
Contenus
- Introduction à la réutilisation de texte
- Prérequis
- Installation de Passim
- Préparation des données pour Passim
- Exécution de Passim
- Utilisation de la sortie de Passim
- Pour aller plus loin
- Remerciements
- Bibliographie
Dans cette leçon, vous serez initié(e) à la détection automatique de la réutilisation des textes avec la bibliothèque Passim. Vous apprendrez comment installer et exécuter Passim et ses dépendances, comment préparer vos textes en tant que fichiers d’entrée adaptés à l’utilisation de Passim et, enfin, comment traiter la sortie générée par Passim pour effectuer des analyses de base.
Cette leçon s’adresse aux personnes dont le travail relève des humanités numériques (HN). Aucune connaissance préalable de la réutilisation de texte n’est requise, toutefois, il est nécessaire d’avoir une compréhension basique de l’usage de l’environnement bash et du langage Python, ainsi que de certaines opérations de manipulation de données. Si vous souhaitez compléter vos connaissances concernant l’utilisation du bash et de Python, référez-vous aux tutoriels du Programming Historian suivants qui offrent une introduction au bash et à la collection de tutoriels sur Python.
Plus particulièrement, la leçon donne un aperçu de Passim, un outil open source conçu pour la détection automatique de la réutilisation de texte. Bien que cet outil ait été employé dans des projets HN, grands comme petits, une documentation destinée aux utilsateurs et utilisatrices pour une prise en main facile, avec des exemples et des instructions, fait défaut. Ainsi, nous visons à combler cette lacune grâce à cetter leçon du Programming Historian.
Introduction à la réutilisation de texte
La réutilisation de texte peut être définie comme « une réitération significative d’un texte, généralement au-delà de la simple répétition du langage courant » (Romanello et al. 2014). Il s’agit d’un concept si large, qu’il peut être compris à différents niveaux et être étudié dans une grande variété de contextes. Dans un contexte de publication ou d’enseignement, par exemple, les cas de réutilisation de texte peuvent être considérés comme du plagiat, si des parties de texte d’un(e) autre auteur(e) sont employées sans une référence appropriée. Dans le cadre des études littéraires, la réutilisation de texte n’est bien souvent qu’un synonyme pour désigner des phénomènes littéraires tels que les allusions, les paraphrases et les citations directes.
La liste ci-dessous présente une partie des outils qui permettent de détecter la réutilisation de texte :
- Paquet
textreuse(R) développé par Lincoln Mullen - TRACER (Java) développé par Marco Büchler et ses collaborateurs
- Basic Local Alignment Search Tool (BLAST)
- Tesserae (PHP, Perl)
- TextPAIR (Pairwise Alignment for Intertextual Relations)
- Passim (Scala) développé par David Smith (Université Northeastern)
Pour ce tutoriel, nous avons choisi de nous concentrer sur la bibliothèque Passim et cela pour trois raisons principales. Premièrement, car celle-ci peut être adaptée à une grande variété d’utilisation, puisqu’elle fonctionne autant sur une petite collection de texte que sur un corpus de grande échelle. Deuxièmement, parce que, bien que la documentation au sujet de Passim soit exhaustive, du fait que ses utilisateurs soient relativement avancés, un guide « pas-à-pas » de la détection de la réutilisation de texte avec Passim plus axé sur l’utilisateur serait bénéfique pour l’ensemble de la communauté. Enfin, les exemples suivants illustrent la variété de scénarios dans lesquels la réutilisation de texte est une méthodologie utile :
- Pour déterminer si une bibliothèque numérique contient plusieurs éditions de mêmes œuvres
- Pour trouver des citations dans un texte, à condition que les œuvres choisies soient connues (par exemple, pour trouver des citations de la Bible au sein de la littérature anglaise du 17e siècle)
- Pour étudier la viralité et la diffusion des textes (par exemple Viral Texts par Cordell and Smith pour les journaux historiques)
- Pour identifier, et si possible filtrer, les documents en double dans une collection de texte avant d’effectuer d’autres étapes de traitement (par exemple, la modélisation de sujet comme illustré par Schofield et al. (2017)).
Pour ces raisons, Passim est un excellent choix. Passim vous aidera à automatiser la recherche de passages textuels répétés dans un corpus – qu’il s’agisse d’annonces publicitaires dans les journaux, de copies multiples du même poème ou de citations directes (et légèrement indirectes) dans l’ouvrage d’un(e) autre auteur(e).
La détection de réutilisation de texte telle qu’elle est mise en place dans Passim vise à identifier ces copies et répétitions automatiquement. Elle produit des clusters de passages qui ont été jugés comme étant liés les uns aux autres. En fin de compte, le contenu d’un cluster peut varier et dépendra beaucoup de votre question de recherche. Passim peut ainsi regrouper des copies d’un même article qui ne diffèrent que par des erreurs de reconnaissance optique de caractères (OCR), mais il peut aussi aider à retrouver des textes qui partagent le même modèle journalistique, comme des horoscopes ou des publicités.
Prérequis
Ce tutoriel nécessite les connaissances suivantes :
- Une compréhension basique du terminal bash. Pour les lecteurs et les lectrices qui auraient besoin d’informations au sujet du script bash, vous pouvez lire la leçon du Programming Historian qui offre une introduction au sujet.
- Des connaissances en JSON. Pour en apprendre davantage au sujet de JSON, vous pouvez consulter la leçon du Programming Historian intitulée « Reshaping JSON with jq ».
De plus, bien qu’une compréhension de base de Python - et une installation de Python fonctionnelle - ne soient pas strictement nécessaires pour travailler avec Passim, elles sont requises pour exécuter certaines parties de ce tutoriel (par exemple le carnet Jupyter avec l’exploration des données, ou le script de préparation des données Early English Books Online (EEBO)). Si vous n’êtes pas familier avec Python, veuillez lire la leçon du Programming Historian « Introduction à Python et installation ».
Notez que l’installation de Passim sur Windows est plus difficile que celle pour macOS ou pour Linux. Par conséquent, nous vous recommandons d’utiliser macOS ou Linux (ou une machine virtuelle) pour cette leçon.
Installation de Passim
L’installation de Passim exige l’installation des logiciels ci-dessous :
Mais pourquoi toutes ces dépendances sont-elles nécessaires ?
Passim est écrit dans un langage de programmation appelé Scala. Pour exécuter un logiciel écrit en Scala, ses sources doivent être compilées en un fichier JAR exécutable, ce qui est réalisé par sbt, l’outil de compilation interactif de Scala. Enfin, puisque Passim est conçu pour travailler également sur des grandes collections de textes (avec plusieurs milliers ou millions de documents), il utilise en coulisse Spark, un framework de calcul en cluster qui est écrit en Java. L’utilisation de Spark permet à Passim de gérer le traitement distribué de certaines parties du code, ce qui est utile lors de la manipulation de grandes quantités de données. Le Spark glossary est une ressource utile pour apprendre la terminologie de base de Spark (des mots comme « driver », « executor », etc.), toutefois apprendre cette terminologie n’est pas indispensable si vous exécutez Passim sur un petit ensemble de données.
Avant d’installer cet ensemble de logiciels, vous aurez besoin de télécharger le code source de la version 1 de Passim depuis GitHub :
>>> git clone https://github.com/dasmiq/passim.git --branch v1.0.0
ou téléchargez le code source depuis la page de la version v1.0.
Si vous n’êtes pas familier avec Git et Github, nous vous recommandons de lire la leçon du Programming Historian qui offre une introduction à la gestion de versions Git avec l’application GitHub Desktop.
Instructions pour macOS
Ces instructions sont destinées aux utilisateurs de macOS d’Apple et ont été testées sous la version 10.13.4 (alias High Sierra).
Vérification de l’installation de Java
Assurez-vous que vous disposez du kit de développement Java 8 en tapant la commande suivante dans une nouvelle fenêtre de l’invite de commande :
>>> java -version
Si le résultat de cette commande ressemble à l’exemple suivant, alors Java 8 est installé sur votre ordinateur.
openjdk version "1.8.0_262"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_262-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.262-b10, mixed mode)
Installation de Java 8
Si une autre version de Java est déjà installée sur votre ordinateur, suivez les prochaines étapes afin d’installer Java 8, tout en conservant la version déjà installée de Java.
Ceci est important afin de ne pas casser les liens avec les logiciels déjà installés qui ont besoin de versions plus récentes de Java.
-
Installez le gestionnaire de paquets
brewen suivant les instructions d’installation sur le site Brew.sh. Une fois l’installation achevée, exécutezbrew --helppour qu’elle fonctionne. -
Utilisez
brewpour installer Java 8.
