
Contenus
- Introduction : penser en termes de données, un défi conceptuel
- De la saisie à la modélisation des données
- Construire une base de données avec nodegoat
- Conclusion
- Notes
Introduction : penser en termes de données, un défi conceptuel
Au moment de faire ses premiers pas dans le monde des humanités numériques, le chercheur ou la chercheuse en sciences humaines se confronte à plusieurs défis. Ce sont souvent des défis techniques : l’emploi des outils numériques n’est pas toujours évident et la maitrise d’une méthode, d’un logiciel ou encore plus d’un langage de programmation exige souvent une pratique longue et parfois ardue. Il existe néanmoins un autre type de défi, différent mais tout aussi complexe que les défis techniques : savoir conceptualiser sa recherche en termes de « données ».
Mais alors, de quoi parle-t-on quand on parle de « données » ? De manière générale, nous pouvons définir les données (en anglais, « data ») comme des informations structurées en unités discrètes et se prêtant au traitement automatique. La nature et la structure de ces informations doivent permettre d’arriver toujours aux mêmes résultats en répétant avec elles les mêmes opérations.
Mettre en données l’objet d’une recherche implique un certain travail de traduction : il faut traduire nos informations depuis leur forme de base à une forme structurée. La donnée, contrairement à ce qu’on peut croire, n’est pas du tout « donnée » : elle n’est pas disponible dans la réalité, elle n’attend pas qu’on la cueille – elle est, au contraire, le produit d’un travail d’interprétation et de transformation. Afin de produire ses données, le chercheur ou la chercheuse doit lire ses sources en suivant une problématique définie, en extraire les informations pertinentes et les consigner de manière structurée. 1
Celles et ceux qui font de la recherche en sciences humaines rencontrent souvent des problèmes à ce stade, car la notion même de « donnée » n’est pas limpide. En histoire, en anthropologie ou en littérature, nous pouvons réfléchir aux phénomènes que nous étudions en termes flexibles, ouverts et souvent incertains. Nous avons l’habitude de réfléchir à la subjectivité du chercheur et de donner une place centrale à la contingence. Nous savons analyser les phénomènes politiques, sociaux et culturels en tant qu’objets complexes, difficiles à réduire à un « ensemble de données ». Comme le dit Miriam Posner dans un billet de blog à ce sujet (ma traduction) :
Nous, les chercheurs et chercheuses en sciences humaines, entretenons un rapport avec nos preuves tout à fait différent de celui qu’ont les autres scientifiques, même ceux des sciences sociales. Nous connaissons les choses d’une manière différente que le peuvent les chercheurs et chercheuses d’autres disciplines. Nous pouvons savoir que quelque chose est vrai sans être en mesure de présenter un ensemble de données, comme on l’entend traditionnellement.2
Ainsi, pour les chercheurs et chercheuses en sciences humaines, cela peut sembler contre-intuitif de lire leurs sources, leurs documents ou leurs notes ethnographiques pour en tirer des informations destinées à être insérées dans des catégories fixes, discrètes, structurées dans un tableur. Cela peut même sembler simpliste et superficiel : comment pourrait-on traduire en termes de « données » une tradition politique ; la dimension affective d’une pratique culturelle locale ; les enjeux conceptuels de la philosophie moderne, ou la psychologie d’un personnage littéraire ?
Pourtant, penser notre recherche en termes de données n’amène pas forcément à une simplification ou un aplatissement de notre objet d’étude, comme le montre la nouvelle vague de travaux en histoire quantitative, qui semble faire un retour en force. Ces travaux nous montrent qu’il est possible d’adopter une démarche méthodologique qui fait appel aux données, tout en réservant une place à la complexité et à la subjectivité. Comme le rappelle Johanna Drucker, spécialiste en design graphique, les données recueillies ne sont jamais indépendantes de l’opération de recueil dont elles résultent : au contraire, un travail d’interprétation s’effectue toujours pour capter, saisir et découper ces données de la réalité. Autrement dit, « all data is capta » (toute donnée est captée).3
Pour sa part, l’historien Manfred Thaller insiste sur le fait que les données peuvent représenter la réalité, mais sont insuffisantes si elles n’émanent pas d’un travail d’interprétation. Il propose un schéma hiérarchique qui distingue « données », « information » et « savoir ». Les données sont des symboles qui peuvent être rangés dans un système de représentation ; il en résulte de l’information lorsqu’elles sont interprétées dans un contexte défini. Le savoir, lui, est le produit d’informations qui génèrent une prise de décision ou une action.4
En reconnaissant la complexité mais aussi la nature structurée des données, concevoir notre recherche en termes de données nous offre des avantages importants.
D’abord, enregistrer nos informations en forme de données nous permet de les traiter ensuite par des méthodes numériques automatiques, et de les prêter à des analyses quantitatives. Cela s’avère utile lorsque notre recherche nous demande de manipuler une grande quantité d’information, ou lorsqu’on peut directement prélever des séries de données depuis nos sources (inventaires, données démographiques, etc.).
De plus, le processus même de traduire nos informations en données exige que nous définissions de manière claire et nette les éléments de notre investigation, nos hypothèses et nos questions de recherche. Ceci nous apporte donc un avantage conceptuel. Autrement dit, on devient obligé de formaliser les objets de notre recherche, les relations qui les relient mutuellement, ainsi que la nature et les conséquences de leurs interactions.
Enfin, enregistrer des informations dans une base de données nous permet de les partager facilement avec le reste de la communauté scientifique.
Dans cette leçon, nous discuterons des difficultés auxquelles on est susceptible de se confronter au moment de concevoir une base de données dans le cadre d’une recherche en sciences humaines, en tant que débutant dans le domaine du numérique. Nous allons donc :
- aborder les notions et les dispositifs techniques nécessaires pour concevoir un modèle de données
- faire les premiers pas dans la construction d’une base de données en se servant de l’environnement en ligne nodegoat
Ainsi, nous espérons pouvoir faire comprendre les avantages d’une méthode de travail dont la logique n’est pas toujours évidente pour ceux et celles qui ont reçu une formation en sciences humaines.
De la saisie à la modélisation des données
Comme nous l’avons mentionné, plus nous inspectons nos sources, plus notre recherche produit une quantité conséquente d’informations ; dans ce cas, il est souvent préférable de cataloguer ces informations de manière organisée et structurée. Par exemple, imaginons que nous menions une recherche historique sur un ensemble de livres : un projet hypothétique portant sur les ouvrages produits par les écrivains dissidents des régimes communistes d’Europe de l’Est.
