
Conteúdos
- Objetivos
- Um pequeno exemplo
- Analisar o discurso sobre o Estado da União de Barack Obama em 2016
- Análise dos discursos do Estado da União de 1790 a 2016
- Próximos passos
- Notas
Objetivos
Hoje em dia há uma quantidade substancial de dados históricos disponíveis em forma de texto simples e digitalizado. Alguns exemplos comuns são cartas, artigos de jornal, notas pessoais, diários, documentos legais e transcrições de discursos. Enquanto algumas aplicações de softwares independentes têm ferramentas para analisar dados textuais, o uso de linguagens de programação apresenta uma maior flexibilidade para analisar um corpus de documentos de texto. Neste tutorial, guiaremos os usuários no básico da análise de texto na linguagem de programação R. A nossa abordagem envolve usar apenas a tokenização que produz uma análise sintática do texto, com elementos como palavras, frases e orações. No final da presente lição, os usuários poderão:
- utilizar análises exploratórias para verificar erros e detectar padrões gerais;
- aplicar métodos básicos de estilometria através do tempo e entre autores;
- conseguir resumir o conteúdo do documento para oferecer uma descrição geral do corpus.
Para esta lição, será utilizado um conjunto de dados com os textos dos discursos presidenciais dos Estados Unidos da América sobre o Estado da União1.
Assumimos que os usuários possuem um conhecimento básico da linguagem de programação R. A lição Noções básicas de R com dados tabulares2 (em inglês) é um excelente guia que contém todos os conhecimentos em R necessários aqui, tais como instalar e abrir R, instalar e carregar pacotes e importar e trabalhar com dados básicos de R. Os usuários podem fazer o download do R indicado para os seus sistemas operativos em The Comprehensive R Archive Network. Ainda que não seja um pré-requisito, recomendamos que os novos usuários façam o download do R Studio, um ambiente de desenvolvimento de código aberto para escrever e executar programas em R.
Todo o código desta lição foi testado em R na versão 4.0.2, mas esperamos que ele rode adequadamente em qualquer versão futura do programa.
Um pequeno exemplo
Configuração de pacotes
É necessário instalar dois pacotes de R antes de começar com o tutorial: o tidyverse3 e o tokenizers4. O primeiro proporciona ferramentas convenientes para ler e trabalhar com grupos de dados e o segundo contém funções para dividir os dados do texto em palavras e orações. Para instalá-los, abra o R no seu computador e execute essas duas linhas de código no console:
install.packages("tidyverse")
install.packages("tokenizers")
Dependendo da configuração do seu sistema, pode ser aberta uma caixa de diálogo solicitando a escolha de um lugar da internet para fazer o download. Caso apareça, escolha a opção mais perto de sua localização atual. O download e a instalação, provavelmente, irão ocorrer automaticamente.
Agora que esses pacotes estão no seu computador, precisamos de avisar ao R que eles devem ser carregados para o uso. Isso é feito através do comando library. Pode ser que apareçam alguns avisos enquanto carregam outras dependências, mas eles podem ser ignorados sem nenhum problema. Execute essas duas linhas de código no console para habilitar o uso dos pacotes:
library(tidyverse)
library(tokenizers)
O comando install.packages (instalar pacotes) só é necessário executar na primeira vez em que iniciar este tutorial, o comando library deverá ser executado todas as vezes que se inicia o R5.
Segmentação de palavras
Nesta seção, vamos trabalhar com um único parágrafo. Este exemplo pertence ao início do último discurso de Barack Obama sobre o Estado da União, em 2016. Para facilitar a compreensão do tutorial nesta primeira etapa, estudamos este parágrafo traduzido para português6.
Para carregar o texto, copie e cole o seguinte no console do R:
texto <- paste("Também entendo que, pelo fato de estarmos em temporada eleitoral, as expectativas quanto ao que vamos realizar este ano são baixas. Mesmo assim, senhor presidente da Câmara, aprecio a atitude construtiva que o senhor e os outros líderes assumiram no final do ano passado para aprovar o orçamento e perpetuar a redução dos impostos sobre as famílias trabalhadoras. Desse modo, espero que possamos colaborar este ano sobre questões que são prioritárias para ambos os partidos, como a reforma da justiça criminal e a assistência às pessoas dependentes de drogas vendidas com receita médica. Quem sabe possamos surpreender os cínicos novamente.")
Depois de executar o comando (clicando em “Enter”), escreva a palavra texto no console e pressione Enter. O R irá mostrar o conteúdo do objeto texto, uma vez que ele contém parte do discurso proferido por Obama.
O primeiro passo do processamento de texto envolve utilizar a função tokenize_words (segmentar palavras) do pacote tokenizers para dividir o texto en palavras individuais.
palavras <- tokenize_words(texto)
Para apresentar os resultados na janela do console do R, mostrando tanto o resultado tokenizado como a posição de cada elemento na margem esquerda, execute palavras no console:
palavras
Isso produz o seguinte resultado:
> [[1]]
[1] "também" "entendo" "que" "pelo" "fato"
[6] "de" "estarmos" "em" "temporada" "eleitoral"
[11] "as" "expectativas" "quanto" "ao" "que"
[16] "vamos" "realizar" "este" "ano" "são"
[21] "baixas" "mesmo" "assim" "senhor" "presidente"
[26] "da" "câmara" "aprecio" "a" "atitude"
[31] "construtiva" "que" "o" "senhor" "e"
[36] "os" "outros" "líderes" "assumiram" "no"
[41] "final" "do" "ano" "passado" "para"
[46] "aprovar" "o" "orçamento" "e" "perpetuar"
[51] "a" "redução" "dos" "impostos" "sobre"
[56] "as" "famílias" "trabalhadoras" "desse" "modo"
[61] "espero" "que" "possamos" "colaborar" "este"
[66] "ano" "sobre" "questões" "que" "são"
[71] "prioritárias" "para" "ambos" "os" "partidos"
[76] "como" "a" "reforma" "da" "justiça"
[81] "criminal" "e" "a" "assistência" "às"
[86] "pessoas" "dependentes" "de" "drogas" "vendidas"
[91] "com" "receita" "médica" "quem" "sabe"
[96] "possamos" "surpreender" "os" "cínicos" "novamente"
Como o texto carregado mudou depois de se executar essa função de R? Ela removeu toda a pontuação, dividiu o texto em palavras individuais e converteu tudo para minúsculas. Em breve, veremos porque todas essas intervenções são úteis para a nossa análise.