>>> brew cask install adoptopenjdk/openjdk/adoptopenjdk8
Vérifiez que Java 8 est bien installé.
>>> /usr/libexec/java_home -V
Cette commande devrait produire quelque chose de semblable à ce qui suit :
Matching Java Virtual Machines (2):
13.0.2, x86_64: "Java SE 13.0.2" /Library/Java/JavaVirtualMachines/jdk-13.0.2.jdk/Contents/Home
1.8.0_262, x86_64: "AdoptOpenJDK 8" /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home
/Library/Java/JavaVirtualMachines/jdk-13.0.2.jdk/Contents/Home
- Installez
jenv, un outil qui vous permet de gérer plusieurs versions de Java installées sur le même ordinateur et qui vous permet de passer facilement de l’une à l’autre.
>>> brew install jenv
Pour être capable d’appeler jenv sans spécifier le chemin complet du fichier, n’oubliez pas d’ajouter jenv à votre variable d’environnement $PATH en ouvrant le fichier ~/.bashrc avec votre éditeur de texte préféré et en ajoutant les lignes suivantes à la fin du fichier :
# activate jenv
export PATH="$HOME/.jenv/bin:$PATH"
eval "$(jenv init -)"
Après avoir ajouté ces lignes, vous devez soit ouvrir une autre fenêtre de l’invite de commande soit exécuter la ligne suivante pour que la variable $PATH soit mise à jour avec le changement que vous venez de faire (la commande source déclenche le rechargement de votre configuration bash).
>>> source ~/.bashrc
Une fois installé, ajoutez les versions existantes de Java à jenv (c’est-à-dire celles listées par la commande /usr/libexec/java_home -V) :
# il est possible que votre chemin d'accès varie, donc soyez certain de remplacer ce chemin
# avec le véritable chemin d'accès au JAVA_HOME de votre ordinateur
>>> jenv add /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home
Maintenant vous pouvez définir la version par défaut de Java pour ce projet en exécutant ce qui suit :
>>> jenv local 1.8
# Vérifiez
>>> java -version
Compilation de Passim à partir des sources (macOS)
Passim est écrit dans un langage de programmation appelé Scala. Avant de pouvoir exécuter un logiciel écrit en Scala, ses sources doivent être compilées. Cette tâche est effectuée par sbt, l’outil de compilation interactif.
Pour déterminer si sbt est installé sur votre ordinateur, exécutez la commande suivante :
>>> sbt about
Si votre commande affiche bash: sbt: command not found cela signifie que sbt n’est pas installé.
Cependant, Passim est livré avec un script utile (build/sbt) qui téléchargera et installera sbt automatiquement avant de compiler les sources de Passim.
NB : L’utilisation d’un SBT externe (c’est-à-dire déjà installé) peut conduire à des problèmes, nous vous recommandons la méthode suivante pour compiler Passim.
Pour compiler le programme, exécutez la commande suivante depuis le répertoire où vous avez précédemment cloné le dépôt Github de Passim :
>>> cd Passim/
>>> build/sbt package
Cette commande prendra un certain temps (environ 3 minutes sur une connexion moderne), mais elle vous tiendra informé(e) de la progression du téléchargement. Au fur et à mesure que votre ordinateur commence à télécharger les fichiers requis, un journal sera affiché à l’écran. À la fin de ce processus, sbt aura créé une archive .jar contenant les sources compilées pour Passim. Ce fichier se trouve dans le répertoire target: target/scala-2.11/Passim_2.11-0.2.0.jar. Selon la version de Scala et de Passim que vous possèdez, le chemin réel peut être légèrement différent sur votre ordinateur.
Le répertoire bin contient un fichier Passim : il s’agit de l’exécutable qui va lancer Passim. Pour que votre ordinateur connaisse l’emplacement de ce fichier, et donc pour qu’il reconnaisse la commande Passim, il est nécessaire d’ajouter le chemin à la variable d’environnement PATH.
# remplacez /home/simon/Passim par le répertoire où vous avez installé Passim
>>> export PATH="/home/simon/Passim/bin:$PATH"
Pour ajouter le chemin de façon permanente à la variable d’environnement PATH ouvrez le ~/.bashrc avec votre éditeur de texte préféré et ajoutez la ligne suivante n’importe où dans le fichier (puis exécutez source ~/.bashrc pour appliquer ce changement) :
# remplacez /home/simon/Passim par le répertoire où vous avez installé Passim
export PATH="/home/simon/Passim/bin:$PATH"
Installation de Spark
-
Accédez à la section de téléchargement du site Web de Spark et sélectionnez la version publiée de Spark 3.x.x (où x.x indique les éditions de la version 3.) ainsi que le type de paquetage « Pre-built for Apache Hadoop 2.7 » dans les menus déroulants.
- Extrayez les données binaires compressées dans le répertoire de votre choix (par exemple
/Applications) :>>> cd /Applications/ >>> tar -xvf ~/Downloads/spark-3.1.x-bin-hadoop2.7.tgz - Ajoutez le répertoire où vous avez installé Spark à votre variable d’environnement
PATH. Pour ce faire, exécutez temporairement la commande suivante :
>>> export PATH="/Applications/spark-3.1.x-bin-hadoop2.7/bin:$PATH"
Pour ajouter le répertoire d’installation du chemin de façon permanente à votre variable d’environnement PATH, ouvrez le fichier ~/.bashrc avec votre éditeur de texte préféré et ajoutez la ligne suivante n’importe où dans le fichier :
export PATH="/Applications/spark-3.1.x-bin-hadoop2.7/bin:$PATH"
Après avoir édité ~/.bashrc, ouvrez une autre fenêtre de l’invite de commande ou bien exécutez la commande suivante :
>>> source ~/.bashrc
Instructions pour Linux
Ces instructions sont destinées aux distributions basées sur Debian (Debian, Ubuntu, Linux Mint, etc.). Si vous utilisez un autre type de distribution (Fedora, Gentoo, etc.), remplacez les commandes spécifiques à la distribution(par exemple apt) par celles que votre distribution impose.
Vérifiez l’installation de Java
Pour vous assurer que le kit de développement Java 8 est bien installé, exécutez la commande suivante :
>>> java -version
Si la commande ci-dessus renvoie à 1.8.0_252 ou à quelque chose de semblable, alors vous avez installé le kit de développement Java 8 (le 8 vous indique qu’il s’agit du bon kit qui a été installé et qui a été sélectionné par défaut). Si votre résultat est différent, choisissez en conséquence l’une des commandes suivantes :
# Si vous ne l'avez pas, installez-le
>>>> apt install openjdk-8-jdk
# si votre JDK *par défaut* n'est pas la version 8
>>> sudo update-alternatives --config java
Compilation de Passim à partir des sources
Reportez-vous aux instructions de compilation pour macOS, car elles sont les mêmes que pour l’environnement Linux.
Installation de Spark
- Téléchargez les données binaires Spark en utilisant la commande
wget:>>> wget -P /tmp/ http://apache.mirrors.spacedump.net/spark/spark-3.1.2/spark-3.1.2-bin-hadoop2.7.tgz - Extrayez les données binaires compressées dans un répertoire de votre choix :
>>> tar -xvf /tmp/spark-3.1.2-bin-hadoop2.7.tgz -C /usr/local/ - Ajoutez le répertoire dans lequel vous avez installé Spark à votre variable d’environnement
PATH. Pour ajouter temporairement le répertoire à votre variable d’environnementPATH, exécutez la commande suivante :>>> export PATH="/usr/local/spark-3.1.2-bin-hadoop2.7/bin:$PATH" # notez que "/usr/local/" est le répertoire spécifié ci-dessus, si vous avez spécifié un autre répertoire, changez-le en conséquence.Pour ajouter le répertoire à votre variable d’environnement
PATHde façon permanente, ouvrez le fichier~/.bashrcavec votre éditeur de texte préféré et ajoutez la ligne suivante n’importe où dans le fichier :export PATH="/Applications/spark-3.1.x-bin-hadoop2.7:$PATH"Après avoir modifié
~/.bashrc, vous devez ouvrir une nouvelle fenêtre de l’invite de commande ou bien exécuter la ligne suivante pour que votre variablePATHsoit mise à jour avec le changement que vous venez de faire.>>> source ~/.bashrc
Vérifiez l’installation
À ce stade, vous avez installé Passim et tous les paquets nécessaires sur votre ordinateur. Si vous tapez Passim --help dans la ligne de commande, vous devriez voir une sortie similaire à ce qui suit :
Ivy Default Cache set to: /Users/matteo/.ivy2/cache
The jars for the packages stored in: /Users/matteo/.ivy2/jars
:: loading settings :: url = jar:file:/Applications/spark-2.4.6-bin-hadoop2.7/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
com.github.scopt#scopt_2.11 added as a dependency
graphframes#graphframes added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-bb5bd11f-ba3c-448e-8f69-5693cc073428;1.0
confs: [default]
found com.github.scopt#scopt_2.11;3.5.0 in spark-list
found graphframes#graphframes;0.7.0-spark2.4-s_2.11 in spark-list
found org.slf4j#slf4j-api;1.7.16 in spark-list
:: resolution report :: resolve 246ms :: artifacts dl 4ms
:: modules in use:
com.github.scopt#scopt_2.11;3.5.0 from spark-list in [default]
graphframes#graphframes;0.7.0-spark2.4-s_2.11 from spark-list in [default]
org.slf4j#slf4j-api;1.7.16 from spark-list in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 3 | 0 | 0 | 0 || 3 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-bb5bd11f-ba3c-448e-8f69-5693cc073428
confs: [default]
0 artifacts copied, 3 already retrieved (0kB/6ms)
20/07/17 15:23:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/07/17 15:23:19 INFO SparkContext: Running Spark version 2.4.6
20/07/17 15:23:19 INFO SparkContext: Submitted application: Passim.PassimApp
20/07/17 15:23:19 INFO SecurityManager: Changing view acls to: matteo
20/07/17 15:23:19 INFO SecurityManager: Changing modify acls to: matteo
20/07/17 15:23:19 INFO SecurityManager: Changing view acls groups to:
20/07/17 15:23:19 INFO SecurityManager: Changing modify acls groups to:
20/07/17 15:23:19 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(matteo); groups with view permissions: Set(); users with modify permissions: Set(matteo); groups with modify permissions: Set()
20/07/17 15:23:20 INFO Utils: Successfully started service 'sparkDriver' on port 62254.