Saisie simple de données tabulaires
Si nous le voulions, nous pourrions enregistrer des informations sur ces livres de manière intuitive, en utilisant les fonctionnalités offertes par un tableur, comme ceci :
Tableau Basique
| Titre | Ville de parution | Auteur |
|---|---|---|
| L’Archipel du Gulag | Paris | Alexandre Soljenitsyne |
| Vie et destin | Genève | Vassili Grossman |
| The New Class | New York | Milovan Djilas |
| The Captive Mind | Paris | Czesław Miłosz |
| La machine et les rouages | Paris | Michel Heller |
| The Intellectuals on the Road to Class Power | Brighton | Geoge Konrad, Ivan Szelenyi |
Ce tableau à trois colonnes constitue une première saisie qui nous permet de visualiser nos informations très simplement. Nous commençons à construire déjà, de manière plutôt élémentaire, ce qui pourrait ensuite devenir un « jeu de données » (en anglais, « dataset »). Chaque ligne dans le tableau représente un « cas », ou « enregistrement », et chaque colonne représente une « caractéristique », ou « attribut » de ces cas . Ici, ce sont le titre, la ville d’édition et l’auteur de chaque ouvrage.
Pour l’instant, cet outil nous suffit car nous n’y conservons qu’une quantité peu conséquente d’information. Mais imaginons que, au fur et à mesure que nous approfondissons notre enquête, nous questionnions de plus en plus les ouvrages et les auteurs. Ainsi, nous multiplierions les informations enregistrées. Nous pourrions, par exemple, élargir le tableau comme suit :
Tableau Élargi
| Titre | Ville de parution | Langue de la première édition | Date de parution | Maison d’édition | Date de fondation de la maison d’édition | Auteur | Nationalité de l’auteur | Ville de naissance de l’auteur | Date de naissance de l’auteur |
|---|---|---|---|---|---|---|---|---|---|
| L’Archipel du Gulag | Paris | Français | 1973 | Le Seuil | 1930 | Alexandre Soljenitsyne | Russe | Kislovodsk | 1918 |
| Vie et destin | Genève | Français | 1980 | L’âge d’homme | 1955 | Vassili Grossman | Russe | Berdytchiv | 1905 |
| The New Class | New York | Anglais | 1957 | Praeger | 1950 | Milovan Djilas | Monténégrine | Podbišće | 1911 |
| The Captive Mind | Paris | Anglais | 1953 | Instytut Literacki | 1946 | Czesław Miłosz | Polonaise | Szetejnie | 1911 |
| La machine et les rouages | Paris | Français | 1985 | Calmann-Lévy | 1920 | Michel Heller | Russe | Moguilev | 1922 |
| The Intellectuals on the Road to Class Power | Brighton | Anglais | 1979 | Harvester Press | ? | George Konrad, Ivan Szelenyi | Hongrois, Hongrois | Berettyóújfalu, Budapest | 1933, 1938 |
Grâce à ce nouveau tableau, nous pouvons maintenant croiser plus d’informations et ainsi approfondir l’analyse. Cela nous permet d’interroger les relations entre les caractéristiques des livres, celles des maisons d’édition et celles des auteurs. Nous pourrions, par exemple, formuler et vérifier l’hypothèse que les auteurs russes publient plus souvent en français, ou nous demander éventuellement si certaines maisons d’édition préfèrent les auteurs d’un certain âge, ou d’une certaine nationalité.
Cependant, plus nous multiplions les cas analysés et les questions posées, plus l’information se multiplie. Ce tableau devient alors bien moins pratique. Dans certains cas, l’information elle-même est compliquée. L’ouvrage The Intellectuals on the Road to Class Power, par exemple, a plus d’un auteur. La maison d’édition Harvester Press n’a pas de date de fondation (car les informations sur cette petite maison d’édition anglaise sont plutôt limitées) – un exemple classique de l’incertitude qui caractérise la recherche en sciences humaines. Il devient donc de plus en plus difficile de lire, croiser et interpréter toutes ces informations.
Quand cela arrive, il est souvent plus utile de commencer à réfléchir aux « relations » qui relient les différents objets de notre recherche et de construire une table qui les représente - une table de données - avant de les rassembler dans une base de données.
Du tableur à la base de données: les principes de modélisation
Qu’est-ce qu’une « base de données » ? De manière générale, il s’agit d’un contenant qui organise des informations selon une certaine structure. Plus spécifiquement, comme le dit Georges Gardarin, une base de données est « un ensemble de données modélisant les objets d’une partie du monde réel et servant de support à une application informatique ».5 Les données dans une base de données doivent pouvoir être « interrogeables » : nous devons pouvoir retrouver toutes les données qui satisfont un certain critère (ici, par exemple, tous les auteurs de nationalité russe ou tous les ouvrages parus en français). C’est cette interrogeabilité qui fait de la base de données un outil puissant d’exploration et d’analyse de nos informations.
Dans cette leçon, nous nous concentrerons sur un type particulier et assez fréquent de base de données : la base de données relationnelle. La structure d’une base de données relationnelle (« base de donnée » par la suite) est un ensemble de tables, reliées de façon à ce que l’on puisse circuler des unes aux autres. La base de données contient notamment deux types d’éléments : les objets et les relations entre ces objets. Chaque objet représente une réalité complexe. Il comporte de nombreuses caractéristiques (ou les « attributs », dans les colonnes) qui s’expriment dans des cas particuliers (les « enregistrements », sur les lignes). Avant de pouvoir construire cette base de données, nous devons donc d’abord définir les objets, les attributs qu’ils contiennent et la façon dont ils sont connectés les uns aux autres. Cela nous oblige à passer par ce que l’on appelle un modèle de données.