Quantas palavras existem neste fragmento de texto? Se usamos a função length (comprimento) diretamente no objeto palavras, o resultado não é muito útil.
length(palavras)
O resultado é igual a:
[1] 1
O comprimento equivale a 1 porque a função tokenize_words retorna uma lista de objetos com uma entrada por documento carregado. O nosso carregamento possui apenas um documento, então a lista também possui apenas um elemento. Para ver as palavras dentro do primeiro documento, utilizamos o símbolo [], da seguinte forma: [[1]]. O objetivo é selecionar apenas o primeiro elemento da lista:
length(palavras[[1]])
O resultado é 100, indicando que existem 100 palavras neste parágrafo.
A separação do documento em palavras individuais torna possível calcular quantas vezes cada palavra foi utilizada durante o texto. Para fazer isso, primeiro aplicamos a função table (tabela) nas palavras do primeiro (e, neste caso, único) documento e depois separamos os nomes e os valores da tabela num novo objeto chamado data frame. O uso de um quadro de dados em R é semelhante ao uso de uma tabela numa base de dados. Esses passos, em conjunto com a impressão do resultado, são obtidos com as seguintes linhas de código:
tabela <- table(palavras[[1]])
tabela <- data_frame(palavra = names(tabela), contagem = as.numeric(tabela))
tabela
O resultado deste comando deve aparecer assim no seu console (tibble é um tipo específico de data frame criado no pacote Tidy Data):
# A tibble: 77 x 2
palavra contagem
<chr> <dbl>
1 a 4.
2 ambos 1.
3 ano 3.
4 ao 1.
5 aprecio 1.
6 aprovar 1.
7 as 2.
8 às 1.
9 assim 1.
10 assistência 1.
# ... with 67 more rows
Há uma quantidade substancial de informação nesta amostra. Vemos que existem 77 palavras únicas, como indica a dimensão da tabela. As 10 primeiras fileiras do conjunto de dados são apresentadas, com a segunda coluna mostrando quantas vezes a palavra da primeira coluna foi utilizada. Por exemplo, “ano” foi usada três vezes, enquanto “aprovar”, apenas uma vez.
Também podemos ordenar a tabela usando a função arrange (organizar). Esta função precisa do conjunto de dados a utilizar, aqui tabela, e depois o nome da coluna que serve de referência para ordená-lo. A função desc no segundo argumento indica que queremos ordenar em ordem decrescente.
arrange(tabela, desc(contagem))
E agora o resultado será:
# A tibble: 77 x 2
palavra contagem
<chr> <dbl>
1 que 5.
2 a 4.
3 ano 3.
4 e 3.
5 os 3.
6 as 2.
7 da 2.
8 de 2.
9 este 2.
10 o 2.
# … with 67 more rows
As palavras mais comuns são pronomes e palavras funcionais tais como “que”, “a”, “e” e “os”. Observe como a análise é facilitada pelo uso da versão em minúsculas de cada palavra. Qualquer contagem prevê que a palavra possa estar no início ou no meio da frase.
Uma técnica popular é carregar uma lista de palavras frequentemente usadas e eliminá-las antes da análise formal. As palavras em tal lista são chamadas “stopwords” ou “palavras vazias” e são geralmente pronomes, conjugações dos verbos mais comuns e conjunções. Neste tutorial, temos uma variação sutil desta técnica.
Detectar frases
O pacote tokenizer também contém a função tokenize_sentences, que detecta limites de frases, ao invés de palavras. Ele pode ser executado da seguinte maneira:
frases <- tokenize_sentences(texto)
frases
Com o resultado:
> frases
[[1]]
[1] "Também entendo que, pelo fato de estarmos em temporada eleitoral, as expectativas quanto ao que vamos realizar este ano são baixas."
[2] "Mesmo assim, senhor presidente da Câmara, aprecio a atitude construtiva que o senhor e os outros líderes assumiram no final do ano passado para aprovar o orçamento e perpetuar a redução dos impostos sobre as famílias trabalhadoras."
[3] "Desse modo, espero que possamos colaborar este ano sobre questões que são prioritárias para ambos os partidos, como a reforma da justiça criminal e a assistência às pessoas dependentes de drogas vendidas com receita médica."
[4] "Quem sabe possamos surpreender os cínicos novamente."
O resultado é um vetor de caracteres, um objeto unidimensional que consiste apenas em elementos representados como caracteres. Observe que o resultado marcou cada frase como um elemento separado.
É possível conectar o resultado da divisão das frases com o resultado da divisão das palavras. Se executarmos a divisão de frases do parágrafo com a função tokenize_words, cada frase será tratada como um único documento. Execute isto usando a seguinte linha de código e veja se o resultado é o esperado, a segunda linha de comando serve para imprimir o resultado.
frases_palavras <- tokenize_words(frases[[1]])
frases_palavras
Se olharmos para o tamanho do resultado diretamente, podemos ver que existem quatro “documentos” no objeto frases_palavras:
length(frases_palavras)
Ao acessar cada uma delas diretamente, é possível saber quantas palavras há em cada frase do parágrafo:
length(frases_palavras[[1]])
length(frases_palavras[[2]])
length(frases_palavras[[3]])
length(frases_palavras[[4]])
Isto pode demandar um pouco de esforço, mas felizmente existe uma maneira mais simples de o fazer. A função sapply executa a função no segundo argumento para cada elemento do primeiro argumento. Como resultado, podemos calcular a extensão de cada frase do primeiro parágrafo com uma única linha de código:
sapply(frases_palavras, length)
O resultado agora será assim:
[1] 21 37 35 7
Podemos ver que existem quatro frases com um comprimento de 21, 37, 35 e 7 palavras. Utilizaremos esta função para trabalharmos com documentos maiores.
Analisar o discurso sobre o Estado da União de Barack Obama em 2016
Análise exploratória
Vamos aplicar as técnicas da seção anterior a um discurso sobre o Estado da União completo, desta vez, usando o original em inglês. Por uma questão de coerência, vamos usar o mesmo discurso de 2016 de Barack Obama. Agora, vamos carregar os dados de um ficheiro, uma vez que a cópia direta é difícil em grande escala.