20/07/17 15:23:20 INFO SparkEnv: Registering MapOutputTracker
20/07/17 15:23:20 INFO SparkEnv: Registering BlockManagerMaster
20/07/17 15:23:20 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
20/07/17 15:23:20 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
20/07/17 15:23:20 INFO DiskBlockManager: Created local directory at /private/var/folders/8s/rnkbnf8549qclh_gcb_qj_yw0000gv/T/blockmgr-f42fca4e-0a6d-4751-8d3b-36db57896aa4
20/07/17 15:23:20 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
20/07/17 15:23:20 INFO SparkEnv: Registering OutputCommitCoordinator
20/07/17 15:23:20 INFO Utils: Successfully started service 'SparkUI' on port 4040.
20/07/17 15:23:20 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.0.24:4040
20/07/17 15:23:20 INFO SparkContext: Added JAR file:///Users/matteo/.ivy2/jars/com.github.scopt_scopt_2.11-3.5.0.jar at spark://192.168.0.24:62254/jars/com.github.scopt_scopt_2.11-3.5.0.jar with timestamp 1594992200488
20/07/17 15:23:20 INFO SparkContext: Added JAR file:///Users/matteo/.ivy2/jars/graphframes_graphframes-0.7.0-spark2.4-s_2.11.jar at spark://192.168.0.24:62254/jars/graphframes_graphframes-0.7.0-spark2.4-s_2.11.jar with timestamp 1594992200489
20/07/17 15:23:20 INFO SparkContext: Added JAR file:///Users/matteo/.ivy2/jars/org.slf4j_slf4j-api-1.7.16.jar at spark://192.168.0.24:62254/jars/org.slf4j_slf4j-api-1.7.16.jar with timestamp 1594992200489
20/07/17 15:23:20 INFO SparkContext: Added JAR file:/Users/matteo/Documents/Passim/target/scala-2.11/Passim_2.11-0.2.0.jar at spark://192.168.0.24:62254/jars/Passim_2.11-0.2.0.jar with timestamp 1594992200489
20/07/17 15:23:20 INFO Executor: Starting executor ID driver on host localhost
20/07/17 15:23:20 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62255.
20/07/17 15:23:20 INFO NettyBlockTransferService: Server created on 192.168.0.24:62255
20/07/17 15:23:20 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
20/07/17 15:23:20 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.0.24, 62255, None)
20/07/17 15:23:20 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.0.24:62255 with 366.3 MB RAM, BlockManagerId(driver, 192.168.0.24, 62255, None)
20/07/17 15:23:20 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.0.24, 62255, None)
20/07/17 15:23:20 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.0.24, 62255, None)
Usage: Passim [options] <path>,<path>,... <path>
--boilerplate Detect boilerplate within groups.
--labelPropagation Cluster with label propagation.
-n, --n <value> index n-gram features; default=5
-l, --minDF <value> Lower limit on document frequency; default=2
-u, --maxDF <value> Upper limit on document frequency; default=100
-m, --min-match <value> Minimum number of n-gram matches between documents; default=5
-a, --min-align <value> Minimum length of alignment; default=20
-L, --min-lines <value> Minimum number of lines in boilerplate and docwise alignments; default=5
-g, --gap <value> Minimum size of the gap that separates passages; default=100
-c, --context <value> Size of context for aligned passages; default=0
-o, --relative-overlap <value>
Minimum relative overlap to merge passages; default=0.8
-M, --merge-diverge <value>
Maximum length divergence for merging extents; default=0.3
-r, --max-repeat <value>
Maximum repeat of one series in a cluster; default=10
-p, --pairwise Output pairwise alignments
-d, --docwise Output docwise alignments
--linewise Output linewise alignments
-N, --names Output names and exit
-P, --postings Output postings and exit
-i, --id <value> Field for unique document IDs; default=id
-t, --text <value> Field for document text; default=text
-s, --group <value> Field to group documents into series; default=series
-f, --filterpairs <value>
Constraint on posting pairs; default=gid < gid2
--fields <value> Semicolon-delimited list of fields to index
--input-format <value> Input format; default=json
--schema-path <value> Input schema path in json format
--output-format <value> Output format; default=json
--aggregate Output aggregate alignments of consecutive seqs
-w, --word-length <value>
Minimum average word length to match; default=2
--help prints usage text
<path>,<path>,... Comma-separated input paths
<path> Output path
20/07/17 15:23:20 INFO SparkContext: Invoking stop() from shutdown hook
20/07/17 15:23:20 INFO SparkUI: Stopped Spark web UI at http://192.168.0.24:4040
20/07/17 15:23:21 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/07/17 15:23:21 INFO MemoryStore: MemoryStore cleared
20/07/17 15:23:21 INFO BlockManager: BlockManager stopped
20/07/17 15:23:21 INFO BlockManagerMaster: BlockManagerMaster stopped
20/07/17 15:23:21 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/07/17 15:23:21 INFO SparkContext: Successfully stopped SparkContext
20/07/17 15:23:21 INFO ShutdownHookManager: Shutdown hook called
20/07/17 15:23:21 INFO ShutdownHookManager: Deleting directory /private/var/folders/8s/rnkbnf8549qclh_gcb_qj_yw0000gv/T/spark-dbeee326-7f37-475a-9379-74da31d72117
20/07/17 15:23:21 INFO ShutdownHookManager: Deleting directory /private/var/folders/8s/rnkbnf8549qclh_gcb_qj_yw0000gv/T/spark-9ae8a384-b1b3-49fa-aaff-94ae2f37b2d9
Préparation des données pour Passim
Le but de l’utilisation de Passim est d’automatiser la recherche de passages de texte répétés dans un corpus. Par exemple, un corpus de journaux contient de multiples copies d’un même article, identiques ou légèrement différentes les unes des autres, ainsi que des répétitions de plus petites portions d’une page de journal (par exemple, publicité, liste d’événements, etc.).
Comme le précise la documentation de Passim, « l’entrée de Passim est un ensemble de documents. En fonction du type de données que vous avez, vous pouvez choisir des documents comme des livres entiers, des pages de livres, des numéros entiers de journaux, des articles de journaux individuels, etc. Au minimum, un document est constitué d’une chaîne d’identification et d’une seule chaîne de contenu textuel ». Vous pouvez vous référer à l’exemple de saisie JSON minimale dans la section suivante pour davantage d’informations sur la structure de la saisie pour Passim.
La figure 1 représente schématiquement les données d’entrée et de sortie fournies à Passim. Étant donné qu’il s’agit d’un ensemble de documents en entrée et qu’il est divisé en séries de documents, Passim tentera d’identifier la réutilisation de texte à partir de documents de différentes séries, et non au sein de ces séries. Dans le cas d’un corpus de journaux, les articles d’un même journal appartiendront à la même série de documents, car nous ne sommes pas intéressés par la détection de la réutilisation au sein d’un même journal, mais entre différents journaux.
