot(dados, variáveis) + função geométrica. Os dados correspondem ao objeto de dados que contém as variáveis que queremos visualizar, que para ggplot2 deve estar no formato data frame. As variáveis são interpretadas aqui como os parâmetros estéticos (aes) nos quais as colunas escolhidas serão representadas (por exemplo, posição nos eixos x e y, tamanho, cor). A função geométrica (geom) nos permite escolher o objeto visual com o qual os dados serão representados. Por ser uma lógica de camadas, o sinal + permite adicionar tantas camadas quantas forem consideradas necessárias para que o gráfico inclua os elementos entendidos como relevantes.
Se quiser visualizar graficamente a tabela de contingência construída anteriormente, é possível começar fazendo a equivalência de um ataque = um ponto no plano, ao qual a sentença mínima corresponderia:
ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_point()
Com o código acima, o resultado será semelhante ao da Figura 4.
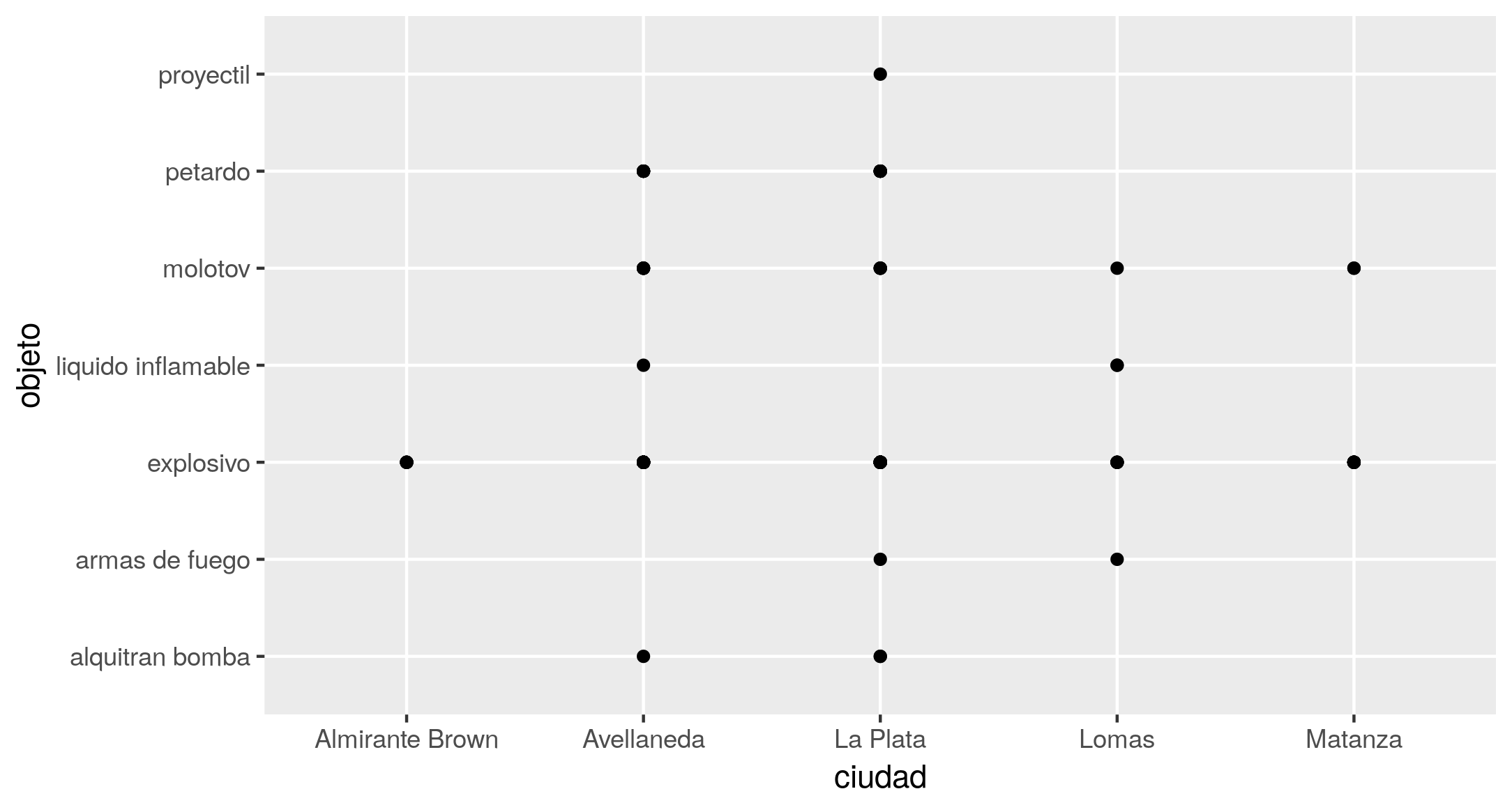
Figura 4. Gráfico de pontos mostrando o cruzamento das variáveis objeto e cidade.