Para tal, vamos combinar a função readLines (ler linhas) para carregar o texto em R e a função paste (colar) para combinar todas as linhas num único objeto. Vamos criar a URL do arquivo de texto usando a função sprintf, uma vez que este formato permitirá que ele seja facilmente aproveitado para outros recursos online7,8.
base_url <- "https://raw.githubusercontent.com/programminghistorian/jekyll/gh-pages/assets/basic-text-processing-in-r/"
url <- sprintf("%s/sotu_text/236.txt", base_url)
texto <- paste(readLines(url), collapse = "\n")
Como antes, vamos segmentar o texto e ver o número de palavras no documento.
palavras <- tokenize_words(texto)
length(palavras[[1]])
Vemos que este discurso contém um total de 6113 palavras. Ao combinar as funções table (tabela), data_frame e arrange (organizar), como fizemos no exemplo anterior, obtemos as palavras mais frequentes em todo o discurso. Ao fazer isso, observe como é fácil reutilizar o código anterior para repetir a análise num novo conjunto de dados. Este é um dos maiores benefícios de usar uma linguagem de programação para realizar uma análise baseada em dados 9.
tabela <- table(palavras[[1]])
tabela <- data_frame(word = names(tabela), count = as.numeric(tabela))
tabela <- arrange(tabela, desc(count))
tabela
O resultado deve ser:
>#A tibble: 1,590 x 2
word count
<chr> <dbl>
1 the 281.
2 to 209.
3 and 189.
4 of 148.
5 that 125.
6 we 124.
7 a 120.
8 in 105.
9 our 96.
10 is 72.
>#... with 1,580 more rows
Mais uma vez, palavras extremamente comuns como the (“o” ou “a”), to (“para”) e and (“e”) estão no topo da tabela. Estes termos não são particularmente esclarecedores se quisermos conhecer o assunto do discurso. Na realidade, queremos encontrar palavras que se destaquem mais neste texto do que num grande corpus externo em inglês. Para conseguir isso, precisamos de um conjunto de dados que forneça essas frequências. Aqui está o conjunto de dados de Peter Norviq usando o Google Web Trillion Word Corpus (Corpus de um trilhão de palavras da web do Google), coletado a partir dos dados compilados através do rastreamento de sites populares em inglês pelo Google 10:
palavras_frequentes <- read_csv(sprintf("%s/%s", base_url, "word_frequency.csv"))
palavras_frequentes
A primeira coluna indica o idioma (sempre “en” para inglês neste caso), a segunda coluna - frequency - fornece a palavra em questão e a terceira coluna indica a percentagem com a qual ela aparece no Corpus de um trilhão de palavras do Google. Por exemplo, a palavra “for” aparece quase exatamente 1 vez a cada 100 palavras, pelo menos nos textos dos sites indexados pelo Google.
Para combinar estas palavras frequentes com o conjunto de dados na tabela construída a partir do discurso do Estado da União, podemos usar a função inner_join (união interna). Esta função toma dois conjuntos de dados e combina-os em todas as colunas que têm o mesmo nome. Neste caso, a coluna comum é a chamada word (“palavra”).
tabela <- inner_join(tabela, palavras_frequentes)
tabela
Note que agora o nosso conjunto de dados tem duas colunas extras que fornecem o idioma (aqui relativamente pouco útil já que é sempre “en”) e a frequência da palavra no corpus externo. Esta segunda nova coluna será muito útil, porque podemos filtrar linhas que têm uma frequência inferior a 0,1%, ou seja, que aparecem mais de uma vez em cada 1000 palavras:
filter(tabela, frequency < 0.1)
Isto produz:
>#A tibble: 1,457 x 4
word count language frequency
<chr> <dbl> <chr> <dbl>
1 america 28. en 0.0232
2 people 27. en 0.0817
3 just 25. en 0.0787
4 world 23. en 0.0734
5 american 22. en 0.0387
6 work 22. en 0.0713
7 make 20. en 0.0689
8 want 19. en 0.0440
9 change 18. en 0.0358
10 years 18. en 0.0574
>#... with 1,447 more rows
Esta lista está começando a se tornar mais interessante. Um termo como “america” aparece no topo da lista porque, podemos pensar, é muito usado nos discursos dos políticos e menos em outros campos. Ao estabelecer o limiar ainda mais baixo, em 0.002, obtemos um melhor resumo do discurso. Como seria útil ver mais do que as dez linhas padrão, vamos usar a função print (imprimir) junto com a opção n (de número) definida como 15 para que possamos ver mais linhas.
print(filter(tabela, frequency < 0.002), n = 15)
Isto agora nos mostra o seguinte resultado:
>#A tibble: 463 x 4
word count language frequency
<chr> <dbl> <chr> <dbl>
1 laughter 11. en 0.000643
2 voices 8. en 0.00189
3 allies 4. en 0.000844
4 harder 4. en 0.00152
5 qaida 4. en 0.000183
6 terrorists 4. en 0.00122
7 bipartisan 3. en 0.000145
8 generations 3. en 0.00123
9 stamp 3. en 0.00166
10 strongest 3. en 0.000591
11 syria 3. en 0.00136
12 terrorist 3. en 0.00181
13 tougher 3. en 0.000247
14 weaken 3. en 0.000181
15 accelerate 2. en 0.000544
>#... with 448 more rows
Os resultados parecem sugerir alguns dos temas principais deste discurso, como “syria” (Síria), “terrorist” (terrorista) e “qaida” (Qaeda) (o nome al-qaida foi dividido em “al” e “qaida” pelo tokenizador).
Sumarizar o documento
Para fornecer informações contextuais para o conjunto de dados que estamos analisando, temos uma tabela com metadados sobre cada um dos discursos do Estado da União. Vamos carregá-la em R:
metadados <- read_csv(sprintf("%s/%s", base_url, "metadata.csv"))
metadados
As primeiras dez linhas do grupo de dados aparecem assim:
>#A tibble: 236 x 4
president year party sotu_type
<chr> <int> <chr> <chr>
1 George Washington 1790 Nonpartisan speech
2 George Washington 1790 Nonpartisan speech
3 George Washington 1791 Nonpartisan speech
4 George Washington 1792 Nonpartisan speech
5 George Washington 1793 Nonpartisan speech
6 George Washington 1794 Nonpartisan speech
7 George Washington 1795 Nonpartisan speech
8 George Washington 1796 Nonpartisan speech
9 John Adams 1797 Federalist speech
10 John Adams 1798 Federalist speech
>#... with 226 more rows
Temos o nome do presidente, o ano, o partido político do presidente e o formato de discurso do Estado da União (oral ou escrito) para cada discurso no conjunto. O discurso de 2016 está na linha 236 dos metadados que, por acaso, é a última linha.