En fin de compte, ce qui compose un document et comment ces documents devraient être divisés en séries sont les choix que vous devrez faire lorsque vous préparerez vos données pour Passim. Naturellement, la décision sur ce qui constitue des séries de documents dépend directement de vos objectifs ou de vos questions de recherche. Trouver des citations de la Bible dans un corpus de livres est un cas de relation « un à plusieurs » (1,N) de détection de réutilisation de texte, qui exige que les documents soient groupés en deux séries (bible et non_bible). Au contraire, la comparaison entre plusieurs éditions de la Bible (également nommée par collection) peut être considérée comme un cas de relation « plusieurs à plusieurs » (N,N), où chaque édition correspondra et constituera une série de documents (par exemple des pages). Si vos questions de recherche changent à un moment donné, ce qui requiert ainsi une redéfinition des séries de documents, vous devrez également produire de nouvelles données d’entrée pour Passim, afin de refléter ce changement.
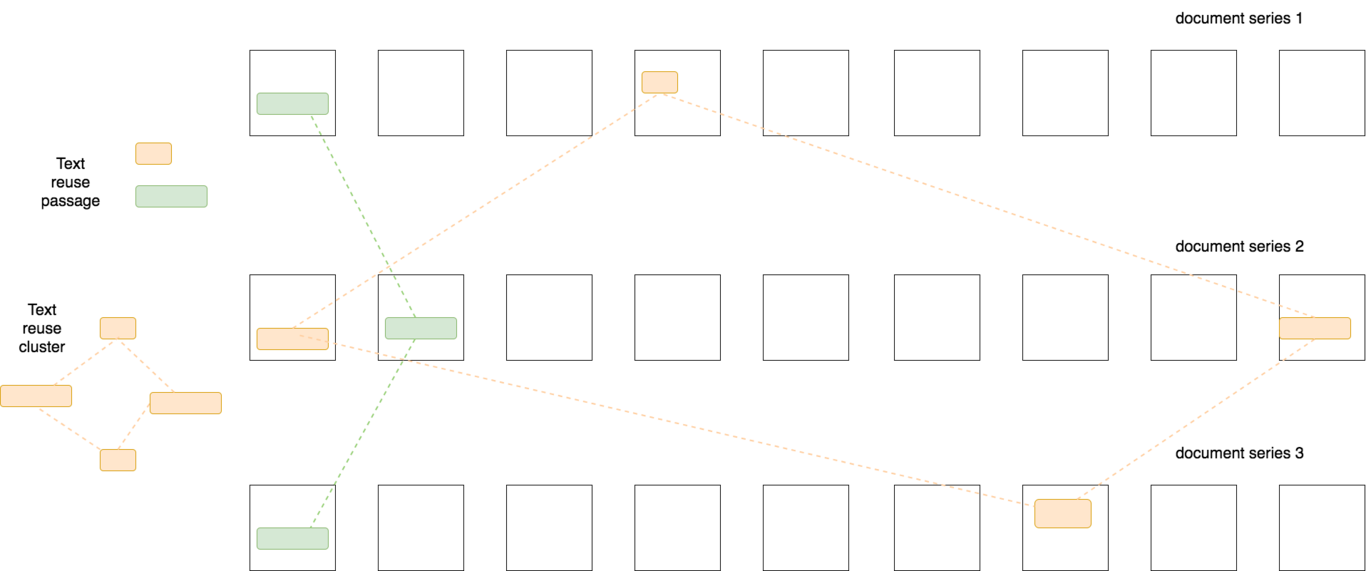
Figure 1. Représentation schématique des clusters de réutilisation de texte ; chaque cluster est formé de passages similaires trouvés dans plusieurs séries de documents.
Format JSON de base
Le format d’entrée de Passim consiste en des documents JSON qui sont au format JSON lines (c’est-à-dire que chaque ligne de texte contient un seul document JSON).
Le contenu suivant d’un fichier nommé test.json illustre le format minimal d’entrée requis pour Passim :
{"id": "d1", "series": "abc", "text": "This is the text of a document."}
{"id": "d2", "series": "def", "text": "This is the text of another document."}
Les champs id, series et text sont les seuls champs obligatoirement requis pour Passim. Avec ce fichier en entrée, le logiciel va tenter de détecter la réutilisation de texte entre les documents de la série abc et ceux de la série def, sur la base du contenu de text.
Tout au long de ce tutoriel, nous utiliserons l’outil en ligne de commande jq pour inspecter et effectuer quelques traitements de base sur les données JSON en entrée et en sortie. Notez que, si vous n’avez pas installé jq, vous devrez exécuter sudo apt-get install jq sous Ubuntu ou brew install jq sous macOS (pour les autres systèmes d’exploitation référez-vous à la page officielle d’installation de JQ).
Par exemple, pour sélectionner et afficher le champ series de votre entrée test.json, exécutez la commande suivante :
>>> jq '.series' test.json
# ce qui affichera
"abc"
"def"
Note : Si vous employez jq pour consulter vos données JSON, vous devez utiliser le paramètre --slurp chaque fois que vous voulez traiter le contenu d’un ou plusieurs fichiers de lignes JSON comme un seul tableau de documents JSON et y appliquer des filtres (par exemple, pour sélectionner et afficher un seul document, utilisez la commande suivante jq --slurp '.[-1]' test.json). Sinon jq traitera chaque document séparément, ce qui provoquera alors l’erreur suivante :
>>> jq '.[0]' test.json
jq: error (at <stdin>:1): Cannot index string with string "series"
jq: error (at <stdin>:2): Cannot index string with string "series"
Note au sujet du stockage des données
En fonction de la taille totale de vos données, il peut être judicieux de stocker les fichiers d’entrée de Passim sous forme de fichiers compressés. Passim supporte plusieurs schémas de compression comme .gzip et .bzip2. Notez qu’un flux de données compressé sera plus lent à traiter qu’un flux non compressé, donc l’utilisation de cette option ne sera bénéfique que si vos données sont volumineuses (par exemple des gigaoctets de texte), si vous avez accès à une grande puissance de calcul, ou si vous disposez d’une quantité limitée d’espace disque.
Cette commande ou, mieux, cette chaîne de commandes produira le premier document dans un fichier de lignes JSON compressé par bzip2 (certains champs ont été tronqués pour des raisons de lisibilité) :
>>> bzcat impresso/GDL-1900.jsonl.bz2 | jq --slurp '.[0]'
Et produira le résultat suivant :
{
"series": "GDL",
"date": "1900-12-12",
"id": "GDL-1900-12-12-a-i0001",
"cc": true,
"pages": [
{
"id": "GDL-1900-12-12-a-p0001",
"seq": 1,
"regions": [
{
"start": 0,
"length": 13,
"coords": {
"x": 471,
"y": 1240,
"w": 406,
"h": 113
}
},
{
"start": 13,
"length": 2,
"coords": {
"x": 113,
"y": 1233,
"w": 15,
"h": 54
}
},
...
]
}
],
"title": "gratuitement ,la §azette seia envoyée",
"text": "gratuitement\n, la § azette\nseia envoyée\ndès ce jour au 31 décembre, aux personnes\nqui s'abonneront pour l'année 1901.\nLes abonnements sont reçus par l'admi-\nnistration de la Gazette de Lausanne et dans\ntous les bureaux de poste.\n"
}
Personnalisation du format JSON
Merci de noter d’emblée que cette sous-section n’est pas strictement nécessaire pour exécuter Passim, comme le montrera la deuxième étude de cas. Néanmoins, ces étapes peuvent être utiles aux lecteurs ayant besoin de connaissances plus avancées en ce qui concerne le format et la structure des données d’entrée.
Dans certains cas, il se peut que vous désiriez inclure des informations supplémentaires (c’est-à-dire des champs JSON) dans chaque document d’entrée, en plus des champs obligatoires (id, series, text). Par exemple, lorsque vous travaillez avec des données OCR, il est possible que vous souhaitiez passer les informations de coordonnées de l’image avec le texte de l’article. Passim supporte l’utilisation de données d’entrée qui suivent un format JSON personnalisé, car, en coulisses, il s’appuie sur Spark pour déduire la structure des données d’entrée (c’est-à-dire le schéma JSON). Passim n’utilisera pas directement ces champs, mais il les conservera dans la sortie produite.
Cependant, il arrive quelques fois que Spark ne parvienne pas à déduire la structure correcte des données d’entrée (par exemple, en déduisant un type de données erroné pour un champ donné). Dans cette situation, vous devez informer Passim du schéma correct des données d’entrée.