Dans notre exemple, nous avons identifié trois objets qui nous intéressent : les ouvrages, les maisons d’édition et les auteurs. Comment sont-ils reliés ? La réponse dépendra surtout de notre problématique de recherche. Dans le cas proposé ici, si notre attention porte sur la problématique du « livre en tant qu’objet de circulation », nous pouvons par exemple imaginer un graphique élémentaire reliant ouvrage, auteur et maison d’édition de cette façon :
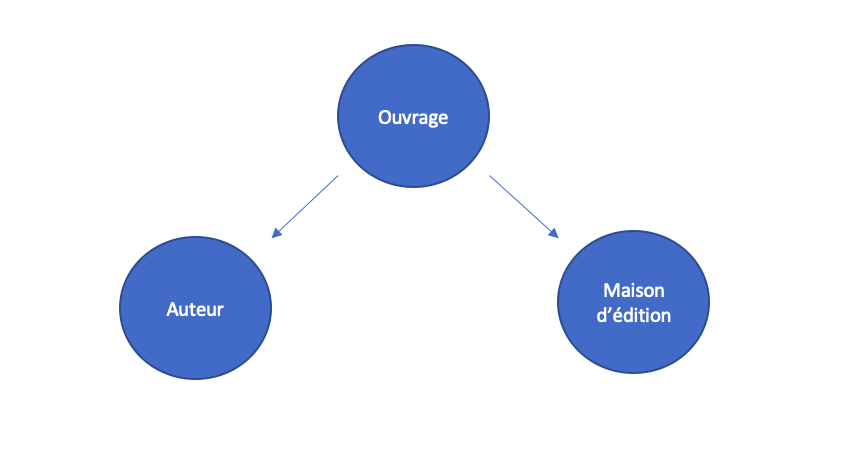
Figure 1. Schéma logique représentant les relations entre ouvrages, maisons d’édition et auteurs.
Ce schéma correspond plus ou moins à un « modèle conceptuel de données »5 représentant les entités qui nous intéressent et les relations qui les relient. Ici, chaque ouvrage est ainsi lié à un certain auteur qui l’a écrit et à une certaine maison d’édition qui l’a publié.
Nous devons ensuite nous demander, comme nous l’avons déjà évoqué :
- quelle information contient chaque objet ?
- de quels éléments est-il est composé ?
- comment exactement ces objets sont-ils reliés entre eux ?
Nos réponses dépendront de leurs attributs respectifs. En suivant le tableau crée plus haut pour cataloguer les informations de notre recherche hypothétique, nous pouvons définir nos objets comme contenant les attributs suivants et comme étant connectés ainsi :
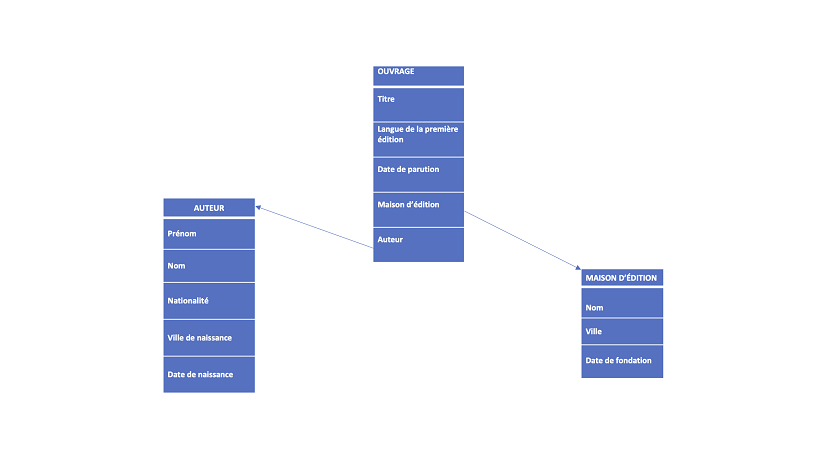
Figure 2. Modèle de données montrant les objets, leurs attributs et leurs relations.
Ceci correspond maintenant à ce que l’on appelle généralement un « modèle logique de données », qui nous permet de définir plus clairement nos objets et leurs relations et, ainsi, d’implémenter le modèle conceptuel. Sur la base de ce schéma, nous pouvons maintenant créer des tables pour enregistrer les caractéristiques de chaque objet séparément :
Table 1 : ouvrage
| Titre | Langue de la première édition | Date de parution | Maison d’édition | Auteur |
|---|---|---|---|---|
| L’Archipel du Gulag | Français | 1973 | Le Seuil | Alexandre Soljenitsyne |
| Vie et destin | Français | 1980 | L’âge d’homme | Vassili Grossman |
| The New Class | Anglais | 1957 | Praeger | Milovan Djilas |
| The Captive Mind | Anglais | 1953 | Instytut Literacki | Czesław Miłosz |
| La machine et les rouages | Français | 1985 | Calmann-Lévy | Michel Heller |
| The Intellectuals on the Road to Class Power | Anglais | 1979 | Harvester Press | Geoge Konrad, Ivan Szelenyi |
Table 2 : auteur
| Prénom | Nom | Nationalité | Ville de naissance | Date de naissance |
|---|---|---|---|---|
| Alexandre | Soljenitsyne | Russe | Kislovodsk | 1918 |
| Vassili | Grossman | Russe | Berdytchiv | 1905 |
| Milovan | Djilas | Monténégrine | Podbišće | 1911 |
| Czesław | Miłosz | Polonaise | Szetejnie | 1911 |
| Michel | Heller | Russe | Moguilev | 1922 |
| Geoge | Konrad | Hongrois | Berettyóújfalu | 1933 |
| Ivan | Szelenyi | Hongrois | Budapest | 1938 |
Table 3 : maisons d’édition
| Nom | Ville | Date de fondation |
|---|---|---|
| Le Seuil | Paris | 1930 |
| L’âge de l’homme | Genève | 1955 |
| Praeger | New York | 1950 |
| Instytut Literacki | Paris | 1946 |
| Calmann-Lévy | Paris | 1920 |
| Harvester Press | Brighton | ? |
Nous avons maintenant organisé ces informations en trois tables qui représentent notre jeu de données. Afin de pouvoir naviguer entre ces tables, en suivant les relations que nous avons établies dans le schéma du modèle de données, il faut maintenant les relier. Pour ce faire, on définit les possibilités et les restrictions qui se manifestent dans leurs relations - nous appelons cela la cardinalité6.
Quand on construit une base de données relationnelle, on doit toujours s’interroger sur les relations qui existent entre les tables : chaque élément d’une table se rapporte-t-il exclusivement à un élément individuel d’une autre table, ou entretient-il des relations multiples et croisées ? Dans le cas exemple des relations entre auteurs et ouvrages : chaque ouvrage a-t-il seulement un auteur (cardinalité 1,1) ? Ou peut-il en avoir deux ou plus, comme The Intellectuals on the Road to Class Power (cardinalité 1,N) ? À l’inverse, chaque auteur d’un livre avec plusieurs auteurs ne pourrait-il pas être l’auteur de plusieurs ouvrages (cardinalité N,N) ? Ces questions se posent certainement au moment de constituer notre base de données7. Les réponses dépendront de notre jeu de données. Dans la partie suivante, nous verrons comment mettre tout ceci en pratique.