Na próxima seção, pode ser útil resumir os dados para um discurso numa única linha de texto. Podemos fazer isto extraindo as cinco palavras mais frequentes com uma frequência inferior a 0,002% no Corpus de um trilhão de palavras do Google e combinando isso com dados sobre o presidente e o ano.
tabela <- filter(tabela, frequency < 0.002)
resultado <- c(metadados$president[236], metadados$year[236], tabela$word[1:5])
paste(resultado, collapse = "; ")
Isto deveria dar-nos o seguinte resultado:
[1] "Barack Obama; 2016; laughter; voices; allies; harder; qaida"
[1] “Barack Obama; 2016; risadas; vozes; aliados; mais duro; qaeda”
Esta linha capta tudo sobre o discurso? É evidente que não. O processamento de texto nunca substituirá a leitura atenta de um texto, mas ajuda a dar um resumo de alto nível das questões discutidas (“risadas” aparecem aqui porque as reações do público são anotadas no texto do discurso). Este resumo é útil de várias maneiras. Pode fornecer um título ad-hoc ou resumo para um documento que não tenha estas informações; pode servir para lembrar aos leitores que leram ou ouviram o discurso quais foram os principais temas discutidos; e compilar vários resumos com uma única ação pode mostrar padrões em grande escala que muitas vezes se perdem em grandes corpus. É a este último uso que recorremos agora ao aplicar as técnicas desta seção a um grupo maior de discursos do Estado da União.
Análise dos discursos do Estado da União de 1790 a 2016
Carregar o corpus
A primeira coisa a fazer para analisar o corpus de discursos do Estado da União é carregá-los em R. Isto envolve as mesmas funções paste (colar) e readLines (ler linhas) como antes, mas temos que gerar um loop for (para) que executa as funções nos 236 ficheiros de texto. Estas são combinadas com a função c.
ficheiros <- sprintf("%s/sotu_text/%03d.txt", base_url, 1:236)
texto <- c()
for (f in ficheiros) {
texto <- c(texto, paste(readLines(f), collapse = "\n"))
}
Esta técnica carrega todos os ficheiros um a um do Github. Opcionalmente, é possível baixar um arquivo zip (comprimido) com o corpus completo e carregar os ficheiros manualmente. Esta técnica é descrita na próxima seção.
Forma alternativa de carregar o corpus (opcional)
Pode fazer o download do corpus aqui: sotu_text.zip. Descompacte o repositório em algum lugar no seu computador e defina a variável input_loc (local de upload) para o caminho do diretório onde o arquivo foi descompactado. Por exemplo, se os ficheiros estão na área de trabalho de um computador macOS e o usuário é o stevejobs, input_loc deve ser:
input_loc <- "/Users/stevejobs/Desktop/sotu_text"
Uma vez feito, pode usar o seguinte bloco de código para carregar todos os textos:
ficheiros <- dir(input_loc, full.names = TRUE)
texto <- c()
for (f in ficheiros) {
texto <- c(texto, paste(readLines(f), collapse = "\n"))
}
É possível usar esta mesma técnica para carregar seu próprio corpus de textos.
Análise exploratória
Uma vez mais, com a função tokenize_words, podemos calcular o comprimento de cada discurso em número de palavras.
palavras <- tokenize_words(texto)
sapply(palavras, length)
Existe um padrão temporal na duração dos discursos? Como se compara a duração dos discursos de outros presidentes com os de Franklin D. Roosevelt, Abraham Lincoln e George Washington?
A melhor maneira de descobrir é criando um gráfico de dispersão. É possível construir um usando a função qplot (gráfico), com o ano (year) no eixo x ou horizontal e o número de palavras (lenght) no eixo y ou vertical.
qplot(metadados$year, sapply(palavras, length)) + labs(x = "Ano", y = "Número de palavras")
Isto cria um gráfico como este:
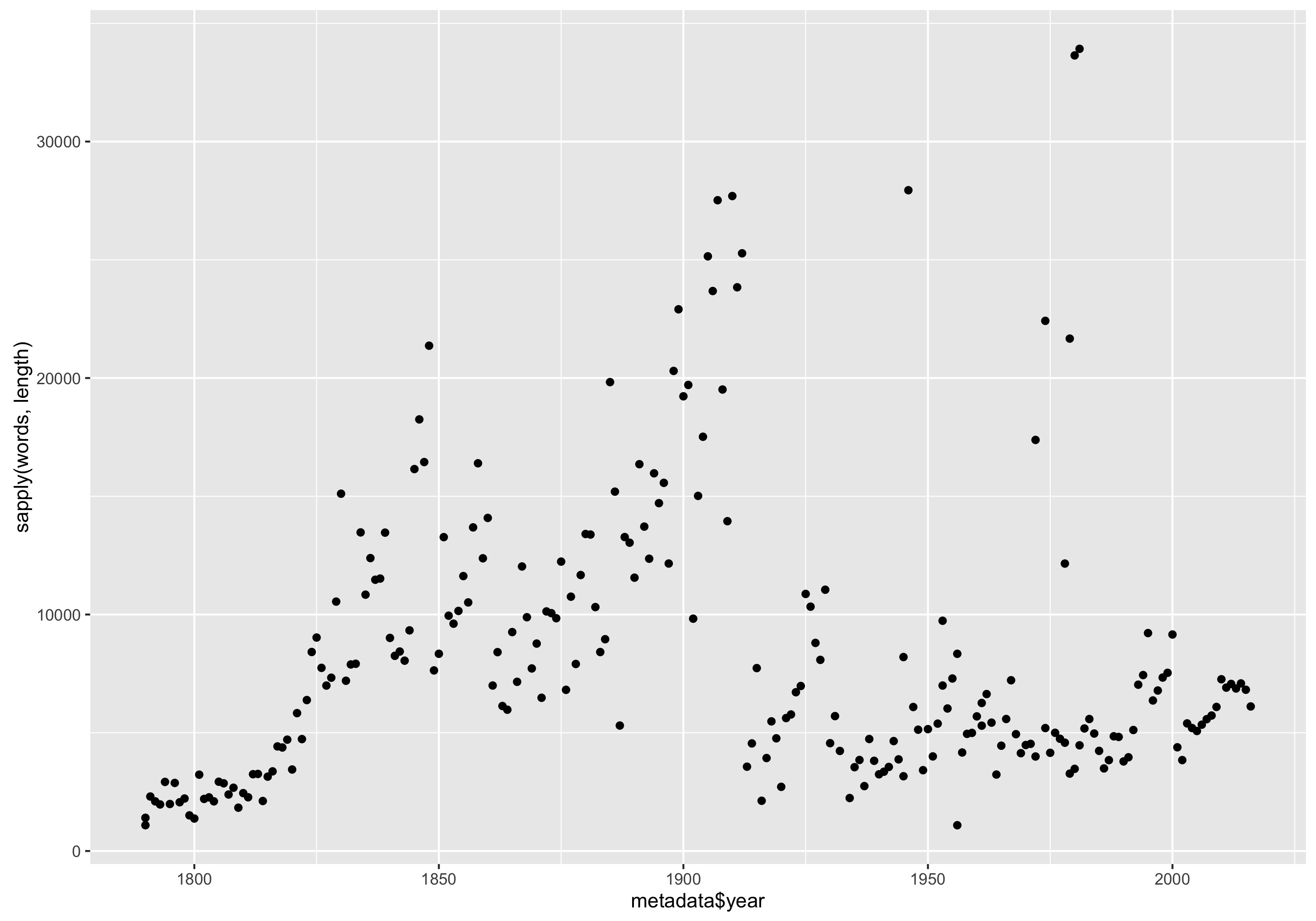 Número de palavras em cada discurso do Estado da União por ano.