L’exemple suivant explique une approche pas à pas pour résoudre cette situation relativement rare dans laquelle il faut corriger le schéma JSON qui a été déduit. Passim possède de base la commande json-df-schema, qui exécute un script (Python) pour déduire le schéma à partir de n’importe quelle entrée JSON. Les étapes suivantes sont nécessaires pour déduire la structure à partir de n’importe quelle donnée JSON :
- Installez les bibliothèques Python nécessaires.
>>> pip install pyspark - Extrayez un exemple d’entrée à partir de l’un des fichiers d’entrée compressés.
# ici nous prenons le 3ème document dans le fichier .bz2 # et nous le sauvegardons dans un nouveau fichier local >>> bzcat impresso/data/GDL-1900.jsonl.bz2 | head | jq --slurp ".[2]" > impresso/data/impresso-sample-document.json - Demandez à
json-df-schemade déduire le schéma de nos données à partir de notre fichier d’exemple.>>> json-df-schema impresso/data/impresso-sample-document.json > impresso/schema/Passim.schema.orig
json-df-schema tentera de déduire le schéma JSON des données d’entrée et de le sortir dans un fichier. L’exemple suivant nous montre à quoi ressemble le schéma généré par Passim (Passim.schema.orig) :
{
"fields": [
{
"metadata": {},
"name": "cc",
"nullable": true,
"type": "boolean"
},
{
"metadata": {},
"name": "date",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "id",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "pages",
"nullable": true,
"type": {
"containsNull": true,
"elementType": {
"fields": [
{
"metadata": {},
"name": "id",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "regions",
"nullable": true,
"type": {
"containsNull": true,
"elementType": {
"fields": [
{
"metadata": {},
"name": "coords",
"nullable": true,
"type": {
"fields": [
{
"metadata": {},
"name": "h",
"nullable": true,
"type": "long"
},
{
"metadata": {},
"name": "w",
"nullable": true,
"type": "long"
},
{
"metadata": {},
"name": "x",
"nullable": true,
"type": "long"
},
{
"metadata": {},
"name": "y",
"nullable": true,
"type": "long"
}
],
"type": "struct"
}
},
{
"metadata": {},
"name": "length",
"nullable": true,
"type": "long"
},
{
"metadata": {},
"name": "start",
"nullable": true,
"type": "long"
}
],
"type": "struct"
},
"type": "array"
}
},
{
"metadata": {},
"name": "seq",
"nullable": true,
"type": "long"
}
],
"type": "struct"
},
"type": "array"
}
},
{
"metadata": {},
"name": "series",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "text",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "title",
"nullable": true,
"type": "string"
}
],
"type": "struct"
}
Passim n’a pas reconnu que le champ de coordonnées contient des valeurs entières et il l’a interprété comme un type de données long. A ce stade, nous devons changer le type des sous-champs de coords (c’est-à-dire h, w, x, et y) de "type": "long" à "type": "integer". Ce décalage de type doit être corrigé, sinon Passim traitera les valeurs int comme si elles étaient long, menant potentiellement à des problèmes ou des incohérences dans la sortie générée.
Nous pouvons maintenant enregistrer le schéma dans un nouveau fichier (passim.schema) pour une utilisation ultérieure. Ce schéma est nécessaire pour traiter les données d’entrée fournies par la deuxième étude de cas présentée dans ce cours.
Exécution de Passim
Dans cette section, nous illustrerons l’utilisation de Passim avec deux études de cas distinctes : 1) la détection de citations bibliques dans des textes du XVIIe siècle et 2) la détection de réutilisation de textes dans un large corpus de journaux historiques. La première étude de cas met en évidence certaines bases de l’utilisation de Passim, tandis que la deuxième étude de cas contient de nombreux détails et des pratiques qui pouraient être utiles pour un projet de réutilisation de texte de grande échelle.
Dans le tableau suivant, nous nous basons sur la documentation originale de Passim et expliquons les paramètres les plus utiles que cette bibliothèque offre. Les études de cas ne vous obligent pas à maîtriser ces paramètres, alors n’hésitez pas à passer directement à la section Téléchargement de données et à revenir à cette section lorsque vous serez suffisamment à l’aise pour utiliser Passim sur vos propres données.
| Paramètre | Valeur par défaut | Description | Explication |
|---|---|---|---|
--n |
5 | Ordre des n-grammes pour la détection de réutilisation de textes | Les n-grammes sont des chaînes de mots de longueur N. Ce paramètre vous permet de décider de quel type de n-gramme (unigramme, bigramme, trigramme…) devra être utilisé par Passim lors de la création d’une liste de candidats possibles à la réutilisation de textes. Le réglage de ce paramètre à une valeur plus faible peut aider dans le cas de textes bruités (c’est-à-dire lorsque de nombreux mots d’un texte sont affectés par une ou plusieurs erreurs d’OCR). En effet, plus le n-gramme est long, plus il est susceptible de contenir des erreurs d’OCR. |
--minDF (-l) |
2 | Limite inférieure de la fréquence de document des n-grammes utilisés | Puisque les n-grammes sont utilisés dans Passim pour retrouver des paires de documents candidats, un n-gramme n’apparaissant qu’une seule fois n’est pas utile, car il ne retrouvera qu’un seul document (et non une paire). Pour cette raison, la valeur par défaut de --minDF est de 2. |
--maxDF (-u) |
100 | Limite supérieure de la fréquence du document pour les n-grammes utilisés. | Ce paramètre permettra de filtrer les n-grammes trop fréquents, donc apparaissant de nombreuses fois dans un document donné. Cette valeur a un impact sur les performances, car elle va réduire le nombre de paires de documents récupérés par Passim qui devront être comparés. |
--min-match (-m) |
5 | Nombre minimum de n-grammes correspondants entre deux documents | Ce paramètre vous permet de décider combien de n-grammes doivent être trouvés entre deux documents. |
--relative-overlap (-o) |
0.8 | Proportion, mesurée sur le passage le plus long, que deux passages alignés différents du même document doivent se chevaucher pour être regroupés. | Ce paramètre détermine le degré de similarité des chaînes de caractères que deux passages doivent avoir pour être regroupés. Dans le cas de textes bruités, il peut être préférable de fixer ce paramètre à une valeur plus petite. |
--max-repeat (-r) |
10 | Répétition maximale d’une série dans un cluster | Ce paramètre vous permet de préciser la quantité potentiellement présente d’une série donnée dans un cluster. |
Téléchargement des données
Les échantillons de données nécessaires pour exécuter les exemples de commande dans les deux études de cas peuvent être téléchargés à partir du dépôt Github dédié. Avant de poursuivre les études de cas, téléchargez une copie locale des données en clonant le dépôt.
>>> git clone https://github.com/impresso/PH-Passim-tutorial.git
Il est également possible de télécharger les données de cette leçon via Zenodo.
Etude de cas 1 : Citations bibliques dans des textes du XVIIe siècle
Dans cette première étude de cas, nous nous pencherons sur la réutilisation des textes en utilisant des textes tirés du corpus EEBO-TCP phase I, la version accessible au public de Early English Books Online qui est fournie par l’initiative Text Creation Partnership. Cette étude de cas est un exemple particulier de la réutilisation de texte. Car nous ne nous concentrons pas sur la réutilisation de texte entre auteurs, mais plutôt sur l’influence qu’un seul livre - dans ce cas, la version King James de la Bible publiée en 1611 - a eu sur divers auteurs. Est-il possible de détecter quels documents contiennent des extraits de la Bible ?
Comme il s’agit d’un exemple à petite échelle, qui peut ressembler à une question de recherche réelle qui fait appel aux méthodes de réutilisation des textes, nous n’utiliserons qu’une partie des 25 368 œuvres disponibles dans EEBO-TCP, celles-ci prises aléatoirement. Cette sélection de taille réduite devrait également permettre à toute personne qui lit ce tutoriel d’exécuter cet exemple sur son ordinateur portable personnel. Idéalement, nous recommandons à quelqu’un qui souhaite étudier correctement l’utilisation des citations bibliques dans les textes du XVIIe siècle d’opter pour un corpus tel que Early Modern Multiloquent Authors (EMMA), rassemblé par le projet Mind Bending Grammars de l’Université d’Anvers. Ce corpus a l’avantage de fournir des métadonnées recueillies manuellement dans un format facilement analysable, permettant aux chercheur(e)s de se focaliser sur des auteurs spécifiques, des périodes, etc.