Entretanto, deve-se reconhecer que a acumulação de pontos, um em cima do outro, na mesma coordenada (fenômeno conhecido como overplotting), resulta em uma visualização pouco útil, pois, ao contrário da tabela, não consegue representar as frequências. Mostra apenas a existência de cruzamentos de variáveis, não quantas vezes elas ocorrem. Em casos como este, é aconselhável substituir a função geom_point() por uma que conte o número de ocorrências de cada combinação, para obter uma imagem que lhe dê uma rápida pista sobre as variações na freqüência dos ataques. Para este fim, a geom_count() está disponível, o que, além do efeito visual, adiciona uma escala de frequência ao gráfico.
Se também estiver interessado em enriquecer a visualização adicionando etiquetas ao gráfico (dando-lhe um título, mudando os nomes das variáveis nos eixos, etc.), é possível adicionar uma camada com a função labs(). Ainda, existe a possibilidade de alterar a aparência geral adicionando uma camada com uma das variantes fornecidas pelas funções theme_(), que lhe permitem controlar os elementos não-dados do gráfico. Assim, o resultado obtido será semelhante ao da Figura 5.
ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_count() +
labs(title = "Atentados durante 1959", subtitle = "Objeto utilizado por cidade", x = "CIDADE", y = "OBJETO") +
theme_bw()
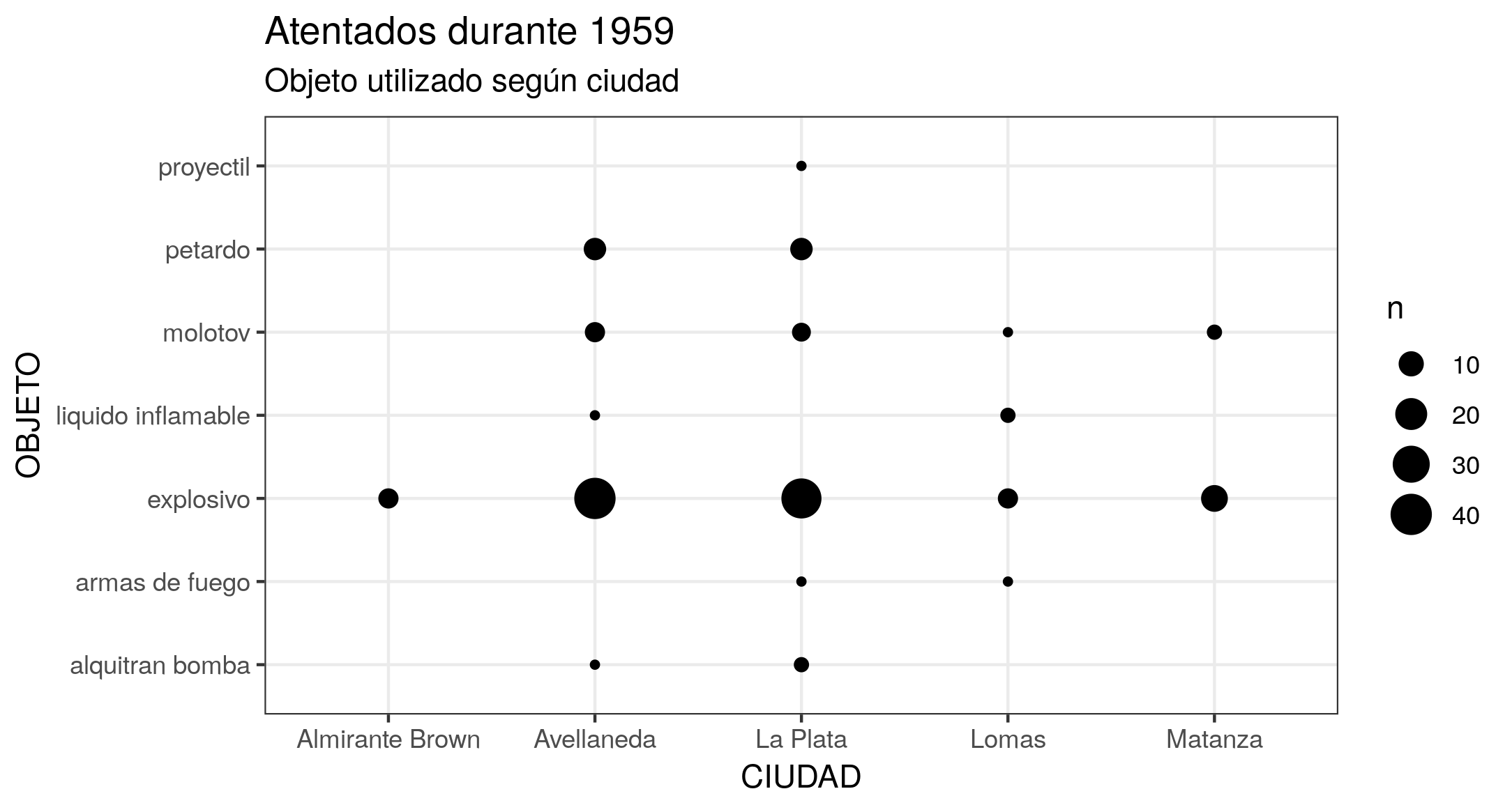
Figura 5. Gráfico de pontos representando a frequência dos ataques, por objeto e cidade. O tamanho dos pontos depende do número de combinações entre o objeto do ataque e a cidade. Pode-se ver que as cidades de Avellaneda e La Plata têm o maior número de ataques, e que foram utilizados explosivos na maioria deles.