Número de palavras em cada discurso do Estado da União por ano.
Parece que a maioria dos discursos aumentaram de 1790 a 1850 e depois aumentaram novamente no final do século XIX. A duração diminuiu drasticamente em torno da Primeira Guerra Mundial, com alguns pontos discrepantes espalhados ao longo do século XX.
Existe alguma razão por trás dessas mudanças? Para explicar esta variação, podemos definir a cor dos pontos para denotar se são discursos que foram apresentados por escrito ou falados. O comando para fazer este gráfico envolve apenas uma pequena mudança no comando do gráfico:
qplot(metadados$year, sapply(palavras, length), color = metadados$sotu_type) + labs(x = "Ano", y = "Número de palavras", color = "Modalidade do discurso")
Isto produz o seguinte gráfico:
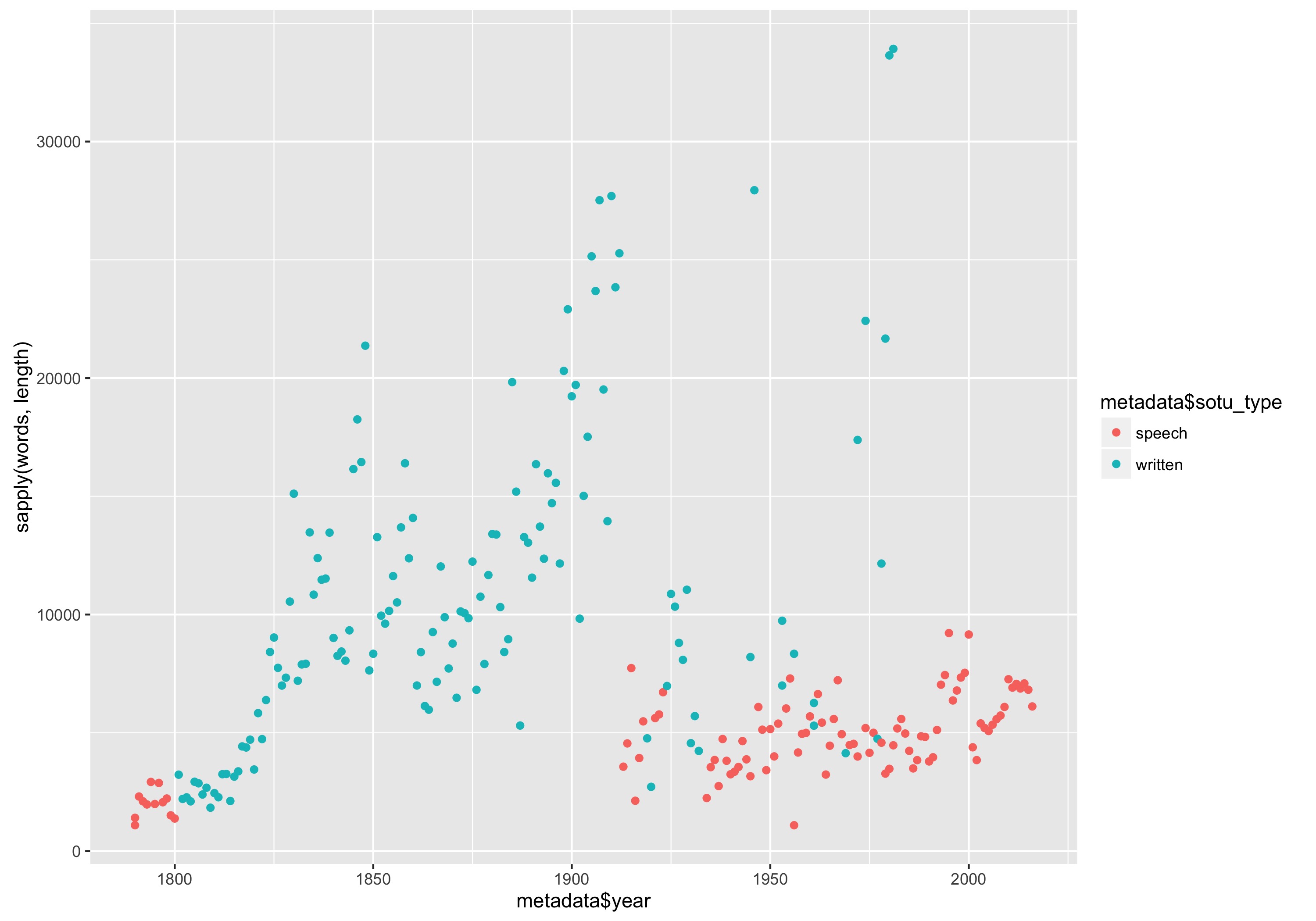 Número de palavras em cada discurso do Estado da União organizado por ano e com a cor denotando se se tratava de um discurso escrito ou oral.
Número de palavras em cada discurso do Estado da União organizado por ano e com a cor denotando se se tratava de um discurso escrito ou oral.
Vemos que o aumento no século XIX foi quando os discursos se tornaram documentos escritos e que a queda drástica foi quando Woodrow Wilson (28º Presidente dos Estados Unidos, entre 1913 e 1921) rompeu com a tradição e deu o seu discurso sobre o Estado da União oralmente no Congresso. Os pontos discrepantes que vimos anteriormente eram discursos proferidos por escrito após a Segunda Guerra Mundial.