Construire une base de données avec nodegoat
La construction d’une base de données relationnelle se fait à l’aide de logiciels spécialisés, les systèmes de gestion de base de données (SGBD), qui permettent d’interroger et de manipuler les données selon les principes du langage de requête SQL. Il existe une multitude de SGBD, sous licence libre ou propriétaires (comme Microsoft Access). Il faut noter que ces logiciels peuvent vite devenir difficiles à manier. C’est pourquoi nous allons nous servir ici du logiciel en ligne nodegoat, spécifiquement conçu pour faciliter ce processus pour les chercheurs et chercheuses en sciences humaines. Comme nous allons le constater, il permet de concevoir un modèle de données de manière flexible ; de gérer et conserver des données en ligne ; d’introduire des informations historiques ayant un certain degré d’incertitude ; d’exporter et importer ces données de manière simple et, enfin, de produire des visualisations telles que cartes ou réseaux.7
Démarrer avec nodegoat
nodegoat est un logiciel en ligne qui permet aux utilisateurs et aux utilisatrices de modéliser, de construire et de partager leur base de données, de façon relativement intuitive. Cette leçon a été conçue en se servant de la version 7.3 de nodegoat, mais nous avons vérifié qu’elle marche tout aussi bien avec la version 8.2 (version en vigueur au moment de la publication de cette leçon). Notez bien que ni l’interface, ni la documentation du logiciel ne sont disponibles en français. Il faut par conséquent avoir une connaissance élémentaire de la langue anglaise afin d’utiliser nodegoat. Avant de commencer, il faut demander l’ouverture d’un compte pour utiliser (gratuitement) nodegoat en ligne. Attention, nodegoat peut prendre jusqu’à 48 heures pour vous accorder votre compte.
nodegoat est un logiciel libre et il est aussi possible de l’installer localement, mais cela exige néanmoins des compétences informatiques poussées. Dans les deux cas (installation locale ou application en ligne), l’utilisation de fonctionnalités plus avancées, notamment pour travailler sur plusieurs projets ou de manière collaborative, requiert de souscrire à l’un des abonnements payants proposés par la société qui le développe.
Les instructions qui suivent visent à guider les lectrices et les lecteurs dans la création d’une base de données sur nodegoat, selon les principes expliqués dans la première partie de la leçon. L’approche que prend le logiciel ressemble fortement à celle qu’on a décrite plus haut pour conceptualiser notre recherche : essentiellement, elle traite les personnes, les groupes et les choses comme des objets, connectés par des relations diverses.8 nodegoat offre aussi des outils d’analyse relationnelle et de production de visualisations telles que cartes ou réseaux. Surtout, le logiciel accepte de consigner des informations incertaines ou ambigües, courantes en sciences humaines. Par exemple, il peut suggérer d’utiliser un intervalle de temps si on ne dispose pas de dates exactes, ou de dessiner un polygone si on ne dispose pas de coordonnées géographiques exactes.
Certes, l’objet de cette leçon n’est pas l’utilisation de nodegoat en soi - vous pouvez tout à fait utiliser d’autres logiciels de gestion de bases de données spécifiquement conçus pour la recherche en sciences humaines et sociales. Malgré tout, en combinant tous ces outils dans un même environnement, nodegoat facilite considérablement l’exercice de concevoir sa recherche en données. Son avantage majeur pour nous, dans cette leçon, est qu’il facilite particulièrement la définition et l’exécution du modèle que nous avons décrit de façon abstraite ci-dessus.
Mettre en place son projet dans nodegoat
En se connectant à nodegoat pour la première fois, nous nous trouvons face à notre Domain (espace de travail), vide pour l’instant, où l’on voit trois onglets : Data (données), Management (gestion) et Model (modèle). Dans Model, nous allons construire notre modèle de données selon la logique expliquée dans la section précédente. Dans Management, nous définirons les paramètres pour mettre en œuvre ce modèle. Enfin, dans Data, nous cataloguerons nos données selon la structure définie par le modèle, et nous examinerons ces données.
Figure 3. Le domaine de nodegoat encore vide.
Définir les objets de la base de données
Nous allons d’abord créer notre projet, puis définir notre modèle de données et construire notre base. En cliquant sur l’onglet Management, créons notre projet (via Add project) et attribuons-lui un titre en utilisant la barre (Name) qui s’affiche : « Ouvrages de l’Est ».
Nous allons ensuite naviguer vers l’onglet Model afin de définir notre modèle de données. Commençons par ajouter un « object type » (type d’objet) en cliquant sur Add Object Type. Dans notre modèle, nous avons déjà défini nos trois types d’objets : l’ouvrage, l’auteur, et la maison d’édition.
Figure 4. L’onglet ‘Model’ et l’option qui nous permet de commencer à définir notre modèle de données.
Sous Name, nous pouvons établir le nom du premier type d’objet de notre jeu de données (« Ouvrage ») et, sous Descriptions, définir ses attributs. Les attributs du type Ouvrage sont le titre, la date de parution ou la langue de la première édition. Il faut bien préciser le type de valeur que prend chaque attribut : String (chaine de caractères) pour les valeurs textuelles comme le titre de l’ouvrage ; Date pour des formats spécifiques comme la date de parution, ou autre en fonction de la nature du jeu de données.
Ici, attention : étant donné que nous incluons le titre de l’ouvrage comme attribut dans Descriptions, il faut désactiver l’option Fixed Field (qui fixe le nom du type d’objet selon la valeur donnée à Name) et cocher à la place la case Name sous notre premier attribut Titre. Le nom des objets du type Ouvrage dans la base de données prendra alors la valeur donnée à l’attribut Titre.