Para armazenar o gráfico em um ficheiro, há a função ggsave(), que salvará sua imagem em seu diretório de trabalho:
ggsave("nome-ficheiro.png")
Outra maneira de aproveitar os benefícios de visualização de R e evitar a sobreposição de pontos é usar a propriedade jitter, que afeta a posição dos pontos. A função gráfica geom_jitter() permite adicionar uma pequena variação aleatória à localização de cada ponto; isto é muito útil se estivermos trabalhando com posições discretas e pequenos conjuntos de dados. Para explorar outras capacidades estéticas, tente, por exemplo, definir a cor dos pontos a serem diferentes por cidade, usando o argumento colour. Como o argumento deve estar em formato numérico, devemos convertê-lo com as.numeric(). Além de definir a coloração, temos a possibilidade de manipular o tamanho dos pontos com o argumento size, sua transparência com alpha e a distância vertical ou horizontal entre pontos com width ou height. O gráfico obtido será semelhante ao da Figura 6.
ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_jitter(colour = as.numeric(at59$ciudad), size = 3) +
labs(title = "Atentados durante 1959", subtitle = "Objeto utilizado por cidade", x = "CIDADE", y = "OBJETO") +
theme_bw()
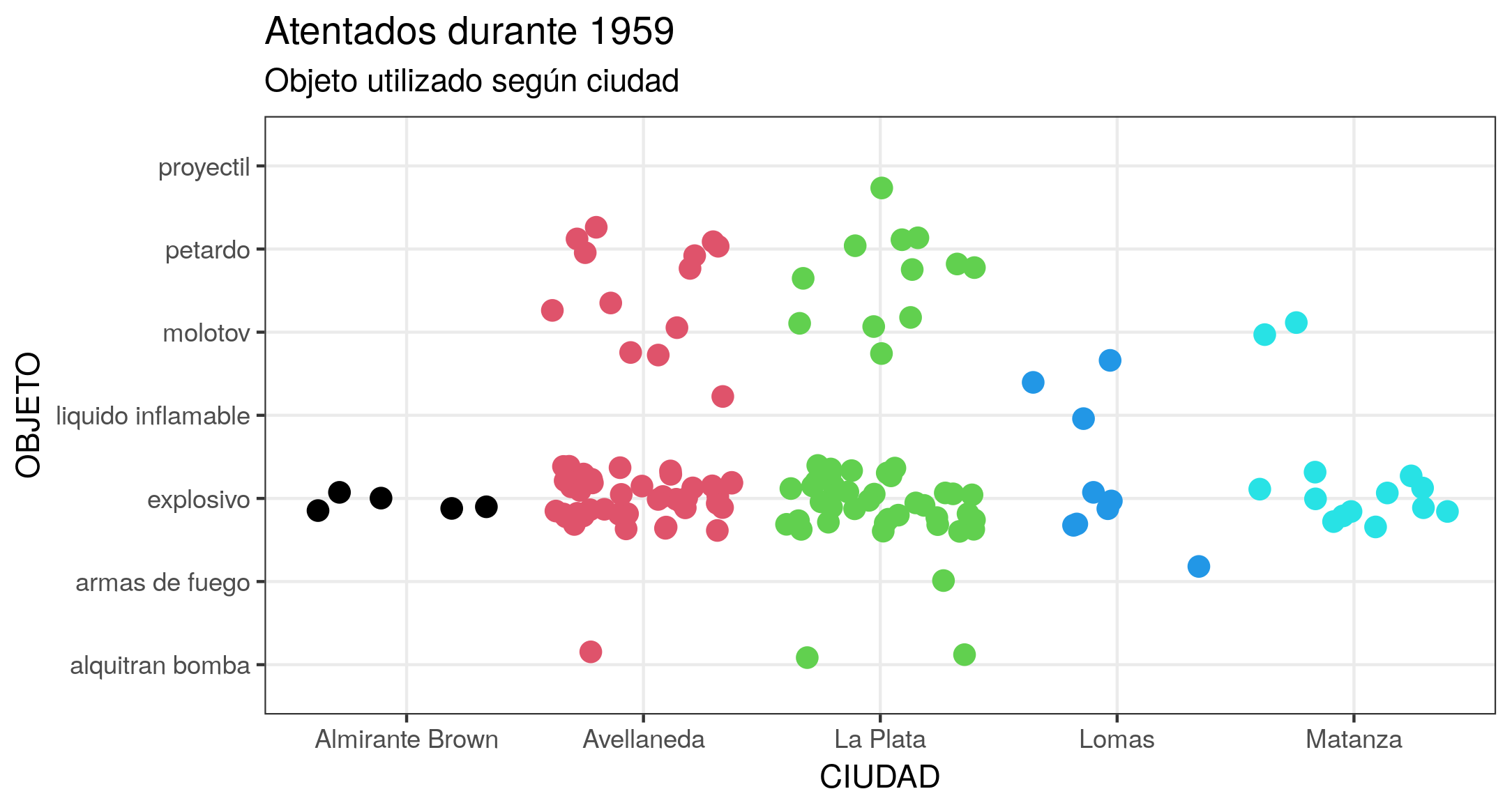
Figura 6. Gráfico resultante da aplicação da função geom_jitter(). Ele permite visualizar a mesma tendência do gráfico anterior (mais explosivos em Avellaneda e La Plata), mas atribuindo um ponto para cada combinação objeto/cidade para evitar sobreposições.