Análise estilométrica
A estilometria, o estudo linguístico do estilo, faz uso extensivo de métodos computacionais para descrever o estilo de escrita de um autor. Com o nosso corpus, é possível detectar mudanças no estilo de escrita ao longo dos séculos XIX e XX. Um estudo estilométrico mais formal, geralmente, envolve o uso de código de análise sintática ou de reduções dimensionais algorítmicas complexas, tais como a análise dos principais componentes a serem estudados ao longo do tempo e entre autores. Neste tutorial, continuaremos a nos concentrar no estudo do comprimento das frases.
O corpus pode ser dividido em frases usando a função tokenize_sentences. Neste caso, o resultado é uma lista com 236 objetos, cada um representando um documento específico.
frases <- tokenize_sentences(texto)
Em seguida, queremos dividir cada frase em palavras. A função tokenize_words pode ser utilizada, mas não diretamente sobre a lista de objetos frases. Poderíamos fazer isso com um loop for de novo, mas há uma forma mais simples de o fazer. A função sapply oferece uma aproximação mais direta. Aqui, queremos aplicar a segmentação de palavras individualmente a cada documento e, para isso, esta função é perfeita.
frases_palavras <- sapply(frases, tokenize_words)
Agora, temos uma lista (com cada elemento representando um documento) de listas (com cada elemento representando as palavras de uma dada frase). O resultado que precisamos é uma lista de objetos que forneça o comprimento de cada frase num dado documento. Para isto, combinamos o loop for com a função sapply.
comprimento_frases <- list()
for (i in 1:nrow(metadados)) {
comprimento_frases[[i]] <- sapply(frases_palavras[[i]], length)
}
O resultado de comprimento_frases pode ser visualizado numa linha temporal. Primeiro, precisamos de resumir o comprimento de todas as frases de um documento a um único número. A função median (mediana), que encontra o 50º percentil dos dados inseridos, é uma boa opção para resumir as frases, porque não será muito afectada por possíveis erros de segmentação que podem ter criado uma frase artificialmente longa 11.
mediana_comprimento_frases <- sapply(comprimento_frases, median)
Agora, criamos um diagrama com essa variável junto com os anos dos discursos utilizando, mais uma vez, a função qplot.
qplot(metadados$year, mediana_comprimento_frases) + labs(x = "Ano", y = "Mediana do comprimento das frases")
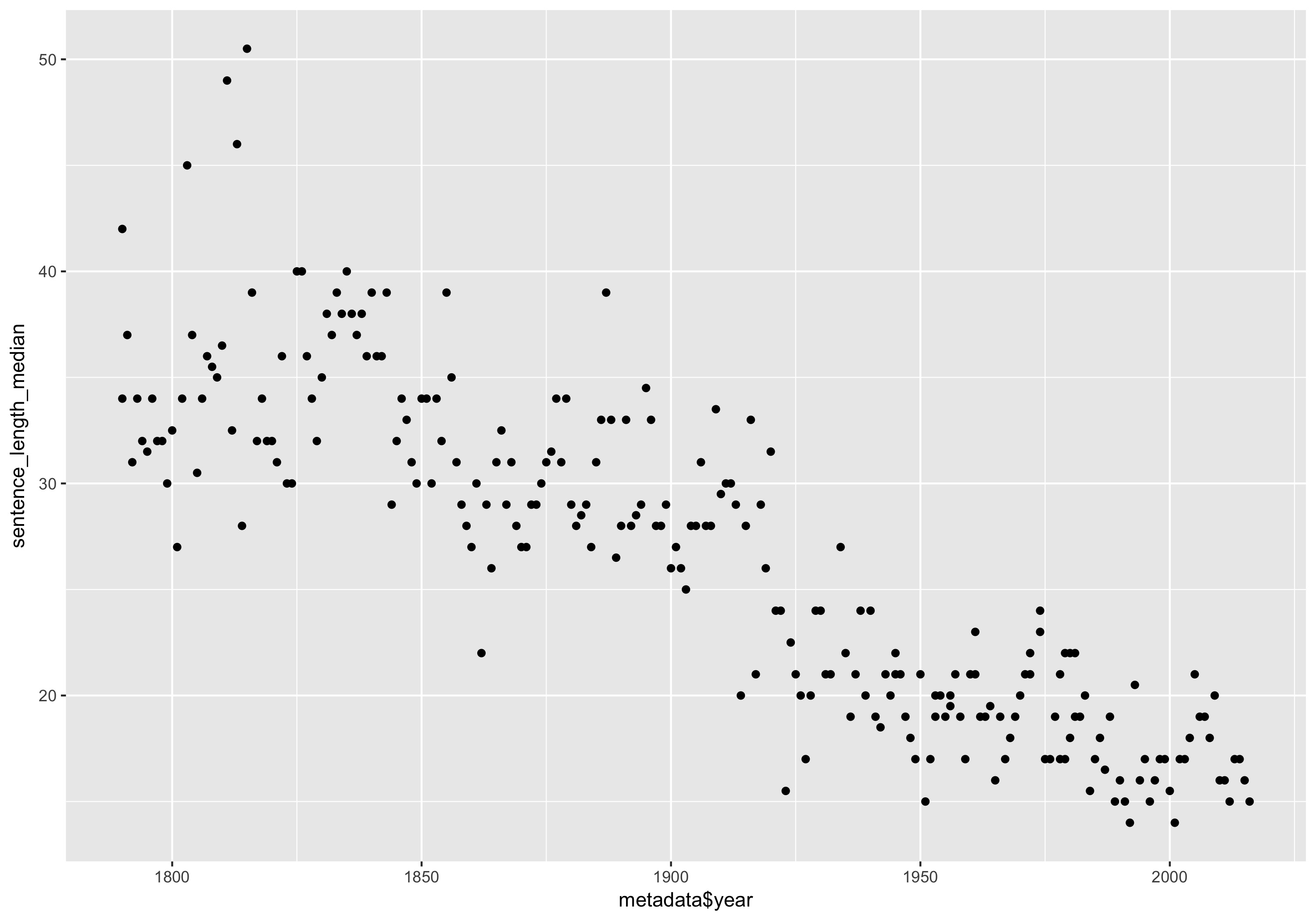 Duração mediana das frases por discurso do Estado da União.
Duração mediana das frases por discurso do Estado da União.
O gráfico mostra-nos uma forte tendência geral de frases mais curtas nos dois séculos do corpus. Lembre-se que alguns discursos no final da segunda metade do século XX eram longos e escritos, muito parecidos com os do século XIX. É particularmente interessante que estes não se destaquem em se tratando de mediana do comprimento das frases.