Extraction des données
À la racine du répertoire nouvellement créé se trouve un fichier JSON : passim_in.json. Ce fichier contient toutes nos données, dans le format décrit ci-dessus : un document par ligne (text), structuré avec le strict minimum de métadonnées requises (id, series). Comme il s’agit d’un fichier de petite taille, nous vous encourageons à l’ouvrir à l’aide d’un éditeur de texte tel que Notepad++ sur Windows ou Sublime Text sur Linux/macOS, afin de vous familiariser avec le format des données. Puisque notre étude de cas se concentre sur la détection de passages de la Bible dans plusieurs documents et non pas sur la réutilisation de texte dans tous les documents, nous avons formaté les données de sorte que le champ series contienne bible pour la Bible (dernière ligne de notre fichier JSON), et not_bible pour tous les autres documents. Passim n’analyse pas les documents qui appartiennent à la même série, donc ceci indique effectivement au logiciel qu’il doit comparer l’ensemble des documents avec uniquement la Bible - et non entre eux.
Le dépôt Github d’accompagnement contient un script Python pour transformer EEBO-TCP dans le format JSON requis par Passim et qui est utilisé pour cette leçon. Nous encourageons les lecteurs et les lectrices à le réutiliser et à l’adapter à leurs besoins.
Exécution de Passim
Créez un répertoire dans lequel vous allez stocker la sortie de Passim (nous utiliserons Passim_output_bible mais n’importe quel nom conviendra). Si vous décidez de garder le répertoire par défaut Passim_output_bible, assurez-vous de supprimer tout son contenu (c’est-à-dire les résultats pré-calculés par Passim) soit manuellement, soit en exécutant rm -r ./eebo/Passim_output_bible/*.
Comme nous le verrons plus en détail dans le deuxième cas d’utilisation, Passim, à travers Spark, offre de nombreuses possibilités. Par défaut, Java n’alloue pas beaucoup de mémoire à ses processus, et faire tourner Passim, même sur de très petits jeux de données, fera planter Passim à cause d’une erreur OutOfMemory — même si vous avez un ordinateur qui possède beaucoup de RAM. Pour éviter cela, quand vous appelez Passim, il faut ajouter des paramètres supplémentaires qui diront à Spark d’utiliser davantage de RAM pour ses processus.
Vous êtes maintenant prêt(e)s à vous lancer dans votre premier projet de réutilisation de texte.
-
Déplacez-vous dans le sous-répertoire
eeboen exécutant la commandecd eebo/, en partant du répertoire où vous avez auparavant cloné le dépôtPH-Passim-tutorial. -
Exécutez la commande suivante et allez boire une tasse de votre boisson chaude préférée :
>>> SPARK_SUBMIT_ARGS='--master local[12] --driver-memory 8G --executor-memory 4G' passim passim_in.json passim_output_bible/
Pour l’instant, ne vous souciez pas des arguments supplémentaires SPARK_SUBMIT_ARGS='--master local[12] --driver-memory 8G --executor-memory 4G'; dans la section Etude de Cas 2 nous les expliquerons en détail.
Ce cas de test prend approximativement huit minutes sur un ordinateur portable récent avec huit threads. Vous pouvez également suivre la progression de la détection sur http://localhost:4040 — un tableau de bord interactif créé par Spark. Notez que le tableau de bord se fermera dès que Passim aura terminé son exécution.
Etude de cas 2 : Réutilisation de textes dans un grand corpus de journaux historiques
La deuxième étude de cas est tirée d’impresso, un projet de recherche visant à permettre l’exploration textuelle critique des archives de journaux par la mise en œuvre d’un cadre technologique permettant d’extraire, de traiter, de relier et d’explorer les données des archives de la presse écrite.
Dans ce projet, nous utiliserons Passim pour détecter la réutilisation de texte à grande échelle. Les clusters de réutilisation de texte extraits sont ensuite intégrés dans l’application du projet impresso de deux manières. Premièrement, dans la vue principale de lecture de l’article, les utilisateurs et utilisatrices peuvent facilement voir quelles parties d’un article ont été réutilisées par d’autres articles du corpus. Deuxièmement, il est possible de parcourir tous les clusters dans une page dédiée (actuellement plus de 6 millions), effectuer des recherches de texte intégral sur leur contenu et filtrer les résultats selon un certain nombre de critères (taille du cluster, période couverte, chevauchement lexical, etc.)
De façon plus générale, la détection de la réutilisation de textes dans un corpus de journaux à grande échelle peut s’avérer utile dans les cas suivants :
- Identifier (et éventuellement filtrer) les documents dupliqués avant d’effectuer d’autres étapes de traitement (par exemple, la modélisation des thèmes)
- Étudier la viralité et la propagation des nouvelles
- Étudier les flux d’information, tant à l’intérieur qu’à l’extérieur des frontières nationales
- Permettre aux utilisateurs de découvrir quels contenus, au sein de leurs propres collections, ont généré une réutilisation de texte (par exemple, des discours politiques célèbres, des parties de constitutions nationales, etc.)
Pour cette étude de cas, nous traiterons d’une petite partie du corpus impresso, constituée d’une année de données de journaux (c’est-à-dire 1900) prélevées sur un échantillon de quatre journaux. Le corpus contient 76 journaux provenant de Suisse et du Luxembourg, couvrant une période de 200 ans. Les échantillons de données nécessaires à l’exécution pas à pas de cette étude de cas sont contenus dans le dossier impresso/.
Préparation des données
Le format utilisé dans impresso pour stocker les données des journaux diffère légèrement du format d’entrée de Passim. Nous avons donc besoin d’un script qui se charge de transformer le premier dans le second. Bien que la discussion sur le fonctionnement de ce script dépasse largement le cadre de ce cours, vous pouvez trouver le script de conversion sur le dépôt GitHub d’impresso, si cela vous intéresse. Le résultat de ce script est un fichier JSON par journal et par an, compressé dans une archive .bz2 pour un stockage efficace. Des exemples de ce format peuvent être trouvés dans le répertoire impresso/data et sont montrés dans l’exemple suivant :
>>> ls -la impresso/data/
EXP-1900.jsonl.bz2
GDL-1900.jsonl.bz2
IMP-1900.jsonl.bz2
JDG-1900.jsonl.bz2
Chaque archive de journal est nommée d’après l’identifiant du journal : par exemple, GDL équivaut à la Gazette de Lausanne. Au total, ces quatre fichiers .bz2 contiennent 92 000 articles dans Passim, ce qui correspond à tous les articles publiés en 1900 dans les quatre journaux de l’échantillon.
Parfois, il n’est pas aisé d’inspecter des données conditionnées de cette manière. Mais certaines commandes bash comme bzcat ainsi que jq peuvent nous aider. La chaîne de commandes suivante nous permet par exemple de savoir combien de documents (articles de journaux) sont contenus dans chacun des fichiers d’entrée en comptant leurs ID :
>>> bzcat impresso/data/GDL-1900.jsonl.bz2 | jq --slurp '[.[] |del(.pages)| .id]|length'
28380
Et de la même manière, dans tous les fichiers d’entrée :
>>> bzcat impresso/data/*-1900.jsonl.bz2 | jq --slurp '[.[] |del(.pages)| .id]|length'
92514
Le rôle de ces commandes est de lire le contenu du fichier .bz2 au moyen de bzcat et ensuite d’acheminer à l’aide d’un pipe (|), ce contenu dans jq qui
- se répète à travers tous les documents dans le fichier en ligne JSON
- supprime pour chaque document le champ
pages, car il n’est pas nécessaire et il sélectionne seulement le champid - finalement, calcule la taille de la liste d’identifiants créée par l’expression précédente avec
lengthjq.
Exécution de Passim
Pour traiter les données impresso à travers Passim, effectuez la commande suivante dans une fenêtre Terminal :
SPARK_SUBMIT_ARGS='--master local[12] --driver-memory 10G --executor-memory 10G --conf spark.local.dir=/scratch/matteo/spark-tmp/' Passim --schema-path="impresso/schema/Passim.schema" "impresso/data/*.jsonl.bz2" "impresso/Passim-output/"
Cette commande est composée des paramètres suivants :
SPARK_SUBMIT_ARGSenvoie quelques paramètres de configuration à Spark, la bibliothèque qui s’occupe de l’exécution parallèle des processus--master local[10]:localsignifie que nous exécutons Spark en mode machine unique ;[10]spécifie le nombre de workers (ou threads, dans ce cas précis) sur lesquels les processus doivent être distribués ; (local [*]utilisera le nombre maximum de threads)--executor-memory 4G: L’équivalent de la taille maximale du tas lors de l’exécution d’une application JAVA normale. C’est la quantité de mémoire que Spark alloue à chaque exécuteur--conf spark.local.dir=/scratch/matteo/spark-tmp/: Un répertoire où Spark stocke des données temporaires. Lorsque vous travaillez avec de grands ensembles de données, il est important de spécifier un emplacement qui possède suffisamment d’espace libre sur le disque
--schema-pathspécifie le chemin vers le schéma JSON, en décrivant les données d’entrée à exécuter par Passim (voir la section sur la personnalisation du format JSON de la partie qui porte sur la préparation des données pour Passim pour plus d’informations sur la façon de générer un tel schéma)impresso/data/*.jsonl.bz2spécifie les fichiers d’entrée (c’est-à-dire tous les fichiers contenus dansimpresso/data/avec.jsonl.bz2dans le nom du fichier)impresso/Passim-output/spécifie où Passim doit écrire sa sortie
Si vous voulez limiter le traitement à quelques fichiers d’entrée - par exemple pour limiter l’utilisation de la mémoire - vous pouvez spécifier l’entrée en utilisant la commande suivante :
impresso/data/{EXP-1900.jsonl.bz2,GDL-1900.jsonl.bz2}.jsonl.bz2
Vous pouvez suivre la progression de Passim en cours d’exécution en vous rendant depuis votre navigateur à l’adresse localhost:4040, c’est là que se trouve le tableau de bord accessible de Spark (figure 2).