Animando a visualização dos dados com gganimate
Embora existam diferentes pacotes para animar visualizações em R, nós o convidamos a fazê-lo com gganimate^[12]], que é uma extensão do pacote ggplot2 que lhe permitirá criar uma animação a partir de um gráfico ggplot e ver dinamicamente como seus dados evoluem de acordo com os estados ou com o tempo. As funções centrais do gganimate são as funções de transição (transition_*()), que permitem especificar como os dados devem ser interpretados em termos de sua animação, ou seja, de acordo com que critérios os quadros (frames) a serem animados serão criados.
Para instalar e ativar o pacote, use o código abaixo. Sugerimos também a instalação da última versão do pacote gifski. Algumas pessoas relataram problemas gerando animações ao usar uma versão mais antiga que 0.8.6.
install.packages("gganimate")
library (gganimate)
# Se trabalha com Mac ou se a sua versão de gifski é anterior a 0.8.6
install.packages("gifski")
Se quiser gerar uma animação que represente a ocorrência de ataques de acordo com uma progressão no tempo, a função indicada é transiton_time(). O procedimento é muito simples: ao código que escrevemos para fazer o gráfico, adicionamos esta função, colocando como argumento a variável temporal, neste caso, a fecha (data). Entretanto, a fim de fazer uma visualização mais clara de seus dados, é conveniente que acrescentemos alguns elementos ao código.