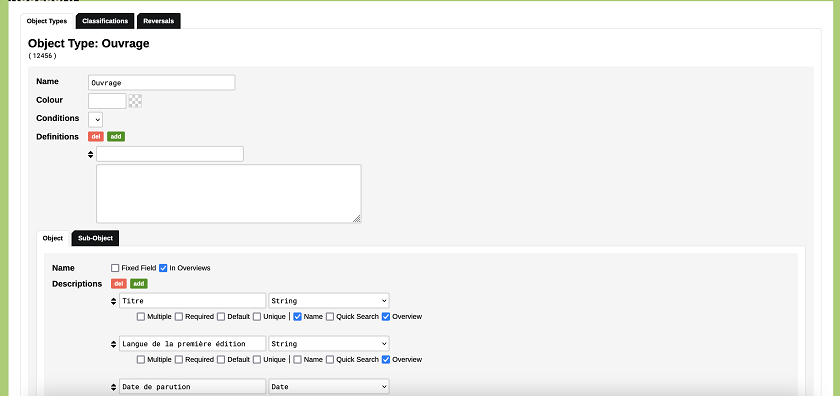
Figure 5. Définition d’un premier type d’objet pour à travers l’option ‘Add Object Type’.
Créons de la même façon les deux autres types d’objets de notre modèle, à savoir l’auteur et la maison d’édition. Sous Name, nous déterminons le nom du type d’objet (Auteur, puis Maison d’Edition) et sous Descriptions, ses attributs. Pour ces deux types aussi, nous choisirons de désactiver l’option Fixed Field et nous cocherons plutôt la case Name sous l’attribut qui donnera le nom de l’élément. Dans le cas de l’auteur, nous pouvons cocher cette option sous Prénom et Nom, attributs séparés dans notre exemple. Ainsi, nous verrons dans l’aperçu de notre base de données que le nom de chaque auteur sera formé de la combinaison de ces deux valeurs.
Pour l’ouvrage, en revanche, nous ne définirons que l’attribut Titre comme Name. Si nous souhaitons éviter que la base de données affiche le titre d’un ouvrage deux fois (en tant que nom de l’objet, et en tant que nom de son attribut Titre), nous pouvons désactiver l’option Overview (à côté de Fixed Field). Notre base de données ne donnera ainsi pas de nom à l’objet autre que les valeurs sous lesquelles nous avons coché Name (ici, donc, le Titre).
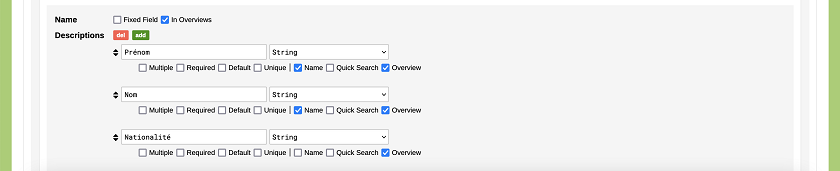
Figure 6. Choix des attributs ‘Prénom’ et ‘Nom’ comme valeurs bases du nom de l’objet.

Figure 7. L’option ‘Overview’ desactivée.
Nous allons maintenant choisir quels types d’objets nous voulons utiliser dans ce projet. Cette distinction est importante, car il est tout à fait possible d’enregistrer une variété de types d’objets dans notre base de données, sans tous les utiliser, ou sans les explorer de la même manière, selon le projet. Naviguons donc vers l’onglet Management (gestion), et cliquons sur l’option Edit, qui s’affiche à droite du nom du projet.
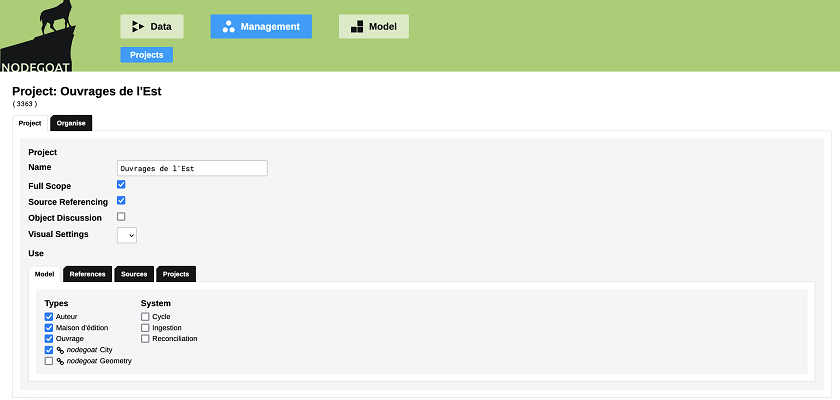
Figure 8. Volet ‘Management’ permettant de gérer le projet et de choisir quels objets seront utilisés.
nodegoat offre en plus deux types d’objets pré-enregistrés, que nous pouvons ici choisir d’utiliser ou non: « City » (ville) et « Geometry » (géométrie). Geometry est utile pour représenter des régions, pays ou autres unités politiques du passé ou du présent. Les données géospatiales de ces deux types d’objets (périmètre, coordonnées géographiques, etc.) proviennent de bases de données géographiques externes telles que GeoNames, qui sont reliées à nodegoat. Il s’agit ainsi de deux types d’objets très utiles et prêts à l’emploi, dont chaque utilisateur et utilisatrice peut se servir pour sa recherche et, inversement, contribuer à enrichir. Dans le cadre de notre projet, nous allons nous servir du type d’objet City, qui contient des informations utiles sur les villes. Le logiciel vient donc de nous aider à améliorer notre modèle de données, en ajoutant un type d’objet à nos trois premiers, ainsi qu’un nombre d’attributs que nous n’avions pas pensé à comprendre initialement, ou dont nous n’aurions pas pu disposer autrement (par exemple, le pays auquel appartient une ville).
Paramétrer la base de données
Il nous reste encore une étape fondamentale à réaliser : établir les relations entre nos objets. Jusqu’ici, nous n’avons fourni que des informations attachées à un seul type d’objet à la fois. Pourtant, l’élément crucial que nous offre cette base de données relationnelle est, justement, de pouvoir relier nos objets entre eux. Pour rappel, nous avons commencé à construire notre modèle en créant des types d’objets que nous avons par la suite activés dans l’onglet Management (gestion). À présent, il nous faut revenir dans l’onglet Model pour connecter chaque type d’objet aux autres. Ce seront les attributs de nos objets qui, comme l’a prescrit notre modèle de données, fonctionneront comme « connecteurs ».