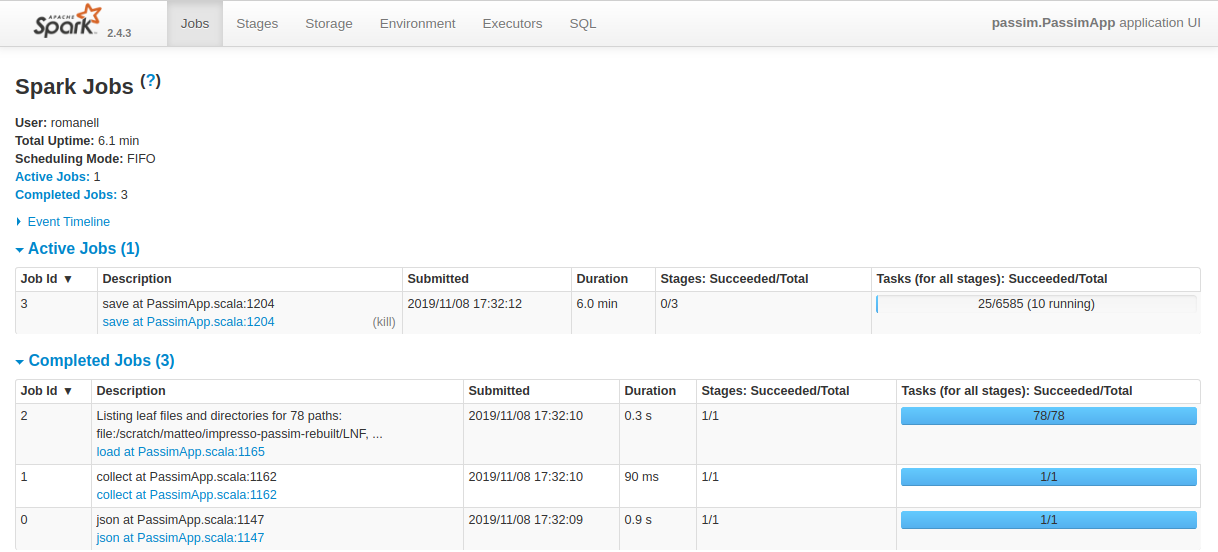
Figure 2. Capture d’écran du tableau de bord de Spark en train d’exécuter Passim.
L’exécution de Passim avec huit workers (et 4 Go de mémoire d’exécution) pour traiter les 92 514 articles publiés en 1900 dans les journaux GDL, JDG, EXP et IMP prend environ 5 minutes, sachant néanmoins que ce temps peut varier.
Si vous fournissez un dossier avec des fichiers *.bz2 en tant qu’entrée, assurez-vous que ces fichiers ne se trouvent pas dans des sous-répertoires, sinon Passim ne sera pas capable de les trouver automatiquement.
Il est important que le dossier de sortie dans lequel Passim écrira ses résultats soit vide. En particulier, lors des premières utilisations, car vous vous familiarisez avec le logiciel. Il est facile de spécifier un dossier de sortie non vide. Si vous avez spécifié un dossier de sortie non vide, cela conduit généralement à une erreur, car Passim traite le contenu du dossier et ne l’écrase pas.
Contrôle de la sortie de Passim
Une fois que le processus de Passim est terminé, le dossier de sortie impresso/Passim-output/ contiendra un sous-dossier out.json/ avec les clusters de réutilisation de texte extraits. Si vous avez spécifié --output=parquet à la place de --output=json, ce sous-dossier sera nommé out.parquet.
Dans la sortie JSON, chaque dictionnaire correspond à un passage de réutilisation de texte. Comme les passages sont agrégés en clusters, chaque passage contient un champ cluster avec l’ID du cluster auquel il appartient.
Pour obtenir le nombre total de cluster, il faut compter le nombre d’ID de clusters qui sont uniques avec la commande suivante :
>>> cat impresso/Passim-output/out.json/*.json | jq --slurp '[.[] | .cluster] | unique | length'
2721
De même, nous pouvons afficher le centième ID du cluster :
>>> cat impresso/Passim-output/out.json/*.json | jq --slurp '[.[] | .cluster] | unique | .[100]'
77309411592
Et avec une simple requête jq, nous pouvons afficher tous les passages qui appartienent à ce cluster de réutilisation de texte :
>>> cat impresso/Passim-output/out.json/*.json | jq --slurp '.[] | select(.cluster==77309411592)|del(.pages)'
{
"uid": -6695317871595380000,
"cluster": 77309411592,
"size": 2,
"bw": 8,
"ew": 96,
"cc": true,
"date": "1900-07-30",
"id": "EXP-1900-07-30-a-i0017",
"series": "EXP",
"text": "nouvel accident de\nmontagne : Le fils dû guide Wyss, de\nWilderswil, âgé de 17 ans, accompagnait\nvendredi un touriste italien dans l'as-\ncension du Petersgrat En descendant sur\nle glacier de Tschingel, le jeune guide\ntomba dans une crevasse profonde de\n25 mètres. La corde était trop courte\npour l'en retirer, et des guides appelés\nà son secours ne parvinrent pas non\nplus à le dégager. Le jeune homme crie\nqu'il n'est pas blessé. Une nouvelle co-\nlonne de secours est partie samedi de\nLauterbrunnen.\nAarau, 28 juillet.\n",
"title": "DERNIÈRES NOUVELLES",
"gid": -8329671890893709000,
"begin": 53,
"end": 572
}
{
"uid": -280074845860282140,
"cluster": 77309411592,
"size": 2,
"bw": 2,
"ew": 93,
"cc": true,
"date": "1900-07-30",
"id": "GDL-1900-07-30-a-i0016",
"series": "GDL",
"text": "NOUVEAUX ACCIOENTS\nInterlaken. 29 juillet.\nLe fils du guide Wyss, de Wilderswil, âgé\nde dix-sept ans, accompagnait, vendredi, un\ntouriste italien dans l'ascension du Peters-\ngrat.\nEn descendant sur le glacier de Tschingel,\nU jeune guide tomba dans une crevasse pro-\nfonde de vingt-cinq mètres. La corde était trop\ncourte pour l'en retirer, et des guides appelés\nà son secours ne parvinrent pas non plus à le\ndégager. Le jeune homme crie qu'il n'est pas\nblessé. Une nouvelle colonne de secours est\npartie samedi de Lauterbrunnen.\nChamonix, 28 juillet.\n",
"title": "(Chronique alpestre",
"gid": 2328324961100034600,
"begin": 20,
"end": 571
}
Comme vous pouvez le voir dans les sorties ci-dessus, ce cluster contient le même article - un accident de montagne qui est survenu à Interlaken le 30 juillet 1900 - rapporté le même jour par deux journaux différents avec des mots qui diffèrent légèrement.
Utilisation de la sortie de Passim
Puisque l’utilisation des données de réutilisation de texte dépend en fin de compte des questions de recherche - et il y a plusieurs applications possibles de la réutilisation de texte, comme nous l’avons vu ci-dessus -, s’intéresser à l’utilisation des sorties de Passim va plus loin que les objectifs de ce cours.
Les données issues de Passim peuvent être ensuite réinvesties à travers d’autres langages de programmation, comme par exemple Python. Les clusters extraits peuvent être utilisés pour dédoublonner des documents dans un corpus, ou même rassembler de multiples témoins du même texte, mais cela dépendra entièrement du contexte de recherche et du cas d’utilisation spécifique.