Para tornar esse padrão ainda mais explícito, é possível adicionar uma linha de tendência no gráfico com a função geom_smooth (geometrização suave).
qplot(metadados$year, mediana_comprimento_frases) + geom_smooth() + labs(x = "Ano", y = "Mediana do comprimento das frases")
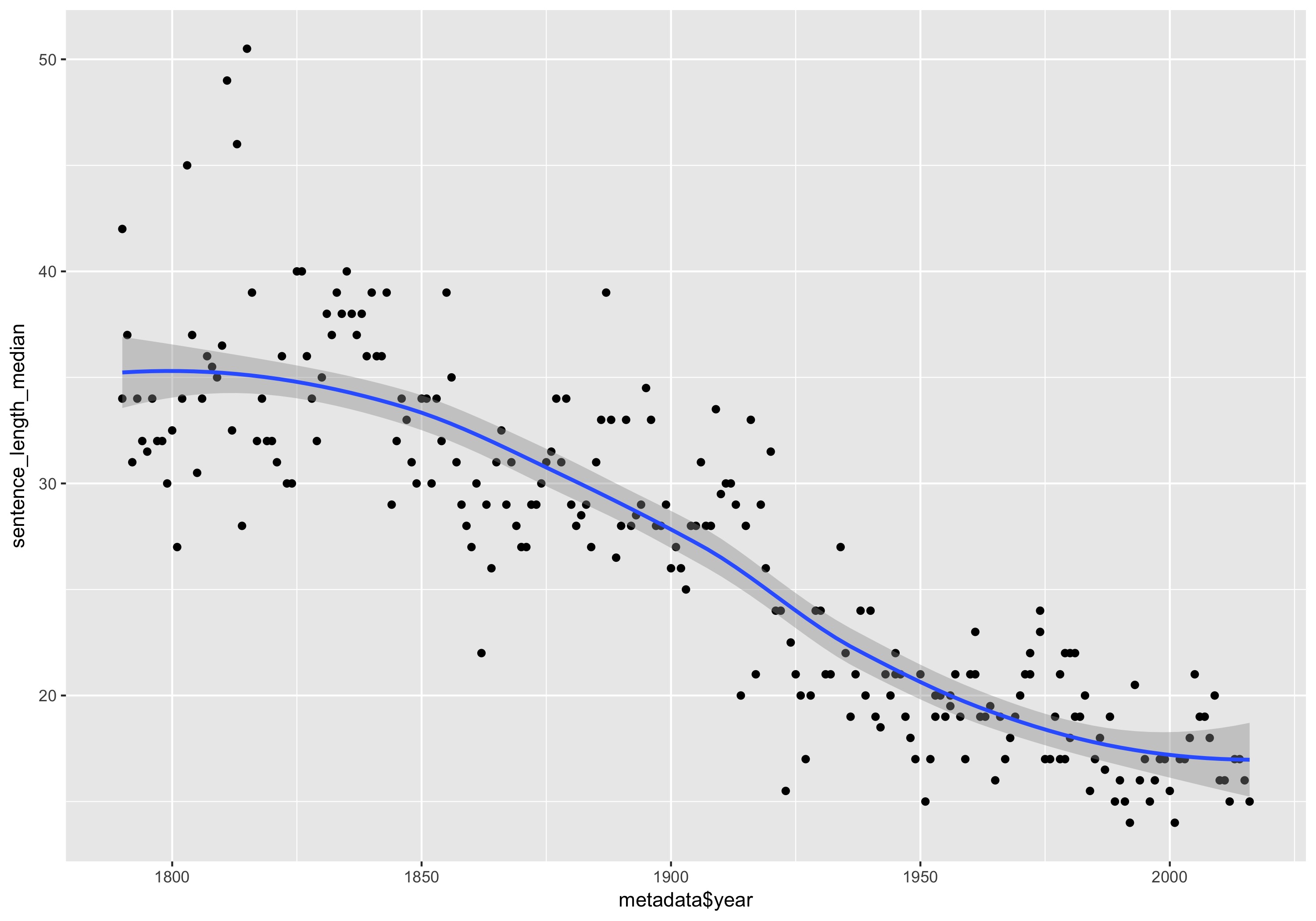 Comprimento mediano de cada discurso do Estado da União com uma linha de tendência.
Comprimento mediano de cada discurso do Estado da União com uma linha de tendência.
As linhas de tendência são um ótimo complemento aos gráficos. Elas possuem a função dupla de mostrar a tendência geral dos dados no tempo, enquanto destacam pontos atípicos ou periféricos.
Resumo do documento
Como tarefa final, queremos aplicar a função de resumo simples que utilizamos na seção anterior a cada um dos documentos desse corpus mais amplo. Precisamos utilizar um loop outra vez, mas o código interno permanece quase o mesmo, com a exceção de que precisamos guardar os resultados como um elemento do vetor description (descrição).
description <- c()
for (i in 1:length(palavras)) {
tabela <- table(palavras[[i]])
tabela <- data_frame(word = names(tabela), count = as.numeric(tabela))
tabela <- arrange(tabela, desc(count))
tabela <- inner_join(tabela, palavras_frequentes)
tabela <- filter(tabela, frequency < 0.002)
resultado <- c(metadados$president[i], metadados$year[i], tabela$word[1:5])
description <- c(description, paste(resultado, collapse = "; "))
}
Enquanto se processa cada ficheiro como resultado da função inner_join, é possível ver uma linha que diz Joining, by = “word”. Como o loop pode demorar um ou mais minutos o processamento da função, esta linha serve para assegurar que o código está processando os ficheiros. Podemos ver o resultado do loop escrevendo description no console, mas, com a função cat, obtemos uma visão mais nítida dos resultados.