Commençons avec le type d’objet Ouvrage. Via le bouton Edit, nous accédons à l’onglet Object Types puis aux attributs (Descriptions). Deux nous intéressent particulièrement : Auteur et Maison d’édition. L’attribut Auteur relie le type d’objet Ouvrage au type Auteur ; l’attribut Maison d’édition relie le type d’objet Ouvrage au type Maison d’Edition. Dans le menu déroulant à droite du nom des attributs Auteur et Maison d’Edition, activons l’option Reference: Object Type. Ce faisant, un nouveau menu déroulant apparait, affichant une liste des types d’objets de notre modèle. Nous choisissons respectivement Auteur et Maison d’Edition. Le type d’objet Ouvrage est, comme défini dans notre modèle conceptuel, maintenant relié aux types d’objets Auteur et Maison d’Edition, à travers ses attributs Auteur et Maison d’Edition. Les deux types d’objets Auteur et Maison d’Edition deviennent ainsi sources d’informations qui pouront être intégrées dans le type Ouvrage. Nous avons donc concrétisé les liens définis de manière abstraite dans notre modèle.
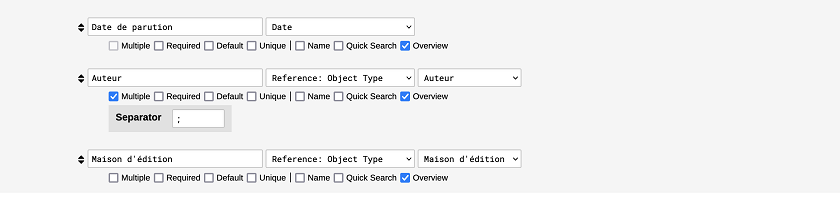
Figure 9. Action pour connecter les objets à travers certains attributs via l’option ‘Reference: Object Type’.
Nous devons ici cocher la case Multiple sous l’attribut Auteur, afin d’indiquer que certains ouvrages peuvent avoir plus d’un auteur, comme dans le cas de The Intellectuals on the Road to Class Power. Il faut aussi sélectionner le symbole que nodegoat utilisera pour séparer les auteurs multiples dans une même case. Les « separators » (séparateurs) les plus fréquemment utilisés sont , ou ; ou encore |, mais attention : vérifiez bien le séparateur de données choisi en format tabulaire au moment de l’export du CSV. S’ils sont les mêmes, cela risque de dérégler la structure des données au moment de l’export.
Enfin, lors de la définition de nos objets et de leurs structures, nous pouvons être confrontés à des informations historiques incertaines. L’exemple de l’ouvrage The Intellectuals on the Road to Class Power illustre bien ce cas, car nous ne connaissons pas la date exacte de fondation de la maison d’édition Harvester Press. Comment faire dans un cas comme celui-ci ? Si notre recherche indique que les publications de cet éditeur commencent dans les années 1970, nous pouvons formuler l’hypothèse que ses débuts d’activité doivent se trouver quelque part entre l’année 1970 et l’année 1979, date de parution de notre ouvrage. nodegoat permet de cataloguer une information temporelle en forme d’intervalle de temps (ce que l’on appelle Chronology), utile dans ce genre de cas.
Pour cela, revenons à l’onglet Model afin d’examiner le type d’objet Maison d’Edition. En toute probabilité, nous avions défini l’attribut Date de fondation de la même manière que la date de naissance d’un auteur : dans l’onglet Objects, sur la liste des Descriptions et en choissisant le type de donnée Date.
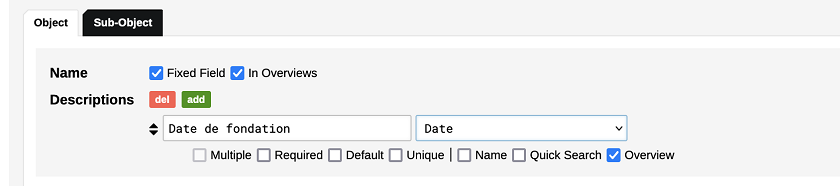
Figure 10. L’attribut ‘Date de fondation’.
Afin de pouvoir consigner plutôt une date en forme d’intervalle de temps, nous devons en revanche nous servir de l’onglet Sub-Object (sous-objet). Ici, nous allons créer un sous-objet appelé Date de fondation et cocher les options Date et Chronology.
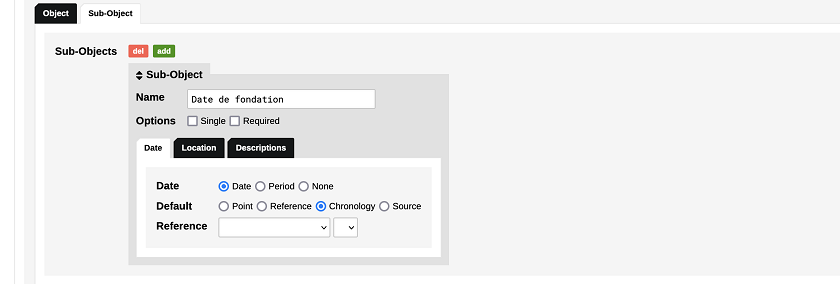
Figure 11. Création d’un sub-objet ‘Chronology’ pour le type ‘Maisons d’Edition’.
Désormais, le type d’objet Maison d’Edition comporte un attribut différent d’Auteur et d’Ouvrage, qui permet d’introduire des informations temporelles en tant qu’intervalles de temps. Avant de continuer, il faudra supprimer l’attribut Date de fondation dans l’onglet Objects, car nous venons de le remplacer par le sous-objet chronologique.