Afin de donner un exemple sur l’étape suivante, pour celles et ceux qui souhaitent manipuler et approfondir leurs connaissances sur les données de la réutilisation de texte en Python, nous leur fournissons un carnet Jupyter (explore-Passim-output.ipynb) qui explique comment importer des sorties JSON de Passim dans un pandas.DataFrame et comment analyser la distribution des clusters de réutilisation de texte dans les deux cas présentés précédemment. Pour les lecteurs et les lectrices novices qui utilisent la bibliothèque pandas de Python, la leçon du Programming Historian rédigée par Charlie Harper sur la visualisation des données avec Bokeh et Pandas est une bonne lecture d’introduction (et très fortement recommandée).
Le code contenu et expliqué dans le journal produira les graphiques des figures 3 et 4, qui montrent respectivement comment les tailles des clusters de réutilisation de texte sont distribuées dans les données de impresso et dans les données de la Bible.
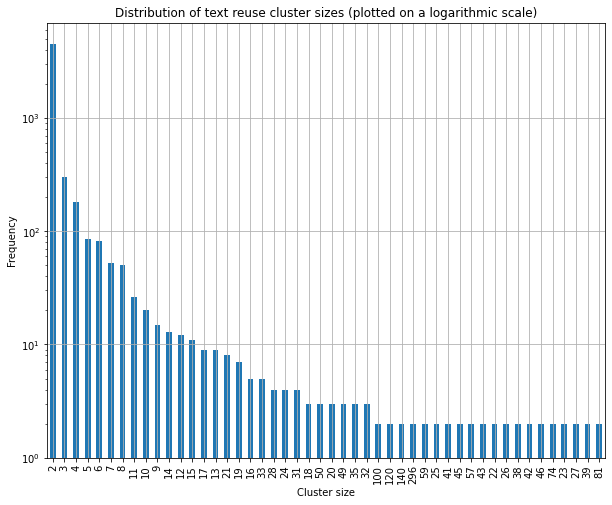
Figure 3. Distribution des tailles des clusters de réutilisation de texte dans l’échantillon de données de impresso.
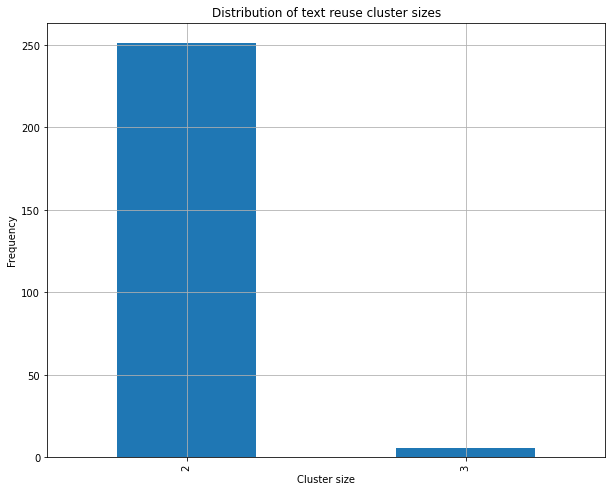
Figure 4. Distribution des tailles des clusters de réutilisation de texte dans les données de l’échantillon biblique.
Comme vous pouvez le voir dans ces graphiques, la majorité des clusters de réutilisation de texte contient au maximum deux passages dans les deux cas. Cependant, dans l’échantillon de données d’impresso, il y a beaucoup plus de variations quant à la taille des clusters, avec 10% des échantillons qui ont une taille comprise entre 6 et 296 passages, contrairement aux données de la Bible, dont la taille maximum d’un cluster n’est que de 3.
Pour aller plus loin
Passim
- Smith et al. (2015) présentent en détail l’algorithme de détection de réutilisation de texte implémenté dans Passim
- Cordell (2015) a employé Passim pour étudier la réutilisation de textes dans un large corpus de journaux américains
textreuse
- Vogler et al. (2020) utilisent le paquetage R
textreuse(Mullen 2016) pour étudier le phénomène de concentration des médias dans le journalisme contemporain
TRACER
- Büchler et al. (2014) expliquent les algorithmes de détection de la réutilisation de textes qui sont mis en œuvre dans TRACER
- Franzini et al. (2018) utilisent et évaluent TRACER pour l’extraction de citations d’un texte latin (le Summa contra Gentiles de Thomas d’Aquin)
BLAST
- Vierthaler et al. (2019) utilisent l’algorithme d’alignement BLAST pour détecter la réutilisation dans des textes chinois
- Vesanto et al. (2017) and Salmi et al. (2019) appliquent BLAST à un corpus complet de journaux publiés en Finlande
Remerciements
Nous remercions sincèrement Marco Büchler et Ryan Muther pour la révision de cette leçon, ainsi que nos collègues Marten Düring et David Smith pour leurs commentaires constructifs sur une première version de ce tutoriel. Nous remercions également Anna-Maria Sichani pour son rôle d’éditrice. (N.D.L.R.) Les remerciements portent sur la version originale en anglais de cette leçon.
Les auteurs remercient chaleureusement le journal Le Temps — propriétaire de La Gazette de Lausanne (GDL) et du Journal de Genève (JDG) — ainsi que le groupe ArcInfo — propriétaire de L’Impartial (IMP) et de L’Express (EXP) — pour avoir accepté de partager leurs données à des fins académiques.
Matteo Romanello remercie le Fonds national suisse de la recherche scientifique (FNS) pour son soutien financier au projet impresso – Media Monitoring of the Past sous le numéro de subvention CR-SII5_173719. Le travail de Simon Hengchen a été soutenu par le programme de recherche et d’innovation Horizon 2020 de l’Union européenne sous la subvention 770299 (NewsEye). Simon Hengchen était affilié à l’Université d’Helsinki et à l’Université de Genève pour la plupart de ces travaux, et est actuellement financé par le projet Towards Computational Lexical Semantic Change Detection soutenu par le Conseil suédois de la recherche (20192022; dnr 2018-01184).
Bibliographie
- Franzini, Greta, Maria Moritz, Marco Büchler et Marco Passarotti. « Using and evaluating TRACER for an Index fontium computatus of the Summa contra Gentiles of Thomas Aquinas ». Proceedings of the Fifth Italian Conference on Computational Linguistics (CLiC-it 2018) (2018). Lien
- Smith, David A., Ryan Cordell et Abby Mullen. « Computational Methods for Uncovering Reprinted Texts in Antebellum Newspapers ». American Literary History 27 (2015). Lien
- Cordell, Ryan. « Reprinting Circulation, and the Network Author in Antebellum Newspapers ». American Literary History 27 (2015): 417–445. Lien
- Vogler, Daniel, Linards Udris et Mark Eisenegger. « Measuring Media Content Concentration at a Large Scale Using Automated Text Comparisons ». Journalism Studies 21, no.11 (2020). Lien
- Mullen, Lincoln. textreuse: Detect Text Reuse and Document Similarity. Github. (2016). Lien
- Büchler, Marco, Philip R. Burns, Martin Müller, Emily Franzini et Greta Franzini. « Towards a Historical Text Re-use Detection ». In Text Mining: From Ontology Learning to Automated Text Processing Applications dir. Chris Biemann et Alexander Mehler, 221–238. Springer International Publishing, 2014. Lien
- Vierthaler, Paul et Meet Gelein. « A BLAST-based, Language-agnostic Text Reuse Algorithm with a MARKUS Implementation and Sequence Alignment Optimized for Large Chinese Corpora ». Journal of Cultural Analytics 4, vol.2 (2019). Lien
- Vesanto, Aleksi, Asko Nivala, Heli Rantala, Tapio Salakoski, Hannu Salmi et Filip Ginter. « Applying BLAST to Text Reuse Detection in Finnish Newspapers and Journals, 1771-1910 ». Proceedings of the NoDaLiDa 2017 Workshop on Processing Historical Language (2017): 54–58. Lien
- Salmi, Hannu, Heli Rantala, Aleksi Vesanto et Filip Ginter. « The long-term reuse of text in the Finnish press, 1771–1920 ». CEUR Workshop Proceedings 2364 (2019): 394–544.
- Soto, Axel J, Abidalrahman Mohammad, Andrew Albert, Aminul Islam, Evangelos Milios, Michael Doyle, Rosane Minghim et Maria Cristina de Oliveira. « Similarity-Based Support for Text Reuse in Technical Writing ». Proceedings of the 2015 ACM Symposium on Document Engineering (2015): 97–106. Lien
- Schofield, Alexandra, Laure Thompson et David Mimno. « Quantifying the Effects of Text Duplication on Semantic Models ». Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (2017): 2737–2747. https://doi.org/10.18653/v1/D17-1290
- Romanello, Matteo, Aurélien Berra et Alexandra Trachsel. « Rethinking Text Reuse as Digital Classicists ». Digital Humanities conference (2014). Lien