Por um lado, como no gganimate a animação resultante é um conjunto de imagens (instantâneas) exibidas em séries consecutivas, cada novo quadro (frame) - se não dissermos o contrário - quando exibido esconde o anterior e só veremos pontos piscando. Para lidar com isto, temos o grupo de funções shadow (sombras), que lhe permite escolher como exibir dados que não correspondem mais ao quadro (frame) atual. No caso deste gráfico, a fim de manter todos os dados anteriores em segundo plano, precisamos usar shadow_mark(past = TRUE), o que permite deixar visíveis os quadros já apresentados. Por outro lado, como pode ser bastante difícil entender uma animação sem qualquer indicação do significado de cada ponto de tempo, gganimate fornece um conjunto de variáveis para cada frame (frame variables), que podemos inserir nas etiquetas dos gráficos usando a própria sintaxe do pacote glue, que usa os símbolos {}. Isto lhe fornecerá um conjunto de metadados, dependendo da variante de transição que se tentar. Para transition_time(), há {frame_time}, que retornará o valor do argumento processado pela função durante o frame atual, ou seja, permitirá visualizar a data correspondente. O código ficaria assim:
ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_jitter(colour = as.numeric(at59$ciudad), size = 4) +
labs(title = "Atentados durante 1959", subtitle = "Objeto utilizado por cidade - Data: {frame_time}", x = "CIDADE", y = "OBJETO") +
theme_bw() +
transition_time(fecha) +
shadow_mark(past = TRUE)
Quando inserimos o código diretamente no console, o processo de geração da animação, chamado rendering (renderização), começa. Este processo tem uma duração relativa, dependendo do volume de dados e de seu processamento. Neste caso, deve levar apenas alguns segundos, durante os quais vemos uma barra de progresso indicando quanto tempo ainda resta. Quando terminar, na aba Viewer da janela de utilidades, poderemos assistir a animação. Se pressionamos o ícone Show in new window (mostrar em nova janela), um gif será aberto em seu navegador padrão associado, de onde poderemos salvá-lo. Caso se deseje continuar praticando com o console, também é possível salvá-lo com a função anim_save(), que salva a última animação em seu diretório de trabalho:
anim_save("nome-ficheiro.gif")
Para explorar mais possibilidades do pacote gganimate, a sugestão é que se atribua o bloco de código para gerar o gráfico a um objeto. Isto lhe dará a possibilidade de lidar com parâmetros como velocidade e pausas na animação por meio da função animate(). Com ele, também podemos ajustar o número total de quadros, a duração total e os quadros por segundo. Para experimentar, dê aos fps um parâmetro de 5 quadros por segundo e acrescente uma pausa final de 15 segundos com end_pause. Isto lhe dará uma animação semelhante à Figura 7.