Explorer et exploiter la base de données
Notre modèle, ses types d’objets et leurs relations sont maintenant définies. Si nous revenons sur l’onglet Management et cliquons sur le nom du projet, nodegoat nous montre une visualisation du modèle qui, comme vous le remarquerez, ressemble beaucoup à notre modèle original :
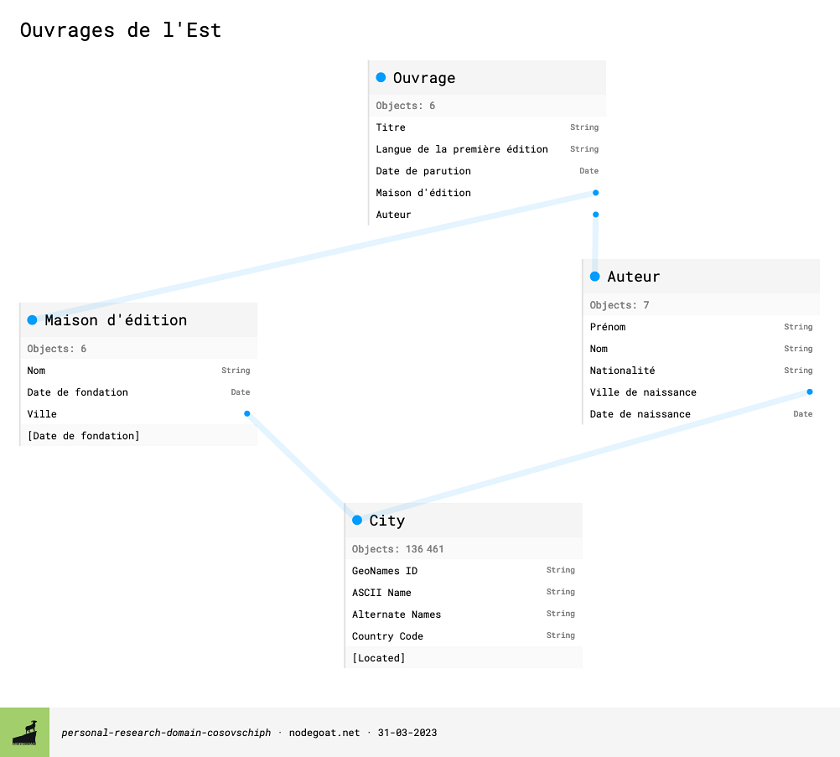
Figure 12. Visualisation de notre modèle de données sur nodegoat.
Nous allons enfin pouvoir renseigner manuellement notre base de données avec les valeurs que nous collecterons au fur et à mesure de notre recherche. Cela se fait depuis l’onglet Data (données) avec l’option Add (ajouter), que l’on voit sur l’onglet de chaque type d’objet.
Notons que l’attribut Date de fondation du type d’objet Maison d’Edition ne s’affiche pas avec les autres attributs, mais en tant qu’élément des Sub-Objects, et dont la date est définie comme Chronology. Le logiciel nous permet ici de renseigner les détails de la chronologie à travers un choix entre trois options : 1) « Point » pour indiquer une date exacte; 2) « Statement » (déclaration) pour indiquer une période après ou avant une certaine date (année, mois ou jour) ; 3) « Between Statements » (entre déclarations) pour indiquer une période comprise entre deux dates (comme dans notre exemple, entre 1970 et 1979).
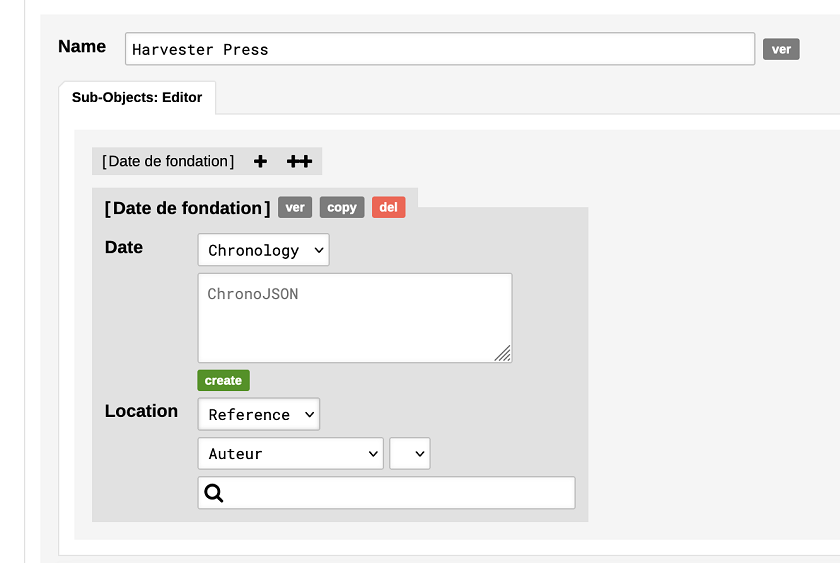
Figure 13. Création d’une chronologie pour Harvester Press.
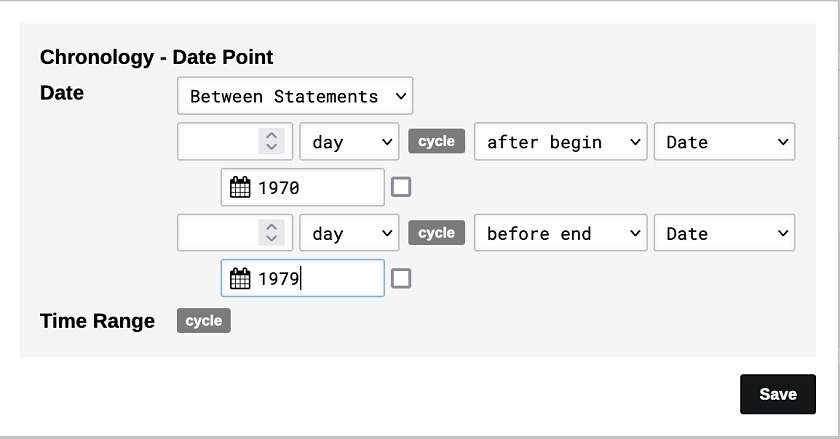
Figure 14. Exemple de chronologie définie comme période « entre déclarations ».
Une fois que nous aurons enregistré tous les ouvrages, auteurs et maisons d’édition, l’interface de consultation de la base de données ressemblera aux images ci-dessous. Il suffira alors de cliquer sur chaque élément pour accéder aux informations le concernant :
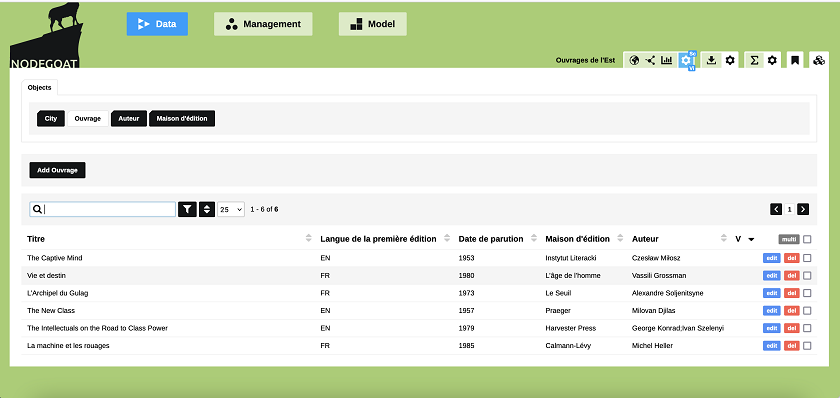
Figure 15. Aperçu des ouvrages dans notre base de données.