cat(description, sep = "\n")
Os resultados oferecem uma linha para cada discurso do Estado da União. Aqui, por exemplo, estão as linhas dos presidentes Bill Clinton, George W. Bush e Barack Obama:
>William J. Clinton; 1993; deficit; propose; incomes; invest; decade
William J. Clinton; 1994; deficit; renew; ought; brady; cannot
William J. Clinton; 1995; ought; covenant; deficit; bureaucracy; voted
William J. Clinton; 1996; bipartisan; gangs; medicare; deficit; harder
William J. Clinton; 1997; bipartisan; cannot; balanced; nato; immigrants
William J. Clinton; 1998; bipartisan; deficit; propose; bosnia; millennium
William J. Clinton; 1999; medicare; propose; surplus; balanced; bipartisan
William J. Clinton; 2000; propose; laughter; medicare; bipartisan; prosperity
George W. Bush; 2001; medicare; courage; surplus; josefina; laughter
George W. Bush; 2002; terrorist; terrorists; allies; camps; homeland
George W. Bush; 2003; hussein; saddam; inspectors; qaida; terrorists
George W. Bush; 2004; terrorists; propose; medicare; seniors; killers
George W. Bush; 2005; terrorists; iraqis; reforms; decades; generations
George W. Bush; 2006; hopeful; offensive; retreat; terrorists; terrorist
George W. Bush; 2007; terrorists; qaida; extremists; struggle; baghdad
George W. Bush; 2008; terrorists; empower; qaida; extremists; deny
Barack Obama; 2009; deficit; afford; cannot; lending; invest
Barack Obama; 2010; deficit; laughter; afford; decade; decades
Barack Obama; 2011; deficit; republicans; democrats; laughter; afghan
Barack Obama; 2012; afford; deficit; tuition; cannot; doubling
Barack Obama; 2013; deficit; deserve; stronger; bipartisan; medicare
Barack Obama; 2014; cory; laughter; decades; diplomacy; invest
Barack Obama; 2015; laughter; childcare; democrats; rebekah; republicans
Barack Obama; 2016; laughter; voices; allies; harder; qaida
Como já foi referido, estes resumos temáticos não são, de forma alguma, um substituto para uma leitura atenta de cada documento. Eles servem, no entanto, como um resumo geral e de alto nível de cada presidência. Vemos, por exemplo, o foco inicial no déficit durante os primeiros anos da presidência de Bill Clinton, sua mudança em direção ao bipartidarismo enquanto a Câmara e o Senado se inclinavam para os republicanos em meados dos anos 1990, e uma mudança em direção à reforma do Medicare no final de sua presidência. Os discursos de George W. Bush concentraram-se, principalmente, no terrorismo, com exceção do discurso de 2001 proferido antes dos ataques terroristas de 11 de setembro. Barack Obama voltou a preocupar-se com a economia sob a sombra da recessão de 2008. A palavra “riso” aparece frequentemente porque é adicionada às transcrições quando o riso do público faz com que o orador pare.
Próximos passos
Neste pequeno tutorial exploramos algumas maneiras básicas de analisar dados textuais com a linguagem de programação R. Há várias direções que se pode tomar para se aprofundar nas novas técnicas de análise de texto. Aqui estão três exemplos particularmente interessantes:
-
conduzir uma análise completa com base em processamento de linguagem natural (NLP) num texto para extrair características tais como nomes de entidades, categorias gramaticais e relações de dependência. Estes estão disponíveis em vários pacotes R, incluindo o cleanNLP12, e para vários idiomas.
-
realizar uma modelagem por tópicos (topic models) para detectar discursos específicos no corpus usando pacotes como mallet13 e topicmodels14.
-
aplicar técnicas de redução de dimensionalidade para traçar tendências estilísticas ao longo do tempo ou entre diferentes autores. Por exemplo, o pacote tsne 15 realiza uma poderosa forma de redução de dimensionalidade particularmente favorável a gráficos detalhados.
Existem muitos tutoriais genéricos para estes três exemplos, assim como uma documentação detalhada dos pacotes16. Esperamos oferecer tutoriais focados em aplicações históricas deles no futuro.
Notas
-
O nosso corpus contém 236 discursos sobre o Estado da União. Dependendo do que for contado, este número pode ser ligeiramente superior ou inferior. ↩
-
Taryn Dewar, “R Basics with Tabular Data,” Programming Historian (05 September 2016), /lessons/r-basics-with-tabular-data. ↩
-
Hadley Wickham. “tidyverse: Easily Install and Load ‘Tidyverse’ Packages”. R Package, Version 1.1.1. https://cran.r-project.org/web/packages/tidyverse/index.html ↩
-
Lincoln Mullen and Dmitriy Selivanov. “tokenizers: A Consistent Interface to Tokenize Natural Language Text Convert”. R Package, Version 0.1.4. https://cran.r-project.org/web/packages/tokenizers/index.html ↩
-
Tenha em mente que os nomes das funções, como
libraryeinstall.packages, sempre estarão em inglês. Apesar disso, colocamos uma tradução do significado para facilitar a compreensão e traduzimos os nomes das variáveis [N. de T.]. ↩ -
Tradução publicada pela Folha em português (13 de janeiro de 2016) https://www1.folha.uol.com.br/mundo/2016/01/1729011-leia-a-integra-do-ultimo-discurso-do-estado-da-uniao-de-obama.shtml [N. de T.] ↩
-
Foi feito o download de todos os discursos presidenciais do The American Presidency Project da University of California Santa Barbara (acesso em 11 de novembro de 2016) http://www.presidency.ucsb.edu/sou.php ↩
-
Aqui, voltamos para a versão original do discurso, em inglês, para dar prosseguimento à análise e, particularmente, para observarmos a lista de palavras mais utilizadas em inglês. Continuaremos a traduzir os nomes das variáveis e das funções para facilitar a compreensão em português [N. de T.]. ↩
-
Aqui, optamos por nomear as colunas da tabela em inglês, como word (palavra) e count (contagem), para facilitar a interação com o conjunto de dados que será introduzido depois com a função
inner_join[N. de T.]. ↩ -
Peter Norvig. “Google Web Trillion Word Corpus”. (Accedido el 11 de noviembre de 2016) http://norvig.com/ngrams/. ↩
-
Isto ocorre em alguns discursos escritos do Estado da União, quando uma lista com numeração é segmentada numa única frase longa. ↩
-
Taylor Arnold. “cleanNLP: A Tidy Data Model for Natural Language Processing”. R Package, Version 0.24. https://cran.r-project.org/web/packages/cleanNLP/index.html ↩
-
David Mimno. “mallet: A wrapper around the Java machine learning tool MALLET”. R Package, Version 1.0. https://cran.r-project.org/web/packages/mallet/index.html ↩
-
Bettina Grün and Kurt Hornik. “https://cran.r-project.org/web/packages/topicmodels/index.html”. R Package, Version 0.2-4. https://cran.r-project.org/web/packages/topicmodels/index.html ↩
-
Ver o artigo” t-distributed stochastic neighbor embedding” na Wikipedia (em inglês). https://en.wikipedia.org/wiki/T-distributed_stochastic_neighbor_embedding [N. de T.] ↩
-
Ver, por exemplo, o livro dos autores Taylor Arnold and Lauren Tilton. Humanities Data in R: Exploring Networks, Geospatial Data, Images, and Text. Springer, 2015. ↩