atentados <- ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_jitter(colour = as.numeric(at59$ciudad), size = 4) +
labs(title = "Atentados durante 1959", subtitle = "Objeto utilizado por cidade - Data: {frame_time}", x = "CIDADE", y = "OBJETO") +
theme_bw() +
transition_time(fecha) +
shadow_mark(past = TRUE)
animate(atentados, fps = 5, end_pause = 15, renderer = gifski_renderer())
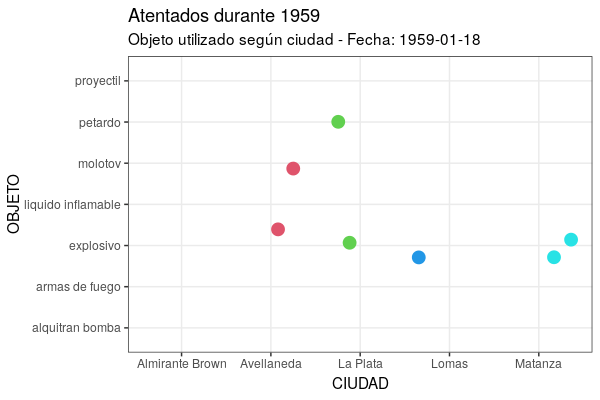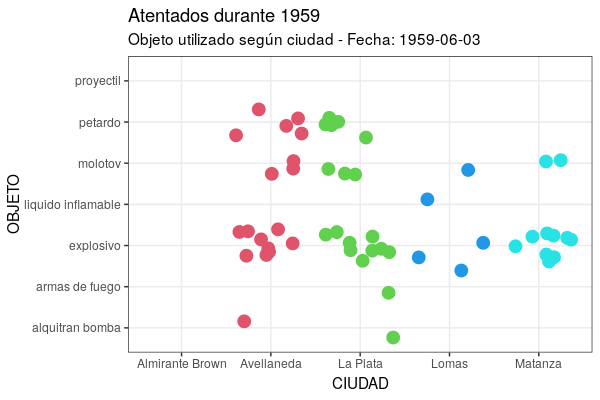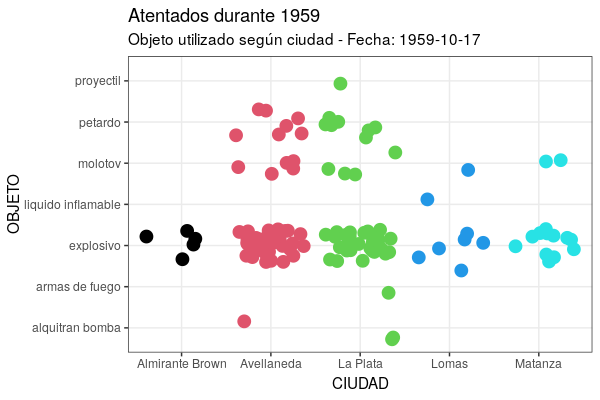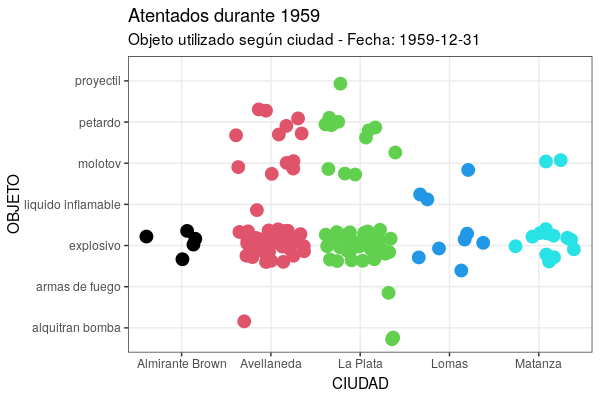
Figura 7. Versão animada do gráfico criado com a função geom_jitter.
Neste ponto e com estes resultados, podemos considerar que foi realizada uma análise exploratória de seus dados e que está em condições de apresentar hipóteses a este respeito. No caso de ter trabalhado, e se o (a) pesquisador (a) se dedica à história das lutas sociais e políticas na Argentina contemporânea, as tabelas de contingência e gráficos estáticos trabalhados nesta lição, por exemplo, permitem encontrar semelhanças entre Avellaneda e La Plata, tanto em termos da frequência dos ataques quanto de seu tipo (em termos do objeto utilizado). Além disso, temos o ritmo temporal (intensidade) dos ataques, o que nos convida a nos concentrar em possíveis padrões ou relações de natureza mais histórica entre casos que normalmente não estão conectados na pesquisa devido a sua diferente estrutura sócio-econômica na época.
Conclusão
Esta lição procurou oferecer uma ideia geral das várias tarefas que devem ser seguidas a fim de preparar e realizar uma primeira análise exploratória de dados sobre uma série de documentos históricos. Este procedimento permite realizar cálculos básicos com estes dados e analisá-los visualmente a fim de pensar, gerar perguntas e hipóteses a partir deles.
Nesta lição, oferecemos apenas um ponto de partida para a análise de suas tabelas históricas. Como um desafio, e com base no que se aprendeu neste tutorial, propomos que se continue a tentar outros cruzamentos de variáveis. Finalmente, te convidamos a descobrir por si próprio o poder do ggplot e do gganimate, explorando a documentação deste último pacote para aprender sobre as outras opções disponíveis.
Notas
-
Roderick Floud, Métodos cuantitativos para historiadores (Madrid: Alianza, 1983). ↩
-
Para encontrar uma referência detalhada do ficheiro no local da Comissão Provincial pela Memória da Província de Buenos Aires: https://www.comisionporlamemoria.org/extra/archivo/cuadroclasificacion/ ↩
-
Os fundamentos e o significado da noção de “dados ordenados” podem ser encontrados em: Hadley Wickham, “Tidy Data”, Journal of Statistical Software, Volume 59, Issue 10, 2019,https://www.jstatsoft.org/index.php/jss/article/view/v059i10/v59i10.pdf) ↩