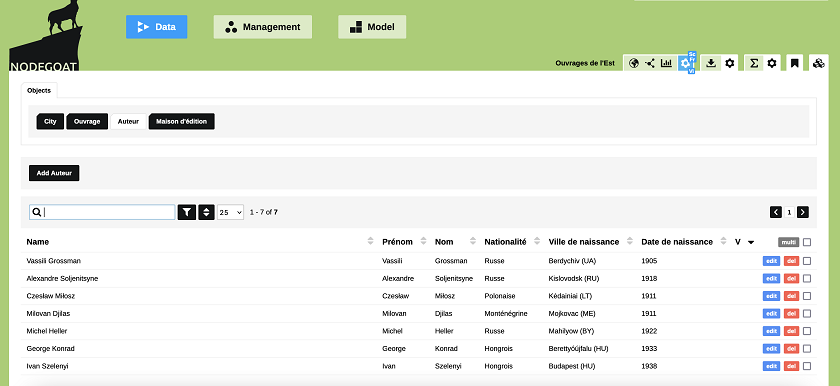
Figure 16. Aperçu des auteurs dans notre base de données.
Nous pouvons aussi importer l’ensemble de nos données après la fin du dépouillement de nos sources, à l’aide de fichiers CSV, plutôt que les enregistrer manuellement au fur et à mesure.
Indépendamment de l’option choisie, une fois notre base de données constituée et peuplée, nous pouvons utiliser les outils de visualisation proposés par le logiciel pour explorer davantage nos objets et leurs relations. Voici, par exemple, une carte fournie par nodegoat pour visualiser les lieux de naissance des auteurs (points bleus) :
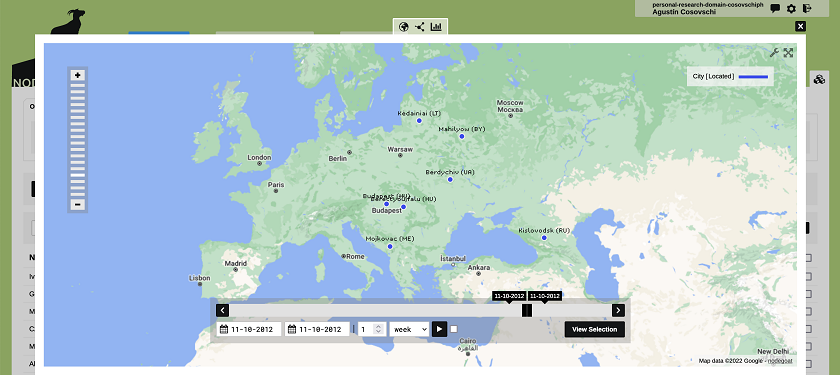
Figure 17. Visualisation géographique des villes de naissance de nos auteurs sur nodegoat.
Somme toute, nodegoat nous permet de définir notre modèle de données et de constituer une base de données de manière relativement simple. Il propose des possibilités multiples pour consigner des informations géographiques et temporelles en prenant en compte l’incertitude qui accompagne souvent le type d’information que nous recueillons en sciences humaines. Par ailleurs, les outils de visualisation permettent d’apprécier l’évolution de notre recherche et d’identifier certaines tendances. Enfin, cet environnement de recherche permet de stocker et de gérer nos données en ligne, tout en offrant la possibilité de les sauvegarder ou de les exporter pour les exploiter à l’aide d’autres outils.
Conclusion
Cette leçon a pour but d’encourager les chercheurs et les chercheuses en sciences humaines à concevoir leur recherche en termes de données, en les initiant à la conception et la réalisation d’une base de données, souvent difficiles pour les néophytes. Nous avons essayé ici de donner certains éléments introductifs en nous servant du logiciel en ligne nodegoat qui est particulièrement adapté aux besoins de celles et ceux qui débutent dans la gestion numérique des données.
Certes, nodegoat comporte aussi certaines limitations : l’accès individuel gratuit est limité à la réalisation d’un seul projet hébergé sur le site du logiciel. Si l’objectif est de gérer plusieurs projets, d’avoir plusieurs comptes ou d’héberger le projet sur un serveur propre, il devient nécessaire de basculer sur un abonnement payant. Celui-ci demande souvent un soutien financier et/ou technique de la part d’une institution de recherche ou d’enseignement.
Pour approfondir votre utilisation de nodegoat et explorer tout son potentiel, nous vous invitons à explorer les Guides préparés par l’équipe de LAB1100, qui expliquent en détail le fonctionnement du logiciel. Sur le site de nodegoat, vous pouvez aussi explorer d’autres exemples de modèles de données proposés par les créateurs, ainsi que des exemples de recherches historiques mobilisant des bases de données.
Notes
-
Lemercier Claire et Claire Zalc, Méthodes quantitatives pour l’historien, Paris, Repères/La Découverte, 2008. DOI : https://doi.org/10.3917/dec.lemer.2008.01 ↩
-
Posner, Miriam, (2015), “Humanities Data: A Necessary Contradiction”, Miriam Posner’s Blog https://miriamposner.com/blog/humanities-data-a-necessary-contradiction/ ↩
-
Drucker, Johanna (2011), “Humanities Approaches to Graphical Display”, Digital Humanities Quarterly 5, n. 1. ↩
-
Thaller, Manfred (2018), “On Information in Historical Sources”, A Digital Ivory Tower, https://ivorytower.hypotheses.org/56 ↩
-
Gardarin, Georges (2003), Bases de données, Paris : Eyrolles. Le livre est librement accessible depuis le site web de l’auteur. ↩ ↩2
-
Voir cette notice de Wikipédia pour plus d’éléments sur la notion de « cardinalité » : « Modèle relationnel », https://fr.wikipedia.org/wiki/Mod%C3%A8le_relationnel#Relation_1:N. Voir aussi Gardarin, ouvrage cité, 412-413. ↩
-
Bree, P. van, Kessels, G., (2013). nodegoat: a web-based data management, network analysis & visualisation environment, http://nodegoat.net from LAB1100 ↩ ↩2
-
Les créateurs de nodegoat décrivent l’approche relationnelle du logiciel comme « orienté-objet ». Ce concept étant le plus souvent utilisé pour décrire un paradigme de programmation informatique, nous préférons éviter l’emploi de ce terme afin d’éviter des confusions. ↩